Amazon Web Services ブログ
東京海上日動システムズ株式会社様の AWS 生成 AI 事例:全社生成 AI 実行基盤とエンタープライズ RAG システムの構築
はじめに
東京海上日動システムズ株式会社様(以下、同社)では、生成 AI を活用した継続的な変革に取り組まれています。これまで、生成AIによるアプリケーションモダナイゼーションや AI-DLC(AI-Driven Development Life Cycle)による開発変革について紹介してきましたが、本ブログでは、同社の生成 AI 活用のもう一つの重要な取り組みである、全社向けの生成 AI アプリケーション実行基盤の構築についてご紹介します。
特に、RAG(Retrieval-Augmented Generation)システムの構築における技術選定と実装の工夫は、同様のプロジェクトを検討されている企業の皆様にとって有益な知見となるはずです。
全社生成 AI 実行基盤の構想
プロジェクトの背景と目的
同社は、全社向けの生成 AI アプリケーション実行基盤の構築に取り組みました。このプラットフォームは、生成 AI アプリケーションのガバナンス機能、データ、ビジネスロジック等を共通化することで、アプリケーション開発の品質と速度を向上させることを目的としており、生成 AI アプリケーション構築における中核プラットフォームとしての役割を担います。
アーキテクチャの特徴
同社はマルチアカウント構成によるスケーラビリティを重視した設計を採用しました。各生成 AI アプリケーションを独立したアカウントで運用することで、障害や負荷の影響を分離できます。また、Amazon Bedrock などの AWS サービスにはアカウント単位でリクエスト数などのクォータが設定されていますが、アカウントを分離することで各アプリケーションが独立してクォータを利用でき、スケーラブルな運用が可能になります。
一方、共通 GW アカウントでは、入出力のフィルタリングやログの監視などのガバナンス機能を集約して提供します。これにより、全社で統一されたセキュリティポリシーとコンプライアンス要件を満たしながら、各アプリケーションが安全に生成 AI を活用できる環境を実現します。
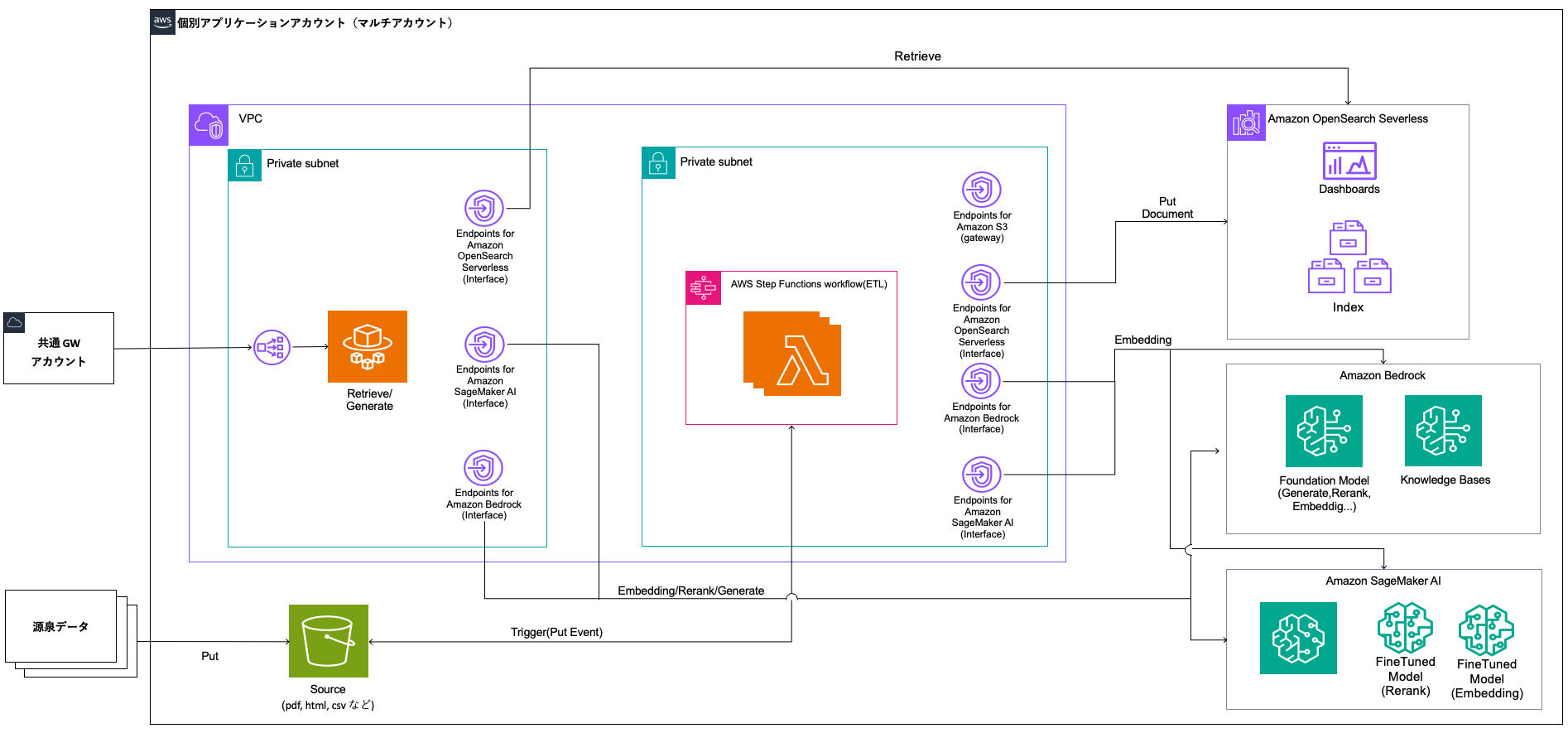
全社生成 AI 実行基盤のアーキテクチャ
RAG システムの構築
システムの概要
プラットフォーム上で動作する生成 AI アプリケーションの1つとして、同社は RAG システムを開発しています。このシステムは、複数のデータソース(社内 FAQ サイト、社内マニュアル、過去の問い合わせ履歴など)を統合し、高精度な情報検索と回答生成を実現します。
この RAG システムの構築において、同社はいくつかの技術的な工夫を行いました。
ドキュメント解析:Foundation Model Parsing の活用
このシステムで扱う社内マニュアルは、二段組レイアウト、図表とテキストの混在、階層的な情報構造など、非常に複雑な特徴を持っています。このような複雑なレイアウトを正確に理解し、適切な形式で情報を抽出するため、Amazon Bedrock Knowledge Bases の Foundation Model Parsing を採用しました。
この機能は、Anthropic Claude などの高度な基盤モデルを活用したマルチモーダル機能により、PDF や画像ファイル内のテキスト、図表、画像などを理解し、抽出します。Claude の高度な視覚理解能力により、複雑な文書構造を正しい順序で抽出し、注釈や図表の説明を適切な位置に配置することで、高精度な情報検索と回答生成が可能となりました。
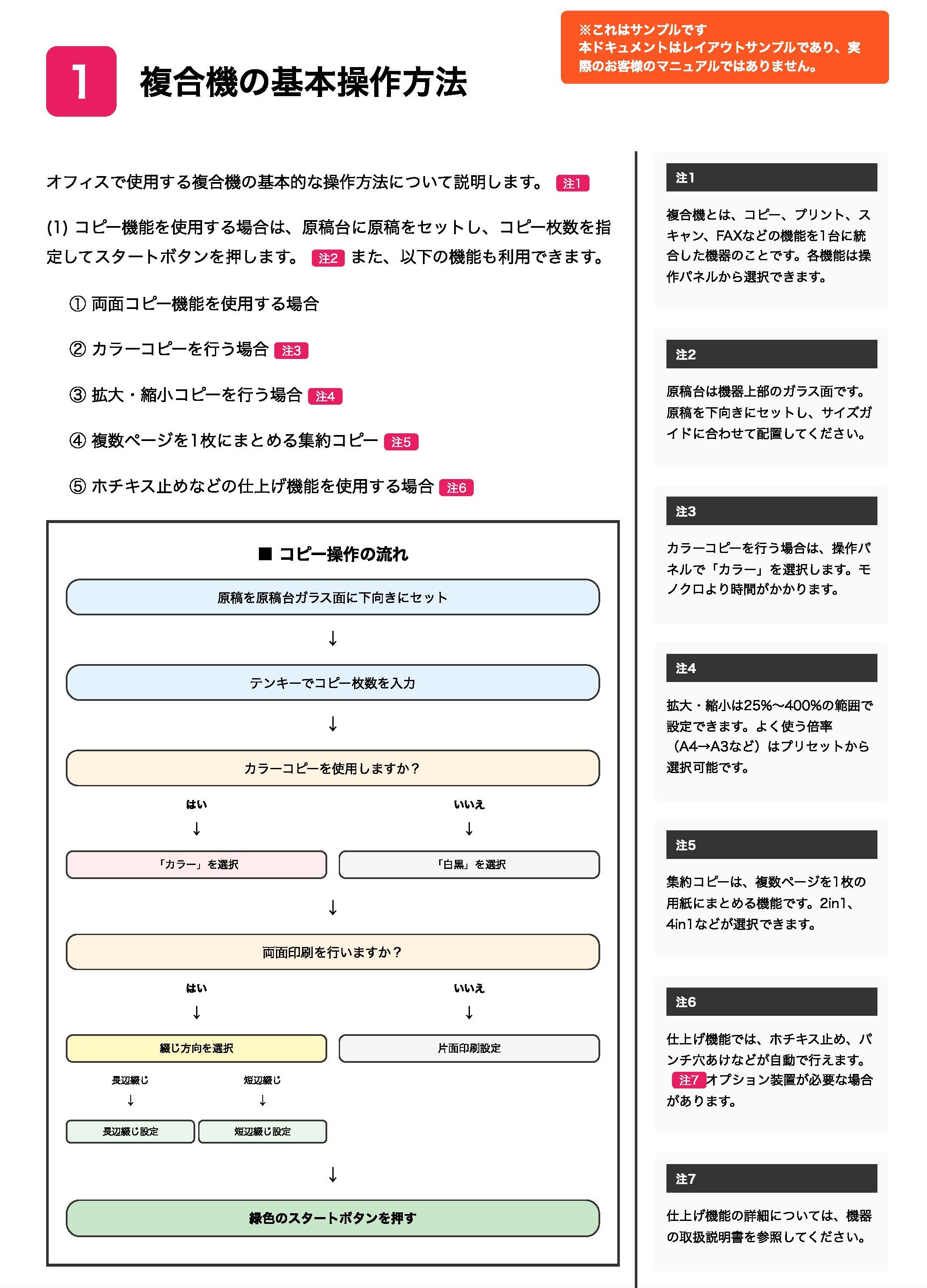
以下は、Claude Sonnet 4 を利用した Foundation Model Parsing による抽出の様子を示すサンプルです。実際の同社のマニュアルではありません。左側のページの画像から、右側のように構造化されたテキストが抽出されます。
 |
<markdown>
|
このように、二段組テキストの統合、フローチャート図の構造化、注釈の対応付けが正確に行われ、検索時に適切なコンテキストを提供できる形式で抽出されています。
検索精度の最適化:ハイブリッドアーキテクチャ
同社が複数のデータソースで検証を行った結果、Embedding モデル(テキストをベクトル化して数値表現に変換し、意味的な類似性を計算できるようにするモデル)の違いによって検索精度が異なることが判明しました。特に、一部のデータソースでは、Amazon Bedrock Knowledge Bases で提供されているモデルよりも、オープンソースの Embedding モデルの方が高い検索精度を示しました。
そこで同社は、このオープンソースの Embedding モデルを活用するため、Amazon SageMaker AI を活用する方針としました。Amazon SageMaker AI は、独自のモデルをホスティングしてインフラを詳細に制御できる機械学習サービスで、Amazon Bedrock では提供されていないオープンソースモデルを柔軟に利用できます。
同社は、データソースの特性に応じて最適なアプローチを選択するハイブリッドアーキテクチャを構築しました。社内マニュアルのようなレイアウトが複雑なファイルを扱うデータソースについては、Amazon Bedrock Knowledge Bases を活用し、Foundation Model Parsing によるデータ抽出からベクトル化、データベース格納までをマネージドサービスで処理します。一方、オープンソースの Embedding モデルが高精度を示したデータソースについては、AWS Step Functions でデータ抽出、チャンキング、ベクトル化、データベース格納といったドキュメント登録処理のワークフローを構築し、ベクトル化には Amazon SageMaker AI でホストした Embedding モデルを活用する独自実装の RAG としました。このハイブリッドアーキテクチャにより、各データソースに最適化された高精度な検索を実現しています。
大量ドキュメントの高速登録:二段階の並列制御
独自実装の RAG では、ドキュメントの変更や追加時に、テキスト抽出、チャンキング、ベクトル化、データベース格納という一連の処理を実行します。数千から数万のファイルを高速に処理するため、同社は並列処理を活用していますが、単純に並列度を上げるだけでは ベクトル化を行う Amazon SageMaker AI エンドポイントの処理能力を超えてしまいます。
AWS Step Functions と Amazon SageMaker AI を組み合わせたデータ処理パイプラインを構築し、エンドポイントの処理能力を考慮した二段階の並列制御を実装しました。
定期的なバッチ処理で S3 バケットにファイルが配置されると、それをトリガーとして AWS Step Functions ステートマシンが起動され、ドキュメント登録処理が開始されます。複数のファイルが同時に配置された場合は複数のステートマシンが並列で起動されますが、Amazon DynamoDB を使用したロック機構により同時実行数を制御しています。
次に、各ステートマシン内では、Distributed Map を活用して 1 ファイル内の数百〜数千のチャンクを並列処理します。Amazon SageMaker AI エンドポイントのインスタンス数を増やすことで、より多くのチャンクを同時にベクトル化でき、処理時間を短縮できます。
この二段階の制御により、ファイル単位でのエラーハンドリングを維持しながら、チャンクレベルでは大規模な並列処理による高速化を実現しています。
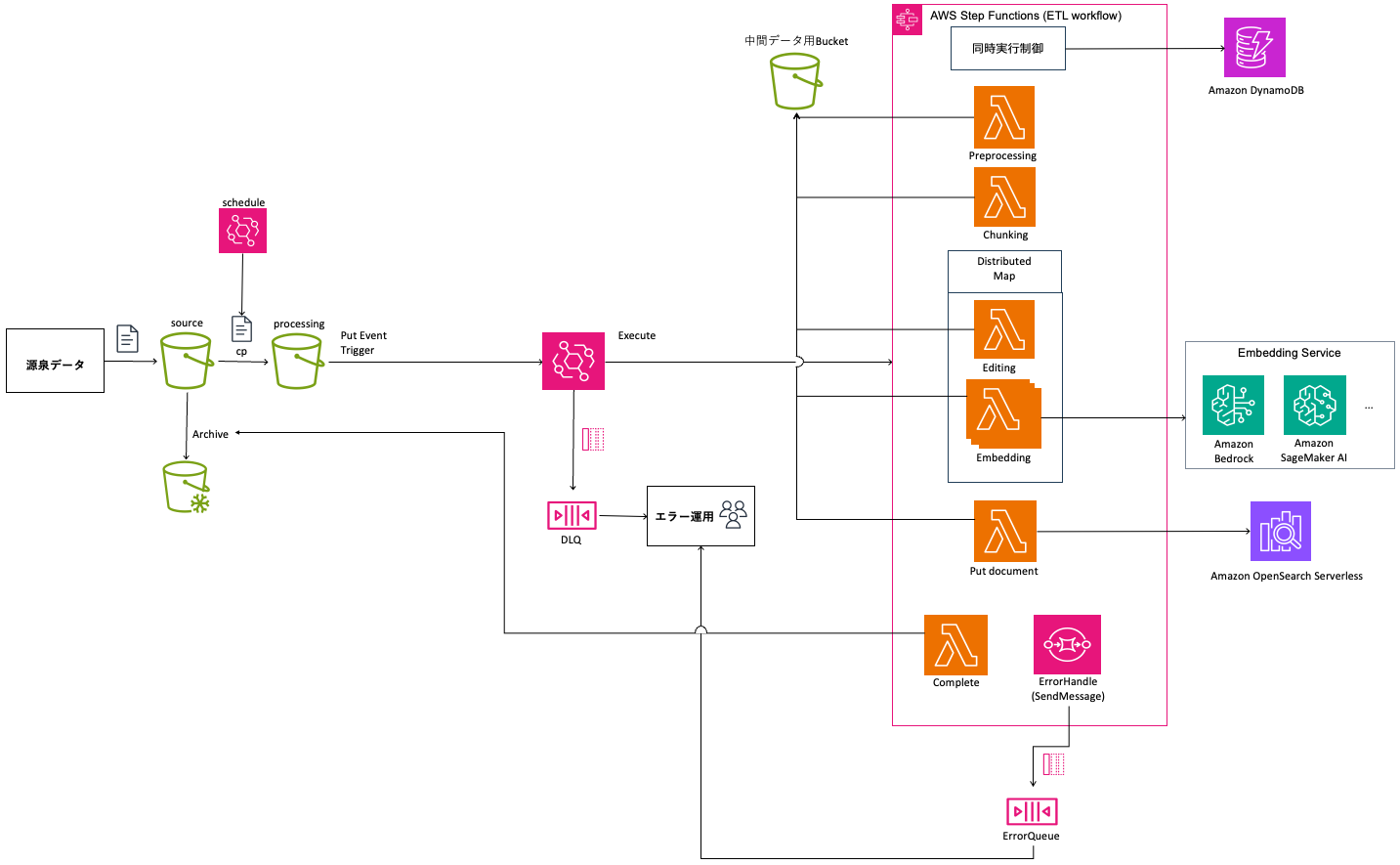
ドキュメント登録処理の並列制御アーキテクチャ
コスト最適化:用途別エンドポイントの使い分け
ベクトル化処理において、検索時とドキュメント登録時では処理の特性が異なります。検索時はユーザーの質問をリアルタイムでベクトル化する必要があり、1 回あたりの処理データ量は少量ですが、常時稼働が求められます。一方、ドキュメント登録時は定期的なバッチ処理で数千〜数万のドキュメントを一括でベクトル化するため、大量のデータを処理する必要がありますが、常時稼働は不要です。
同社は、この特性の違いに応じて Amazon SageMaker AI のエンドポイントを 2 つに分けて運用しています。検索用エンドポイントは常時稼働が必要なため低コストな CPU インスタンスを採用し、ドキュメント登録用エンドポイントは高速処理のため GPU インスタンスを採用しつつ、処理がない時間帯はゼロスケーリングでコストを削減しています。この使い分けにより、高いパフォーマンスとコスト効率を両立しています。
お客様の評価と今後の展望
東京海上日動システムズ デジタルイノベーション本部 デジタルイノベーション開発部 佐田様からは以下のコメントをいただいています。
全社生成 AI プラットフォームの開発は、当社にとって非常にチャレンジングなプロジェクトでした。生成 AI をビジネスに効果的に活用していくために、大規模かつ高精度なナレッジ検索の機能は必要不可欠であると考えていますが、Amazon Bedrock Knowledge Bases をはじめとする AWS の各サービスおよびソリューションアーキテクトやサービス開発チームの皆様のサポートのおかげでこれを実現することができました。今後も、このプラットフォームを全社の生成 AI 基盤として拡大していき、金融業界における生成 AI 活用のリーディングケースを作っていきたいと考えています。
同社は今後、この全社生成 AI 実行基盤を AI エージェント実行基盤へと発展させていく方針です。Amazon Bedrock AgentCore などのサービスを活用し、多様なフレームワークやモデルを柔軟に組み合わせながら、AI エージェントを安全かつスケーラブルに運用できる環境の構築を目指しています。
まとめ
本事例を通じて、企業における生成 AI の本格展開に向けた重要な示唆が得られました。
生成 AI を全社に展開する際は、ガバナンス、スケーラビリティ、コスト効率を初期段階から考慮した基盤設計が重要です。マルチアカウント構成やゼロスケーリングなどの設計パターンにより、持続可能な運用が可能になります。
RAG システムの構築では、まず Amazon Bedrock Knowledge Bases で迅速に構築し、データソースの特性に応じて独自実装を追加する段階的なアプローチが有効です。マネージドサービスと独自実装を組み合わせることで、開発速度と柔軟性を両立できます。
また、RAG システムの性能は、ドキュメントの構造やデータソースの特性を深く理解することで大きく向上します。実際のデータで検証を行い、適材適所で技術を選択することが重要です。
同社が構築した全社生成 AI 実行基盤とその上で動作する RAG システムは、金融業界における生成 AI の本格展開のモデルケースとして、業界全体での活用促進に貢献することが期待されます。