Amazon Web Services ブログ
キャパシティ対応推論:SageMaker AI エンドポイントにおけるインスタンスの自動フォールバック
本ブログは “Capacity-aware inference: Automatic instance fallback for SageMaker AI endpoints” を翻訳したものです。
組織が本番環境で生成 AI ワークロードをスケールさせていく中で、信頼性の高い GPU コンピュートを確保することは、最も根強い運用上の課題の 1 つになっています。大規模言語モデル (LLM) やマルチモーダルアーキテクチャは特定のインスタンスタイプを必要とし、そのキャパシティが利用できない場合、エンドポイントは 1 件のリクエストも処理する前に失敗してしまいます。
Amazon SageMaker AI でリアルタイム推論エンドポイントを構築する際は、これまで作成時に単一のインスタンスタイプを指定する必要がありました。そのインスタンスタイプのキャパシティが不足していると、エンドポイントは実行状態に到達できません。設定を更新し、別のインスタンスタイプを選択して再試行する、というサイクルをプロビジョニングが成功するまで繰り返すことになります。
本日、Amazon SageMaker AI は、新規および既存の推論エンドポイント向けに キャパシティ対応インスタンスプール を導入します。優先順位付きのインスタンスタイプリストを定義しておけば、SageMaker AI はキャパシティが制約されているとき (作成時、スケールアウト時、スケールイン時) に、自動的にそのリストを順に処理します。エンドポイントは手動の介入なしで、利用可能な AI インフラ上にプロビジョニングされます。この機能は、シングルモデルエンドポイント、推論コンポーネントベースのエンドポイント、非同期推論エンドポイントで利用できます。
本記事では、インスタンスプールの仕組みと、新規エンドポイントの作成や既存エンドポイントの移行を含めた使い始め方について説明します。
これまでの課題
SageMaker AI 推論エンドポイント (リアルタイムまたは非同期) にモデルをデプロイするとき、単一のインスタンスタイプを指定します。そのインスタンスタイプの利用可能なキャパシティがない場合、エンドポイントの作成は失敗します。この制約は、エンドポイントのライフサイクルのあらゆる段階で現れます。
キャパシティ不足によるエンドポイント作成失敗:
希望するインスタンスタイプが利用できない場合、SageMaker AI は Insufficient Capacity エラーを返します。エンドポイントを稼働状態にするには代替のインスタンスタイプを手動で試行し続ける必要があり、結果がわかるまで毎回かなりの時間を要します。
Auto Scaling がフリートを拡張できない:
スケールアウトイベントが発生し、インスタンスタイプにキャパシティが不足している場合、Auto Scaling は同じインスタンスタイプを際限なくリトライします。トラフィックが増加し続ける一方で、エンドポイントのサイズは現状のままです。
スケールダウンに優先順位の概念がない:
単一のインスタンスタイプでは、優先 (preferred) とフォールバック (fallback) のハードウェアという概念がありません。すべてのインスタンスが区別なく削除候補となります。
オブザーバビリティが集約されてしまい、対処につなげにくい:
Amazon CloudWatch メトリクスはエンドポイントレベルで集約されます。レイテンシやキャパシティの問題を調査する際、メトリクスは「何かがおかしい」ことは示しても、「どのインスタンスタイプが原因か」までは示してくれません。
優先順位ベースのインスタンスプールの仕組み
エンドポイント設定の中で、instance pools と呼ばれるインスタンスタイプの優先順位付きリストを定義します。SageMaker AI はキャパシティが制約されたときに、自動的にそのリストを順番に処理します。
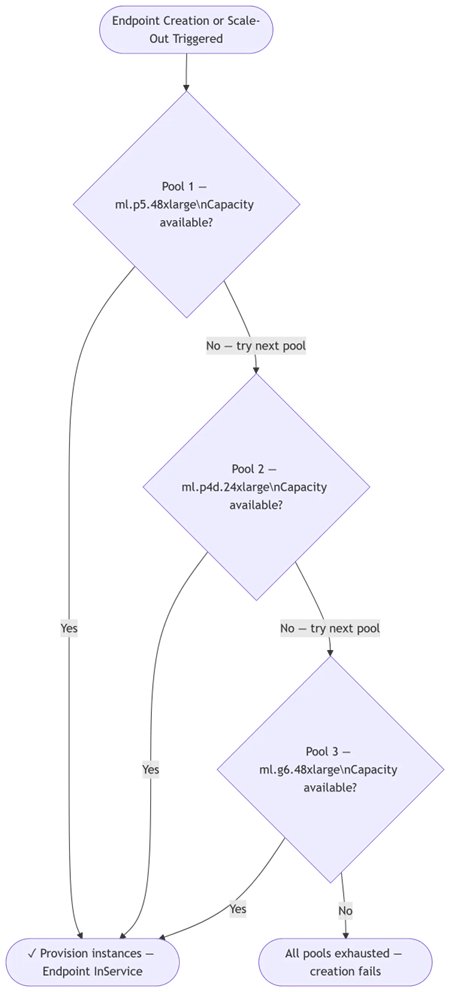
エンドポイントが立ち上がる:
SageMaker AI は最初の選択肢のインスタンスタイプを試します。キャパシティが利用できない場合、ただちに 2 番目の選択肢、次に 3 番目の選択肢を試します。手動でリトライする必要はありません。エンドポイントは数分以内に、最初に利用可能な AI インフラ上で InService に到達します。
エンドポイントが稼働し続ける:
Auto Scaling がトリガーされ、優先するインスタンスタイプが制約されている場合、SageMaker AI は優先順位リストの次に利用可能なインスタンスタイプでスケールアウトするため、トラフィックが流れ続けます。
フリートは優先ハードウェアに収束する傾向を持つ:
スケールイン時、SageMaker AI は最も優先度の低い (フォールバック) インスタンスから先に削除します。その後のスケールアウトイベントでは、再び最も優先度の高いタイプから試行します。優先するハードウェアが利用可能になるにつれて、フリートは時間とともに自然にそちらへ戻り、手動の介入は必要ありません。
すべてを可視化できる:
既存のすべての CloudWatch メトリクスに InstanceType ディメンションが追加されているため、1 つのエンドポイント内のインスタンスタイプごとに、レイテンシ、スループット、GPU 使用率、インスタンス数を追跡できます。
詳細については、Amazon SageMaker AI のドキュメント を参照し、GitHub のサンプルノートブック を試してみてください。
各インスタンスタイプに適切なモデルを当てる
フォールバック先のインスタンスタイプは、GPU メモリ、コンピュート性能、アーキテクチャが異なることがよくあります。高メモリのマルチ GPU インスタンス向けに最適化されたモデルが、より小さなシングル GPU のフォールバックで必ずしも動作するとは限りません。プールリスト内の各インスタンスタイプを、正しく構成されたモデルとマッチングさせる方法は 2 つあります。
オプション 1: 自分で最適化したモデルを持ち込む
ターゲットのインスタンスタイプがすでに分かっている場合、それぞれに対してモデルアーティファクトを準備します。プライマリのハイエンドインスタンスでは、複数 GPU にわたるテンソル並列を使うかもしれません。中位のフォールバックでは、推論を高速化するために投機的デコーディング (speculative decoding) を適用することが考えられます。最も優先度の低いフォールバックでは、メモリ予算に収めるために INT4 量子化を使うかもしれません。
各構成について個別の SageMaker AI モデルを作成し、それぞれの InstancePools エントリ (Single Model Endpoint の場合) またはインスタンスタイプごとの Specifications (InferenceComponent ベースのエンドポイントの場合) で、ModelNameOverride を使って参照します。SageMaker AI が優先度の低いプールにフォールバックすると、そのハードウェア用に準備したモデルがデプロイされます。
オプション 2: SageMaker AI 推論レコメンデーション機能を使う
各ハードウェアターゲットを手動で最適化するのが手間な場合は、SageMaker AI 推論レコメンデーション によってハードウェア固有の構成を生成できます。ベースモデルを与えると、投機的デコーディングや量子化などの技術を使って、ターゲットのインスタンスタイプ全体にわたる最適化された構成を SageMaker AI が生成します。
レコメンデーションジョブはターゲットのインスタンスタイプごとに 1 つの結果を返します。各結果には AIRecommendationModelDetails のレスポンス内に ModelPackageArn と InferenceSpecificationName が含まれており、それぞれ特定のハードウェア向けの構成を示しています。両方のフィールドを使って結果ごとに 1 つの SageMaker AI モデルを作成し、対応するプールエントリで ModelNameOverride を介して参照します。これはオプション 1 と同じパターンですが、最適化作業はサービス側が処理します。
MODEL_PACKAGE_ARN = "arn:aws:sagemaker:us-west-2:123456789012:model-package/MyModelPkgGroup/1"
# AIRecommendationModelDetails の両フィールドを使ってインスタンスタイプごとに 1 つのモデルを作成。
sm.create_model(
ModelName="my-llm-for-p5",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "p5-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
sm.create_model(
ModelName="my-llm-for-g6",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "g6-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
# その後、後述の「セットアップ」のとおり、プールエントリごとに ModelNameOverride で各モデルを参照する。
混在フリートでの Auto Scaling
Auto Scaling は、作成時に定義したのと同じ優先順位ロジックに従います。スケールアウトはまず最も優先度の高いプールを試し、キャパシティが利用できない場合は次のプールにフォールバックします。スケールインは最も優先度の低いインスタンスから先に削除し、フリートが縮小しても優先するハードウェアを温存します。
加重スケーリングメトリクスを構築する
フリートには異なるスループットキャパシティを持つインスタンスタイプが含まれているため、デフォルトの集約メトリクスは実際の使用状況を正しく表現できないことがあります。たとえば p5 インスタンスが 18 件の同時リクエストを処理し、g6 が 7 件処理しているとき、これらの生の数値を平均して 12.5 にしても、どちらのインスタンスタイプの負荷も正確には反映されません。
CloudWatch のメトリクス計算 (metric math) を使うと、タイプごとの使用率( per-type utilization ratios )に基づいた加重メトリクスを構築できます。各項はそのタイプで観測された並列実行数を最大キャパシティで割って、0.0 〜 1.0 の値を生成します。それらの比率を平均することで、TargetValue と同じ 0.0 〜 1.0 のスケールでフリートレベルの使用シグナルが得られます。TargetValue を 0.7 に設定すると、「フリート内のすべてのインスタンスタイプにわたる加重平均がキャパシティの 70% を超えたらスケールアウトする」という意味になります。
aas = boto3.client("application-autoscaling")
aas.put_scaling_policy(
PolicyName="weighted-utilization-scaling",
ServiceNamespace="sagemaker",
ResourceId="endpoint/my-heterog-endpoint/variant/primary",
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 0.7, # 加重フリート使用率が 70% を超えたらスケールアウト
"CustomizedMetricSpecification": {
"Metrics": [
{
"Id": "p5_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.p5.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "g6_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.g6.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "weighted_utilization",
# タイプごとの使用率比 = 観測値 / 最大キャパシティ、それを平均する
"Expression": "(p5_concurrency / 20 + g6_concurrency / 8) / 2",
"ReturnData": True,
},
],
},
},
)
この式の 20 と 8 は、各インスタンスタイプで測定された最大同時並列数です。この例では p5 は最大 20 リクエスト、g6 は最大 8 リクエストを処理します。これらの値は、負荷テストでお使いのモデルについて測定した最大値に置き換えてください。次の表は、トラフィックレベルごとにこのメトリクスがどう反応するかを示しています。
| トラフィックレベル | p5 リクエスト | g6 リクエスト | 加重使用率 | アクション |
|---|---|---|---|---|
| 低 | 5 | 2 | (0.25 + 0.25) / 2 = 0.25 | スケールイン |
| 中 | 12 | 5 | (0.60 + 0.63) / 2 = 0.61 | 維持 |
| 高 | 18 | 7 | (0.90 + 0.88) / 2 = 0.89 | スケールアウト |
| ターゲット付近 | 14 | 6 | (0.70 + 0.75) / 2 = 0.73 | ターゲット付近 — 維持 |
注: すべてのインスタンスタイプのスループットキャパシティが同程度のワークロードでは、既存のスケーリングポリシーを変更せずにそのまま使用できます。加重使用率メトリクスは、プールメンバーの GPU キャパシティが大きく異なる場合に最も価値を発揮します。
フリートをモニタリングする
既存のすべての CloudWatch メトリクスに InstanceType という新しいディメンションが追加されました。ModelLatency、ConcurrentRequestsPerModel、GPUUtilization、InstanceCount、InvocationsPerInstance を、1 つのエンドポイント内のハードウェアタイプごとに分解できます。各インスタンスタイプを独立して追跡するダッシュボードやアラームを構築できます。
DescribeEndpoint はプールごとの現在のインスタンス数を返すため、フリートの構成を常に把握できます。
response = sm.describe_endpoint(EndpointName="my-heterog-endpoint")
pools = response["ProductionVariants"][0]["InstancePools"]
# 出力例:
# [
# {"InstanceType": "ml.p5.48xlarge", "CurrentInstanceCount": 4},
# {"InstanceType": "ml.g6.48xlarge", "CurrentInstanceCount": 2},
# ]
トラフィックルーティング
インスタンスプールを使うエンドポイントでは、ProductionVariant の RoutingConfig を設定することで、Least Outstanding Requests (LOR) ルーティングを有効化することを推奨します。LOR は受信リクエストごとに、モデルコピーあたり処理中のリクエストが最も少ないインスタンスへルーティングします。キャパシティの大きいインスタンスはリクエストを高速に処理するためキューが速やかに解消され、定常状態では処理中のリクエスト数が少なく保たれます。これにより、手動の重み付け設定なしで、キャパシティの大きいインスタンスは自然に多くのトラフィックを受け取るようになります。
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"}
この設定がない場合、エンドポイントはデフォルトで RANDOM ルーティングを使用し、インスタンスの負荷に関係なくリクエストを均等に分散します。プールメンバー間でスループットキャパシティが大きく異なる場合、これは最適ではありません。詳細については、ProductionVariant API リファレンスの RoutingConfig を参照してください。
更新とロールバック
インスタンスプールは、Blue/Green デプロイ と ローリングデプロイ の両方をサポートしています。
Blue/Green デプロイ では、トラフィックを切り替える前に、同じ優先順位ベースのフォールバックロジックを使って、新しい (グリーン) フリート全体をプロビジョニングします。ヘルスチェックがパスしたらトラフィックがカットオーバーされます。失敗した場合は自動ロールバックによってブルーフリートが保持され、エンドポイントは終始 InService を維持します。
ローリングデプロイ では、設定可能なバッチ (一度に 5〜50% のインスタンス) でフリートを更新します。Blue/Green 全体ほどの追加キャパシティを必要としないため、特に大規模モデルや需要の高い GPU インスタンスタイプで価値があります。SageMaker AI は新しい各バッチをプロビジョニングする際に、優先順位ベースのフォールバックロジックを適用します。ベーキング期間中に CloudWatch のアラームが発火した場合、トラフィックは自動的にロールバックされます。設定の詳細は Use rolling deployments を参照してください。
前提条件
開始する前に、以下を確認してください。
sagemaker:CreateEndpointConfig、sagemaker:CreateEndpoint、sagemaker:UpdateEndpointの IAM 権限を持つ AWS アカウント- Amazon S3 にアーティファクトを持つ少なくとも 1 つの SageMaker モデル
- Boto3 1.43.1 以降 (Python SDK での
InstancePoolsサポートのため) - (任意) ターゲットのインスタンスタイプごとに最適化された個別のモデルアーティファクト、または SageMaker AI 推論レコメンデーション からの ModelPackage
SageMaker AI 推論エンドポイントのインスタンスプールサポートは、すべての商用 AWS リージョンで利用可能です。AWS マネジメントコンソール、AWS Command Line Interface (AWS CLI)、または AWS SDK から始められます。
インスタンスプールでエンドポイントを構成するワークフロー
インスタンスプールを構成する方法は 2 つあります。Amazon SageMaker AI で新規エンドポイントを作成する場合と、既存のエンドポイントを移行する場合の 2 通りです。
- 新規エンドポイントを作成する場合、以下の図がワークフローを説明します。
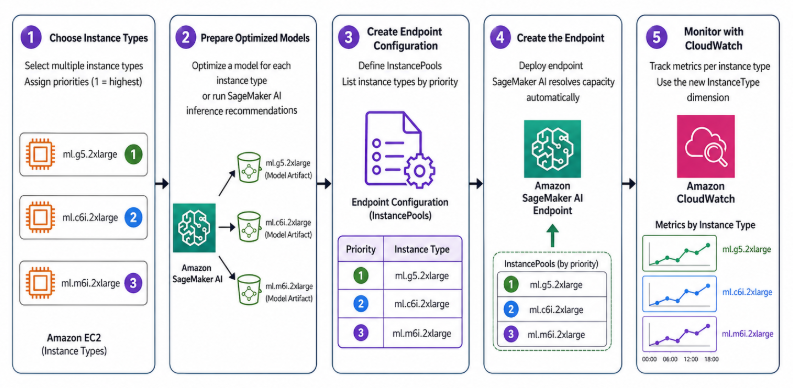
- インスタンスタイプを選択し、優先順位を割り当てる (1 が最高)。
- 各インスタンスタイプ向けに最適化したモデルを準備する、または SageMaker AI 推論レコメンデーションを実行して生成する。
- 優先順位を持つ
InstancePoolsをリスト化したエンドポイント設定を作成する。 - エンドポイントを作成する。SageMaker AI が自動的にキャパシティの確保を処理する。
- 新しい
InstanceTypeディメンションを使って、インスタンスタイプごとの CloudWatch モニタリングを設定する。
- 既存のエンドポイントを移行する場合、以下の図がワークフローを説明します。
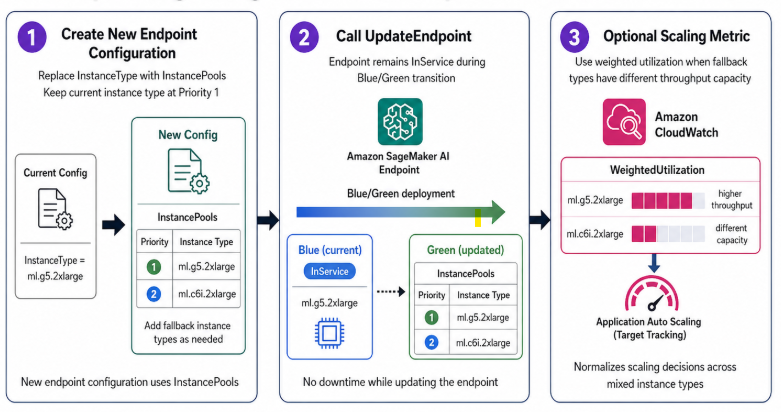
- 新しいエンドポイント設定を作成する。
InstanceTypeをInstancePoolsに置き換え、現在のインスタンスタイプをPriority: 1に保つ。 UpdateEndpointを呼び出す。エンドポイントは Blue/Green 移行中もInServiceを維持する。- フォールバック先のインスタンスタイプ間でスループットキャパシティが大きく異なる場合は、加重使用率スケーリングメトリクスを任意で追加する。
セットアップ
インスタンスプールの導入は、エンドポイント設定の 1 フィールドを変更するだけで済みます。ProductionVariant の単一の InstanceType フィールドを InstancePools リストに置き換えてください。モデル、スケーリングポリシー、モニタリングダッシュボードは変更なしで動作し続けます。
既存エンドポイントの移行
移行前: 単一インスタンスタイプ
import boto3
sm = boto3.client("sagemaker")
sm.create_endpoint_config(
EndpointConfigName="my-config",
ProductionVariants=[{
"VariantName": "primary",
"ModelName": "my-llm",
"InitialInstanceCount": 2,
"InstanceType": "ml.g6e.48xlarge", # 単一タイプ — キャパシティフォールバックなし
}],
)
移行後: 優先順位付きインスタンスプール
sm.create_endpoint_config(
EndpointConfigName="my-config-v2",
ProductionVariants=[{
"VariantName": "primary",
"ModelName": "my-llm",
"InitialInstanceCount": 2,
"VariantInstanceProvisionTimeoutInSeconds": 1200, # 後述の注を参照
"InstancePools": [
{"InstanceType": "ml.g6e.48xlarge", "Priority": 1}, # 現在のタイプ
{"InstanceType": "ml.g6.48xlarge", "Priority": 2}, # 同ファミリ、最初のフォールバック
{"InstanceType": "ml.p4d.24xlarge", "Priority": 3}, # より広いフォールバック
],
}],
)
Blue/Green 移行中もエンドポイントは InService を維持します。
sm.update_endpoint(
EndpointName="my-endpoint",
EndpointConfigName="my-config-v2",
)
注: VariantInstanceProvisionTimeoutInSeconds は、インスタンスプールサポートで導入された新しいフィールドです。プールからインスタンスを調達する全体の時間枠を設定します。SageMaker AI はこの時間枠の中で Insufficient Capacity エラーに対してリトライを続け、タイムアウト後に次のプールへ移ります。有効な範囲は 300 〜 3600 秒です。大規模 GPU インスタンスタイプでは、1200 秒が妥当な開始値です。このタイマーはインスタンス調達のみをカバーします。モデルダウンロードとコンテナ起動時間は、既存の ModelDataDownloadTimeoutInSeconds と ContainerStartupHealthCheckTimeoutInSeconds フィールドで個別に管理されます。インスタンスタイプごとに異なる最適化済みモデルをデプロイするには、任意のプールエントリに ModelNameOverride を追加します。モデル設定オプションは前のセクションで確認できます。
InferenceComponent ベースのエンドポイント
sm.create_inference_component(
InferenceComponentName="my-ic",
EndpointName="my-heterogeneous-endpoint",
VariantName="primary",
Specifications=[
{
"InstanceType": "ml.p5.48xlarge",
"ModelName": "my-model-p5-optimized",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 8,
"MinMemoryRequiredInMb": 65536,
},
},
{
"InstanceType": "ml.g6.48xlarge",
"ModelName": "my-model-g6-optimized",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 8,
"MinMemoryRequiredInMb": 32768,
},
},
],
RuntimeConfig={"CopyCount": 4},
)
非同期推論エンドポイント
非同期推論 エンドポイントでもインスタンスプールは同じように動作します。InstancePools の定義と並べて CreateEndpointConfig の呼び出しに AsyncInferenceConfig ブロックを追加するだけで、優先順位ベースのプロビジョニングとフォールバックロジックがそのまま適用されます。これは、インスタンス数 0 までスケールダウンする非同期ワークロードで特に有用です。エンドポイントが再びスケールアップしてキューイングされたリクエストを処理する際、SageMaker AI はまず最も優先度の高い利用可能なプールを使ってプロビジョニングし、手動介入なしで耐障害性のあるコールドスタート挙動を提供します。
まとめ
Amazon SageMaker AI Instance Pools は、推論エンドポイント向けにインスタンスタイプの優先順位付きリストを定義することを可能にし、SageMaker AI がその順序に基づいてキャパシティを自動的に管理します。
エンドポイント作成時、スケールアウト時、スケールイン時にわたって、SageMaker AI は優先するインスタンスタイプを順に処理するため、第 1 候補のハードウェアが利用できないときでもデプロイを手動でリトライする必要がありません。始め方は簡単です。エンドポイント設定の InstanceType を InstancePools に置き換えて UpdateEndpoint を呼び出します。既存のモデル、Auto Scaling ポリシー、モニタリングダッシュボードは大きな変更なしに動作し続けます。
インスタンスタイプごとの CloudWatch メトリクスと DescribeEndpoint からの詳細なプール数によって、どのインスタンスタイプがフリートを支えているかをリアルタイムに明確に把握できます。コスト最適化、GPU キャパシティ制約への対応、ゼロからコールドスタート可能な耐障害性の高い非同期パイプラインの構築など、どの目的であっても、インスタンスプールは運用負荷を抑えながら ML 推論をスムーズに動かし続けるための柔軟性と自動化を提供します。
この機能は本日から追加費用なしで利用可能です。実際にプロビジョニングされたインスタンスタイプに対しては、標準の単一タイプエンドポイントと同じ料率で課金されます。詳細については、Amazon SageMaker AI のドキュメント と GitHub のサンプルノートブック を参照してください。
著者について
 |
Kareem Syed-MohammedKareem Syed-Mohammed は AWS のプロダクトマネージャーです。SageMaker HyperPod 上での生成 AI モデル開発とガバナンスの実現に注力しています。それ以前は Amazon QuickSight で組み込み分析と開発者エクスペリエンスをリードしました。QuickSight に加えて、AWS Marketplace と Amazon Retail でもプロダクトマネージャーを務めてきました。Kareem はコールセンター技術の開発者としてキャリアをスタートし、Expedia の Local Expert と広告、McKinsey の経営コンサルタントとしての経歴を持ちます。 |
 |
Dmitry SoldatkinDmitry Soldatkin は AWS の SageMaker Inference におけるスペシャリストソリューションアーキテクチャのワールドワイドリーダーです。エンタープライズ全体にわたる生成 AI および AI/ML ソリューションの設計、構築、最適化を支援する取り組みを率いています。彼の仕事は幅広い ML ユースケースに及び、生成 AI、ディープラーニング、大規模な ML のデプロイメントに重点を置いています。金融サービス、保険、通信などの業界の企業と協業してきました。Dmitry とは LinkedIn でつながることができます。 |
 |
Johna LiuJohna Liu は Amazon SageMaker チームのソフトウェア開発エンジニアです。効率を高め新たな機能を可能にする AI/LLM 駆動のツールを構築し探求しています。仕事以外では、テニス、バスケットボール、野球を楽しんでいます。 |
 |
Xu DengXu Deng は SageMaker チームのソフトウェアエンジニアリングマネージャーです。Amazon SageMaker 上でお客様の AI/ML 推論体験の構築と最適化を支援することに注力しています。余暇には旅行とスノーボードを楽しんでいます。 |
 |
Mona MonaMona Mona は現在、Amazon でシニア AI/ML スペシャリストソリューションアーキテクトとして勤務しています。以前は Google でリード生成 AI スペシャリストとして働いていました。『Natural Language Processing with AWS AI Services: Derive strategic insights from unstructured data with Amazon Textract and Amazon Comprehend』および『Google Cloud Certified Professional Machine Learning Study Guide』の 2 冊の著者であり、AI/ML とクラウド技術に関する 19 本のブログを執筆、CORD19 Neural Search に関する研究論文の共著者として、権威ある AAAI (Association for the Advancement of Artificial Intelligence) カンファレンスで Best Research Paper 賞を受賞しています。 |
翻訳は Solutions Architect 片山洋平 が担当しました。原文はこちらです。