Amazon Web Services ブログ
Agentic workflowを使用したAmazon Nova Premierによるコード移行の効率化
多くの企業は、保守と拡張が困難になった古いテクノロジーで構築されたレガシーシステムに悩まされています。
この投稿では、Amazon Bedrock Converse APIとAmazon Nova Premierをagentic workflow内で使用して、レガシーCコードを最新のJava/Springフレームワークアプリケーションに体系的に移行する方法を紹介します。移行プロセスを複数の専門エージェントで分担し、堅牢なフィードバックループを実装することで、組織は以下を達成できます:
- 移行時間とコストの削減 – 自動化により反復的な変換タスクを処理し、人間のエンジニアは高付加価値作業に集中できます
- コード品質の向上 – 専門的な検証エージェントが、移行されたコードの最新のベストプラクティスへの準拠を保証します
- リスクの最小化 – 体系的なアプローチにより、移行中に重要なビジネスロジックの損失を防ぎます
- クラウド統合の実現 – 結果として得られるJava/SpringコードはAWSサービスとシームレスに統合できます
課題
レガシーシステムから最新のフレームワークへのコード移行には、AI機能と人間の専門知識を組み合わせたバランスの取れたアプローチを必要とするいくつかの重要な課題があります:
- 言語パラダイムの違い – CコードをJavaに変換するには、メモリ管理、エラー処理、プログラミングパラダイムの根本的な違いをナビゲートする必要があります。Cの手続き型の性質と直接的なメモリ操作は、Javaのオブジェクト指向アプローチと自動メモリ管理とは大きく対照的です。AIは多くの構文変換を自動的に処理できますが、開発者はこれらの変換の意味的正確性をレビューおよび検証する必要があります。
- アーキテクチャの複雑性 – レガシーシステムには、人間の分析と計画を必要とするコンポーネント間の複雑な相互依存関係が含まれていることがよくあります。我々のケースでは、Cコードベースには、一部のTP(Transaction Program)が最大12の他のモジュールに接続されているなど、モジュール間の複雑な関係が含まれていました。人間の開発者は依存関係マッピングを作成し、移行順序を決定する必要があります。通常は依存関係が最小のリーフノードから移行を開始します。AIはこれらの関係を識別するのに役立ちますが、移行シーケンスに関する戦略的決定には人間の判断が必要です。
- ビジネスロジックの維持 – 変換中に重要なビジネスロジックが正確に保持されることを確認するには、継続的な人間の監視が必要です。我々の分析では、自動移行はシンプルで構造化されたコードには非常に成功していますが、大きなファイル(700行以上)に埋め込まれた複雑なビジネスロジックには、エラーや欠落を防ぐために慎重な人間のレビューと手動での改良が必要であることが示されました。
- 一貫性のない命名と構造 – レガシーコードには、移行中に標準化する必要がある一貫性のない命名規則と構造が含まれていることがよくあります。AIは多くのルーチン変換(関数名の英数字IDの変換、C形式のエラーコードのJava例外への変換、C構造体のJavaクラスへの変換など)を処理できますが、人間の開発者は命名標準を確立し、自動変換が曖昧になる可能性のあるエッジケースをレビューする必要があります。
- 統合の複雑性 – 個々のファイルを変換した後、まとまりのあるアプリケーションを作成するには人間が主導する統合が不可欠です。元のCファイル全体で一貫していた変数名は、個々のファイル変換中に一貫性がなくなることが多く、開発者は調整作業を実行し、適切なモジュール間通信を促進する必要があります。
- 品質保証 – 変換されたコードが元のコードと機能的に同等であることを検証するには、自動テストと人間による検証の組み合わせが必要です。これは複雑なビジネスロジックにとって特に重要です。微妙な違いが重大な問題につながる可能性があります。開発者は包括的なテストスイートを設計し、徹底的なコードレビューを実行して移行の正確性を確保する必要があります。
これらの課題には、大規模言語モデル(LLM)のパターン認識機能と構造化ワークフローおよび重要な人間の監視を組み合わせて、成功した移行結果を生み出す体系的なアプローチが必要です。鍵となるのは、AIを使用してルーチン変換を処理しながら、戦略的決定、複雑なロジック検証、品質保証のために人間をループに留めることです。
ソリューション概要
このソリューションは、Amazon Bedrock Converse APIとAmazon Nova Premierを使用して、体系的なagentic workflowを通じてレガシーCコードを最新のJava/Springフレームワークコードに変換します。このアプローチは、複雑な移行プロセスを管理可能なステップに分割し、反復的な改良とトークン制限の処理を可能にします。
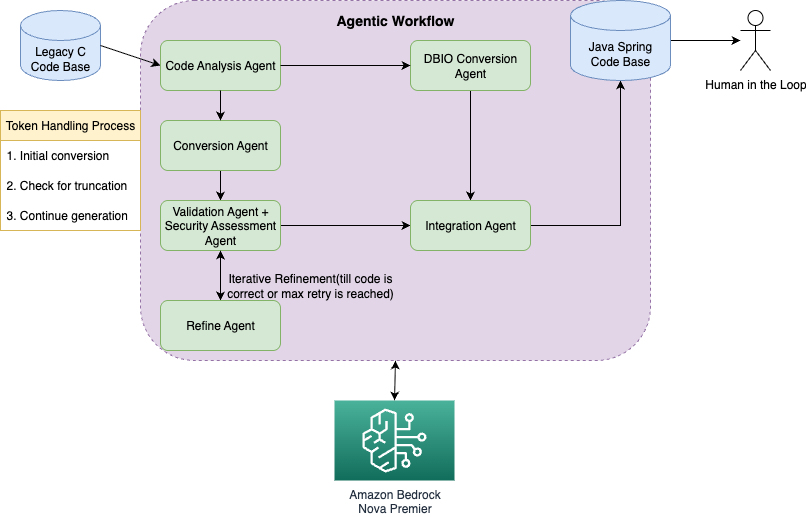
ソリューションアーキテクチャは、いくつかの主要なコンポーネントで構成されています:
- Code analysis agent – Cコードの構造と依存関係を分析します
- Conversion agent – CコードをJava/Springコードに変換します
- Security assessment agent – レガシーコードと移行されたコードの脆弱性を識別します
- Validation agent – 変換の完全性と正確性を検証します
- Refine agent – validation agentからのフィードバックに基づいてコードを書き直します
- Integration agent – 個別に変換されたファイルを結合します
我々のagentic workflowは、堅牢なエージェントオーケストレーションとLLM推論のためにAmazon Bedrock Converse APIと組み合わせたStrands Agentsフレームワークを使用して実装されています。アーキテクチャ(次の図に示すように)は、Strandsのセッション管理機能とトークン継続のためのカスタムBedrockInference処理を組み合わせたハイブリッドアプローチを使用しています。
このソリューションは、以下のコアテクノロジーを使用しています:
- Strands Agentsフレームワーク(v1.1.0+) – エージェントライフサイクル管理、セッション処理、構造化されたエージェント通信を提供します
- Amazon Bedrock Converse API – Amazon Nova PremierモデルでLLM推論を実行します
- カスタムBedrockInferenceクラス – テキスト事前入力とレスポンス継続によりトークン制限を処理します
- Asyncioベースのオーケストレーション – 並行処理とノンブロッキングエージェント実行を可能にします
ワークフローは以下のステップで構成されています:
1. コード分析:
- Code analysis agent – 変換要件を理解するために入力コード分析を実行します。Cコードベース構造を調べ、依存関係を識別し、複雑性を評価します。
- フレームワーク統合 – 分析にBedrockInferenceを使用しながら、セッション管理にStrandsを使用します。
- 出力 – 依存関係マッピングと変換推奨事項を含むJSON構造化分析。
2. ファイル分類とメタデータ作成:
- 実装 – 複雑性評価を含むFileMetadataデータクラス。
- Categories – Simple(0-300行)、Medium(300-700行)、Complex(700行以上)。
- File types – 標準Cファイル、ヘッダーファイル、データベースI/O(DBIO)ファイル。
3. コード変換:
- Conversion agent – code analysis agentからの情報に基づいて個々のファイルのコード移行を実行します。
- Token handling – トークン制限を超える大きなファイルを処理するためにstitch_output()メソッドを使用します。
4. セキュリティ評価フェーズ:
- Security assessment agent – レガシーCコードと変換されたJavaコードの両方で包括的な脆弱性分析を実行します。
- Risk categorization – セキュリティ問題を重大度(Critical、High、Medium、Low)で分類します。
- Mitigation recommendations – 具体的なコード修正とセキュリティベストプラクティスを提供します。
- Output – アクション可能な修復ステップを含む詳細なセキュリティレポート。
5. 検証とフィードバックループ:
- Validation agent – 変換の完全性と正確性を分析します。
- Refine agent – 検証結果に基づいて反復的な改善を適用します。
- Iteration control – 満足のいく結果が得られた場合の早期終了を伴う最大5回のフィードバック反復。
- Session persistence – Strandsフレームワークは反復間で会話コンテキストを維持します。
6. 統合と最終化:
- Integration agent – 個別に変換されたファイルの結合を試みます。
- Consistency resolution – 変数命名を標準化し、適切な依存関係を提供します。
- Output generation – まとまりのあるJava/Springアプリケーション構造を作成します。
7. DBIO変換:
- Purpose – SQL DBIO CソースコードをMyBatis XMLマッパーファイルに変換します。
- Framework – 一貫性のために同じStrandsとBedrockInferenceハイブリッドアプローチを使用します。
ソリューションは以下の主要なオーケストレーション機能で構成されています:
- Session persistence – 各変換はエージェント相互作用間でセッション状態を維持します
- Error recovery – グレースフルデグラデーションを伴う包括的なエラー処理
- Performance tracking – 処理時間、反復回数、成功率の組み込みメトリクス
- Token continuation – レスポンススティッチングによる大きなファイルのシームレスな処理
このフレームワーク固有の実装により、多様なCコードベース構造と複雑性を処理する柔軟性を維持しながら、信頼性が高くスケーラブルなコード変換が促進されます。
前提条件
このコード変換ソリューションを実装する前に、以下のコンポーネントが設定されていることを確認してください:
AWS環境:
- Amazon Nova Premierモデルへのアクセス権限を含む、適切なAmazon Bedrock権限を持つAWSアカウント
- 開発とテスト用のAmazon Elastic Compute Cloud(Amazon EC2)インスタンス(t3.medium以上)またはローカルマシン
開発セットアップ:
- Python 3.10以上(Boto3 SDK、Strands Agentsライブラリをインストール済み)
- AWS CLI(適切な認証情報とリージョン設定済み)
- Git(バージョン管理用)
- テキストエディタまたはIDE(CとJavaコード対応)
ソースとターゲットコードベースの要件:
- 整理された構造のCソースコード
- Java 11以上とMaven/Gradleビルドツール
- Spring Framework 5.xまたはSpring Boot 2.x以上
この投稿で使用されているソースコードとプロンプトは、GitHubリポジトリにあります。
エージェントベースの変換プロセス
このソリューションは、Strandsフレームワークを使用して実装された洗練されたマルチエージェントシステムを使用しており、各エージェントはコード変換プロセスの特定の側面を専門としています。この分業アプローチは、多様なコード構造と複雑性を処理する柔軟性を維持しながら、徹底的な分析、正確な変換、包括的な検証を可能にします。
Strandsフレームワーク統合
各エージェントはBaseStrandsConversionAgentクラスを拡張し、Strandsセッション管理とカスタムBedrockInference機能を組み合わせたハイブリッド構成で実装しています:
class BaseStrandsConversionAgent(ABC):
def __init__(self, name: str, bedrock_inference, system_prompt: str):
self.name = name
self.bedrock = bedrock_inference # トークン処理のためのカスタムBedrockInference
self.system_prompt = system_prompt
# セッション管理のためのstrands agentを作成
self.strands_agent = Agent(name=name, system_prompt=system_prompt)
async def execute_async(self, context: ConversionContext) -> Dict[str, Any]:
# 各専門エージェントによって実装される
passCode analysis agent
Code analysis agentは、Cコードベースの構造を調べ、ファイル間の依存関係を識別し、最適な変換戦略を決定します。このエージェントは、最初に変換するファイルに優先順位を付け、潜在的な課題を識別するのに役立ちます。
以下は、code analysis agentのプロンプトテンプレートです:
You are a Code Analysis Agent with expertise in legacy C codebases and modern Java/Spring architecture.
<c_codebase>
{c_code}
</c_codebase>
## TASK
Your task is to analyze the provided C code to prepare for migration.
Perform a comprehensive analysis and provide the following:
## INSTRUCTIONS
1. DEPENDENCY ANALYSIS:
- Identify all file dependencies (which files include or reference others)
- Map function calls between files
- Detect shared data structures and global variables
2. COMPLEXITY ASSESSMENT:
- Categorize each file as Simple (0-300 lines), Medium (300-700 lines), or Complex (700+ lines)
- Identify files with complex control flow, pointer manipulation, or memory management
- Flag any platform-specific or hardware-dependent code
3. CONVERSION PLANNING:
- Recommend a conversion sequence (which files to convert first)
- Suggest logical splitting points for large files
- Identify common patterns that can be standardized during conversion
4. RISK ASSESSMENT:
- Highlight potential conversion challenges (e.g., pointer arithmetic, bitwise operations)
- Identify business-critical sections requiring special attention
- Note any undocumented assumptions or behaviors
5. ARCHITECTURE RECOMMENDATIONS:
- Suggest appropriate Java/Spring components for each C module
- Recommend DTO structure and service organization
- Propose database access strategy using a persistence framework
Format your response as a structured JSON document with these sections.Conversion agent
Conversion agentは、CコードからJava/Springコードへの実際の変換を処理します。このエージェントには、CとJava/Springフレームワークの両方の専門知識を持つシニアソフトウェア開発者の役割が割り当てられています。
Conversion agentのプロンプトテンプレートは以下の通りです:
You are a Senior Software Developer with 15+ years of experience in both C and Java Spring framework.
<c_file>
{c_code}
</c_file>
## TASK
Your task is to convert legacy C code to modern Java Spring code with precision and completeness.
## CONVERSION GUIDELINES:
1. CODE STRUCTURE:
- Create appropriate Java classes (Service, DTO, Mapper interfaces)
- Preserve original function and variable names unless they conflict with Java conventions
- Use Spring annotations appropriately (@Service, @Repository, etc.)
- Implement proper package structure based on functionality
2. JAVA BEST PRACTICES:
- Use Lombok annotations (@Data, @Slf4j, @RequiredArgsConstructor) to reduce boilerplate
- Implement proper exception handling instead of error codes
- Replace pointer operations with appropriate Java constructs
- Convert C-style arrays to Java collections where appropriate
3. SPRING FRAMEWORK INTEGRATION:
- Use dependency injection instead of global variables
- Implement a persistence framework mappers for database operations
- Replace direct SQL calls with mapper interfaces
- Use Spring's transaction management
4. SPECIFIC TRANSFORMATIONS:
- Replace PFM_TRY/PFM_CATCH with Java try-catch blocks
- Convert mpfmdbio calls to a persistence framework mapper method calls
- Replace mpfm_dlcall with appropriate Service bean injections
- Convert NGMHEADER references to input.getHeaderVo() calls
- Replace PRINT_ and PFM_DBG macros with SLF4J logging
- Convert ngmf_ methods to CommonAPI.ngmf method calls
5. DATA HANDLING:
- Create separate DTO classes for input and output structures
- Use proper Java data types (String instead of char arrays, etc.)
- Implement proper null handling and validation
- Remove manual memory management code
## OUTPUT FORMAT:
- Include filename at the top of each Java file: #filename: [filename].java
- Place executable Java code inside <java></java> tags
- Organize multiple output files clearly with proper headers
Generate complete, production-ready Java code that fully implements all functionality from the original C code.Security assessment agent
Security assessment agentは、元のCコードと変換されたJavaコードの両方で包括的な脆弱性分析を実行し、潜在的なセキュリティリスクを識別し、具体的な緩和戦略を提供します。このエージェントは、移行中にセキュリティの脆弱性が持ち越されないようにし、新しいコードがセキュリティのベストプラクティスに従っていることを確認するために不可欠です。
以下は、security assessment agentのプロンプトテンプレートです:
You are a Security Assessment Agent with expertise in identifying vulnerabilities in both C and Java codebases, specializing in secure code migration practices.
ORIGINAL C CODE:
<c_code>
{c_code}
</c_code>
CONVERTED JAVA CODE:
<java_code>
{java_code}
</java_code>
## TASK
Your task is to perform comprehensive security analysis on both the legacy C code and converted Java code, identifying vulnerabilities and providing specific mitigation recommendations.
## SECURITY ANALYSIS FRAMEWORK
1. **LEGACY C CODE VULNERABILITIES:**
- Buffer overflow risks (strcpy, strcat, sprintf usage)
- Memory management issues (dangling pointers, memory leaks)
- Integer overflow/underflow vulnerabilities
- Format string vulnerabilities
- Race conditions in multi-threaded code
- Improper input validation and sanitization
- SQL injection risks in database operations
- Insecure cryptographic implementations
2. **JAVA CODE SECURITY ASSESSMENT:**
- Input validation and sanitization gaps
- SQL injection vulnerabilities in persistence framework queries
- Improper exception handling that leaks sensitive information
- Authentication and authorization bypass risks
- Insecure deserialization vulnerabilities
- Cross-site scripting (XSS) prevention in web endpoints
- Logging of sensitive data
- Dependency vulnerabilities in Spring framework usage
3. **MIGRATION-SPECIFIC RISKS:**
- Security assumptions that don't translate between languages
- Privilege escalation through improper Spring Security configuration
- Data exposure through overly permissive REST endpoints
- Session management vulnerabilities
- Configuration security (hardcoded credentials, insecure defaults)
4. **COMPLIANCE AND BEST PRACTICES:**
- OWASP Top 10 compliance assessment
- Spring Security best practices implementation
- Secure coding standards adherence
- Data protection and privacy considerations
## OUTPUT FORMAT
Provide your analysis as a structured JSON with these fields:
- "critical_vulnerabilities": array of critical security issues requiring immediate attention
- "security_risk_issues": array of security concerns
- "secure_code_recommendations": specific code changes to implement security fixes
- "spring_security_configurations": recommended Spring Security configurations
- "compliance_gaps": areas where code doesn't meet security standards
- "migration_security_notes": security considerations specific to the C-to-Java migration
For each vulnerability, include:
- Description of the security risk
- Potential impact and attack vectors
- Specific line numbers or code sections affected
- Detailed remediation steps with code examples
- Priority level and recommended timeline for fixes
Be thorough in identifying both obvious and subtle security issues that could be exploited in production environments.Validation agent
Validation agentは、変換されたコードをレビューして、欠落または不正に変換されたコンポーネントを識別します。このエージェントは、後続の変換反復で使用される詳細なフィードバックを提供します。
Validation agentのプロンプトテンプレートは以下の通りです:
You are a Code Validation Agent specializing in verifying C to Java/Spring migrations.
ORIGINAL C CODE:
<c_code>
{c_code}
</c_code>
CONVERTED JAVA CODE:
<java_code>
{java_code}
</java_code>
## TASK
Your task is to thoroughly analyze the conversion quality and identify any issues or omissions.
Perform a comprehensive validation focusing on these aspects:
## INSTRUCTIONS
1. COMPLETENESS CHECK:
- Verify all functions from C code are implemented in Java
- Confirm all variables and data structures are properly converted
- Check that all logical branches and conditions are preserved
- Ensure all error handling paths are implemented
2. CORRECTNESS ASSESSMENT:
- Identify any logical errors in the conversion
- Verify proper transformation of C-specific constructs (pointers, structs, etc.)
- Check for correct implementation of memory management patterns
- Validate proper handling of string operations and byte manipulation
3. SPRING FRAMEWORK COMPLIANCE:
- Verify appropriate use of Spring annotations and patterns
- Check proper implementation of dependency injection
- Validate correct use of persistence framework mappers
- Ensure proper service structure and organization
4. CODE QUALITY EVALUATION:
- Assess Java code quality and adherence to best practices
- Check for proper exception handling
- Verify appropriate logging implementation
- Evaluate overall code organization and readability
## OUTPUT FORMAT
Provide your analysis as a structured JSON with these fields:
- "complete": boolean indicating if conversion is complete
- "missing_elements": array of specific functions, variables, or logic blocks that are missing
- "incorrect_transformations": array of elements that were incorrectly transformed
- "spring_framework_issues": array of Spring-specific implementation issues
- "quality_concerns": array of code quality issues
- "recommendations": specific, actionable recommendations for improvement
Be thorough and precise in your analysis, as your feedback will directly inform the next iteration of the conversion process.Refine agentによるフィードバックループの実装
フィードバックループは、変換されたコードの反復的な改良を可能にする重要なコンポーネントです。このプロセスには以下のステップが含まれます:
- Conversion agentによる初期変換。
- Security assessment agentによるセキュリティ評価。
- Validation agentによる検証。
- Refine agentによるフィードバックの組み込み(検証とセキュリティの両方のフィードバックを組み込む)。
- 満足のいく結果が得られるまで繰り返す。
Refine agentは、機能的な改善とともにセキュリティの脆弱性修正を組み込み、セキュリティ評価結果は本番デプロイメント前の最終レビューと承認のために開発チームに提供されます。
以下は、コード改良のためのプロンプトテンプレートです:
You are a Senior Software Developer specializing in C to Java/Spring migration with expertise in secure coding practices.
ORIGINAL C CODE:
<c_code>
{c_code}
</c_code>
YOUR PREVIOUS JAVA CONVERSION:
<previous_java>
{previous_java_code}
</previous_java>
VALIDATION FEEDBACK:
<validation_feedback>
{validation_feedback}
</validation_feedback>
SECURITY ASSESSMENT:
<security_feedback>
{security_feedback}
</security_feedback>
## TASK
You've previously converted C code to Java, but validation and security assessment have identified issues that need to be addressed. Your task is to improve the conversion by addressing all identified functional and security issues while maintaining complete functionality.
## INSTRUCTIONS
1. ADDRESSING MISSING ELEMENTS:
- Implement any functions, variables, or logic blocks identified as missing
- Ensure all control flow paths from the original code are preserved
- Add any missing error handling or edge cases
2. CORRECTING TRANSFORMATIONS:
- Fix any incorrectly transformed code constructs
- Correct any logical errors in the conversion
- Properly implement C-specific patterns in Java
3. IMPLEMENTING SECURITY FIXES:
- Address all critical and high-risk security vulnerabilities identified
- Implement secure coding practices (input validation, parameterized queries, etc.)
- Replace insecure patterns with secure Java/Spring alternatives
- Add proper exception handling that does not leak sensitive information
4. IMPROVING SPRING IMPLEMENTATION:
- Correct any issues with Spring annotations or patterns
- Ensure proper dependency injection and service structure
- Fix persistence framework mapper implementations if needed
- Implement Spring Security configurations as recommended
5. MAINTAINING CONSISTENCY:
- Ensure naming conventions are consistent throughout the code
- Maintain consistent patterns for similar operations
- Preserve the structure of the original code where appropriate
## OUTPUT FORMAT
Output the improved Java code inside <java></java> tags, with appropriate file headers. Ensure all security vulnerabilities are addressed while maintaining complete functionality from the original C code.Integration agent
Integration agentは、個別に変換されたJavaファイルをまとまりのあるアプリケーションに結合し、変数命名の不整合を解決し、適切な依存関係を提供します。
Integration agentのプロンプトテンプレートは以下の通りです:
You are an Integration Agent specializing in combining individually converted Java files into a cohesive Spring application.
CONVERTED JAVA FILES:
<converted_files>
{converted_java_files}
</converted_files>
ORIGINAL FILE RELATIONSHIPS:
<relationships>
{file_relationships}
</relationships>
## TASK
Your task is to integrate multiple Java files that were converted from C, ensuring they work together properly.
Perform the following integration tasks:
## INSTRUCTIONS
1. DEPENDENCY RESOLUTION:
- Identify and resolve dependencies between services and components
- Ensure proper autowiring and dependency injection
- Verify that service method signatures match their usage across files
2. NAMING CONSISTENCY:
- Standardize variable and method names that should be consistent across files
- Resolve any naming conflicts or inconsistencies
- Ensure DTO field names match across related classes
3. PACKAGE ORGANIZATION:
- Organize classes into appropriate package structure
- Group related functionality together
- Ensure proper import statements across all files
4. SERVICE COMPOSITION:
- Implement proper service composition patterns
- Ensure services interact correctly with each other
- Verify that data flows correctly between components
5. COMMON COMPONENTS:
- Extract and standardize common utility functions
- Ensure consistent error handling across services
- Standardize logging patterns
6. CONFIGURATION:
- Create necessary Spring configuration classes
- Set up appropriate bean definitions
- Configure any required properties or settings
Output the integrated Java code as a set of properly organized files, each with:
- Appropriate package declarations
- Correct import statements
- Proper Spring annotations
- Clear file headers (#filename: [filename].java)
Place each file's code inside <java></java> tags. Ensure the integrated application maintains all functionality from the individual components while providing a cohesive structure.DBIO conversion agent
この専門エージェントは、SQL DBIO CソースコードをJava Springフレームワークのpersistence framework互換のXMLファイルに変換する処理を行います。
以下は、DBIO conversion agentのプロンプトテンプレートです:
You are a Database Integration Specialist with expertise in converting C-based SQL DBIO code to persistence framework XML mappings for Spring applications.
SQL DBIO C SOURCE CODE:
<sql_dbio>
{sql_dbio_code}
</sql_dbio>
## TASK
Your task is to transform the provided SQL DBIO C code into properly structured persistence framework XML files.
Perform the conversion following these guidelines:
## INSTRUCTIONS
1. XML STRUCTURE:
- Create a properly formatted persistence framework mapper XML file
- Include appropriate namespace matching the Java mapper interface
- Set correct resultType or resultMap attributes for queries
- Use proper persistence framework XML structure and syntax
2. SQL TRANSFORMATION:
- Preserve the exact SQL logic from the original code
- Convert any C-specific SQL parameter handling to persistence framework parameter markers
- Maintain all WHERE clauses, JOIN conditions, and other SQL logic
- Preserve any comments explaining SQL functionality
3. PARAMETER HANDLING:
- Convert C variable bindings to persistence framework parameter references (#{param})
- Handle complex parameters using appropriate persistence framework techniques
- Ensure parameter types match Java equivalents (String instead of char[], etc.)
4. RESULT MAPPING:
- Create appropriate resultMap elements for complex result structures
- Map column names to Java DTO property names
- Handle any type conversions needed between database and Java types
5. DYNAMIC SQL:
- Convert any conditional SQL generation to persistence framework dynamic SQL elements
- Use <if>, <choose>, <where>, and other dynamic elements as appropriate
- Maintain the same conditional logic as the original code
6. ORGANIZATION:
- Group related queries together
- Include clear comments explaining the purpose of each query
- Follow persistence framework best practices for mapper organization
## OUTPUT FORMAT
Output the converted persistence framework XML inside <xml></xml> tags. Include a filename comment at the top: #filename: [EntityName]Mapper.xml
Ensure the XML is well-formed, properly indented, and follows persistence framework conventions for Spring applications.トークン制限の処理
Amazon Bedrock Converse APIのトークン制限に対処するために、モデルが中断したところからコード生成を続行できる継続生成機能を実装しました。このアプローチは、モデルのコンテキストウィンドウを超える大きなファイルにとって特に重要であり、Strandsベースの実装における重要な技術的工夫を表しています。
技術実装
以下のコードは、継続生成機能を持つBedrock Inferenceクラスを実装しています:
class BedrockInference:
def __init__(self, region_name: str = "us-east-1", model_id: str = "us.amazon.nova-premier-v1:0"):
self.config = Config(read_timeout=300)
self.client = boto3.client("bedrock-runtime", config=self.config, region_name=region_name)
self.model_id = model_id
self.continue_prompt = {
"role": "user",
"content": [{"text": "Continue the code conversion from where you left off."}]
}
def run_converse_inference_with_continuation(self, prompt: str, system_prompt: str) -> List[str]:
"""大きな出力の継続処理で推論を実行"""
ans_list = []
messages = [{"role": "user", "content": [{"text": prompt}]}]
response, stop = self.generate_conversation([{'text': system_prompt}], messages)
ans = response['output']['message']['content'][0]['text']
ans_list.append(ans)
while stop == "max_tokens":
logger.info("Response truncated, continuing generation...")
messages.append(response['output']['message'])
messages.append(self.continue_prompt)
# 継続コンテキストのために最後の数行を抽出
sec_last_line = '\n'.join(ans.rsplit('\n', 3)[1:-1]).strip()
messages.append({"role": "assistant", "content": [{"text": sec_last_line}]})
response, stop = self.generate_conversation([{'text': system_prompt}], messages)
ans = response['output']['message']['content'][0]['text']
del messages[-1] # 事前入力メッセージを削除
ans_list.append(ans)
return ans_list継続戦略の詳細
継続戦略は以下のステップで構成されています:
1. レスポンス監視:
- システムはAmazon BedrockレスポンスのstopReasonフィールドを監視します。
- stopReasonがmax_tokensに等しい場合、継続が自動的にトリガーされます。これにより、トークン制限によるコード生成の損失を防ぎます。
2. コンテキストの保持:
- システムは生成されたコードの最後の数行を継続コンテキストとして抽出します。
- テキスト事前入力を使用してコード構造とフォーマットを維持します。継続間で変数名、関数シグネチャ、コードパターンを保持します。
3. レスポンスのスティッチング:
def stitch_output(self, prompt: str, system_prompt: str, tag: str = "java") -> str:
"""複数のレスポンスを結合し、指定されたタグ内のコンテンツを抽出"""
ans_list = self.run_converse_inference_with_continuation(prompt, system_prompt)
if len(ans_list) == 1:
final_ans = ans_list[0]
else:
final_ans = ans_list[0]
for i in range(1, len(ans_list)):
# オーバーラップを削除してレスポンスをシームレスに結合
final_ans = final_ans.rsplit('\n', 1)[0] + ans_list[i]
# 指定されたタグ(java、xmlなど)内のコンテンツを抽出
if f'<{tag}>' in final_ans and f'</{tag}>' in final_ans:
final_ans = final_ans.split(f'<{tag}>')[-1].split(f'</{tag}>')[0].strip()
return final_ans変換品質の最適化
実験を通じて、変換品質に大きく影響するいくつかの要因を特定しました:
- ファイルサイズ管理 – 300行を超えるコードファイルは、変換前に小さな論理単位に分割することで効果が向上します。
- 集中変換 – 異なるファイルタイプ(C、ヘッダー、DBIO)を個別に変換すると、各ファイルタイプが異なる変換パターンを持つため、より良い結果が得られます。変換中、C関数はクラス内のJavaメソッドに変換され、C構造体はJavaクラスになります。ただし、ファイルはクロスファイルコンテキストなしで個別に変換されるため、最適なオブジェクト指向設計を達成するには、関連する機能の統合、適切なクラス階層の確立、変換されたコードベース全体での適切なカプセル化を促進するために人間の介入が必要になる場合があります。
- 反復的な改良 – 複数のフィードバックループ(4〜5回の反復)により、より包括的な変換が生成されます。
- 役割の割り当て – モデルに特定の役割(シニアソフトウェア開発者)を割り当てると、出力品質が向上します。
- 詳細な指示 – 一般的なパターンに対する具体的な変換ルールを提供すると、一貫性が向上します。
前提条件
この移行戦略は以下の主要な前提条件を設けています:
- コード品質 – レガシーCコードは、識別可能な構造を持つ合理的なコーディング慣行に従っています。難読化された、または構造が不十分なコードは、自動変換前に前処理が必要になる場合があります。
- スコープの制限 – このアプローチは、低レベルのシステムコードではなく、ビジネスロジックの変換を対象としています。ハードウェアとの相互作用やプラットフォーム固有の機能を持つCコードには、手動介入が必要になる場合があります。
- テストカバレッジ – 移行後の機能的同等性を検証するための包括的なテストケースがレガシーアプリケーションに存在します。十分なテストがない場合、追加の検証ステップが必要です。
- ドメイン知識 – agentic workflowはCとJavaの両方の専門知識の必要性を軽減しますが、重要なビジネスロジックの保持を検証するためにビジネスドメインを理解する主題専門家へのアクセスが必要です。
- 段階的移行 – このアプローチは、コンポーネントを個別に変換および検証できる段階的な移行戦略が許容されることを前提としており、プロジェクト全体レベルの移行ではありません。
結果とパフォーマンス
Amazon Nova Premierを活用した移行アプローチの有効性を評価するために、典型的な顧客シナリオを代表するエンタープライズグレードのコードベース全体でパフォーマンスを測定しました。評価は2つの成功要因に焦点を当てました:構造的完全性(すべてのビジネスロジックと機能の保持)とフレームワーク準拠(Spring Bootのベストプラクティスと規約への準拠)。
コードベースの複雑性による移行精度
agentic workflowは、ファイルの複雑性に基づいて異なる効果を示し、すべての結果は主題専門家によって検証されました。以下の表は結果をまとめたものです。
| ファイルサイズカテゴリ | 構造的完全性 | フレームワーク準拠 | 平均処理時間 |
|---|---|---|---|
| Small(0-300行) | 93% | 100% | 30〜40秒 |
| Medium(300-700行) | 81%* | 91%* | 7分 |
| Large(700行以上) | 62%* | 84%* | 21分 |
*複数のフィードバックサイクル後
エンタープライズ導入のための主要な洞察
これらの結果は重要なパターンを明らかにしています:agenticアプローチは、移行作業の大部分(小〜中規模ファイル)の処理に優れており、人間の監視を必要とする複雑なファイルに対しても依然として大きな価値を提供します。これにより、AIがルーチン変換とセキュリティ評価を処理し、開発者が統合とアーキテクチャの決定に集中するハイブリッドアプローチが実現します。
結論
我々のソリューションは、agentic workflow内で実装されたAmazon Bedrock Converse APIとAmazon Nova Premierが、レガシーCコードを最新のJava/Springフレームワークコードに効果的に変換できることを実証しています。このアプローチは複雑なコード構造を処理し、トークン制限を管理し、最小限の人間の介入で高品質の変換を生成します。
このソリューションは、変換プロセスを専門のエージェントロールに分割し、堅牢なフィードバックループを実装し、継続技術によりトークン制限を処理します。このアプローチは移行プロセスを加速し、コード品質を向上させ、エラーの可能性を減らします。
独自のユースケースでソリューションを試し、コメントでフィードバックと質問を共有してください。