Amazon Web Services ブログ
Autodesk が、Amazon SageMaker Debugger で Fusion 360 の視覚的類似性検索モデルを最適化
この記事は、Autodesk の機械学習エンジニアである Alexander Carlson が共同執筆したものです。
Autodesk は、数年前にプライベートデータセンターから AWS のサービスにワークロードを移動したことからデジタルトランスフォーメーションの旅を始めました。デジタルトランスフォーメーションの利点は、ジェネレーティブデザインで明らかになります。これは、クラウドコンピューティングを使用して、人間が行える範囲を超えてデザインの探索を推し進める新しいテクノロジーです。ジェネレーティブデザインを使用すると、特定の制約 (材料、重量、コスト、製造方法など) に基づいて一連の高性能デザインオプションをすばやく生成できます。ジェネレーティブデザインには、製造業を (良い方向へ) 淘汰する可能性があります。Autodesk は、Amazon SageMaker を使用して、ジェネレーディブデザインにより数時間または数日ではなく 1 時間で数百のシミュレーションを実行できるようにスケーリングしました。
2019 年秋、Autodesk は、機械学習 (ML) を使用して、Fusion 360 のジェネレーティブデザインテクノロジー向けの視覚的類似性検索機能を構築およびリリースする準備をしていました。Autodesk チームは、AWS と提携し、Amazon SageMaker Debugger を使用して、モデルのトレーニングとデバッグプロセスをどのように改善できるかを評価しました。SageMaker Debugger は、コードを変更することなく、トレーニング実行からのデータのキャプチャと分析をリアルタイムで自動化することにより、ML モデルのトレーニングプロセスに対する完全な洞察を提供します。
この記事では、Autodesk が他のいくつかの利点を享受しながら、モデルをどのように素早く設計、トレーニング、デバッグしたかについて概説します。以下のセクションでは、視覚的類似性検索モデル、Autodesk の SageMaker Debugger 以前のアプローチ、SageMaker Debugger にコードを適合させるために行われる手順、SageMaker Debugger 後のアプローチ、および両方のアプローチのパフォーマンス比較について見ていきます。
視覚的類似性検索モデル
トレーニングされた視覚的類似性検索モデルは、特徴ベクトルを計算します。特徴ベクトルは、距離でグループ化したり、最近傍のジェネレーティブデザインの結果を見つけたりするために使用できます。同じ様なジェネレーティブデザインは、同様の特徴ベクトルを生み出します。視覚的類似性検索は、ジェネレーティブデザインからのデザイン結果のカテゴリ別ビューを提供するため、最適なデザインを選択できます。次のスクリーンショットは、視覚的類似性検索モデルを使用した Fusion 360 の例を示しています。

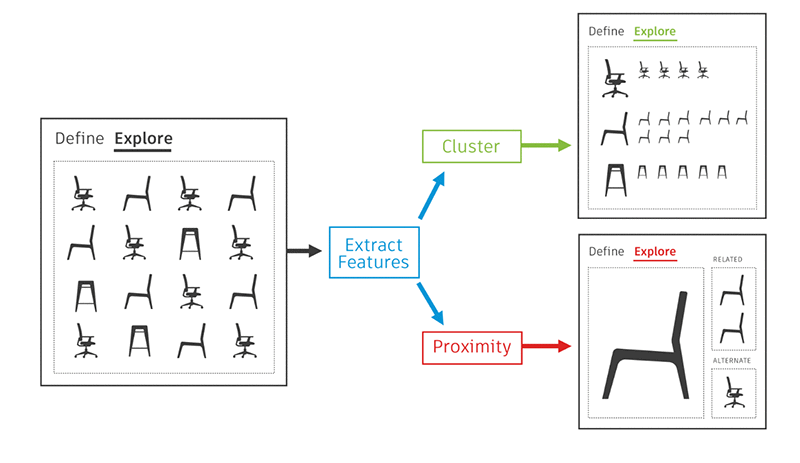
Fusion 360 のジェネレーティブデザインが生成する各結果は 3D の形状をしています。ビジュアル検索モデルは、3D オブジェクトのいくつかのスナップショットをさまざまな角度から取得し、モデルはそれらのスナップショットの再構築を試みます。
Autodesk の ML モデルは、次のレイヤーで構成されるオートエンコーダーです。
- Encoder – 入力の特徴を学習します
- Bottleneck – 入力データの圧縮表現をオートエンコーダーに強制的に学習させます
- Decoder – 潜在的な特徴ベクトルを受け取り、元の入力の再構築を試みます
オートエンコーダーをトレーニングした後、特定の形状の最も重要な特徴を学習したボトルネックレイヤーを使用して、すべてのジオメトリの特徴ベクトルを生成できます。次に、特徴ベクトルを使用して、類似性の設計結果をクラスター化し、最適なデザインをより簡単かつ効率的に見つけることができます。
SageMaker Debugger 以前のアプローチ
Autodesk のチームは、SageMaker Debugger を使用する前に、モデルのトレーニングと編集に線形プロセスを実行しました。モデルのトレーニングコストを抑えることが、並行トレーニングジョブを開始しない理由の 1 つでした。ただし、これには他のネットワークアーキテクチャを探索して、最も効率的で最良の結果が得られるネットワークアーキテクチャを見つけることができないという代償が伴いました。
次の図は、ハイパーパラメータを検証するワークフローを示しています。
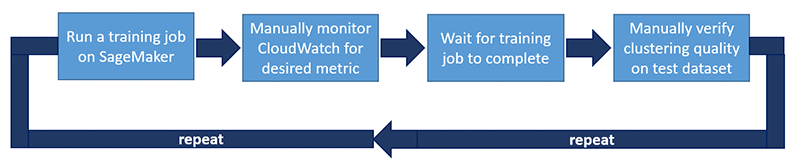
ワークフローには次の手順が含まれます。
- Amazon SageMaker でトレーニングジョブを実行します。トレーニングデータを用意した後、Autodesk はトレーニングジョブのハイパーパラメータを設定し、Amazon SageMaker ノートブックからトレーニングジョブを起動しました。Autodesk は Tensorboard を使用して、自動エンコーダーの再構築パフォーマンスを視覚化しました。
- 希望するメトリクスを得るために、Amazon CloudWatch Events を手動でモニタリングします。精度と損失は、特定のトレーニング間隔で報告されました。Autodesk は、損失の減少と精度の向上の組み合わせを、健全なトレーニングジョブを識別するためのメトリクスとして使用しました。モデルの検証には、Autodesk は Tensorboard のローカルインスタンスを使用しました。モデルには、チェックポイントごとにオートエンコーダーの入力と出力を生成するコードがあり、モデルを視覚的に検査および検証できました。
- トレーニングジョブが完了するまで待ちます。通常、1 つのトレーニングジョブを完了するのに 10〜15 時間かかりました。何度か、悪いトレーニングジョブが夜通し実行されたままになり、時間とコストのかかるコンピューティングリソースが無駄になってしまいました。悪いトレーニングジョブとは、収束しなかったジョブ、または数時間のトレーニングの後も悪い出力を生成し続けたジョブと定義されました。
- テストデータセットのクラスタリング品質を手動で確認します。Autodesk は、Tensorboard の視覚化を使用して、モデルのクラスタリングパフォーマンスを検証しました。次のスクリーンショットは、Tensorboard の視覚化を示しています。

Tensorboard 投影での 3D 空間配置は、T-SNE クラスタリングの結果を表しています。T-SNE は、t 分布の確率的近傍埋め込みです。この手法では、高次元のデータを 2 次元または 3 次元の空間にマッピングし、簡単に視覚化できます。同様の形状は同様の TSNE 埋め込みを生成し、その結果、埋め込みスペースに近接するはずです。これにより、Autodesk は、モデルの埋め込みがジェネレーティブデザインの結果を望ましい方法でクラスター化しているかどうかを確認できました。人間のユーザーが認めるような方法で結果を正常にグループ化することにより、優れたモデルパフォーマンスが示されました。
コードを適合させて Amazon SageMaker Debugger を使用する
SageMaker Debugger を Autodesk のトレーニングジョブに追加するのは簡単でした。SageMaker Debugger は、ゼロコード変更パラダイムをサポートしています。つまり、トレーニングスクリプトを変更する必要はまったくありません。どのテンソルを出力するかを定義する Amazon SageMaker 推定子でデバッガフック設定を指定する必要があるだけです。
SageMaker Debugger は、重み、バイアス、勾配、損失などのデフォルトのコレクションを提供します。正規表現を指定してテンソル名を含めることで、カスタムコレクションを簡単に定義することもできます。たとえば、Relu 活性化の出力を含める場合は、次のコードでコレクションを定義できます。
Autodesk の視覚的類似性検索モデルでは、次のデフォルトのコレクションが発行されました。
Amazon SageMaker Debugger は、推定子に渡された設定と、LossNotDecreasing 組み込みルールの設定をフックします。次のコードを参照してください。
次のセクションでは、組み込みルールについて詳しく説明します。
SageMaker Debugger のアプローチ
Autodesk は SageMaker Debugger を使用して、並列トレーニングジョブを開始して、パラメータスイープを実行しました。トレーニングジョブの並列化により、ワークフロー全体が大幅に変化しました。計算コストを抑えるために、Autodesk は組み込みの SageMaker Debugger ルールを使用して、最適でないトレーニングジョブの自動終了をトリガーしました。
Autodesk は、さまざまなハイパーパラメータ値を使用して、どの組み合わせが最良の結果をもたらしたかを評価しました。SageMaker Debugger を導入する前は、Autodesk は、ハイパーパラメータ値のセットがそれぞれ異なる複数のトレーニングジョブを実行し、これらのトレーニングジョブが完了するまで待ってから結果を検査する必要がありました。SageMaker Debugger を使用すると、複数のトレーニングジョブを並行して実行し、組み込みルールを設定し、アラートがトリガーされたときにトレーニングを停止するオプションを選択できます。悪いハイパーパラメータによってトレーニングジョブが収束しなかった場合、トレーニングジョブが終了したため、Autodesk は時間と費用を節約できました。
次の図は、新しいワークフローを示しています。
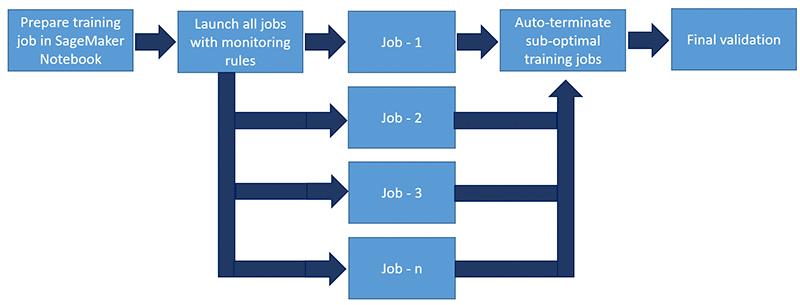
SageMaker Debugger は、勾配の消失や極端な増幅、ニューロンの飽和など、最も一般的なトレーニングの問題を検出する一連の組み込みルールを備えています。これらのルールは、問題があるかどうかを示すメトリクスを出力して CloudWatch に送ります。CloudWatch アラームと AWS Lambda 関数を設定して、トレーニングジョブを停止できます。
この機能により、Autodesk は並行トレーニングジョブを開始して、大規模なパラメータスイープを実行し、次善のトレーニングジョブを自動終了することができました。その結果、計算コストを節約し、より優れたモデルを作成できました。
パラメータスイープ中に、Autodesk は主に組み込みのルール LossNotDecreasing を使用しました。これは、損失が指定されたパーセンテージで減少しない場合にトリガーされます。損失関数は、モデル出力とグラウンドトゥルースを評価します。オートエンコーダーの場合、損失関数は、オートエンコーダーの出力と入力の間の距離を測定します。Autodesk の視覚的類似性検索モデルは L2 損失を使用しました。再設定された出力が優れているほど、L2 損失は小さくなります。減少しない損失は、次のことを示している可能性があります。
- トレーニングが局所最適に到達したため、過剰適合につながる可能性があるため、モデルをさらにトレーニングする必要はない
- ハイパーパラメータが悪いためにトレーニングプロセス全体で損失が減少しない場合に、モデルがまったく学習しない
どちらの場合も、トレーニングを停止することをお勧めします。
パラメータスイープ中に、Autodesk は学習率、学習率の低下、バッチサイズ、トレーニングデータセットを変化させました。
SageMaker Debugger のカスタムルールを定義することもできます。Autodesk は、モデルパフォーマンスの重要な指標として、SageMaker Debugger を使用しました。これは、潜在スペース内の同様の入力を上手くグループ化します。潜在スペース内の同じクラスの入力間の距離をチェックするカスタムルールを簡単に定義し、類似の入力が近くにない場合は例外を発生させることができます。
SageMaker Debugger は、並列トレーニングジョブを実行し、ルールに基づいてそれらを自動的に終了する機能に加えて、トレーニングの進行中に Autodesk がテンソルの統計をリアルタイムで視覚化および計算できるようにしました。
smdebug オープンソースライブラリは、テンソルの読み取りとフィルタリングを容易にします。便利なことに、smdebug はデータを NumPy 配列として提供しているため、NumPy、Scipy、Scikit などのライブラリを使用してデータを分析および視覚化できます。
次のコード例は、レイヤーごとのグラデーションの最小値と最大値を取得する方法を示しています。
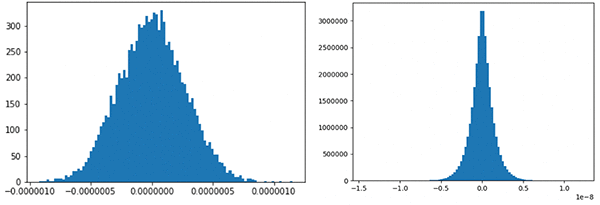
テンソルを取得した後、重み、勾配、活性化出力などの分布をリアルタイムで視覚化できます。Autodesk では、この分析により、モデルが勾配の消失に悩まされており、内側のレイヤーの重みはわずかな更新しか受けていないことがわかりました。これは、次の要因によるものです。
- L2 損失関数の収束が速すぎて、小さな勾配が生じた。L2 損失は入力と出力の間の強度値のみを比較するため、これはオートエンコーダーの一般的な問題です。これにより、損失値が小さくなり、再設定された出力がぼやけます。
- モデルの層が多すぎるため、モデルの初期層に近づくにつれて勾配が小さくなった。
- ボトルネックレイヤーは完全に接続されたいくつかのレイヤーで設定されていたが、それらのほとんどは小さな更新のみを受け取った。
次のグラフは、エンコーダーの最初と最後のレイヤーの勾配の分布を示しています。グラデーションには小さな範囲があり、その大きさの順序はレイヤー間で異なります。
分析に基づいて、Autodesk は次の最適化を適用しました。
- 構造的類似性インデックス (SSIM) 損失は、L2 損失関数に取って代わりました。SSIM は、画像間の類似性を比較するのにより適したメトリクスです。視覚的類似性検索モデルは、SSIM を使用することにより、より細かな詳細を学習し、より高品質の出力を生成しました。
- エンコーダーとデコーダーで一部のレイヤーが削除され、モデルの品質に影響を与えることなくモデルが小さくなりました。
- ボトルネック層が 3 分の 1 以上減少し、パラメータの数が大幅に減少しました。
Autodesk は、TSNE 埋め込みの視覚化情報を使用して、オートエンコーダーモデルが適切にトレーニングされているかどうかを判断しました。SageMaker Debugger と Scikit-Learn を使用すると、トレーニングを継続しながら、埋め込みをリアルタイムで計算して視覚化できます。詳細については、GitHub リポジトリをご覧ください。
次のスクリーンショットは、最適化されたモデルによって生成されたサンプル画像を示しています。

Amazon SageMaker Debugger の利点
Autodesk チームは、SageMaker Debugger を使用することにより、次の利点を実現しました。
- 時間の節約 – 並列トレーニングジョブをトリガーできるため、モデル全体のトレーニング時間が 90% 以上短縮されました。Autodesk は、SageMaker Debugger を使用してモデル全体を 10 時間でトレーニングしましたが、手動トレーニングアプローチでは 5〜6 日かかりました。
- コンピューティングコストの節約 – SageMaker Debugger を使用して設定されたトレーニングジョブのほとんどが迅速に終了し、コンピューティングコストの約 70% を節約できました。また、最適化されていないトレーニングジョブの検証手順を回避することで、開発者の時間を節約しました。
- モデルサイズの縮小 – Autodesk チームは、モデルパフォーマンスデータから得られた洞察を使用して、各ネットワークレイヤーのパフォーマンスを決定しました。このような洞察により、レイヤー数が 33% 削減され、モデル全体のサイズが 40% 縮小されました。
推奨事項
この記事で概説されているアプローチと利点に加えて、ML モデルをトレーニングしてデプロイする際には、次の推奨事項を考慮してください。
- Amazon SageMaker Studio を使用して、モデル作成を簡素化します。
- 同時 Lambda 関数を使用して、Amazon S3 のデータセットに変換をすばやく適用します。Lambda トリガーとして機能する Amazon SQS キューにジョブを送信することにより、同時 Lambda 関数を利用できます。
- Amazon SageMaker スポットインスタンスを使用したトレーニングにより、コンピューティングコストを最大 70% 節約できます。チェックポイントの頻度を増やして、割り込みまでの時間のロスを減らすことができます。
- Amazon SageMaker Ground Truth で、チームまたは組織のみがアクセスできるプライベートデータラベル付けジョブをセットアップします。これにより、データを外部に公開せずにツールを使用できます。
SageMaker Debugger の使用の詳細については、GitHub リポジトリを参照してください。
まとめ
この記事では、Autodesk が SageMaker Debugger を使用して ML モデルを設計、トレーニング、デバッグした方法について説明しました。SageMaker Debugger を使用すると、時間を節約し、コストを計算し、モデルサイズを縮小できます。
著者について
 Alexander Carlson は、Autodesk の Fusion 360 機械学習チームで働く機械学習エンジニアです。現在、Autodesk の本番ワークフローに機械学習を実装するため、AWS ベースのインフラストラクチャを使って作業しています。
Alexander Carlson は、Autodesk の Fusion 360 機械学習チームで働く機械学習エンジニアです。現在、Autodesk の本番ワークフローに機械学習を実装するため、AWS ベースのインフラストラクチャを使って作業しています。
 Nathalie Rauschmayr は、AWS の機械学習サイエンティストで、お客様によるディープラーニングアプリケーションの開発を支援しています。
Nathalie Rauschmayr は、AWS の機械学習サイエンティストで、お客様によるディープラーニングアプリケーションの開発を支援しています。
 Niraj Jetly は、AWS と連携する Neptune のソフトウェア開発マネージャーです。現在の職務に就く前は、Niraj はシニア CSM として Autodesk のデジタルトランスフォーメーションを率いていました。AWS と連携する前は、Niraj は CTO、VP-Engineering、および製品管理責任者として、15 年以上にわたっていくつものプロダクトチームとエンジニアリングチームを率いていました。
Niraj Jetly は、AWS と連携する Neptune のソフトウェア開発マネージャーです。現在の職務に就く前は、Niraj はシニア CSM として Autodesk のデジタルトランスフォーメーションを率いていました。AWS と連携する前は、Niraj は CTO、VP-Engineering、および製品管理責任者として、15 年以上にわたっていくつものプロダクトチームとエンジニアリングチームを率いていました。
 Satadal Bhattacharjee は、AWS AI のプリンシパルプロダクトマネージャーです。彼は、Amazon SageMaker などのプロジェクトで機械学習エンジン PM チームを率い、TensorFlow、PyTorch、MXNet などの機械学習フレームワークを最適化しています。
Satadal Bhattacharjee は、AWS AI のプリンシパルプロダクトマネージャーです。彼は、Amazon SageMaker などのプロジェクトで機械学習エンジン PM チームを率い、TensorFlow、PyTorch、MXNet などの機械学習フレームワークを最適化しています。