Amazon Web Services ブログ
AWS Glue Data Catalog のテーブル統計自動収集機能の紹介 – Amazon Redshift と Amazon Athena のクエリパフォーマンス向上
本記事は 2024 年 12 月 3 日 に公開された「Introducing AWS Glue Data Catalog automation for table statistics collection for improved query performance on Amazon Redshift and Amazon Athena」を翻訳したものです。
AWS Glue Data Catalog で、新しいテーブルの統計情報を自動的に生成できるようになりました。これらの統計情報は Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザー (CBO) と統合され、クエリパフォーマンスの向上とコスト削減につながります。
大規模なデータセットに対するクエリは、大量のデータを読み取り、複数のデータセット間で複雑な結合操作を実行することがよくあります。Redshift Spectrum や Athena などのクエリエンジンがクエリを処理する際、CBO はテーブル統計を使用してクエリを最適化します。例えば、CBO がテーブル列の個別値の数を把握していれば、最適な結合順序と戦略を選択できます。これらの統計情報は事前に収集し、最新のデータ状態を反映するように更新し続ける必要があります。
これまで、Data Catalog は Parquet、ORC、JSON、ION、CSV、XML 形式のテーブルに対して、Redshift Spectrum と Athena の CBO で使用されるテーブル統計の収集をサポートしてきました。この機能とそのパフォーマンス上のメリットについては、Enhance query performance using AWS Glue Data Catalog column-level statistics で紹介しています。また、Data Catalog は Apache Iceberg テーブルもサポートしています。これについては Accelerate query performance with Apache Iceberg statistics on the AWS Glue Data Catalog で詳しく説明しています。
これまで、Data Catalog で Iceberg テーブルの統計を作成するには、テーブルの設定を継続的に監視および更新する必要がありました。以下のような差別化につながらない重労働が必要でした:
- 特定のデータテーブル形式 (Parquet、JSON、CSV、XML、ORC、ION など) や Iceberg などのトランザクショナルデータテーブル形式を持つ新しいテーブルと、それぞれのバケットパスを検出する
- スキャン戦略 (サンプリング率とスケジュール) に基づいてコンピューティングタスクを決定し、セットアップする
- 特定のタスクに対して AWS Identity and Access Management (IAM) と AWS Lake Formation のロールを設定し、特定の Amazon Simple Storage Service (Amazon S3) アクセス、Amazon CloudWatch ログ、CloudWatch 暗号化用の AWS Key Management Service (AWS KMS) キー、信頼ポリシーを提供する
- データレイクの変更を把握するためのイベント通知システムをセットアップする
- オプティマイザー設定に基づくクエリパフォーマンスとストレージ改善戦略をセットアップする
- スケジューラーをセットアップするか、セットアップとティアダウンを含む独自のイベントベースのコンピューティングタスクを構築する
今回、Data Catalog では、1 回限りのカタログ設定で、更新および作成されたテーブルの統計を自動的に生成できるようになりました。Lake Formation コンソールでデフォルトカタログを選択し、テーブル最適化設定タブでテーブル統計を有効にすることで開始できます。新しいテーブルが作成されると、Iceberg テーブルでは個別値の数 (NDV) が収集され、Parquet などの他のファイル形式では null の数、最大値、最小値、平均長などの追加統計が収集されます。Redshift Spectrum と Athena は、更新された統計を使用して、最適な結合順序やコストベースの集計プッシュダウンなどの最適化を行い、クエリを最適化できます。AWS Glue コンソールでは、更新された統計と統計生成の実行状況を確認できます。
データレイク管理者は、カタログ内のすべてのデータベースとテーブルに対して週次の統計収集を設定できるようになりました。自動化を有効にすると、Data Catalog はテーブル内のすべての列のカラム統計を週次で生成および更新します。このジョブはテーブル内のレコードの 20% を分析して統計を計算します。これらの統計は、Redshift Spectrum と Athena の CBO がクエリを最適化するために使用できます。
さらに、この新機能では、テーブルレベルで自動化設定とスケジュールされた収集設定を柔軟に構成できます。個々のデータオーナーは、特定の要件に基づいてカタログレベルの自動化設定を上書きできます。データオーナーは、自動化を有効にするかどうか、収集頻度、対象列、サンプリング率など、個々のテーブルの設定をカスタマイズできます。この柔軟性により、管理者はプラットフォーム全体を最適化しながら、データオーナーが個々のテーブルの統計を微調整できます。
この記事では、Data Catalog がテーブル統計収集を自動化する方法と、それを使用してデータプラットフォームの効率を向上させる方法について説明します。
カタログレベルの統計収集を有効にする
データレイク管理者は、Lake Formation コンソールでカタログレベルの統計収集を有効にできます。以下の手順を実行します:
- Lake Formation コンソールで、ナビゲーションペインの Catalogs を選択します。
- 設定するカタログを選択し、Actions メニューから Edit を選択します。
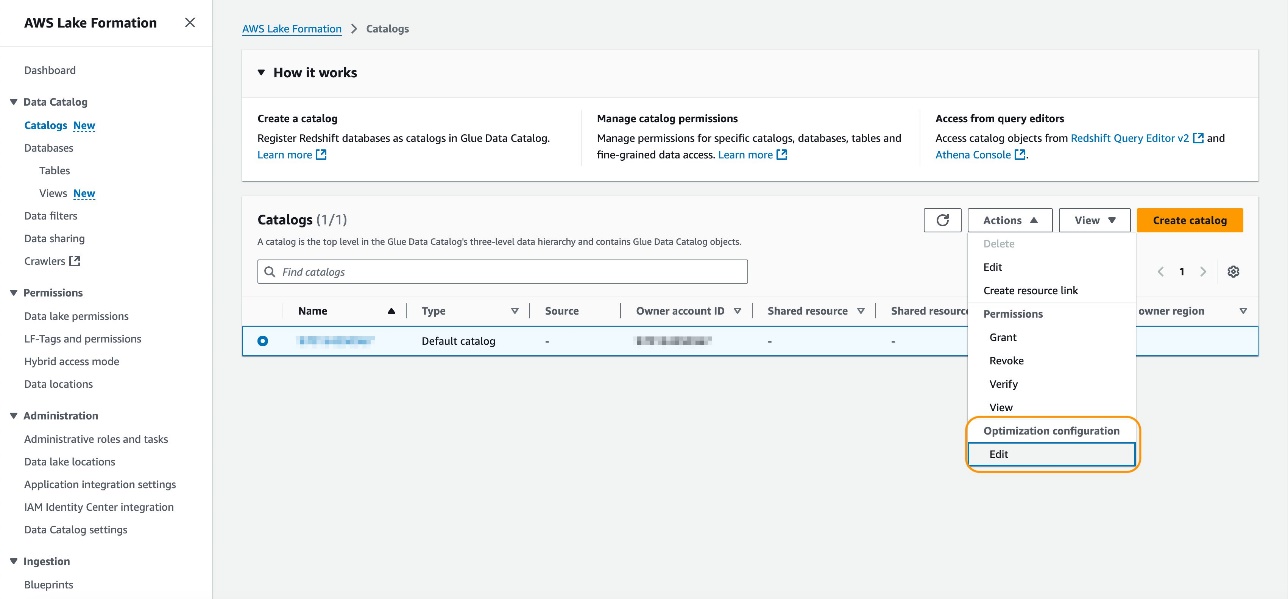
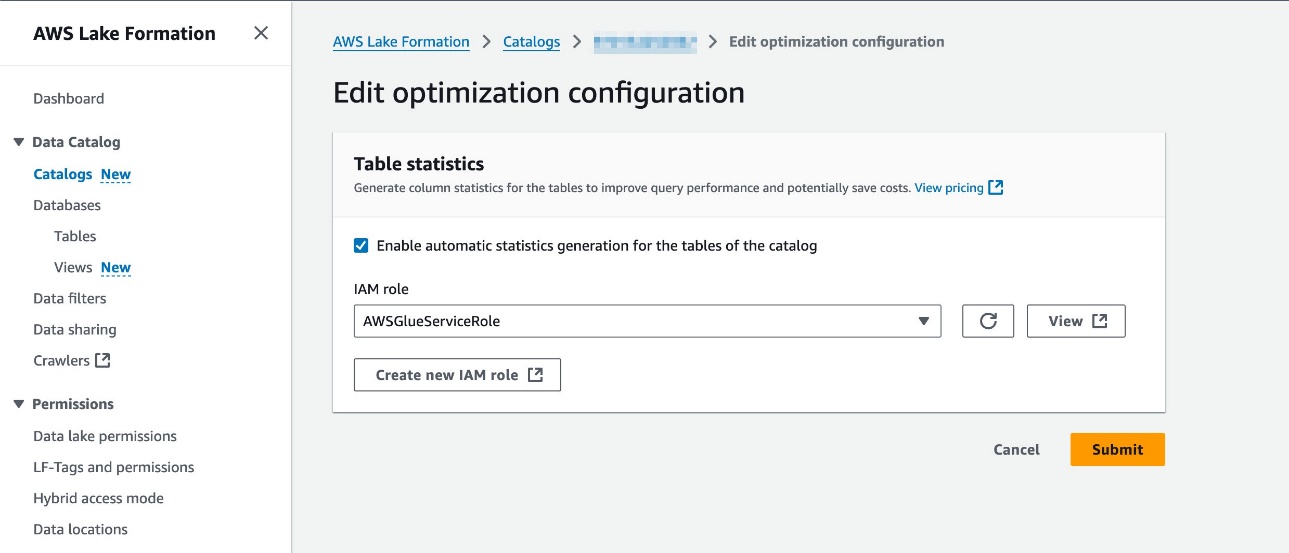
- Enable automatic statistics generation for the tables of the catalog を選択し、IAM ロールを選択します。必要な権限については、カラム統計を生成するための前提条件を参照してください。
- Submit を選択します。
AWS Command Line Interface (AWS CLI) を使用してカタログレベルの統計収集を有効にすることもできます:
このコマンドは AWS Glue の UpdateCatalog API を呼び出し、カタログレベルの統計に対して以下のキーと値のペアを期待する CatalogProperties 構造体を受け取ります:
- ColumnStatistics.RoleArn – カタログレベルの統計のためにトリガーされるすべてのジョブに使用される IAM ロールの Amazon リソースネーム (ARN)
- ColumnStatistics.Enabled – カタログレベルの設定が有効か無効かを示すブール値
UpdateCatalog の呼び出し元は、UpdateCatalog IAM 権限を持ち、Lake Formation 権限を使用している場合はルートカタログに対する ALTER on CATALOG 権限が付与されている必要があります。GetCatalog API を呼び出して、カタログプロパティに設定されているプロパティを確認できます。渡されるロールに必要な権限については、カラム統計を生成するための前提条件を参照してください。
これらの手順に従うことで、カタログレベルの統計収集が有効になります。AWS Glue は、週次で各テーブルのすべての列の統計を自動的に更新し、レコードの 20% をサンプリングします。これにより、データレイク管理者はデータプラットフォームのパフォーマンスとコスト効率を効果的に管理できます。
自動化されたテーブルレベルの設定を確認する
カタログレベルの統計収集が有効になっている場合、AWS Glue コンソール、AWS SDK、または AWS Glue クローラーを通じて AWS Glue の CreateTable または UpdateTable API を使用して Apache Hive テーブルまたは Iceberg テーブルが作成または更新されると、そのテーブルに対応するテーブルレベルの設定が作成されます。
自動統計生成が有効なテーブルは、以下のいずれかのプロパティに従う必要があります:
- Parquet、Avro、ORC、JSON、ION、CSV、XML などの HIVE テーブル形式
- Apache Iceberg テーブル形式
テーブルが作成または更新された後、AWS Glue コンソールでテーブルの説明を確認することで、統計収集設定が設定されていることを確認できます。設定には Schedule プロパティが Auto に、Statistics configuration が Inherited from catalog に設定されているはずです。以下の設定を持つテーブル設定は、AWS Glue によって内部的に自動的にトリガーされます。
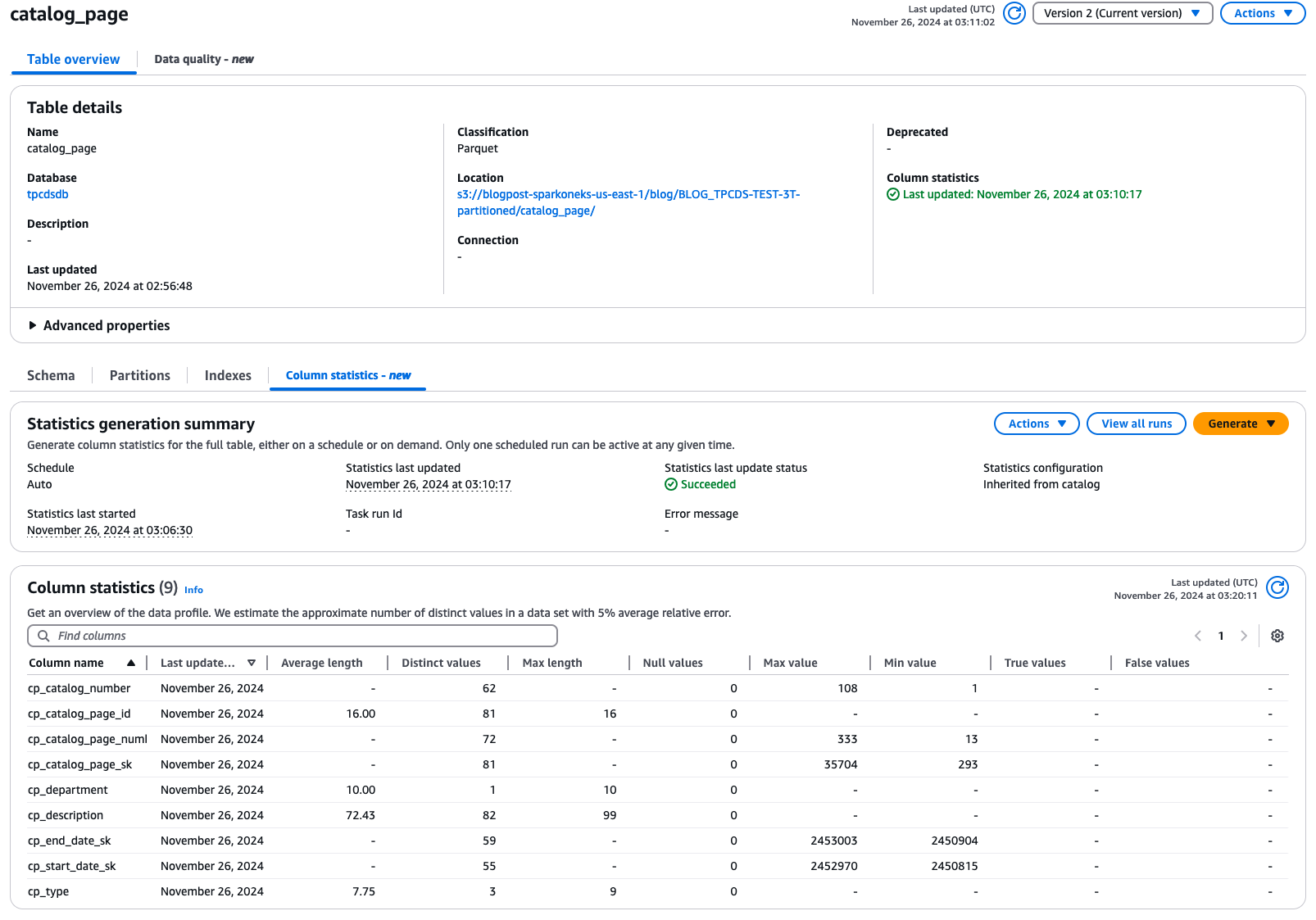
以下は、カタログレベルの統計収集が適用され、統計が収集された Hive テーブルの画像です:
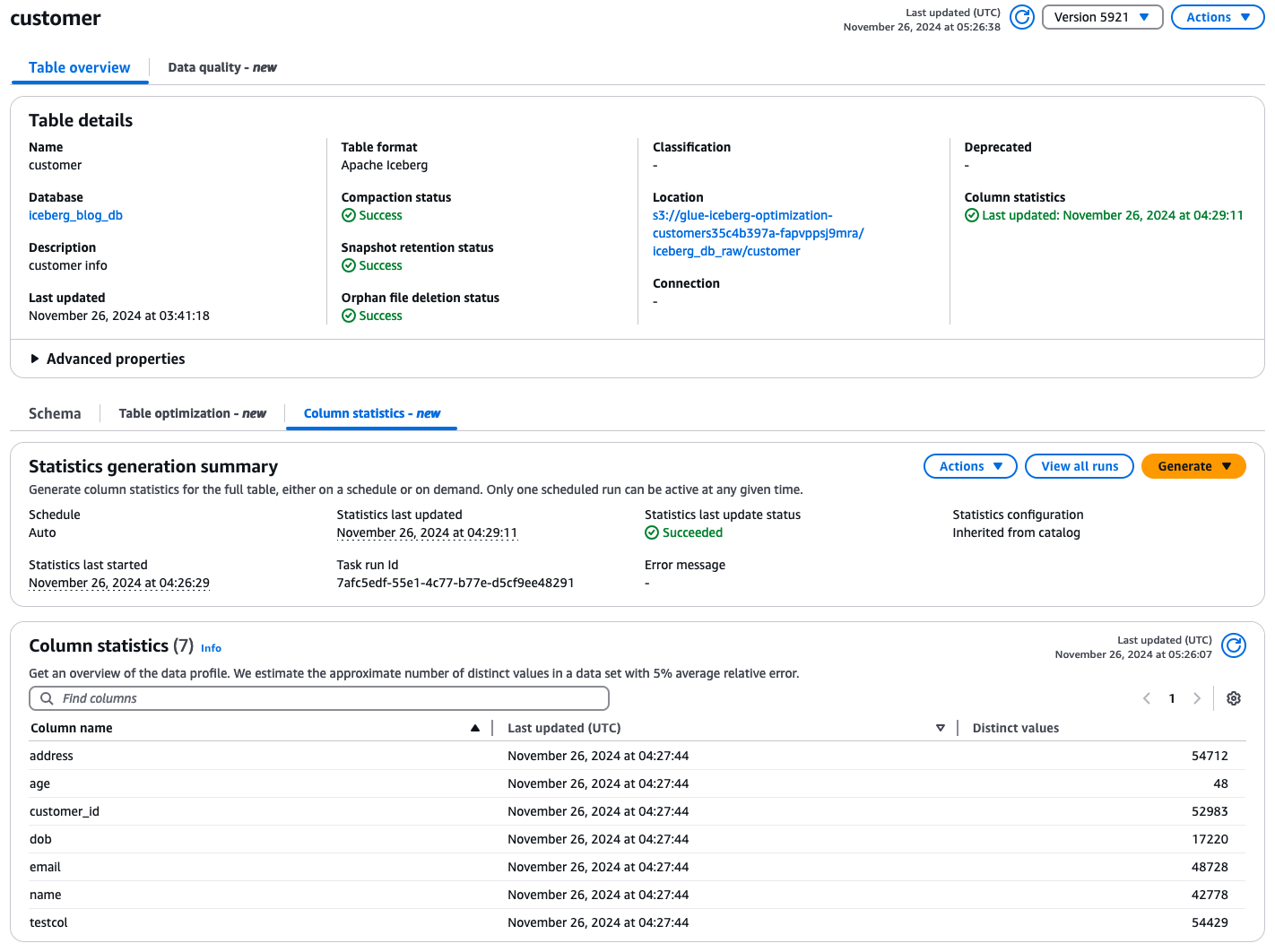
以下は、カタログレベルの統計収集が適用され、統計が収集された Iceberg テーブルの画像です:
テーブルレベルの統計収集を設定する
データオーナーは、特定のニーズに合わせてテーブルレベルで統計収集をカスタマイズできます。頻繁に更新されるテーブルでは、週次よりも頻繁に統計を更新できます。また、最も頻繁にクエリされる列に焦点を当てるために、対象列を指定することもできます。
さらに、統計を計算する際に使用するテーブルレコードの割合を設定できます。そのため、より正確な統計が必要なテーブルではこの割合を増やし、小さなサンプルで十分なテーブルではコストと統計生成パフォーマンスを最適化するために減らすことができます。
これらのテーブルレベルの設定は、前述のカタログレベルの設定を上書きできます。
AWS Glue コンソールでテーブルレベルの統計収集を設定するには、以下の手順を実行します:
- AWS Glue コンソールで、ナビゲーションペインの Data Catalog の下にある Databases を選択します。
- データベースを選択して、利用可能なすべてのテーブルを表示します (例:
optimization_test)。 - 設定するテーブルを選択します (例:
catalog_returns)。 - Column statistics に移動し、Generate on schedule を選択します。
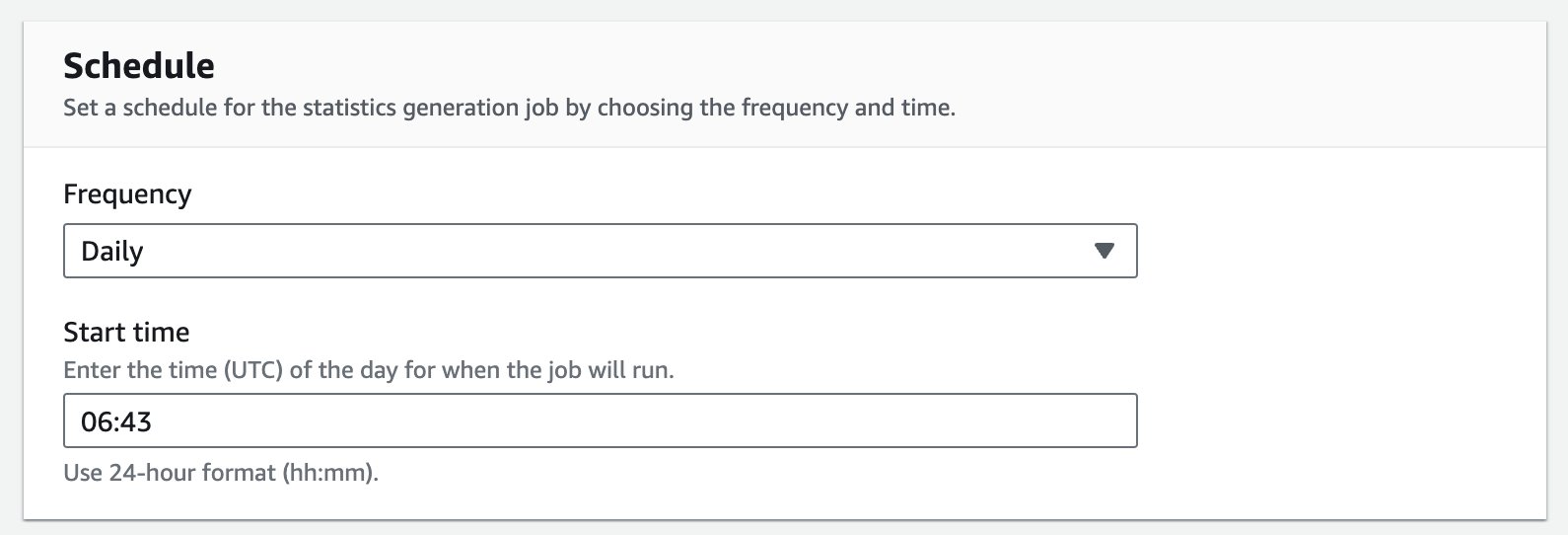
- Schedule セクションで、Hourly、Daily、Weekly、Monthly、Custom (cron 式) から頻度を選択します。この例では、Frequency で Daily を選択します。
- Start time に、UTC で
06:43と入力します。
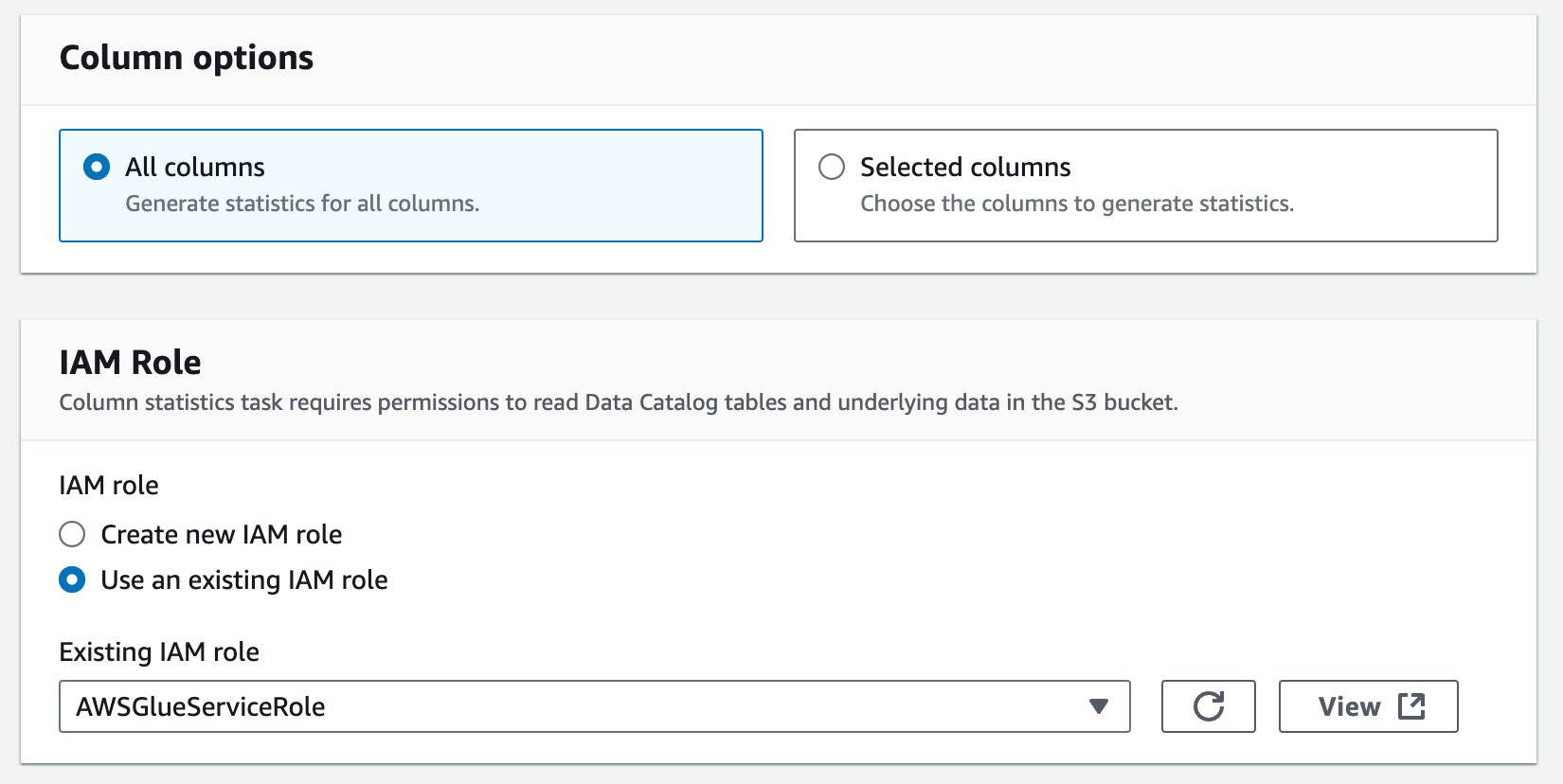
- Column options で、All columns を選択します。
- IAM role で、既存のロールを選択するか、新しいロールを作成します。必要な権限については、カラム統計を生成するための前提条件を参照してください。
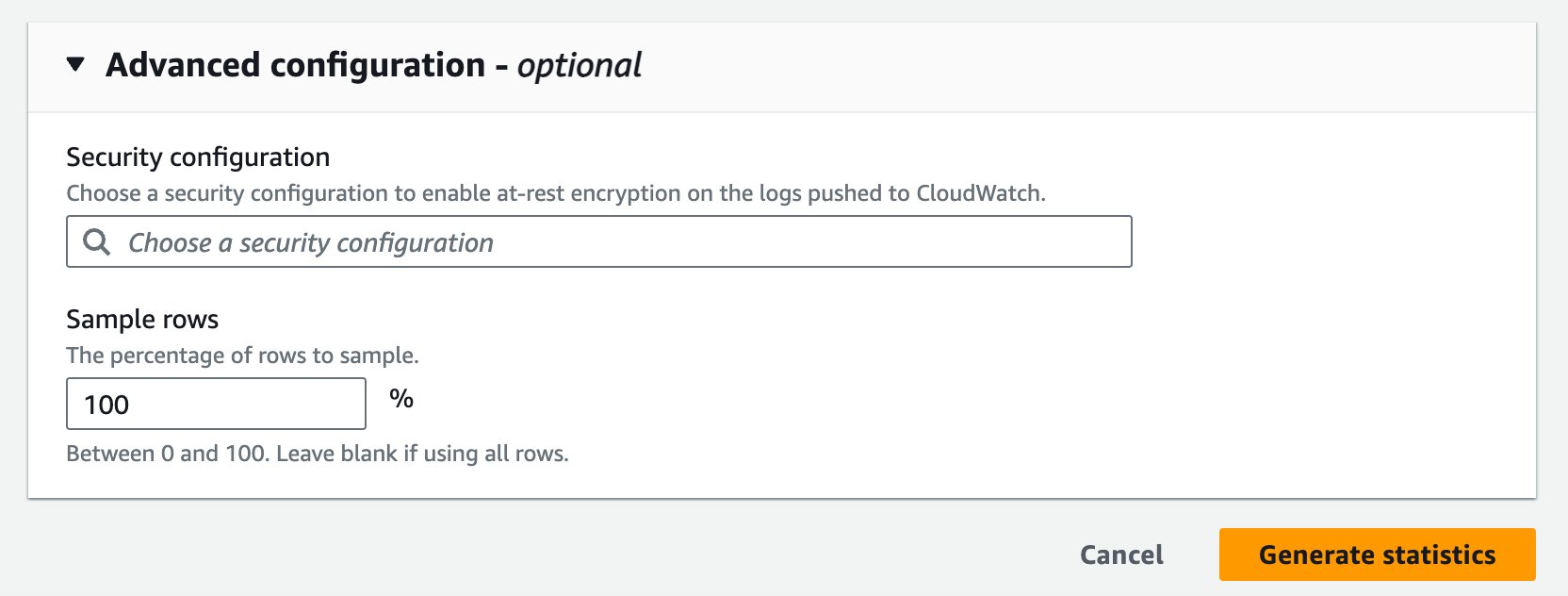
- Advanced configuration の下で、Security configuration で、オプションでセキュリティ設定を選択して、CloudWatch にプッシュされるログの保存時の暗号化を有効にします。
- Sample rows に、サンプリングする行の割合として
100と入力します。 - Generate statistics を選択します。
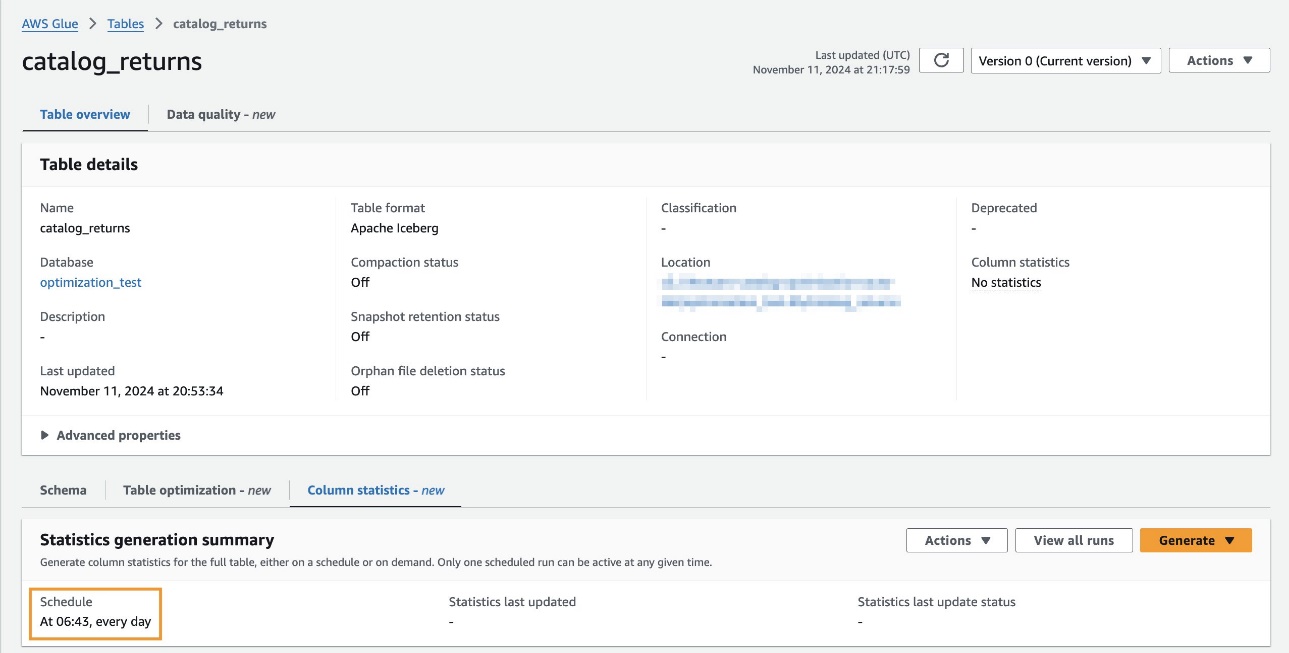
AWS Glue コンソールのテーブルの説明で、指定した日時に統計収集ジョブがスケジュールされていることを確認できます。
これらの手順に従うことで、テーブルレベルの統計収集を設定できました。これにより、データオーナーは特定の要件に基づいてテーブル統計を管理できます。これをデータレイク管理者によるカタログレベルの設定と組み合わせることで、データプラットフォーム全体を最適化するためのベースラインを確保しながら、個々のテーブルの要件に柔軟に対応できます。
AWS CLI を使用してカラム統計生成スケジュールを作成することもできます:
必須パラメータは database-name、table-name、role です。schedule、column-name-list、catalog-id、sample-size、security-configuration などのオプションパラメータも含めることができます。詳細については、スケジュールに基づくカラム統計の生成を参照してください。
まとめ
この記事では、カタログレベルで自動統計収集を有効にし、テーブルごとに柔軟な制御を可能にする Data Catalog の新機能を紹介しました。組織は、最新のカラムレベルの統計を効果的に管理および維持できます。これらの統計を組み込むことで、Redshift Spectrum と Athena の両方の CBO がクエリ処理とコスト効率を最適化できます。
ぜひこの機能をお試しいただき、コメントでフィードバックをお聞かせください。
著者について
 Sotaro Hikita は、Analytics Solutions Architect です。幅広い業界のお客様が分析プラットフォームをより効果的に構築・運用できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
Sotaro Hikita は、Analytics Solutions Architect です。幅広い業界のお客様が分析プラットフォームをより効果的に構築・運用できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
 Noritaka Sekiyama は、AWS Glue チームの Principal Big Data Architect です。東京を拠点に活動しています。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇にはロードバイクでサイクリングを楽しんでいます。
Noritaka Sekiyama は、AWS Glue チームの Principal Big Data Architect です。東京を拠点に活動しています。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇にはロードバイクでサイクリングを楽しんでいます。
 Kyle Duong は、AWS Glue および AWS Lake Formation チームの Senior Software Development Engineer です。ビッグデータ技術と分散システムの構築に情熱を持っています。
Kyle Duong は、AWS Glue および AWS Lake Formation チームの Senior Software Development Engineer です。ビッグデータ技術と分散システムの構築に情熱を持っています。
 Sandeep Adwankar は、AWS の Senior Product Manager です。カリフォルニア州ベイエリアを拠点に、世界中のお客様と協力して、ビジネスおよび技術要件を、お客様がデータの管理、セキュリティ、アクセス方法を改善できる製品に変換しています。
Sandeep Adwankar は、AWS の Senior Product Manager です。カリフォルニア州ベイエリアを拠点に、世界中のお客様と協力して、ビジネスおよび技術要件を、お客様がデータの管理、セキュリティ、アクセス方法を改善できる製品に変換しています。
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。