Amazon Web Services ブログ
S3 Tables の Intelligent-Tiering でデータ管理を最適化する
本記事は 2026 年 2 月 26 日 に公開された「Optimize data management on S3 Tables with Intelligent-Tiering」を翻訳したものです。
多くの組織が、ペタバイト規模の成長とパフォーマンスに対応でき、コストのかかるリライトなしにスキーマやパーティションを柔軟に変更できる Apache Iceberg をデータレイクに採用しています。タイムトラベルやインクリメンタル処理といった機能により、最新のデータレイク管理が可能になります。しかし、データが増大するにつれ、Iceberg データセットの効率的な管理は難しくなります。規制要件や長期的な分析ニーズから数か月〜数年にわたりデータを保持する組織も多く、パフォーマンスやアクセス性とコストのバランスに苦慮しています。テーブルのメンテナンス、ファイルレイアウトの最適化、コスト効率の高いリテンションポリシー(維持期間)の実装は、継続的にリソースを消費し、コスト増加につながります。
Amazon S3 Tables は、Iceberg テーブル向けに設計されたテーブルストレージと新しいバケットタイプを導入し、Amazon S3 に構造化データを簡単に保存できるようにしました。S3 Tables はコンパクション、スナップショット管理、参照されていないファイルの削除といったメンテナンスタスクを自動的に処理します。さらに、Intelligent-Tiering ストレージクラスのサポートが追加されました。アクセスパターンに基づいてデータをストレージ階層間で自動的に移動し、ストレージコストを最適化します。データレイクの規模が拡大しデータが古くなっても、パフォーマンスに影響を与えることなくコスト効率を継続的に最適化できます。
本記事では、Intelligent-Tiering をコンパクションやスナップショット管理などのメンテナンス機能と組み合わせて、長期的な総所有コスト (TCO) を削減する方法を詳しく解説します。
S3 Tables でのデータ管理の最適化
S3 Tables にデータが到着した時点では、最適な状態ではない場合があります。たとえば、分析効率よりも取り込みスループットや柔軟性を優先してデータが取り込まれることがあります。ストリーミング更新で頻繁にテーブルへの変更がコミットされ小さなファイルが生成されるケースや、merge-on-read パターンでテーブル更新時にインクリメンタルな差分ファイル/deleteファイルが追加されるケースが典型的です。このような場合、クエリパフォーマンスの向上と長期的なストレージの最適化にメンテナンス操作が必要になります。S3 Tables は長期的なデータ最適化のために以下の手法をサポートしています。
- スナップショット管理 – 必要な履歴データのみを保持し、冗長な情報を体系的に廃止・削除して、参照されていないファイルを完全に除去します
- コンパクション (Binpack、Sort、Z-order) – 小さなファイルを統合してより大きく効率的なファイルを作成します。Sort や Z-order を使ってデータを並べ替え、より高速でコスト効率の高いクエリを実現したり、delete ファイルをデータファイルにマージしたりできます
- ストレージ階層の最適化 – Intelligent-Tiering ストレージクラスを活用し、規制やビジネスニーズによる長期データ保持のストレージコストを削減します
S3 Tables のスナップショット管理
Iceberg のスナップショットは、テーブルの完全な状態を記録した不変のポイントインタイムレコードです。既存のコンテンツを変更せずに、すべてのデータファイルとメタデータをキャプチャします。タイムトラベルクエリ、同時操作中の一貫した読み取り、運用復旧やリストアのための以前のテーブルバージョンへのロールバックといった機能を実現します。
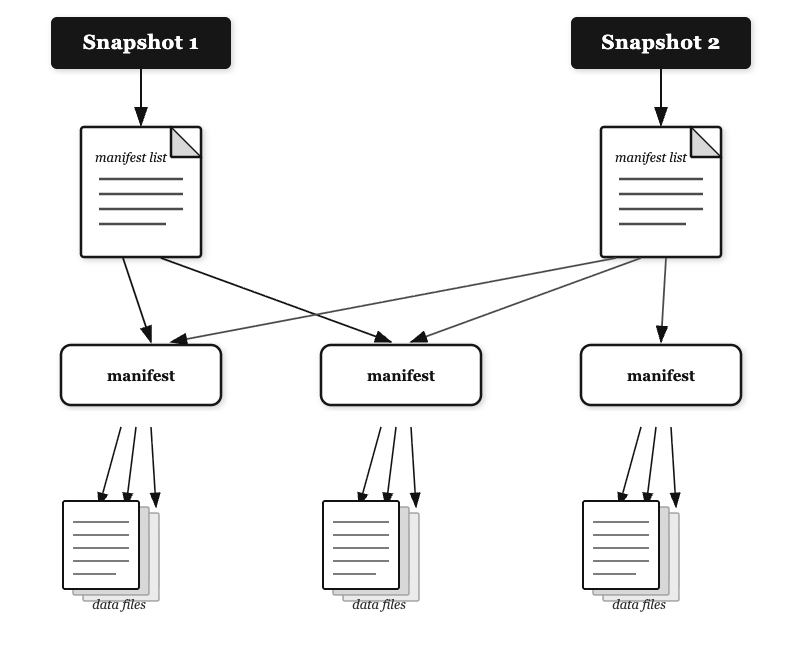
S3 Tables は、リテンションポリシーの設定やライフサイクル管理の自動化のためのコンソールコントロールと API 操作でスナップショット管理を効率化します。
S3 Tables は、履歴データのニーズとストレージ最適化のバランスをとるための調整可能な有効期限ルールを提供し、ガバナンス要件に対応するスナップショットメトリクスと監査証跡も備えています。保持するスナップショットの最小数、スナップショットの最大保持期間、参照されていないファイルの削除などのプロパティが含まれます。スナップショット管理の詳細はこちらの動画で解説しています。
nonCurrentDays、unreferencedDays、maximumSnapshotAge、minimumSnapshots などのチューニングパラメータについては、考慮事項と制限を慎重に評価することをお勧めします。リテンション要件に合わせて適切に値を調整してください。
S3 Tables のコンパクション
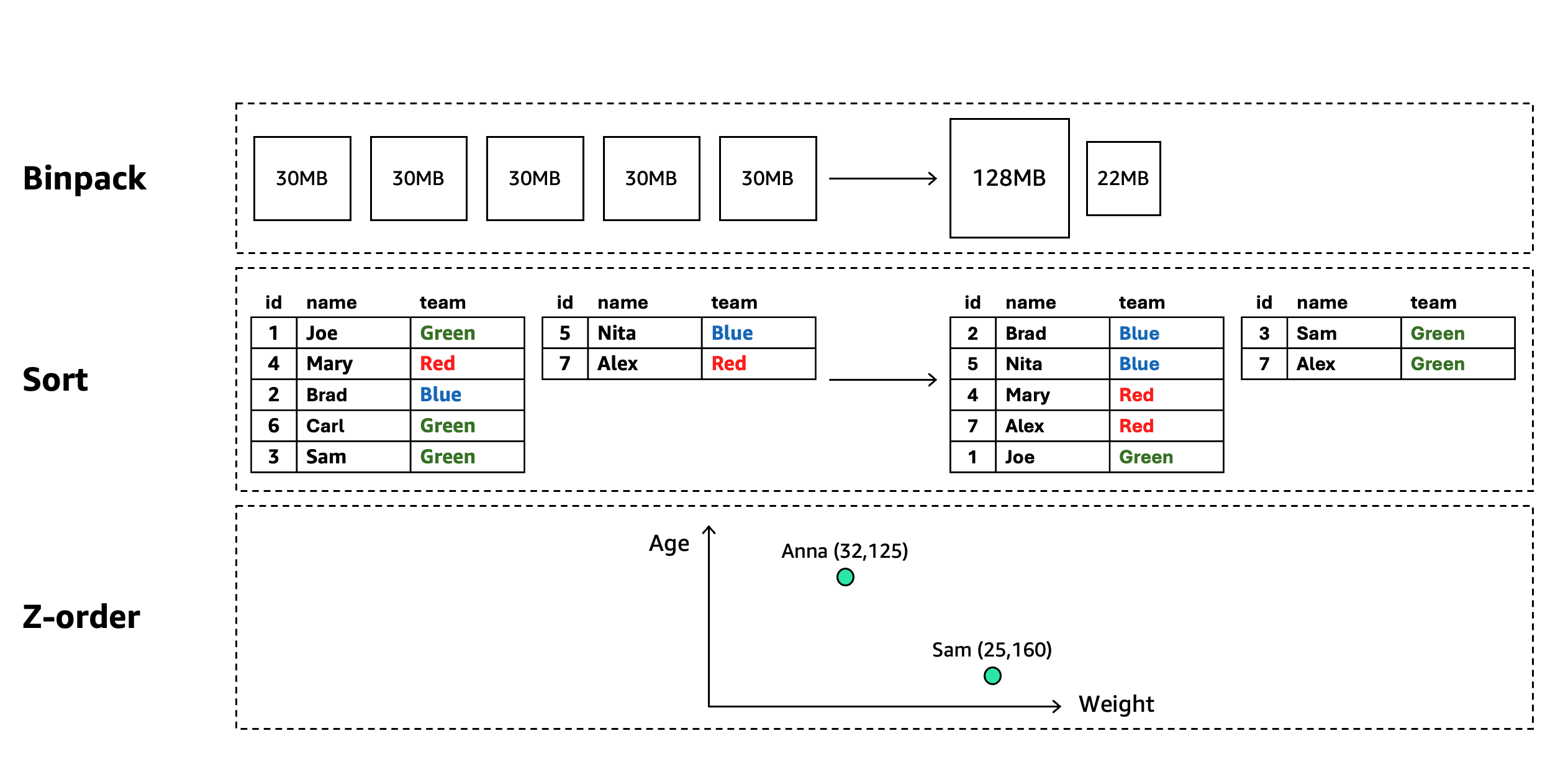
Apache Iceberg のコンパクションは、複数の戦略でテーブルパフォーマンスを最適化します。小さなファイルを大きなファイルに統合してメタデータの負荷と I/O リクエスト料金を削減し、delete ファイルをマージし、ソート順でデータをリライトしてパーティション述語を高速化し、多次元クラスタリングで関連データを近接配置して複数カラムでのスキャン効率を向上させます。Amazon S3 Tables は適切なポリシーでコンパクションを自動化し、テーブルのファイルレイアウトを継続的に最適化し、クエリパフォーマンスの向上とコスト削減を実現します。コンパクションのスケジューリング、リソース割り当て、実行を自動的に処理するため、運用負荷がなくなります。S3 Tables は以下のコンパクション手法をサポートしています。
- Binpack コンパクション – 多数の小さなデータファイルを少数の最適なサイズのファイルに統合し、メタデータの負荷を削減して、分散処理フレームワークでクエリパフォーマンスを低下させる「スモールファイル問題」を最小化します
- Sort コンパクション – 1 つ以上の指定カラムに従ってレコードを物理的に並べ替えるようにデータファイルをリライトし、メタデータベースのフィルタリングによる効率的なデータスキッピングを可能にして、ソートカラムに一致する述語でのクエリパフォーマンスを大幅に向上させます
- Z-order コンパクション – 空間充填曲線(space-filling curve)アルゴリズムで多次元データを 1 次元空間にマッピングし、複数カラムにわたって類似するレコードを近接配置して、Z-order 対象次元の任意のサブセットに対する述語を持つクエリを最適化します
- Auto (デフォルト) – Amazon S3 Tables がテーブルのソート順に基づいて最適なコンパクション戦略を選択します。すべてのテーブルのデフォルトのコンパクション戦略です。メタデータにソート順が定義されているテーブルには Sort コンパクションが自動的に適用されます。ソート順が定義されていないテーブルには Binpack コンパクションがデフォルトで使用されます
詳細は S3 Tables メンテナンスドキュメントと、AWS での Apache Iceberg 利用に関する規範的ガイダンスのコンパクションセクションをご覧ください。
適切なコンパクションの実施は、持続可能なデータレイク管理に不可欠です。最適化されていないテーブルは、時間の経過とともにパフォーマンスが低下しコストが増加します。定期的なコンパクションにより、小さなファイルの蓄積を防ぎ、最適なデータ構成を維持し、テーブルがペタバイト規模に成長してもクエリ効率を確保できます。パフォーマンス面の直接的なメリットに加え、適切に実行されたコンパクションは圧縮率とファイルレイアウトの改善によりストレージ効率を向上させます。より安定したクエリパフォーマンス、予測可能なコスト、そしてリアクティブなテーブルメンテナンスではなく価値を生み出す活動にエンジニアリングリソースを集中できるようになります。
S3 Tables の Intelligent-Tiering
前述のスナップショットとコンパクション機能に加え、S3 Tables は re:Invent 2025 で S3 Intelligent-Tiering によるストレージ最適化を提供開始しました。このストレージクラスは、アクセスパターンの変化に基づいてコスト効率の高いアクセス階層間でデータを自動的に移動します。データ取得にかかる費用、パフォーマンスへの影響、可用性の変化はありません。
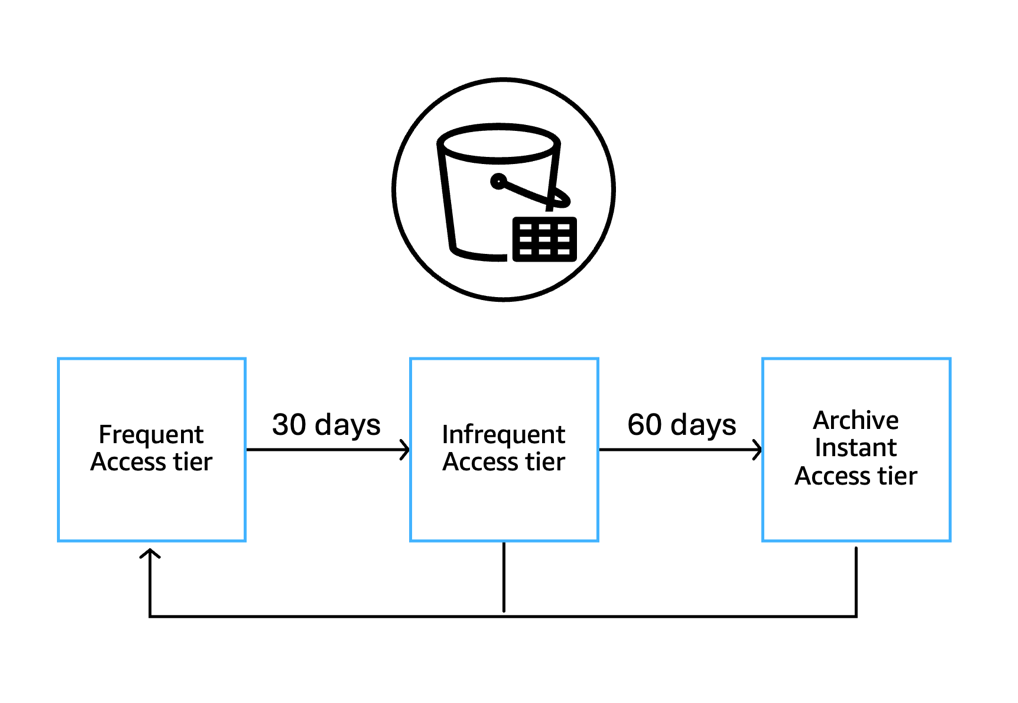
S3 Intelligent-Tiering は個々のデータファイルレベルで動作するため、1 つのテーブル内のファイルが異なる階層に同時に存在できます。データは以下の 3 つのアクセス階層で自動的に管理されます。
- 高頻度アクセス (FA) – すべてのファイルのデフォルト階層。他の階層のファイルもアクセスされるとここに戻ります
- 低頻度アクセス (IA) – 30 日間連続してアクセスがないファイルがここに移動します
- アーカイブインスタントアクセス (AIA) – 90 日間連続してアクセスがないファイルがここに移動します
すべての階層でミリ秒レイテンシー、高スループットパフォーマンス、99.9% の可用性、99.999999999% の耐久性が維持されます。オブジェクトは Get API 呼び出しでアクセスされると高頻度アクセス (FA) 階層に遷移します。テーブル内のデータファイルが読み取られるたびに、読み取りをトリガーした操作に関係なく発生します。データファイルの読み取り (FA 階層への遷移) をトリガーする操作は以下のとおりです。
- テーブルへの直接アクセス – データファイルを読み取るクエリやスキャン
- テーブル管理操作 – 既存のデータファイルの読み取りを必要とする LoadTable や UpdateTable などの REST API 呼び出し
- レプリケーション – テーブルがレプリケートされる際、コンテンツを転送先に転送するためにソースデータファイルを読み取る必要があり、IA/AIA 階層のファイルに対して Get 呼び出しがトリガーされます
重要なポイントとして、階層の遷移はデータファイルが読み取られたときにファイルレベルで発生し、テーブルが参照されたときではありません。基盤となる S3 オブジェクトの読み取りを伴う操作はすべて、オブジェクトを IA/AIA から FA 階層に移動させます。なお、128 KB 未満のファイルは高頻度アクセス階層に留まりますが、コンパクションでより大きなファイルに統合されると階層移動の対象になります。
S3 Tables の Intelligent-Tiering とメンテナンスタスクの連携
スナップショット管理やファイルクリーンアップなどのテーブルメンテナンス操作は、すべての階層で引き続き実行されます。コンパクションについては、S3 Tables は独自のアプローチをとります。コンパクションタスクの開始時に、コンパクションの種類 (Binpack、Sort、Z-order) に関係なく、S3 Tables はコンパクション候補のデータファイルの階層を確認します。この確認自体は階層の変更に影響しません。S3 Tables は FA 階層にあるファイルのみにコンパクションを実行し、30 日以上アクセスしていないデータやファイルが昇格されないようにします。FA 階層のファイルのみを対象とすることで、頻繁にアクセスされるデータのパフォーマンスを最適化しつつ、コールドデータのメンテナンスコストを削減できます。低い階層のデータファイルがアクセスされると FA 階層に戻り、コンパクションの対象になります。
コンパクションは高頻度アクセス階層のファイルのみを処理するため、低コスト階層のデータに対する削除操作では、自動的にコンパクションされない delete ファイルが生成されます。関連するデータファイルがアクセスされて高頻度アクセス階層に戻ると、delete ファイルもコンパクションの対象になります。この動作の詳細はドキュメントをご覧ください。
以下に、この動作を示す 2 つの例を紹介します。
Binpack コンパクションの例
シンプルな Binpack コンパクションのプロセスを見てみましょう。あるお客様が、当初有効にしていなかったコンパクションを有効にすることにしました。パーティション内の一部のデータファイルは頻繁にアクセスされていましたが、一部はアクセスされておらず、30 日後に自動的に IA 階層に遷移しています。

S3 Tables のコンパクションエンジンが起動すると、コンパクション候補のデータファイルの階層を検証します。FA 階層にあるデータファイルのみにコンパクションを実行し、アクセスされていないファイルはそのまま残します。IA や AIA 階層のファイルを確認しても、階層ステータスには影響しません。結果として、頻繁にアクセスされたデータはより効率的なファイルになり、アクセスされていないファイルのコスト削減は維持されます。2 週間後、残りの 2 つのファイルのデータにクエリがアクセスし、FA 階層に戻りました。
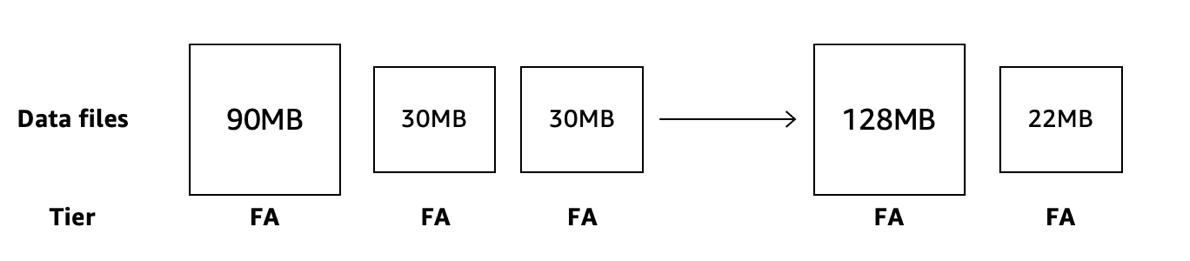
すべてのファイルが FA 階層にある状態で、次のコンパクションエンジンのイテレーションでは、S3 Tables のコンパクションエンジンが追加のコンパクションを実行し、2 つの小さなファイルを大きなファイルにマージします。
Delete ファイルの例
Apache Iceberg の equality delete、positional delete、deletion vector (v3) などの delete ファイルタイプは、個別の delete 参照ファイルを生成します。これらのファイルは merge-on-read で使用されるか、メンテナンス操作中にデータファイルにマージされます。ここでは equality delete を使って、コンパクションエンジンと S3 Tables Intelligent-Tiering の連携を説明し、delete ファイル管理とデータファイルのストレージ階層のライフサイクルを示します。
Apache Iceberg の equality delete は、位置ベースのメタデータを必要とせずに特定のフィルター条件に一致するレコードを削除できるデータ変更操作で、大規模データセットでの効率的かつ正確なデータ削除を可能にします。テーブル更新の merge-on-read 方式です。
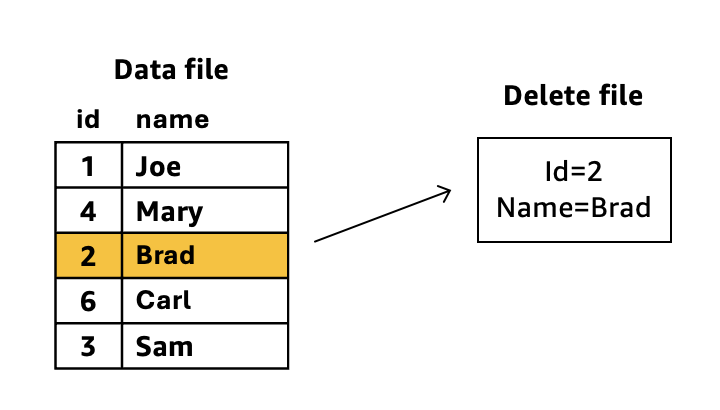
上の図の例では、クエリ時に Iceberg が delete ファイルの述語をデータファイルに動的に適用します。id=2、name=Brad の行はストレージに残りますが、クエリからは見えなくなります。Iceberg は元のデータファイルを変更せずに、読み取り操作中に削除情報を「マージ」します。この 2 つのファイルに対してコンパクションが実行されると、以下の処理が行われます。
- データファイルと delete ファイルの両方を読み取る
- id=2、name=Brad に一致する行をデータから物理的に削除する
- 削除された行を含まない新しい統合データファイルを作成する
- 条件が適用済みのため、個別の delete ファイルを除去する
テーブルデータへのアクセスを最適化し、読み取り操作中の処理負荷を削減するために一般的に有効な操作ですが、データファイルが IA や AIA 階層にある場合、S3 Tables はコンパクションを実行しません。ただし、ファイルが再度読み取られて高頻度アクセス階層に戻ると、コンパクションが新しいサイクルを開始する際にデータファイルの階層を評価し、FA 階層にあることを確認してメンテナンスタスクを実行します。不要な行を削除し、読み取りに最適化されたファイルを作成します。

S3 Tables でコンパクションを手動実行して delete ファイルの統合やレコードの完全削除を行うことも可能ですが、外部コンパクションジョブは Intelligent-Tiering ストレージクラスの認識とは独立して動作します。S3 Tables は外部コンパクションジョブの実行タイミングを予測できないため、Intelligent-Tiering の最適化はテーブルの自然なアクセスパターンのみに基づきます。手動コンパクションを実行すると、IA や AIA 階層に遷移したファイルを含むデータファイルが統合のために読み取られ、FA 階層に戻ります。その結果、ストレージコストが増加する可能性があります。
まとめ
データ駆動型の環境において、効果的なテーブルメンテナンスは大規模データレイクを管理する組織にとって不可欠です。S3 Tables は、スナップショット管理、コンパクション戦略、Intelligent-Tiering を統合したデータライフサイクル管理ソリューションを提供します。スナップショットで重要な履歴データを保持し、アクセスパターンを考慮したコンパクションでファイルレイアウトを最適化し、コールドデータをコスト効率の高いストレージ階層に自動的に移動します。
スナップショット管理、コンパクション、Intelligent-Tiering の連携により、日常的にアクセスされるデータも長期保存されるデータも、ライフサイクル全体を通じてパフォーマンスとコスト効率の両方が維持されます。組織は複雑なメンテナンスワークフローからデータからの価値ある洞察の抽出へと注力を移すことができ、安定したパフォーマンス、最適化されたストレージコスト、ビジネスニーズの変化に対応するスケーラブルなデータレイクの恩恵を受けられます。本ブログをお読みいただきありがとうございます。ご質問やコメントがありましたら、コメントセクションにお気軽にお寄せください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Akira Shimosako がレビューしました。