Amazon Web Services ブログ
AWS Parallel Computing Service (PCS)を利用したスケーラブルなクライオ電子顕微鏡データ解析環境

クライオ電子顕微鏡(Cryo-EM)は、創薬研究者が創薬に不可欠な生体分子の三次元構造を決定することを可能にします。Cryo-EMの導入が進むにつれ、科学者やITシステム管理者は、これらの顕微鏡によって毎日生成される数テラバイトのデータを効率的に処理する方法を模索してきました。これらの処理パイプラインには、スケーラブルで多様なワークロードに対応できるコンピューティング環境と、高速かつコスト効率に優れたストレージが必要です。
AWS Parallel Computing Service (PCS)は、クラウドでハイパフォーマンスコンピューティング(HPC)クラスタを展開・管理するためのマネージドサービスです。Cryo-EMにPCSを使用することで、構造生物学者にとって一貫したユーザー体験を維持しながら、HPCインフラの構築と管理に伴う差別化につながらない重労働を軽減し、研究に迅速に取り掛かることができます。
この投稿では、PCS上でCryo-EMに使用できる推奨リファレンスアーキテクチャを紹介し、一般的なアプリケーションである CryoSPARC を使用した具体例を示します。また、可視化ツールとして ChimeraX について紹介し、一般的にクラウドでCryo-EMを実行するためのベストプラクティスについても解説します。
アーキテクチャの概要
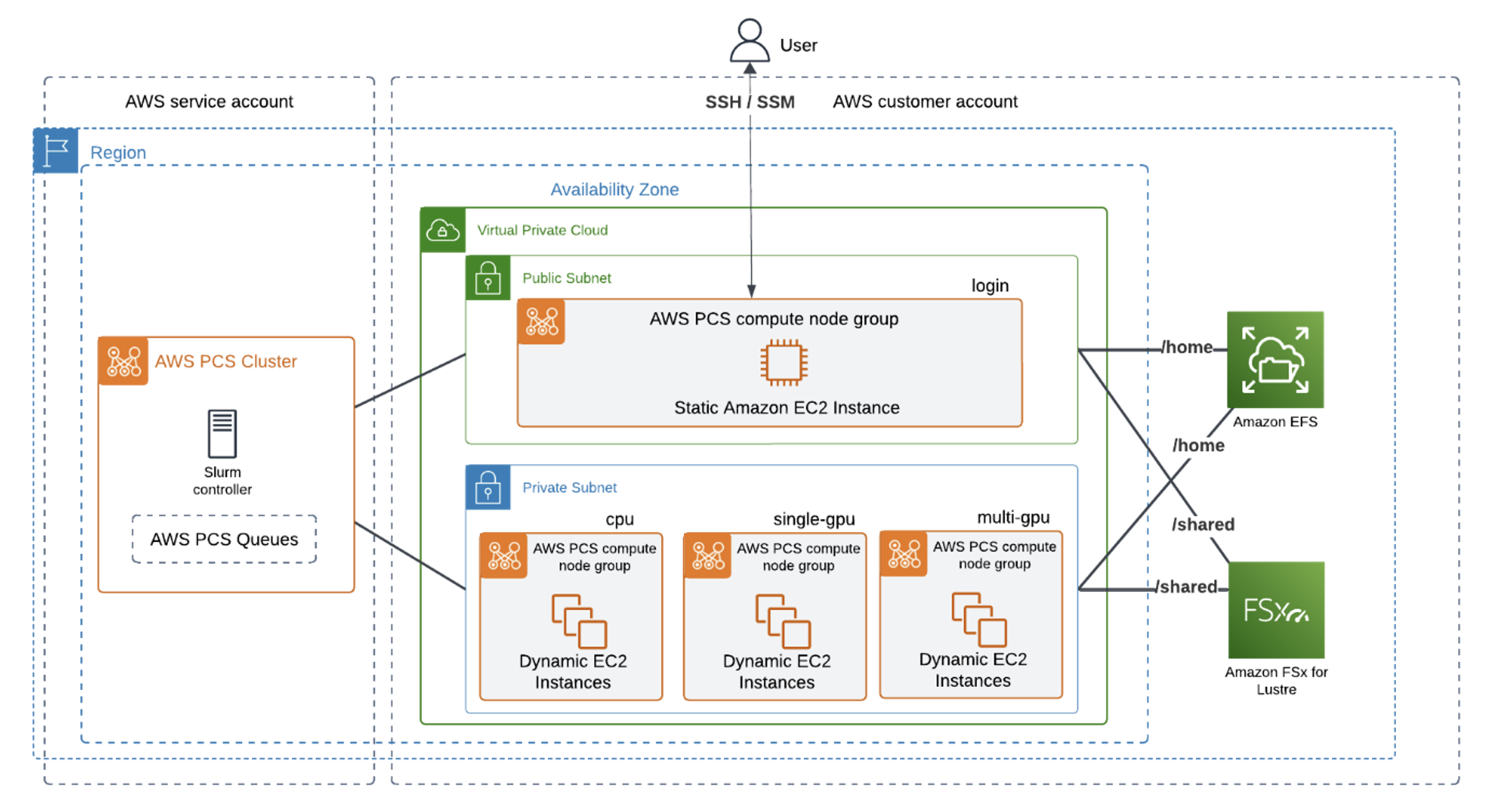
図1 – AWS上のCryoSPARCのアーキテクチャ概要。SlurmコントローラはAWSサービスアカウントに配置され、コンピュートとストレージリソースはユーザーAWSアカウントに配置されます。クラスタにはFSx for LustreとAmazon Elastic File Store (EFS)がマウントされています。
セットアップと前提条件
PCSドキュメントに記載されている前提条件に加え、CryoSPARCのライセンスが必要です。ライセンスなしでこのガイドに従ってPCSクラスタを作成することは可能ですが、最終的にはソフトウェアをインストールしてテストジョブを実行するためにライセンスが必要になります。ライセンスを取得するには、Structura Biotechnology にお問い合わせください。
共有ストレージを使用したクラスタの作成
HPC Recipes Library は AWS のエンジニアリングチームとアーキテクチャチームが作成したテンプレートを共有するGitHubの公開リポジトリです。これにより、面倒な構築手順なしにHPCインフラをクラウド上に展開できます。この例に適した共有ストレージを備えたPCSクラスタを作成するには、AWS CloudFormationを使用してクラスタ全体を迅速に起動する PCS guidance for a one-click deployment を利用できます。
CloudFormationが起動するとパラメータ指定の画面が表示されます。ここにクラスターのログインノードにアクセスするためのSSHキーをプルダウンで指定するオプションが表示されます。その他のフィールドはすべてそのままにしておき、Create を選択してください。これにより、必要なネットワークの前提条件、ログインノードグループを含むクラスター、単一のデモ用コンピューティングノードグループ、/home用のEFSファイルシステム、および/shared用のLustreファイルシステムが作成されます。。
準備が整うとCloudFormation console に以下のスタックが表示されるはずです。図2はCloudFormationのスクリーンショットで、各スタックにデプロイされた内容の簡単な説明が含まれています。

図2: hpcレシピテンプレートによって作成されたCloudFormationスタック
また、PCSクラスタを手動で作成する場合や、アカウント内の既存のリソースを使用する場合は PCS User Guide の手順に従ってこれらのリソースを設定するだけです。
LustreファイルシステムのスループットのためのFSxの調整
CloudFormation console でView Nested のラジオスライダーをクリックして、デプロイしたテンプレートから作成されたさまざまなスタックを確認します。get-started-cfn-FSxLStorage で始まるスタックを見つけてクリックします。コンソールの右側にスタック情報が表示されたら、Outputs タブをクリックし、後ほど使用する FSxLustreFilesystemId の値をメモします。
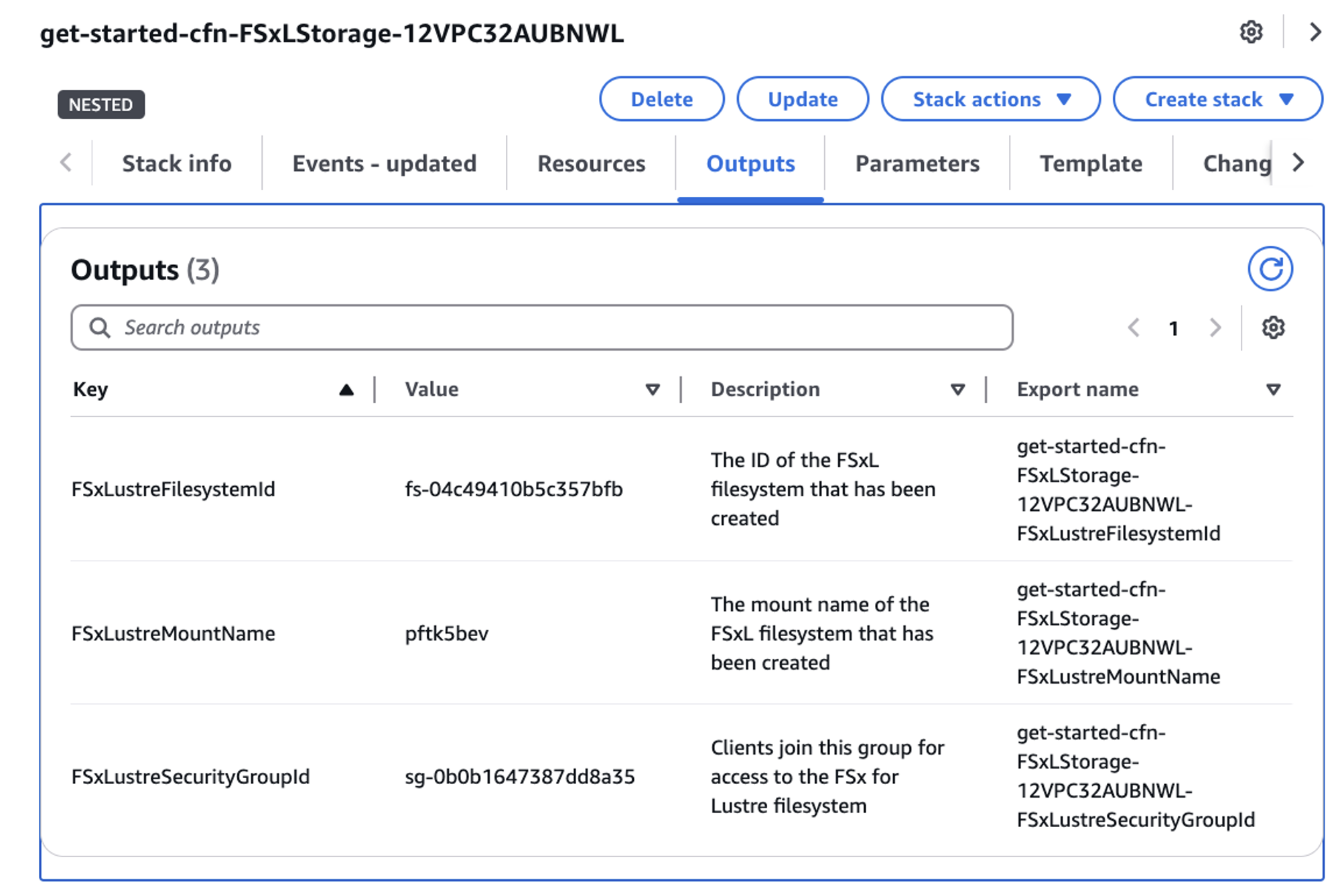
図 3: hpc レシピテンプレートによって作成された FSx for Lustre CloudFormation スタック
CryoSPARC のインストールを成功させるには、FSx for Lustre システムのストレージ単位あたりのスループットを 250 MB/s/TiB に更新する必要があります。この処理には最大 20 分かかる場合がありますので、残りのクラスター設定を進める間、ファイルシステムの更新がバックグラウンドで完了する時間を確保するため、今すぐコマンドを実行しましょう。
aws fsx update-file-system \
--file-system-id $FSX-LUSTRE-ID \
--lustre-configuration PerUnitStorageThroughput=250
追加のノードグループとキューの作成
最初のクラスタ作成が完了したら、いくつかのコンピュートノードグループとキューを作成します。AWS PCSのコンピュートノードグループは、Amazon Elastic Compute Cloud (Amazon EC2)のノード(インスタンスと呼称されます)の論理的な集合体です。これらは、あなたがジョブを実行する一時的なマシンとなります。AWS PCSキューは、スケジューラのネイティブ実装であるワークキューを軽量に抽象化したものです。ジョブはキューに投入され、キューは1つ以上のコンピュートノードグループにマッピングされます。CryoSPARCでは、レーンはPCSキューに相当します。
compute-cpu(c5a.8xlargeインスタンス)、compute-single-gpu(g6.4xlarge)、compute-multi-gpu(g6.48xlarge)の3つの新しい計算ノードグループを作成し、これらの計算ノードグループをそれぞれのキューにマッピングします。これらのインスタンスタイプは、私たちの内部テストに基づいて選定されました。処理パイプライン内の個々のタスクのスケーラビリティに関する詳細な説明は CryoSPARC performance benchmarks にて選定理由が説明されています。
これらのノードグループはPCSコンソールから作成できますが、ここではAWS CLIで作成する方法を紹介します。このコマンドを実行して、compute-1 の PCS Compute Node GroupのAMI ID、Instance Profile、Launch Template IDを取得し、出力を保存します。次の一連のコマンドでこれを使用して、追加のコンピュートノードグループを作成します:
aws pcs get-compute-node-group \
--cluster-identifier $PCS_CLUSTER_NAME \
--compute-node-group-identifier compute-1
以下のコマンドを実行し、各コマンドの出力から計算ノードグループ名とIDを保存します。これを使用して、これらのノードグループをキューにマッピングします:
aws pcs create-compute-node-group \
--compute-node-group-name compute-cpu \
--cluster-identifier $PCS_CLUSTER_NAME \
--region $REGION \
--subnet-ids $PRIVATE_SUBNET_ID \
--custom-launch-template id=$COMPUTE_LT_ID,version='1' \
--ami-id $AMI_ID \
--iam-instance-profile $INSTANCE_PROFILE_ARN \
--scaling-config minInstanceCount=0,maxInstanceCount=2 \
--instance-configs instanceType=c5a.8xlarge
aws pcs create-compute-node-group \
--compute-node-group-name compute-single-gpu \
--cluster-identifier $PCS_CLUSTER_NAME \
--region $REGION \
--subnet-ids $PRIVATE_SUBNET_ID \
--custom-launch-template id=$COMPUTE_LT_ID,version='1' \
--ami-id $AMI_ID \
--iam-instance-profile $INSTANCE_PROFILE_ARN \
--scaling-config minInstanceCount=0,maxInstanceCount=2 \
--instance-configs instanceType=g6.4xlarge
aws pcs create-compute-node-group \
--compute-node-group-name compute-multi-gpu \
--cluster-identifier $PCS_CLUSTER_NAME \
--region $REGION \
--subnet-ids $PRIVATE_SUBNET_ID \
--custom-launch-template id=$COMPUTE_LT_ID,version='1' \
--ami-id $AMI_ID \
--iam-instance-profile $INSTANCE_PROFILE_ARN \
--scaling-config minInstanceCount=0,maxInstanceCount=2 \
--instance-configs instanceType=g6.48xlarge
以下のコマンドを実行して、ノードグループの作成状況を確認します:
aws pcs get-compute-node-group --region $region \
--cluster-identifier $cluster-name \
--compute-node-group-identifier $node-group-name
3つのノードグループそれぞれのステータスが ACTIVE になったら、キューの作成に進むことができます。各キューは1つ以上のノードグループにマッピングされ、これらのノードグループはキューに到着したジョブを処理するための一時的なインスタンスを供給する役割を担います。このクラスタでは、各キューを単一のノードグループにマッピングします。
$NODE_GROUP_ID はノードグループ名と同じではないことに注意してください。
aws pcs create-queue \
--queue-name cpu-queue \
--cluster-identifier $PCS_CLUSTER_NAME \
--compute-node-group-configurations
computeNodeGroupId=$COMPUTE_CPU_NODE_GROUP_ID
aws pcs create-queue \
--queue-name single-gpu-queue \
--cluster-identifier $PCS_CLUSTER_NAME \
--compute-node-group-configurations computeNodeGroupId=$COMPUTE_SINGLE_GPU_NODE_GROUP_ID
aws pcs create-queue \
--queue-name multi-gpu-queue \
--cluster-identifier $PCS_CLUSTER_NAME \
--compute-node-group-configurations computeNodeGroupId=$COMPUTE_MULTI_GPU_NODE_GROUP_ID
次に、キューが正常に作成されたことを確認します:
aws pcs get-queue --region $REGION \
--cluster-identifier $PCS_CLUSTER_NAME \
--queue-identifier $PCS_QUEUE_NAME
ステータスが ACTIVE を返したら、キューの作成は完了です。クラスタログインノードにログインして、CryoSPARCをインストールします。
Amazon EC2のコンソールを開き Instancesに移動します。 検索バーで aws:pcs:compute-node-group-id = <LOGIN_COMPUTE_NODE_GROUP_ID> を検索し、<LOGIN_COMPUTE_NODE_GROUP_ID> をログインノードグループのIDに置き換えてエンターキーを押します。このインスタンスを選択し、Connectを選択します。次のページで、Session Managerを選択し、Connectを選択します。ブラウザのタブでターミナルセッションが開きます(これはSession Managerの優れた機能です)。ターミナルで、ユーザをec2-userに変更します。ec2-userは、ジョブの投入と管理を行うSlurmの権限を持つクラスタ内のユーザです。
sudo su - ec2-userクラスタのログインノードに接続したら、次のコマンドを実行して追加のSlurmパーティションを確認します:
sinfo以下のように表示されます:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
demo up infinite 4 idle~ compute-1-[1-4]
single-GPU up infinite 4 idle~ single-GPU-[1-4]
CPU up infinite 4 idle~ CPU-[1-4]
multi-GPU up infinite 4 idle~ multi-GPU-[1-4]クラスタにログインできたので、CryoSPARCをインストールしてテストデータセットをダウンロードします。
CryoSPARCのインストールとテストデータセットのダウンロード
CryoSPARCのインストールとセットアップを簡単にするために、共有ファイルシステムにアプリケーションをインストールし、クラスタのキュー名に基づいてレーンを登録するシェルスクリプトを用意しました。これにアクセスするには、キーペアを生成してログインノードにSSH接続します。ログインノードに接続したら、スクリプトをダウンロードして実行可能ファイルにしてください:
wget https://raw.githubusercontent.com/aws-samples/cryoem-on-aws-parallel-cluster/refs/heads/main/source/pcs-cryosparc-post-install.shスクリプトを実行し、インストール用の共有ファイルシステムを指定します。$LICENSE_IDをCryoSPARCのライセンスに置き換えてください。最大1時間かかります。
chmod +x pcs-cryosparc-post-install.sh
sudo ./pcs-cryosparc-post-install.sh $LICENSE_ID /shared/cryosparc /shared/cuda 11.8.0 11.8.0_520.61.05 /shared
インストールが完了したら、CryoSPARCサーバーを起動します:
/shared/cryosparc/cryosparc_master/bin/cryosparcm startログインノードを再起動した場合、CryoSPARCサーバーのstartコマンドを再度実行する必要があります。このコマンドを起動テンプレートのEC2ユーザーデータセクションに追加することで、このプロセスを自動化できます。Amazon EC2ユーザーデータの操作については PCS User Guideを参照してください。
サーバーが正常に起動し、 CryoSPARC master started という確認メッセージが表示されたら、新しいユーザーを作成します:
cryosparcm createuser \
--email "<youremail@email.com>" \
--password "<yourpassword>" \
--username "<yourusername>" \
--firstname "yourname>" \
--lastname "<yourlastname>"
完了したら、ログインノードからログアウトしてください。
CryoSparc UIへのアクセス
次に、先に生成したEC2キーペアを使用してSSHトンネルをCryoSPARCのログインノードに設定します:
ssh -i /path/to/key/key-name -N -f -L \ localhost:45000:localhost:45000 ec2-user@publicIPofyourinstanceこれを実行した後、ウェブブラウザで http://localhost:45000 にアクセスすると、CryoSPARC のログイン画面が表示されます。
図4: ウェブブラウザのログイン画面から、新しく作成したユーザー認証情報を使ってCryoSPARCにアクセスします。
テストジョブの実行
sharedディレクトリにテストデータ用のデータフォルダを作成し、以下のコマンドでテストデータセットをダウンロードします:
mkdir /shared/data
cd /shared/data
/shared/cryosparc/cryosparc_master/bin/cryosparcm downloadtest
tar -xf empiar_10025_subset.tar
このステップの完了には数分かかります。
このテストでは、データセットをLustreファイルシステムに直接ダウンロードしています。本番環境では、Amazon Simple Storage Service (Amazon S3)にデータセットを保存し、Amazon S3とAmazon Fsx for Lustreファイルシステム間で Data Repository Association (DRA) を使用することをお勧めします。1つのCryo-EMサンプルのサイズは数十テラバイトになることがあり、組織は定期的にペタバイトの顕微鏡データを保存しているため、このようにAmazon S3とFSx for Lustreを使用すると、コストを大幅に削減できます。DRA をセットアップするには FSx for Lustre documentationを参照してください。
テストデータセットのダウンロードが完了したら Get Started with CryoSPARC Tutorial の手順に従って、Import Movies ジョブを実行します。ジョブのキューを選択すると、Slurmクラスタのキューが表示されます。Import Moviesジョブのcompute-cpuレーンを選択します:
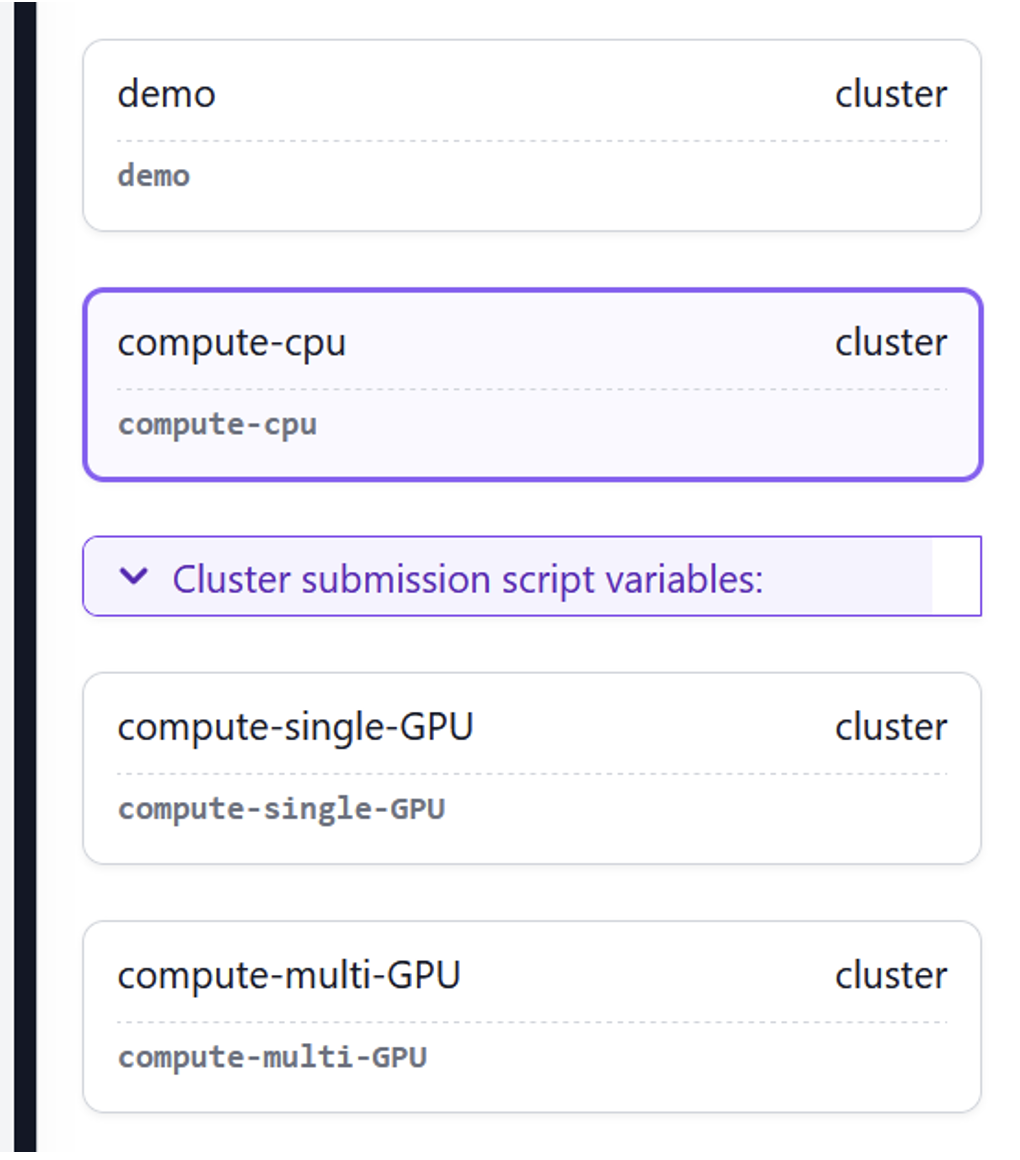
図5:CryoSPARCは、PCSキューと同じ名前でレーンを構成しています。ムービーのインポートジョブにcompute-cpuを選択します
ジョブを実行します。CryoSPARC UIのEvent Logの下に、このようなSlurmサブミッションが表示されるはずです:
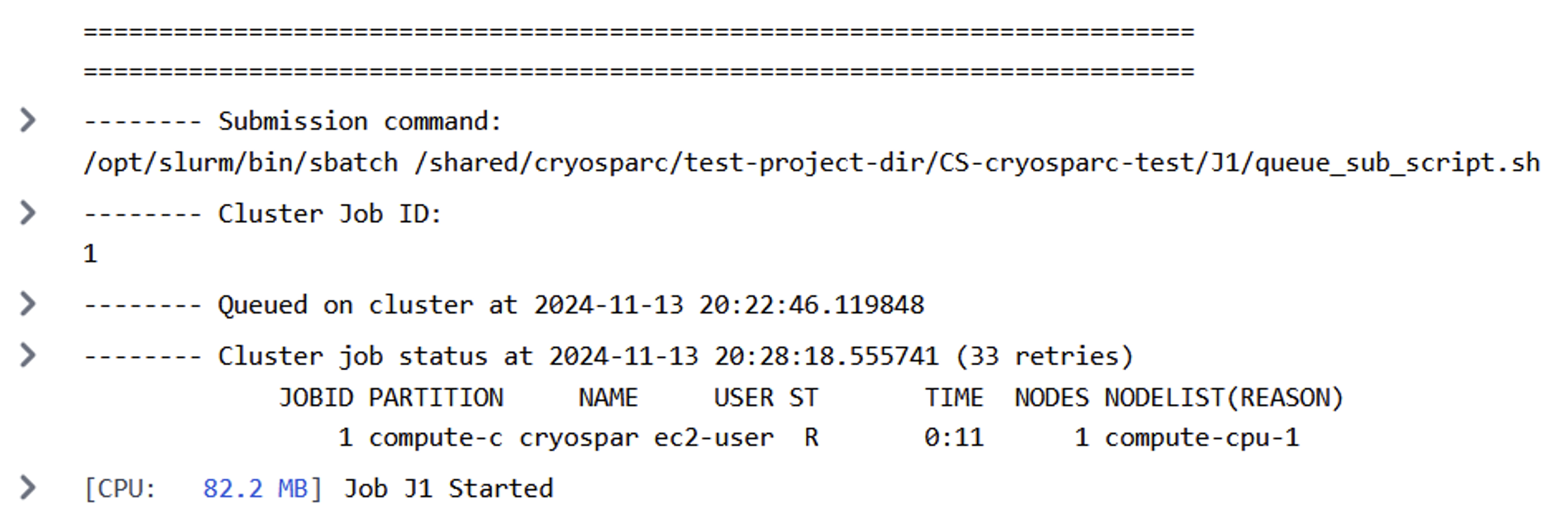
図6: 成功したCryoSPARCジョブ投入
ターミナルに戻ってログインノードからsqueueコマンドを実行すると、クラスタ上で実行されているジョブを確認できます:
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 compute-c cryospar ec2-user CF 1:02 1 compute-cpu-1
sinfo を実行して、ジョブ用に割り当てられているノードを確認します:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
demo up infinite 4 idle~ compute-1-[1-4]
compute-cpu up infinite 1 mix# compute-cpu-1
compute-cpu up infinite 3 idle~ compute-cpu-[2-4]
compute-single-GPU up infinite 4 idle~ compute-single-gpu-[1-4]
compute-multi-GPU up infinite 4 idle~ compute-multi-gpu-[1-4]
このノードは、EC2によってAWSアカウントにプロビジョニングされたシングルインスタンスです。EC2コンソールで確認できます。ジョブは数分で正常に完了するはずです。これ以上ジョブをキューに投入しなければ、最後のジョブが完了した数分後にそのインスタンスが動的に終了するのがわかります。
可視化と次のステップ
可視化パッケージのような追加アプリケーションをクラスタ共有ストレージにインストールすることができます。
ChimeraXは構造生物学者によく使われている可視化アプリケーションです。この記事では取り上げませんが、ログインノードにAmazon DCVを設定することで、クラスタ上でこれを実行することができます。DCVは、デスクトップとクラウド間で低レイテンシー、高解像度のリモート可視化を提供し、手元の環境とクラウド間の時間とコストのかかるデータ移動を不要にします。
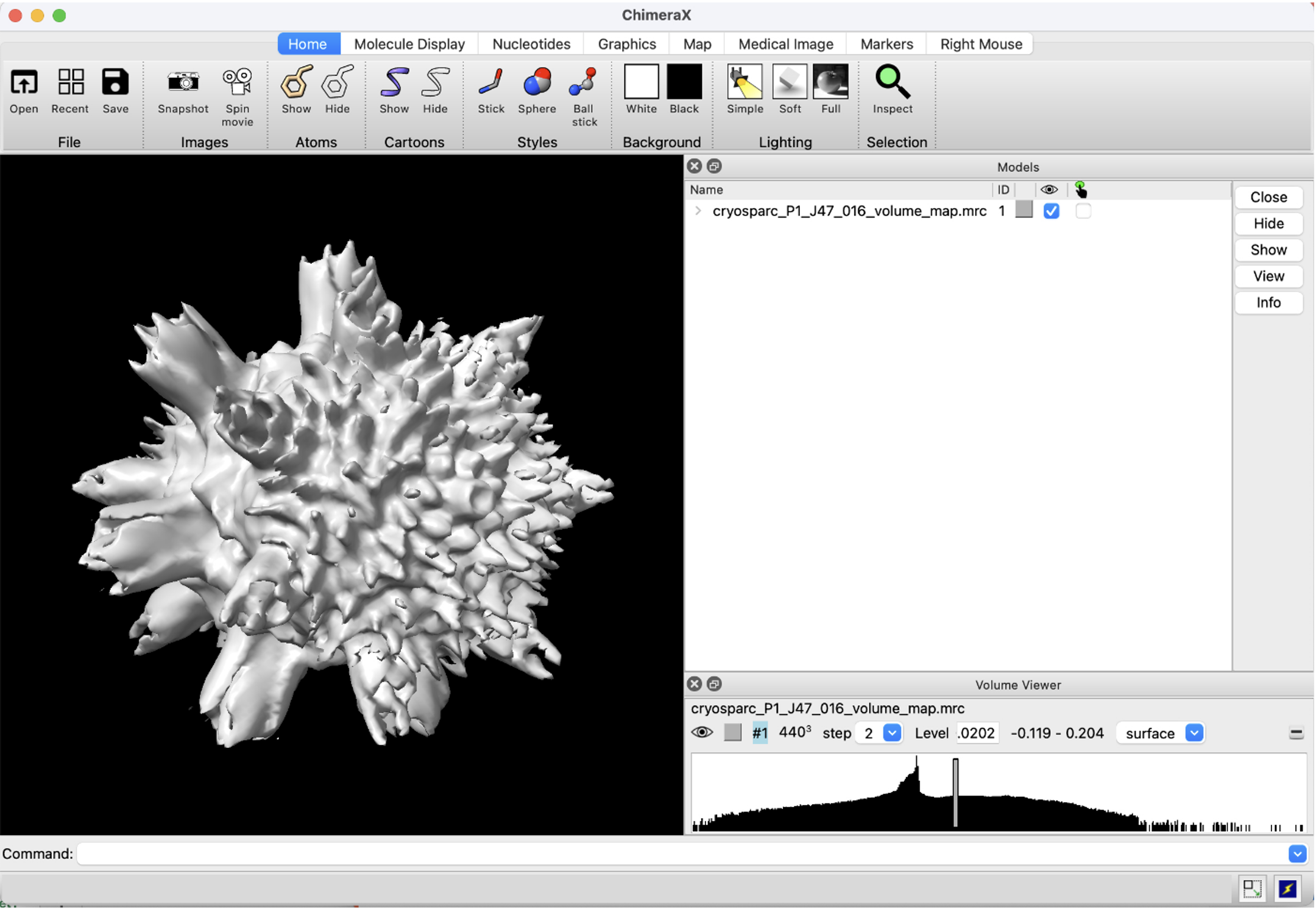
図7: CryoSPARCで実行し、ChimeraXで可視化したEMPIAR 10288サンプルの結果のスクリーンショット。
環境の削除
AWS CLIを使用して、まず以下のコマンドを使用してcpu-queue、single-gpu-queue、multi-gpu-queueを削除することで、この投稿で構築した環境を削除できます:
aws pcs delete-queue --cluster-identifier <pcs_cluster_name> --queue-identifier <pcs_queue_name>次に、以下のコマンドで compute-cpu, compute-single-gpu と compute-multi-gpu の各コンピュートノードグループを削除します:
aws pcs delete-queue --cluster-identifier <pcs_cluster_name> --compute-node-group-identifier <pcs_compute_node_group_name>最後に、次のコマンドを使用してCloudFormationテンプレートを削除することで、PCSクラスタとそれで作成されたすべてのリソースを削除します:
aws cloudformation delete-stack --stack-name <pcs_cloudformation_stack name>結論
AWS Parallel Computing Service は、 Cryo EM をクラウドで実行するためのパワフルでスケーラブルなソリューションを提供し、研究者が新しい科学的発見を解き放つことを可能にします。
AWS上のスケーラブルでオンデマンドなコンピューティングにより、科学者のアイデアや意欲の成長に合わせて要求に応えることができます。多様なワークロードに対応できるコンピューティングでAWS PCSを構成し、利用可能になった最新のインスタンスタイプで状態を保つことができます。Amazon DCVを使用してPCSに統合された高解像度、低レイテンシーの可視化により、科学者はデスクトップから直接、完全なCryo-EMワークフローを実行できます。
お客様がクライオ電子顕微鏡(Cryo-EM)のデータ解析環境にAWSを選択するメリットは、研究者にとってスケーラビリティ、柔軟性、最終的な効率性をもたらすことができることです。
本ガイドでは、PCS上でCryo-EMジョブを実行する方法の一例を紹介します。構造生物学者は、1つのサンプルを処理する際に複数のアプリケーションを使用し、組織内の研究グループ間でデータセットを共有することがよくあります。AWS Professional ServicesとClovertexのようなAmazon Partner Network (APN)のメンバーは、組織のニーズに合わせてこの初期システムのスケールアウトを支援することができます。詳細については、AWSアカウントチームにお問い合わせいただくか ask-hpc@amazon.com までご連絡ください。