Amazon Web Services ブログ
Amazon Aurora DSQL の裏側:知っておくとおもしろい技術解説 Part 2 – 概要
本記事は 2025/11/25に投稿された Everything you don’t need to know about Amazon Aurora DSQL: Part 2 – Shallow view を翻訳した記事です。
このブログ記事シリーズでは基本的なデータベースの概念と、それらが Amazon Aurora DSQL にどのように適用されるかの概要から始めました。
この第2回の記事では、Aurora DSQL のアーキテクチャを検証し、その設計判断が機能(楽観的ロックや PostgreSQL の機能サポートなど)にどのような影響を与えるかを説明し、アプリケーションとの互換性を評価できるようにします。ユーザーから完全に抽象化されている基盤アーキテクチャの包括的な概要を提供します。リージョンエンドポイントのみを介して操作することで、ユーザーはサービスの機能に直接アクセスできます。サービスのアーキテクチャを理解することで、その潜在能力を戦略的に活用できるようになると私は確信しています。
サービス概要
Aurora DSQL は、オンライントランザクション処理(OLTP)ワークロード向けに特別に設計された最新のサーバーレス分散型 SQL データベースです。PostgreSQL 互換性を念頭に置いて構築され、その機能のサブセットを提供し、リージョン内およびリージョン間の両方で読み取りと書き込みトラフィックを処理できるピアとして、すべてのデータベースリソースが機能するアクティブ-アクティブデプロイメントモデルを採用しています。また、このサービスは実際のリソース消費量とデータストレージ要件に基づく従量課金制の価格モデルを採用しています。
このサービスは、同期データレプリケーションにより、単一リージョンおよびマルチリージョンクラスターの両方でデータ損失ゼロを実現し、読み取りに対して書き込み後の強い読み取り一貫性を提供します。
次の図は、Aurora DSQL インフラストラクチャの高レベルな概要を示しており、単一リージョン(左)とウィットネスリージョンを持つマルチリージョン(右)の同期クラスターのスケーラビリティを示しています。
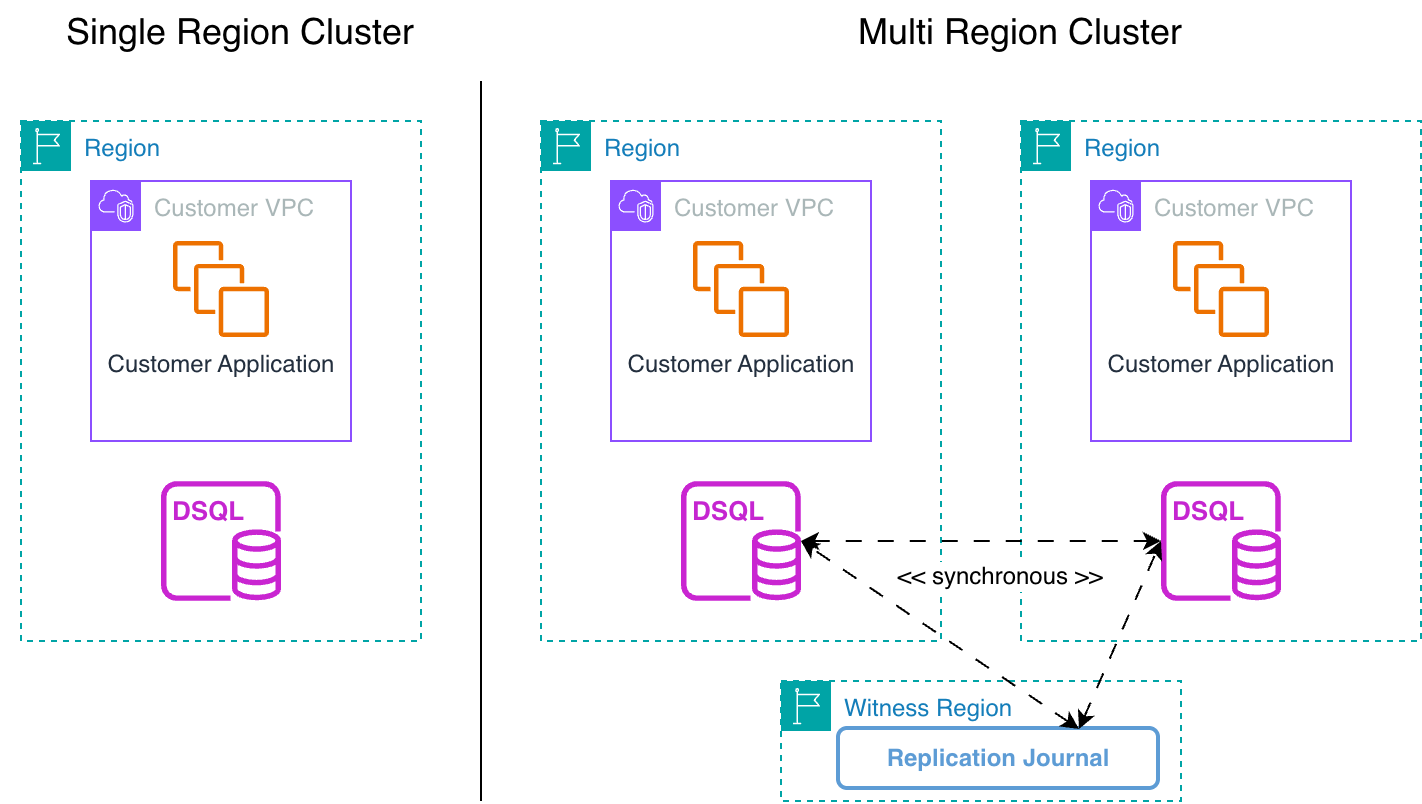
単一リージョンおよびウィットネスリージョンを持つマルチリージョン同期クラスターのスケーラビリティを示す Aurora DSQL インフラストラクチャの大まかな概要
単一リージョン構成では、コンピュート、トランザクションログ、ストレージの各層が3つのアベイラビリティーゾーンに分散配置された多層処理モデルで構成されており、高可用性を実現しています。アプリケーションは専用のエンドポイント経由でアクセスします。
マルチリージョン構成では、それぞれが単一リージョン構成と同じインフラストラクチャを持つ2つの同期リージョンに加え、ウィットネスリージョンと呼ばれる第3のリージョンで構成されています。ウィットネスリージョンは、トランザクションの合意形成に参加し、ネットワーク障害時におけるタイブレーカーとして機能します。
Aurora DSQL は、単一リージョン構成で 99.99% の可用性を提供し、マルチリージョン構成ではさらに高い可用性(99.999%)を実現できます。この高い信頼性を活用するためには単にサービスを複数のリージョンで稼働させるだけでは不十分で、アプリケーションが必要に応じて自動的にリージョン間を切り替えるよう設計されている必要があります。つまり、1つのリージョンで問題が発生した場合、アプリケーションは自動的に正常なリージョンに接続できることが重要です。これは非常用電源を持つのと似たような考え方で、複数の電源を用意するだけでなく、正常な電源への自動切り替え機能があってこそ真価を発揮します。この設計アプローチによって、1つのリージョンの障害が他に波及する相関障害を防ぎ、アプリケーションが稼働中のリージョンに接続できる限りサービス全体の停止を回避することが可能です。
Aurora DSQL の読み取り処理は実行元のリージョン内で完結するため、リージョン間のレイテンシーは完全に排除されます。書き込み処理では、コミット時にのみリージョン間レイテンシーが発生します。運用面では、Aurora DSQL はデータベース管理の簡素化とスケーラビリティ向上において複数のメリットを提供します。このアーキテクチャによって、コンピュート・コミット・ストレージの各層を独立してスケールできるため、ワークロードの要求に応じた精密なリソース配分が可能となります。これらの処理はすべてバックグラウンドで自動実行され、AWS が完全に管理するため、真のサーバーレス体験を実現しています。結果として、メンテナンスウィンドウが不要となり、運用負荷の軽減とシステムの可用性が向上します。
Aurora DSQL は他の AWS サービスと深く統合されており、アクセス制御のための AWS Identity and Access Management(IAM)や監査ログのための AWS CloudTrail などのサービスとの連携を容易にします。
Aurora DSQL アーキテクチャ
Aurora DSQL は、Firecracker 仮想化など、多数の Amazon のイノベーションを活用した新しい分散データベースシステムです。DSQL の設計では、コンピュートやストレージなどの単一インスタンスデータベースコンポーネントを、厳密に定義された仕様によって連携を確保しつつ、特定のタスクに集中できる疎結合なマルチテナントフリートとして再構築することで複雑さを削減しています。各コンポーネントは、それぞれのドメインにとって最適な設計判断を行います。これは次の3つの基本的な特性に沿っています:
- 各コンポーネントが独立して変更と改善を行う
- コンポーネントは個別にスケールする
- 各コンポーネントに対して異なるセキュリティ分離の決定が行われる
Amazon Aurora DSQL の最も重要なコンポーネントは次の通りです:クエリプロセッサ(QP)は各接続専用の PostgreSQL エンジンとして機能し、SQL の処理のほとんどをローカルで処理し、読み取りに応じてデータを返し、トランザクションがコミットされるまで書き込みデータをスプールします。アジュディケータは読み書きトランザクションがコミットされるかどうかを決定し、分離を確保するために他のアジュディケータと通信します。ジャーナルはコミットされたトランザクションを永続化し、アベイラビリティゾーン間、マルチリージョン構成ではリージョン間で、データを複製する順序付けられたデータストリームです。クロスバーはジャーナルからのデータストリームをマージし、ストレージにルーティングします。ストレージノードはデータへのアクセスを提供し、シャードキーに基づいてデータを保存します。また、データの複数の読み取りレプリカも含んでいます。
以下の図は、書き込みパス(実線)と読み取りパス(点線)を明確に示し、異なるアクセスパターンに対してシステムが最適化できる能力を強調しています。
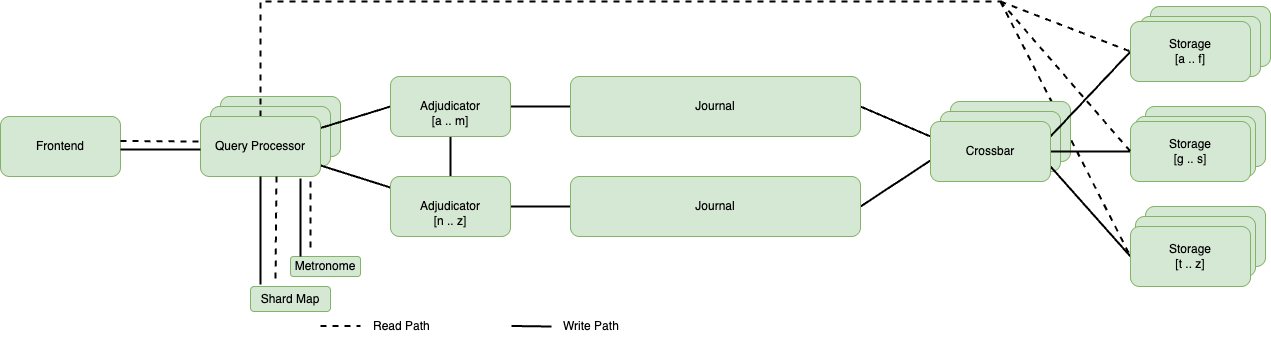
Amazon Aurora DSQL 内のデータ処理ワークフローを示すシステムアーキテクチャ図
フロントエンドはトランザクションとセッションのルーターとして機能し、各接続を独自のクエリプロセッサにルーティングします。QP は SQL クエリを実行し、読み取りに応じて対応するデータを返す責任があり、時間ベースの分離と調整を通じて一貫した処理を提供するためにメトロノーム(タイミングコンポーネント)と連携します。QP はローカルのシャードマップを参照して、どのキーがストレージ(読み取り用)とアジュディケータ(読み書きトランザクションのコミット用)のどこに配置されているかを判断します。また、書き込みに応じてデータをバッファし、トランザクションプロトコルを管理します。Amazon Aurora DSQL のトランザクションは最大300秒(ハード制限)で、この期間を超えるトランザクションは拒否されます。特筆すべきは、QP が他の QP と通信することはなく、ディスクページではなく行を要求することです。Amazon Aurora DSQL は、パフォーマンス向上と QP に戻るデータ通信を削減するために述語をストレージにプッシュダウンします。これは、フィルタリング、集約、射影などの重要な処理の多くがストレージレイヤーで実行されることを意味します。各トランザクションは独自の QP を受け取り、水平方向にスケーリングが可能になり、各トランザクションが他のトランザクションに影響を与えたり、影響を受けたりすることなく独自のコンピュートリソースを確保できます。Aurora DSQL 内のコンピュートスタックは QP のみで構成されています。
コミット時に、QP はトランザクションをアジュディケータに提出し、アジュディケータは楽観的同時実行制御プロトコルを実行します。アジュディケータは特定のキー範囲を割り当てられ、複数のキーセットに影響するトランザクションについてピアと調整します。彼らはトランザクションが自分のシャード内でコミットできるかどうかを判断し、必要に応じて協力します。マルチリージョンクラスターでは、アジュディケータはすべてのリージョン間で競合する書き込みを検出します。このアプローチは楽観的同時実行制御を使用し、検証フェーズまでロックを取得せずにトランザクションを進行させます。これは分散システム全体でのデータ一貫性を維持しながら、同時操作を管理します。トランザクションの終わりに競合をチェックすることで、この方法はダーティリードやロストアップデートなどの問題を防ぎ、競合がまれなシナリオに特に適しています。
ジャーナルはコミットされたトランザクションを永続化する順序付けられたデータストリームであり、クライアントに書き込みを確認します。Amazon Aurora DSQL 内のコミットスタックはアジュディケータとジャーナルで構成され、各ジャーナルは単一のアジュディケータに排他的に関連付けられています。
クロスバーはジャーナルストリームを時系列順にマージし(ジャーナルがトランザクション順にコミットを保存するのとは対照的に)、ストレージに書き込みを発行します。
ストレージは複数のストレージノードで構成され、データは主キーに基づくレンジパーティショニングによってノード間に分散されています。ストレージノードは読み取りを提供するために存在し、短期的な耐久性については責任を負いません。ストレージは、ノード上のキーに対する大量の読み取りリクエストに対応するため、そのノードの読み取り専用レプリカを作成する場合があります。
アーキテクチャに基づく Aurora DSQL のメリット概要
以下は、この分散アーキテクチャを通じて得られるメリットの概要です(完全なリストではありません):
- Aurora DSQL は、同期データレプリケーション、スナップショット分離、アトミック性、アベイラビリティーゾーン間およびリージョン間の耐久性により、強力な一貫性を持つ原子性、一貫性、独立性、永続性(ACID)トランザクションを提供します。
- Aurora DSQL は snapshot isolation とロックフリーの同時実行制御を実装しています。このアプローチの主な利点の1つは、読み取り専用トランザクションが強力な一貫性を維持しながらも、アベイラビリティーゾーン間やリージョン間のレイテンシーを発生させないことです。
- 書き込みトランザクションは、コミット時にリージョン間レイテンシーの往復時間(RTT)を2回発生させます。レイテンシーはステートメントごとではなくトランザクションごとに発生するため、ステートメントの数は関係ありません。
- コミット前に発生するすべての処理は QP 内でローカルに行われ、各接続が専用のQPリソースを持つことで、処理の遅いクライアントが他のクライアントに影響を与えることはありません。
- Aurora DSQL 内の各コンポーネントは、それぞれが受け取る個別のタスクに特化して設計されており、各コンポーネントが独立してスケールし、個別にシャーディングすることができます。これによってデータベースはさまざまな読み取り/書き込み、コンピューティング-読み取り、コンピューティング-読み取りの比率に対して動的に適応します。
- コンポーネントは独立してデプロイされ、複数のステートレスホストに分散されています。必要に応じてホスト間で移動を行うため、顧客に影響を与えず、メンテナンスウィンドウを必要としません。
Aurora DSQL を使用する際の考慮事項
Aurora DSQL は PostgreSQL 互換の分散データベースで、事実上無制限のスケールと高可用性を提供します。PostgreSQL 互換ではありますが、Aurora DSQL は現在 PostgreSQL で利用可能なすべての機能を提供しているわけではありません。この機能差異は時間と共に解消されていく予定ですが、Aurora DSQL の分散アーキテクチャの特性上、一部の機能は異なる実装となります。サポートされている PostgreSQL 機能セットについては、Aurora DSQLのドキュメントで透明性をもって公開されており、アプリケーション要件との適合性を事前に確認することができます。その結果、PostgreSQL の実績ある基盤と先進的な分散コンピューティング機能を組み合わせたデータベースが提供され、アプリケーションの将来の成長とスケール要求に対応できます。
Aurora DSQL のためにワークロードを設計する際は、以下の要素を考慮してください(完全なリストではありません):
- Aurora DSQL は楽観的同時実行制御のため、ロックを実装していません。アプリケーションが明示的なデータベースロックを実装するロジックに依存している場合、アプリケーションの一部を再構築する必要があるかもしれません。詳細については、Amazon Aurora DSQL の同時実行制御を参照してください。
- このサービスは3つ以上の読み書きエンドポイントを持つマルチリージョン構成をサポートしていません。つまり、3つ以上のリージョンでデータを同期的に複製する必要があるユースケースをサポートしていません。
- Aurora DSQL は、2つの重要な設計原則に従うことで最も効果を発揮します:ホットキー書き込みとホットキー範囲の回避です。Amazon Aurora DSQL ではテーブルにランダムな主キーを定義することが理想的です。これは UUID に基づく単一キーか、または複数の列を組み合わせた高いカーディナリティを持つ複合キーを意味します。
- 楽観的同時実行制御を採用しているため、複数のトランザクションが同時に同じデータを変更しようとする場合(ホットキーの書き込み)、1つが成功し、他は再試行しなければならないことを意味します。
- 同様に、特定のキー範囲内に操作を集中すること(ホットキー範囲)は、DSQL の分散アーキテクチャが損なうことになります。
- マルチリージョン構成で読み書き操作の強力な一貫性を保証するため(読み取り専用操作は対象外)、Aurora DSQL はコミット時に2往復分(2 RTT)の追加レイテンシーが発生します。このレイテンシーは選択した2つのリージョン間の物理的距離に比例して増加します。
これらの原則に沿って設計することで、Aurora DSQL の大きなメリットを最大限に活用でき、データ要件の拡大に対応した成長と安定したパフォーマンスを実現する基盤を築くことができます。
まとめ
この投稿では、Amazon Aurora DSQL のアーキテクチャと、そのアーキテクチャへの貢献、メリット、およびサービスを使用する上での考慮事項について探りました。次回の投稿では、Aurora DSQL のエンドツーエンドのトランザクション処理機能について詳しく掘り下げていきます。