Amazon Web Services ブログ
AWS COVID-19 パブリックデータレイクの探索
AWS COVID-19 のデータレイク — 新型コロナウイルス (SARS-CoV-2) とこれに関連する病気である COVID-19 の広がりおよび特性についての、またはそれに関する最新のデータセットが収集され、一元化されたリポジトリが現在利用可能になりました。詳細については、COVID-19 データの分析用のパブリックデータレイクをご参照ください。世界的には、このデータを収集するためにいくつかの取り組みが進行中であり、AWS はパートナーと協力して、この重要なデータを自由に利用できる状態にし、最新の状態に保てるように尽力しています。
このデータは、質問、独自のデータセットとの混合、独自のデータレイクへの新しい洞察の取り込みを行うためにすぐに利用できます。AWS は、パンデミック監視手法の開発研究を行うノースウェスタン大学をサポートしています。医療情報学博士号取得候補者の Ariel Chandler は、次のように述べています。「AWS COVID-19 データレイクを使用すれば、公開データに簡単にアクセスできるので、誰もがすぐに使えるはずの情報にアクセスするために手間をかける必要がなくなりました。AWS Data Exchange とこれらの処理ツールにアクセスすることにより、州全体にまたがる COVID-19 の拡散を追跡、報告、視覚化して、イリノイ州の公衆衛生への対応を支援しています。データレイクは、消費者や場所のデータを含む幅広いデータソースを使用して、どのコミュニティが最も危険にさらされているかを通知します。その情報は、この危機の最中に最も情報を必要とする人々に対して医療サービスや社会サービスを提供するために使用されます」
また、情報をクエリしてそれらの洞察をデータレイクに公開する新しい方法を作成することもできます。データは、公開ウェブサイト、AWS Data Exchange のデータプロバイダーを介して購入したデータ、または内部システムから取得される場合があります。
この記事では、Amazon SageMaker または Jupyter を介して AWS Glue データカタログから AWS COVID-19 データレイクにアクセスし、オープンソースの AWS Data Wrangler ライブラリを使用する方法について説明します。AWS Data Wrangler は、Pandas ライブラリの機能を AWS に拡張し、DataFrames と AWS データ関連サービス (Amazon Redshift、Amazon S3、AWS Glue、Amazon Athena、および Amazon EMR など) を接続するオープンソースの Python パッケージです。このデータレイクを使用して構築できる対象については、GitHub で公開されている関連 Jupyter ノートブックを参照してください。
この投稿のデータは次のソースからのものです。
- Enigma – グローバルコロナウイルス (COVID-19) データ (ジョンズ・ホプキンズ) – COVID-19 データレイク経由でアクセス
- Rearc – 米国の病院のベッド– COVID-19 | Definitive Healthcare – COVID-19 データレイクを介してアクセス
- Foursquare – COVID-19 徒歩移動データ – AWS Data Exchange 経由でアクセス
このデータレイクは、パブリックに読み取り可能な Amazon S3 バケットのデータで構成されています。COVID-19 データの選択については、研究開発で利用可能な COVID-19 に関連するデータを参照してください。データ製品をサブスクライブする手順については、AWS Data Exchange – データ製品の検索、サブスクライブ、および使用を参照してください。
ソリューションの概要
このチュートリアルには、次の手順が含まれます。
- AWS CLI のインストール
- Amazon SageMaker の構成
- データカタログを介してデータを探す
また、4 つの分析とその視覚化資料についても調べます。
- 国レベルの変化率
- 公共の場所には徒歩で移動する
- 症例数が病院のベッド数に与える影響
- 人口密度が病院のベッド数に与える影響
前提条件
この投稿は、AWS CloudFormation テンプレートを使用してデータへのアクセスを設定していることを前提としています。手順については、COVID-19 データの分析用のパブリックデータレイクをご参照ください。
また、以下を実行するアクセス許可を持つ AWS アカウントへのアクセス権も必要です。
- CloudFormation スタックを作成する
- AWS Glue リソースを作成する (カタログデータベースとテーブル)
- Amazon SageMaker ノートブックを起動する
AWS CLI のインストール
最初のステップでは、AWS CLI をインストールして、us-east-2 リージョン用に構成します。ここに COVID-19 パブリックデータレイクが存在します。
Jupyter でローカルに作業する場合は、Python パッケージをインストールするための仮想環境をセットアップする必要があります。次の Python パッケージがインストールされていることを確認してください: plotly、pandas、numpy、および awswrangler。
Amazon SageMaker の構成
Amazon SageMaker を構成するには、次の手順を実行します。
us-east-2で Amazon SageMaker ノートブックインスタンスを作成します (COVID-19 データの分析用のパブリックデータレイク記事で作成したデータベースとテーブルはそのリージョンにあります)。- ノートブックインスタンスに使用する IAM ロールを記録します。
- ノートブックインスタンスに割り当てられた IAM ロールを変更して、ポリシー
AmazonAthenaFullAccessおよびAWSDataExchangeSubscriberFullAccessを追加します。 - 新しいノートブックインスタンスに Jupyter ノートブックを作成します。
次の Python パッケージがインストールされていることを確認してください: plotly、pandas、numpy、awswrangler。外部 Python パッケージのインストールについては、ノートブックインスタンスに外部ライブラリとカーネルをインストールするを参照してください。
データカタログを介してデータを探す
CloudFormation スタックがステータス CREATE_COMPLETE を表示すると、テンプレートが作成したテーブルを表示できます。これで、データとその視覚化資料を探索する準備が整いました。この投稿では、視覚化資料の例を 4 つ紹介します。
国レベルの変化率
Enigma – グローバルコロナウイルス (COVID-19) データ (ジョンズ・ホプキンズ) は、1 日あたりの世界の症例数、回復者数、および死亡者数を追跡します。データソースには、世界保健機関 (WHO)、米国疾病対策予防センター (CDC)、中華人民共和国国民健康委員会 (NHC) が含まれます。データはジョンズ・ホプキンズ大学によって収集され、ESRI Living Atlas チームによってサポートされています。
このデータを使用して、1 日における米国の郡別感染人口の増加率を視覚化できます。たとえば、郡の人口が 1,000 人で、月曜日から火曜日までの感染人口が 10 人から 100 人に増えた場合、その感染人口の割合は 1% から 10% に増加します。
次の視覚化資料は、2020 年 3 月 29 日から 2020 年 3 月 30 日までのニューヨーク州とその周辺地域における感染人口の割合の増加を示しています。郡の色が黄色になるほど、感染病例数が大きくなります。灰色の郡では 3 月 29 日から 3 月 30 日までの増加が 0.01% 未満でした。

次の視覚化資料は、ニューヨーク州を拡大したものです。黄色の郡はニューヨーク州 (マンハッタンの自治区) では、3 月 29 日から 3 月 30 日までに COVID-19 の感染人口が 0.23% 増加しています。東側にある青色の州はナッソー州とサフォーク州で、それぞれ 0.07% と 0.05% 増加しています。ニューヨーク州の北にある青緑色の州はウェストチェスター州で、0.08% 増加しています。

付属のノートブックでは、日付パラメータを変更してさまざまな増加率を視覚化し、マップ全体をズームアウトして米国全体を視覚化できます。
公共の場所には徒歩で移動する
Foursquare – COVID-19 徒歩移動データは、2020 年 2 月 19 日以降、別々の大都市圏でのさまざまな場所 (空港、ジム、食料品店など) への徒歩移動の変化を示す、匿名化されたパーセンテージデータセットです。次の視覚化資料を取得するには、AWS Data Exchange からデータをダウンロードし、Amazon SageMaker ノートブックを使用して視覚化します。
次の視覚化資料は、徒歩移動データを使用して、2 月 19 日以降にさまざまな場所への徒歩移動の変化を示しています。このプロットは、ショッピングモール、衣料品店、カジュアルダイニングチェーン、および空港への公共交通量が 3 月 13 日の国家緊急事態宣言の後に急激に減少したことを示しています。一方、同期間の食料品店、倉庫、ドラッグストアへの交通量は急増しています。
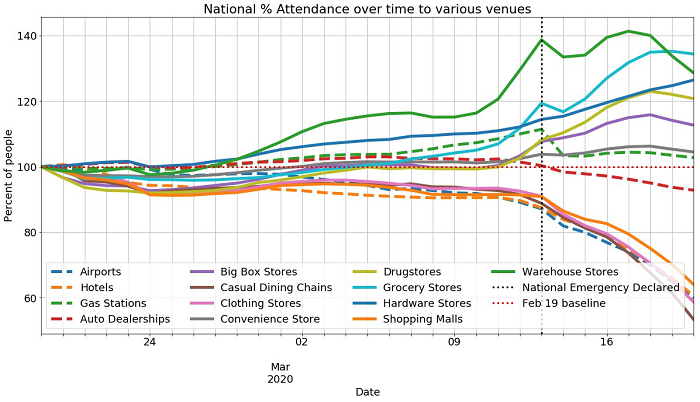
ニューヨーク、サンフランシスコ/オークランド、ロサンゼルス、シアトルなどのさまざまな大都市圏、およびノートブックが付属する 19 ヵ所の各場所で同様のプロットを作成できます。
症例数が病院のベッド数に与える影響
次の視覚化資料では、Enigma – グローバルコロナウイルス (COVID-19) データ (ジョンズ・ホプキンズ) および Rearc – 米国の病院のベッド数 – COVID-19 | Definitive Healthcare を使用して、COVID-19 症例の増加が地元の病院に及ぼす影響を分析しています。病院のベッドのデータセットは、米国の病院のベッド数、スタッフのベッド数、ICU ベッド数、およびベッド使用率のデータセットです。
最初のプロットは、ニューヨーク州での 10 日間の入院患者数の増加を示しています。入院症例は入院率 10% で計算されます。つまり、マンハッタンの COVID-19 症例の 10% が入院しているという意味です。付属のノートブックでは、入院率がパラメータになっているため、さまざまな入院率がそれぞれの医療ニーズにどのように対応しているかを視覚化できます。このプロットを生成するには、ジョンズ・ホプキンズによって毎日発表される COVID-19 症例情報を使用して入院症例数をシミュレートし、Definitive Healthcare 病院ベッドデータを使用してマンハッタンの総合病院のキャパシティーを計算します。

2 番目の視覚化資料は、米国全体の郡別病院使用率を示しています。州の色が黄色いほど、その医療リソースに COVID-19 入院率の 20% がかかります。灰色の州の入院率は 5% 未満です。

以前の視覚化資料と同様に、付属のノートブックでさまざまな入院率をシミュレートして、COVID-19 が全国の医療リソースにどのように負担をかけているかを視覚化できます。また、データパラメータを変更して、時間の経過に伴う医療リソース要件の変化を視覚化することもできます。
人口密度が病院のベッド数に与える影響
次の視覚化資料では、Enigma – グローバルコロナウイルス (COVID-19) データ (ジョンズ・ホプキンズ)、Rearc – 米国の病院のベッド数 – COVID-19 | Definitive Healthcare およびアメリカ国勢調査局の郡別データを使用して、2 つの異なる郡で 1 平方キロメートルあたりの確定症例と利用可能な病院のベッド数を比較しています。Enigma データセットは事例データを提供します。Rearc データセットは、全国の病院のベッド情報を郡レベルで集計して提供しています。病例数とベッド数は、米国国勢調査局の群別データを使用して、平方キロメートルの土地面積で正規化されています。
付属のノートブックでは、視覚化資料の範囲、実物の数、およびベッドのリソースを変更できます。次の視覚化資料は、アラメダ州とサンディエゴ州の州レベルで 1 平方キロメートルあたりの病例数と許可されたベッド数を示しています。

これらの例は、パブリックデータレイクで実行できる無数の分析の一部です。
クリーンアップ
AWS COVID-19 データレイクへのアクセスに、使用する AWS のサービスの標準料金を超える追加費用は発生しません。たとえば、Athena を使用する場合、Amazon S3 でクエリを実行するためのコストとクエリ結果によるデータストレージコストは発生しますが、データレイクにアクセスするためのコストは発生しません。選択した Amazon SageMaker インスタンスによっては、Amazon SageMaker の料金が発生する場合があります。詳細については、Amazon SageMaker 料金を参照してください。
繰り返し発生する請求を回避するには、Amazon SageMaker インスタンス、作成した S3 バケットをシャットダウンして削除し、AWS Data Exchange の自動サブスクリプションを無効にします。
まとめ
組織や科学分野での垣根を超え、私たちの総力をもってすれば、COVID-19 のパンデミックとの戦いに打ち勝つことができます。AWS COVID-19 データレイクを使用することで、ウイルスに関連するキュレーションされたデータを実験および分析できるほか、独自のデータや結果を共有できます。データ、テクノロジー、科学を組み合わせたオープンで協力的な取り組みを通じて、COVID-19 を封じ込め、感染規模を縮小し、最終的には完治させるために必要な洞察を引き出し、飛躍的な進歩を実現できると信じています。
AWS COVID-19 パブリックデータレイクの詳細については、https://aws.amazon.com/covid-19-data-lake/ をご覧ください。
著者について
 Jason Berkowitz は、アメリカのデータおよび分析プロフェッショナルサービスのプラクティスリードです。機械学習、データレイクアーキテクチャのバックグラウンドを備えており、顧客がデータ駆動型を使用するように支援しています。彼は現在、お客様がプロフェッショナルサービス内の AWS でデータレイクと分析を形作るよう支援しています。
Jason Berkowitz は、アメリカのデータおよび分析プロフェッショナルサービスのプラクティスリードです。機械学習、データレイクアーキテクチャのバックグラウンドを備えており、顧客がデータ駆動型を使用するように支援しています。彼は現在、お客様がプロフェッショナルサービス内の AWS でデータレイクと分析を形作るよう支援しています。
 Colby Wise は Amazon Machine Learning ソリューションラボのシニアデータサイエンティスト兼マネージャーで、さまざまな業界に属する AWS のお客様による AI およびクラウド導入促進のお手伝いをしています。
Colby Wise は Amazon Machine Learning ソリューションラボのシニアデータサイエンティスト兼マネージャーで、さまざまな業界に属する AWS のお客様による AI およびクラウド導入促進のお手伝いをしています。
 Ninad Kulkarni は、Amazon Machine Learning ソリューションラボのデータサイエンティストです。ビジネス問題に対処するためのソリューションを構築することにより、顧客が機械学習および AI ソリューションを採用するのを支援します。最近では、ファンのエンゲージメントを向上させるために、画面上の使用量に関してスポーツ系お客様向けの予測モデルを構築しています。
Ninad Kulkarni は、Amazon Machine Learning ソリューションラボのデータサイエンティストです。ビジネス問題に対処するためのソリューションを構築することにより、顧客が機械学習および AI ソリューションを採用するのを支援します。最近では、ファンのエンゲージメントを向上させるために、画面上の使用量に関してスポーツ系お客様向けの予測モデルを構築しています。