Amazon Web Services ブログ
風力発電: AWS でのオープンデータ
 空間コンテキストでプロセスを記述するデータは、私たちの日常生活のいたるところにあり、ビッグデータの問題を支配しています。たとえば、道路ネットワークや衛星からのリモートセンシングデータを記述する地図データは、どこへ行く必要があるか示してくれます。シミュレーションやセンサーからの大気データは、天気予報や気候モデルの基礎となります。GPS を備えたデバイスおよびセンサーは、ほぼすべてのモバイルデータに空間的なコンテキストを提供できます。
空間コンテキストでプロセスを記述するデータは、私たちの日常生活のいたるところにあり、ビッグデータの問題を支配しています。たとえば、道路ネットワークや衛星からのリモートセンシングデータを記述する地図データは、どこへ行く必要があるか示してくれます。シミュレーションやセンサーからの大気データは、天気予報や気候モデルの基礎となります。GPS を備えたデバイスおよびセンサーは、ほぼすべてのモバイルデータに空間的なコンテキストを提供できます。
この記事では、Amazon のクラウドサービスで世界に公開されている膨大な (500 TB) オープン気象モデルデータセットの WIND ツールキットを紹介します。このデータにアクセスする方法と、こうしたデータに簡単にアクセスできるように開発されたオープンソースソフトウェアのいくつかを説明します。このソリューションでは、グリッド (ラスタ) 上に存在する地理空間データのサブセットを検討し、気象モデルから大規模なラスタデータへのアクセスを提供する方法を探索します。このソリューションでは、基礎的な AWS のサービスと、科学データ用によく採用されている形式である Hierarchical Data Format (HDF) を使用します。
ここで開発したアプローチは、疎ベクトルと密ベクトルおよび任意の次元の行列を記述できる HDF5 ファイルに収まる任意のデータに拡張することができます。この形式は、実験データとシミュレーションデータの両方について、物理学で既に普及しています。Wind Integration National Dataset (WIND) ツールキットと呼ばれる公共気象モデル出力の膨大なデータセットのためのグリッドデータストレージのソリューションについて検討します。また、他の大規模な地理空間データ管理の問題に対して一般的な戦略も取り上げます。
Wind Integration National Dataset
世界各地の電力系統において変動性の再生可能電力の普及水準が増加するにつれて、電力網の継続的な経済的かつ信頼性の高い運用を確保するための再生可能な統合に関する研究の重要性も増しています。WIND ツールキットは、現在最大の自由に利用できるグリッド統合データセットです。
WIND ツールキットは、ヴァイサラの 3 TIER サービスが開発しました。ヴァイサラは、既存の米国のグリッドへの風力エネルギーの統合に関する研究を支援する、National Renewable Energy Laboratory (NREL) の下請けでした。NREL は、米国エネルギー省の国立研究所ネットワークの一部であり、エネルギー効率、持続可能な輸送、再生可能な電力技術の科学と工学を推進する使命を担っています。
このツールキットは、グリッド統合研究をサポートするために世界中のコンサルタント、研究グループ、大学によって使用されています。あまり伝統的でない用途には、風力発電所のリソース評価 (Amazon データセンターへの電力の供給など)、バハ半島のカリフォルニアコンドルの移動に対する天気の影響の調査などもあります。
 アプリケーションの多様性は、このアクセスしやすくオープンな公開データの価値を強調しています。しかし、キャッチがあります: データセットは巨大です。WIND ツールキットは、複数の高さで 2km の空間解像度と 5 分間の時間解像度でシミュレーションされた 7 年分の大気 (気象) データを提供します。データセット全体は、0.5 ペタバイト (500 TB) のサイズであり、コロラド州ゴールデンの NREL ハイパフォーマンスコンピューティングデータセンターに保存されています。このデータセットを簡単かつコスト効率良く公開することは大きな課題です。
アプリケーションの多様性は、このアクセスしやすくオープンな公開データの価値を強調しています。しかし、キャッチがあります: データセットは巨大です。WIND ツールキットは、複数の高さで 2km の空間解像度と 5 分間の時間解像度でシミュレーションされた 7 年分の大気 (気象) データを提供します。データセット全体は、0.5 ペタバイト (500 TB) のサイズであり、コロラド州ゴールデンの NREL ハイパフォーマンスコンピューティングデータセンターに保存されています。このデータセットを簡単かつコスト効率良く公開することは大きな課題です。
他の研究所や公的機関がデータを世界に公開するようになると、私たちが経験したのと同様の問題に直面する可能性があります。巨大なデータセットをそのまま公開するための先行的かつ善意の努力により、技術的には利用可能であるが根本的に使用不可能なデータリソースが生まれました。こうしたデータリソースは、直感的でない形式で保存されているか、インデックス付けされ、潜在的用途のサブセットだけをサポートするように編成されています。数百テラバイトのデータをダウンロードすることは、多くの場合実用的ではありません。ほとんどのユーザーは、ビッグデータのクラスター (またはスーパーコンピュータ) にアクセスして、データをダウンロードした後に必要に応じて細かく分割することはできません。
そこで私たちは、効率的でスケーラブルで使いやすい方法で大量のデータ (50 テラバイト) を一般に公開することを目指しています。多くの場合、研究者は、ローカルに保存された小さなデータセット用に開発したのと同じソフトウェアとアルゴリズムを使用して、こうした巨大なクラウド配置のデータセットにアクセスできます。個々の分析に必要なデータだけをダウンロードする必要があります。この作業を機能させるために、HDF グループと協力して、今後リリースされる予定の高スケーラブルデータサービス上に構築しました。
この記事の残りの部分では、こうした巨大な地理空間データセットへの便利でスケーラブルなアクセスを提供するために Amazon EC2 と Amazon S3 のリソースを使用する HSDS ソフトウェアをどのように開発したかについて説明します。WIND ツールキットデータセットでの作業のために HSDS サービスをどのように配置したかを説明し、h5pyd Python ライブラリと REST API を使用してアクセスする方法を示します。最後に、AWS のサービスを使用してより「オープン」なデータセットを公開するための継続的な作業や、Amazon ECS や AWS Lambda のようなより新しい Amazon のサービスで HSDS を改善し拡張する方法についての情報で結論付けます。
大規模な地理空間データのためのスケーラブルなサービスの開発
HDF5 ファイル形式と API は長年使用されており、大規模な科学データセットを保存する有効な手段です。 たとえば、NASA の地球観測システム (EOS) 衛星は、HDF5 を使用して 1 日に 16TB 以上のデータを収集します。
クラウドの台頭に伴い、クラウドネイティブアーキテクチャのコンポーネントとして効果的に機能するように HDF5 を強化する方法を再考する新たな課題と機会があります。 HDF グループにとって、NREL と協力することは、本稼働規模のデータセットでアイデアを実践する絶好の機会でした。
HDF5 ファイルは、グループオブジェクトとデータセットオブジェクトの有向グラフで構成されています。 データセットは、ユーザー定義のメタデータタグと圧縮をサポートする多次元配列と考えることができます。 データセットに対する一般的な操作は、データを通常の小領域に読み書きすること (ハイパースラブ)、または個々の要素を読み書きすること (ポイント選択) です。 また、グループオブジェクトとデータセットオブジェクトには、それぞれ属性として知られている任意の数のユーザー定義のメタデータ要素を含めることができます。
多くの人々は、EC2 インスタンスで動作するように開発または移植されたアプリケーションで HDF ライブラリを使用してきましたが、多くの場合問題であると判明する、以下のような制約があります。
- HDF5 ライブラリは、S3 オブジェクトとして保存された HDF5 ファイルから直接読み取ることができません。最初のバイトを読み取る前に、ファイル全体 (多くの場合、GB 単位) をローカルストレージにコピーする必要があります。また、インスタンスを適切なサイズの EBS ボリュームで構成する必要もあります。
- HDF ライブラリは、(インスタンスのクラスターとは対照的に) インスタンス自体のコンピューティングリソースにしかアクセスできないため、多くの操作はライブラリがボトルネックとなります。
- HDF5 ファイルへの変更は、S3 に書き戻す前に、他のインスタンスが同じファイルに対して行った変更と何らかの形で同期させる必要があります。
こうした制約の解決策は、AWS の多くの製品に共通のパターンを使用して、HDF データモデルを中心とするサービスフレームワークを開発することです。このモデルを使用して、HDF グループは、従来は HDF5 ライブラリによって提供されていたすべての機能を提供する高スケーラブルデータサービス (HSDS) を作成しました。 このサービスを使用すると、独自のファイルボリュームを管理する必要はなく、必要なデータを読み書きするだけで済みます。
このサービスが耐久性のあるメディア (この場合は S3) への実際のデータ永続性を管理するため、ディスク管理について心配する必要はありません。必要なデータを必要なときにサービスから簡単にストリーミングできます。 第 2 に、機能をサービスの背後に置くことで、パフォーマンスを向上させるいくつかのトリックが可能になります (詳細は後で説明します)。最後に、HSDS は任意の数のクライアントが同時にデータにアクセスできるようにし、HDF5 を複数のリーダーおよびライター向けの調整メカニズムとして使用できるようにします。
HSDS アーキテクチャの設計では、HSDS サービスのスケーラビリティを実現する方法を十分に考えました。 HDF5 データへのアクセスについて、考慮すべき次の 2 つの異なるタイプのスケーリングがあります。
- サービスに多くのリクエストを行う複数のクライアント
- 大量のデータ処理を必要とする単一のリクエスト
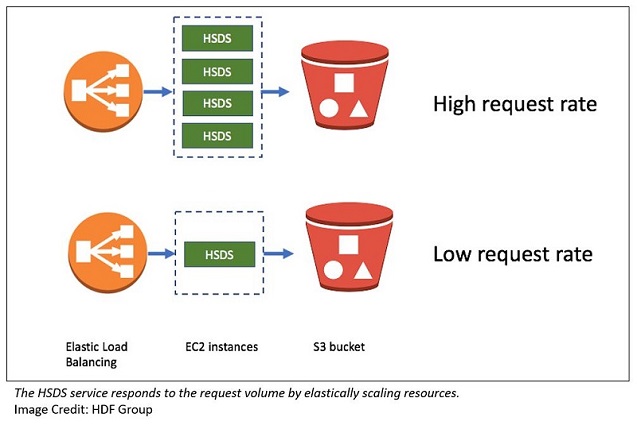
最初のスケーリングの課題に対処するために、ほとんどのサービスと同様に、リクエストレートの増加に応じてサービスがどのように応答するかを検討しました。 AWS には、この点で役立つ素晴らしいツールがいくつか用意されています。
- Auto Scaling グループ
- Elastic Load Balancing ロードバランサー
- 大規模な集約スループットレートを処理する S3 の能力
ロードバランサーの背後にある EC2 インスタンスのクラスターを使用することで、費用効果の高い方法でさまざまなクライアント負荷を処理できます。
第 2 のスケーリングの課題は、1 つのコンピューティングノードで大幅な処理時間を要する単一のリクエストに関係します。 WIND ツールキットでのこの例の 1 つは、特定の地理的ポイントとデータセットの 7 年間のすべての値を抽出することです。
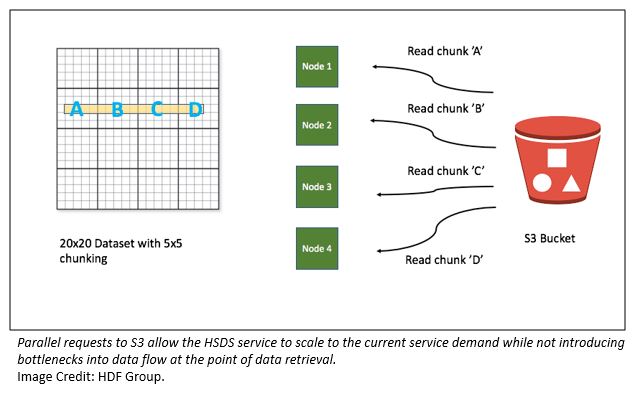
HDF5 では、大きなデータセットは通常「チャンク」として保存されます。つまり、通常の配列のパーティションです。 HSDS では、各チャンクは S3 のバイナリオブジェクトとして保存されます。 時系列値を取得するための逐次的なアプローチは、サービスが必要とされる各チャンクを S3 から読み込み、必要な要素を抽出して、次のチャンクに進むことです。 この場合、2557 チャンクの処理が伴い、かなり遅くなります。
幸いなことに、HSDS では、クラスターのコンピューティング機能と I/O 機能を活用することで、これをかなり高速化できます。 リクエストを受信すると、受信ノードは、クラスター内の他のノードを使用して、選択の異なる部分を読み取ることができます。 複数のノードが S3 から並列で読み取ると、クラスターのサイズが大きくなるにつれてパフォーマンスが向上します。
下の図は、4 つのチャンクと 4 つのノードで単純化されたケースでのこの動作の仕組みを示しています。
このアーキテクチャは実際にうまく機能しています。 WIND ツールキットと時系列抽出を使用したテストでは、4 ノードで約 60 秒、40 ノードで約 5 秒のリクエストレイテンシーを観測しました。パフォーマンスは、クラスターのサイズにほぼ比例します。
AWS Lambda をワーカー処理に使用する拡張を計画しています。 これにより、AWS Lambda で使用される CPU 時間のミリ秒単位でしか支払わなくてすむので、妥当なコストで 1000 通りの並列読み取りが可能になります。
HSDS と AWS を使用した大気データへのパブリックアクセス
WIND ツールキットのデータをリリースする際の初期の課題は、さまざまなユースケースのデータをサブセット化する方法を決定することでした。一般に、0.5 PB のデータ全体にアクセスする必要がある研究者は殆どなく、指示された構成データセットを作成することによって多くの効率化とコスト削減を実現することができます。

NREL のグリッド統合研究者は、当初、風力資源が開発に適していると思われる 120,000 ポイントを選択することにより、2 TB のサブセットを抽出しました。彼らはまた、風力アプリケーションに重要なデータ (100 m の風速、電力に変換)、グリッド研究を行う人々にとって最も関心がある場所だけを選択しました。より多くのデータ解像度が必要な残りのユーザーをサポートするために、データを 60 分の時間解像度までダウンサンプリングし、他のすべての変数と空間解像度をそのまま維持しました。これで削減されたデータセットは、30 以上の大気データ変数を 7 年間、60 分の時間解像度で記述する 50 TB のデータです。
 WindViz ブラウザベースの Gridded Wind Toolkit Visualizer が、JavaScript で HSDS REST API の実装例として作成されました。このビジュアライザーは、webpack と Babel を含む最新の開発ツールチェーンを使用して、ECMAScript 2016 のスタイルで記述されています。ソースコードは、GitHub リポジトリから入手できます。デモページは GitHub ページを介してホストされており、クロスオリジン AJAX リクエストを使用して、EC2 インフラストラクチャで実行されている HSDS サービスからデータを取得します。このビジュアライザーを使用して、マップ上のグリッド付きツールキットデータを探索することができます。特定の地域を拡大して、完全な空間解像度を実現します。
WindViz ブラウザベースの Gridded Wind Toolkit Visualizer が、JavaScript で HSDS REST API の実装例として作成されました。このビジュアライザーは、webpack と Babel を含む最新の開発ツールチェーンを使用して、ECMAScript 2016 のスタイルで記述されています。ソースコードは、GitHub リポジトリから入手できます。デモページは GitHub ページを介してホストされており、クロスオリジン AJAX リクエストを使用して、EC2 インフラストラクチャで実行されている HSDS サービスからデータを取得します。このビジュアライザーを使用して、マップ上のグリッド付きツールキットデータを探索することができます。特定の地域を拡大して、完全な空間解像度を実現します。
広く使われている h5py ライブラリの分散版である h5pyd Python ライブラリを使用すると、プログラムによるアクセスが可能です。ユーザーはデータセット (変数) とやりとりし、そのデータが (時間 x 経度 x 緯度) キューブ形式に収まるように分割します。
例とユースケースは、Jupyter ノートブックのセットに記述があり、GitHub:
NREL/hsds-examples から入手できます。
これらのノートブックをオレゴンリージョンの EC2 インスタンスで実行するには、次のコマンドを実行します。
これで、Jupyter ノートブックサーバーが EC2 サーバーで動作しています。
ラップトップから、SSH トンネルを作成します。
これで正しいトークンを使用して localhost:8888 をブラウズし、ローカルの場合と同様にノートブックでやり取りできます。ディレクトリ内には、HSDS API にアクセスし、matplotlib を使用して風と気象のデータをプロットするためのサンプルがあります。
アクセスコントロールとコスト削減
最後の懸念事項は、レート制限とアクセスコントロールです。HSDS サービスはスケーラブルで比較的堅牢ですが、実際にはいくつかの懸念事項がありました。
- (たとえば、S3からデータセット全体を繰り返しダウンロードしようとする人物など) 退出に高い費用がかかる悪意のある使用や偶発的な使用からどのように保護できるでしょうか?
- データリソースの価値を文書化して費用を正当化するために、誰がデータを使用しているかを把握するにはどうすればよいでしょうか?
- 費用が高すぎる場合、API の使用の一部または全部に課金して、費用に充てることができるでしょうか?
こうした問題にアプローチするために、Amazon API Gateway および SaaS の収益化のための AWS Marketplace との単純な統合ならびにサードパーティの API プロキシを使用して調査しました。
最終的に、http://data.gov に密接に関与しているため、API Umbrella を使用することを選択しました。AWS Marketplace は将来のデータセットのための魅力的な選択肢ですが、少なくとも現在は、このデータセットを完全にオープンに保つことに決定しました。コミュニティの利用と関連費用が増加するにつれて、Marketplace を再考する可能性があります。一方で、API Umbrella は、すぐに使えるレート制限と API キー登録のコントロールを提供し、HSDS のフロントエンドプロキシとして実装するのは簡単でした。API の使用料を請求する可能性のあるアプリケーションでは、Amazon API Gateway と AWS Marketplace を使用して同様の戦略を実現できます。
進行中の作業およびその他のリソース
NREL やその他の政府研究機関、地方自治体、組織が一般の人々とデータを共有しようとしているので、多くの方々がこの記事で説明したアーキテクチャでアプローチしようとしている課題と同様の課題に直面することが予想されます。大規模なデータセットを提供することは 1 つの課題です。ユーザーにとって経済的で便利な方法でこれを行うことは、非常に難しい目標です。AWS クラウドネイティブのサービスと既存の HDF ファイル形式の基盤を使用することで、その課題を意味のある方法で解決することができました。
その他の参考資料
この記事が参考になった場合は、「Perform Near Real-time Analytics on Streaming Data with Amazon Kinesis and Amazon Elasticsearch Service」、「Analyze OpenFDA Data in R with Amazon S3 and Amazon Athena」、「Querying OpenStreetMap with Amazon Athena」もぜひご覧ください。
著者について
 Caleb Phillips 博士は、国立再生可能エネルギー研究所の計算科学センターのデータ分析および可視化グループの上級サイエンティストです。Caleb のバックグラウンドは、コンピュータサイエンスシステム、応用統計、計算モデリング、最適化です。NREL での彼の研究は、再生可能エネルギー技術の幅広い分野に及んでおり、最新のデータサイエンス技術を大規模なデータ問題に適用することに重点を置いています。
Caleb Phillips 博士は、国立再生可能エネルギー研究所の計算科学センターのデータ分析および可視化グループの上級サイエンティストです。Caleb のバックグラウンドは、コンピュータサイエンスシステム、応用統計、計算モデリング、最適化です。NREL での彼の研究は、再生可能エネルギー技術の幅広い分野に及んでおり、最新のデータサイエンス技術を大規模なデータ問題に適用することに重点を置いています。
 Caroline Draxl 博士は、NREL の上級サイエンティストです。 彼女は、中規模から風力発電の規模まで、米国エネルギー省の研究とモデリング活動を支援しています。Caroline はメソスケールモデルを使用して様々な国の風力資源を研究し、オンショアおよびオフショアの境界層研究やメゾスケールフローフィーチャ (キロメートル規模) とマイクロスケール (数十メートル規模) の結合に参加しています。彼女は、オーストリアのインスブルック大学から気象学と地球物理学の修士号を、デンマーク工科大学から気象学の博士号を取得しています。
Caroline Draxl 博士は、NREL の上級サイエンティストです。 彼女は、中規模から風力発電の規模まで、米国エネルギー省の研究とモデリング活動を支援しています。Caroline はメソスケールモデルを使用して様々な国の風力資源を研究し、オンショアおよびオフショアの境界層研究やメゾスケールフローフィーチャ (キロメートル規模) とマイクロスケール (数十メートル規模) の結合に参加しています。彼女は、オーストリアのインスブルック大学から気象学と地球物理学の修士号を、デンマーク工科大学から気象学の博士号を取得しています。
 John Readey は、2014 年 6 月に入社して以来、HDF グループのシニアアーキテクトを務めています。 彼の関心は、HDF に関連するウェブサービス、HDF の使用をサポートするアプリケーション、データの可視化などにあります。HDF グループに加わる前、John は 2006 〜 2014 年の間、Amazon.com で働いており、電子商取引と AWS のサービスベースのシステムを開発しました。
John Readey は、2014 年 6 月に入社して以来、HDF グループのシニアアーキテクトを務めています。 彼の関心は、HDF に関連するウェブサービス、HDF の使用をサポートするアプリケーション、データの可視化などにあります。HDF グループに加わる前、John は 2006 〜 2014 年の間、Amazon.com で働いており、電子商取引と AWS のサービスベースのシステムを開発しました。
 Jordan Perr-Sauer は、国立再生可能エネルギー研究所の計算科学センターのデータ分析および可視化グループの RPP インターンです。 Jordan は、ソフトウェアエンジニアリングでの専門的バックグラウンドと応用数学での学問的トレーニングを活用して、アメリカと世界が直面している困難な問題を解決したいと願っています。
Jordan Perr-Sauer は、国立再生可能エネルギー研究所の計算科学センターのデータ分析および可視化グループの RPP インターンです。 Jordan は、ソフトウェアエンジニアリングでの専門的バックグラウンドと応用数学での学問的トレーニングを活用して、アメリカと世界が直面している困難な問題を解決したいと願っています。