Amazon Web Services ブログ
カスタム Amazon Nova モデル用の Amazon SageMaker Inference の発表
AWS New Summit 2025 で Amazon SageMaker AI の Amazon Nova カスタマイズをリリースして以来、お客様からは Amazon SageMaker Inference でオープンウェイトモデルをカスタマイズする場合と同じ機能を Amazon Nova でも使用したいと伺っていました。また、本番環境のワークロードに必要なインスタンスタイプ、自動スケーリングポリシー、コンテキストの長さ、同時実行設定について、カスタムモデル推論の制御と柔軟性を高めたいという声もお聞きしました。
2026 年 2 月 16 日、Amazon SageMaker Inference でのカスタム Nova モデルサポートの一般提供を発表いたしました。これは、フルランクのカスタマイズされた Nova モデルをデプロイおよびスケールするための、本番環境グレードかつ設定可能で、コスト効率の高いマネージド推論サービスです。Amazon SageMaker Training Jobs または Amazon HyperPod を使用して Nova Micro、Nova Lite、Nova 2 Lite の各モデルを推論機能付きでトレーニングし、Amazon SageMaker AI のマネージド推論インフラストラクチャを利用してシームレスにデプロイする、エンドツーエンドのカスタマイズジャーニーをご体験いただけるようになりました。
カスタム Nova モデル用の Amazon SageMaker Inference では、P5 インスタンスの代わりに Amazon Elastic Compute Cloud (Amazon EC2) の G5 および G6 インスタンスを使用した GPU 使用率の最適化、5 分間の使用パターンに基づく自動スケーリング、設定可能な推論パラメータを通じて推論コストを削減できます。この機能により、継続的な事前トレーニング、教師ありのファインチューニング、またはユースケースに合わせた強化ファインチューニングを使用して、カスタマイズされた Nova モデル向けにデプロイできます。また、コンテキストの長さ、同時実行数、バッチサイズに関する詳細設定を設定して、特定のワークロードのレイテンシーとコスト精度のトレードオフを最適化することもできます。
カスタマイズした Nova モデルを SageMaker AI リアルタイムエンドポイントにデプロイする方法、推論パラメータを設定する方法、テスト用にモデルを呼び出す方法を見てみましょう。
SageMaker 推論にカスタム Nova モデルをデプロイする
AWS re:Invent 2025 では、Nova モデルを含む一般的な AI モデル向けに Amazon SageMaker AI の新しいサーバーレスカスタマイズを導入しました。数回クリックするだけで、モデルとカスタマイズ手法をシームレスに選択し、モデル評価とデプロイを行うことができます。トレーニング済みのカスタム Nova モデルアーティファクトが既にある場合は、SageMaker Studio または SageMaker AI SDK を通じて SageMaker Inference でモデルをデプロイできます。
SageMaker Studio の [モデル] メニューで、お使いのモデル内のモデルで、トレーニング済みの Nova モデルを選択します。[デプロイ] ボタン、[SageMaker AI]、[新規エンドポイントを作成] を選択して、モデルをデプロイできます。
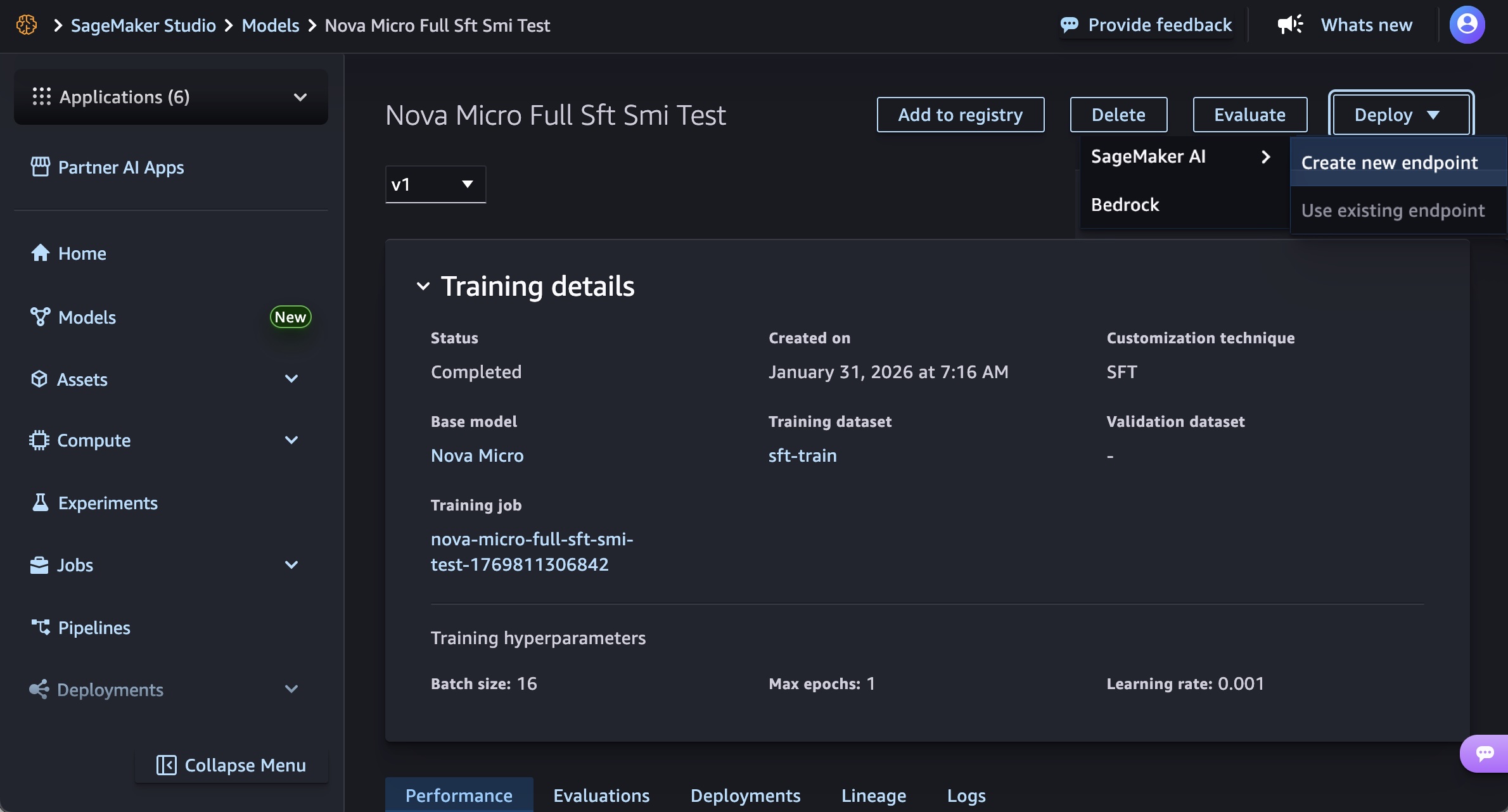
エンドポイント名、インスタンスタイプ、およびインスタンス数、最大インスタンス数、アクセス許可とネットワークなどの詳細オプション、[デプロイ] ボタンを選択します。GA の起動時には、Nova Micro モデルの場合は g5.12xlarge、g5.24xlarge、g5.48xlarge、g6.12xlarge、g6.24xlarge、g6.48xlarge、p5.48xlarge インスタンスタイプ、Nova Lite モデルの場合は g5.24xlarge、g5.48xlarge、g6.24xlarge、g6.48xlarge、p5.48xlarge、Nova 2 Lite モデルの場合は p5.48xlarge を使用できます。
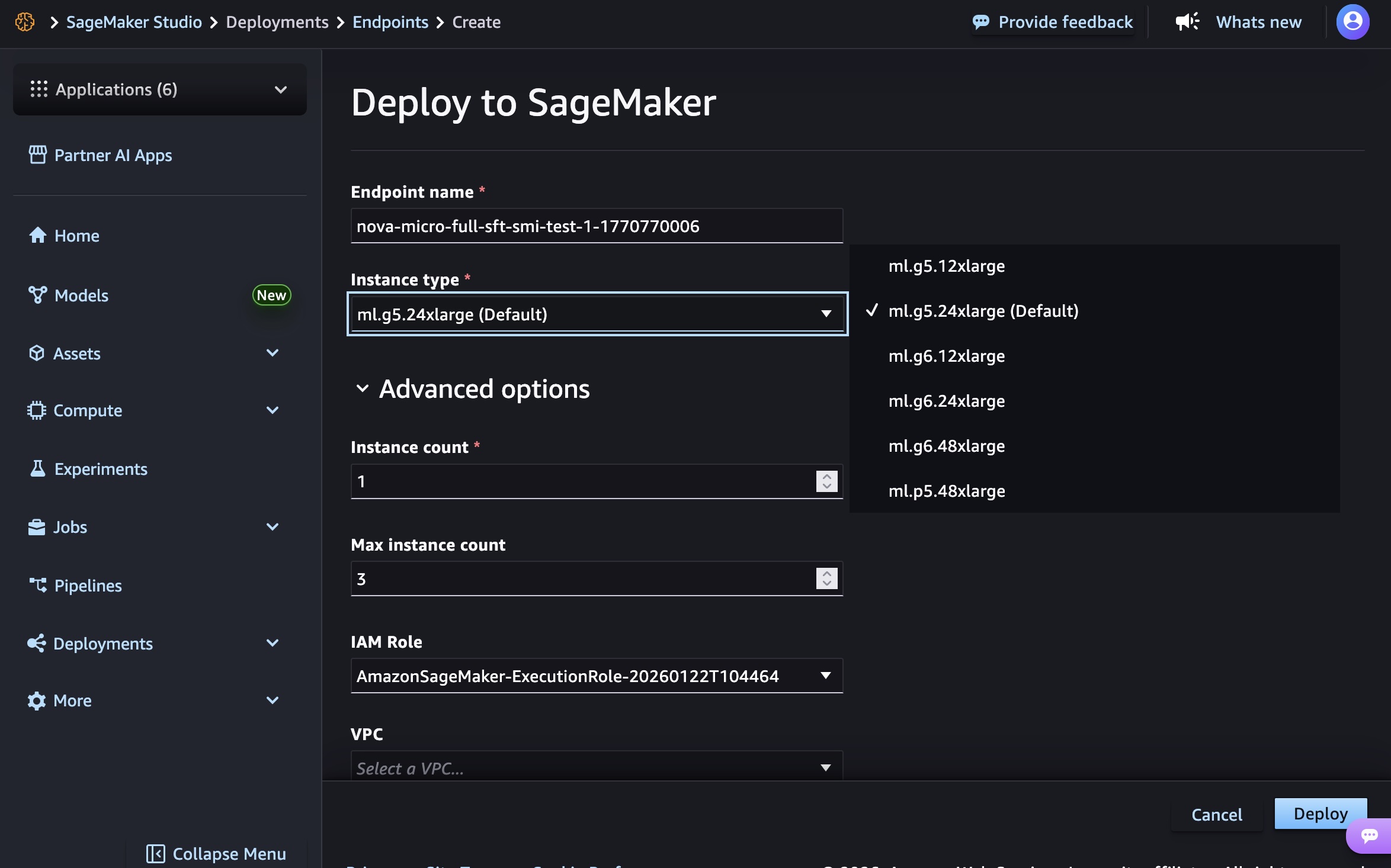
エンドポイントを作成する際には、インフラストラクチャのプロビジョニング、モデルアーティファクトのダウンロード、推論コンテナの初期化に時間がかかります。
モデルのデプロイが完了し、エンドポイントのステータスで [InService] と表示されたら、新しいエンドポイントを使用してリアルタイムの推論を実行できます。モデルをテストするには、[プレイグラウンド] タブを選択し、チャットモードでプロンプトを入力します。
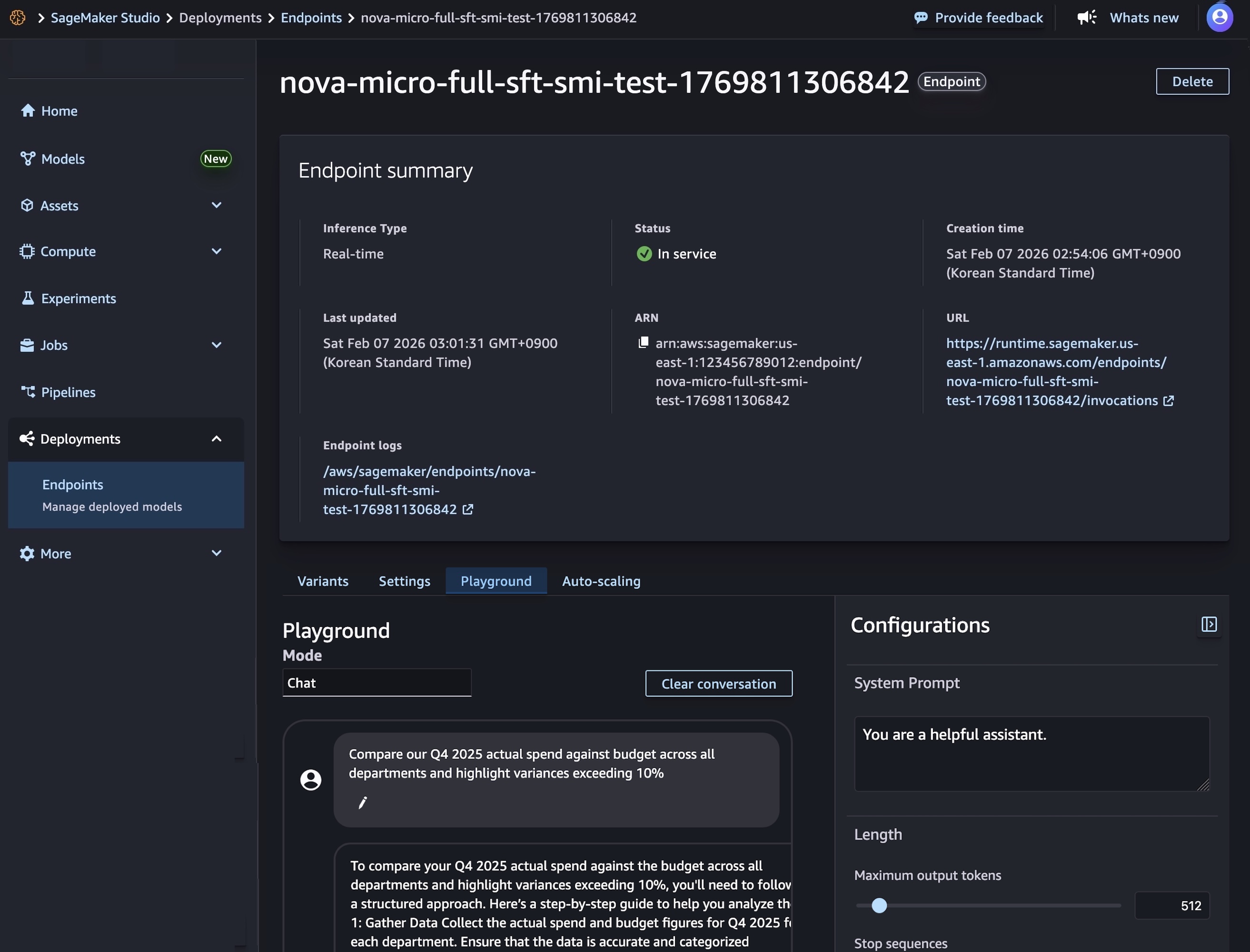
SageMaker AI SDK を使用して 2 つのリソースを作成することもできます。1 つは Nova モデルアーティファクトを参照する SageMaker AI モデルオブジェクトで、もう 1 つはモデルのデプロイ方法を定義するエンドポイント設定です。
次のコードは、Nova モデルアーティファクトを参照する SageMaker AI モデルを作成します。
# Create a SageMaker AI model
model_response = sagemaker.create_model(
ModelName= 'Nova-micro-ml-g5-12xlarge',
PrimaryContainer={
'Image': '123456789012.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://your-bucket-name/path/to/model/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# Model Parameters
'Environment': {
'CONTEXT_LENGTH': 8000,
'CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Model created successfully!")次に、デプロイインフラストラクチャを定義するエンドポイント設定を作成し、SageMaker AI リアルタイムエンドポイントを作成して Nova モデルをデプロイします。このエンドポイントはモデルをホストし、推論リクエストを行うための安全な HTTPS エンドポイントを提供します。
# Create Endpoint Configuration
production_variant = {
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config',
ProductionVariants= production_variant
)
print("Endpoint configuration created successfully!")
# Deploy your Noval model
endpoint_response = sagemaker.create_endpoint(
EndpointName= 'Nova-micro-ml-g5-12xlarge-endpoint',
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config'
)
print("Endpoint creation initiated successfully!")
エンドポイントが作成されたら、推論リクエストを送信してカスタム Nova モデルから予測を生成できます。Amazon SageMaker AI は、ストリーミング/非ストリーミングモードのリアルタイム用の同期エンドポイントと、バッチ処理用の非同期エンドポイントをサポートします。
例えば、次のコードはテキスト生成用のストリーミング補完形式を作成します。
# Streaming chat request with comprehensive parameters
streaming_request = {
"messages": [
{"role": "user", "content": "Compare our Q4 2025 actual spend against budget across all departments and highlight variances exceeding 10%"}
],
"max_tokens": 512,
"stream": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"logprobs": True,
"top_logprobs": 2,
"reasoning_effort": "low", # Options: "low", "high"
"stream_options": {"include_usage": True}
}
invoke_nova_endpoint(streaming_request)
def invoke_nova_endpoint(request_body):
"""
Invoke Nova endpoint with automatic streaming detection.
Args:
request_body (dict): Request payload containing prompt and parameters
Returns:
dict: Response from the model (for non-streaming requests)
None: For streaming requests (prints output directly)
"""
body = json.dumps(request_body)
is_streaming = request_body.get("stream", False)
try:
print(f"Invoking endpoint ({'streaming' if is_streaming else 'non-streaming'})...")
if is_streaming:
response = runtime_client.invoke_endpoint_with_response_stream(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=body
)
event_stream = response['Body']
for event in event_stream:
if 'PayloadPart' in event:
chunk = event['PayloadPart']
if 'Bytes' in chunk:
data = chunk['Bytes'].decode()
print("Chunk:", data)
else:
# Non-streaming inference
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Accept='application/json',
Body=body
)
response_body = response['Body'].read().decode('utf-8')
result = json.loads(response_body)
print("✅ Response received successfully")
return result
except ClientError as e:
error_code = e.response['Error']['Code']
error_message = e.response['Error']['Message']
print(f"❌ AWS Error: {error_code} - {error_message}")
except Exception as e:
print(f"❌ Unexpected error: {str(e)}")完全なコード例を使用するには、「Amazon SageMaker AI での Amazon Nova モデルのカスタマイズ」をご参照ください。モデルのデプロイと管理に関するベストプラクティスの詳細については、「SageMaker AI のベストプラクティス」をご覧ください。
今すぐご利用いただけます
カスタム Nova モデル用の Amazon SageMaker Inference は、2026 年 2 月 16 日、米国東部 (バージニア北部) および米国西部 (オレゴン) の AWS リージョンでご利用いただけます。リージョンごとの提供状況や今後のロードマップについては、「AWS Capabilities by Region」にアクセスしてください。
この機能は、自動スケーリングを使用して EC2 G5、G6、P5 インスタンスで実行される、推論機能を備えた Nova Micro、Nova Lite、Nova 2 Lite モデルをサポートします。使用したコンピューティングインスタンス分のみに対してお支払いいただきます。時間単位の請求で、最小契約はありません。詳細については、Amazon SageMaker AI の料金ページをご覧ください。
Amazon SageMaker AI コンソールをぜひお試しいただき、AWS re:Post for SageMaker 宛てに、または通常の AWS サポートの連絡先を通じて、フィードバックをお寄せください。
– Channy
原文はこちらです。