Amazon Web Services ブログ
AWS Glue Data Catalog での Apache Iceberg マテリアライズドビューのご紹介
本記事は 2025 年 12 月 9 日 に公開された「Introducing Apache Iceberg materialized views in AWS Glue Data Catalog」を翻訳したものです。
数十万のお客様が AWS 上で人工知能と機械学習 (AI/ML) およびアナリティクスアプリケーションを構築しており、クエリパフォーマンスを向上させるために、生データから処理済みデータセット、最終的な分析テーブルまで、複数のステージを経てデータを変換しています。データエンジニアは、ベーステーブルで変更されたデータの検出、変換ロジックの作成と保守、依存関係を考慮したワークフローのスケジューリングとオーケストレーション、コンピューティングインフラストラクチャのプロビジョニングと管理、パイプラインの健全性を監視しながらの障害のトラブルシューティングなど、複雑な問題を解決する必要があります。
例えば、E コマース企業での分析ユースケースで、データエンジニアがクリックストリームログと注文データを継続的にマージする必要がある状況を考えてみましょう。各変換には、堅牢な変更検出メカニズムの構築、複雑な結合と集計の作成、複数のワークフローステップの調整、コンピューティングリソースの適切なスケーリング、運用の監視が必要です。これらすべてを、データ品質とパイプラインの信頼性をサポートしながら行う必要があります。この複雑さには数か月の専任エンジニアリング作業と継続的なメンテナンスが必要であり、データから洞察を得ようとする組織にとって、データ変換はコストと時間がかかるものとなっています。
これらの課題に対処するため、AWS は AWS Glue Data Catalog の Apache Iceberg テーブル向けの新しいマテリアライズドビュー機能を発表しました。この新しいマテリアライズドビュー機能は、データパイプラインを簡素化し、データレイクのクエリパフォーマンスを向上させます。マテリアライズドビューは、AWS Glue Data Catalog 内のマネージドテーブルであり、クエリの事前計算結果を Iceberg 形式で保存し、基盤となるデータセットの変更を反映するために増分更新されます。これにより、変換されたデータセットを生成してクエリパフォーマンスを向上させるための複雑なデータパイプラインの構築と保守が不要になります。Amazon Athena、Amazon EMR、AWS Glue の Apache Spark エンジンは、新しいマテリアライズドビューをサポートし、パフォーマンスを向上させながらコンピューティングコストを削減するマテリアライズドビューを使用するようにクエリをインテリジェントに書き換えます。
この記事では、Iceberg マテリアライズドビューの仕組みと使い始め方を紹介します。
Iceberg マテリアライズドビューの仕組み
Iceberg マテリアライズドビューは、使い慣れた SQL 構文に基づいたシンプルなマネージドソリューションを提供します。複雑なパイプラインを構築する代わりに、Spark から標準の SQL クエリを使用してマテリアライズドビューを作成し、カスタムデータパイプラインを作成することなく、集計、フィルター、結合でデータを変換できます。変更検出、増分更新、ソーステーブルの監視は AWS Glue Data Catalog で自動的に処理され、新しいデータが到着するとマテリアライズドビューが更新されるため、手動でのパイプラインオーケストレーションが不要になります。データ変換はフルマネージドのコンピューティングインフラストラクチャで実行されるため、サーバーのプロビジョニング、スケーリング、メンテナンスの負担がなくなります。
結果として得られる事前計算データは、お客様のアカウント内の Amazon Simple Storage Service (Amazon S3) 汎用バケット、または Amazon S3 Tables バケットに Iceberg テーブルとして保存され、変換されたデータは Athena、Amazon Redshift、AWS 最適化 Spark ランタイムなど、複数のクエリエンジンからすぐにアクセスできます。Athena、Amazon EMR、AWS Glue の Spark エンジンは、マテリアライズドビューをインテリジェントに使用する自動クエリ書き換え機能をサポートしており、データ処理ジョブやインタラクティブなノートブッククエリのパフォーマンスを自動的に向上させます。
以下のセクションでは、マテリアライズドビューの作成、クエリ、更新の手順を説明します。
前提条件
この記事に沿って進めるには、AWS アカウントが必要です。
Amazon EMR で手順を実行するには、以下のステップを完了してクラスターを設定します。
- Amazon EMR クラスター 7.12.0 以上を起動します。
- Amazon EMR クラスターのプライマリノードに SSH ログインし、以下のコマンドを実行して必要な設定で Spark アプリケーションを起動します。
AWS Glue for Spark で手順を実行するには、以下のステップを完了してジョブを設定します。
- AWS Glue バージョン 5.1 以上のジョブを作成します。
- ジョブパラメータを設定します。
- キー:
--conf - 値:
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
- キー:
- 以下のスクリプトでジョブを設定します。
- 以下のクエリを Spark SQL で実行してベーステーブルをセットアップします。AWS Glue では、
spark.sql("QUERY STATEMENT")を通じて実行できます。
以降のセクションでは、このベーステーブルを使用してマテリアライズドビューを作成します。
マテリアライズドビューを汎用 Amazon S3 バケットではなく Amazon S3 Tables に保存する場合は、この記事の最後にある付録 1 で設定の詳細を参照してください。
マテリアライズドビューの作成
マテリアライズドビューを作成するには、以下のコマンドを実行します。
マテリアライズドビューを作成した後、Spark のインメモリメタデータキャッシュが新しいマテリアライズドビューの情報を反映するまで時間がかかります。このキャッシュ構築期間中、ベーステーブルに対するクエリはマテリアライズドビューを使用せずに通常どおり実行されます。キャッシュが完全に構築された後 (通常は数十秒以内)、Spark はクエリにマテリアライズドビューが適用できることを自動的に検出し、事前計算されたマテリアライズドビューを使用するようにクエリを書き換えて、パフォーマンスを向上させます。
この動作を確認するには、マテリアライズドビューを作成した直後に以下の EXPLAIN コマンドを実行します。
以下の出力は、キャッシュ構築前の初期結果を示しています。
この初期実行プランでは、Spark は base_tbl を直接スキャン (BatchScan glue_catalog.iceberg_mv.base_tbl) し、生データに対して集計 (COUNT と SUM) を実行しています。これはマテリアライズドビューのメタデータキャッシュが構築される前の動作です。
メタデータキャッシュの構築のために約数十秒待った後、同じ EXPLAIN コマンドを再度実行します。以下の出力は、キャッシュ構築後のクエリ最適化プランの主な違いを示しています。
キャッシュが構築された後、Spark はベーステーブルではなくマテリアライズドビュー (BatchScan glue_catalog.iceberg_mv.mv) をスキャンするようになりました。クエリは、マテリアライズドビュー内の事前計算された集計データから読み取るように自動的に書き換えられています。出力では、集計関数が生データから COUNT と SUM を再計算するのではなく、事前計算された値を単純に合計 (sum(mv_order_count) と sum(mv_total_amount)) していることがわかります。
自動更新スケジュール付きのマテリアライズドビューの作成
デフォルトでは、新しく作成されたマテリアライズドビューには初期クエリ結果が含まれています。基盤となるベーステーブルのデータが変更されても自動的には更新されません。マテリアライズドビューをベーステーブルのデータと同期させるには、自動更新スケジュールを設定できます。自動更新を有効にするには、マテリアライズドビューを作成するときに REFRESH EVERY 句を使用します。この句は時間間隔と単位を受け入れるため、マテリアライズドビューが更新される頻度を指定できます。
以下の例では、24 時間ごとに自動更新されるマテリアライズドビューを作成します。
更新間隔は、SECONDS、MINUTES、HOURS、DAYS のいずれかの時間単位を使用して設定できます。データの鮮度要件とクエリパターンに基づいて適切な間隔を選択してください。
マテリアライズドビューの更新タイミングをより細かく制御したい場合や、スケジュールされた間隔外で更新する必要がある場合は、いつでも手動更新をトリガーできます。フル更新と増分更新を含む手動更新オプションの詳細な手順は、この記事の後半で説明します。
マテリアライズドビューへのクエリ
Amazon EMR クラスターでマテリアライズドビューをクエリして集計データを取得するには、標準の SELECT ステートメントを使用できます。
このクエリは、マテリアライズドビューからすべての行を取得します。出力には、集計された顧客の注文数と合計金額が表示されます。結果には、3 人の顧客とそれぞれのメトリクスが表示されます。
さらに、Athena SQL から同じマテリアライズドビューをクエリできます。以下のスクリーンショットは、Athena で実行された同じクエリと結果の出力を示しています。
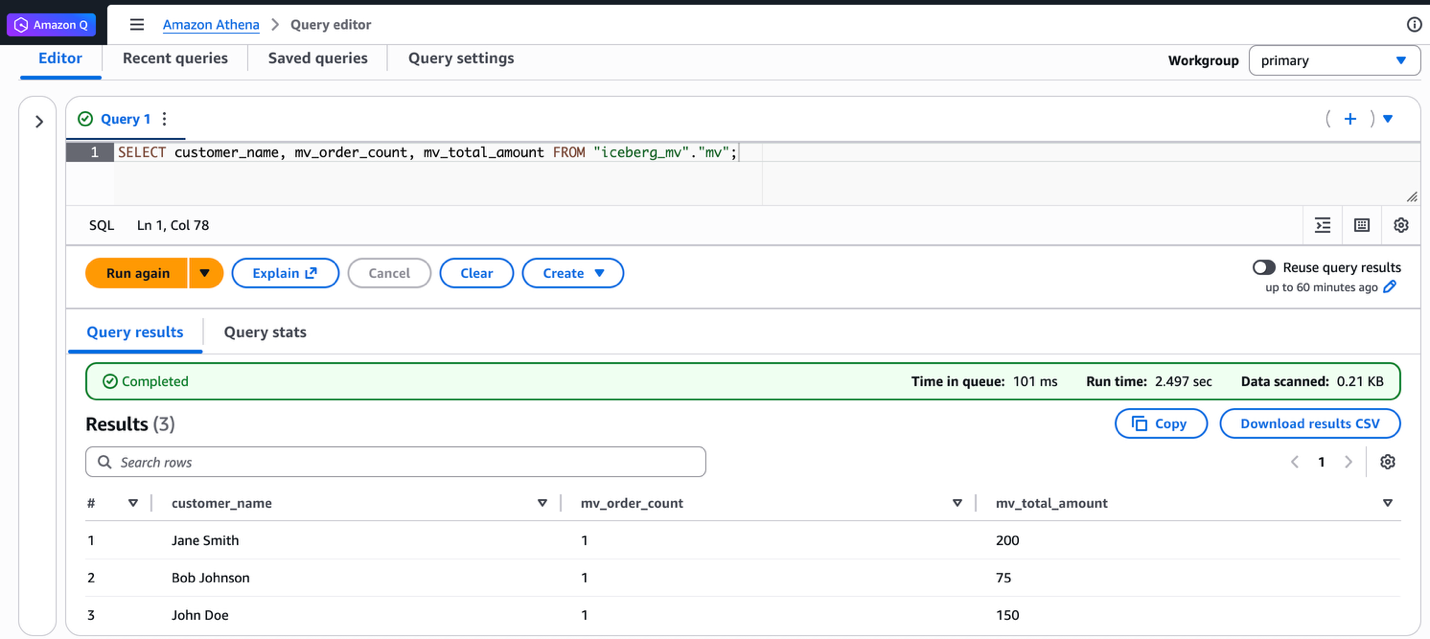
マテリアライズドビューの更新
マテリアライズドビューは、フル更新または増分更新の 2 つの更新タイプを使用して更新できます。フル更新は、すべてのベーステーブルデータからマテリアライズドビュー全体を再計算します。増分更新は、前回の更新以降の変更のみを処理します。フル更新は、一貫性が必要な場合や大幅なデータ変更後に最適です。増分更新は、即時更新が必要な場合に適しています。以下の例では、両方の更新タイプを示します。
フル更新を使用するには、以下のステップを完了します。
- 新しいデータの到着をシミュレートするために、ベーステーブルに 3 つの新しいレコードを挿入します。
- マテリアライズドビューをクエリして、まだ古い集計値が表示されることを確認します。
- 以下のコマンドを使用してマテリアライズドビューのフル更新を実行します。
- マテリアライズドビューを再度クエリして、集計値に新しいレコードが含まれていることを確認します。
増分更新を使用するには、以下のステップを完了します。
- Spark 設定プロパティを設定して増分更新を有効にします。
- ベーステーブルに 2 つの追加レコードを挿入します。
FULL句なしでREFRESHコマンドを使用して増分更新を実行します。増分更新が有効になっているかどうかを確認するには、この記事の最後にある付録 2 を参照してください。- マテリアライズドビューをクエリして、増分変更が集計結果に反映されていることを確認します。
Spark SQL を使用する以外に、スケジュールされた間隔外で更新が必要な場合は、AWS Glue API を通じて手動更新をトリガーすることもできます。以下の AWS CLI コマンドを実行します。
AWS Lake Formation コンソールには、API でトリガーされた更新の更新履歴が表示されます。マテリアライズドビューを開くと、更新タイプ (INCREMENTAL または FULL)、開始時刻と終了時刻、ステータスなどを確認できます。

Iceberg マテリアライズドビューを使用して効率的なデータ処理とクエリを行う方法を学びました。Amazon EMR 上の Spark を使用してマテリアライズドビューを作成し、Amazon EMR と Athena の両方からクエリを実行し、フル更新と増分更新の 2 つの更新メカニズムを使用しました。Iceberg マテリアライズドビューは、データパイプラインを簡単に変換および最適化するのに役立ちます。
考慮事項
この機能を最適に使用するために考慮すべき重要な点があります。
- マテリアライズドビューを管理するための新しい SQL コマンドは、AWS によって最適化された Spark ランタイムエンジンでのみ動作します。これらは、Athena、Amazon EMR、AWS Glue の Spark バージョン 3.5.6 以上で利用できます。オープンソースの Spark はサポートされていません。
- マテリアライズドビューは、ベーステーブルと結果整合性があります。ソーステーブルが変更されると、マテリアライズドビューは、作成時に更新スケジュールでユーザーが定義したバックグラウンド更新プロセスを通じて更新されます。更新ウィンドウ中、マテリアライズドビューに直接アクセスするクエリは古いデータを参照する可能性があります。ただし、最新のデータセットにすぐにアクセスする必要があるお客様は、シンプルな
REFRESH MATERIALIZED VIEWSQL コマンドで手動更新を実行できます。
クリーンアップ
今後の料金が発生しないように、このウォークスルーで作成したリソースをクリーンアップします。
- 以下のコマンドを実行して、マテリアライズドビューとテーブルを削除します。
- Amazon EMR の場合は、Amazon EMR クラスターを終了します。
- AWS Glue の場合は、AWS Glue ジョブを削除します。
まとめ
この記事では、Iceberg マテリアライズドビューが AWS 上で効率的なデータレイク操作をどのように促進するかを示しました。新しいマテリアライズドビュー機能は、データパイプラインを簡素化し、ベーステーブルの変更に応じて自動的に更新される事前計算結果を保存することでクエリパフォーマンスを向上させます。使い慣れた SQL 構文を使用してマテリアライズドビューを作成し、フル更新と増分更新の両方のメカニズムを使用してデータの一貫性を維持できます。このソリューションは、Athena、Amazon EMR、AWS Glue などの AWS サービスとのシームレスな統合を提供しながら、複雑なパイプラインのメンテナンスを不要にします。自動クエリ書き換え機能は、該当する場合にマテリアライズドビューをインテリジェントに活用することでパフォーマンスをさらに最適化し、データ変換ワークフローを合理化してクエリパフォーマンスを向上させたい組織にとって強力なツールとなっています。
付録 1: Apache Iceberg マテリアライズドビューを保存するための Amazon S3 Tables を使用する Spark 設定
この記事で前述したように、マテリアライズドビューはお客様のアカウント内の Amazon S3 Tables バケットに Iceberg テーブルとして保存されます。汎用 Amazon S3 バケットではなく Amazon S3 Tables をマテリアライズドビューの保存場所として使用する場合は、Amazon S3 Tables カタログで Spark を設定する必要があります。
前提条件セクションで示した標準の AWS Glue Data Catalog 設定との違いは、glue.id パラメータの形式です。Amazon S3 Tables の場合は、アカウント ID だけでなく、<account-id>:s3tablescatalog/<s3-tables-bucket-name> の形式を使用します。
これらの設定で Spark を設定した後、この記事で示したのと同じ SQL コマンドを使用してマテリアライズドビューを作成および管理でき、マテリアライズドビューは Amazon S3 Tables バケットに保存されます。
付録 2: Spark SQL でマテリアライズドビューの更新を確認する
Spark SQL で SHOW TBLPROPERTIES を実行して、どの更新方法が使用されたかを確認します。
著者について
 Tomohiro Tanaka AWS の Senior Cloud Support Engineer です。AWS 上のデータレイクで Apache Iceberg を使用するお客様を支援することに情熱を注いでいます。余暇には、同僚とのコーヒーブレイクや自宅でのコーヒー作りを楽しんでいます。
Tomohiro Tanaka AWS の Senior Cloud Support Engineer です。AWS 上のデータレイクで Apache Iceberg を使用するお客様を支援することに情熱を注いでいます。余暇には、同僚とのコーヒーブレイクや自宅でのコーヒー作りを楽しんでいます。
 Leon Lin AWS の Software Development Engineer で、Open Data Analytics Engines チームで Apache Iceberg と Apache Spark の開発に注力しています。オープンソースの Apache Iceberg プロジェクトへのアクティブなコントリビューターでもあります。
Leon Lin AWS の Software Development Engineer で、Open Data Analytics Engines チームで Apache Iceberg と Apache Spark の開発に注力しています。オープンソースの Apache Iceberg プロジェクトへのアクティブなコントリビューターでもあります。
 Noritaka Sekiyama AWS Analytics サービスの Principal Big Data Architect です。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇には、ロードバイクでのサイクリングを楽しんでいます。
Noritaka Sekiyama AWS Analytics サービスの Principal Big Data Architect です。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇には、ロードバイクでのサイクリングを楽しんでいます。
 Mahesh Mishra AWS Analytics チームの Principal Product Manager です。AWS の多くの大規模なお客様と新興テクノロジーのニーズについて協力し、トランザクショナルデータレイクの強力なサポートを含む、AWS 内のいくつかのデータおよびアナリティクスイニシアチブをリードしています。
Mahesh Mishra AWS Analytics チームの Principal Product Manager です。AWS の多くの大規模なお客様と新興テクノロジーのニーズについて協力し、トランザクショナルデータレイクの強力なサポートを含む、AWS 内のいくつかのデータおよびアナリティクスイニシアチブをリードしています。
 Layth Yassin AWS Glue チームの Software Development Engineer です。大規模で困難な問題に取り組み、分野の限界を押し広げる製品を構築することに情熱を注いでいます。仕事以外では、バスケットボールをプレイしたり観戦したり、友人や家族と過ごすことを楽しんでいます。
Layth Yassin AWS Glue チームの Software Development Engineer です。大規模で困難な問題に取り組み、分野の限界を押し広げる製品を構築することに情熱を注いでいます。仕事以外では、バスケットボールをプレイしたり観戦したり、友人や家族と過ごすことを楽しんでいます。
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。