Amazon Web Services ブログ
AWS Batchを用いた大規模なタンパク質立体構造予測
タンパク質は、体内で重要な役割を果たす巨大な生体分子です。タンパク質の物理的な構造を知ることは、その機能を理解する上で重要な鍵となります。しかし多くの場合、タンパク質の構造を実験的に決定することは困難であり、高額な費用を要します。そこで近年、機械学習アルゴリズムを用いてタンパク質の構造を予測することが検討されています。AlphaFold2 や RoseTTAFold など、複数の著名な研究チームがタンパク質構造予測に関するアルゴリズムを発表しています。彼らの研究は重要なものであり、Science 誌の 2021 Breakthrough of the Year に選ばれました。
AlphaFold2 や RoseTTAFold は、既知のタンパク質のテンプレートを用いて学習させたMultitrack transformer architectureを使用して、未知のペプチド配列の立体構造を予測します。これらの予測は GPU に大きく依存し、完了するまでに数分から数日を要します。予測するための入力には、多重配列アライメント (Multiple sequence alignment; MSA) データが含まれます。MSA 生成のアルゴリズムは CPU に依存し、それ自体で処理に数時間を要することもあります。
MSA 生成と構造予測の両方を同じ計算機で実行する場合、コスト効率が悪くなります。なぜなら、MSA 生成プロセスが実行されている間に、構造予測に必要である高価な GPU リソースは使用されないためです。その代わり、AWS Batch のようなハイパフォーマンスコンピューティング (HPC) サービスを使用することで、CPU やメモリ、GPU リソースを最適に組み合わせたコンテナ化されたジョブとして各ステップを実行することができます。
この投稿では、RoseTTAFold を例に挙げ、AI ドリブンなタンパク質フォールディングのアルゴリズムを実行するために、AWS Batch やその他のサービスをプロビジョニングして使用する方法を紹介します。
[訳注] また、AlphaFold2 でお試ししたい方はこちらの GitHub リポジトリをご覧ください。
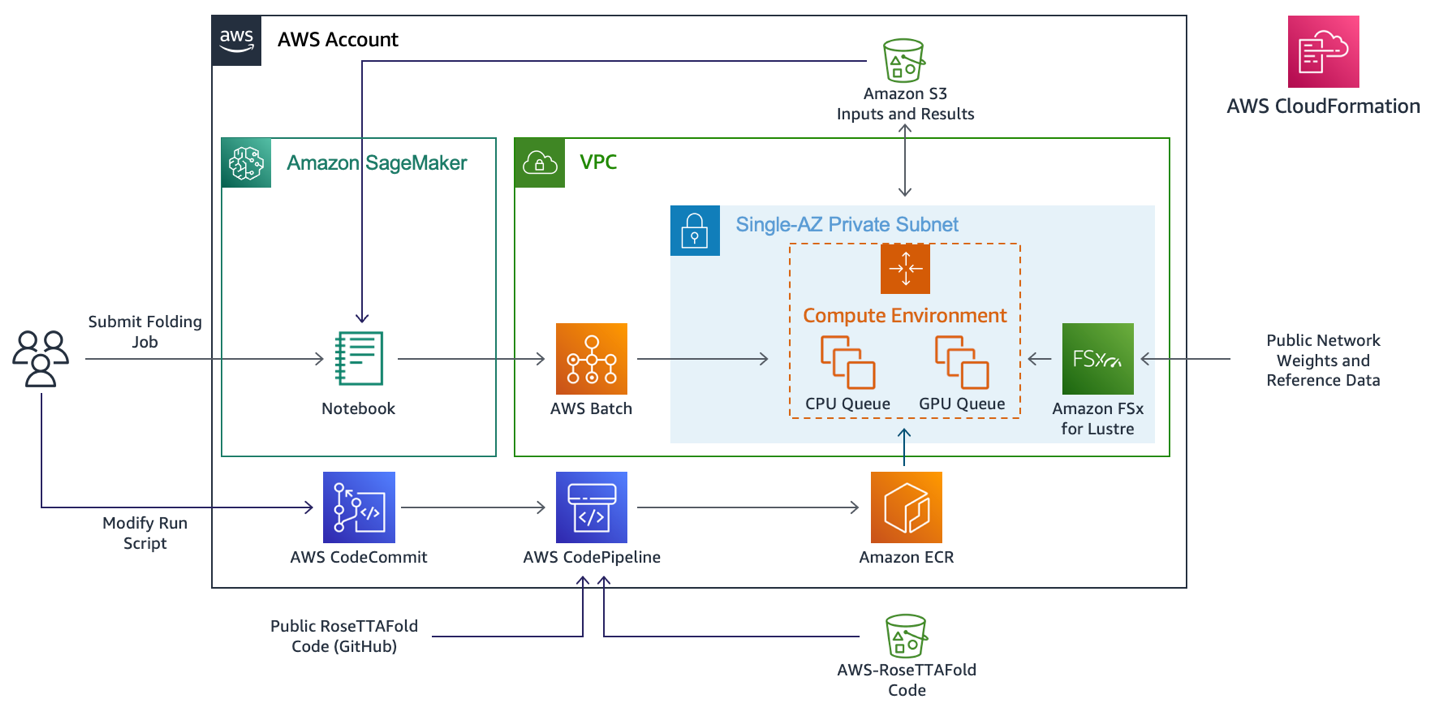
以前のブログ記事では、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを使用して AWS 上で AlphaFold2 ワークロードをインストールし実行する方法について説明しました。これは、長時間稼働し、高度にカスタマイズ可能な環境でタンパク質フォールディングのアルゴリズムを活用したい研究者にとっては素晴らしいソリューションです。しかし、タンパク質構造予測の規模を拡大したいチームは、サービス指向アーキテクチャを好むかもしれません。
このプロジェクトでは、2 つの AWS Batch コンピューティング環境を使用して、エンドツーエンドの RoseTTAFold アルゴリズムを実行します。最初の環境では、ジョブパラメータで指定された vCPU とメモリ要件に基づいて、c4、m4、及び r4 インスタンスを使用します。2 番目の環境では、パフォーマンスや可用性、コストのバランスを考慮して、NVIDIA T4 GPU を搭載した g4dn インスタンスを使用します。
このプロジェクトでは 2 つの Jupyter ノートブックを提供しており、いずれかのノートブックを使用して構造予測ジョブを作成することができます。AWS-RoseTTAFold.ipynb は、単一の解析ジョブを投入し、結果を表示する方法を示したノートブックです。また CASP14-Analysis.ipynb は、CASP14 のターゲットリストを用いて複数のジョブを一度に投入する方法を示したノートブックです。どちらの場合も、解析のためにシーケンスを投入すると、2つの AWS Batch ジョブが作成されます。最初のジョブは、CPU 計算環境を使用してMSA データやその他の特徴量を生成します。2つ目のジョブは、GPU 計算環境を使用して構造予測を行います。
データ作成と構造予測ジョブには、Ubuntu20 上に NVIDIA CUDA 環境をインストールした、同じカスタム Docker イメージが使用されています。公開されている RoseTTAFold リポジトリの v1.1 リリースと、AWS サービスとの連携用スクリプトが追加されています。AWS CodeBuild は、スタック作成時にこのコンテナ定義を自動的にダウンロードし、必要なイメージをビルドします。スタックに含まれる AWS CodeCommit リポジトリにプッシュすることで、このイメージに変更を加えることができます。
チュートリアル
インフラスタックをデプロイする
 をクリックします。
をクリックします。- [スタックの名前] には、アカウントとリージョンに固有の値を入力します。
- [パラメータ] の [ StackAvailabilityZone ] に、デプロイしたい Availability Zone を指定します。
- 「AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。」のチェックを入れます。
- [スタックの作成] ボタンを押してデプロイします。
- AWS CloudFormation がインフラストラクチャスタックを作成し、AWS CodeBuild が AWS-RoseTTAFold コンテナを構築して Amazon Elastic Container Registry (Amazon ECR) に発行します。完了までに約30分要します。
- モデルの重みとシーケンスデータベースのファイルをロードします。ロードの方法には以下の 2 つのオプションがあります。
オプション 1:EC2 インスタンスに Amazon FSx for Lustre ファイルシステムをマウントする
- AWS マネジメントコンソールにサインインし、Amazon EC2 コンソールを開きます。
- ナビゲーションペインで [インスタンス] の下にある [起動テンプレート] を選択します。
- aws-rosettafold-launch-template-stack-id-suffixのような名称の起動テンプレート ID を選択します。
- [アクション] → [テンプレートからインスタンスを起動] を選択します。
- 新しい EC2 インスタンスを起動し、SSH または Systems Manager を使用してインスタンスに接続します。
- RoseTTAFold のパブリックリポジトリのインストール手順 3 と 5 に従って、モデルの重みとシーケンスデータベースのファイルをダウンロードし、
/fsx/aws-rosettafold-ref-dataの添付ボリュームに展開します。
オプション 2:S3 データリポジトリからデータを読み込む
- デプロイしたいリージョンに新しい S3 バケットを作成します。
- モデルの重みとシーケンスデータベースのファイルを、オプション 1 の手順 6 で示した方法でダウンロード及び解凍し、S3 バケットに転送します。
- AWS マネジメントコンソールにサインインし、Amazon FSx for Lustreコンソールを開きます。
- aws-rosettafold-fsx-lustre-stack-id-suffix のような名称のファイルシステム名を選択します。
- ファイルシステムの詳細ページで、[データリポジトリ] → [データリポジトリの関連付けの作成] を選択します。
- ファイルシステムのパスには、
/aws-rosettafold-ref-dataと入力します。 - [データリポジトリのパス] に、作成した S3 バケットの S3 URLを入力します。
- [作成] を選択します。
データリポジトリの関連付けを作成すると、ファイルのメタデータがすぐにファイルシステムに読み込まれます。しかし、データ自体はジョブから要求されるまで利用できません。このため、最初に投入するジョブの所要時間が数時間長くなります。しかし、それ以降のジョブははるかに速く完了します。
モデルの重みとシーケンスデータベースのファイルのロードが完了すると、Amazon FSx for Lustre ファイルシステムには以下のファイルが含まれます。
Jupyterから構造予測ジョブを投入する
- CloudFormation で作成した CodeCommit リポジトリを、SageMaker Studio などの Jupyter Notebook 環境にクローンします。
- 用途に応じて AWS-RoseTTAFold.ipynb あるいは CASP14-Analysis.ipynb のノートブックを開き、タンパク質配列の解析を実行します。
ディスカッション
データストレージの要件
ファイルシステムの性能は、MSA アルゴリズムを並列に実行する際の重要な鍵の 1 つです。そこで、Amazon FSx for Lustre ファイルシステムを使用して必要な配列データベースを保存しています。AWS Batch が新しいコンピュートインスタンスを起動すると、数秒で Amazon FSx ファイルシステムがマウントされます。Amazon FSx は、必要なデータへの高スループットなアクセスを提供します。
上記のリンク先のテンプレートは、1200 MB/s の総スループットを持つファイルシステムを作成し、数十の同時実行ジョブをサポートする点をご認識ください。一度に必要なジョブが 1 つか 2 つである場合、テンプレートを変更してコストを削減することができます。この場合、Amazon FSx for Lustre リソースのストレージ単位あたりのスループットを 1000 から 500 MB/s/TiB に下げることをお勧めします。
予測性能
RoseTTAFold の論文では、400残基以下のタンパク質の立体構造予測を実行するために、RTX2080 GPU で約 10 分かかると報告されています。私たちは、NVIDIA T4 GPU を搭載した Amazon EC2 G4dn インスタンスを使用することで、同等またはそれ以上のパフォーマンスを発揮することを確認しました。

400 残基以上のタンパク質の場合、GPU を搭載していないインスタンスタイプで予測ジョブを実行することをお勧めします。このためには、リンク先のノートブックで predict_job_definition と predict_queue フィールドのパラメータを以下のように変更する必要があります。
変更前 :
変更後 :
他のアルゴリズムへの対応
解析のワークロードを 2 つのジョブに分割しているため、特徴量の生成や構造予測に他のアルゴリズムを容易に取り入れることができます。例えば、run_aws_data_prep_ver.sh スクリプトを更新することによって、hhblits を MMSeqs2 などの他のアライメントのアルゴリズムに置き換えることが可能です。ParallelFold プロジェクトは、AlphaFold2 のワークフローに今回の記事と似たマルチステップのアプローチを適用する方法の良い例です。この場合、特徴量生成と構造予測のステップはそれぞれコンテナ化されており、AWS Batch ジョブとして実行することができます。
クリーンアップ
- AWSマネジメントコンソールにサインインし、CloudFormation コンソールを開きます。
- 関連付けられたスタック名を選択します。
- [削除] を選択します。
まとめ
この投稿では、AWS Batch と Amazon FSx for Lustre を使用して、RoseTTAFold などのタンパク質フォールディングのアルゴリズムのパフォーマンス効率とコストを改善する方法を示しました。
AWS がどのように高スループットなモデリングとスクリーニングを実現しライフサイエンス組織をサポートするかの詳細については、 aws.amazon.com/health/biopharma/solutions/ をご覧ください。
著者について

Brian Loyal
Brian Loyal は、Amazon Web Services の Global Healthcare and Life Sciences チームのシニア AI/ML ソリューションアーキテクトです。バイオテクノロジーと機械学習の分野で 16 年以上の経験を持ち、お客様がゲノムやプロテオミクスの課題を解決するための支援に情熱を注いでいます。休日は友人や家族と一緒に料理や食事を楽しんでいます。

Scott Schreckengaust
Scott は生体医工学の学位を持ち、キャリアをスタートさせた当初から科学者とともにデバイスを発明してきました。科学や技術、工学を愛し、ヘルスケア・ライフサイエンスの領域で、スタートアップから大規模な多国籍企業まで数十年にわたる経験を積んでいます。ロボティックリキッドハンドラーのスクリプト作成、機器のプログラミング、自社開発システムのエンタープライズシステムへの統合、規制環境下でのゼロからのソフトウェア開発などを得意としています。また、顧客の科学ワークフローとその課題を把握し、それを実行可能なソリューションに落とし込むことを楽しんでいます。
翻訳は Solutions Architect の森下が担当しました。原文はこちらです。