Amazon Web Services ブログ
Amazon Aurora DSQL の裏側:知っておくとおもしろい技術解説 Part 4 – DSQL のコンポーネント
本記事は 2025/11/25 に投稿された Everything you don’t need to know about Amazon Aurora DSQL: Part 4 – DSQL components を翻訳した記事です。
Amazon Aurora DSQL は、アクティブ-アクティブの分散データベース設計を採用しており、リージョン内およびリージョン間で、すべてのデータベースリソースが等しく読み取りと書き込みの両方のトラフィックを処理します。この設計により、シングルおよびマルチリージョンの Aurora DSQL クラスターにおいて同期データレプリケーションとデータ損失ゼロの自動フェイルオーバーが可能になります。
この Aurora DSQL に関するブログシリーズでは、基本的な概念を説明し、機能と注意点を探り、トランザクションの動作を分析してきました。この記事では、 ACID 準拠で強力な一貫性のあるリレーショナルデータベース機能を提供する、マルチリージョン分散データベースの各コンポーネントとその責務について説明します。
5 部構成の本シリーズの第 2 回のブログ記事では、Aurora DSQL の基本的なコンポーネントを示す次の図を紹介しました。この記事では、各コンポーネントをより詳細に見ていきます。主題に関して包括的に理解するために、第 2 回の記事の対応セクションを再確認することをお勧めします。以下の図は、Aurora DSQL 内のデータ処理ワークフローを示すシステムアーキテクチャ図です。
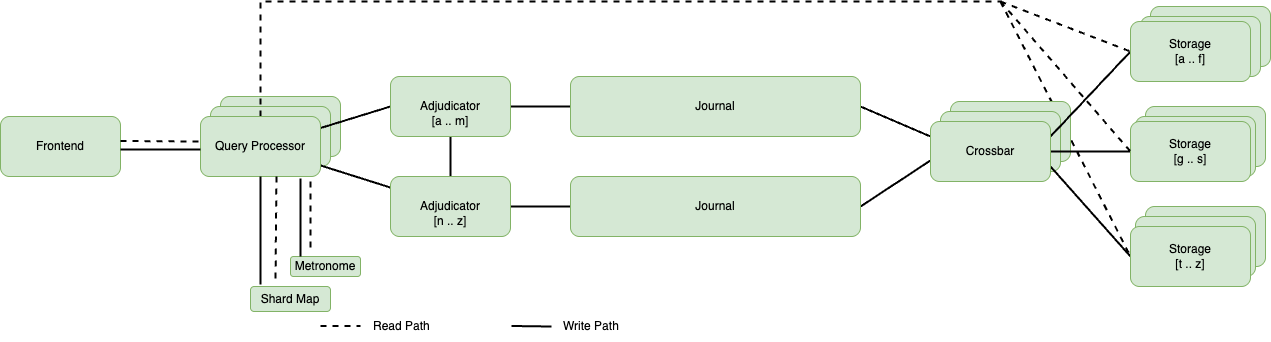
Amazon Aurora DSQL 内のデータ処理ワークフローを示すシステムアーキテクチャ図
クエリプロセッサ(QP)は、SQLの実行ライフサイクル全体を統括します。入力された SQL 文を解析し、実行計画を構築し、実行計画の処理を最適化します。QP はデータの取得を管理し、結果をマージし、クライアントに結果セットを返す前に必要な集計を行います。トランザクション処理中、読み取りセットと書き込みセットの両方を追跡し、トランザクションがコミットまたはロールバックするまで一時的に書き込みをスプールします。トランザクション完了時には(前回の記事で説明したように)、QP は COMMIT プロトコル全体を調整し、他のシステムコンポーネントとの適切な連携を提供します。
QP は一時的で、ソフトステート特性を持つシェアードナッシングのコンポーネントとして設計されています。したがって、耐久性、一貫性の強制、同時実行制御、耐障害性、スケールアウト操作などの従来のデータベース機能の多くを担当していません。これらの機能は、Aurora DSQL アーキテクチャ内の他のコンポーネントによって処理されます。インフラストラクチャの観点からは、QP は QP ホスト上の Firecracker マイクロ仮想マシン(microVM)内で動作し、各ホストが複数の QP をサポートしています。各トランザクションは単一の専用 QP によって処理されます。データベースごとに専用の QP プーラーが、接続とアクティブな QP のマッピングを管理し、厳密なデータベース分離を維持しながら効率的なリソース使用を提供します。
Aurora DSQL は、データベースカタログとメタデータに対してのみキャッシングを使用し、データキャッシングを完全に避けるという設計上の決定をしています。データベースは通常、次の3つの主要な課題に対処するためにキャッシュを使用することを考えると、この設計上の決定は直感に反するように見えるかもしれません:
- メモリアクセスと比較して高いストレージレイテンシー
- BTree などのデータ構造に対する複数のアクセスポイントの必要性
- I/O ラッチによるクラッシュ一貫性を維持する要件
しかし、Aurora DSQL はこれらの課題に異なる方法で対処しています。このアーキテクチャは、QP がロックを保持せずに動作し、ストレージフリートの配置とパフォーマンスが最適化され、ラウンドトリップを最小限に抑えるために処理がプッシュダウンされるなど、いくつかの利点を提供します。この革新的なアプローチにより、キャッシングメカニズムを必要とせずに、あらゆる規模で一貫したパフォーマンスを実現しています。
Aurora DSQL の QP は、単一トランザクション処理モデルで動作します。データウェアハウスシステムとは異なり、クエリは複数のプロセッサに分散されるのではなく、単一の QP 内で実行されます。つまり、すべてのクエリ実行は QP で行われ、遅いクライアントがデータベースを遅くしたり、他のクライアントに影響を与えたりすることはありません(ノイジーネイバー問題はありません)。
アジュディケータ
Aurora DSQL のアジュディケータシステムは分散コンポーネントとして機能し、複数のアジュディケータがデータベース全体で責任を共有しています。各アジュディケータは特定のキー範囲を所有しています。このシャーディングアプローチにより、単一のアジュディケータがボトルネックになることはなく、システムが複数のリージョンにわたってスケールすることが可能になります。
アジュディケータは、障害やパーティション発生時に一貫性を維持するために、高度なリースベースのシステムを実装しています。アジュディケーターがキー範囲の責任を引き受ける際、ジャーナルに対してリースを取得し、定期的なハートビートを通じてそれを維持します。このリースシステムにより、任意の時点で任意のキーに対して権限を持つアジュディケータは正確に1つだけとなり、障害シナリオ中の競合する決定を防止します。
これらのメカニズムを通じて、アジュディケータシステムは分散データベースシステムのスケーラビリティと信頼性の要件を維持しながら、堅牢な一貫性保証を提供します。
ジャーナル
ジャーナルは Aurora DSQL アーキテクチャにおいて重要なコンポーネントとして機能し、データベースの耐久性の実装を根本的に再構築しています。従来のデータベースではストレージ層が耐久性の責任を担っているのに対し、Aurora DSQL ではこのタスクをジャーナルに委任しています。このアーキテクチャの選択により、機能を分離することでデータベースエンジンが大幅に簡素化されています。トランザクションはジャーナルにコミットされるとコミット済みとみなされ、トランザクション処理と耐久性保証の間に明確な境界を確立します。ジャーナルは単に操作や変更をログに記録するのではなく、トランザクションの包括的なポストイメージを保存します。このアプローチは、より大きなストレージ容量を必要とする一方で、いくつかの利点を提供します:
- 予測可能な回復操作を容易にします。
- ストレージノードの処理を最適化します。
- レプリケーション中の計算オーバーヘッドを最小限に抑えます。
ジャーナルは、高いスループットを管理するために複数のジャーナルが並列処理を行う洗練されたスケーリングモデルを採用しています。アジュディケータによって保証される順序のおかげで、トランザクションは利用可能な任意のジャーナルに書き込むことができます。コミットするアジュディケータと同じアベイラビリティーゾーン内のジャーナルを選択することで、パフォーマンスを最適化することができます。
ジャーナルはリカバリ機能を提供するために、Amazon Simple Storage Service(Amazon S3)にスナップショットのデータを保存します。システムは定期的にスナップショットを取得し、ストレージの完全な状態を記録します。リカバリ時には、システムは最新のスナップショットをロードし、その時点からジャーナルを再生します。このアプローチにより、トランザクション履歴全体を再生することなく耐久性保証を維持することができます。
クロスバー
Aurora DSQL のジャーナルコンポーネントは、システム内の仲介役として機能するクロスバーコンポーネントにトランザクションデータを提供します。クロスバーは複数のジャーナルからのデータを完全に順序付けられたシーケンスにマージし、適切なストレージシャードにデータを配布します。重要なのは、クロスバーが操作を開始する前に、特定のタイムスタンプまですべてのジャーナルが処理を完了するのを待つ必要があることです。
クロスバーは高度なファンアウトメカニズムとして機能し、部分的に順序付けられたシステム内のすべてのジャーナルをサブスクライブして、完全に順序付けられ統合されたトランザクションのストリームを生成します。その主な責任は、キー範囲に基づいて原子的なトランザクションを分解し、各ストレージノードに割り当てられたキー空間に該当するデータのみを受け取るようにすることです。このターゲットを絞った配信により、システム効率が大幅に向上し、冗長なデータ転送が最小限に抑えられます。
クロスバーの主要な機能の1つは、ストレージノードへのデータ配信のタイミングを管理することです。監視するすべてのジャーナルで特定のタイムスタンプを確認した後にデータを転送します。この同期メカニズムは一貫性を提供しますが、潜在的なレイテンシーの課題をもたらします。これに対処するため、システムはすべての関連ジャーナルでデータが利用可能になると進む最低水準(low-water mark)を採用しています。
クロスバーは、イレイジャーコーディングを使用した革新的なテールレイテンシー削減アプローチを実装しています。このシステムでは、アジュディケータがメッセージを M 個のセグメントに分割し、元のメッセージは任意の k 個のセグメント( k は M 以下)から再構築できます。これらのセグメントは複数のジャーナルに分散され、クロスバーは任意のメッセージの k 個のセグメントを受信した後に処理を進めることができます。この設計はスケーラビリティと耐障害性の両方を提供します。
これらのメカニズムを通じて、クロスバーはジャーナルとストレージノード間のデータフローを調整するという複雑なタスクを、一貫性とパフォーマンスを維持しながら管理します。この全体設計は Aurora DSQL のスケーラビリティと信頼性に貢献しています。
ストレージ
Aurora DSQL のストレージ層は、データの永続性と取得のための基盤として機能し、従来のデータベースストレージシステムとは大きく異なります。その主な機能は、長期的なデータ耐久性の提供とデータクエリの実行であり、すべて複数のコンポーネントにわたって機能を分離するユニークなアーキテクチャフレームワーク内で行われます。
書き込み操作はシステムを通じて独自の経路をたどり、ジャーナルから始まり、データを適切なシャードに分割するクロスバーを経由します。その後、データはストレージノードに到達し、アプライヤーがそれをストレージシステムに取り込みます。対照的に、読み取り操作はより直接的な経路を採用し、効率性を高めるために中間コンポーネントをバイパスして QP からストレージに直接流れます。
即時の耐久性(これはジャーナルの担当範囲)を処理する代わりに、ストレージ層は Amazon S3 に保存される定期的なスナップショットを通じて長期的な耐久性に焦点を当てています。これらのスナップショットは複数の重要な機能をサポートします:
- 障害後の回復
- スケーリング操作
- インデックスの作成
- ポイントインタイムリカバリを含むバックアップと復元機能
ストレージシステムは、水平トリムの概念(古いものから時系列順に処理する)に基づくガベージコレクションメカニズムを実装しており、最大トランザクション時間に対応するアジュディケータの 5 分の最低水準に合わせています。このアプローチにより、各コンポーネントはローカル時間に基づいて独自のガベージコレクションを管理でき、複雑な連携の必要性が排除されます。
ストレージノードの障害が発生した場合、システムはパーティションメンバーを他のストレージノードに再分配し、スナップショットを使用してシステムの状態を復元します。このアプローチは、ジャーナルの短期的な耐久性保証と組み合わさることで、高可用性とデータ耐久性の両方を提供します。
ストレージ層の設計は、Aurora DSQL が同時実行制御などの従来のデータベース機能を特化したコンポーネントに委任しながら、堅牢なデータ管理を重視していることを反映しています。
まとめ
この記事では、Amazon Aurora DSQL の個々のコンポーネント、その処理メカニズム、そしてユニークな特徴について紹介しました。さらに、システム内での責任の分散についても説明しました。次の記事では、Aurora DSQL 内のクロックの概念について説明します。