AWS Big Data Blog
How Zalando innovates their Fast-Serving layer by migrating to Amazon Redshift
While Zalando is now one of Europe’s leading online fashion destination, it began in 2008 as a Berlin-based startup selling shoes online. What started with just a few brands and a single country quickly grew into a pan-European business, operating in 27 markets and serving more than 52 million active customers.
Fast forward to today, and Zalando isn’t just an online retailer—it’s a tech company at its core. With more than €14 billion in annual gross merchandise volume (GMV), the company realized that to serve fashion at scale, it needed to rely on more than just logistics and inventory. It needed data. And not just to support the business—but to drive it.
In this post, we show how Zalando migrated their fast-serving layer data warehouse to Amazon Redshift to achieve better price-performance and scalability.
The scale and scope of Zalando’s data operations
From personalized size recommendations that reduce returns to dynamic pricing, demand forecasting, targeted marketing, and fraud detection, data and AI are embedded across the organization.
Zalando’s data platform operates at an impressive scale, managing over 20 petabytes of data in its lake supporting various analytics and machine learning applications. The data platform hosts more than 5,000 data products maintained by 350 decentralized teams, serving 6,000 monthly users, representing 80% of Zalando’s corporate workforce. As a fully self-service data platform, it provides SQL analytics, orchestration, data discovery, and quality monitoring, empowering teams to build and manage data products independently.
This scale only made the need for modernization more urgent. It was clear that efficient data loading, dynamic compute scaling, and future-ready infrastructure were essential.
Challenges with the existing Fast-Serving Layer (data warehouse)
To enable decisions across analytics, dashboards, and machine learning, Zalando uses a data warehouse that acts as a fast-serving layer and backbone for critical data/reporting use cases. This layer holds about 5,000 curated tables and views, optimized for quick, read-heavy workloads. Every week, more than 3,000 users—including analysts, data scientists, and business stakeholders—rely on this layer for instant insights.
But the incumbent data warehouse wasn’t future proof. It was based on a monolithic cluster setup optimized for peak loads, like Monday mornings, when weekly and daily jobs pile up. As a result, 80% of the time, the system sat underutilized, burning compute and leading to substantial “slack costs” from over-provisioned capacity, with potential monthly savings of over $30,000 if dynamic scaling were possible. Concurrency limitations resulted in high latency and disrupted business-critical reporting processes. The system’s lack of elasticity led to poor cost-to-utilization ratios, while the absence of workload isolation between teams frequently caused operational incidents. Maintenance and scaling required constant vendor support, making it difficult to manage peak periods like CyberWeek due to instance scarcity. Additionally, the platform lacked modern features such as online query editors and proper auto scaling capabilities, while its slow feature development and limited community support further hindered Zalando’s ability to innovate.
Solving for scale: Zalando’s journey to a modern fast serving layer
Zalando was looking for a solution that demonstrated capabilities which could meet their cost and performance targets through a “simple lift and shift” approach. Amazon Redshift was selected for the POC to address autoscaling and concurrency needs, while simultaneously reducing operational efforts as well as its ability to integrate with Zalando’s existing data platform and align with their overall data strategy.
The overall evaluation scope for the Redshift assessment covered following key areas.
Performance and cost
The evaluation of Amazon Redshift demonstrated substantial performance improvements and cost benefits compared to the old data warehousing platform.
- Redshift offered 3-5 times faster query execution time.
- Approximately 86% of distinct queries ran faster on Redshift.
- In a “Monday morning scenario”, Redshift demonstrated 3 times faster accumulated execution time compared to the existing platform
- For short queries, Redshift achieved 100% SLA compliance for queries in the 80-480 second range. For queries up to 80 seconds, 90% met SLA.
- Redshift demonstrated 5x faster parallel query execution, handling significantly higher concurrent queries than the current data warehouse’s maximum parallelism.
- For Interactive Usage use cases, Redshift demonstrated strong performance, which is essential for BI tool users, especially in parallel executions scenario.
- Redshift features such as Automatic Table Optimizations and Automated Materialized views eliminated the need for data producing teams to manually optimize the design of tables, making it highly suitable for a central service offering.
Architecture
Redshift successfully demonstrated workload isolation such as separating transformations(ETL) from serving (BI, Ad-hoc etc.) workload using Amazon Redshift data sharing. It also proved its versatility through integration with Spark and common file formats was also proven.
Security
Amazon Redshift successfully demonstrated end-to-end encryption, auditing capabilities, and comprehensive access controls with Row-Level and Column-Level Security as part of the proof of concept.
Developer productivity
The evaluation demonstrated significant improvements in developer efficiency. A baseline concept for central deployment template authoring and distribution via AWS Service Catalog was successfully implemented. Additionally, Redshift showed impressive agility with its ability to deploy Redshift Serverless endpoints in minutes for ad-hoc analytics, enhancing the team’s ability to quickly respond to analytical needs.
Amazon Redshift migration strategy
This section outlines the approach Zalando took to migrate the fast-serving layer to Amazon Redshift.
From monolith to modular: Redesigning with Redshift
The migration strategy involved a complete re-architecture of the fast-serving layer, moving to Amazon Redshift with a multi-warehouse model that separates data producers from data consumers.Key components and principles of the target architecture include:
- Workload Isolation: Use cases are isolated by instance or environment, with data shares facilitating data exchange between them. Data shares enable an “easy fan out” of data from the Producer warehouse to various Consumer warehouses. The producer and consumer warehouses can be either Provisioned (such as for BI Tools) or Serverless (such as for Analysts). This allows for data sharing between separate legal entities.
- Standardized Data Loading: A Data Loading API (proprietary to Zalando) was built to standardize data loading processes. This API supports incremental loading and performance optimizations. Implemented with AWS Step Functions and AWS Lambda, it detects changed Parquet files from Delta lake metadata and uses Redshift spectrum for loading data into the Redshift Producer warehouse.
- Using Redshift Serverless: Zalando aims to use Redshift Serverless wherever possible. Redshift Serverless offers flexibility, cost efficiency, and improved performance, particularly for the lightweight queries prevalent in BI dashboards. It also enables the deployment of Redshift serverless endpoints in minutes for ad-hoc analytics, enhancing developer productivity.
The following diagram depicts Zalando’s end-to-end Amazon Redshift multi-warehouse architecture, highlighting the producer-consumer model:
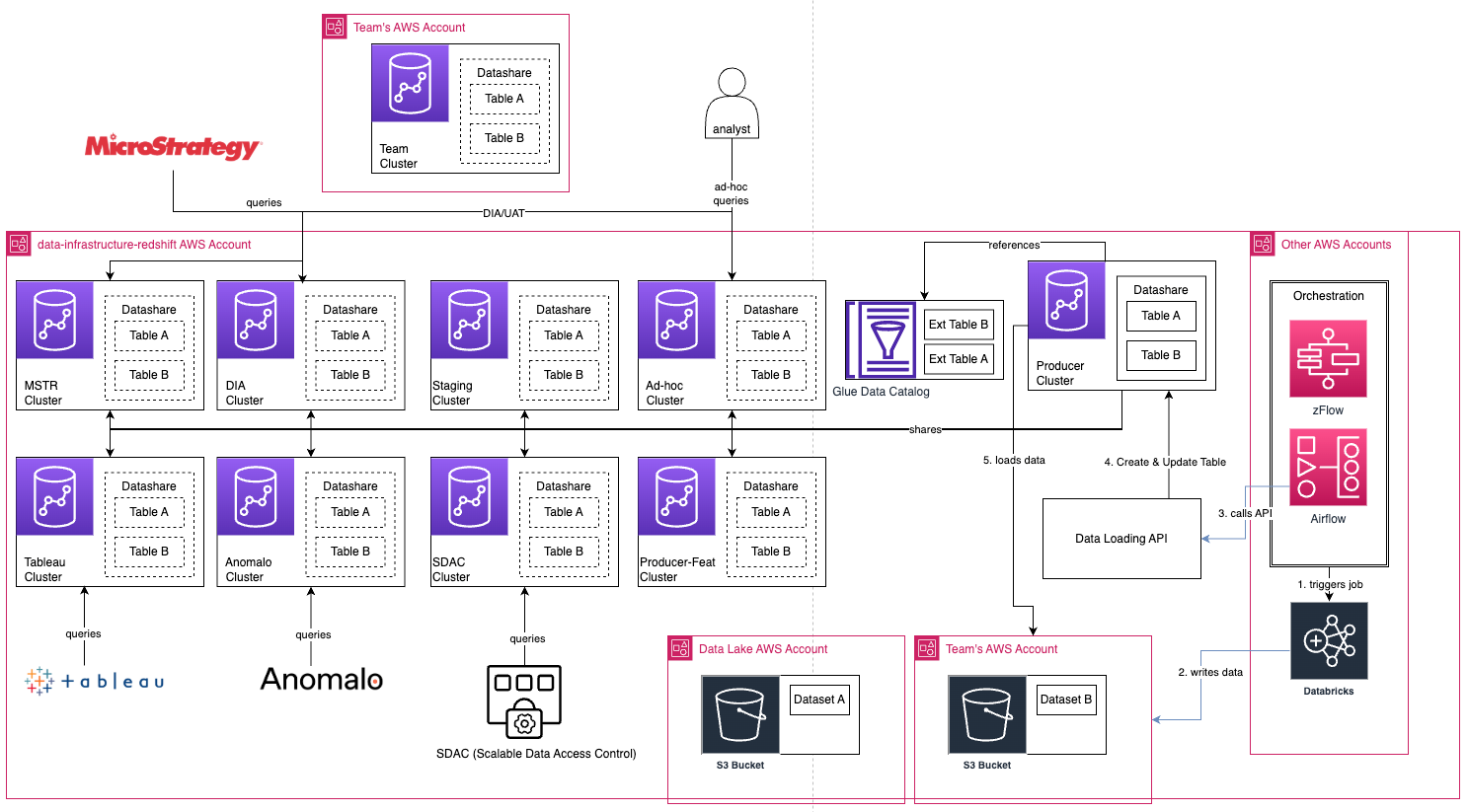
The core strategy of migration was “lift-and-shift” in terms of code to avoid complex refactoring and meet deadlines.
The main principles used were:
- Run tasks in parallel whenever possible.
- Minimize the workload for internal data teams.
- Decouple tasks to allow teams to schedule work flexibly.
- Maximize the work done by centrally managed partners.
Three-stage migration approach
The migration is broken down into three distinct stages to manage the transition effectively.
Stage 1: Data replication
Zalando’s priority was creating a complete, synchronized copy of all target data tables from the old data warehouse to Redshift. An automated process was implemented using Changehub, an internal tool built on Amazon Managed Workflows for Apache Airflow (MWAA), that monitors the old system’s logs and syncs data updates to Redshift approximately every 5-10 minutes, establishing the new data foundation without disrupting existing workflows.
Stage 2: Workload migration
The second stage focused on moving business logic (ETL) and MicroStrategy reporting to Redshift to significantly reduce the load on the legacy system. For ETL migration, semi-automated approach was implemented using Migvisor code convertor to convert the scripts. MicroStrategy reporting was migrated by leveraging MSTR’s capability to automatically generate Redshift-compatible queries based on the semantic layer.
Stage 3: Finalization and decommissioning
The final stage completes the transition by migrating all remaining data consumers and ingestion processes, leading to the full shutdown of the old data warehouse. During this phase, all data pipelines are being rerouted to feed directly into Redshift, and long-term ownership of processes is being transitioned to the respective teams before the old system is fully decommissioned.
Benefits and Results
A major infrastructure change at Zalando occurred on October 30, 2024, switching 80% of analytics reporting from the old data warehouse solution to Redshift. The migration of 80% of analytics reporting to Redshift successfully reduced operational risk for the critical Cyber Week period and enabled the decommissioning of the old data warehouse to avoid significant license fees.
The project resulted in substantial performance and stability improvements across the board.
Performance Improvements
Key performance metrics demonstrate substantial improvements across multiple dimensions:
- Faster Query Execution: 75% of all queries now execute faster on Redshift.
- Improved Reporting Speed: High-priority reporting queries are significantly faster, with a 13% reduction in P90 execution time and a 23% reduction in P99 execution time.
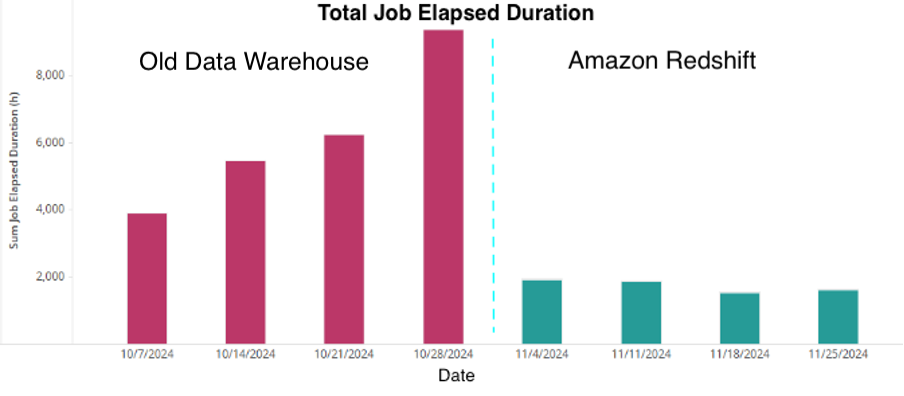
- Drastic Reduction in System Load: The overall processing time for MicroStrategy (MSTR) reports has dramatically decreased. Peak Monday morning execution time dropped from 130 minutes to 52 minutes. In the first four
- weeks, the total MSTR job duration was reduced by over 19,000 hours (equivalent to 2.2 years of compute time) compared to the previous system. This has led to far more consistent and reliable performance.
The following graph shows one of the critical Monday Morning Workload elapsed duration on old-data warehouse as well as Amazon Redshift.
Operational stability
Amazon Redshift has proven to be significantly more stable and reliable, successfully meeting the key objective of reducing operational risk.
- Report Timeouts: Report timeouts, a primary concern, have been virtually eliminated.
- Critical Business Period Performance: Redshift performed exceptionally well during the high-stress Cyber Week 2024. This is a stark contrast to the old system, which suffered critical, financially impactful failures during the same period in 2022 and 2023.
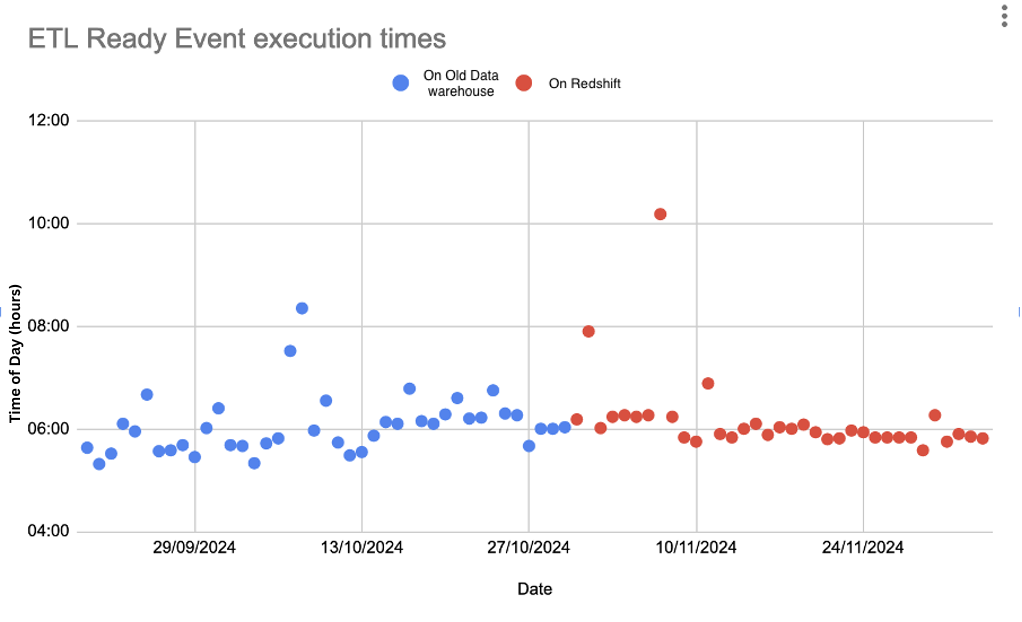
- Data Loading: For data producers, the consistency of data loading is critical, as delays can hold up numerous reports and cause direct business impact. The system relied on an “ETL Ready” event, which triggers report processing only after all required datasets have been loaded. Since the migration to Redshift, the timing of this event has become significantly more consistent, improving the reliability of the entire data pipeline.
The following diagram shows consistency in ETL Ready event, after migrating to Amazon Redshift
End user experience
The reduction in total execution time of Monday morning loads has resulted in dramatically improved end-user productivity. This is the time needed to process the full batch of scheduled reports (peak load), which directly translates to wait times and productivity for end users, since this is when most users need their weekly reports for their business. The following graphs shows typical Mondays before and after the switch and how Amazon Redshift handles the MSTR queue providing much better end user experience.
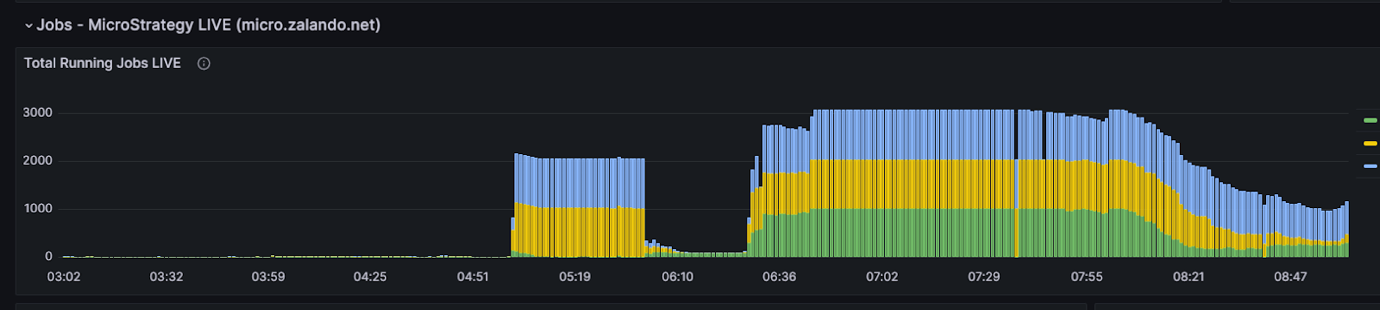 MSTR queue on 28/10/2024 (before switch)
MSTR queue on 28/10/2024 (before switch)
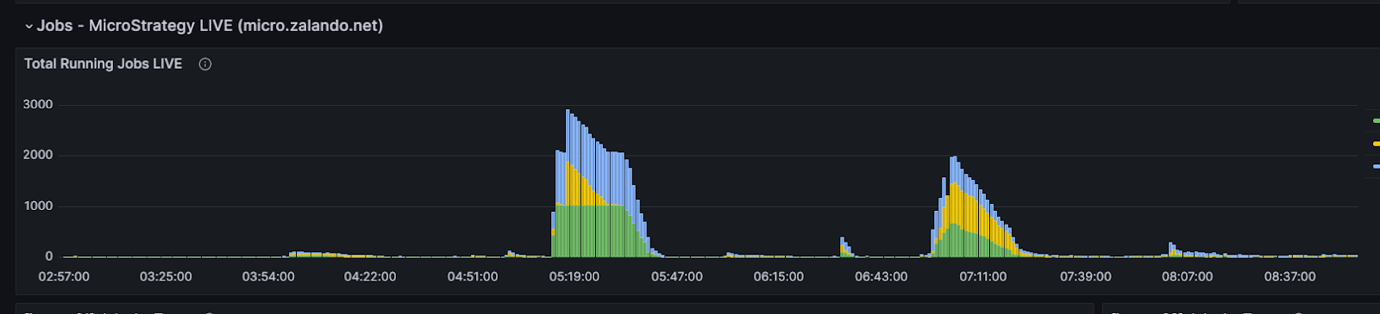 MSTR queue on 02/12/25 (after switch)
MSTR queue on 02/12/25 (after switch)
Learnings and unforeseen challenges
Navigating automatic optimization in a multi-warehouse architecture
One of the most significant challenges Zalando encountered during migration involves Redshift’s multi-warehouse architecture and its interaction with automatic table maintenance. The Redshift architecture is designed for workload isolation: a central producer warehouse for data loading, and multiple consumer warehouses for analytical queries. Data and associated objects reside only on the producer and are shared via Redshift Datashare.
The core issue: Redshift’s Automatic Table Optimization (ATO) operates exclusively on the producer warehouse. This extends to other performance features like Automatic Materialized Views and automatic query rewriting. Consequently, these optimization processes were unaware of query patterns and workloads on consumer warehouses. For instance, MicroStrategy reports running heavy analytical queries on the consumer side were outside the scope of these automated features. This led to suboptimal data models and significant performance impacts, particularly for tables with AUTO-set distribution and sort keys.
To address this, two-pronged approach was implemented:
1. Collaborative manual tuning: Zalando worked closely with the AWS Database Engineering team, who provide holistic performance checks and tailored recommendations for distribution and sort keys across all warehouses.
2. Scheduled table maintenance: Zalando implemented a daily VACUUM process for tables with over 5% unsorted data, ensuring data organization and query performance.
Additionally, following data distribution strategy was implemented:
- KEY Distribution: Explicitly defined DISTKEY for tables with clear JOIN conditions.
- EVEN Distribution: Used for large fact tables without clear join keys.
- ALL Distribution: Applied to smaller dimension tables (under 4 million rows).
This proactive approach has given better control over cluster performance and mitigated data skew issues. Zalando is encouraged that AWS is working to include cross-cluster workload awareness in a future Redshift release, which should further optimize multi-warehouse setup.
CTEs and execution plans
Common Table Expressions (CTEs) are a powerful tool for structuring complex queries by breaking them down into logical, readable steps. Analysis of query performance identified optimization opportunities in CTE usage patterns.
Performance monitoring revealed that Redshift’s query engine would sometimes recompute the logic for a nested or repeatedly referenced CTE from scratch every time it was called within the same SQL statement instead of writing the CTE’s result to an in-memory temporary table for reuse.
Two strategies proved effective in addressing this challenge:
- Convert to a materialized view: CTEs used frequently across multiple queries or with particularly complex logic were converted into materialized views (MVs). This pre-compute the result, making the data readily available without re-running the underlying logic.
- Use explicit temporary tables: For CTEs used multiple times within a single, complex query, the CTE’s result was explicitly written into a temporary table at the beginning of the transaction. For example, within MicroStrategy, the “intermediate table type” setting was changed from the default CTE to “Temporary table.”
Implementation of either materialized views or temporary tables ensures the complex logic is computed only once. This approach eliminated the recomputation issue and significantly improved the performance of multi-layered SQL queries.
Optimizing memory usage by right-sizing VARCHAR columns
It may seem like a minor detail, but defining the appropriate length for VARCHAR columns can have a surprising and significant impact on query performance. This was discovered firsthand while investigating the root cause of slow queries that were showing high amounts of disk spill.
The issue stemmed from data loading API tool, which is responsible for syncing data from Delta Lake tables into Redshift. Because Delta Lake’s StringType datatype does not have a defined length, the tool defaulted to creating Redshift columns with a very high VARCHAR length (such as VARCHAR(16384)).
When a query is executed, the Redshift query engine allocates memory for in-transit data based on the column’s defined size, not the actual size of the data it contains. This meant that for a column containing strings of only 50 characters but defined as VARCHAR(16384), the engine would reserve a vastly oversized block of memory. This excessive memory allocation led directly to high disk spill, where intermediate query results overflowed from memory to disk, drastically slowing down execution.
To resolve this, a new process was implemented requiring data teams to explicitly define appropriate column lengths during object deployment. nalyzing the actual data and setting realistic VARCHAR sizes (such as VARCHAR(100) instead of VARCHAR(16384)), significantly improved memory usage, reduced disk spill, and boosted overall query speed. This change underscores the importance of precision in data definition for an optimized Redshift environment.
Future outlook
Central to Zalando strategy is the shift to a serverless-based warehouse topology. This move enables automatic scaling to meet fluctuating analytical demands, from seasonal sales peaks to new team projects, all without manual intervention. The approach allows data teams to focus entirely on generating insights that drive innovation, ensuring platform performance aligns with business growth.
As the platform scales, responsible management is paramount. The integration of AWS Lake Formation create a centralized governance model for secure, fine-grained data access, enabling safe data democratization across the organization. Simultaneously, Zalando is embedding a strong FinOps culture by establishing unified cost management processes. This provides data owners with a comprehensive, 360-degree view of their costs across Redshift’s services, empowering them with actionable insights to optimize spending and align it with business value. Ultimately, the goal is to ensure every investment in Zalando’s data platform is maximized for business impact.
Conclusion
In this post, we showed how Zalando’s migration to Amazon Redshift has successfully transformed its data platform, making it a more data-driven fashion tech leader. This move has delivered significant improvements across key areas including enhanced performance, increased stability, reduced operational costs, and improved data consistency. Moving forward, a serverless-based architecture, centralized governance with AWS Lake Formation, and a strong FinOps culture will continue to drive innovation and maximize business impact.
If you’re interested in learning more about Amazon Redshift capabilities, we recommend watching the most recent What’s new with Amazon Redshift session in the AWS Events channel to get an overview of the features recently added to the service. You can also explore the self-service, hands-on Amazon Redshift labs to experiment with key Amazon Redshift functionalities in a guided manner.
Contact your AWS account team to learn how we can help you modernize your data warehouse infrastructure.