Amazon Web Services ブログ
Amazon OpenSearch Service の新エンジンでログ分析コストを大幅に削減
本記事は 2026 年 7 月 1 日 に公開された「Run log analytics for a fraction of the cost with the new engine for Amazon OpenSearch Service」を翻訳したものです。
Amazon OpenSearch Service はリアルタイムの検索・分析エンジンで、AI ワークロードからログ分析まで幅広く使われています。業界全体で見ると、組織が扱うログ量は毎年 30〜40% ずつ増え続けており、オブザーバビリティ基盤のインフラコスト膨張とクエリ速度の低下が避けられない状況です。必要なデータを残すか、予算を守るか。多くのチームがこの二択を迫られています。
今回、Amazon OpenSearch Service にログ分析専用の新エンジンが加わりました。価格性能比は最大 4 倍、データ取り込み速度は 2 倍、分析クエリは最大 2 倍高速、ストレージコストは最大 70% 削減されます。ログ分析に最適化しつつも、OpenSearch の強みである全文検索は同じデータに対してそのまま使えるため、コスト削減と検索能力のトレードオフに悩む必要がなくなります。
この記事では新エンジンの仕組み、使い始める手順、そして数十億ドキュメントを使ったベンチマーク結果を紹介します。
最適化エンジンの仕組み
最適化エンジンは Amazon OpenSearch Service ドメイン内の新しいエンジンモードです。コンソール、API、セキュリティモデル、ネットワーク設定はすべて汎用エンジンと共通なので、運用の仕組みを変える必要はありません。
内部では、すべてのデータが Apache Parquet 形式で保存されます。検索対象として設定したフィールドには転置インデックスも作られるため、カラムナストレージの効率と全文検索の速度を両立しています。クエリが来ると Apache Calcite が解析・最適化を行い、カラムナデータの集計は Apache DataFusion、全文検索は Lucene と、処理に応じて最適なエンジンに振り分けます。この 2 つはクエリの途中で連携するため、ログ本文の検索と集計を 1 回のリクエストで完結できます。
利用者から見ると、取り込みには汎用エンジンと同じ REST API やクライアントライブラリがそのまま使えます。エージェントやパイプラインの変更は不要です。クエリ言語は Piped Processing Language (PPL) と SQL の 2 つに対応しており、どちらもベクトル化エンジンで直接実行されます。なお Domain Specific Language (DSL) のクエリ API はローンチ時点では未対応です。
使い方
ローンチ時点では、最適化エンジンはドメイン作成時に選ぶドメインレベルの設定です。既存ドメインへの追加や、個別インデックス単位での有効化には対応していません。最適化エンジンを使うには新しいドメインを作成し、取り込みパイプラインをそちらに向ける必要があります。
Amazon OpenSearch Service コンソールで新規ドメインを作成し、ユースケースに Observability を選ぶと、最適化エンジンがデフォルトで有効になった状態でドメインが構成されます。コンソール上には両エンジンの機能比較が表示されるので、自分のワークロードにどちらが適しているか判断できます。
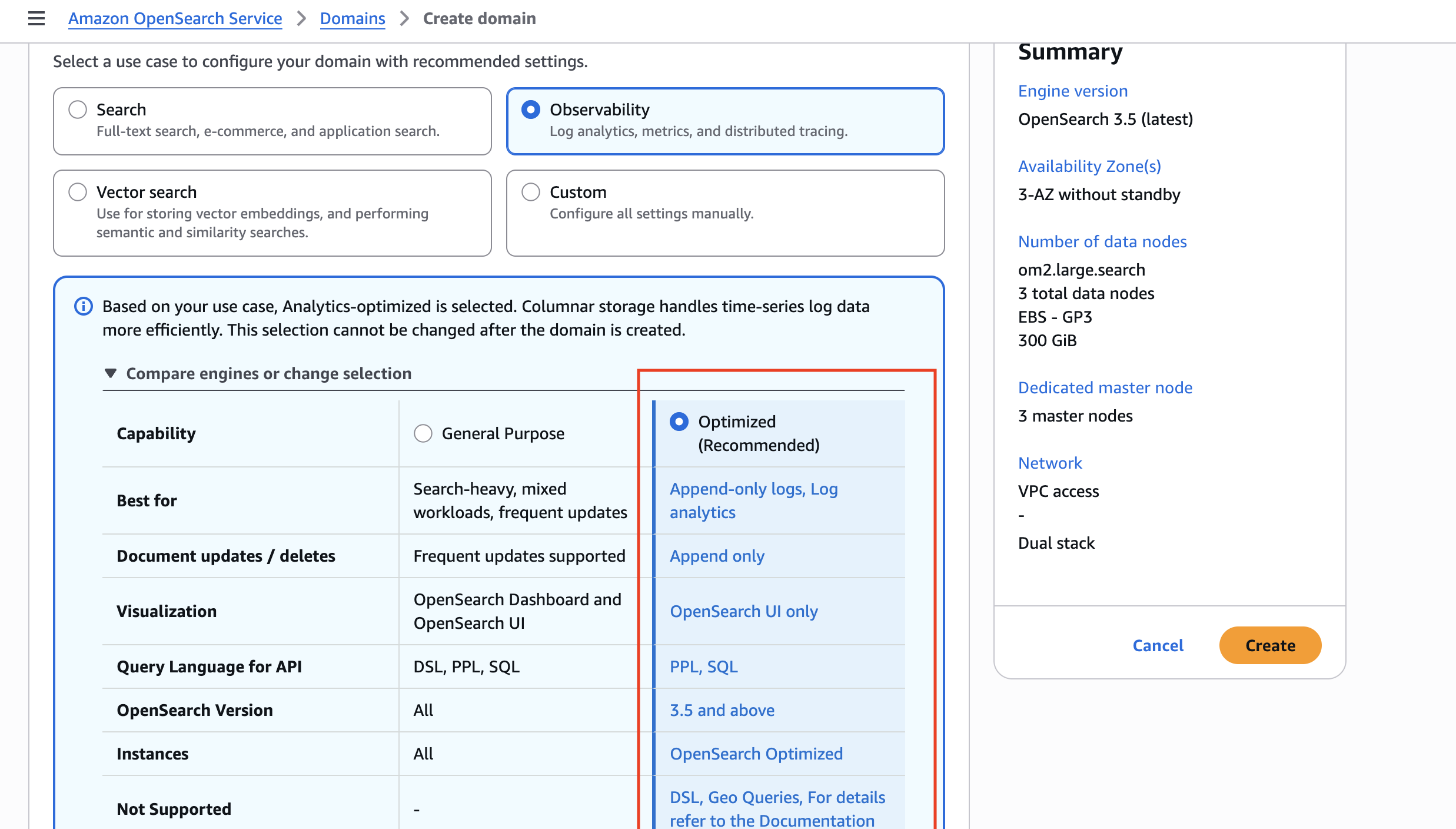
ドメインが準備できたら、汎用エンジンと同じ Bulk API とクライアントライブラリで JSON を投入できます。既存の取り込みパイプラインやアプリケーションコードをそのまま流用できるため、移行時にコード変更は不要です。
ログ分析向け最適化エンジンのメリット
新エンジンで得られる改善をまとめます。
- 最大 4 倍の価格性能比 — 私たちが実施したベンチマークで汎用エンジンと比較した結果です。インシデント調査用の全文検索も引き続き利用できます。
- 最大 2 倍の分析クエリ速度 — データをカラム単位のバッチにまとめて処理するベクトル化実行パスにより、大規模データセットでも高速に結果を返します。
- 最大 2 倍の取り込みスループット — 追記専用のカラムナ書き込みパスで、持続的な取り込みレートが向上します。
- 最大 70% のストレージ削減 — カラムナストレージにより同じコストで最大 3 倍のデータを保持できます。
以下のセクションでは、数十億ドキュメント規模のオブザーバビリティワークロードで実施したベンチマークの方法、環境、結果を説明します。実際のワークロードでの効果はユースケースごとに異なるため、ご自身の環境でもテストされることをおすすめします。
ベンチマークの方法
OpenTelemetry の Telemetry Generator で合成トレースとログを大量に生成し、OTEL トレース、OTEL ログ、Web サーバーアクセスログの 3 種類のデータセットを作りました。生成データは bulk 形式の NDJSON として Amazon Simple Storage Service (Amazon S3) に保存し、AWS Fargate 上の Amazon Elastic Container Service (Amazon ECS) パイプラインで取り込みました。パイプラインは S3 からチャンクを読み、タイムスタンプを変換して OpenSearch の Bulk API に書き込む構成で、本番のオブザーバビリティフローを再現しています。
テスト環境は OpenSearch 3.5 を動かす 2 つの OpenSearch Service ドメインで、それぞれ 3 アベイラビリティゾーン構成、データノード 9 台です。
| 構成 | 最適化エンジン | Standard Lucene |
| インスタンスタイプ | 9x or2.4xlarge.search | 9x r8g.4xlarge.search |
| リーダーノード | 3x m7g.large.search | 3x m7g.large.search |
| EBS | 2,500 GB gp3、7,500 IOPS、500 MB/s (ノードあたり) | 2,500 GB gp3、7,500 IOPS、500 MB/s (ノードあたり) |
| エンジンモード | OPTIMIZED | General Purpose (best_compression) |
3 データセット合計で 244 億ドキュメント、9.5 TB の生 JSON を取り込みました。インデックスは 9 プライマリシャード、1 レプリカで、ISM ロールオーバーはプライマリシャードあたり 50 GB に設定しました。Lucene 側は best_compression (zstd) コーデック + _source 有効で、一般的な本番構成を再現しています。
取り込みパイプラインは同一 VPC 内の Fargate タスク 90 個 (各 16 vCPU、120 GB RAM、48 ライタースレッド、バルクサイズ 3,000 ドキュメント) で実行しました。
結果
取り込みスループット
最適化エンジンは追記専用のカラムナストレージを採用しており、ドキュメントごとに stored field を書く必要がありません。複数ドキュメントをまとめてカラムナセグメントとして一括書き込みするため、高いスループットを実現しています。
| メトリクス | 最適化エンジン | Lucene ベースライン |
| ピークスループット | 178 万 docs/sec | 約 64.7 万 docs/sec |
| ピーク時クラスタ CPU | 62% | 72% |
| Write rejection | 0 | 0 |
| 取り込みドキュメント総数 | 244 億 | 157 億 |
同じ並列度で毎秒 178 万ドキュメントを維持し、Lucene の約 2 倍のスループットを CPU 負荷を抑えながら達成しました。write rejection は両ドメインともゼロでした。1 日に数テラバイトを取り込むチームなら、同じ量をより少ないノードで捌けるか、同じインフラでより長い保持期間を取れることになります。
ストレージ圧縮
Parquet のカラムナ形式では、同じフィールドの値がまとめて格納されるため、辞書エンコーディングや型に特化した圧縮が高い効率で効きます。加えて、行単位で生 JSON を保持する必要がないため、オブザーバビリティデータのストレージを大幅に削減できます。
244 億ドキュメントでの実測値:
| データセット | ドキュメント数 | ソース | 最適化エンジン | Lucene (デフォルト) | 圧縮率 vs. ソース | Lucene 比削減率 |
| Web ログ | 87.6 億 | 2,360 GB | 254 GB | 614 GB | 89% | 59% |
| OTEL ログ | 82.0 億 | 3,720 GB | 815 GB | 1,549 GB | 78% | 47% |
| OTEL トレース | 74.3 億 | 4,131 GB | 841 GB | 1,790 GB | 80% | 53% |
| 合計 | 244 億 | 9,539 GB | 1,910 GB | 3,953 GB | 80% | 52% |
結果として、生 JSON に対して 5 倍の圧縮 (80% 削減) を達成しています。デフォルトの Lucene 構成 (_source 有効) と比べてもストレージはおよそ半分です。最適化エンジンは _source をクエリ時に Parquet カラムから再構成するため、ドキュメントの取得機能を維持しつつ生 JSON を別途保存する必要がなくなっています。
分析クエリ性能
オブザーバビリティダッシュボードの典型的なパターンとして、数十億のログイベントに対し 15 分間のタイムウィンドウで絞った分析集計のレイテンシーを計測しました。最適化エンジンは @timestamp カラムの row-group プルーニングでクエリ対象外のデータをスキップし、必要な部分だけを読みます。
| クエリパターン | データセット | 最適化エンジン | Lucene ベースライン | 高速化倍率 |
| サービス別エラー数 | OTEL ログ | 717 ms | 2.8 s | 3.9x |
| ホスト別ログ量 | OTEL ログ | 252 ms | 17.6 s | 70x |
| サービス・メソッド別 5xx エラー | OTEL ログ | 171 ms | 885 ms | 5.2x |
| エラー上位サービス | OTEL トレース | 635 ms | 569 ms | 約 1x |
| ポイントルックアップ (単一 traceId) | OTEL トレース | 394 ms | 783 ms | 2x |
すべてのクエリは 15 分ウィンドウでスコープ。インデックスサイズ: OTEL ログ 82 億イベント、OTEL トレース 74 億スパン。
最適化エンジンは、数十億ドキュメントに対する時間フィルター付き分析クエリを 171 ms〜717 ms で完了しました。特にフィルターなしの集計 (ホスト別ログ量: 70 倍高速) で差が顕著に現れており、必要なカラムだけを読むカラムナエンジンの特性が効いています。一方、Lucene の転置インデックスが高い選択性を発揮するクエリ (トレースのエラー上位サービス) では両者の性能は同程度でした。
検索とポイントルックアップ
分析だけでなく検索も高速です。最適化エンジンはカラムナストレージと Lucene 転置インデックスの両方を持っており、クエリプランナーが選択的なルックアップ (特定の traceId の検索など) を検出すると、カラムナスキャンではなく転置インデックスにルーティングします。74 億スパンに対する単一 traceId ルックアップは 165 ms で完了しました。
実際の障害調査では、まず集計で問題を絞り込み、次にポイントルックアップで該当トレースを引く、という流れが 1 つのドメインで完結します。
提供開始
Amazon OpenSearch Service のログ分析向け最適化エンジンは、OpenSearch Optimized Instances が利用できるすべての商用 AWS リージョン (AWS GovCloud (US) および中国リージョンを除く) で一般提供されています。
料金はインスタンスとストレージの標準 Amazon OpenSearch Service 料金に準じ、最適化エンジンの追加費用はかかりません。詳細は Amazon OpenSearch Service の料金を参照してください。
設定と使い方の詳細は Optimized for Log Analytics (Amazon OpenSearch Service ドキュメント)、サービス概要は Amazon OpenSearch Service Log Analytics を参照してください。
フィードバックは AWS re:Post for Amazon OpenSearch Service または AWS サポートまでお寄せください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。