Amazon Web Services ブログ
Amazon Q Business と Amazon Bedrock によるSAP データ価値の最大化 – パート 2
自然言語を使用した財務データ分析
チャットベースのインターフェースは、営業チームとリーダーシップに迅速で実用的なインサイトを提供できます。売上と予測データへのアクセスと分析を容易にすることで、組織はより情報に基づいた意思決定を行い、市場の変化により迅速に対応し、複雑なデータ処理プラットフォームを学ぶ必要なく、最終的により良い営業パフォーマンスを推進できます。
営業パフォーマンス、製品インサイト、営業予測、地域比較などの情報は、構造化データ用Amazon Bedrock Knowledge Basesを使用して迅速に利用可能にできるデータの例です。このユースケースでは、Amazon Bedrock Knowledge Bases for Structure Dataを使用して、会話インターフェースを使用してデータへのインサイトを迅速に提供する方法を示します。
SQLデータ用の構造化ナレッジベースは、目的と実装の両方において従来のRAG(Retrieval Augmented Generation)とは異なります。RAGは主にLLMレスポンスを拡張するために非構造化テキストの関連チャンクを取得することに焦点を当てているのに対し、SQLデータ用の構造化ナレッジベースは、データベーススキーマ、テーブル、およびそれらの相互接続に関する明示的な関係、ビジネスルール、メタデータを維持します。この構造により、運用データのより正確で信頼性の高いクエリが可能になり、RAGの確率的性質が適切でない財務計算、在庫数、営業指標などの分野で保証された精度を提供します。
SQLデータ用の構造化ナレッジベースを使用する主な利点は、自然言語アクセスを提供しながらデータの整合性とビジネスロジックを維持できることです。RAGはドキュメントや非構造化コンテンツからのコンテキスト提供に優れていますが、構造化ナレッジベースは、運用データにとって重要なテーブル関係、データ型、ビジネスルールを尊重して、クエリが正しくSQLに変換されることを保証します。さらに、ERPデータには大きなデータセットが含まれており、従来のRAG技術を使用すると性能やコスト効率が良くない場合があります。ペタバイト規模の分析をサポートするAmazon Redshiftにデータを保存することで、大量のデータボリュームにアクセスし、Bedrockで利用可能な選択したLLMによって分析できます。
SAP Datasphere、SAP SLT、AWS Glue、パートナーソリューションなど、SAPが提供する技術を使用して、SAPまたは他のERPシステムからAmazon Redshiftにデータを移動してデータ分析を行うためのいくつかのオプションがあります。詳細については、AWS上のSAPデータ統合と管理のガイダンスを参照してください。
注:このブログでは、Apache 2.0ライセンスの下でGitHubでSAPが公開した自転車販売サンプルデータを使用します。これには、分析のためにS3にロードされる自転車販売データの例が含まれています。リアルタイムデータ更新を有効にするために、S3の情報は、このAWSブログで説明されているように、自動コピーを使用して取り込むことができます。
エンタープライズデプロイメントの場合、ビジネスコンテキストをより良く保持するために、Amazon Redshiftにロードする前にAmazon S3への統合にSAP Datasphereの使用を検討してください。SAP DatasphereはSAP Business Technology PlatformとSAP Business Data Cloudの一部として利用でき、どちらもAWS上で実行されます。
アーキテクチャ
図1はソリューションのアーキテクチャ図を示しており、このセクションではそれを構築する手順を示します:
- データは、お好みの統合ソリューションを使用してSAPからS3にコピーされます。この場合、SAPが公開したBike Salesデータを使用します。
- データはAmazon Redshiftデータウェアハウスにコピーされます。
- 構造化データ用Amazon Bedrock Knowledge Baseを設定します。
- ユーザーは、正確な情報検索のためにSQLを生成するために、お好みのBedrockを活用します。
- 生成されたSQLは、Bedrockナレッジベースによって調整され、リアルタイム情報とスケーラビリティのためにAmazon Redshiftで実行されます。
- モデルは、クエリの結果を使用して、リクエストに基づいてユーザーにインサイトを要約し提供します。コンテキストが維持されるため、ユーザーは会話形式で情報を詳しく調べることができます。
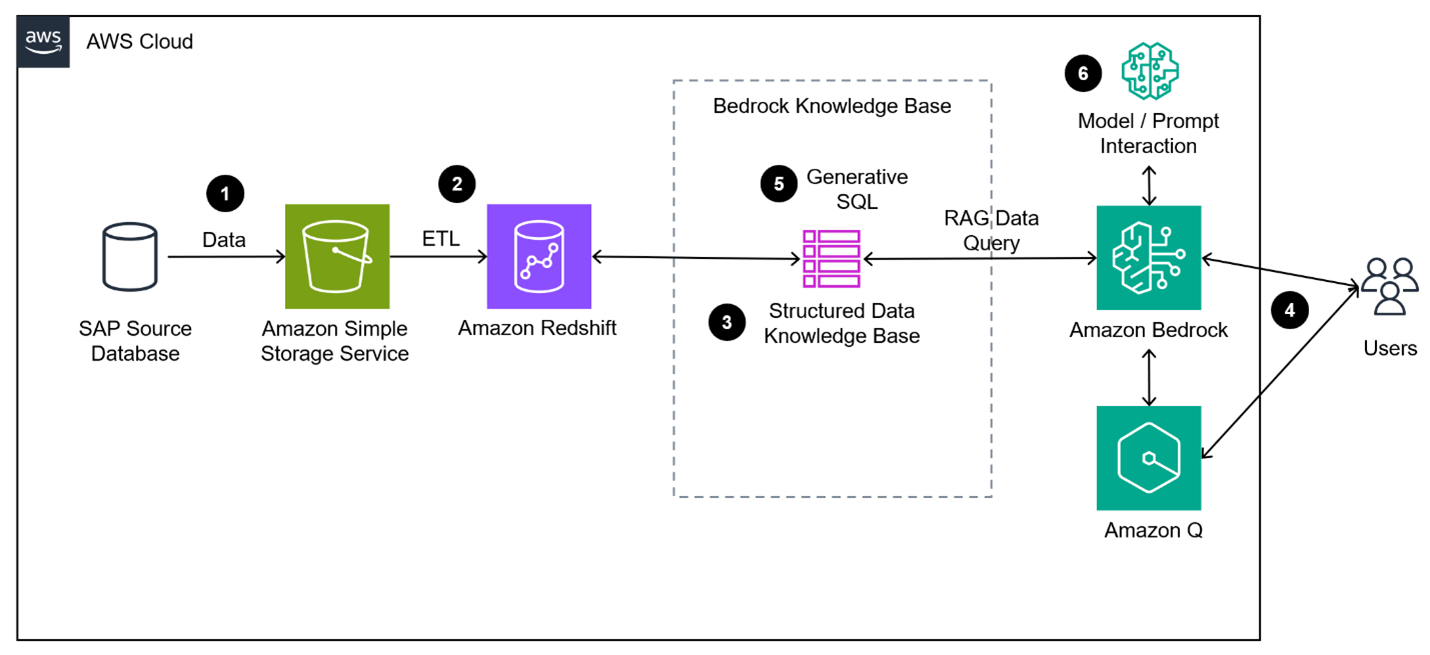
図1: 生成AIを使用した構造化データ分析のアーキテクチャ
プロセス
ここで概説されている手順に従うことで、Amazon Redshiftデータベースを作成し、Bedrockチャットインターフェースを使用して結果をクエリできます。
S3へのデータロード
Amazon S3バケットを作成し(この場合、バケットをkb-structured-data-bike-salesと呼びますが、名前は一意である必要があります)、図2に示すように、Uploadボタンを選択し”Add Files”を選択して、サンプルデータファイル(合計9ファイルである必要があります)をS3バケットにアップロードします。
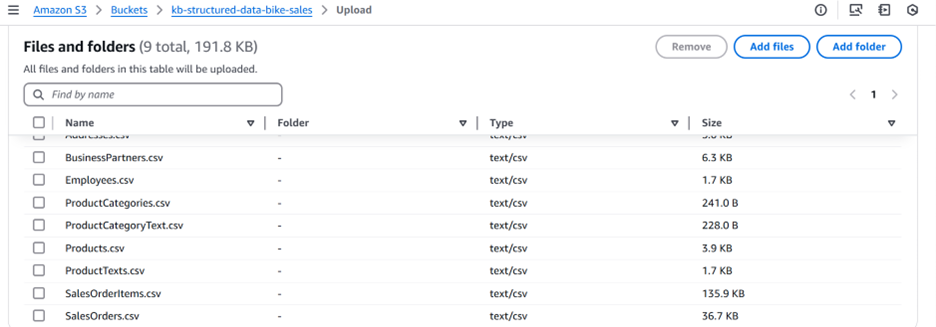
図2: S3バケットでのSAPサンプルデータの保存
注:サンプルファイルEmployees.csvには、以下に示すようにいくつかの空白の列名があります。これらをヘッダーとデータ行で削除して、より簡単にインポートできるようにするために、お気に入りのエディターを使用してください。また、より最近の情報を提示するためにサンプルデータを更新することもできます。
EMPLOYEEID,NAME_FIRST,NAME_MIDDLE,NAME_LAST,NAME_INITIALS,SEX,LANGUAGE,PHONENUMBER,EMAILADDRESS,LOGINNAME,ADDRESSID,VALIDITY_STARTDATE,VALIDITY_ENDDATE,,,,,,
0000000001,Derrick,L,Magill,,M,E,630-374-0306,derrick.magill@itelo.info,derrickm,1000000001,20000101,99991231,,,,,,
0000000002,Philipp,T,Egger,,M,E,09603 61 24 64,philipp.egger@itelo.info,philippm,1000000002,20000101,99991231,,,,,,
0000000003,"Ellis",K,Robertson,,M,E,070 8691 2288,ellis.robertson@itelo.info,ellism,1000000003,20000101,99991231,,,,,,
0000000004,William,M,Mussen,,M,E,026734 4556,william.mussen@itelo.info,williamm,1000000004,20000101,99991231,,,,,,SAPデータと非SAPデータの結合
この段階で、SAPデータを他のビジネスソースからの非SAP関連データと組み合わせることもでき、それが生成AI技術を使用した統合エンタープライズの価値です。
クエリの容易さのためにAmazon Redshiftデータウェアハウスにデータをロード
S3からRedshiftにデータを追加するには、次の手順に従います:
- Amazon Redshiftに移動し、サーバーレス名前空間を作成します。この例では、default-workgroupと名前空間を使用します。
- Redshift Query Editorにアクセスするには、Amazon RedshiftのコンソールからQuery Dataを選択します。これによりRedshiftクエリエディターに移動します
- クエリエディターから、図3に示すようにCreate > Databaseを選択します
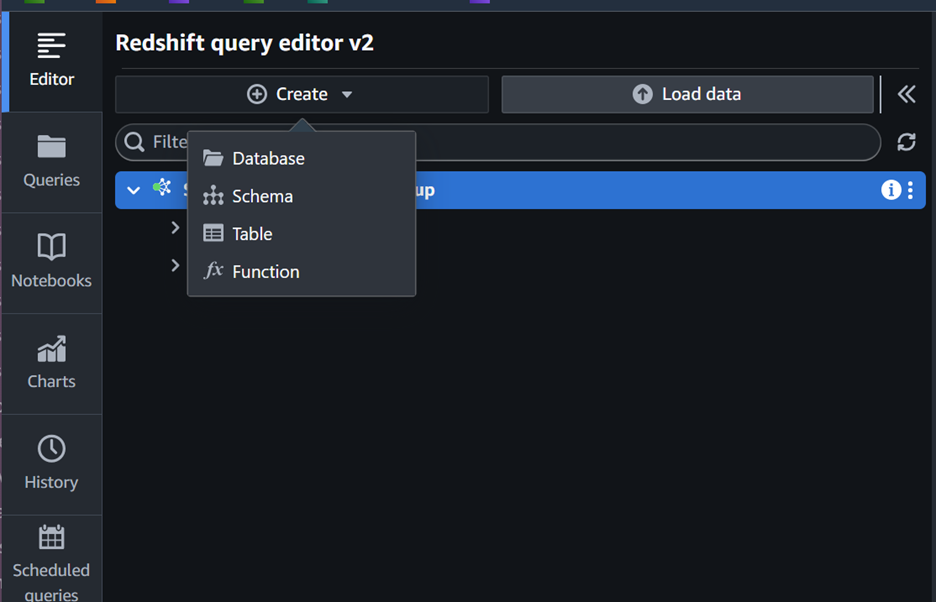
図3: クエリエディター画面からRedshiftデータベースを作成
- “create database”フォームを使用してデータベースを作成します(このブログでは、bike_salesという名前を使用し、Redshift serverlessを使用しています)
- 各.csvファイルについて、bike_salesデータベースに対応するテーブルを作成します。テーブルを作成し、1つのステップでデータをロードするには、”Load Data”ボタンを選択することから始めます
- “Load from S3 Bucket”と”Browse S3″を選択して、適切なファイルを選択します
- データファイルにはYYYYMMDD形式を使用したDATE形式が含まれており、これは整数値として誤って自動検出される可能性があります。これを修正するには、図4に示すように”Data Conversion Parameters”ボタンを選択し、図5に示すようにデータ形式を変更します(空白値に対応するために”Accept any date”を選択する必要がある場合もあります)
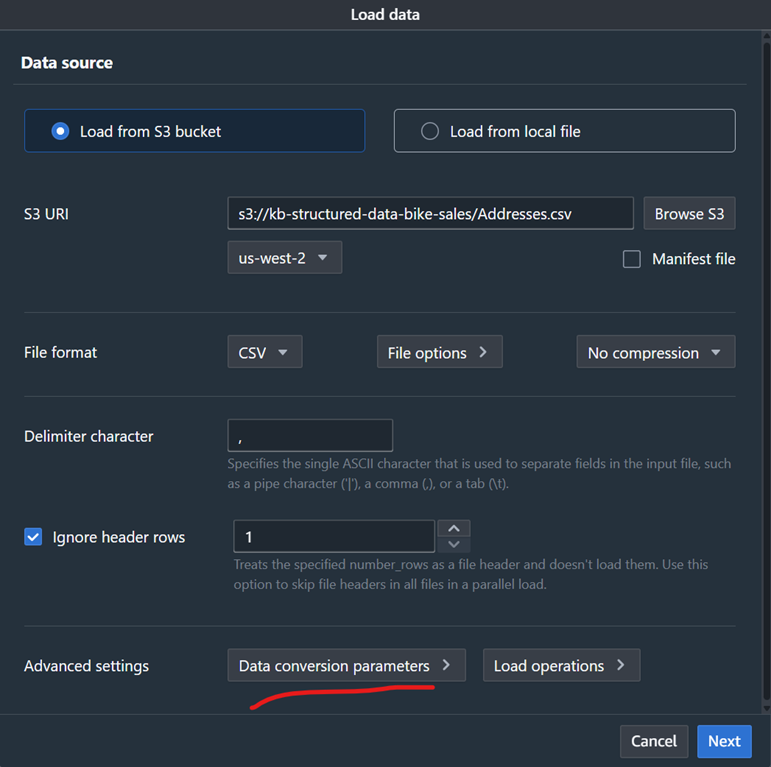
図4: 日付形式のデータ変換パラメータの使用
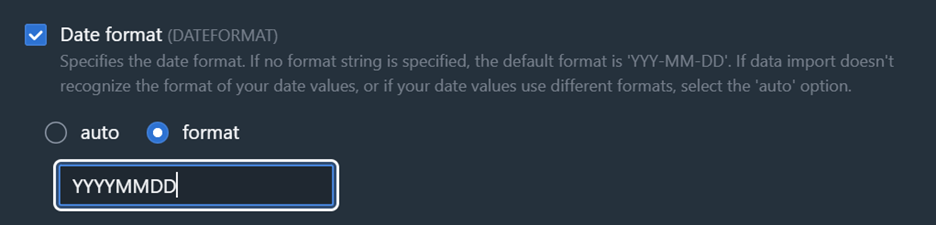
図5: 日付形式変更オプション
- Nextを選択してLoad dataスクリーンに進みます
- “Load new table”を選択して、.csvヘッダー情報に基づいて新しいテーブルを作成します。図6に示すように、ドロップダウンから適切なワークグループ、データベース、スキーマを選択し、.csvファイル名に従ってテーブルに名前を付けます
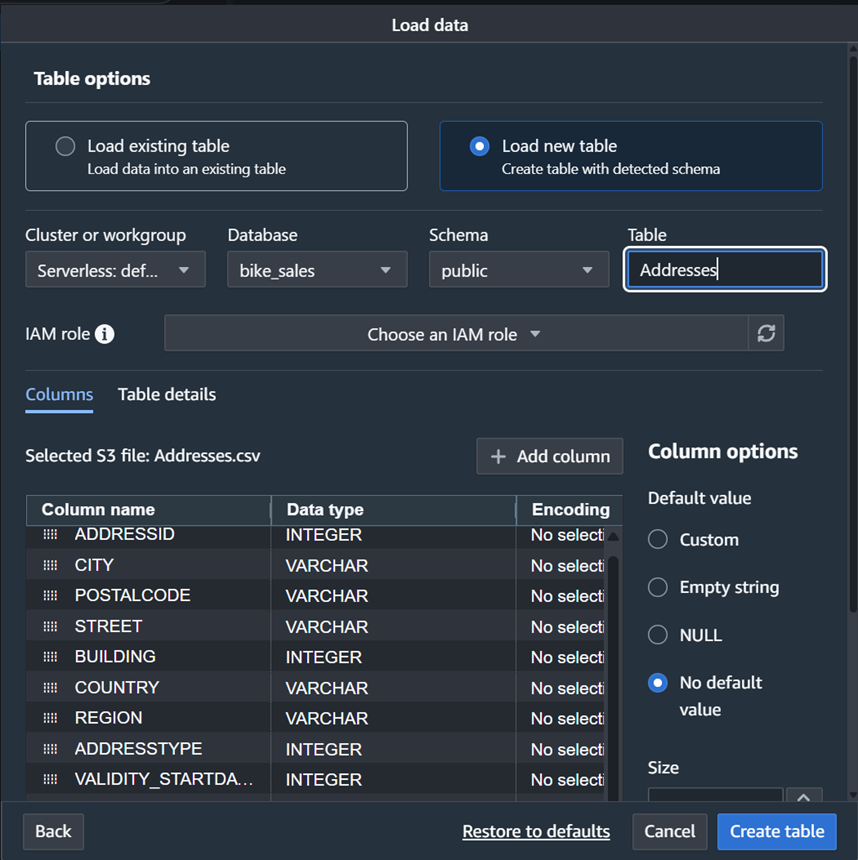
図6: Redshiftへのテーブルロード
- データフィールドのデータ型を”DATE”データ型に変更します(データ型がない列がある場合は、VARCHARを選択できます)
- “Create Table”と”Load Data”を選択して、テーブルを作成しデータをロードします
- テーブル名を右クリックし、”Select table”オプションを選択することで、テーブルが正しく作成されたことを検証します。これにより、select * from “bike_sales”. “public”. “addresses”などのクエリが自動的に作成されます
- 他のテーブルについてもこのプロセスを繰り返します。完了すると、9つのファイルすべてがRedshiftにあり、Amazon Bedrockで使用できるようになります
- Amazon Bedrockに移動し、左パネルからKnowledge Basesを選択します
- 図7に示すように、Createを選択し、次にKnowledge Base with structured data storeを選択します
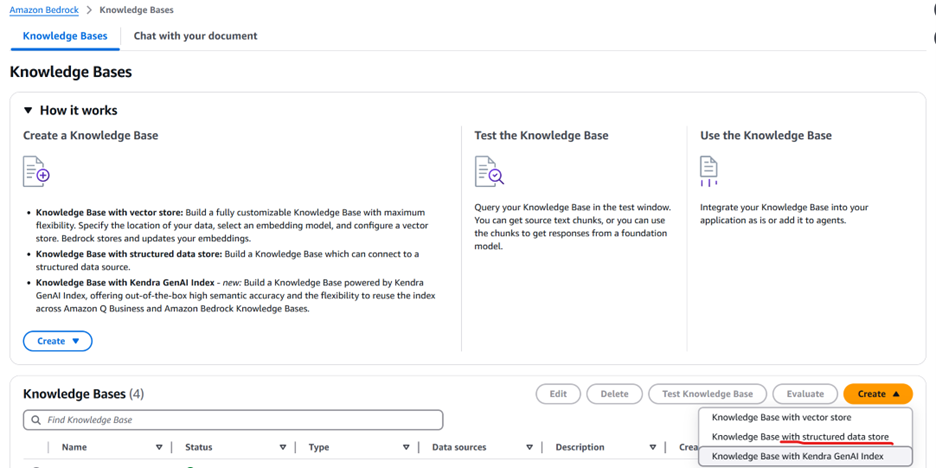
図7: 構造化データストアオプション付きAmazon Bedrock Knowledge Bases
- Knowledge Baseに名前を付け、データソースとしてAmazon Redshiftを選択します
- IAM権限については、”Create and use a new service role”を選択します
- Nextをクリックし、デプロイメントに一致するQuery Engineの詳細を選択します(この例ではredshift serverless)
- ストレージメタデータについては、作成したデータベース(この例ではbike_sales)を選択し、Nextを選択します
- サービスロールをメモし、”Create Knowledge Base”を選択します
サービスロールに対応するRedshiftユーザーを追加
- Redshiftコンソールに移動し、前のステップのサービスロールでユーザーを作成するために次のコマンドを使用します:
create user "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase<XXXXX>" with password disable; - コマンド「grant select on all tables in schema “public” to IAMR:AmazonBedrockExecutionRoleForKnowledgeBase<XXXXX>」を使用してIAMサービスロールに権限を付与します
ヒント: IAMロールの設定に関する追加の詳細とベストプラクティスはこちらに文書化されています。
Query Engineの同期
Amazon Bedrock Knowledge Baseに戻り、図8に示すように同期ボタンを使用します。同期には数分かかり、ステータスが「COMPLETE」と表示されます
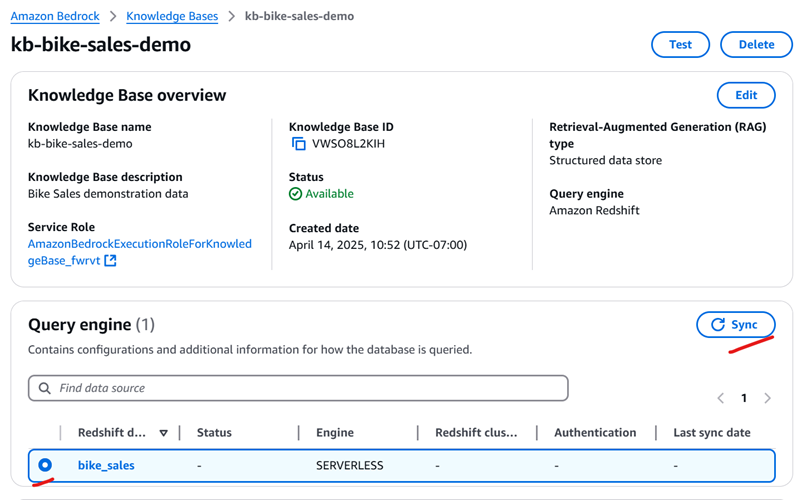
図8: ナレッジベースの同期
基盤モデルを使用した自然言語によるデータ分析
これで、選択した基盤モデルでこのナレッジベースを使用する準備が整いました。図9に示すように、作成したKnowledge Baseを選択し、モデルを選択することから始めます。
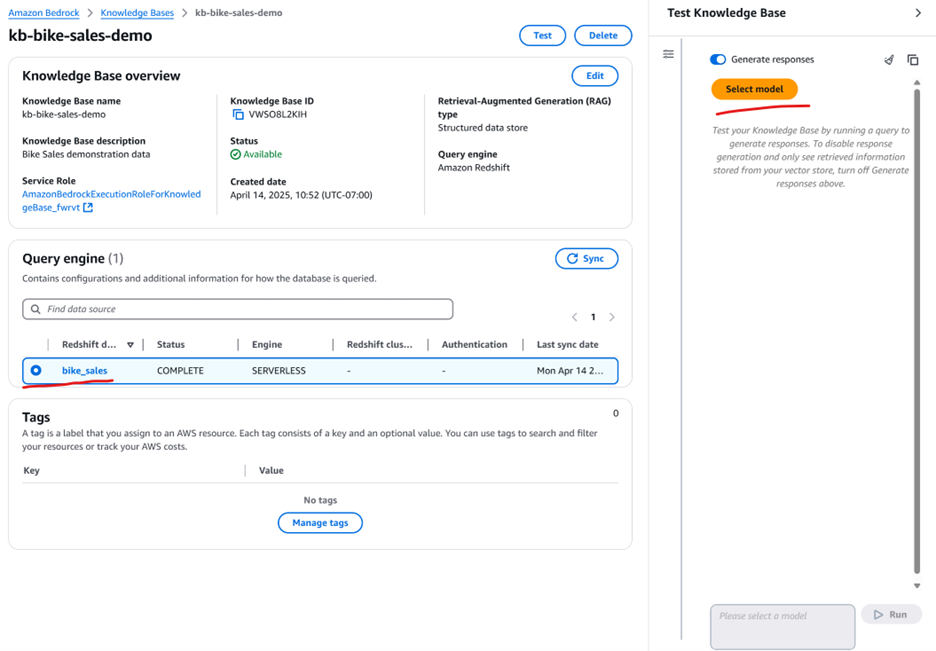
図9: 選択した基盤モデルでRedshiftナレッジベースを使用
ヒント: 私たちのテストでは、「Amazon Nova」と「Anthropic Claude」Sonnetモデルがこの分析に適しています。
図10のスクリーンキャプチャは、基盤モデルからの質問と結果の例を示しています。レスポンスを生成するためにデータセットで使用された特定のクエリを表示するAmazon Bedrockの透明性の側面に注目してください。
図10 – データとのチャットの例
最適なユーザーエクスペリエンスのために複数のモデルをテストし、Redshiftナレッジベースをビジネスアプリケーションに統合できます。
サンプルコスト内訳
次の表は、US-EAST-1(バージニア北部)リージョンでデフォルトパラメータを使用して、独自のAWSアカウントでこのソリューションをデプロイするためのサンプルコスト内訳を提供します。
| AWSサービス | ディメンション | コスト(USD) | |||
|---|---|---|---|---|---|
| Amazon S3 | CSVファイル用の月間10GBストレージ | $0.26 | |||
| Amazon Redshift Serverless | 月間8時間/日実行時間で4RPU | $366.24 | |||
| 構造化データ用Amazon Bedrock Knowledge Base | 平均入出力トークンサイズ1000で1日8時間、1分あたり1リクエスト。 | $259.20 |
コストを管理するために、AWS Cost Explorerを通じて予算を作成することをお勧めします。詳細については、このブログで使用される各AWSサービスの価格ページを参照してください。
リソースのクリーンアップ
このブログで言及されているサービスは、アカウント内のAWSリソースを消費するため、不要になったらさらなるコストを防ぐためにクリーンアップする必要があります。以下を削除してください:
- データステージング用に使用されたS3バケット内のファイルとS3バケット自体
- 構造化データをホストするために使用されたRedshiftデータベース
- 構造化データストア用Amazon Bedrock Knowledge Base
- IAMサービスロール(これらは課金対象ではありませんが、不要になった場合はクリーンアップする必要があります)
結論と次のステップ
このブログでは、特定のユースケースを使用してSAPデータ(構造化および非構造化の両方)に生成AIを使用する方法について説明しましたが、概念は組織が持つ可能性のある他のユースケースにも転用できます。
Amazon BedrockとAmazon Qをすぐに開始するには、AWS生成AIページから始めてください。Kiro CLIとAmazon Bedrock Knowledge Retrieval MCPサーバーを使用してコマンドラインでKnowledge Baseを直接クエリすることもできます。今日試してみてください!また、SAP DevOps用Amazon Qの使用に関する最近公開されたビデオもご覧ください。
本ブログはAmazon Bedrockによる翻訳を行い、パートナーSA松本がレビューしました。原文はこちらです。