AWS Big Data Blog
Tag: Amazon Kinesis

Krones real-time production line monitoring with Amazon Managed Service for Apache Flink
Krones provides breweries, beverage bottlers, and food producers all over the world with individual machines and complete production lines. This post shows how Krones built a streaming solution to monitor their lines, based on Amazon Kinesis and Amazon Managed Service for Apache Flink. These fully managed services reduce the complexity of building streaming applications with Apache Flink. Managed Service for Apache Flink manages the underlying Apache Flink components that provide durable application state, metrics, logs, and more, and Kinesis enables you to cost-effectively process streaming data at any scale.

Processing large records with Amazon Kinesis Data Streams
In this post, we show you some different options for handling large records within Kinesis Data Streams and the benefits and disadvantages of each approach. We provide some sample code for each option to help you get started with any of these approaches with your own workloads.

Stream CDC into an Amazon S3 data lake in Parquet format with AWS DMS
July 2025: This post was reviewed and updated for accuracy. Most organizations generate data in real time and ever-increasing volumes. Data is captured from a variety of sources, such as transactional and reporting databases, application logs, customer-facing websites, and external feeds. Companies want to capture, transform, and analyze this time-sensitive data to improve customer experiences, […]
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]
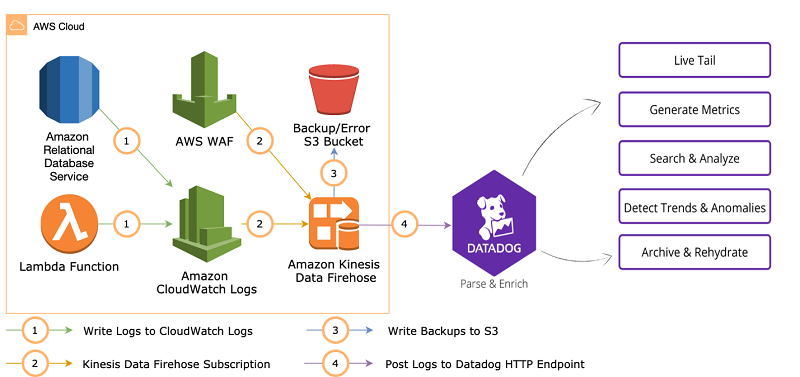
Analyze logs with Datadog using Amazon Kinesis Data Firehose HTTP endpoint delivery
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Kinesis Data Firehose now provides an easy-to-configure and straightforward process for streaming data to a third-party service for analysis, including logs from AWS services. Due to the varying formats and high […]
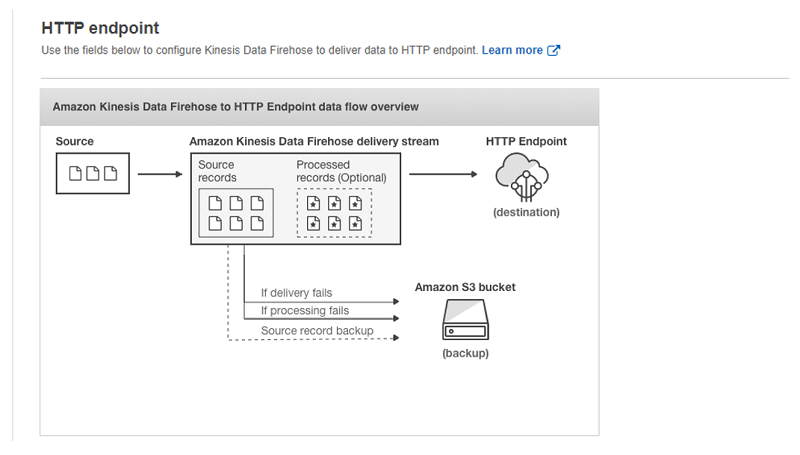
Stream data to an HTTP endpoint with Amazon Data Firehose
November 2024: This post was reviewed and updated for accuracy. The value of data is time sensitive. Streaming data services can help you move data quickly from data sources to new destinations for downstream processing. For example, Amazon Data Firehose can reliably load streaming data into data stores like Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, and […]
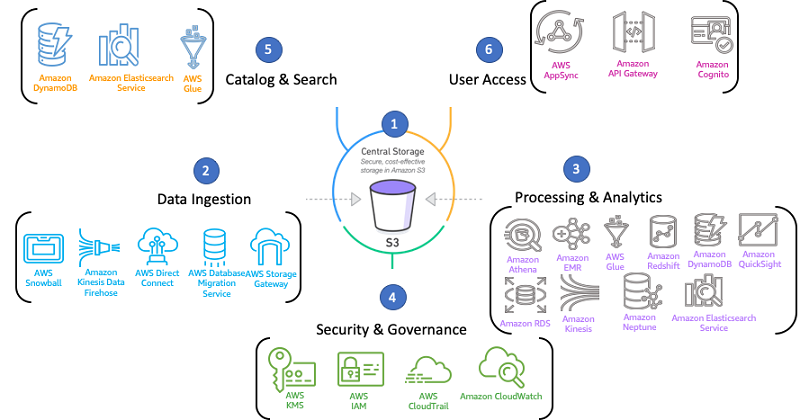
Build an AWS Well-Architected environment with the Analytics Lens
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.

Under the hood: Scaling your Kinesis data streams
Real-time delivery of data and insights enables businesses to pivot quickly in response to changes in demand, user engagement, and infrastructure events, among many others. Amazon Kinesis offers a managed service that lets you focus on building your applications, rather than managing infrastructure. Scalability is provided out-of-the-box, allowing you to ingest and process gigabytes of […]

Amazon Data Firehose custom prefixes for Amazon S3 objects
July 2024: This post was reviewed and updated for accuracy. In February 2019, Amazon Web Services (AWS) announced a new feature in Amazon Data Firehose called Custom Prefixes for Amazon S3 Objects. It lets customers specify a custom expression for the Amazon S3 prefix where data records are delivered. Previously, Firehose allowed only specifying a […]

Build and run streaming applications with Apache Flink and Amazon Kinesis Data Analytics for Java Applications
In this post, we discuss how you can use Apache Flink and Amazon Kinesis Data Analytics for Java Applications to address these challenges. We explore how to build a reliable, scalable, and highly available streaming architecture based on managed services that substantially reduce the operational overhead compared to a self-managed environment.