Amazon Web Services ブログ
「Physical AI on AWS 勉強会 #1」を開催しました
2026 年 3 月 24 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フィジカル AI 開発支援プログラム by AWS ジャパン」の採択企業向け勉強会を東京の AWS 目黒オフィスにて開催しました。勉強会では、 Physical AI on AWS リファレンスアーキテクチャ と Physical AI Scaffolding Kit の 紹介 、参加企業向けの個別相談会を開催しました。本プログラムについては、過去のブログも参照してください。
Physical AI on AWS リファレンスアーキテクチャ
Physical AI の開発における全体構成とそれを実現するための AWS 構成及び活用いただける AWS サービスを AI Specialist Solutions Architect の飯塚より紹介しました。
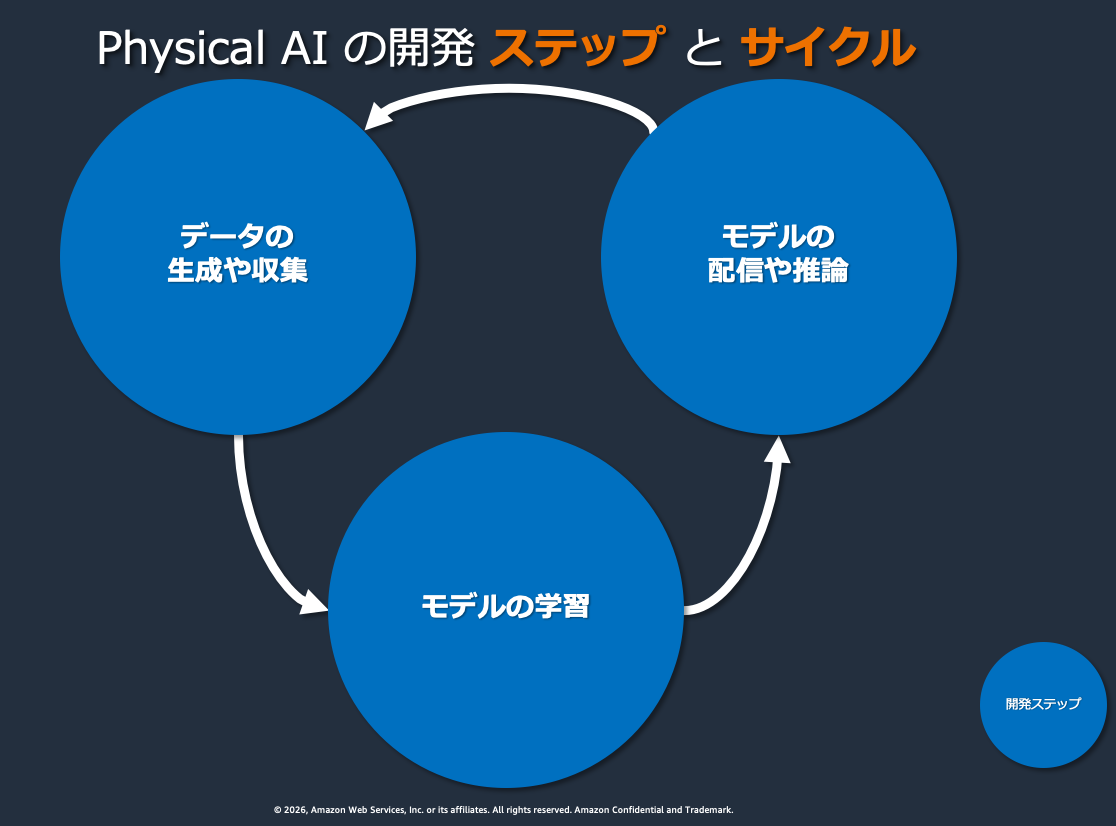
Physical AI の開発は「データ生成・収集 → モデル学習 → モデル配信・推論」の 3 ステップを繰り返すサイクルで進みます。シミュレータでの大量データ生成、GPU クラスタでの分散学習、エッジデバイスへのモデル配信と実環境での評価 ― これらを一気通貫で回す開発環境をいかに構築するかが、Physical AI 開発の生産性を大きく左右します。
まずデータ生成・収集のステップでは、NVIDIA Isaac Sim などのシミュレータを用いて、ロボットの動作データを大量に生成します。実ロボットで収集できるデータ量には物理的な限界があるため、シミュレータによる合成データ生成が不可欠です。AWS 上では Amazon EC2 の GPU インスタンスに Amazon DCV でリモートデスクトップ接続し、Isaac Sim を操作する構成が推奨されます。生成したデータは Amazon S3 に格納し、後続の学習ステップで利用します。
次にモデル学習のステップでは、収集したデータを使って Vision-Language-Action Model(VLA)をファインチューニングします。学習規模に応じた構成の使い分けが重要で、LoRA ファインチューニングのような軽量な学習であれば EC2 の GPU インスタンス単体で完結しますが、フルファインチューニングでは Amazon SageMaker HyperPod や AWS ParallelCluster による GPU クラスタ構成が必要になります。SageMaker HyperPod は GPU 故障時にノードを自動置換しチェックポイントからジョブを再開する機能を備えており、長時間の学習ジョブでも安定した実行を支えます。ストレージには Amazon FSx for Lustre を採用することで、S3 と透過的にデータを連携しながら、分散学習に求められる高速 I/O を実現できます。
GPU 確保も実践上の大きな課題です。AWS では用途に応じた予約の仕組みが用意されており、EC2 Capacity Blocks for ML では 1〜182 日の短期間で GPU を予約でき、需給に応じたダイナミックプライシングが適用されます。SageMaker HyperPod 環境では Flexible Training Plans による予約が可能です。いずれも AWS マネジメントコンソールからキャパシティの空き状況を確認し、利用開始日と終了日を指定して予約する流れになります。
最後にモデル配信・推論のステップでは、学習済みモデルをエッジデバイスや実ロボットにデプロイし、実環境で動作を評価します。AWS IoT Greengrass を使うことで、クラウドからエッジデバイスへのモデル配信をマネージドに管理できます。なお、ロボットのアクション生成に使う VLA モデルはリアルタイム性が求められるためエッジ側での推論が基本ですが、長期的な行動計画を担う LLM についてはクラウド側での推論も選択肢になります。評価結果は次のデータ収集にフィードバックされ、開発サイクルが回り続けます。
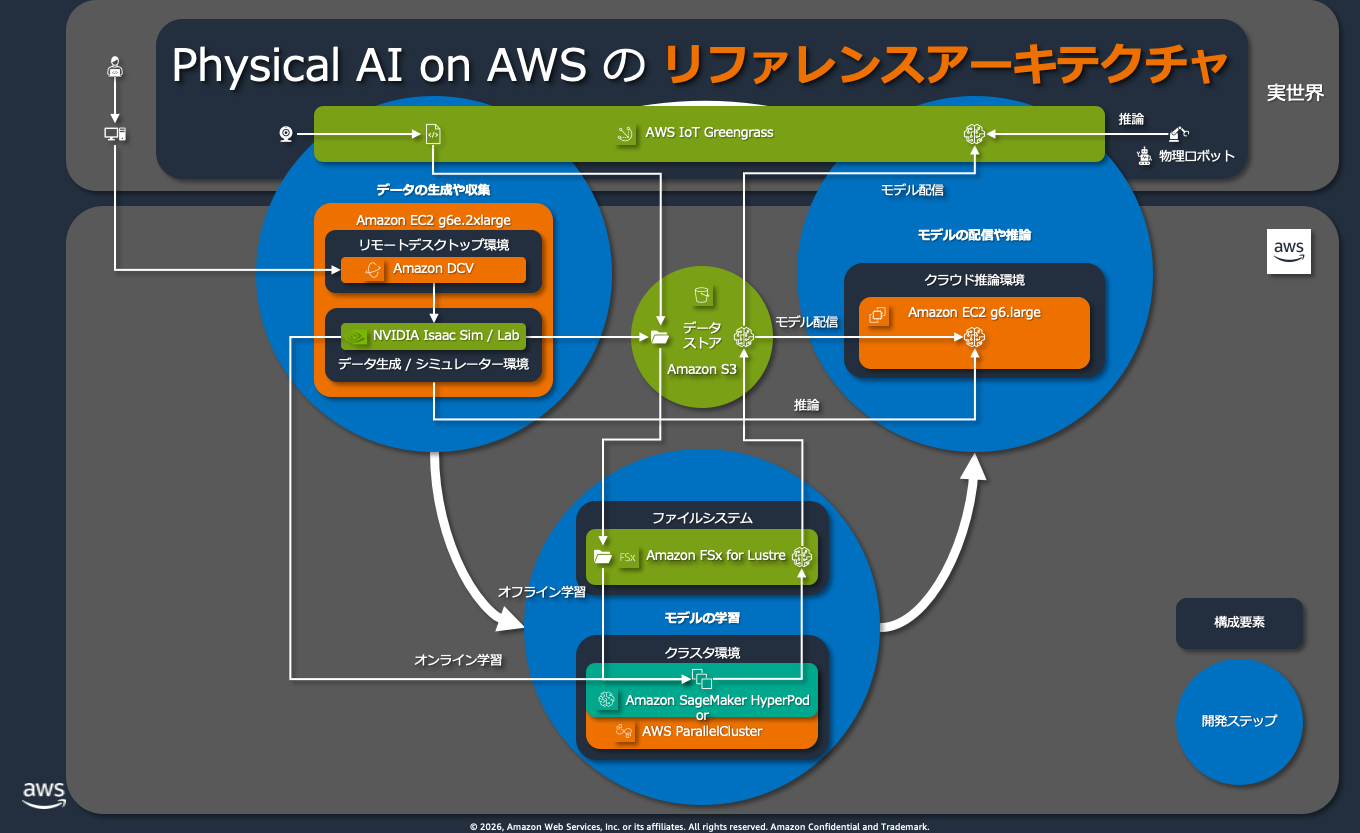
このアーキテクチャを俯瞰すると、Physical AI の開発には ML、HPC、IoT、ストレージ、ロボティクスと多様な技術領域が交差していることがわかります。単一の専門領域だけではカバーしきれない複合的な課題を、クラウド上で統合的に扱えるアーキテクチャの重要性がますます高まっています。AWS 上で統合的に扱うことができ、またそういったアーキテクチャの重要性がますます高まっています。
Physical AI Scaffolding Kit
VLA モデルのトレーニング環境を簡単に AWS 上に構築できるアセット「Physical AI Scaffolding Kit (PASK) 」の紹介をSenior IoT Prototyping Solutions Architect の市川と ML Prototyping Solutions Architect の石橋より紹介がありました。
Githubリポジトリ: https://github.com/aws-samples/sample-physical-ai-scaffolding-kit
PASK の概要
PASK は、Physical AI のモデルトレーニングに必要なサービスを AWS 上に簡単に構築できる CDK コードと学習実行用のサンプルスクリプトをまとめたアセットです。このアセットを使用することで、以下のような環境を数コマンドで構築できます。
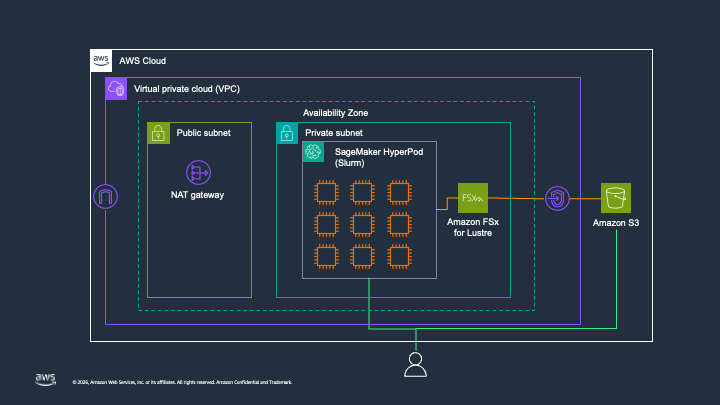
- Amazon SageMaker HyperPod: スケーラブルなクラスター環境です。
- Amazon FSx for Lustre: SageMaker HyperPod 内 Node 間共有ストレージ(S3 バケットとリンク)です。
SageMaker HyperPod クラスター環境の構築
まず、AWS CDK を使用した
SageMaker HyperPod
クラスターの構築方法を紹介しました。
詳細な手順につきましては、こちらをご確認ください。
クラスター構成:
- Controller Group: クラスター管理ノードです
- Login Group: ユーザーがログインし作業するためのノードです
- Worker Group: モデル学習などが実際に行われるノードです
デプロイの流れ:
- CDK のセットアップと関連ライブラリをインストールします
- cdk.json で環境設定を行います(クラスター名、インスタンスタイプなど)
- cdk deploy で一括デプロイを実行します(数十分で完了)
- SSH 接続を設定します(AWS Systems Manager Session Manager 経由)
- Worker Group を追加します
実行前に適宜GPU インスタンスの上限緩和申請や、Amazon SageMaker HyperPod flexible training plansによるインスタンスの確保などが必要になります。
ストレージ構成:
- 各ノードが共通の Lustre ストレージを
/fsxにマウントします。 /fsx/s3linkディレクトリが S3 にリンクされ、トレーニングデータなどを該当バケットにアップロードするだけで各 Node 間でデータが自動連携されます。
VLA モデルのトレーニング実行例
ここでは、2つの代表的な Vision-Language-Action (VLA) モデルのトレーニング方法を解説しました。
こちらのアセットでは、GR00T / openpi で用意されているサンプルデータセットを使って学習を行っていますが、S3 にデータをアップロードいただくことで、独自データセットでの学習も可能です。
1. NVIDIA Isaac GR00T のファインチューニング

GR00T は NVIDIA が開発する VLA モデルで PASK 環境上で以下のワークフローでトレーニングを実行します:
詳細な手順につきましては、こちらをご確認ください。
- 事前準備: Login Node で Git LFS インストール、GR00T リポジトリのクローン などを実行します
- Docker ビルド: Docker イメージのビルドと ECR へのプッシュを行います(Slurm ジョブとして実行)
- Enroot 実行: Enroot による Docker イメージの SquashFS 形式への変換を行います
- 学習実行: Slurm でファインチューニングジョブを投入します
2. OpenPI の LoRA ファインチューニング

OpenPI (Pi0 モデル) は Physical Intelligence が開発する VLA モデルで、LoRA ファインチューニングを上記同様の環境で実行できます:
詳細な手順につきましては、こちらをご確認ください。
- 開発環境: Docker イメージのビルドと ECR へのプッシュを行います
- SageMaker HyperPod (Login Node) 環境: セットアップスクリプト/Enroot 実行による環境準備を行います
- 正規化統計の計算: 学習データの統計情報を取得します(初回のみ実行)
- 学習実行: Worker Node (GPU インスタンス) へ LoRA ファインチューニングジョブを投入します
今後のスケジュール
|
時期 |
内容 |
|
2026 年 4 月 9 日 |
基盤モデル開発勉強会: LLM/VLM 開発の知見共有。Data Parallel でマルチノードクラスターへスケールさせることを見越した内容 |
|
2026 年 4 月 14日 |
|
|
2026 年 4 月中 |
ロボット勉強会: AI 開発者がロボット業界に入っていく上で知っておくべき知識の共有(内容・日程調整中) |
|
2026 年 5 月下旬 |
コミュニティイベント |
|
2026 年 6 月 25-26 日 |
Demo Day(中間報告会)at AWS Summit Tokyo 2026(幕張メッセ) |
|
2026 年 7 月下旬 |
最終成果報告会(AWS 麻布台ヒルズ オフィス 予定) |
おわりに
勉強会 #1では、AWS のサービスを利用して、フィジカル AI に関係してくるサービスや、スケーラブルなトレーニング環境についての基本的な知識を共有することができました。参加された企業の皆様は、既存の環境と合わせて活用いただくことで、より開発を加速させることができる様に、AWS ジャパンとしても引き続き支援をさせていただきます。
AWS ジャパンは、本プログラムを通じて日本のフィジカル AI エコシステムの発展に貢献してまいります。採択企業の皆さまの挑戦と、成果発表会をどうぞご期待ください。