Amazon Web Services ブログ
Amazon SageMaker と Amazon ES を使用しての画像検索アプリケーションの構築
時に人は、探しているものを適格に説明するための言葉を見つけることに、難しさを感じるものです。古いことわざでも、「百聞は一見にしかず」と言います。 言葉による説明より、実際の例や画像を示す方が便利なことも多く、これは、検索エンジンで何かを見つけようとしている場合には顕著です。
今回の記事では、画像検索の結果を提供できるフルスタックのウェブアプリケーションを含む画像検索アプリケーションを、ゼロから、1 時間もかからず構築していきます。
特に、ファッション系およびホームデコレーション系などの小売業や E コマース企業では、画像検索を利用して顧客エンゲージメントを改善できます。画像検索により、販売者は購入者に対し、テーマもしくは形状的に関連のあるアイテムを提案できるようになります。これは、テキストのみのクエリを使用している販売者では、簡単に実現することはできないでしょう。Gartner によれば、「ウェブサイトを早期に画像および音声検索が可能となるよう再設計するブランドでは、そのデジタルコマース収益が、2021 年までに最大 30% 増加することが見込める。」とのことです。
高レベルな画像検索の例
Amazon SageMaker は完全マネージド型サービスであり、あらゆる開発者やデータサイエンティストに対し、機械学習 (ML) モデルを迅速に構築、トレーニング、デプロイするための手段を提供します。同じく完全マネージド型サービスである Amazon Elasticsearch Service では、Elasticsearch のデプロイ、保護、実行を、簡単かつ大規模に、コスト効率良く行えます。Amazon ES では、k–近傍 (KNN) 検索が行えます。これは、製品レコメンデーション、不正検出、画像や動画および意味論的なドキュメントの取得など、今回のものと類似性のあるユースケースで検索を強化するためにも使用できます。軽量かつ効率的な非メトリクス空間ライブラリ (NMSLIB) を使用して構築された KNN は、数千のディメンションにわたる数十億のドキュメントに関する、大規模かつ低レイテンシーの近傍検索を、通常の Elasticsearch クエリと同じ手軽さで実行することを可能にします。
この画像検索のアーキテクチャを次の図に示します。

ソリューションの概要
画像検索アーキテクチャの実装作業は、次の 2 つのフェーズにより構成されます。
- サンプルの画像データセットを用い、参照用の KNN インデックスを Amazon ES 上に構築します。
- Amazon SageMaker エンドポイントと Amazon ES に新しい画像を登録し、類似性のある画像を取得します。
参照用 KNN インデックスの作成
このステップでは、Amazon SageMaker でホスティングされている事前トレーニング済みの Resnet50 モデルを通じ、各画像から 2,048 個の特徴ベクトルを抽出します。各ベクターは、Amazon ES ドメインに置かれる KNN インデックスで保存されます。今回のユースケースでは、ファッションに関する 8,732 の高画質画像を収録している Zalando リサーチのデータセットである、FEIDEGGER を利用し画像を取得します。次のスクリーンショットに、KNN インデックス作成のためのワークフローを示します。

このプロセスは、次のようなステップで構成されます。
- ユーザーは、Amazon SageMaker ノートブックインスタンスにある Jupyter ノートブックを立ち上げます。
- 事前トレーニング済みの Resnet50 深層ニューラルネットが Keras からダウンロードされます。この際、最後の分類子レイヤーは削除され、シリアル化された新しいモデルアーティファクトが、Amazon Simple Storage Service (Amazon S3) に保存されます。このモデルを使用して、Amazon SageMaker のリアルタイムエンドポイントにおいて、TensorFlow の Serving API が起動されます。
- ファッション画像がエンドポイントにプッシュされます。この画像はニューラルネットワークを通過し、その特徴、もしくは埋め込み要素が抽出されます。
- ノートブックのコードが、Amazon ES ドメインにある KNN インデックスに対し、画像の埋め込み要素を書き込みます。
クエリ画像からの画像検索
このステップでは、アプリケーションからクエリ用画像を提供し、Amazon SageMaker でホスティングするモデルを通過させることで、2,048 個の特徴点を抽出します。これらの特徴点は、Amazon ES 内の KNN インデックスに対するクエリに使用されます。KNN for Amazon ES が、ベクトル空間内におけるポイント検索の手段を提供します。これらのポイントの「近傍」を、ユークリッド距離 (デフォルト) もしくは余弦類似性を用いて特定します。指定された画像に関し、近傍ベクトル (例: k = 3 近傍) が特定されたら、Amazon S3 内に保存された内の関連性のある画像が、アプリケーションに対して返されます。次の図に、この画像検索用フルスタックアプリケーションのアーキテクチャを示します。

このプロセスは、次のようなステップで構成されます。
- エンドユーザーが、ブラウザもしくはモバイルデバイスから、ウェブアプリケーションにアクセスします。
- ユーザーがアップロードした画像は、base64 でエンコードされたストリングとして、Amazon API Gateway と AWS Lambda に送られます。さらに Lambda 関数が、これをバイト単位で再エンコーディングします。
- この Lambda 関数内では、パブリックに読み出し可能な画像の URL がストリングとして渡され、バイト単位のダウンロードが行われます。
- これらの各バイトは、推論用ペイロードとして Amazon SageMaker のリアルタイムエンドポイントに送られ、モデルからは、画像の埋め込み要素についてのベクトルが返信されます。
- 検索クエリに含まれる画像埋め込み要素ベクトルが、関数により、Amazon ES ドメインのインデックス内にある k–近傍に渡されます。k 個の類似画像と、それらに対応する Amazon S3 URI が返されます。
- 事前署名された Amazon S3 URL が関数により生成され、クライアントウェブアプリケーションに返信されます。これにより、類似画像がブラウザー上で表示されます。
AWS のサービス
このエンドツーエンドアプリケーション構築には、次のような AWS のサービスを使用します。
- AWS Amplify – AWS Amplify は、フロントエンドとモバイルの開発者が、クラウド利用可能なアプリケーションを構築するための、JavaScript ライブラリです。詳細については、GitHub リポジトリをご参照ください。
- Amazon API Gateway – あらゆる規模の API を作成、公開、保守、監視、保護するための完全マネージド型サービスです。
- AWS CloudFormation – AWS CloudFormation では、開発とビジネスの現場において、AWS とサードパーティ製リソースを関連付けたコレクションを簡単に作成できるので、整然として想定も可能な様式でのプロビジョニングが可能となります。
- Amazon ES – 大規模な Elasticsearch クラスターのデプロイ、運用、およびスケーリングを容易にする、マネージド型サービスです。
- AWS IAM – AWS Identity and Access Management (IAM) は、AWS のサービスとリソースに対するアクセスが、安全に行えるようにします。
- AWS Lambda – イベント駆動型のサーバーレスコンピューティングプラットフォームであり、イベントに応答してコードを実行します。また、そのコードに必要とされるコンピューティングリソースを自動的に管理します。
- Amazon SageMaker – 大規模な ML モデルを構築、トレーニング、チューニング、およびデプロイするための完全マネージド型エンドツーエンド ML プラットフォームです。
- AWS SAM – AWS Serverless Application Model (AWS SAM) は、サーバーレスアプリケーションを構築するためのオープンソースフレームワークです。
- Amazon S3 – 非常に耐久性が高く、高可用性で制限のないスケーリングが可能な、データストレージインフラストラクチャを、非常に低コストで提供するオブジェクトストレージサービスです。
前提条件
このチュートリアルの実行には、CloudFormation テンプレートを起動するための適切なアクセス許可が IAM により付与された、AWS アカウントが必要です。
ソリューションのデプロイ
ソリューションのデプロイには、CloudFormation スタックを利用します。次に挙げる必要なすべてのリソースが、スタックにより作成されます。
- Jupyter ノートブックで Python コードを実行するための、Amazon SageMaker ノートブックインスタンス
- ノートブックインスタンスに関連つけられた IAM ロール
- KNN インデックスで、画像の埋め込み要素ベクトルを保存および取得するための、Amazon ES ドメイン
- 2 つの S3 バケット: 1 つはソースのファッション画像の保存用であり、もう一方は静的ウェブサイトのホスティング用
加えて、Jupyter ノートブックからは次をデプロイします。
- 画像の特徴ベクトルと埋め込み要素をリアルタイムで取得するための、Amazon SageMaker エンドポイント
- API Gateway と Lambda を使用するサーバーレスバックエンドのための、AWS SAM テンプレート
- 実際のエンドツーエンドの ML アプリケーションの動作を表示するための、S3 バケット上でホスティングされた静的なフロントエンドウェブサイト。フロントエンドのコードでは、ReactJS と Amplify JavaScript ライブラリを使用します。
次の手順により作業を実行します。
- IAM ユーザー名とパスワードを使用して AWS マネジメントコンソールにサインインします。
- [Launch Stack (スタックの起動)] をクリックし、新しいタブを開きます。

- [Quick create stack (スタックのクイック作成)] ページでチェックボックスをオンにし、IAM リソースの作成を承認します。
- [Create stack (スタックの作成)] をクリックします。

- スタックの実行が完了するのを待ちます。
[Events (イベント)] タブでは、スタック作成プロセスにおける、さまざまなイベントを確認できます。スタックの作成が完了すると、ステータスに CREATE_COMPLETE と表示されます。
[Resources (リソース)] タブには、CloudFormation テンプレートが作成したすべてのリソースが表示されます。
- [Outputs] タブで、[SageMakerNotebookURL] の横に表示された値をクリックします。
このハイパーリンクにより、Amazon SageMaker ノートブックインスタンスにある Jupyter ノートブックが開きます。この後に続く作業は、このノートブックで完了させます。

Jupyter ノートブックのランディングページが開いているはずです。
- visual-image-search.ipynb をオンにします。

Amazon ES での KNN インデックスの構築
このステップの作業では、Visual image search (画像イメージ検索) とタイトル表示された、ノートブックの開始ページが開かれている必要があります。ノートブック内の手順に従い、各セルを順番通りに実行していきます。
画像の特徴ベクトル (埋め込み要素) を生成するために、Amazon SageMaker エンドポイントでホスティングしている、事前トレーニング済みの Resnet50 モデルを使用します。埋め込み要素は、CloudFormation スタックに作成された、Amazon ES ドメインに保存されています。詳細については、ノートブックのマークダウンセルをご参照ください。
ノートブック上の、Deploying a full-stack visual search application (フルスタック画像検索アプリケーションのデプロイ) と表記されたセルまで作業を進めます。
このノートブックには、重要なセルがいくつか含まれています。
最終的な CNN 分類機能を含まずにトレーニング済み ResNet50 モデルのロードを行うには、次のコードを使用します (このモデルは、単純な画像の特徴抽出機能として使用しています) 。
モデルの保存には、TensorFlow の SavedModel 形式を使用します。これには、重みやコンピューティングを含む、完全な TensorFlow プログラムが包含されます。次にコードを示します。
次のコードを使用し、Amazon S3 にモデルアーティファクト (model.tar.gz) をアップロードします。
Amazon SageMaker Python SDK を使用して、Amazon SageMaker TensorFlow 配信ベースサーバーに対するモデルのデプロイを行います。このサーバーからは、TensorFlow Serving REST API のスーパーセットが提供されています。次にコードを示します。
次のコードにより、Amazon SageMaker エンドポイントから参照画像の特徴点を抽出します。
Amazon ES KNN インデックスのマッピングを定義します。コードは次のとおりです。
画像の特徴ベクトルと、それに対応する Amazon S3 での画像 URI を、Amazon ES KNN インデックスにインポートします。コードは次のとおりです。
フルスタック画像検索アプリケーションの構築
この段階で、画像の特徴を抽出する Amazon SageMaker エンドポイントと、Amazon ES 上の KNN インデックスが機能しています。これで、ML により機能する実践的でフルスタックのウェブアプリ構築のための準備ができました。AWS SAM テンプレートにより、API Gateway と Lambda を使用する、サーバーレスの REST API をデプロイします。REST API では、新しい画像を受け取り、そこから埋め込み要素を抽出して、類似の画像をクライアントに返信します。その後、新たな REST API と通信するフロントエンドのウェブサイトを、Amazon S3 にアップロードします。フロントエンドのコードでは、REST API との統合に、Amplify を使用します。
- 次からのセルでは、フルスタックのアプリケーションが必要とする、Lambda や API Gateway などのリソースを作成する、CloudFormation テンプレートの事前入力を行います。
次のスクリーンショットは、事前生成される CloudFormation テンプレートへのリンクが出力される様子です。

- このリンクをクリックします。
[Quick create stack] ページが開きます。
- IAM リソースの作成を承認するために、チェックボックスをオンにします。この IAM リソースにはカスタム名が付いており、また
CAPABILITY_AUTO_EXPANDとなっています。 - [Create stack (スタックの作成)] をクリックします。
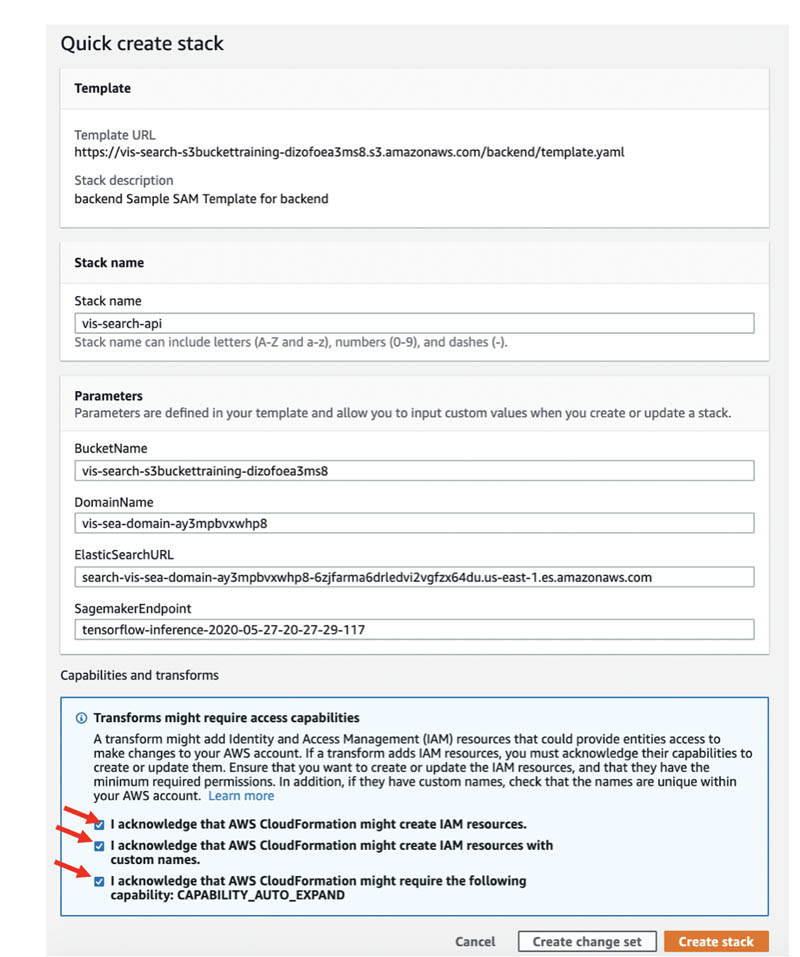
スタックの作成が完了すると、ステータスに CREATE_COMPLETE と表示されます。[Resources (リソース)] タブには、CloudFormation テンプレートが作成したすべてのリソースが表示されます。
- スタックの作成ができたら、さらにセルの作業を進めていきます。
次のセルでは、フロントエンドとバックエンドのコードを含むフルスタックのアプリケーションが、正常にデプロイされたことが確認できます。
以下のスクリーンショットに、URL の出力を示します。

- このリンクをクリックします。
これでアプリケーションページが開きます。このアプリケーションから、ドレスの画像をアップロードするかその画像への URL を入力し、類似のドレスの画像を入手できます。

- 画像検索アプリケーションのテストと実験が終了したら、ノートブックの末尾にある 2 つのセルを実行します。
これらのセルにより、Amazon SageMaker エンドポイントが停止され、S3 バケットが空になり、他のリソースを削除するための準備が整います。
クリーンアップ
残りの AWS リソースを削除するには、AWS CloudFormation コンソールを開き、vis-search-api および vis-search スタックを削除します。

まとめ
今回の記事では、ML による画像検索アプリケーションを作成するための、Amazon SageMaker と Amazon ES KNN インデックスの使用方法を解説しました。そのためのモデルには、ImageNet データセットにより事前トレーニングされた、Resnet50 モデルを使用しました。しかし、VGG、Inception、MobileNet など、他の事前トレーニング済みモデルを、独自のデータセットでファインチューニングしながら適用することも可能です。
ほとんどの深層学習用途には、GPU インスタンスが推奨されています。新たなモデルをトレーニングする場合、CPU インスタンスに比べて GPU インスタンスの方が早く終了します。複数の GPU インスタンスを使用するか、トレーニングを GPU が動作している多くのインスタンス間で分散して実施すれば、おおむね線形なスケーリングを実現できます。しかしながら今回のユースケースでは、チュートリアル全体を AWS の無料利用枠で完了できるようにするため、CPU を使用しました。
本稿で提供したサンプルコードの詳細については、GitHub リポジトリをご参照ください。Amazon ES の詳細については、次をご参照ください。
- Elasticsearch クラスターのインデックス作成パフォーマンスを向上させるにはどうすればよいですか ?
- Amazon Elasticsearch Service のベストプラクティス
- 小規模な Amazon Elasticsearch Service ドメインのコストを削減する
著者について
 Amit Mukherjee は、AWS のシニアパートナーソリューションアーキテクトです。彼は、クラウドでの成功にパートナーを導くため、アーキテクチャ的な指針を提供しています。また、AI と機械学習に特別な興味を持っています。余暇の楽しみは家族と充実した時間を過ごすことです。
Amit Mukherjee は、AWS のシニアパートナーソリューションアーキテクトです。彼は、クラウドでの成功にパートナーを導くため、アーキテクチャ的な指針を提供しています。また、AI と機械学習に特別な興味を持っています。余暇の楽しみは家族と充実した時間を過ごすことです。
 Laith Al-Saadoon は、AWS のソリューションアーキテクトで、データ分析を主に扱っています。彼は、膨大な量のデータを大量に処理するアーキテクチャーを、お客様のために設計することに専念しています。彼は余暇においても、最新の機械学習と人工知能について学んでいます。
Laith Al-Saadoon は、AWS のソリューションアーキテクトで、データ分析を主に扱っています。彼は、膨大な量のデータを大量に処理するアーキテクチャーを、お客様のために設計することに専念しています。彼は余暇においても、最新の機械学習と人工知能について学んでいます。