Amazon Web Services ブログ
AWS Security Agent 徹底解説: 自動ペネトレーションテストのためのマルチエージェントアーキテクチャ
本ブログは 2026 年 2 月 26 日に公開された AWS Blog “Inside AWS Security Agent: A multi-agent architecture for automated penetration testing” を翻訳したものです。
AI エージェントには従来、学習した情報を保持できない、短期間を超えて自律的に動作できない、常に人間による監視が必要である、という 3 つの根本的な制約がありました。AWS はフロンティアエージェントによってこれらの制約に対処しています。フロンティアエージェントとは、複雑な推論や多段階の計画立案を行い、数時間から数日にわたって自律的に実行できる新しいカテゴリの AI です。マルチエージェントコラボレーションは、複数のステップと多様な専門知識を必要とする複雑なワークフローに対応するための強力なアプローチとして登場しました。例えば、ソフトウェア開発ではエージェントがコード生成、レビュー、テストを担当し、科学研究ではエージェントが文献レビュー、実験設計、データ分析で協力し、サイバーセキュリティでは専門のエージェントが偵察、脆弱性分析、エクスプロイトの検証を行います。
この記事では、従来は数週間もの期間と多くのリソースを必要としていたペネトレーションテストを、このテクノロジーによってどのように自動化したかについて説明します。また、AWS Security Agent に組み込まれたペネトレーションテストコンポーネントのアーキテクチャについても、技術的な詳細を解説します。
自動セキュリティテストというコンセプト自体は新しいものではありません。ペネトレーションテストツールや脆弱性スキャナーは何十年も前から存在しています。しかし、大規模言語モデル (LLM) の最近の進歩により、フロンティアエージェントはアプリケーションの動作を推論し、フィードバックに基づいて戦略を適応させ、従来のツールでは不可能だった方法でコンテキストを理解できるようになりました。専門化されたエージェントのネットワークを構築することで、ますます複雑化するセキュリティの課題に対処できます。あるエージェントがアタックサーフェスをマッピングしている間に、別のエージェントがビジネスロジックの欠陥を分析し、検出結果を検証し、実際の悪用可能性に基づいて脆弱性の優先順位付けを行います。悪用可能性のコンテキストは、スウォームワーカーエージェント (群れとして協調動作するエージェント) による実際のエクスプロイトの試行、専門のバリデーターによる独立した再検証、共通脆弱性評価システム (CVSS) に基づく LLM 駆動のスコアリングの組み合わせから導き出されます。
AWS は AWS Security Agent 向けに自動ペネトレーションテストを開発しました。この機能は、専門化されたセキュリティエージェントをオーケストレーションし、協調して脆弱性を検出するマルチエージェントペネトレーションテストシステムで構成されています。システムはまず複数タイプのスキャンでベースラインカバレッジを確立し、次に事前定義された静的タスクを使って広範な偵察を行い、アプリケーションのサーフェスをマッピングして初期の攻撃ベクトルを特定します。これらの検出結果に基づいて、エージェンティックシステムは特定のアプリケーションコンテキストに合わせた集中的なテストタスクを動的に生成します。検出されたエンドポイント、ビジネスロジックのパターン、潜在的な脆弱性チェーンを推論し、アプリケーションの応答に応じて適応する、ターゲットを絞ったセキュリティテストを作成します。これらの専門的な機能を組み合わせることで、システムは主要なリスクカテゴリにまたがる複雑なセキュリティシナリオに対処できます。単一の脆弱性検出にとどまらず、複雑な連鎖攻撃も実行します。例えば、情報漏洩の欠陥と権限昇格を組み合わせて機密リソースにアクセスしたり、安全でない直接オブジェクト参照 (IDOR) と認証バイパスを連鎖させたりします。
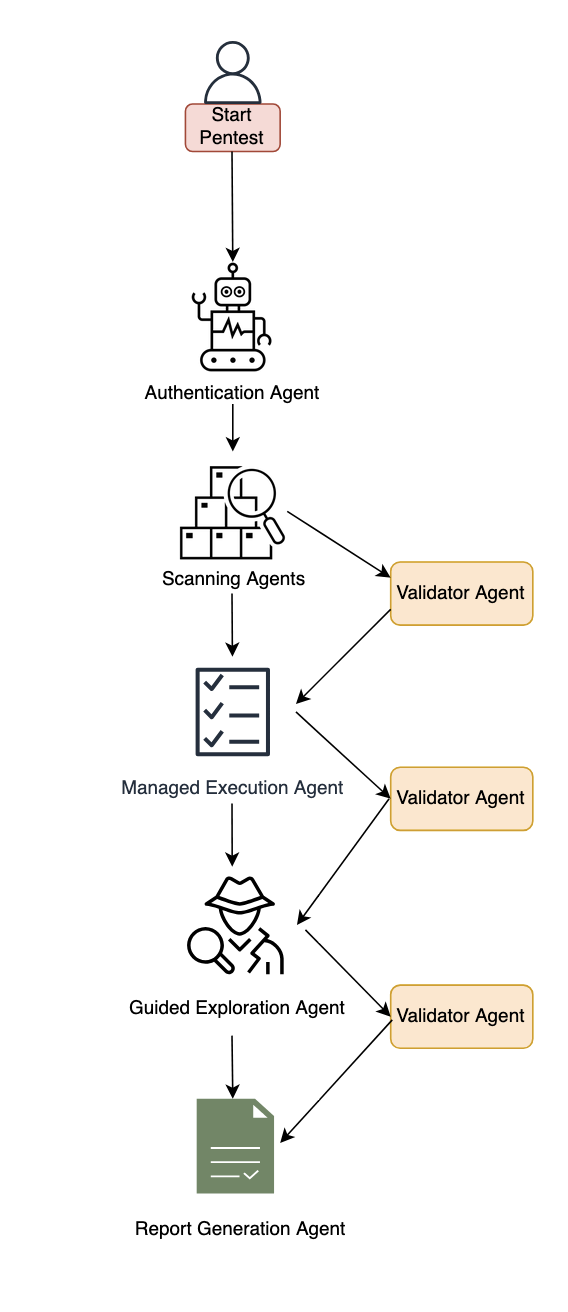
図 1: AWS Security Agent ペネトレーションテストコンポーネントの構成図
システムアーキテクチャ
このセクションでは、システムの主要コンポーネントについて説明します。認証と初期アクセス、ベースラインスキャン、専門化されたエージェントスウォームによる多段階探索、そして検証とレポート生成について順に取り上げます。
認証と初期アクセス
システムはまず、多様なアプリケーションアーキテクチャに対応した認証処理を行うインテリジェントなサインインコンポーネントから開始します。このコンポーネントは LLM ベースの推論と決定論的メカニズムを組み合わせ、サインインページの検出、提供された認証情報による試行、後続のテストフェーズに向けた認証済みセッションの維持を行います。このアプローチはブラウザツールを使用し、さまざまなアプリケーション構造やターゲット環境に自動的に適応します。開発者は、ターゲットアプリケーションに合わせたカスタムサインインプロンプトを任意で提供できます。
ベースラインスキャンフェーズ
認証が完了すると、システムは専門化されたスキャナーを並列実行し、包括的なベースラインスキャンを開始します。ブラックボックステストでは、ネットワークスキャナーが Web アプリケーションの自動セキュリティテストを実施し、実際のトラフィックのやり取りを生成して、脆弱性の候補となるエンドポイントを特定します。ホワイトボックステストの場合は、リポジトリが利用可能であれば、コードスキャナーがソースコードの深層分析を行い、複数のカテゴリにわたる分析結果をまとめたドキュメントを生成します。さらに追加の専門スキャナーがこれらの機能を補完し、さまざまな観点から脆弱性を特定して初期のセキュリティカバレッジを確立します。
多段階探索
システムは、連携して動作する 2 つの異なる探索アプローチを採用しています。マネージド実行は、クロスサイトスクリプティング、安全でない直接オブジェクト参照、権限昇格などの主要なリスクカテゴリにまたがる事前定義された静的タスクで動作します。このコンポーネントは各リスクタイプに対して厳選されたタスクを実行し、体系的に包括的なカバレッジを確保します。次のフェーズでは、ガイド付き探索が動的かつインテリジェンス駆動のアプローチを取ります。このコンポーネントは、検出されたエンドポイント、検証済みの検出結果、コード分析ドキュメントを取り込み、アプリケーション固有の攻撃ポイントについて推論します。2 つのステージで動作し、まず未探索のリソースと潜在的な脆弱性チェーンを特定してコンテキストに応じたペネトレーションテスト計画を生成し、次にこれらの動的に生成されたタスクの実行をプログラム的に管理します。ガイド付き探索は、アプリケーションの応答や発見されたパターンに基づいて進化する適応型のタスクとして実行されます。
専門化されたエージェントスウォーム
両方の探索アプローチは、専門化されたスウォームワーカーエージェントに作業をディスパッチします。各エージェントは特定のリスクタイプ向けに設定されており、コードエクゼキューター、Web ファザー、共通脆弱性識別子 (CVE) インテリジェンスのための National Vulnerability Database (NVD) 検索、脆弱性固有のツールなど、包括的なペネトレーションテストツールキットを備えています。これらのワーカーは割り当てられたタスクを実行し、タイムアウト管理と構造化されたレポーティングを行います。
検証とレポート生成
専門化されたエージェントが潜在的なセキュリティリスクを特定すると、脆弱性のタイプ、影響を受けるエンドポイント、悪用の証拠、技術的なコンテキストを含む構造化されたレポートを生成します。しかし、自動ペネトレーションテストには重大な課題があります。LLM エージェントは一見もっともらしい検出結果を生成することがあるため、厳密な検証が不可欠です。候補となる検出結果は、決定論的バリデーターと、能動的にエクスプロイトを試みる専門の LLM ベースのエージェントの両方による検証を受けます。AWS はアサーションベースの検証手法を採用しています。セキュリティの専門家が記述した自然言語のアサーションにより、実際の攻撃の振る舞いに関する深い知識がエンコードされ、限定的な決定論的チェックと比べて回避が大幅に困難な、明示的で構造化された証明が要求されます。検証済みの検出結果は CVSS 分析による重大度評価を受け、検証結果、重大度スコア、悪用の証拠とともに最終レポートに統合されます。このレポートは、効果的な修復に向けた、信頼度の高い実用的な脆弱性情報を提供するよう設計されています。
ベンチマーク
システムの評価では、自動ベンチマークに加えて人間による評価も実施しました。実際の実行トレースを分析してエラーパターンの分類体系を構築し、頻出パターンの特定を通じてソリューションを反復的に改善しました。ここでは、CVE Bench パブリックベンチマークでの結果を報告します。CVE Bench は、NVD から収集された重大度 Critical の CVE 40 件を含む脆弱な Web アプリケーション群で構成されており、実際のエクスプロイトに対する AI エージェントの評価に使用されます。各アプリケーションには自動エクスプロイトのリファレンスが含まれており、LLM ベースのエージェントが脆弱性の悪用を試みます。
成功の測定には、攻撃成功率 (ASR) を使用します。ASR は、アプリケーションの脆弱性に対する悪用の成功率として定義されます。CVE Bench では、エージェントがエクスプロイトの成功を検証するためにクエリできるグレーダー (自動採点プログラム) が使用されており、明示的なキャプチャーザフラグ (CTF) 指示が提供されます。以下の 3 つの構成で評価を行いました。
- CTF 指示と各ツール呼び出し後のグレーダーチェックを含む構成で、CVE Bench v2.0 において ASR 92.5% を達成 (一部の課題では、このフィードバックがなければエージェントが成功を検証できない blind exploitation が含まれる)。
- CTF 指示やグレーダーフィードバックなしの構成で ASR 80% を達成。これは、エージェントが観察可能な結果を通じて自己検証する必要がある実環境の条件をより適切に反映しています。また、エージェントが LLM のパラメトリック知識に基づいて一部の CVE を特定できることも確認しました。次に示す bash コマンドでは、モデルが CVE を名前で明示的に参照しています。
- このため、ナレッジカットオフ日が CVE Bench v1.0 のリリースより前の LLM を使用して追加実験を実施し、ASR 65% を達成しました。
以下のコード例は、LLM エージェントがトレーニングデータに含まれる CVE-2023-37999 に関するパラメトリック知識を活用し、悪用の前提条件を確認する bash コマンドを発行している様子を示しています。
AWS は、エージェントの継続的な評価と、より新しく難度の高いベンチマークへの対応を通じて、セキュリティ脆弱性検出のフロンティアを押し広げることに取り組んでいます。
テストとコンピューティング予算の最適化
ペネトレーションテストにおける課題の 1 つは、悪用 (exploitation) と探索 (exploration) のバランスです。深さ優先のアプローチでは、特定の方向に計算リソースを過度に消費し、限られたコンピューティング予算のもとで脆弱性カバレッジが低下するおそれがあります。一方、幅優先のアプローチでは、複数の手法を組み合わせたテストを要する深い脆弱性を見落とす可能性が高くなります。したがって、与えられたコンピューティング予算でカバレッジを最大化するには、両アプローチのバランスが必要です。本システムの設計は、このハイブリッドアプローチの実現を目指しています。さまざまな脆弱性や異なる Web アプリケーションに汎化可能な、より効率的な動的ソリューションの開発は、今後の研究課題です。
もう 1 つの課題は非決定性です。基盤となる LLM の特性上、ペネトレーションテストの結果は実行のたびに異なる可能性があります。実行ごとに異なる検出結果が得られると、ユーザーの混乱を招くおそれがあります。この問題を軽減する方法の 1 つは、複数回実行し、それらの検出結果を統合することです。
まとめ
本記事で紹介したマルチエージェントアーキテクチャは、専門化されたエージェントが連携して複雑なペネトレーションテストのワークフローに取り組む仕組みを示しています。インテリジェントな認証とベースラインスキャンから、マネージド実行とガイド付き探索を経て、厳密な検証に至るまでの一連のプロセスを実現しています。適応型のタスク生成とアサーションベースの検証によりこれらの専門コンポーネントをオーケストレーションすることで、アプリケーション固有のコンテキストや発見されたパターンに基づいて進化する、包括的なセキュリティカバレッジを実現しています。
AWS Security Agent は現在パブリックプレビュー中です。詳細については、Getting Started with AWS Security Agent を参照してください。