Amazon Web Services ブログ
Amazon DynamoDB データに対する検索を Amazon OpenSearch Service とのゼロ ETL 統合を使用して実装する
この記事では、Amazon DynamoDB データに対する検索を Amazon OpenSearch Service とのゼロ ETL 統合を使用して実装する方法を紹介します。データパイプラインの構築と保守を行うことなく、アプリケーションに全文検索、あいまい一致、複雑な検索クエリを追加する方法を学びます。
Amazon DynamoDB は、大規模な環境で 1 桁ミリ秒の応答時間と高スループット操作を必要とするアプリケーションに最適な選択肢です。OpenSearch Service と組み合わせることで、アプリケーションは複雑な検索と分析のための強力な機能を獲得します。このゼロ ETL 統合がアプリケーションの検索機能をどのように強化できるかを示す実用的なユースケースを見ていきましょう。
現状の概要
AnyCompany は、エコフレンドリーで持続可能な製品を専門とする架空のオンラインマーケットプレイスで、世界中の環境意識の高い消費者にサービスを提供しています。彼らのアプリケーションは AWS サーバーレスアーキテクチャ上で動作しており、AWS Lambda 関数が e コマース操作を処理します。製品情報や在庫詳細などのコアトランザクションデータは DynamoDB に保存されています。
AnyCompany の製品用 DynamoDB テーブルレイアウトには、以下の属性が含まれます:
| 属性 | 例 |
| product_id (パーティションキー) | Id_1 |
| name | ECO T-Shirt |
| description | Organic CottonTee |
| price | 100 |
| rating | 5 |
| category | Activewear |
| brand | AnyCompany |
| tags | organic |
| specs | {“color”:”white”,”size”:”M”} |
| stock | 48 |
| created_at | 2025-12-16T16:15:43.473864+0000 |
| updated_at | 2025-12-16T16:15:43.473864+0000 |
書き込み操作では、AnyCompany は DynamoDB を使用してデータの一貫性を維持します。製品情報を更新する際、システムは product_id をパーティションキーとして使用して製品の更新を実行します。AnyCompany の製品カタログの拡大により、顧客の検索パターンがより複雑になり、システムはバリエーション、スペルミス、セマンティッククエリ、ファセット検索(顧客が価格帯、ブランド、評価、製品カテゴリなどの複数の属性を使用して製品をフィルタリングし、絞り込むことができる機能)を処理する必要があります。
企業が拡大するにつれて、以下のような検索シナリオが浮上しています:
- マルチフィールド検索 – 顧客は、製品名、説明、カテゴリ、タグなどの複数のフィールドを同時に検索する必要があります。
- マルチレンジ検索 – 顧客は、価格帯($20-$50)や評価(4-5 つ星)など、複数の基準で製品をフィルタリングしたいと考えています。
- 発見とナビゲーション – 顧客は、ファセット検索を使用して結果を段階的に絞り込み(カテゴリ、ブランドなどのフィルタを使用)、動的な集計を通じて選択肢を理解したい(カテゴリ別の製品数、ブランド、評価の分布を確認するなど)と考えています。
- あいまい検索と提案 – 顧客は、タイプミスやスペルミスがあっても検索が機能することを望んでいます(例えば、「reuseble botl」と入力しても「reusable water bottle」が見つかる)。また、入力中にオートコンプリート提案を受け取り、製品をより迅速に見つけられるようにしたいと考えています。
- セマンティック検索 – 顧客は、正確な製品名ではなく自然言語の説明を使用することがよくあります。例えば、「biodegradable kitchen storage containers」を検索すると、関連するエコフレンドリーな食品保存製品が返されるべきです。
AWS は DynamoDB と OpenSearch Service 間のゼロ ETL 統合を提供し、これら 2 つのサービス間でデータを同期します。この統合により、カスタムデータパイプラインを構築および保守することなく、OpenSearch Service の検索機能で DynamoDB ベースのアプリケーションを補完し、これらの検索要件を満たすことができます。
以下の例では、OpenSearch Service が AnyCompany のこれらの検索シナリオで DynamoDB をどのように補完するかについて説明します。
マルチフィールド検索
顧客の検索パターンは本質的に動的であり、顧客は常に製品を検索する新しい方法を求めています。AnyCompany では、顧客は検索クエリが複数の製品属性に同時に一致することを望んでおり、製品名、説明、カテゴリ、タグで一致を探して、関連するアイテムを見逃さないようにしています。
OpenSearch は、検索ユースケースをカスタマイズし、検索の関連性を向上させるための多くの機能を提供します。完全なリストについては、検索機能を参照してください。OpenSearch は、データを検索するために使用できる クエリドメイン固有言語(DSL)と呼ばれる検索言語を提供します。
以下は、この機能を実装するクエリの例です:
GET products/_search
{
"query": {
"bool":{
"should": [
{
}
]
}
},
"size":20
}
マルチレンジ検索
前述の検索機能に基づいて、AnyCompany の顧客は、特定の価格帯($25–50)内の製品を検索しながら、特定のカテゴリと評価を考慮するなど、複数のフィルタリング基準を組み合わせたいと考えることがよくあります。
OpenSearch Service では、さまざまな方法を使用して検索結果をフィルタリングできます。各方法は特定のシナリオに適しています。クエリレベルでフィルタを適用し、Boolean クエリ句と post_filter および aggregation レベルのフィルタを使用できます。
以下は、この機能を実装するクエリの例です:
GET products/_search
{
"query": {
"bool":{
"should": [
{
"multi_match": {
"query": "Men's Wear",
"fields": ["name.ngram","description","category","tags"]
}
}
],
}
},
"size":20
}
発見とナビゲーション
AnyCompany では、顧客は特定のアイテムを検索するのではなく、インタラクティブなインターフェースを通じて製品を発見したいと考えています。例えば、持続可能なファッションを閲覧している顧客は、「Men’s Wear」の検索から始めて、利用可能な製品の全体像を理解したいと考えるかもしれません。彼らは、利用可能なカテゴリ、持続可能なオプションを提供するブランド、一般的な価格帯、製品評価を確認したいと考えています。集計されたデータは通常、サイドバーにフィルタリングオプションとして表示され、顧客が直感的に検索結果を絞り込むことができます。
OpenSearch 集計を使用すると、データを分析し、そこから統計を抽出できます。メトリクス集計を適用して簡単な計算を実行したり、バケット集計を使用してドキュメントのセットをバケットとして分類したり、パイプライン集計を使用して複数の集計を連鎖させたりできます。
以下は、この機能を実装するクエリの例です:
GET products/_search
{
"query": {
"bool":{
"should": [
{
"multi_match": {
"query": "Men's Wear",
"fields": ["name.ngram","description","category","tags"]
}
}
]
}
},
"aggs": {
"categories": {"terms":{"field":"category.keyword","size":10}},
"brands":{"terms":{"field":"brand.keyword","size":10}},
"colors":{"terms":{"field":"specs.color","size":10}},
"sizes":{"terms":{"field":"specs.size","size":10}},
"size":20
}
あいまい検索と提案
AnyCompany では、顧客は不完全な記憶で製品を検索することが多く、タイプミスをしながらも、意図を予測できるリアルタイムの検索提案を期待しています。例えば、「Omga」と入力すると、タイプミスを許容し、「OmegaWear」や「Omega Eco Essentials」などの関連製品を提案する必要があります。これには、スペルのバリエーションやタイプミスを処理しながら、ショッピング体験を向上させる検索提案を提供する堅牢な検索システムが必要です。OpenSearch では、キーストロークごとに更新され、関連する提案を提供し、タイプミスを許容するオートコンプリート機能を設計できます。
以下は、この機能を実装するクエリの例です:
GET products/_search
{
"suggest": {
"product_suggest": {
"prefix": "Om",
},
"size": 5
}
}
}
}
セマンティック検索
AnyCompany では、顧客は特定の製品名やカテゴリではなく、「red beach hat for summer」のような自然なフレーズを使用して製品のニーズを表現することがよくあります。この直感的な検索方法には、キーワードの一致だけでなく、顧客のクエリの背後にあるセマンティックな意味を理解するシステムが必要です。
OpenSearch は、ベクトル検索を通じてこの自然な検索体験を可能にします。システムは、顧客のクエリをベクトル埋め込み(テキストのセマンティックな意味を捉える数値表現)に変換します。これにより、正確なキーワード一致ではなく、概念的な類似性に基づいて一致させることができます。
以下は、この機能を実装するクエリの例です:
GET /products/_search
{
"query": {
},
"aggs": {
"categories": { "terms": { "field": "category" }},
"brands": { "terms": { "field": "brand" }},
"avg_rating": { "avg": { "field": "rating" }}
},
"size": 20
}
以下のセクションでは、既存の Amazon DynamoDB 操作を維持しながら、検索機能をサポートするソリューションを実装する方法を示します。
ソリューションの概要
以下の図は、ソリューションアーキテクチャを示しています。
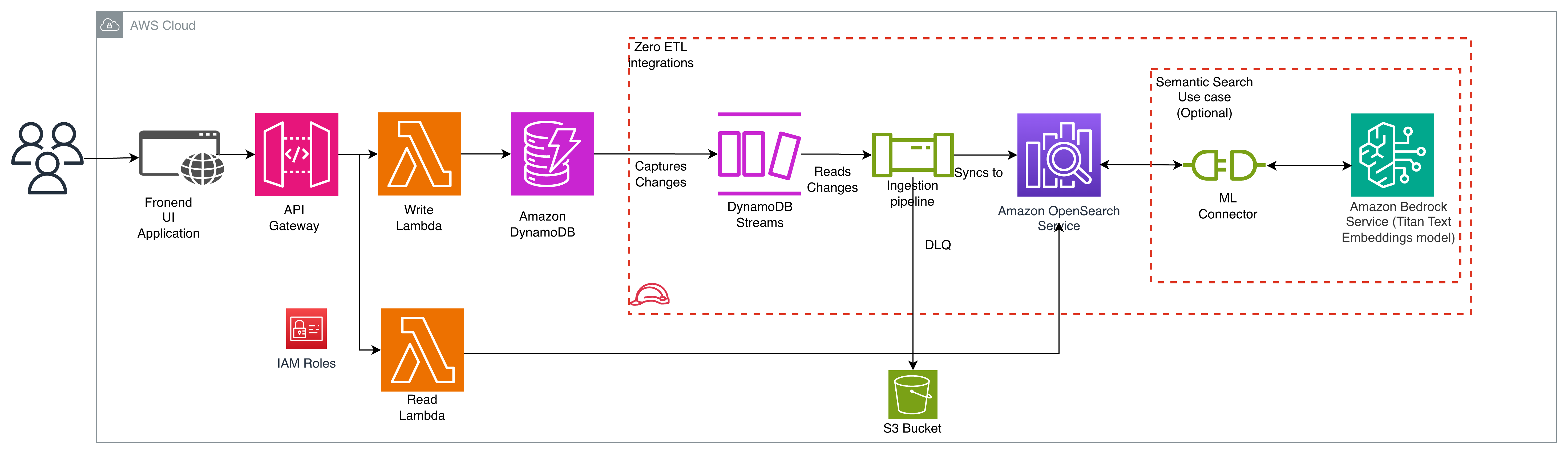
AnyCompany の既存のアーキテクチャは、Amazon API Gateway が顧客のリクエストを AWS Lambda 関数にルーティングするサーバーレスパターンに従っています。この関数は、プライマリデータストアとして機能する DynamoDB テーブルに対して読み取りおよび書き込み操作を実行します。
既存のアーキテクチャを補完するために、AnyCompany は DynamoDB と OpenSearch Service 間のゼロ ETL 統合を実装します。統合は 2 つのフェーズでデータを同期します:ポイントインタイムリカバリ(PITR)は既存の DynamoDB データを Amazon S3 にエクスポートして初期スナップショットを作成し、DynamoDB Streams は継続的な変更をキャプチャして OpenSearch サービスにほぼリアルタイムで更新します。
セマンティック検索に必要なリモート推論を有効にするために、OpenSearch ML コネクタを使用して OpenSearch を Amazon Bedrock の Titan テキスト埋め込みモデルに接続できます。
OpenSearch Ingestion パイプラインはこれらのストリームを消費し、必要に応じてデータを変換し、ほぼリアルタイムで OpenSearch Service に同期します。同期エラーをキャプチャするために、デッドレターキュー(DLQ)として Amazon Simple Storage Service(Amazon S3)バケットを指定します。
検索機能をサポートするために、ソリューションは OpenSearch Service を使用して検索リクエストを処理する新しい Lambda 関数を追加します。この関数は OpenSearch Service SDK を使用してクライアントを作成し、検索クエリを実行します。この新しい関数は、既存の操作を処理し続ける既存の書き込み Lambda 関数と並行して動作します。
この設計により、AnyCompany は e コマースワークロードを維持しながら、堅牢な検索機能を実装できます。
Amazon DynamoDB と Amazon OpenSearch Service 間のゼロ ETL 統合の実装
このセクションでは、強化された検索機能のためのセマンティック検索機能を含む、DynamoDB と OpenSearch Service 間のゼロ ETL 統合をセットアップする方法を示します。
前提条件
このソリューションをセットアップするには、以下が必要です:
- AWS アカウント。
- 以下の AWS リソースを作成および管理するための適切な AWS Identity & Access Management(IAM)権限:
- DynamoDB エクスポートおよび DLQ イベント用の Amazon S3 汎用バケット。
- Amazon Titan Embeddings G1 が有効になっている Amazon Bedrock。詳細については、Amazon Bedrock 基盤モデルへのアクセスを参照してください。
実装手順
ステップ 1:DynamoDB テーブルの作成
ソリューションのウォークスルーの目的で、「Products」という名前の新しい DynamoDB テーブルを作成します。既存の DynamoDB テーブルでこのソリューションを実装する場合は、このステップをスキップできます。以下の AWS CLI コマンドを実行してテーブルを作成します:
aws dynamodb create-table \
--table-name Products \
--attribute-definitions \
AttributeName=product_id,AttributeType=S \
--key-schema \
AttributeName=product_id,KeyType=HASH \
--billing-mode PAY_PER_REQUEST \
--region us-east-1
テーブルのステータスが CREATING から ACTIVE に変わるまで待ちます。ステータスは以下で確認できます:
aws dynamodb describe-table \
--table-name Products \
--region us-east-1 \
--query 'Table.TableStatus'
ステップ 2:DynamoDB Streams とポイントインタイムリカバリ(PITR)の有効化
以下の AWS CLI コマンドを実行します:
aws dynamodb update-table \
--table-name Products \
--stream-specification \
StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES \
--region us-east-1
aws dynamodb update-continuous-backups \
--table-name Products \
--point-in-time-recovery-specification \
PointInTimeRecoveryEnabled=true \
--region us-east-1
ステップ 3:OpenSearch ドメインの作成
以下の AWS CLI コマンドを実行してドメインを作成します:
aws opensearch create-domain \
--domain-name demo \
--engine-version "OpenSearch_3.1" \
--cluster-config InstanceType=t3.small.search,InstanceCount=1 \
--ebs-options EBSEnabled=true,VolumeType=gp3,VolumeSize=10 \
--access-policies '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"*"},"Action":"es:*","Resource":"arn:aws:es:us-east-1:YOUR_ACCOUNT_ID :domain/demo/*"}]}' \
--advanced-security-options '{"Enabled":true,"InternalUserDatabaseEnabled":true,"MasterUserOptions":{"MasterUserName":"admin","MasterUserPassword": "YourStrongPassword123!"}}' \
--node-to-node-encryption-options Enabled=true \
--encryption-at-rest-options Enabled=true \
--domain-endpoint-options EnforceHTTPS=true \
--region us-east-1
注意:
YOUR_ACCOUNT_IDを実際の AWS アカウント ID に置き換えてくださいYourStrongPassword123!を強力なパスワードに置き換えてください(OpenSearch Dashboards へのログインに使用するため保存してください)
ドメインのステータスを確認:
aws opensearch describe-domain \
--domain-name demo \
--region us-east-1 \
--query 'DomainStatus.{Status:Processing,Endpoint:Endpoint }'
Processing フィールドが Status false を返すまで待ちます。これはドメインがアクティブであることを示します。アクティブになったら、Endpoint(API アクセス用)をメモし、作成したマスターユーザー名とパスワードを使用して OpenSearch Dashboards URL(通常は https:///_dashboards/)に移動します。
ステップ 4:OpenSearch セキュリティ設定の構成
- OpenSearch Service ドメインの OpenSearch Dashboards プラグインに移動します。Dashboards エンドポイントは、OpenSearch Service コンソールのドメインダッシュボードで確認できます。
- メインメニューから Security、Roles を選択し、ml_full_access ロールを選択します。
- Mapped users、Manage mapping を選択します。
- Backend roles の下に、ドメインを呼び出す権限が必要な Lambda ロールの ARN を追加します。
- arn:aws:iam:::role/LambdaInvokeOpenSearchMLCommonsRole
- Map を選択し、ユーザーまたはロールが Mapped users の下に表示されることを確認します。
このマッピングにより、モデル統合に必要な権限が有効になります。このロールは、モデル ID を登録する次のステップで作成されます。
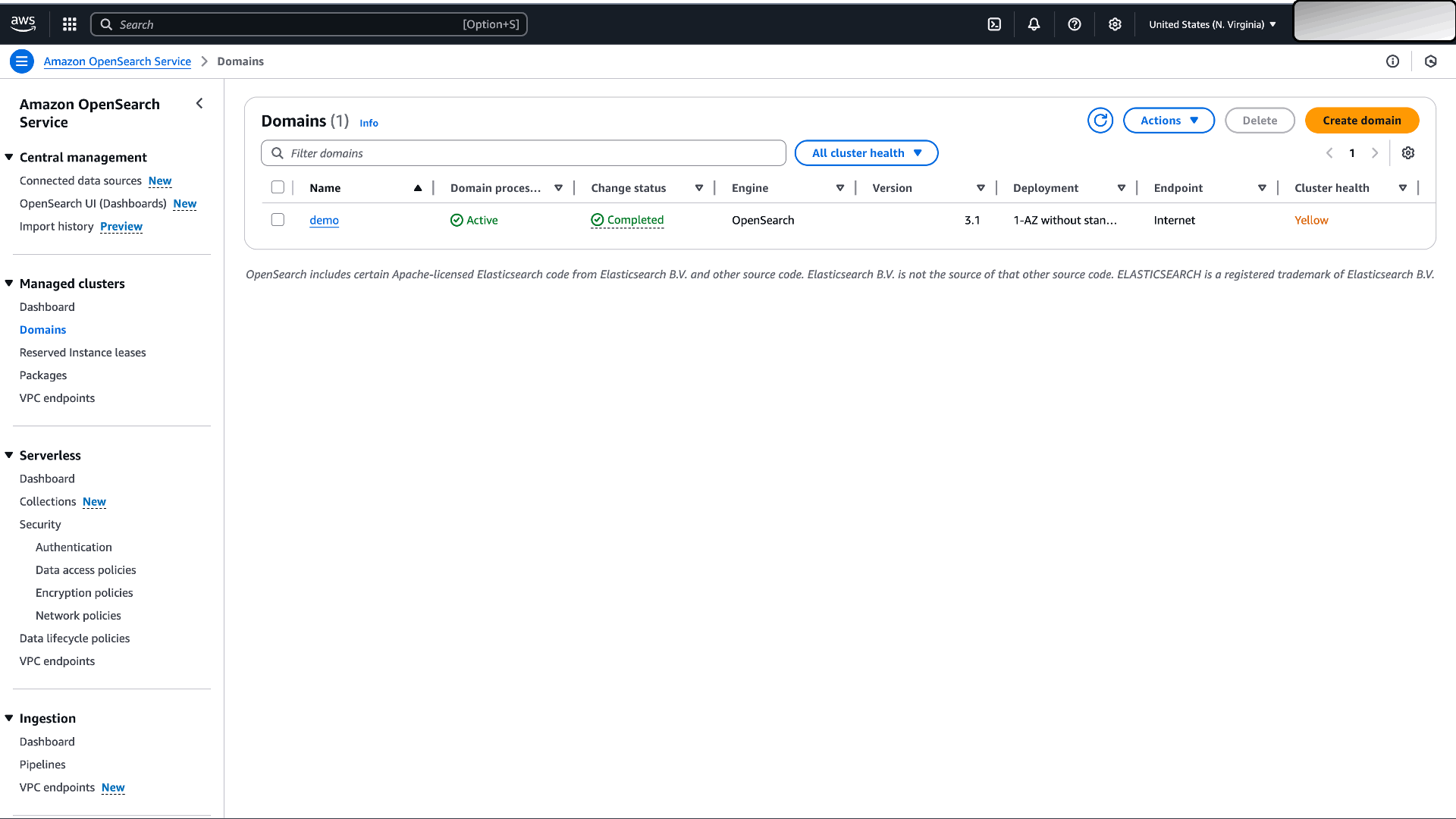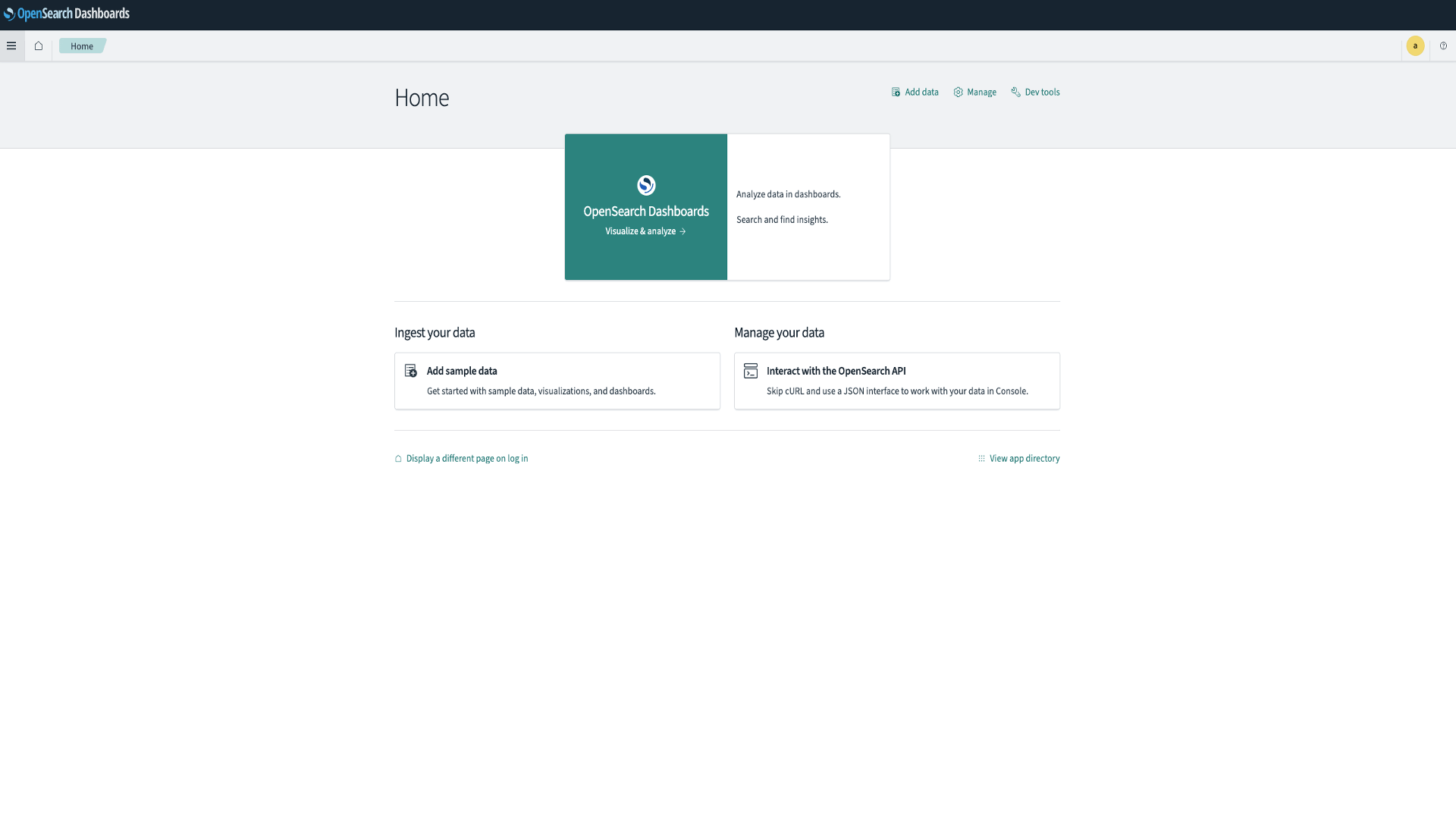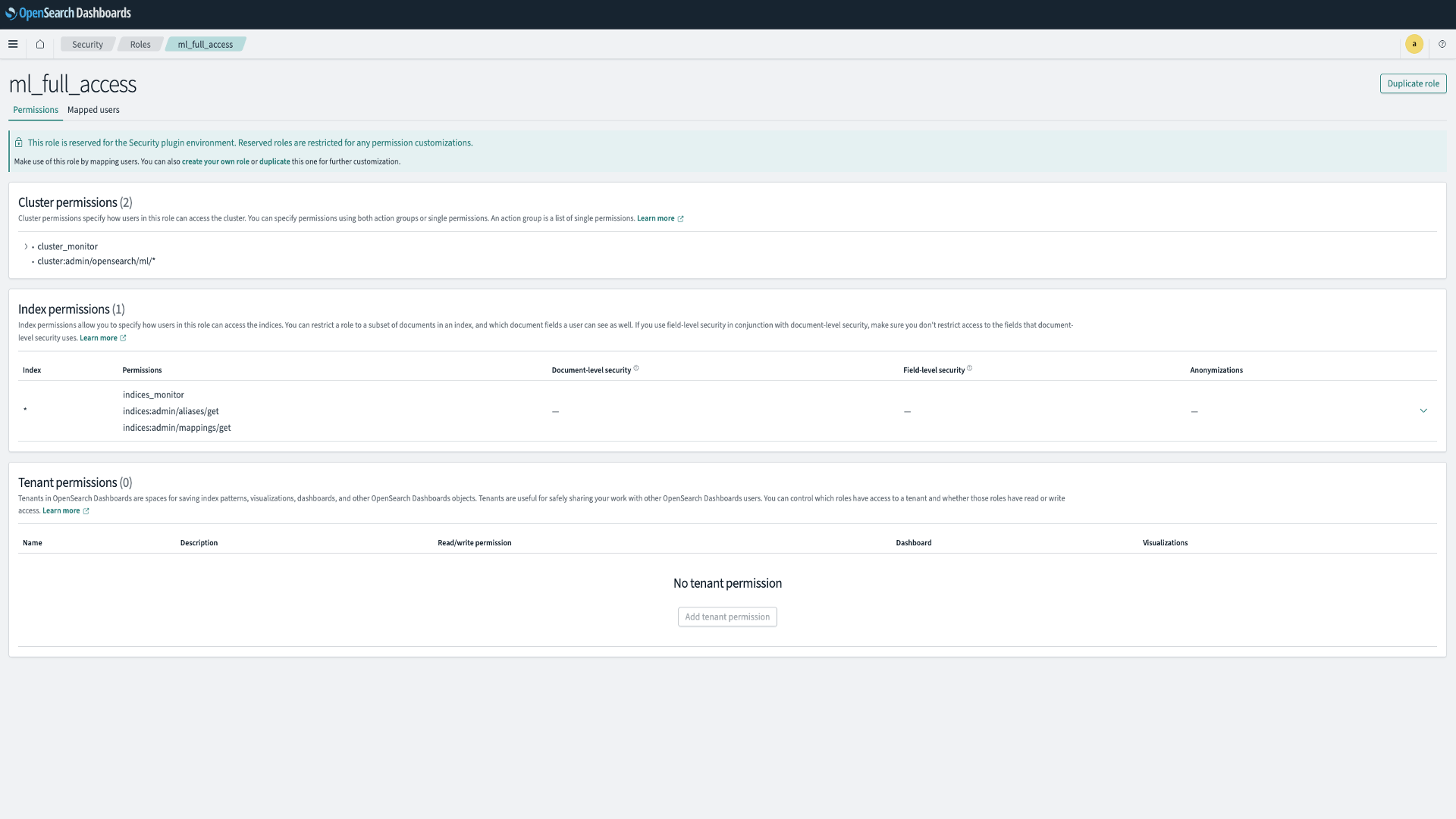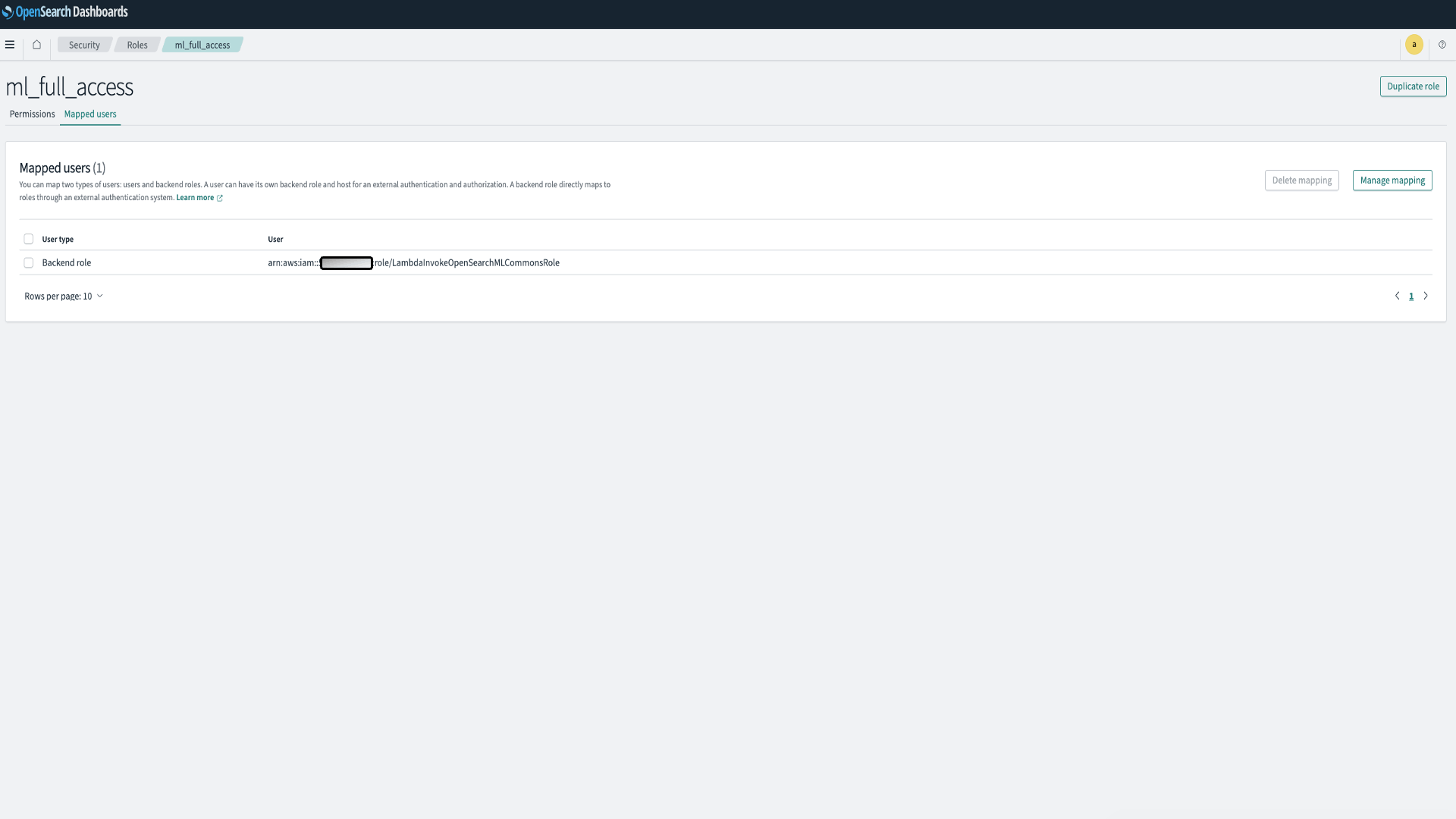
図 2:OpenSearch セキュリティ設定
ステップ 5:Bedrock モデル統合のセットアップ
リモート推論を使用すると、Amazon SageMaker AI や Amazon Bedrock などの ML サービスでモデル推論をリモートでホストし、ML コネクタを使用して Amazon OpenSearch Service に接続できます。
リモート推論のセットアップを容易にするために、Amazon OpenSearch Service はコンソールで AWS CloudFormation テンプレートを提供します。
Amazon OpenSearch Service コンソールを開きます。
- 左側のナビゲーションペインで、Integrations を選択します。
- Integrate with Amazon Titan Text Embeddings model through Amazon Bedrock を選択します
- Configure domain、Configure public domain を選択します。
- 「Amazon OpenSearch Endpoint」と「Model region」のパラメータ値を入力します。
- 「I acknowledge that AWS CloudFormation might create IAM resources」をチェックします
- Create stack を選択します
- スタックのデプロイが正常に完了したら、Outputs タブに移動し、Model Id をメモします。
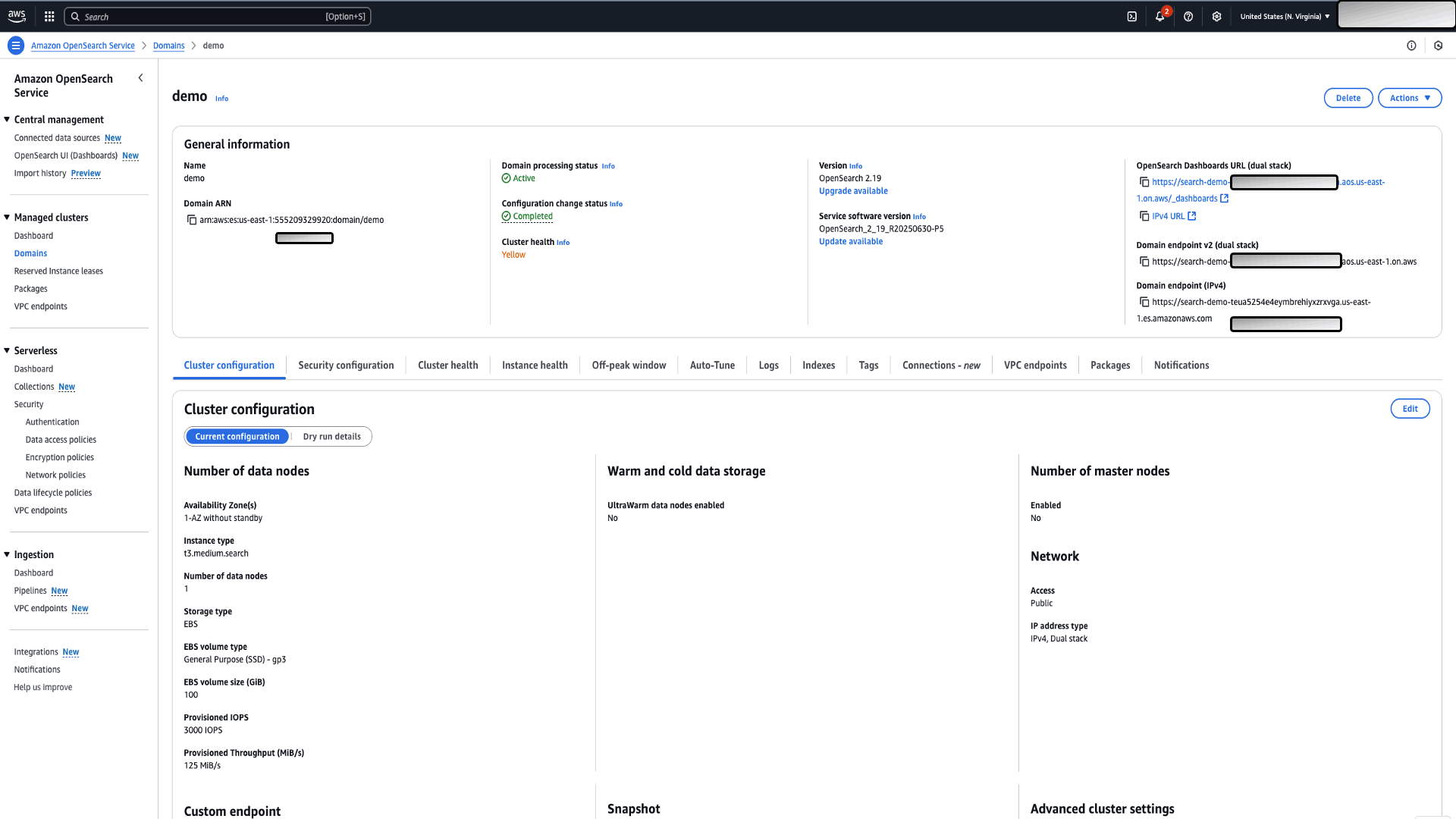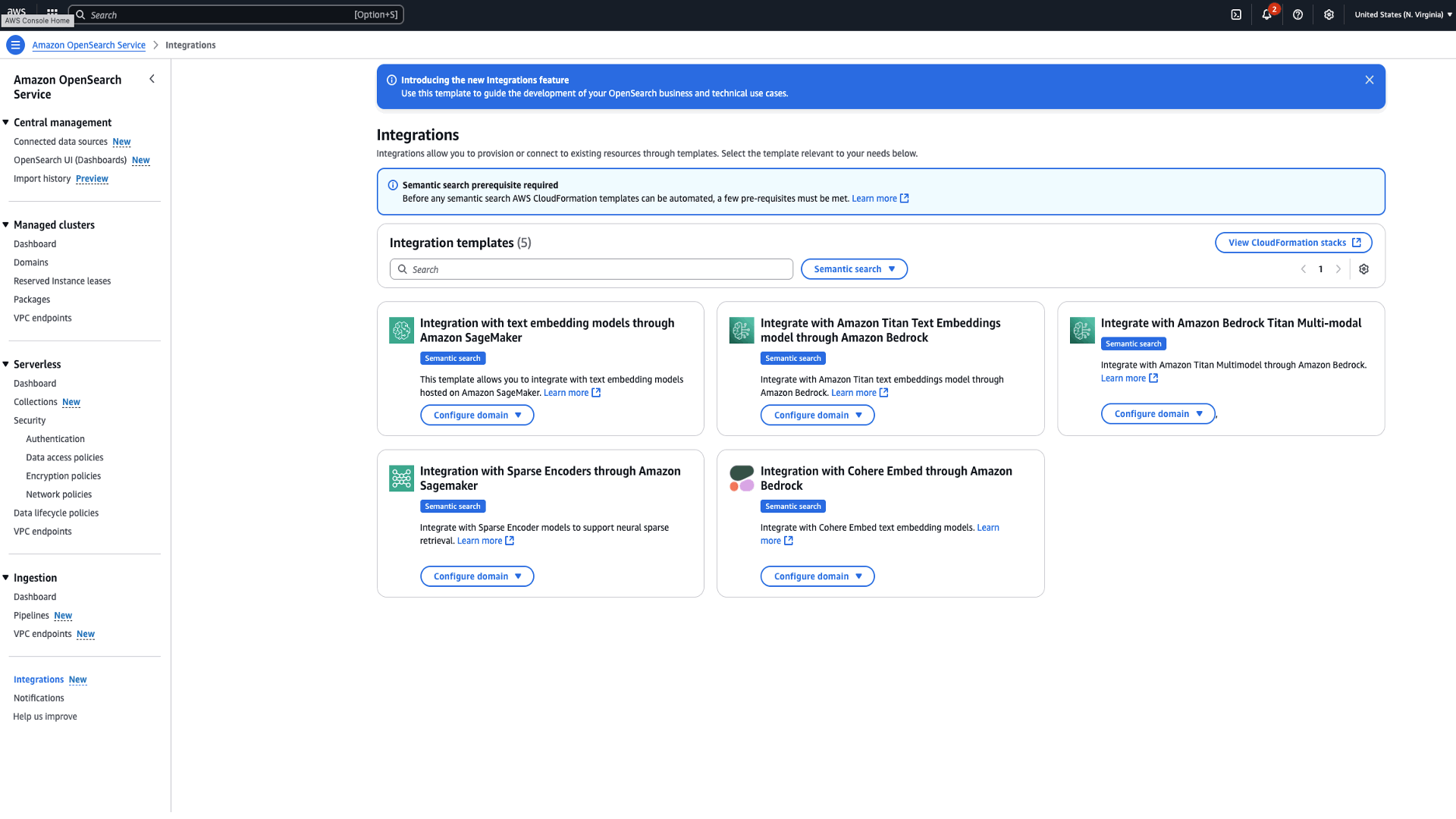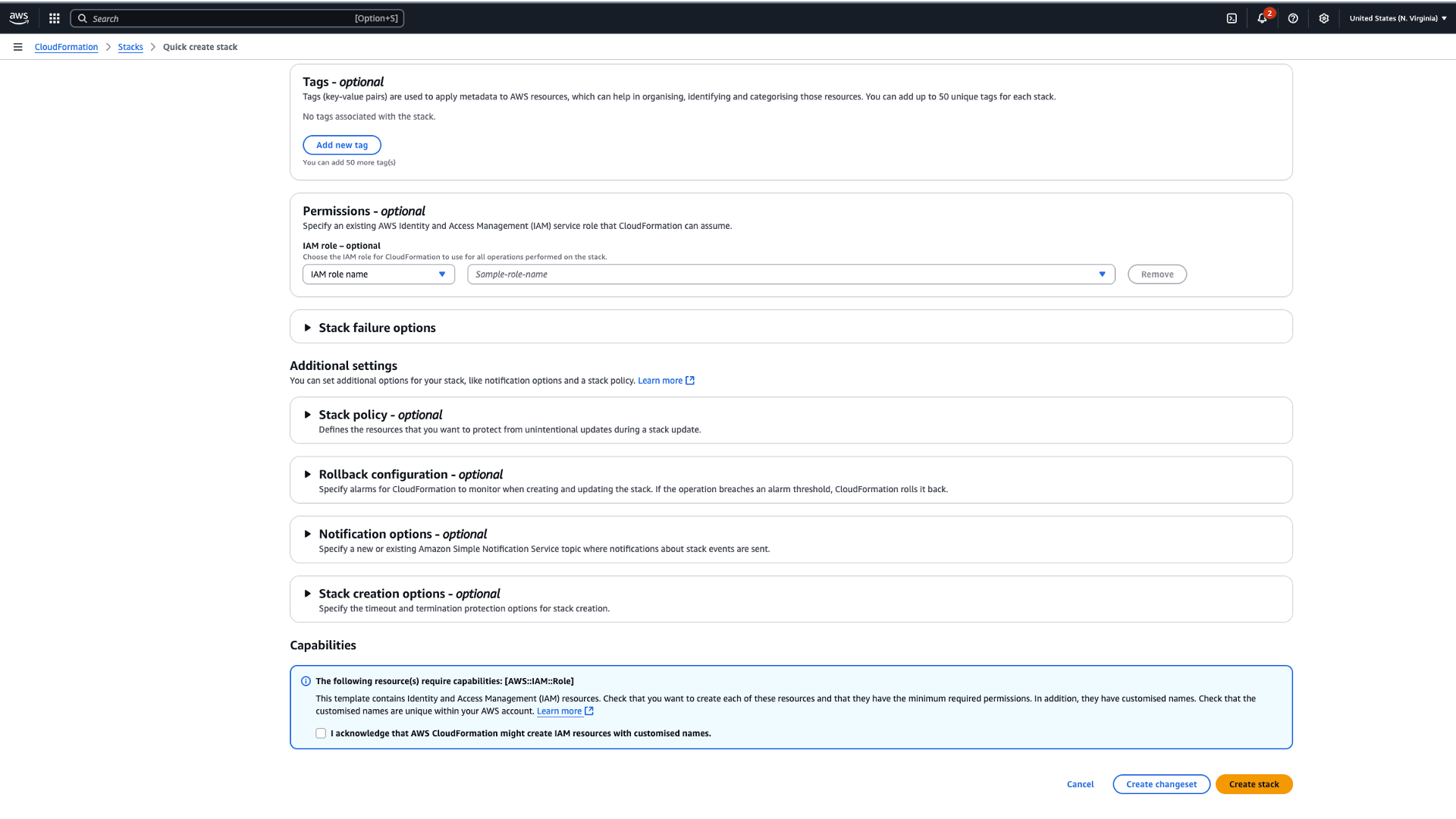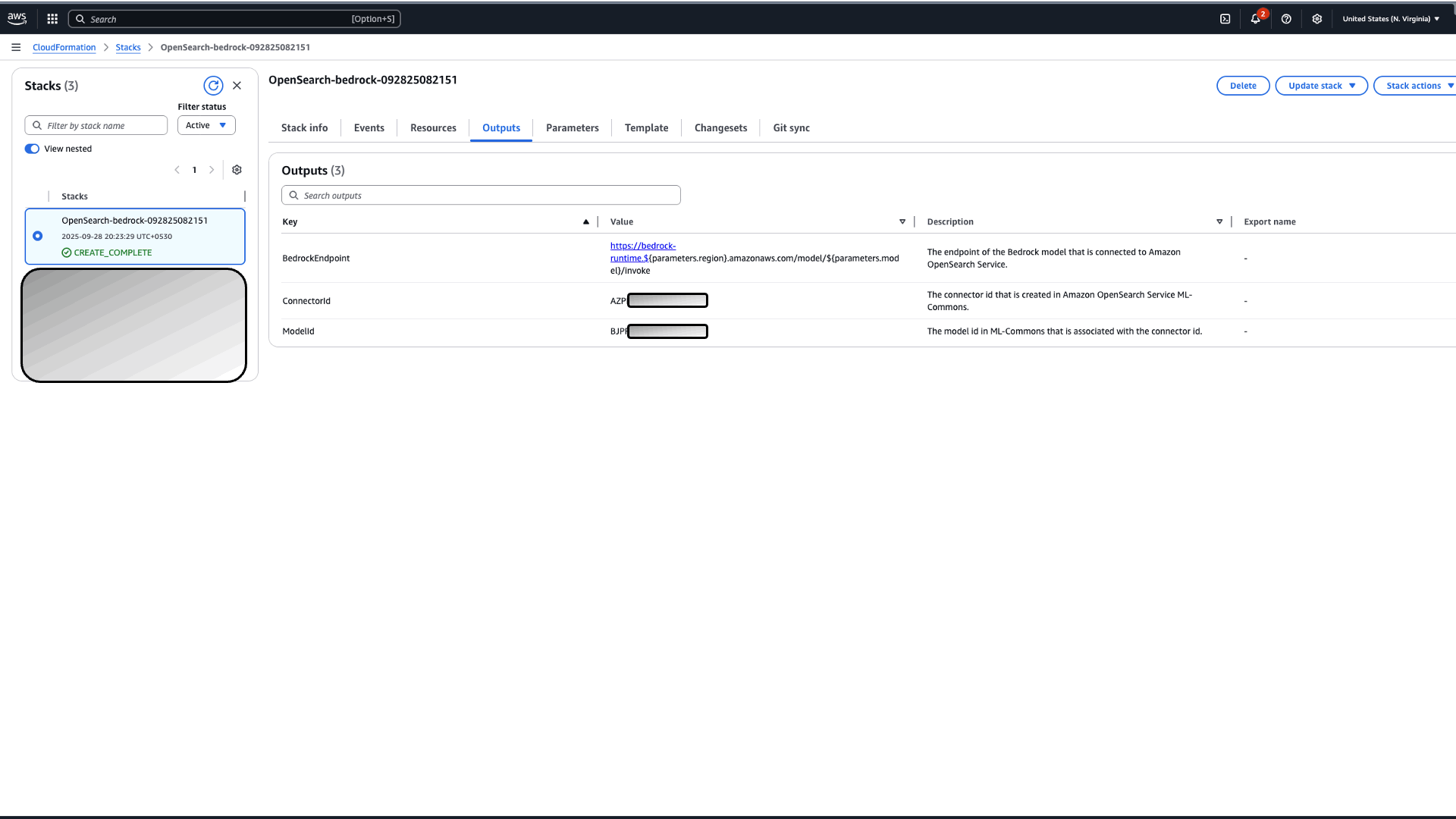
図 3:Bedrock モデル統合
ステップ 6:OpenSearch Ingest パイプラインのセットアップ
Amazon Bedrock のモデルを使用して入力フィールド description から埋め込みを作成し、description_embedding という名前のフィールドにマッピングするインジェストパイプラインを作成します。
- ドメインの OpenSearch Dashboards URL に移動します。URL は OpenSearch Service コンソールのドメインダッシュボードで確認できます。
- 左側のナビゲーションパネルを開き、DevTools を選択します。
- 埋め込みパイプラインを作成します:
PUT /_ingest/pipeline/bedrock-embedding-pipeline { "description": "A text embedding pipeline", "processors": [ { "text_embedding": { "model_id": "<your_model_id>", // 前のステップの ModelId に置き換えます。 "field_map": { "description": "description_embedding" }, "skip_existing": true } } ] }
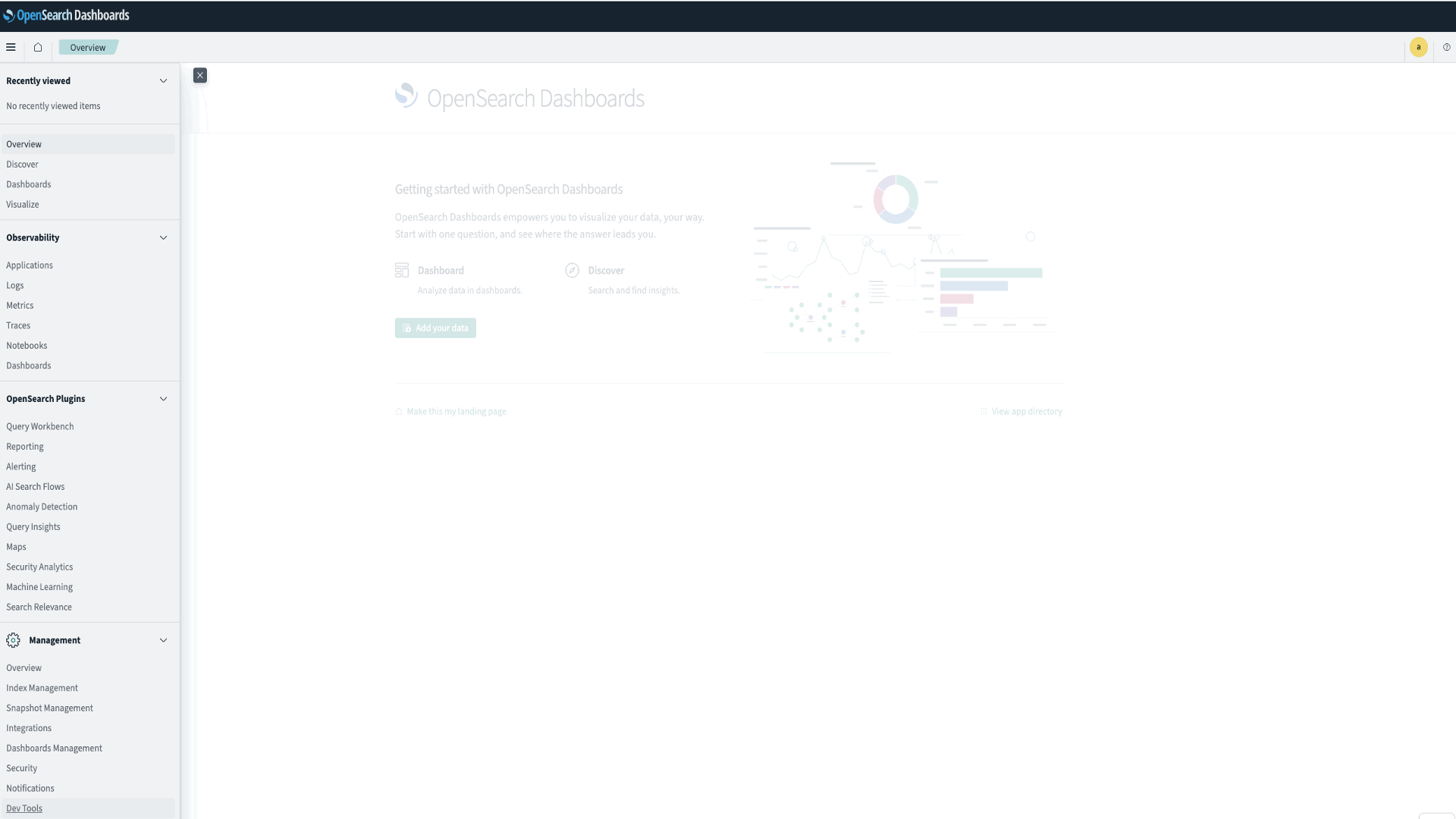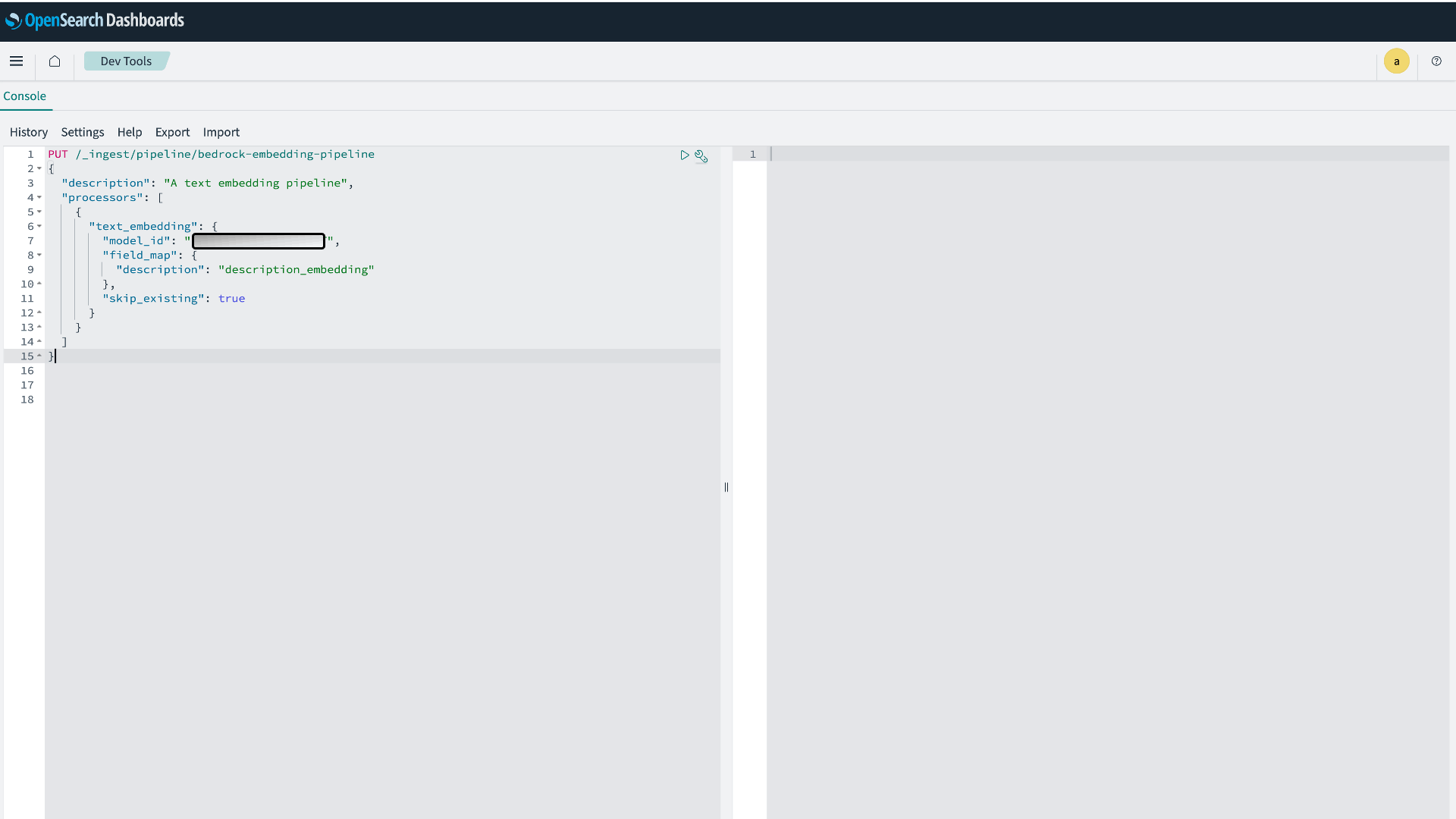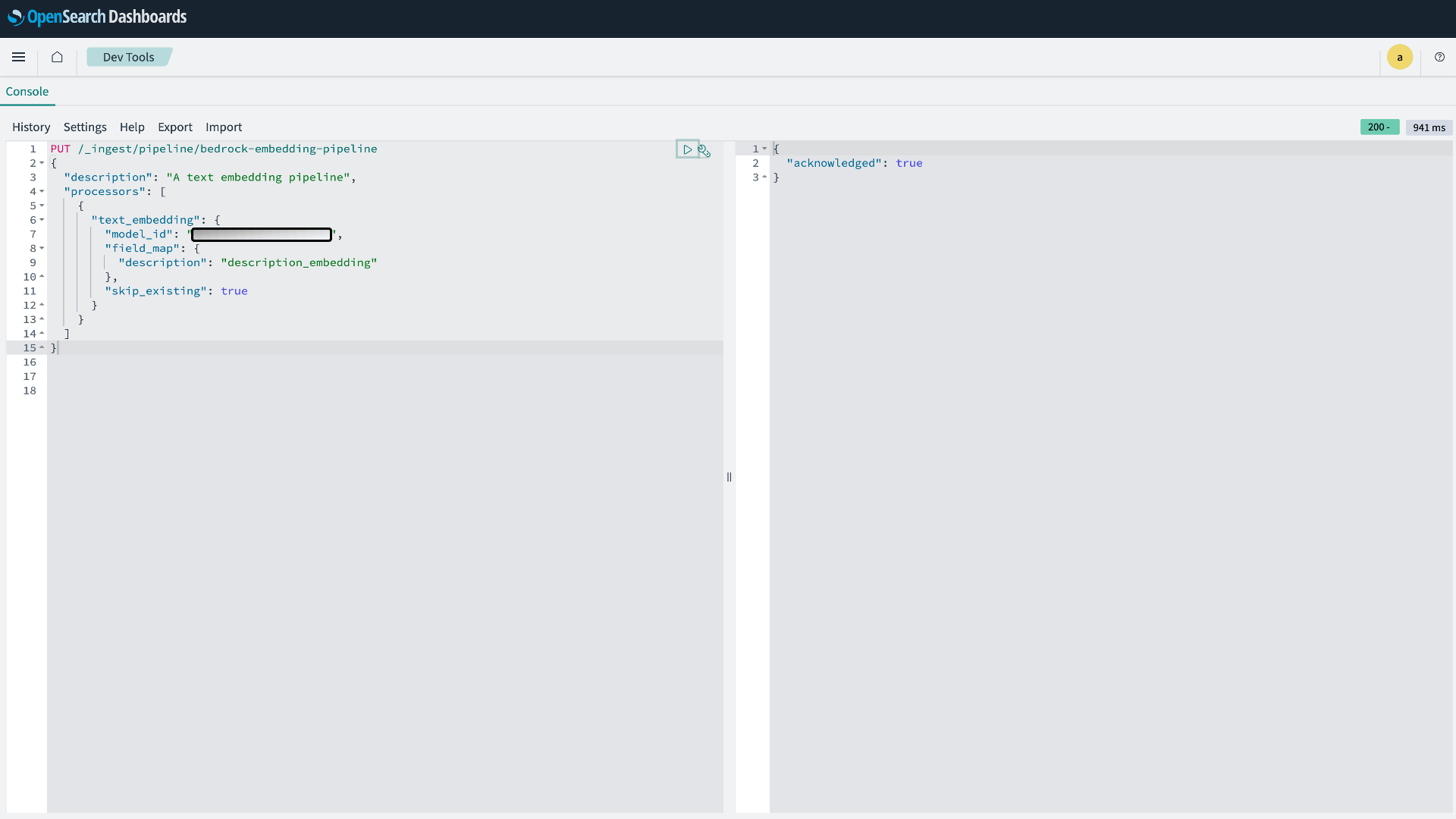
図 4:OpenSearch Ingest パイプラインの作成
ステップ 7:OpenSearch インデックステンプレートの準備
ユースケースのゼロ ETL 統合パイプラインをセットアップする前に、検索要件を分析し、最適なパフォーマンスのための適切なインデックステンプレートを設計します。
以下のガイドラインを検討してください:
- アクセスパターンを分析し、検索可能にする必要があるフィールドを決定し、適切なフィールドタイプを選択します。
product_idやcategoryのような正確な一致には keyword を使用します。- 全文検索機能には、アナライザー付きの text を使用します。
- タイムスタンプフィールドには date を使用します。
- フィールド選択を最適化するために、処理オーバーヘッドを削減するために必要なフィールドのみをインデックス化します。
- 特殊な検索ニーズに対してカスタムアナライザーを実装します。例えば、オートコンプリート機能には n-gram アナライザーを使用し、部分一致を可能にします。
- セマンティック検索要件を決定します。ビジネスユースケースに適したフィールドを埋め込みます。選択した埋め込みモデルとパフォーマンス要件に基づいて、適切な次元とアルゴリズムでベクトルフィールドマッピングを構成します。
以下は、マッピングテンプレートの例です:
{
"template": {
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1,
"knn": true,
"knn.algo_param.ef_search": 100,
"default_pipeline": "bedrock-embedding-pipeline"
},
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"stop"
]
},
"ngram_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"ngram_filter"
]
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 4,
"max_gram": 5
}
}
}
},
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "custom_analyzer",
"fields": {
"keyword": {
"type": "keyword"
},
"ngram": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"suggest": {
"type": "completion",
"analyzer": "simple"
}
}
},
"description": {
"type": "text",
"analyzer": "custom_analyzer"
},
"price": {
"type": "float"
},
"rating": {
"type": "float"
},
"category": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"brand": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"tags": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"specs": {
"properties": {
"color": {
"type": "keyword"
},
"size": {
"type": "keyword"
},
"weight": {
"type": "float"
},
"dimensions": {
"type": "keyword"
}
}
},
"stock": {
"type": "integer"
},
"created_at": {
"type": "date"
},
"updated_at": {
"type": "date"
},
"description_embedding": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {
}
}
}
}
}
}
}
ステップ 8:OpenSearch Ingestion パイプラインのセットアップ
- DynamoDB Service コンソールを開き、Integrations を選択し、統合を作成して Amazon OpenSearch を選択します。
- ソース(DynamoDB テーブル)の構成
- ドロップダウンから統合のソースとなる DynamoDB テーブルを選択します。
- Enable Stream
- Enable Export を有効にし、S3 Bucket、S3 region を構成します
- Configure processor(データ変換のためのプロセッサーをセットアップ)
- Configure sink(OpenSearch ドメイン):
- Choose a domain
- 「Index Name」として「products」と入力します。
- Customized Mapping を選択し、ステップ 7 で定義したテンプレートを使用します。
- 失敗したイベントをオフロードし、分析用にアクセス可能にするために、デッドレターキュー(DLQ)を有効にします。S3 バケット名とリージョンを入力します。
- Configure pipeline
- 一意のパイプライン名を入力します(現在の AWS アカウントの現在のリージョン内で)。
- 要件に応じてパイプライン容量を構成します。単一の Ingestion OpenSearch Compute Unit(OCU)は、課金可能なコンピューティングおよびメモリユニットを表します。データパイプラインの実行に使用される OCU の数に基づいて時間単位で課金されます。ベースラインとして、1 つの OCU は一般的なワークロードで最大 2 MiB/秒を処理できます。ワークロードに応じて最小および最大 OCU 容量を入力します。
- OpenSearch Ingestion は、他のサービスを代理で使用するための権限が必要です。Create and use a new service role を選択します。
- ステップ 4 と同様に、OSIS パイプラインの IAM ロールを OpenSearch all_access ロールのバックエンドロールとしてマッピングします。これにより、データインジェストのための安全できめ細かいアクセス制御が可能になります。
- Review and create
- すべての構成を確認します。
- Preview pipeline を選択し、yaml ファイルを確認します。
- Create Pipeline を選択してパイプラインを作成します。
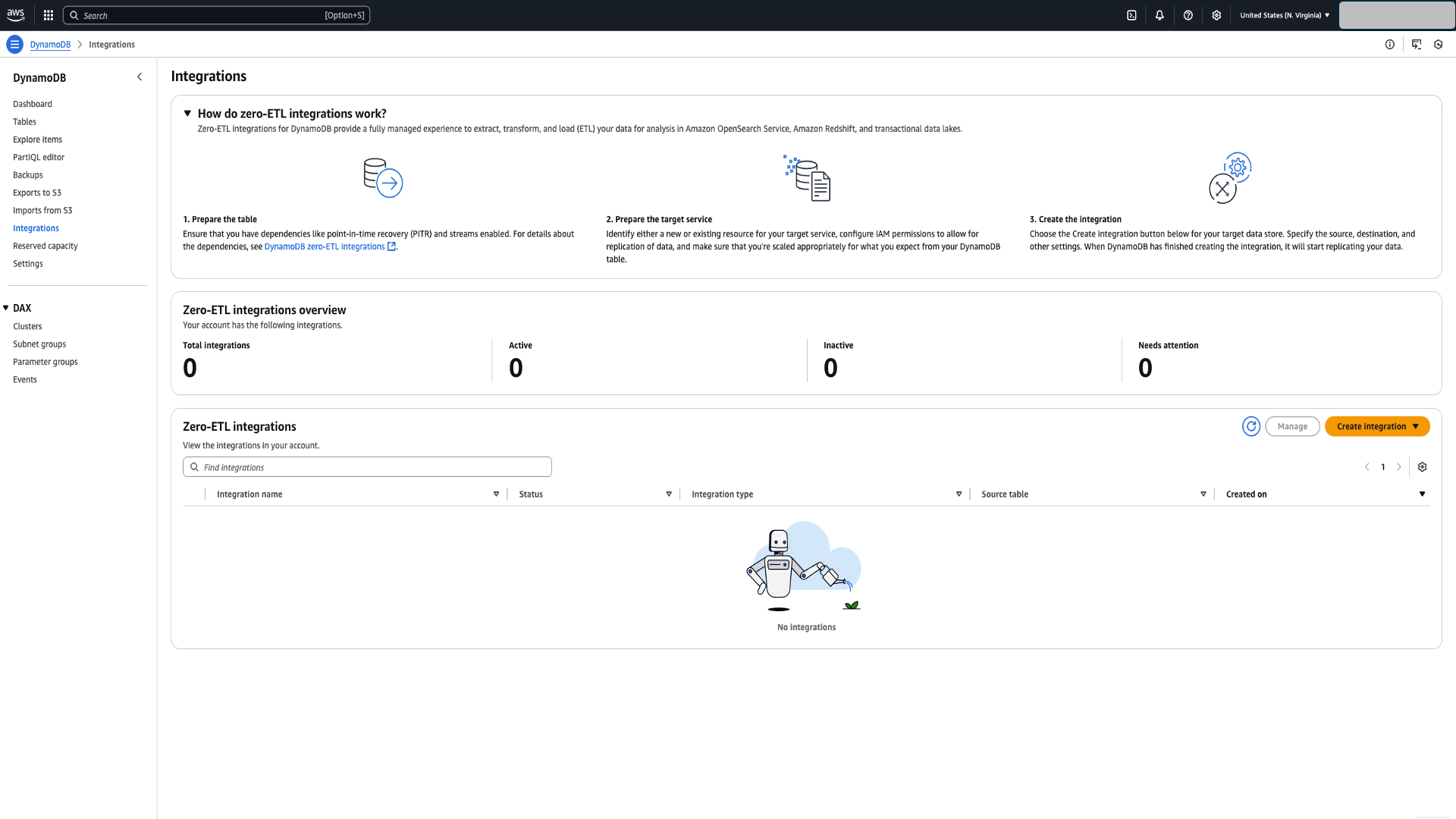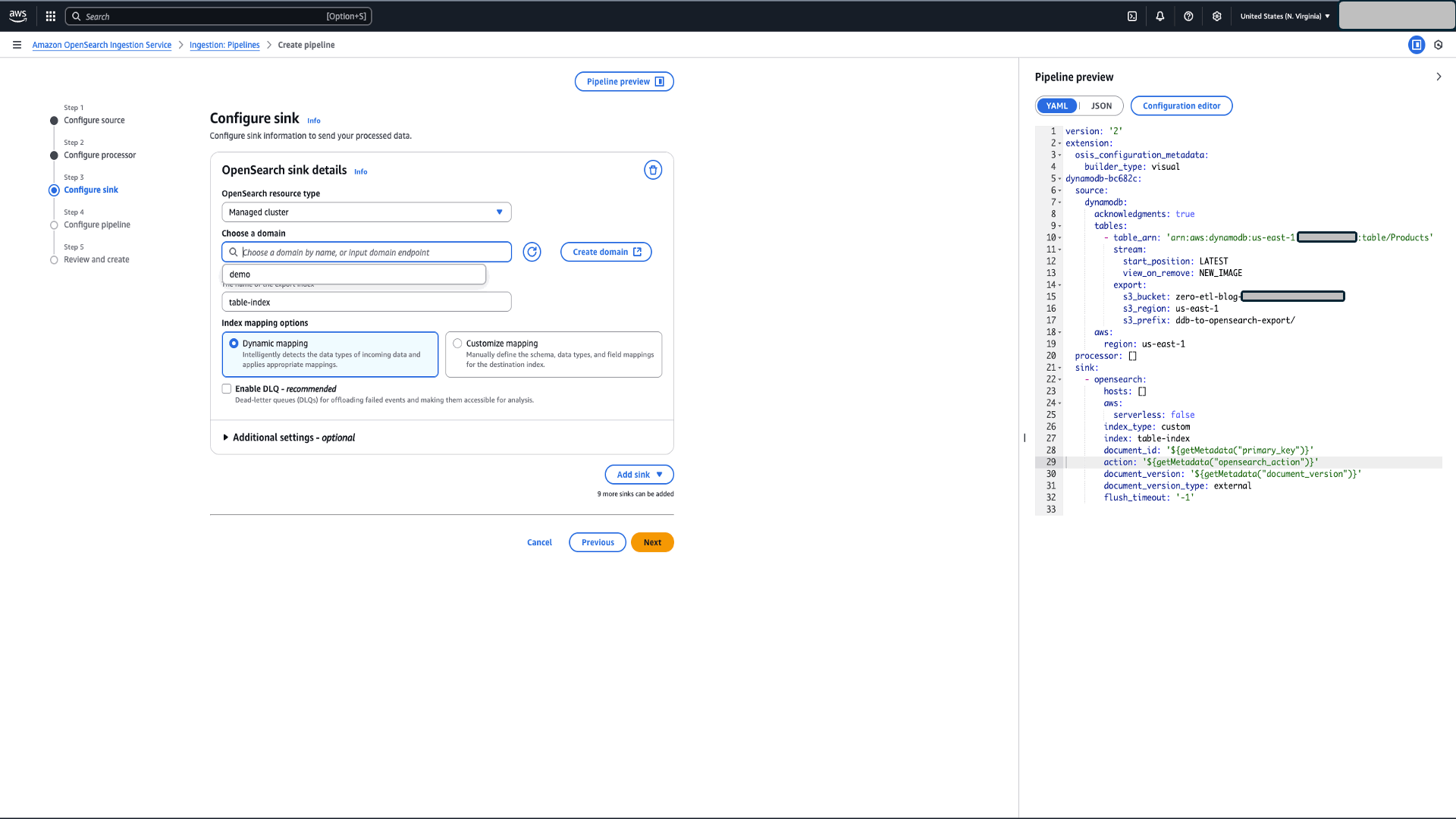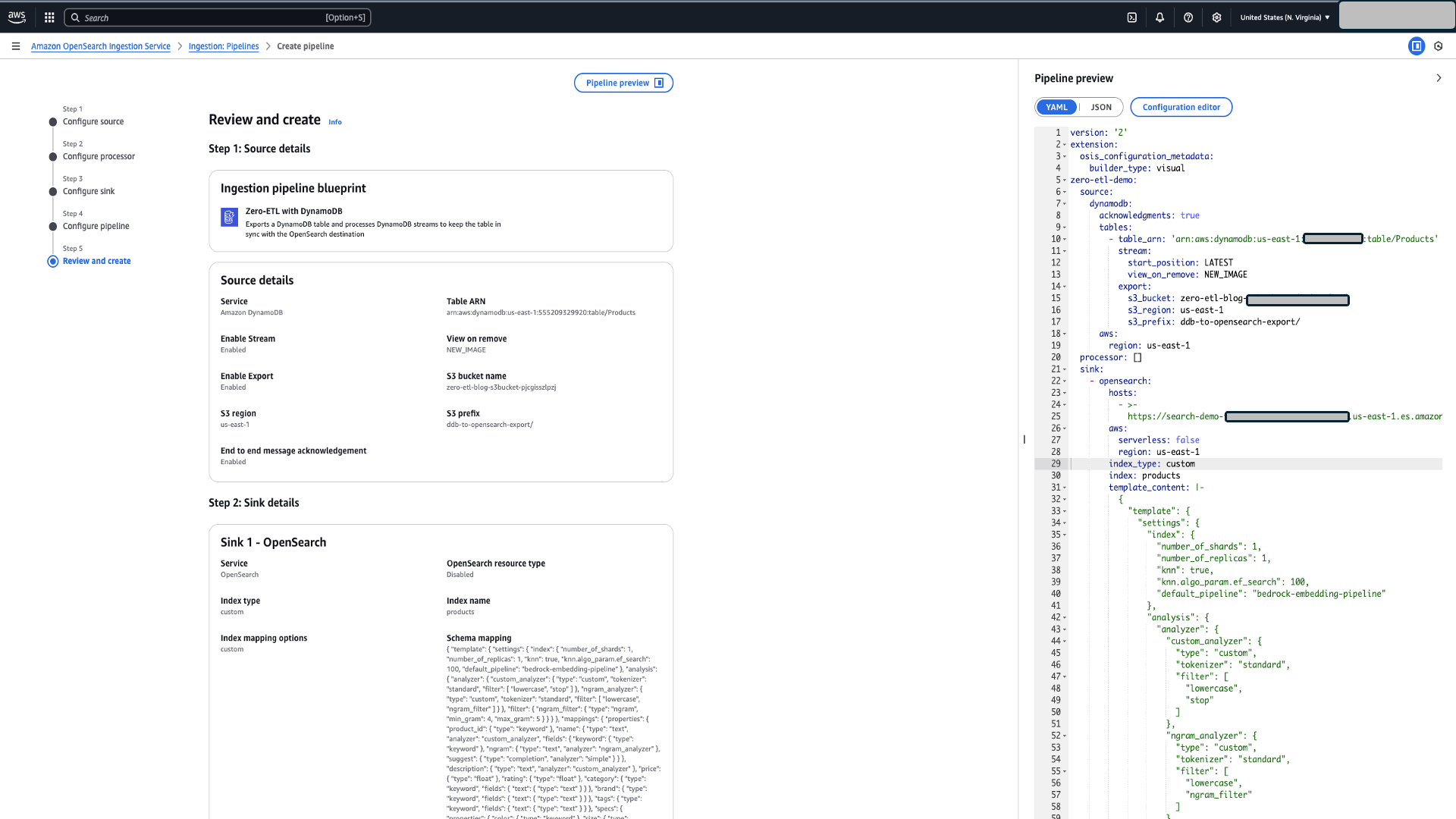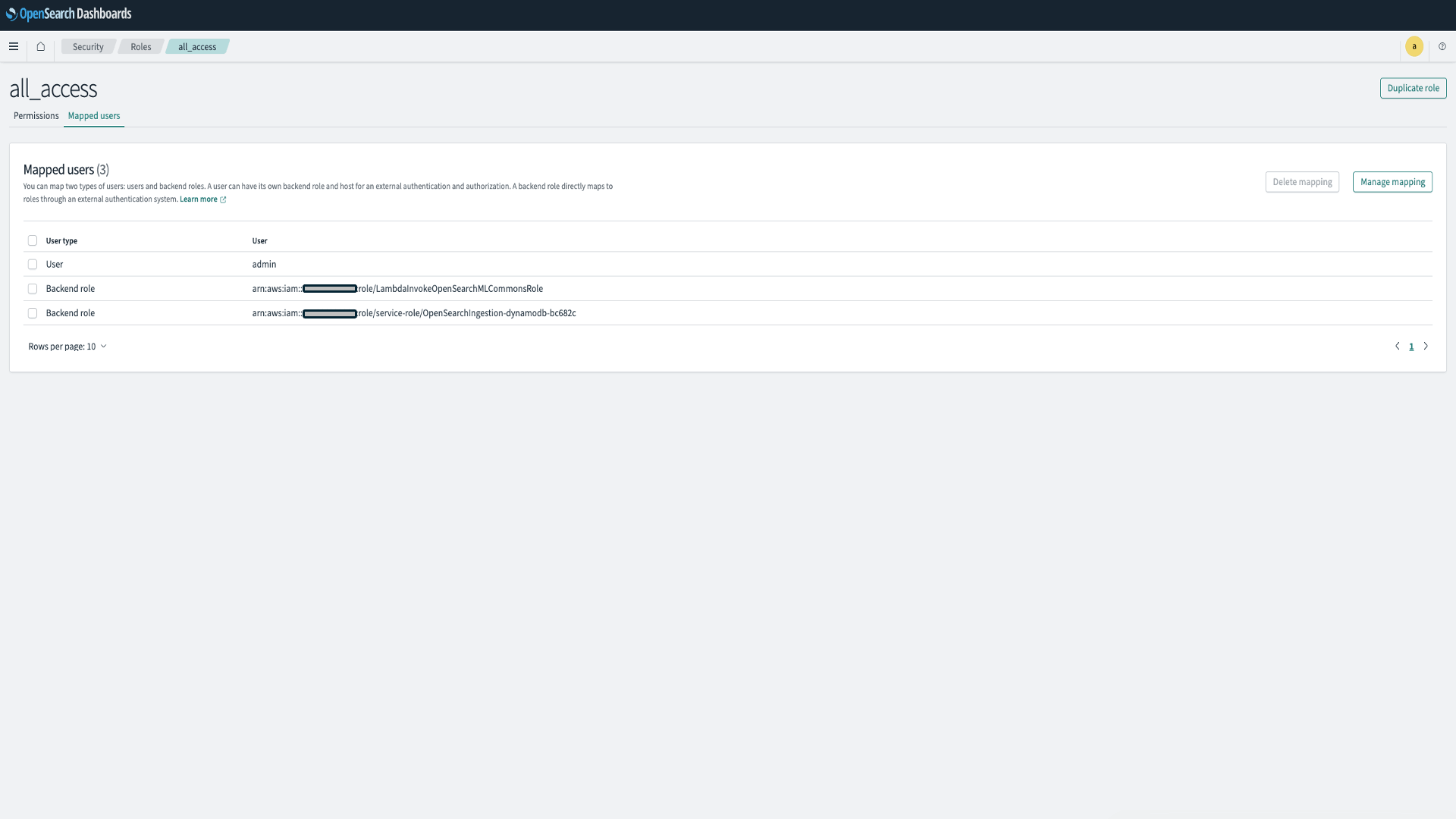
図 5:OpenSearch Ingestion パイプラインの作成
検証
ゼロ ETL 統合をセットアップした後、データが複製されていることをテストおよび検証できます。
- DynamoDB にサンプルアイテムを作成します。以下は、アイテムを作成するサンプルシェルスクリプトです:
#!/bin/bash for i in {1..10}; do colors=("red" "white" "green" "blue" "black") sizes=("XS" "S" "M" "L" "XL") products=("Hoodie" "Jacket" "Pants" "Shorts" "Sweater" "Joggers" "Tank Top" "Polo Shirt" "Vest" "Leggings") categories=("Activewear" "Men's Wear" "Women's Wear" "Loungewear" "Outerwear") brands=("AnyCompany1" " AnyCompany2" " AnyCompany3" " AnyCompany4" " AnyCompany5" " AnyCompany6") features=("Sustainably crafted" "Eco-friendly materials" "Ethically produced" "Premium quality" "Organic materials") color=${colors[$((RANDOM % 5))]} features=${features[$((RANDOM % 5))]} size=${sizes[$((RANDOM % 5))]} category=${categories[$((RANDOM % 5))]} brand=${brands[$((RANDOM % 6))]} product_name=${products[$((i - 1))]} timestamp=$(date -u +"%Y-%m-%dT%H:%M:%SZ") aws dynamodb put-item \ --table-name Products \ --region us-east-1 \ --item "{ \"product_id\": {\"S\": \"product_$i\"}, \"name\": {\"S\": \"$brand $product_name\"}, \"description\": {\"S\": \"$features $product_name - $category\"}, \"price\": {\"N\": \"$((100 + RANDOM % 400)).99\"}, \"rating\": {\"N\": \"4.$((RANDOM % 10))\"}, \"category\": {\"S\": \"$category\"}, \"brand\": {\"S\": \"$brand\"}, \"tags\": {\"L\": [{\"S\": \"organic\"}, {\"S\": \"sustainable\"}, {\"S\": \"eco-friendly\"}]}, \"specs\": {\"M\": { \"color\": {\"S\": \"$color\"}, \"size\": {\"S\": \"$size\"}, \"weight\": {\"N\": \"0.$((RANDOM % 9 + 1))\"}, \"dimensions\": {\"S\": \"$((RANDOM % 30 + 10))x$((RANDOM % 30 + 10))x$((RANDOM % 10 + 1))\"} }}, \"stock\": {\"N\": \"$((RANDOM % 200))\"}, \"created_at\": {\"S\": \"$timestamp\"}, \"updated_at\": {\"S\": \"$timestamp\"} }" && echo "✓ Created: product_id=$i" done echo "Done!" - ドメインの OpenSearch Dashboards URL に移動します。URL は OpenSearch Service コンソールのドメインダッシュボードで確認できます。
- 左側のナビゲーションパネルを開き、Dev Tools を選択します。
- OpenSearch へのデータフローを確認します。
//すべて検索 GET products/_search { "query": { "match_all": {} } } - セマンティックユースケースクエリを実行して、セマンティック要件を検証します。
GET products/_search { "query": { "neural": { "description_embedding": { "query_text": "sports", "model_id": "<ステップ 5 で取得した model_id に更新>" } } } }
この記事の前半で提供されたクエリを使用して、他のすべてのユースケースをテストできます。
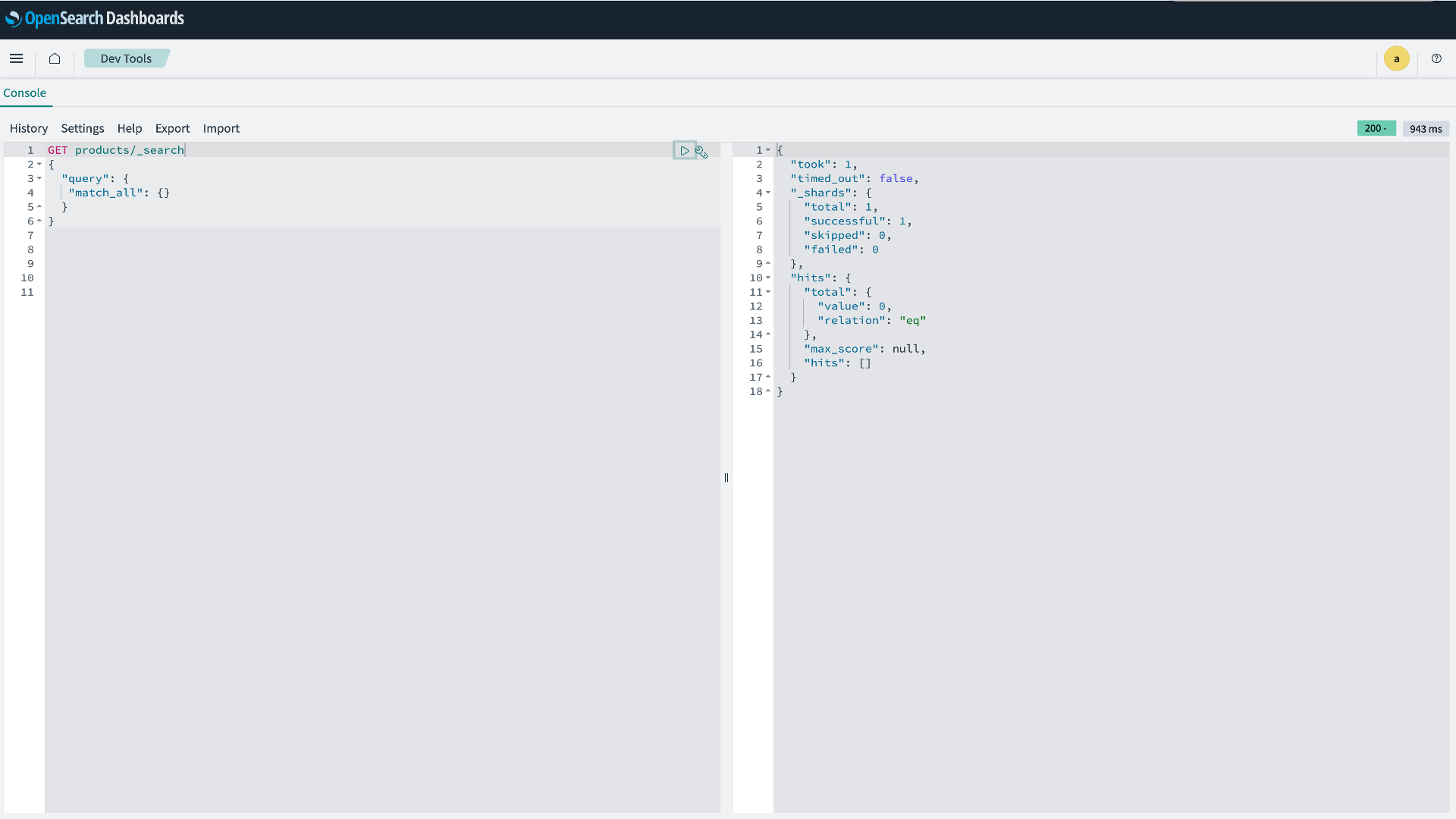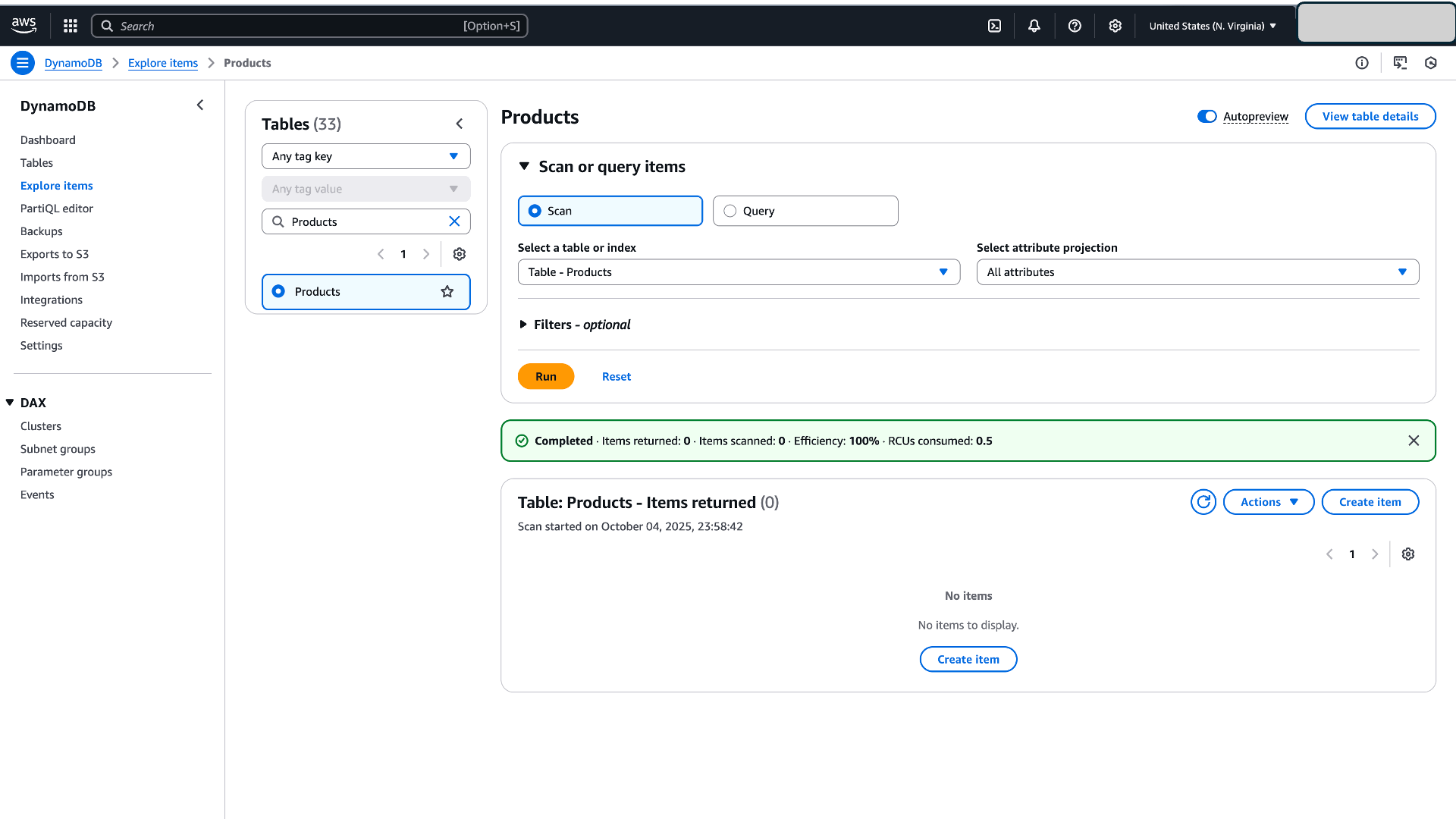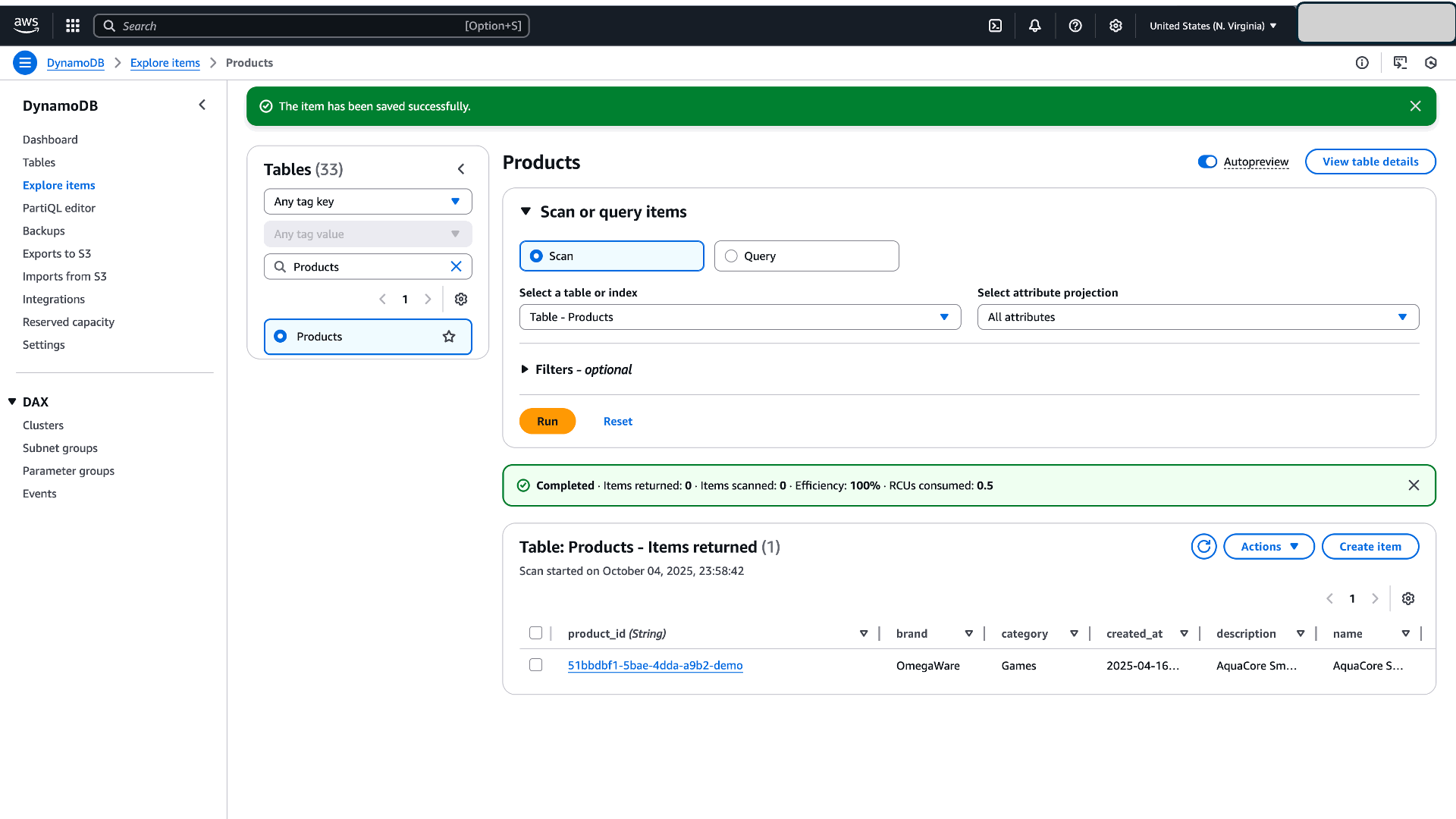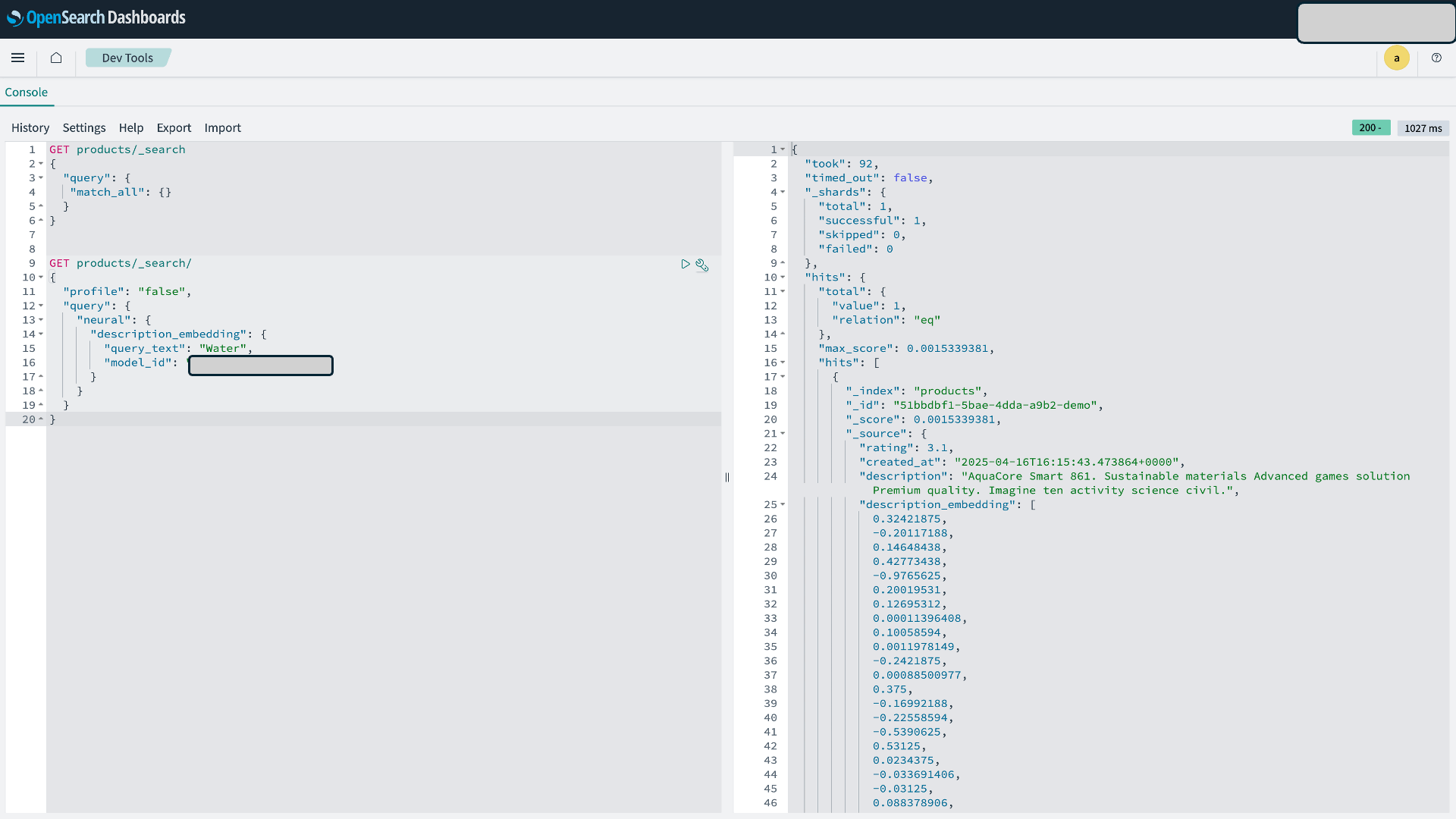
図 6:データ検証
パイプラインのセットアップを完了し、データ同期を検証した後、トランザクション操作を DynamoDB に保持しながら、検索クエリを OpenSearch Service にルーティングするようにアプリケーションコードをリファクタリングします。
具体的な実装は、アプリケーションアーキテクチャとプログラミング言語によって異なります。AWS SDK を使用して OpenSearch Service をクエリする手順については、AWS SDK を使用した Amazon OpenSearch Service との対話を参照してください。
ベストプラクティス
DynamoDB と OpenSearch Service 間のゼロ ETL 統合を実装する際は、以下のベストプラクティスを検討してください:
- OSIS パイプラインのソースオプションとして DynamoDB ストリームを使用します。これにより、完全な初期スナップショットを必要とせずに、新しいレコードまたは更新されたレコードのみがキャプチャされます。ストリーミングデータでパイプラインフローをテストしたら、エクスポートオプションを使用して完全なデータを移行します。
- Amazon VPC を使用して、パブリックインターネット経由ではなく、ネットワーク境界内で OpenSearch Ingestion パイプラインを通じてデータフローを強制します。
- 埋め込みがすでに含まれているフィールドに対する冗長な API 呼び出しを防ぐために、skip_existing フラグを有効にして、埋め込み生成インジェストパイプラインを最適化します。
- OpenSearch Service ドメインと OpenSearch Ingestion パイプラインの Amazon CloudWatch ログを有効にします。これにより、データフロー全体の可視性が提供され、問題を迅速に特定できます。ドメインレベルでログを構成して、検索クエリ、インデックス操作、クラスターヘルスメトリクスをキャプチャします。OpenSearch Ingestion パイプラインの場合、詳細なログを有効にして、データ変換とインジェストプロセスを監視します。
- インジェストパイプラインの DLQ を構成します。マッピングエラー、変換の問題、または一時的なサービスの問題によりドキュメントの処理が失敗した場合、DLQ はこれらの失敗したレコードをキャプチャして、後で分析および再処理できるようにします。これにより、データ損失が防止され、回復メカニズムが提供されます。
- AWS Key Management Service(AWS KMS)を使用して、DynamoDB テーブルと OpenSearch Service ドメインの両方で保存時の暗号化を有効にし、暗号化キーを完全に制御し、コンプライアンス要件を満たします。
- DynamoDB テーブルで削除保護を有効にして、重要なデータの誤削除を防ぎ、本番ワークロードに追加の安全層を提供します。
- 統合パイプラインの各コンポーネントに特定の IAM ロールとポリシーを作成して、最小権限アクセスを実装し、サービスが機能するために必要な権限のみを持つようにします。
- シャードサイジング、インスタンスタイプ、デプロイ構成を含む OpenSearch Service ドメインのサイジング推奨事項については、Amazon OpenSearch Service ドメインサイジングガイドを参照してください。
モニタリングとアラート
OpenSearch Ingestion は、パイプラインのパフォーマンスを監視するのに役立つメトリクスを公開します。パイプラインの健全性を監視する際は、以下の主要な領域に焦点を当ててください:
- データインジェストをブロックする可能性のある認証の問題。
- データ損失につながる可能性のあるドキュメント処理の失敗。
- データ処理を遅くする可能性のある容量のボトルネック。
- アプリケーションの応答時間に影響を与えるパフォーマンスの低下。
- Bedrock 固有の監視については、モデル呼び出しのレイテンシー、スロットリング、トークン使用量のメトリクスに特に注意してください。
これらの領域を積極的に監視することで、DynamoDB から OpenSearch Service への信頼性の高いデータフローを維持し、検索機能の応答性を確保できます。これらの問題を早期に検出するために CloudWatch アラートを設定し、ユーザーに影響を与える前にプロアクティブなアクションを実行できるようにします。
ログとモニタリングの詳細とベストプラクティスについては、Amazon OpenSearch Ingestion のベストプラクティスおよび Amazon Bedrock モニタリングのドキュメントを参照してください。
コストに関する考慮事項
OpenSearch Ingestion を使用した DynamoDB から OpenSearch Service への統合を計画する際は、Amazon CloudWatch メトリクスを通じて DynamoDB の書き込みスループットを分析します。DynamoDB テーブルの書き込みアクティビティは DynamoDB Streams にレコードを生成し、OpenSearch Ingestion パイプラインがそれを消費します。最小、最大、平均の書き込みリクエストユニット(WRU)を理解することで、OpenSearch Ingestion パイプラインを適切にサイジングできます。この記事の執筆時点では、OpenSearch Ingestion パイプラインは 1 から 96 の OpenSearch Compute Unit(OCU)にスケーリングできます。ベースラインとして、1 つの OCU は一般的なワークロードで最大 2 MiB/秒を処理できますが、データサイズ、パイプライン変換、OpenSearch Service ドメインのサイズとインデックス/シャード戦略によって異なる場合があります。
例えば、テーブルが 1 秒あたり 20,000 WRU を処理する場合、このスループットを効率的に処理するには最低 10 OCU が必要です。総コストには、DynamoDB Streams の料金(100,000 読み取りリクエストあたり $0.02)、OpenSearch Service クラスターのコスト(インスタンスタイプとストレージに基づく)、OpenSearch Ingestion パイプラインのコスト(OCU 時間あたりの価格)、および通常の DynamoDB コストが含まれます。DynamoDB から OpenSearch パイプラインにリモート推論用の Amazon Bedrock を組み込む場合は、どのフィールドに埋め込みが必要かを評価し、処理するテキストデータの量を見積もります。レコード数、テキストフィールドのサイズ、更新頻度に基づいて、予想されるトークン使用量を計算します。コスト構造は、選択した基盤モデルによって異なるトークンごとの従量課金モデルに従います。
クリーンアップ
継続的な料金の発生を避けるために、このソリューションで作成したリソースを削除または無効化します。AWS 環境をクリーンアップするには、次の手順に従ってください:
- CloudFormation スタックを削除します:
- CloudFormation コンソールを開きます。
- モデルアクセス用に作成したスタックを選択します。
- Delete を選択し、削除を確認します。
- OpenSearch リソースを削除します:
- Amazon OpenSearch Ingestion コンソールを開き、パイプラインを削除して OSIS パイプラインを削除します。
- Amazon OpenSearch Service コンソールを通じて OpenSearch ドメインを削除します。
- DynamoDB テーブル(Products)を削除します。
- デッドレターキュー(DLQ)と DynamoDB エクスポートに使用した S3 バケットを空にします。
これらの手順を完了したら、各サービスコンソールで、すべてのリソースが適切に削除または無効化されていることを確認してください。
まとめ
この記事では、Amazon DynamoDB データに対する検索を Amazon OpenSearch Service とのゼロ ETL 統合を使用して実装する方法を紹介しました。
AnyCompany の例を通じて、この統合が実際の検索課題(顧客のタイプミスやセマンティッククエリの処理から、ファセット検索やマルチフィールド検索の有効化まで)にどのように対処するかを実証しました。
Amazon OpenSearch Service ドキュメントと DynamoDB ゼロ ETL 統合ガイドを探索して、独自の環境でこれらの機能の実装を開始してください。
本記事は 2026 年 02 月 18 日 に公開された “Implementing search on Amazon DynamoDB data using zero-ETL integration with Amazon OpenSearch service” を翻訳したものです。
著者について
Varun Sharma
Varun は、AWS Professional Services チームで働くシニアデリバリーコンサルタントです。
Vamsi Krishna Ganti
Vamsi は、AWS Professional Services チームで働くシニアデリバリーコンサルタントです。
Sudhansu Mohapatra
Sudhansu は、AWS Professional Services チームで働くデリバリーコンサルタントです。