AWS Database Blog
Build a custom solution to migrate SQL Server HierarchyID to PostgreSQL LTREE with AWS DMS
Data migration from SQL Server Database to Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition can require updates to the database schema or SQL commands used to access the data. To assist migrations, AWS provides DMS Schema Conversion in the AWS Management Console to help you convert existing database schema from one database engine to another and AWS Database Migration Service (AWS DMS) to help migrate your data to AWS with enhanced security features with reduced downtime.
Although the tooling helps automate the migration effort, there are scenarios where you will need to intervene and manually convert SQL from SQL Server to PostgreSQL. In this post, we discuss configuring AWS DMS tasks to migrate HierarchyID columns from SQL Server to Aurora PostgreSQL-Compatible efficiently.
Hierarchical data overview
Hierarchical data structures are fundamental in modern applications, appearing in everything from organizational charts to product categories and file systems. These structures represent information in a tree-like format, where each item has a single parent and can have multiple children. This organization is essential for representing natural relationships between data elements, enabling efficient storage, retrieval, and analysis of complex, interconnected information. The significance of hierarchical data lies in its ability to model nested or layered information effectively, making it invaluable for applications that need to handle structured, parent-child relationships.
SQL Server’s approach with HierarchyID
SQL Server implements hierarchical data handling through its native HierarchyID data type, specifically designed for managing tree-structured data. This built-in feature stores node positions in binary format, providing efficient methods for hierarchy navigation, comparison, and manipulation.
HierarchyID offers specialized functions like GetAncestor and GetDescendant, along with optimized indexing capabilities. These features make it particularly effective for common tree operations such as finding descendants, determining node depths, and reorganizing hierarchical structures within SQL Server databases.
PostgreSQL’s solution with LTREE
PostgreSQL takes a different approach through its LTREE extension, which manages hierarchical data using a label-based system. LTREE represents hierarchical relationships through dot-separated paths, offering a distinct but equally powerful method for handling tree structures. The extension provides comprehensive functionality for path matching, ancestor and descendant searches, and depth calculations, supported by efficient indexing mechanisms. While its implementation differs from SQL Server’s HierarchyID, LTREE delivers comparable capabilities for managing hierarchical data, making it a robust solution for PostgreSQL environments.
Understanding these different approaches is crucial when planning data migrations between these database systems, because they affect how tree relationships must be restructured during the transition.
Solution overview
SQL Server and PostgreSQL handle hierarchical data structures differently, with SQL Server using HierarchyID’s binary format with forward slash notation (for example, /1/1/1/), while PostgreSQL’s LTREE extension uses dot-separated format (for example, 1.1.1).
To illustrate this transformation, let’s consider a department store’s product hierarchy featuring two main departments: Electronics (/1/) and Clothing (/2/).
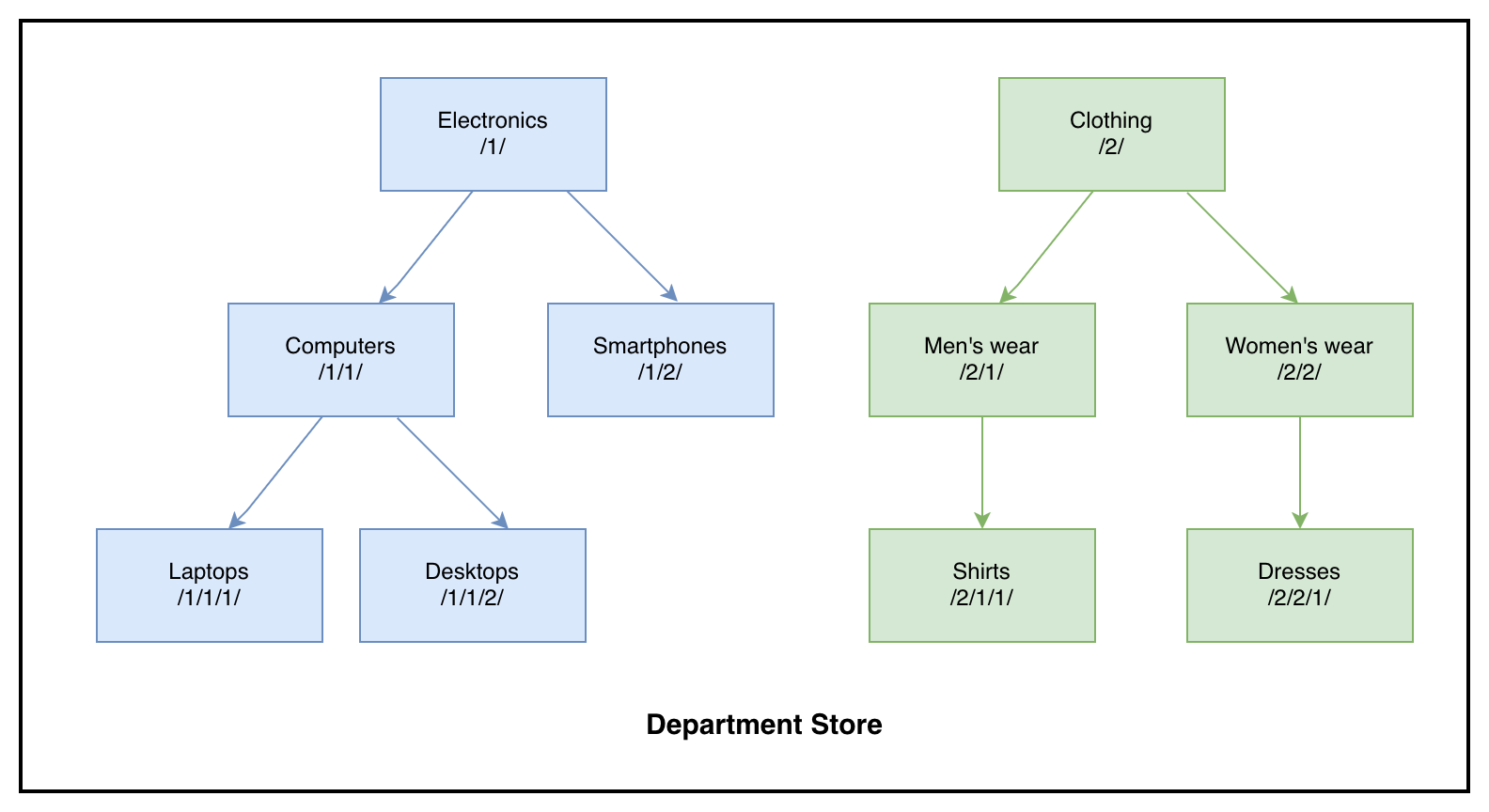
When using the HierarchyID datatype with AWS DMS, note that native support isn’t available. AWS DMS requires a workaround solution for successful data migration. For optimal performance and reliability, it’s recommended to implement the solution described in this post for short-term migrations.To migrate such hierarchical structures:
- Prepare the source SQL Server and target PostgreSQL environments.
- Create source tables containing the HierarchyID data type in SQL Server.
- Install the LTREE extension in PostgreSQL target database.
- Convert the schema using AWS DMS Schema Conversion.
- Execute migration process using AWS DMS:
- Run an AWS DMS full-load and change data capture (CDC) task with Stop after applying cash changed changes settings
- After the task has paused automatically after full load, add a new LTREE column to the target table and transform HierarchyID data with generated transformation logic.
- Resume the AWS DMS task for ongoing CDC replication
- Complete the migration by dropping the original column and renaming the LTREE column with the name of the column that was dropped.
Prerequisites
To get started, you must have the following prerequisites:
- An active AWS account.
- Self-managed SQL Server on Amazon Elastic Compute Cloud (Amazon EC2), an on-premises relational database management server (RDBMS) or an Amazon RDS instance (for this post, we use Amazon RDS for SQL server).
- An Amazon Aurora PostgreSQL or RDS for PostgreSQL database (for this post, we use Aurora PostgreSQL). If you don’t already have an Amazon Aurora PostgreSQL cluster, you can create one. For instructions, see Creating and connection to an Aurora PostgreSQL DB cluster.
- AWS DMS set up with a replication instance. See Getting started with AWS Database Migration service for more information.
- Access to AWS Secrets Manager to create or access secrets. For this post, we use AWS Secrets Manager and the connection information is already updated in Secrets Manager. For more information about creating a secret, see Create an AWS Secrets Manager database secret.
- AWS DMS Schema Conversion service, a fully managed service, directly in the AWS Management Console without downloading and executing AWS Schema Conversion Tool (AWS SCT)
Solution walkthrough
With the prerequisites in place, you’re ready to start the solution walkthrough.
Build sample tables on the source
Start by creating a sample table with a HierarchyID column in SQL Server.
- Connect to your SQL Server instance using SQL Server Management Studio (SSMS) or another SQL client.
- Create a sample table with a HierarchyID column:
- Insert sample data into the table:
- Verify the data was inserted correctly. You should have columns for
id,node_path, andnameand 10 entries: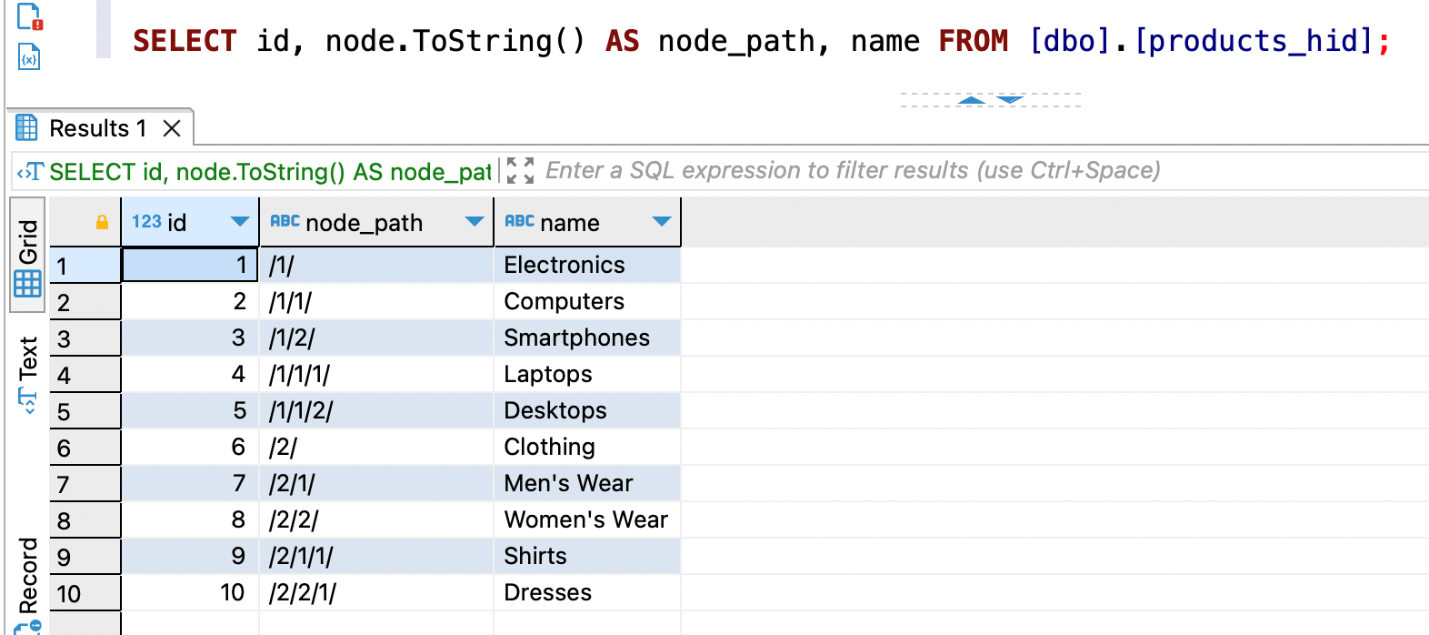
- To capture changes, make sure that the database is configured for full backups and that MS-Replication or MS-CDC is enabled for your database and tables. In this post, we enabled MS-CDC for the database DMS_DB. Because in this example, the source is an RDS SQL server instance, we use RDS stored procedures. For more information, see Using change data capture for Amazon RDS for SQL Server Using change data capture for Amazon RDS for SQL Server
- Check if CDC has been enabled successfully by running the following command.
Set up your target Aurora PostgreSQL DB
- Connect to your Aurora PostgreSQL cluster to create the LTREE extension. This will implement a data type LTREE for representing labels of data stored in a hierarchical tree-like structure.
- Validate the extension was created using the following command:
Prepare the table for migration using AWS DMS SC
For the example in this post, we used AWS DMS SC to prepare the table structure at the target. You can also manually create the table structure at the target.The following is the target data definition language (DDL) created by AWS DMS SC by default:
We change the GENERATED ALWAYS AS IDENTITY to GENERATED BY DEFAULT AS IDENTITY because GENERATED ALWAYS instructs PostgreSQL to always generate a value for the IDENTITY column. If you attempt to insert (or update) values into the GENERATED ALWAYS AS IDENTITY column, PostgreSQL will issue an error when using AWS DMS. For more information, see Handle IDENTITY columns in AWS DMS.
The final DDL for the dms_db_dbo.products_hid table looks like the following code:
After a successful migration, at cutover, make sure to modify the IDENTITY column back to GENERATED ALWAYS. Steps are shown in a later section of this post.
Migrate the HierarchyID column data using AWS DMS
Now, you’re ready to create the AWS DMS endpoints and the migration task. With the endpoints and task ready, you can run the migration.
Create the AWS DMS endpoints
Create AWS DMS endpoints for the source and target databases. AWS DMS endpoints provide connection, data store type, and location information about your data store.
Create your source endpoint
- On the AWS Management Console for AWS DMS, select Source endpoint for the Endpoint type.
- For Endpoint identifier, enter a name.
- For Source engine, select Microsoft SQL Server.
- For Access to endpoint database, select AWS Secrets Manager and select the Secret from the drop down. You can also provide user credentials with a username and password manually, but we recommend using Secrets Manager.
- For IAM role, enter the Amazon Resource Name (ARN) to the AWS Identity and Access Management (IAM) role that has access to Secrets Manager. For more information about the appropriate permissions to replicate data using AWS DMS, see Using secrets to access AWS Database Migration Service endpoints.
- For Secure Socket Layer (SSL) mode, select None.Alternatively, you can encrypt connections for the source and target endpoints by using SSL. See Using SSL with AWS Database Migration Service for details.
- Enter the appropriate database name.
- Test the endpoint, then complete endpoint creation.
Create the target endpoint
Repeat the previous steps with the following parameters for the target endpoint:
- On the AWS DMS console, select Target endpoint for the Endpoint type.
- For Endpoint identifier, enter a name.
- For Target engine, select Amazon Aurora PostgreSQL.
- Test the endpoint, then complete endpoint creation.
Create and run the AWS DMS migration task
An AWS DMS task is where the work happens. This is where you configure what database objects to migrate, logging requirements, error handling, and so on. Complete the following steps to create your task:
- On the AWS DMS console, create a new migration task.
- For Task identifier, enter an identifiable name.
- For Replication instance, select the replication instance you created.
- For Source database endpoint, select the SQL Server endpoint you created.
- For Target database endpoint, select the Aurora PostgreSQL endpoint you created.
- For Migration type, select Migrate existing data and replicate ongoing changes.
- For Target table preparation mode, select Do nothing.
- For Stop task after full load completes, select Stop after applying cached changes.
- Enable CloudWatch Logs under the task settings so you can debug issues.
- Under Table mappings, for Editing mode, select JSON editor. Use the following JSON to create the table mappings:
- Uncheck the Premigration assessment checkbox. Though this feature is typically recommended, you disable it as part of this blog post’s solution.
- Leave everything else as default and choose Create task to start the task. The task begins immediately.
- Wait for the full load to complete. The summary section of the Database migration task shows you the status of the migration task. The task will stop automatically after the full load is finished and the cache changes have been applied.
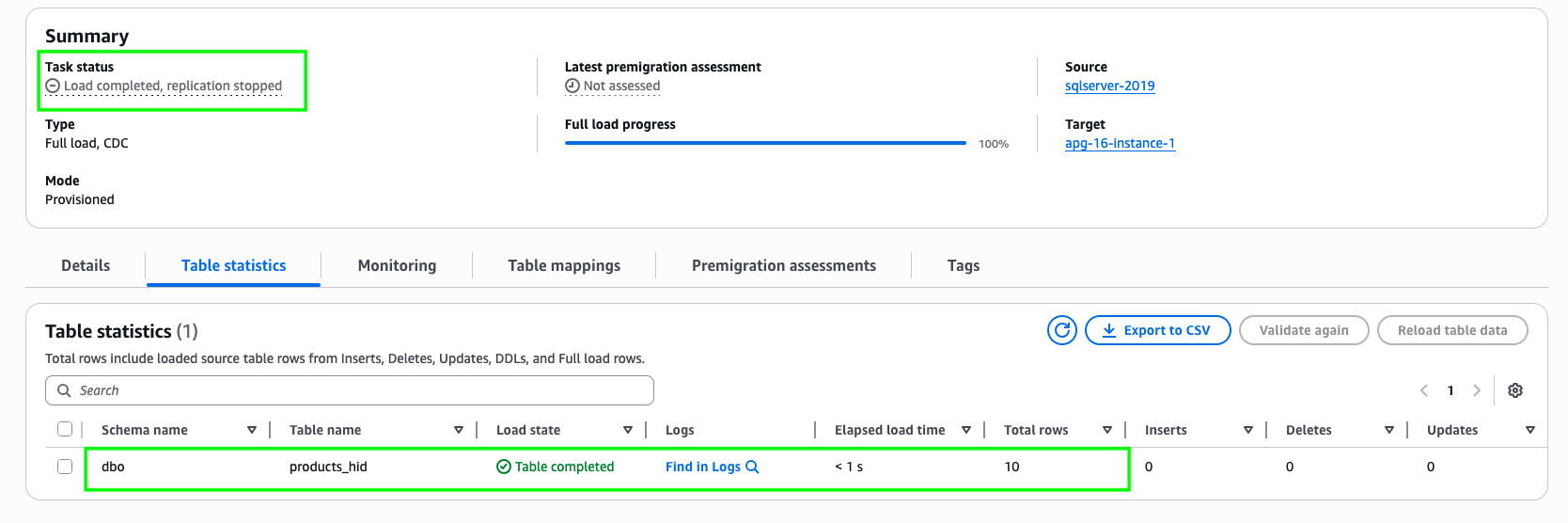
- Verify the migrated data in Aurora PostgreSQL by running the following select query.
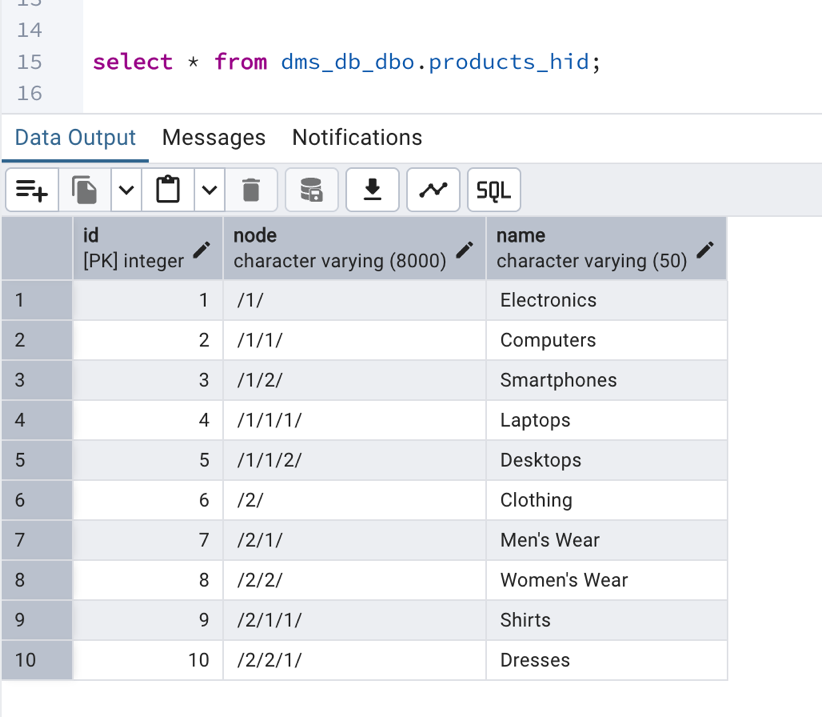
Implement LTREE column transformation on Aurora PostreSQL
To enable hierarchical queries in PostgreSQL, you’ll now add logic to the target table with an LTREE column that automatically transforms the migrated hierarchical data into PostgreSQL’s native format by following the below steps
- Alter the target table in PostgreSQL to add a generated LTREE column. In the blog post we define the root as ‘0’.
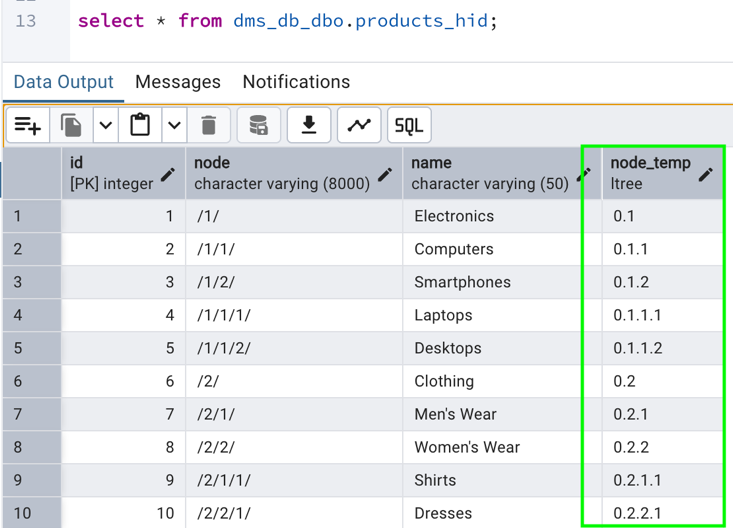
- Verify that the new LTREE column,
node_temp, is populated by running the following select command.
Resume your DMS task to test CDC replication with the new LTREE column
Now that the LTREE column is in place, you’ll resume the migration task to verify that ongoing changes are captured correctly and that the generated LTREE column automatically populates for new records.
- To resume an AWS DMS task, in the AWS DMS console, go to the Actions menu, choose Resume. When the task is in running state, proceed with the next step.
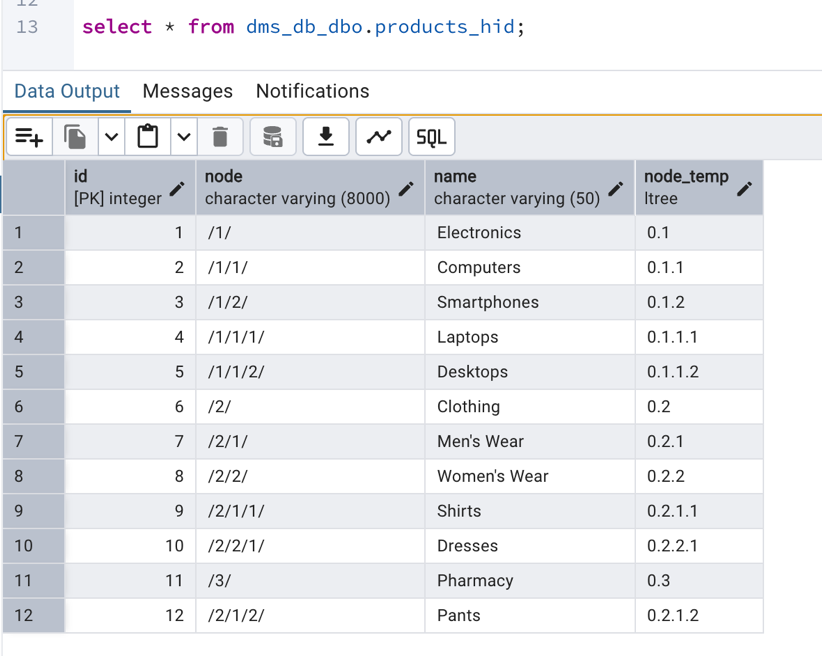
- Test the CDC replication by inserting new rows in the source database:
- Verify that the new rows are migrated correctly to the target database. Notice how the
node_tempis automatically populated for the new records that came in.
Post migration
After the migration is complete and you’ve verified the data integrity, finalize the migration by completing the following steps.
- Replace the original column with the transformed one by running the following commands:
- After completing the data load, you also need to change the
IDENTITYcolumn’s behavior back to its original auto-generation state. To do this, modify theIDENTITYcolumn back toGENERATED ALWAYSand restart the sequence from the last used identity value in your table. In this example that value is 13. - Insert a row in the PostgreSQL database to verify that data is coming in the correct LTREE format.
With this, your HierarchyID columns have been successfully migrated to LTREE format.
Common HierarchyID to LTREE Function Mapping
The table below maps SQL Server HierarchyID operators and functions to their PostgreSQL LTREE equivalents.
Note that the specific syntax may vary depending on your ltree hierarchy structure—whether you represent the root as ‘root’, an empty string, or use another convention.
| SQL Server (HierarchyID) | PostgreSQL (LTREE) | Meaning |
| GetLevel() | nlevel(ltree) | Get node level |
| GetAncestor(n) | Use combination of subpath ( ltree, offset integer, len integer) & nlevel ( ltree ) | Get nth level ancestor |
| GetRoot() | subpath(ltree, 0, nlevel(node) – 1) OR use ltree pattern matching | Get root |
| IsDescendantOf() | ltree <@ ‘parent_path’ | Get all the descendants |
| GetReparentedValue() | No direct equivalent to GetReparentedValue() in PostgreSQL ltree.
You have to manually construct the reparenting logic using ltree functions. |
Moves a node from the old parent to the new parent. |
| GetDescendant() | In PostgreSQL with ltree, there’s no direct equivalent to GetDescendant().
You’d need to create a custom function or use a subquery to find the next available child. |
See what the next child would be for a parent in the table |
| Parse(‘/1/2/3/’) | ‘root.child.grandchild’::ltree | Convert string to path |
| ToString() | path::text | Convert path to string |
Clean up
To avoid ongoing charges, clean up the resources you created:
- Delete the Aurora PostgreSQL DB cluster.
- Delete the RDS for SQL Server instance.
- Clean up AWS DMS resources
Conclusion
In this post, we demonstrated how to migrate SQL Server tables with HierarchyID columns to PostgreSQL using AWS DMS and the LTREE extension. By using this approach, you can preserve the hierarchical structure of your data when moving to PostgreSQL.