AWS Big Data Blog
Identify source schema changes using AWS Glue
In today’s world, organizations are collecting an unprecedented amount of data from all kinds of different data sources, such as transactional data stores, clickstreams, log data, IoT data, and more. This data is often in different formats, such as structured data or unstructured data, and is usually referred to as the three Vs of big data (volume, velocity, and variety). To extract information from the data, it’s usually stored in a data lake built on Amazon Simple Storage Service (S3). The data lake provides an important characteristic called schema on read, which allows you to bring data in the data lake without worrying about the schema or changes in the schema on the data source. This enables faster ingestion of data or building data pipelines.
However, you may be reading and consuming this data for other use cases, such as pointing to applications, building business intelligence (BI) dashboards in services like Amazon QuickSight, or doing data discovery using a serverless query engine like Amazon Athena. Additionally, you may have built an extract, transform, and load (ETL) data pipeline to populate your data store like a relational database, non-relational database, or data warehouse for further operational and analytical needs. In these cases, you need to define the schema upfront or even keep an account of the changes in the schema, such as adding new columns, deleting existing columns, changing the data type of existing columns, or renaming existing columns, to avoid any failures in your application or issues with your dashboard or reporting.
In many use cases, we have found that the data teams responsible for building the data pipeline don’t have any control of the source schema, and they need to build a solution to identify changes in the source schema in order to be able to build the process or automation around it. This might include sending notifications of changes to the teams dependent on the source schema, building an auditing solution to log all the schema changes, or building an automation or change request process to propagate the change in the source schema to downstream applications such as an ETL tool or BI dashboard. Sometimes, to control the number of schema versions, you may want to delete the older version of the schema when there are no changes detected between it and the newer schema.
For example, assume you’re receiving claim files from different external partners in the form of flat files, and you’ve built a solution to process claims based on these files. However, because these files were sent by external partners, you don’t have much control over the schema and data format. For example, columns such as customer_id and claim_id were changed to customerid and claimid by one partner, and another partner added new columns such as customer_age and earning and kept the rest of the columns the same. You need to identify such changes in advance so you can edit the ETL job to accommodate the changes, such as changing the column name or adding the new columns to process the claims.
In this solution, we showcase a mechanism that simplifies the capture of the schema changes in your data source using an AWS Glue crawler.
Solution overview
An AWS Glue data crawler is built to sync metadata based on existing data. After we identify the changes, we use Amazon CloudWatch to log the changes and Amazon Simple Notification Service (Amazon SNS) to notify the changes to the application team over email. You can expand this solution to solve for other use cases such as building an automation to propagate the changes to downstream applications or pipelines, which is out of scope for this post, to avoid any failures in downstream applications because of schema changes. We also show a way to delete older versions of the schema if there are no changes between the compared schema versions.
If you want to capture the change in an event-driven manner, you can do so by using Amazon EventBridge. However, if you want to capture the schema changes on multiple tables at the same time, based on a specific schedule, you can use the solution in this post.
In our scenario, we have two files, each with different schemas, simulating data that has undergone a schema change. We use an AWS Glue crawler to extract the metadata from data in an S3 bucket. Then we use an AWS Glue ETL job to extract the changes in the schema to the AWS Glue Data Catalog.
AWS Glue provides a serverless environment to extract, transform, and load a large number of datasets from several sources for analytic purposes. The Data Catalog is a feature within AWS Glue that lets you create a centralized data catalog of metadata by storing and annotating data from different data stores. Examples include object stores like Amazon S3, relational databases like Amazon Aurora PostgreSQL-Compatible Edition, and data warehouses like Amazon Redshift. You can then use that metadata to query and transform the underlying data. You use a crawler to populate the Data Catalog with tables. It can automatically discover new data, extract schema definitions, detect schema changes, and version tables. It can also detect Hive-style partitions on Amazon S3 (for example year=YYYY, month=MM, day=DD).
Amazon S3 serves as the storage for our data lake. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance.
The following diagram illustrates the architecture for this solution.
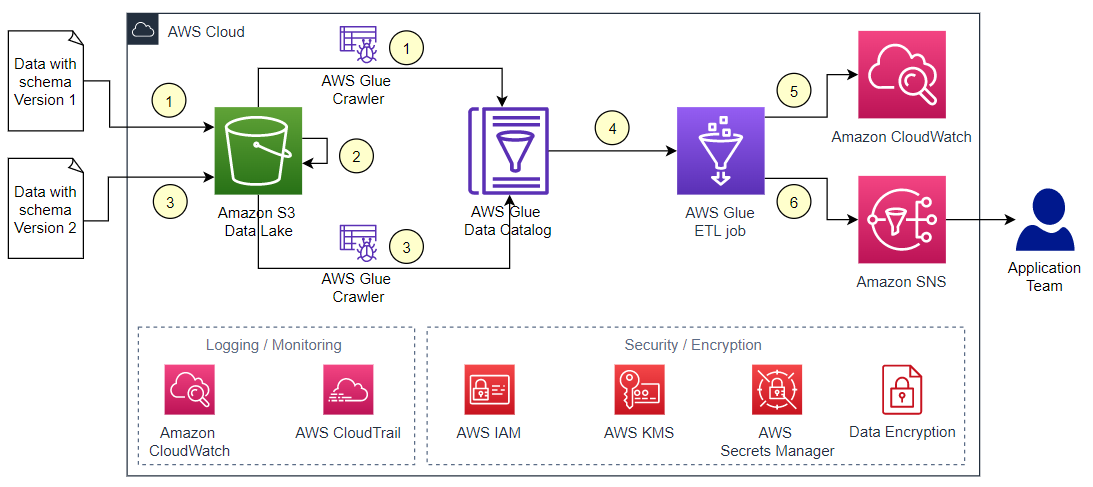
The workflow includes the following steps:
- Copy the first data file to the
datafolder of the S3 bucket and run the AWS Glue crawler to create a new table in the Data Catalog. - Move the existing file from the
datafolder to thearchivedfolder. - Copy the second data file with the updated schema to the
datafolder, then rerun the crawler to create new version of table schema. - Run the AWS Glue ETL job to check if there is a new version of the table schema.
- The AWS Glue job lists the changes in the schema with the previous version of the schema in CloudWatch Logs. If there are no changes in the schema and the flag to delete older versions is set to true, the job also deletes the older schema versions.
- The AWS Glue job notifies all changes in the schema to the application team over email using Amazon SNS.
To build the solution, complete the following steps:
- Create an S3 bucket with the
dataandarchivedfolders to store the new and processed data files. - Create an AWS Glue database and an AWS Glue crawler that crawls the data file in the
datafolder to create an AWS Glue table in the database. - Create an SNS topic and add an email subscription.
- Create an AWS Glue ETL job to compare the two versions of the table schema, list the changes in the schema with the older version of schema, and delete older versions of schema if the flag to delete older versions is set to true. The job also publishes an event in Amazon SNS to notify the changes in the schema to the data teams.
For the purpose of this post, we manually perform the steps to move the data files from the data folder to the archive folder, triggering the crawler and ETL job. Depending on your application needs, you can automate and orchestrate this process through AWS Glue workflows.
Let’s set up the infrastructure required to go through the solution to compare an AWS Glue table version to a version updated with recent schema changes.
Create an S3 bucket and folders
To create an S3 bucket with the data and archived folders to store the new and processed data files, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose Create bucket.
- For Bucket name, enter a DNS-compliant unique name (for example,
aws-blog-sscp-ng-202202). - For Region, choose the Region where you want the bucket to reside.
- Keep all other settings as default and choose Create bucket.
- On the Buckets page, choose the newly created bucket.
- Choose Create folder.
- For Folder name, enter
data. - Leave server-side encryption at its default (disabled).
- Choose Create folder.
- Repeat these steps to create the
archivedfolder in the same bucket.
Create an AWS Glue database and crawler
Now we create an AWS Glue database and crawler that crawls the data file in the data bucket to create an AWS Glue table in the new database.
- On the AWS Glue console, choose Databases in the navigation pane.
- Choose Add database.
- Enter a name (for example,
sscp-database) and description. - Choose Create.
- Choose Crawlers in the navigation pane.
- Choose Add crawler.
- For Crawler name, enter a name (
glue-crawler-sscp-sales-data). - Choose Next.
- For the crawler source type¸ choose Data stores.
- To repeat crawls of the data stores, choose Crawl all folders.
- Choose Next.
- For Choose a data store, choose S3.
- For Include path, choose the S3 bucket and folder you created (
s3://aws-blog-sscp-ng-202202/data). - Choose Next.
- On the Add another data store page, choose No, then choose Next.
- Choose Create an IAM role and enter a name for the role (for example,
sscp-blog). - Choose Next.
- Choose Run on Demand, then choose Next.
- For Database, choose your AWS Glue database (
sscp-database). - For Prefix added to tables, enter a prefix (for example,
sscp_sales_). - Expand the Configuration options section and choose Update the table definition in the data catalog.
- Leave all other settings as default and choose Next.
- Choose Finish to create the crawler.
Create an SNS topic
To create an SNS topic and add an email subscription, complete the following steps:
- On the Amazon SNS console, choose Topics in the navigation pane.
- Choose Create topic.
- For Type, choose Standard.
- Enter a name for the topic (for example,
NotifySchemaChanges). - Leave all other settings as default and choose Create topic.
- In the navigation pane, choose Subscriptions.
- Choose Create subscription.
- For Topic ARN, choose the ARN of the created SNS topic.
- For Protocol, choose Email.
- For Endpoint, enter the email address to receive notifications.
- Leave all other defaults and choose Create subscription.You should receive an email to confirm the subscription.
- Choose the link in the email to confirm.
- Add the following permission policy to the AWS Glue service role created earlier as part of the crawler creation (
AWSGlueServiceRole-sscp-blog) to allow publishing to the SNS topic. Make sure to change <$SNSTopicARN> in the policy with the actual ARN of the SNS topic.
Create an AWS Glue ETL job
Now you create an AWS Glue ETL job to compare two schema versions of a table and list the changes in schemas. If there are no changes in the schema and the flag to delete older versions is set to true, the job also deletes any older versions. If there are changes in schema, the job lists changes in the CloudWatch logs and publishes an event in Amazon SNS to notify changes to the data team.
- On the AWS Glue console, choose AWS Glue Studio.
- Choose Create and manage jobs.
- Choose the Python Shell script editor.
- Choose Create to create a Python Shell job.
- Enter the following code in the script editor field:
- Enter a name for the job (for example,
find-change-job-sscp). - For IAM Role, choose the AWS Glue service role (
AWSGlueServiceRole-sscp-blog). - Leave all other defaults and choose Save.
Test the solution
We’ve configured the infrastructure to run the solution. Let’s now see it in action. First we upload the first data file and run our crawler to create a new table in the Data Catalog.
- Create a CSV file called
salesdata01.csvwith the following contents: - On the Amazon S3 console, navigate to the data folder and upload the CSV file.
- On the AWS Glue console, choose Crawlers in the navigation pane.
- Select your crawler and choose Run crawler.The crawler takes a few minutes to complete. It adds a table (
sscp_sales_data) in the AWS Glue database (sscp-database). - Verify the created table by choosing Tables in the navigation pane.Now we move the existing file in the
datafolder to thearchivedfolder. - On the Amazon S3 console, navigate to the
datafolder. - Select the file you uploaded (
salesdata01.csv) and on the Actions menu, choose Move. - Move the file to the
archivedfolder.Now we copy the second data file with the updated schema to thedatafolder and rerun the crawler. - Create a CSV file called
salesdata02.csvwith the following code. It contains the following changes from the previous version:- The data in the
regioncolumn is changed from region names to some codes (for example, the data type is changed from string to BIGINT). - The
repcolumn is dropped. - The new column
totalis added.
- The data in the
- On the Amazon S3 bucket, upload the file to the
datafolder. - On the AWS Glue console, choose Crawlers in the navigation pane.
- Select your crawler and choose Run crawler.The crawler takes approximately 2 minutes to complete. It updates the schema of the previously created table (
sscp_sales_data). - Verify the new version of the table is created on the Tables page.Now we run the AWS Glue ETL job to check if there is a new version of the table schema and list the changes in the schema with the previous version of the schema in CloudWatch Logs.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Select your job (find-change-job-sscp) and on the Actions menu, choose Edit script.
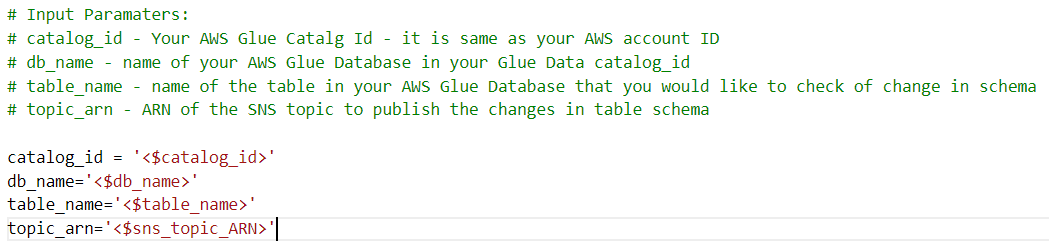
- Change the following input parameters for the job in the script to match with your configuration:
- Choose Save.
- Close the script editor.
- Select the job again and on the Actions menu, choose Run job.
- Leave all default parameters and choose Run job.
- To monitor the job status, choose the job and review the History tab.
- When the job is complete, choose the Output link to open the CloudWatch logs for the job.
The log should show the changes identified by the AWS Glue job.
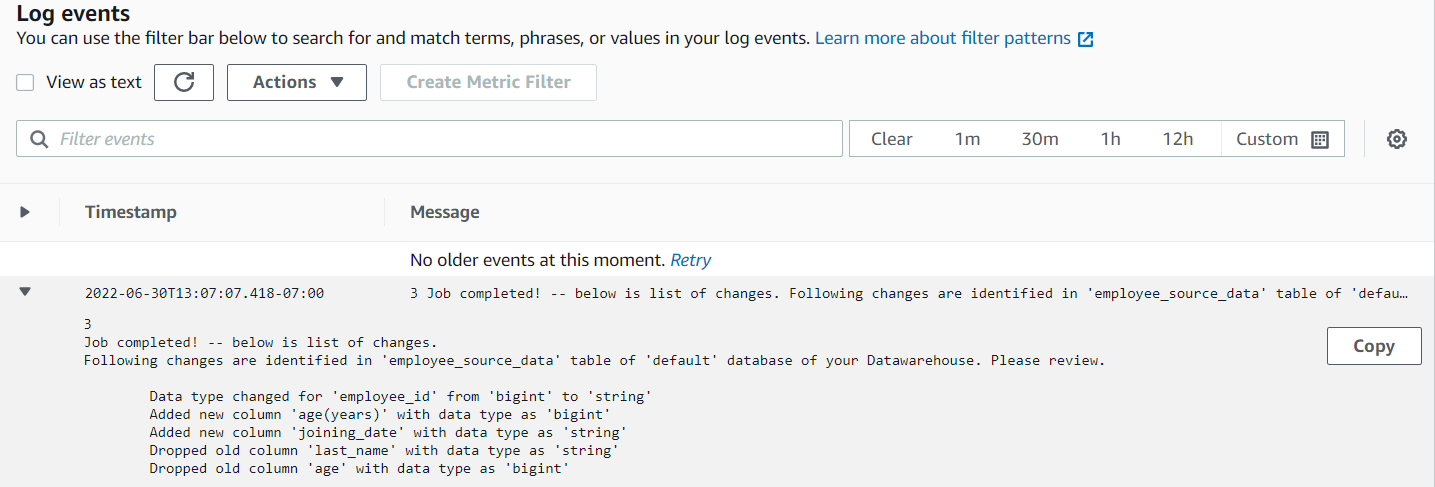
You should also receive an email with details on the changes in the schema. The following is an example of an email received.

We can now review the changes identified by the AWS Glue ETL job and make changes in the downstream data store accordingly before running the job to propagate the data from the S3 bucket to downstream applications. For example, if you have an Amazon Redshift table, after the job lists all the schema changes, you need to connect to the Amazon Redshift database and make these schema changes. Follow the change request process set by your organization before making schema changes in your production system.
The following table has a list of mappings for Apache Hive and Amazon Redshift data types. You can find similar mappings for other data stores and update your downstream data store.
The provided Python code takes care of the logic to compare the schema changes. The script takes in the parameters of the AWS Glue Data Catalog ID, AWS Glue database name, and AWS Glue table name.
| Hive Data Types | Description | Amazon Redshift Data Types | Description |
| TINYINT | 1 byte integer | . | . |
| SMALLINT | Signed two-byte integer | SMALLINT | Signed two-byte integer |
| INT | Signed four-byte integer | INT | Signed four-byte integer |
| BIGINT | Signed eight-byte integer | BIGINT | Signed eight-byte integer |
| DECIMAL | . | . | . |
| DOUBLE | . | . | . |
| STRING | . | VARCHAR, CHAR | . |
| VARCHAR | 1 to 65355, available starting with Hive 0.12.0 | VARCHAR | . |
| CHAR | 255 length, available starting with Hive 0.13.0 | CHAR | . |
| DATE | year/month/day | DATE | year/month/day |
| TIMESTAMP | No timezone | TIME | Time without time zone |
| . | . | TIMETZ | Time with time zone |
| ARRAY/STRUCTS | . | SUPER | . |
| BOOLEAN | . | BOOLEAN | . |
| BINARY | . | VARBYTE | Variable-length binary value |
Clean up
When you’re done exploring the solution, clean up the resources you created as part of this walkthrough:
- AWS Glue ETL job (
find-change-job-sscp) - AWS Glue crawler (
glue-crawler-sscp-sales-data) - AWS Glue table (
sscp_sales_data) - AWS Glue database (
sscp-database) - IAM role for the crawler and ETL job (
AWSGlueServiceRole-sscp-blog) - S3 bucket (
aws-blog-sscp-ng-202202) with all the files in the data and archived folders - SNS topic and subscription (
NotifySchemaChanges)
Conclusion
In this post, we showed you how to use AWS services together to detect schema changes in your source data, which you can then use to change your downstream data stores and run ETL jobs to avoid any failures in your data pipeline. We used AWS Glue to understand and catalog the source data schema, AWS Glue APIs to identify schema changes, and Amazon SNS to notify the team about the changes. We also showed you how to delete the older versions of your source data schema using AWS Glue APIs. We used Amazon S3 as our data lake storage tier.
Here you can learn more about AWS Glue.
About the authors
 Narendra Gupta is a Specialist Solutions Architect at AWS, helping customers on their cloud journey with a focus on AWS analytics services. Outside of work, Narendra enjoys learning new technologies, watching movies, and visiting new places.
Narendra Gupta is a Specialist Solutions Architect at AWS, helping customers on their cloud journey with a focus on AWS analytics services. Outside of work, Narendra enjoys learning new technologies, watching movies, and visiting new places.
 Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.