AWS Big Data Blog
Perform Near Real-time Analytics on Streaming Data with Amazon Kinesis and Amazon Elasticsearch Service
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Nowadays, streaming data is seen and used everywhere—from social networks, to mobile and web applications, IoT devices, instrumentation in data centers, and many other sources. As the speed and volume of this type of data increases, the need to perform data analysis in real time with machine learning algorithms and extract a deeper understanding from the data becomes ever more important. For example, you might want a continuous monitoring system to detect sentiment changes in a social media feed so that you can react to the sentiment in near real time.
In this post, we use Amazon Kinesis Data Streams to collect and store streaming data. We then use Amazon Kinesis Data Analytics to process and analyze the streaming data continuously. Specifically, we use the Kinesis Data Analytics built-in RANDOM_CUT_FOREST function, a machine learning algorithm, to detect anomalies in the streaming data. Finally, we use Amazon Kinesis Data Firehose to export the anomalies data to Amazon OpenSearch Service. We then build a simple dashboard in the open source tool Kibana to visualize the result.
Solution overview
The following diagram depicts a high-level overview of this solution.

Amazon Kinesis Data Streams
You can use Amazon Kinesis Data Streams to build your own streaming application. This application can process and analyze streaming data by continuously capturing and storing terabytes of data per hour from hundreds of thousands of sources.
Amazon Kinesis Data Analytics
Kinesis Data Analytics provides an easy and familiar standard SQL language to analyze streaming data in real time. One of its most powerful features is that there are no new languages, processing frameworks, or complex machine learning algorithms that you need to learn.
Amazon Kinesis Data Firehose
Kinesis Data Firehose is the easiest way to load streaming data into AWS. It can capture, transform, and load streaming data into Amazon S3, Amazon Redshift, and Amazon OpenSearch Service.
Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed service that makes it easy to deploy, operate, and scale Elasticsearch for log analytics, full text search, application monitoring, and more.
Solution summary
The following is a quick walkthrough of the solution that’s presented in the diagram:
- IoT sensors send streaming data into Kinesis Data Streams. In this post, you use a Python script to simulate an IoT temperature sensor device that sends the streaming data.
- By using the built-in RANDOM_CUT_FOREST function in Kinesis Data Analytics, you can detect anomalies in real time with the sensor data that is stored in Kinesis Data Streams. RANDOM_CUT_FOREST is also an appropriate algorithm for many other kinds of anomaly-detection use cases—for example, the media sentiment example mentioned earlier in this post.
- The processed anomaly data is then loaded into the Kinesis Data Firehose delivery stream.
- By using the built-in integration that Kinesis Data Firehose has with Amazon OpenSearch Service, you can easily export the processed anomaly data into the service and visualize it with Kibana.
Implementation steps
The following sections walk through the implementation steps in detail.
Creating the delivery stream
- Open the Amazon Kinesis Data Streams console.
- Create a new Kinesis stream. Give it a name that indicates it’s for raw incoming stream data—for example, RawStreamData. For Number of shards, type 1.

- The Python code provided below simulates a streaming application, such as an IoT device, and generates random data and anomalies into a Kinesis stream. The code generates two temperature ranges, where the first range is the hypothetical sensor’s normal operating temperature range (10–20), and the second is the anomaly temperature range (100–120).Make sure to change the stream name on line 16 and 20 and the Region on line 6 to match your configuration. Alternatively, you can download the Amazon Kinesis Data Generator from this repository and use it to generate the data.
- Open the Amazon OpenSearch Service console and create a new domain.
- Give the domain a unique name. In the Configure cluster screen, use the default settings.
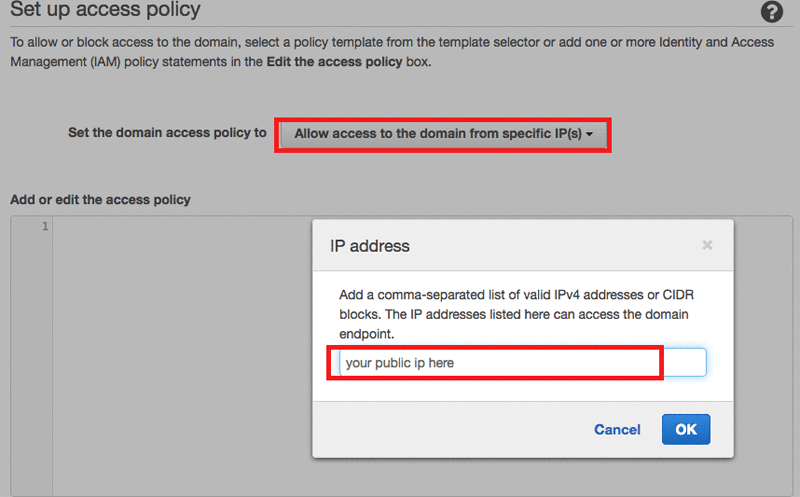
- In the Set up access policy screen, in the Set the domain access policy list, choose Allow access to the domain from specific IP(s).
- Enter the public IP address of your computer.
Note: If you’re working behind a proxy or firewall, see the “Use a proxy to simplify request signing” section in this AWS Database blog post to learn how to work with a proxy. For additional information about securing access to your Amazon OpenSearch Service domain, see How to Control Access to Your Amazon OpenSerach Service Domain in the AWS Security Blog.
- After the Amazon OpenSearch Service domain is up and running, you can set up and configure Kinesis Data Firehose to export results to Amazon OpenSearch Service :
- Open the Amazon Kinesis Data Firehose console and choose Create Delivery Stream.
- In the Destination dropdown list, choose Amazon OpenSearch Service e.

- Type a stream name, and choose the Amazon OpenSearch Service domain that you created in Step 4.
- Provide an index name and ES type. In the S3 bucket dropdown list, choose Create New S3 bucket. Choose Next.

- In the configuration, change the Elasticsearch Buffer size to 1 MB and the Buffer interval to 60s. Use the default settings for all other fields. This shortens the time for the data to reach the ES cluster.
- Under IAM Role, choose Create/Update existing IAM role.
The best practice is to create a new role every time. Otherwise, the console keeps adding policy documents to the same role. Eventually the size of the attached policies causes IAM to reject the role, but it does it in a non-obvious way, where the console basically quits functioning. - Choose Next to move to the Review page.

- Review the configuration, and then choose Create Delivery Stream.
- Run the Python file for 1–2 minutes, and then press Ctrl+C to stop the execution. This loads some data into the stream for you to visualize in the next step.
Analyzing the data
Now it’s time to analyze the IoT streaming data using Amazon Kinesis Data Analytics.
- Open the Amazon Kinesis Data Analytics console and create a new application. Give the application a name, and then choose Create Application.
- On the next screen, choose Connect to a source. Choose the raw incoming data stream that you created earlier. (Note the stream name Source_SQL_STREAM_001 because you will need it later.)
- Use the default settings for everything else. When the schema discovery process is complete, it displays a success message with the formatted stream sample in a table as shown in the following screenshot. Review the data, and then choose Save and continue.

- Next, choose Go to SQL editor. When prompted, choose Yes, start application.
- Copy the following SQL code and paste it into the SQL editor window.
- Choose Save and run SQL.
As the application is running, it displays the results as stream data arrives. If you don’t see any data coming in, run the Python script again to generate some fresh data. When there is data, it appears in a grid as shown in the following screenshot. Note that you are selecting data from the source stream name Source_SQL_STREAM_001 that you created previously. Also note the ANOMALY_SCORE column. This is the value that the Random_Cut_Forest function calculates based on the temperature ranges provided by the Python script. Higher (anomaly) temperature ranges have a higher score.Looking at the SQL code, note that the first two blocks of code create two new streams to store temporary data and the final result. The third block of code analyzes the raw source data (Stream_Pump_1) using the Random_Cut_Forest function. It calculates an anomaly score (ANOMALY_SCORE) and inserts it into the TEMP_STREAM stream. The final code block loads the result stored in the TEMP_STREAM into DESTINATION_SQL_STREAM.
Note that you are selecting data from the source stream name Source_SQL_STREAM_001 that you created previously. Also note the ANOMALY_SCORE column. This is the value that the Random_Cut_Forest function calculates based on the temperature ranges provided by the Python script. Higher (anomaly) temperature ranges have a higher score.Looking at the SQL code, note that the first two blocks of code create two new streams to store temporary data and the final result. The third block of code analyzes the raw source data (Stream_Pump_1) using the Random_Cut_Forest function. It calculates an anomaly score (ANOMALY_SCORE) and inserts it into the TEMP_STREAM stream. The final code block loads the result stored in the TEMP_STREAM into DESTINATION_SQL_STREAM. - Choose Exit (done editing) next to the Save and run SQL button to return to the application configuration page.
Load processed data into the Kinesis Data Firehose delivery stream
Now, you can export the result from DESTINATION_SQL_STREAM into the Amazon Kinesis Data Firehose stream that you created previously.
- On the application configuration page, choose Connect to a destination.
- Choose the stream name that you created earlier, and use the default settings for everything else. Then choose Save and Continue.

- On the application configuration page, choose Exit to Kinesis Data Analytics applications to return to the Amazon Kinesis Data Analytics console.
- Run the Python script again for 4–5 minutes to generate enough data to flow through Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and finally into the Amazon OpenSearch Service domain.
- Open the Kinesis Data Firehose console, choose the stream, and then choose the Monitoring

- As the processed data flows into Kinesis Data Firehose and Amazon OpenSearch Service, the metrics appear on the Delivery Stream metrics page. Keep in mind that the metrics page takes a few minutes to refresh with the latest data.

- Open the Amazon OpenSearch Service dashboard in the AWS Management Console. The count in the Searchable documents column increases as shown in the following screenshot. In addition, the domain shows a cluster health of Yellow. This is because, by default, it needs two instances to deploy redundant copies of the index. To fix this, you can deploy two instances instead of one.

Visualize the data using Kibana
Now it’s time to launch Kibana and visualize the data.
- Use the ES domain link to go to the cluster detail page, and then choose the Kibana link as shown in the following screenshot.

If you’re working behind a proxy or firewall, see the “Use a proxy to simplify request signing” section in this blog post to learn how to work with a proxy. - In the Kibana dashboard, choose the Discover tab to perform a query.

- You can also visualize the data using the different types of charts offered by Kibana. For example, by going to the Visualize tab, you can quickly create a split bar chart that aggregates by ANOMALY_SCORE per minute.


Conclusion
In this post, you learned how to use Amazon Kinesis to collect, process, and analyze real-time streaming data, and then export the results to Amazon OpenSearch Service for analysis and visualization with Kibana. If you have comments about this post, add them to the “Comments” section below. If you have questions or issues with implementing this solution, please open a new thread on the Amazon Kinesis or Amazon OpenSearch Service discussion forums.
Next Steps
Take your skills to the next level. Learn real-time clickstream anomaly detection with Amazon Kinesis Data Analytics.

About the Author
 Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS.
Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS.