Amazon Web Services ブログ
Amazon Redshift Data Sharing を活用した位置情報ビッグデータ分析基盤の進化 ~KDDI Location Analyzer の新機能開発事例~
本ブログは、KDDI株式会社 高山 伸也 氏、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 安藤 が共同で執筆しました。
みなさん、こんにちは。AWS ソリューションアーキテクトの安藤です。
位置情報データを活用した商圏分析は、小売・飲食・観光業界において出店計画や集客戦略の意思決定に広く活用されています。今回は、KDDI株式会社(以下、KDDI)が提供する位置情報ビッグデータ分析サービス「KDDI Location Analyzer(以下、KLA)」の新機能開発事例をご紹介します。特に Amazon Redshift Data Sharing 機能を活用することで、既存機能への影響を抑えながら新機能を追加するアーキテクチャを実現しています。
導入背景
KDDI Location Analyzer とは
KDDI は au の携帯電話ネットワークから取得した GPS 位置情報データを活用した商圏分析サービス「KDDI Location Analyzer」を 2019 年 6 月にサービス開始しました。位置情報統計データ・GIS データを統合し、125m メッシュ単位・町丁目単位での高精度な商圏分析を実現しています。サービス開始から約7年間でのべ 1,000 以上の民間企業・自治体に利用されており、小売・飲食業界の店舗出店戦略から観光業界・地方公共団体まで幅広い分野で活用されています。インフラには、位置情報というセンシティブなデータを扱う上で KDDI 社内で利用が認定されたクラウド環境として AWS を採用しています。
新機能開発の背景
観光需要の回復と新たなニーズ
観光需要の回復を背景に、地域の魅力創出や商圏の最適化に向けたデータ活用の重要性が高まっています。行政や企業においては、定量的な人流データに基づく政策・戦略立案がこれまで以上に求められるようになりました。
特に、観光地や商業エリアでは、単なる来訪者数の把握にとどまらず、以下のようなニーズが顕在化していました。
- 来訪前後の行動パターンの把握・分析
- 宿泊エリアの分析
- 店舗間の回遊構造の可視化
携帯電話の GPS 位置情報は時系列でトレースできることが最大のメリットです。既存ユーザーからも「この強みをもっと活用した機能が欲しい」という要望が寄せられており、それが今回の新機能開発の直接的なきっかけとなりました。
新機能「観光動態・店舗間回遊の可視化機能」
これらのニーズに応えるため、KDDI は KLA の国内居住者版に以下の3つの新機能を追加しました。
(1)前後立ち寄り分析
都道府県・市区町村、またはジオフェンスで指定した施設に対し、「どこから来訪し、次にどこへ向かったのか」を可視化します。前後時間帯指定スライダー(最大前後 180 分)を動かすことで時系列の変遷を確認でき、スライダーの操作に応じてヒートマップや滞在者数グラフが即座に更新されます。
- 来訪者区分:全体 or 都道府県外 or 市区町村外(施設選択時)
- 集計期間: 1 日〜1 カ月、時間帯: 5 時〜29 時(30 分単位)
- 属性:性年代・居住者・勤務者・来街者
- 集計結果:周辺滞在者数グラフ(最大前後 180 分)、立ち寄り地滞在者数リスト(町丁目・市区町村・都道府県)
- 活用シーン:域内の観光ルート立案、店舗販促・品揃えやメニュー開発
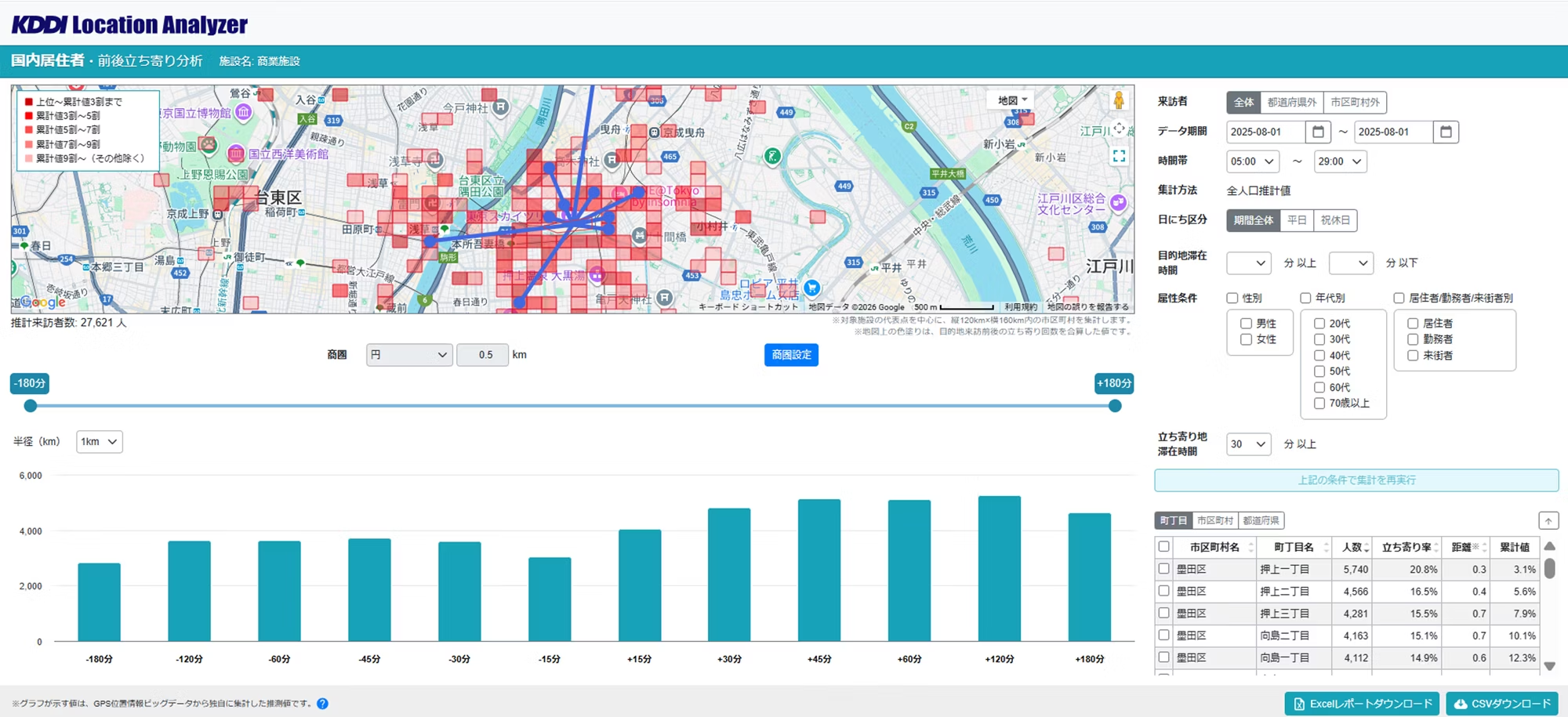
「前後立ち寄り分析」操作画面
(2)宿泊地分析
指定した市区町村に来訪した旅行者の宿泊エリアを可視化します。
- 来訪者区分:旅行者
- 集計期間: 1 日〜 1 カ月、日にち区分:期間全体・日〜木・金・土・祝休前日
- 属性:性年代
- 集計結果:旅行者数グラフ(性年代×日にち区分、宿泊・日帰り)、宿泊施設タイプ別施設数・部屋数(市区町村別)、宿泊地ランキングリスト(市区町村×日にち区分)
- 活用シーン:地域の宿泊供給と旅行者ニーズを総合的に分析
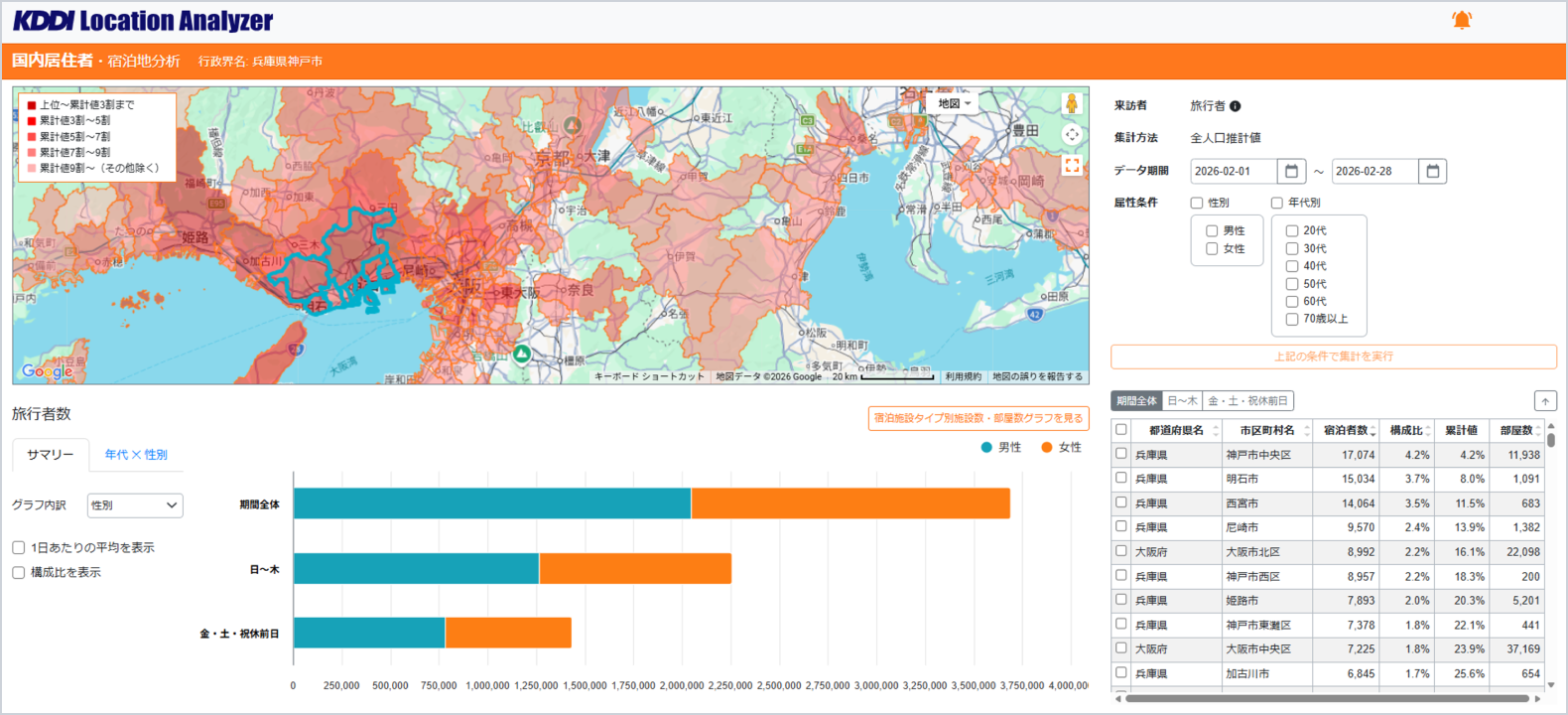
「宿泊地分析」操作画面
(3)発地分析
特定期間に指定した目的地(都道府県・市区町村)へ来訪した人の出発地*を可視化します。
*:来訪前日の宿泊地または居住地(深夜滞在地)
- 来訪者区分:全体 or 旅行者
- 集計期間: 1 日〜 1 カ月、時間帯: 5 時〜 29 時(30 分単位)、日にち区分:期間全体・平日・祝休日
- 属性:性年代・居住者・勤務者・来街者
- 集計結果:発地別来訪者数グラフ(性年代・居住地別)、日にち区分別来訪者数グラフ(市区町村別)、発地別来訪者数リスト(都道府県・市区町村×日にち区分)
- 活用シーン:観光プロモーション施策の検討、経済圏としての強み弱みの把握とサービス改善
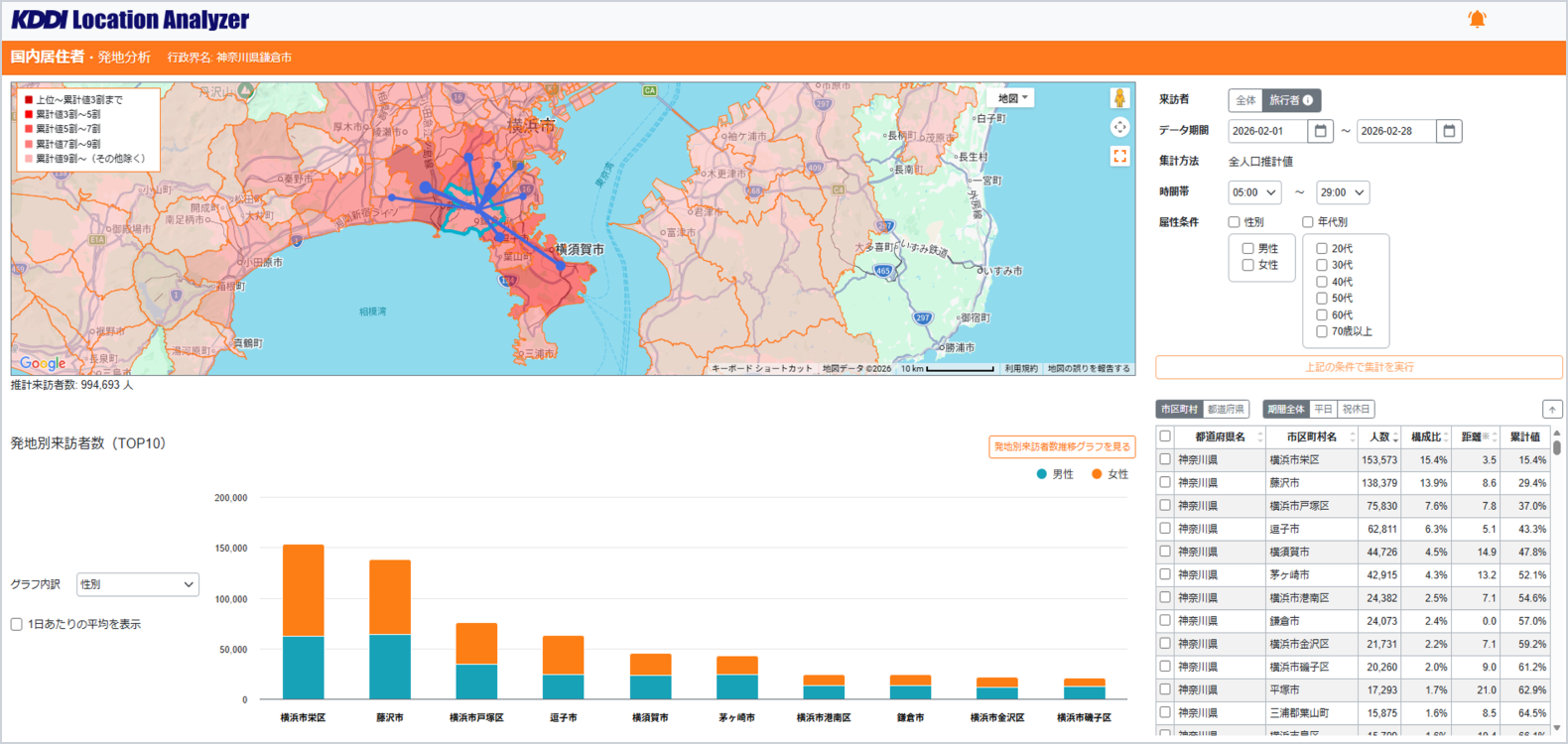
「発地分析」操作画面
システムアーキテクチャ
全体構成
KLA のインフラは AWS 上に構築されており、以下のような構成となっています。
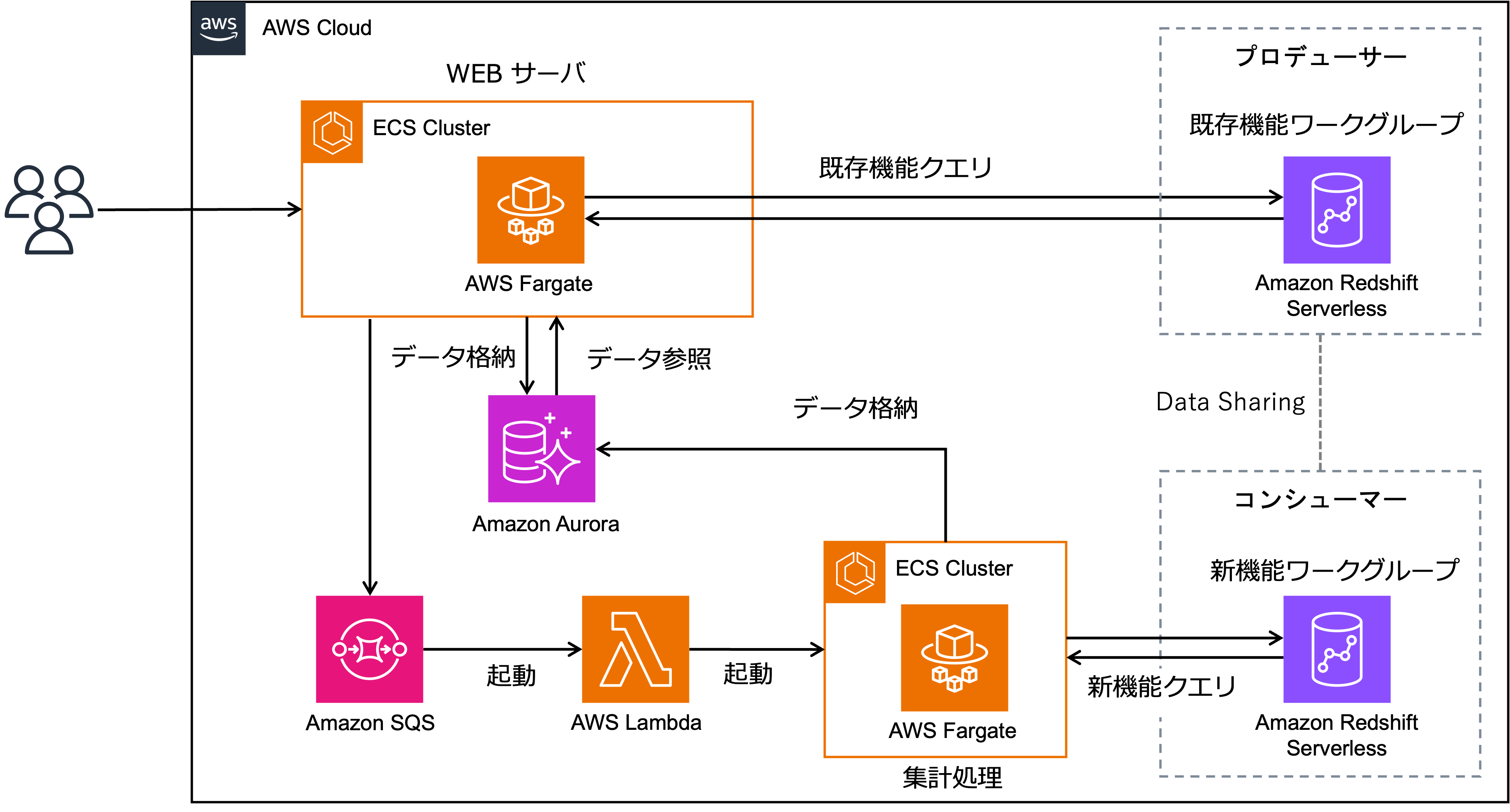
KLAのアーキテクチャ
ワークロードは既存機能と新機能で処理フローが異なります。
既存機能では、ユーザーのリクエストを Amazon ECS Fargate 上の Web サーバが受け取り、Amazon Redshift Serverless(既存機能の集計基盤)に直接クエリを発行して結果を返却するシンプルな同期処理です。
新機能の回遊分析は、複数地点間の時系列データを処理するため、クエリ1件あたりの実行時間が集計対象地域や集計条件によって数分程度に及ぶ重い処理です。RPU を上げることでクエリ実行時間を短縮できる可能性はありますが、KLA ではコストと UX のバランスを取った設定のもと、同期処理ではユーザーを長時間待たせてしまうため非同期処理を採用しています。Web サーバがリクエストを受け取ると Amazon SQS にメッセージを送信し、AWS Lambda がそれを受けて複数の AWS Fargate タスクを並列起動します。各タスクが Redshift にクエリを発行し、処理結果を Amazon Aurora に格納します。アプリケーションが定期的に Aurora を参照して結果をユーザーに返す非同期構成です。SQS でキューイングすることで、Fargate タスクの起動から結果の Aurora への格納までの一連の集計処理を統一的に管理しています。ユーザーには「集計中」ダイアログを表示することで処理中のタイムラグを意識させない UX を実現しています。
Amazon Redshift Data Sharing の活用
新機能の開発にあたり、2 つの課題がありました。
1 つ目はワークロード分離です。既存機能は同期処理で応答を返せるクエリである一方、新機能の回遊分析は前述の通り数分程度かかる重いクエリです。同一ワークグループで動かすと互いの処理が干渉するリスクがあるため、ワークグループを分離する必要がありました。なお、Amazon Redshift Serverless には AI 主導のスケーリングと最適化機能があり、ワークロードパターンを機械学習で予測してクエリ実行前にコンピュートリソースを自動最適化することで、バースト的な高負荷クエリが他のクエリに影響を与えないよう対応できます。一方、ベースとなる RPU やサービス要件、クエリ特性、実行周期などが定常的に大きく異なるワークロードを扱う場合には、ワークグループを分離する構成も有効な選択肢となります。
2 つ目はテーブル設計です。新機能の回遊分析では、複数地点間の時系列データを効率的に処理するため、既存テーブルとは異なるソートキーを持つマートテーブルを新たに作成する必要がありました。まずマテリアライズドビュー(MV)の活用を検討しましたが、KLA が扱う位置情報データは約7年4か月分・数十 TB 規模で今後も増加し続けるため、初回作成に 1 日以上かかるという課題がありました。また、日次データ連携でデータが追加されるたびにリフレッシュが必要となる負荷に加え、ユーザーがエリア・期間・属性を自由に組み合わせて指定するサービス特性上、クエリパターンごとに MV を作り分けると管理が煩雑になることも懸念されました。今回の KLA のデータ規模とサービス特性には MV は適合しないと判断し、新機能のクエリパターンに最適化したソートキーを持つマートテーブルとして作成する方針を選択しました。
しかし、ワークグループを分離した上で新機能用ワークグループにもテーブルを持つ構成にすると、日次データ連携や VACUUM・ANALYZE などのテーブル管理を両方のワークグループで行う必要が生じます。この課題を解決する手段として Amazon Redshift Data Sharing を採用しました。
Data Sharing とは、データをコピーや移動することなく、異なるワークグループ・クラスター・AWS アカウント間でライブデータへの即時アクセスを可能にする機能です。データを保有する側をプロデューサー、参照する側をコンシューマーと呼び、プロデューサーが datashare(共有単位)を作成してデータベース・スキーマ・テーブル・ビューなどを公開します。コンシューマーはその datashare に接続することで、データの実体を持たずに直接クエリを実行できます。
KLA での具体的な構成は以下の通りです。プロデューサー側の既存機能ワークグループに、従来機能用と新機能用の2種類のテーブルを作成し、新機能用テーブルを Data Sharing でコンシューマー側に公開しています。コンシューマー側の新機能ワークグループはデータを持たずにこのテーブルをリアルタイムで参照するだけで済み、テーブル管理はプロデューサー側に集約されます。これにより、ワークロード分離とテーブルの一元管理を両立しています。
今後の展望
新機能のリリースに先立ち実施したユーザー向け説明会では、「前後立ち寄り機能はまさに欲しかった機能」「活用イメージが湧きやすい」といった声が寄せられ、特に民間企業からの期待が高まっています。
運用改善とさらなるパフォーマンス向上
現在も継続的な改善に取り組んでいます。
パフォーマンスの継続的な改善: 現在の構成では、プロデューサーワークグループ上でクエリ実行と VACUUM・ANALYZE などのメンテナンス処理が同時に行われるため、数十 TB 規模のデータを扱う KLA では両者が干渉するケースがあります。なお、VACUUM・ANALYZE は現在定期バッチで対応しており、Redshift のオートノミクス(自動実行)機能は利用していません。2026 年 2 月に Amazon Redshift のオートノミクス機能が強化され、自動バキューム・自動分析などのメンテナンス処理に追加コンピューティングを割り当てることで、ユーザーワークロードへの影響を抑えながら自動実行できるようになりました。VACUUM・ANALYZE の自動実行については、日次データ連携との実行タイミングの兼ね合いも考慮しながら、追加コンピューティング割り当て機能の活用も含めて引き続き検討を進めていく予定です。
メンテナンス作業の効率化: ⼤規模なデータ追加やテーブル変更など、Redshift に⼤きな変更が必要な場合では、サービス提供を止める時間を最小限に食い止めるため、短時間でメンテナンス作業を終わらせる必要があります。Redshift へのデータ投⼊所要時間を考慮すると、事前にスナップショットから新規 Redshift を復元して変更を加えておき、その短時間のサービス停止中に、Redshift を切り替えるという運⽤を現在取っていますが、この⽅法では、新規 namespace を作成するたびに datashare の参照先をコンシューマー側で、⼿動で変更し直す作業が発生します。2026 年 3 月、Amazon Redshift Serverless にスナップショットから同一 namespace にリストアした際に datashare のパーミッションが自動で維持される機能が追加されました。新規 namespace への復元ではなく既存の namespace への上書きリストアに運用を切り替えることで、コンシューマー側の手動変更作業を解消できる可能性があり、今後検討を進めていく予定です。
まとめ
KDDI による本取り組みは、位置情報ビッグデータ分析における Amazon Redshift Data Sharing の実用的な活用事例です。既存機能と新機能でワークロード特性が根本的に異なるという課題に対し、Data Sharing を活用してコンピューティングを分離することで、ワークグループ間のデータコピーなしに各機能に最適化したテーブル設計とリソース配分を実現しました。
従来の公的統計データでは把握できなかった「人の動き」を、GPS 位置情報データと AWS のスケーラブルな分析基盤を組み合わせることで可視化し、観光施策や商圏戦略の高度化に貢献しています。今後の展開と成果に注目していきたいと思います。
著者
 |
高山 伸也
KDDI株式会社 パーソナル事業統括本部 システム開発本部 プラットフォームビジネス部 |
 |
安藤 麻衣
アマゾン ウェブ サービス ジャパン合同会社 技術統括本部 ストラテジックインダストリー技術本部 通信グループ ソリューションアーキテクト |