Amazon Web Services ブログ
Amazon EC2 Trn1 UltraClusters を使って大規模言語モデル(LLM)学習をスケールする
こちらは、AWS blog の Scaling Large Language Model (LLM) training with Amazon EC2 Trn1 UltraClusters を翻訳したものです。
最近のモデルの事前学習において、時間とコストを削減するために、大規模なクラスターが必要になることがよくあります。サーバーレベルでは、このようなモデル学習ワークロードには、より高速なコンピューティングとより多くのメモリが必要です。モデルが数千億のパラメーター規模になると、複数のノード (インスタンス) にまたがる分散学習のメカニズムが必要になります。
2022 年 10 月に、AWS が設計した第 2 世代の機械学習アクセラレータである AWS Trainium を搭載した Amazon EC2 Trn1 インスタンス がローンチしました。Trn1 インスタンスは、ハイパフォーマンスなディープラーニングモデルの学習のために設計されており、同等の GPU ベースのインスタンスと比べてモデルの学習にかかるコストを最大 50% 節約できます。EC2 Trn1 UltraCluster を使用して大規模モデルの学習ジョブを分散することで、学習時間を数週間から数日に、または数日から数時間に短縮することができます。このクラスターは、密結合された Trn1 コンピュートインスタンスのラックで構成され、すべてがペタバイト規模のノンブロッキングネットワークで相互接続されています。これまでで最大の UltraCluster であり、最大30,000個の Trainium チップで 6 エクサフロップスの計算能力をオンデマンドで提供します。
この投稿では、簡単な例として、Hugging Face BERT-Large モデルの事前学習ワークロードを使用して、Trn1 UltraClusters の使い方を説明します。
Trn1 UltraClusters
Trn1 UltraCluster は、データセンター内の Trn1 インスタンスのプレイスメントグループです。1 回のクラスター実行の一部として、Trainium アクセラレータを搭載した Trn1 インスタンスのクラスターを起動できます。次の図はその例を示しています。
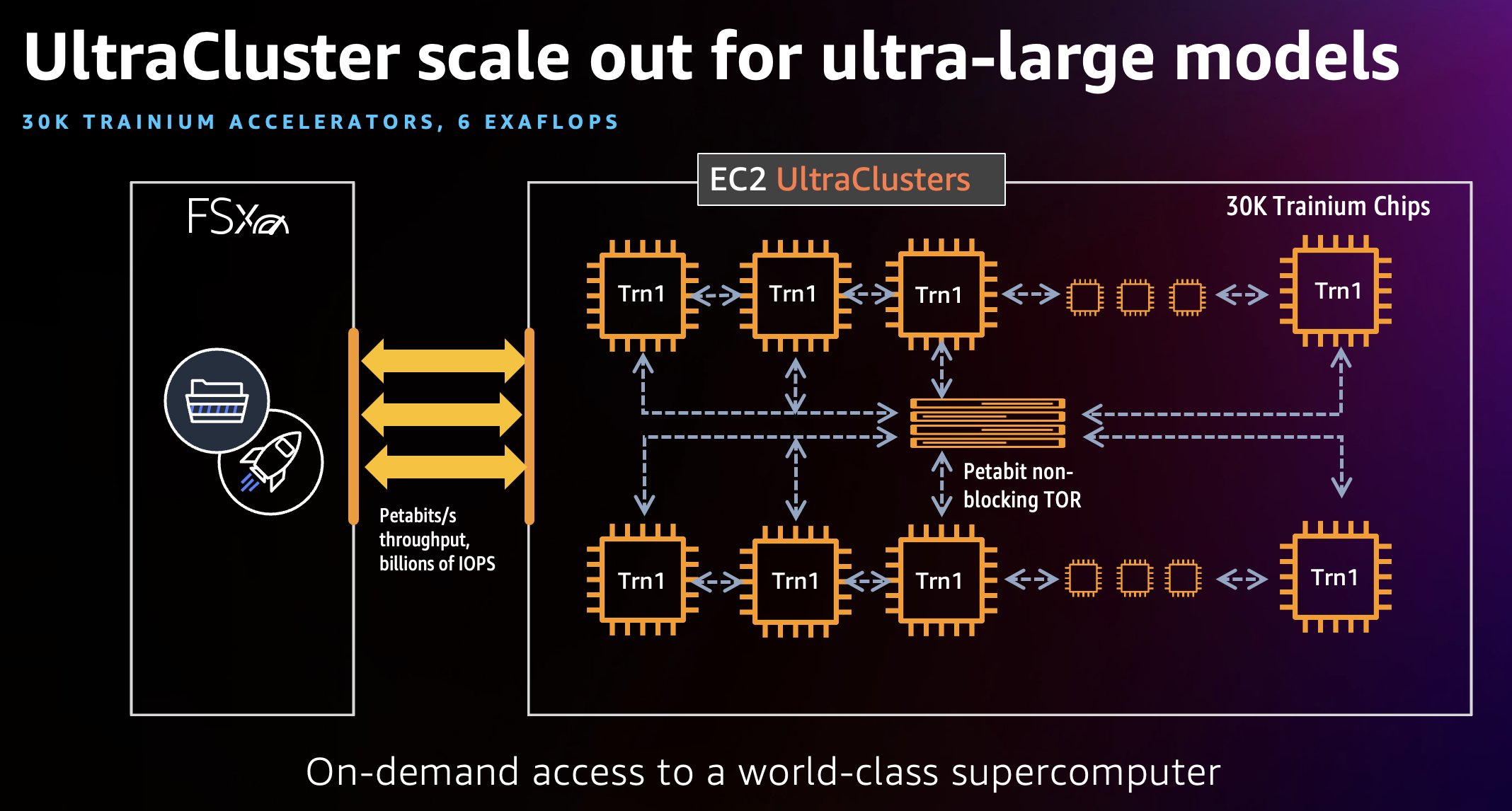
Trn1 インスタンスの UltraClusters は単一のデータセンター内に配置され、Elastic Fabric Adapter (EFA) を使用して相互接続されます。EFA はペタバイト規模のノンブロッキングネットワークインターフェイスで、最大 800 Gbps のネットワーク帯域幅で、AWS P4d インスタンスがサポートする帯域幅の 2 倍 (今後利用可能になる Trn1n インスタンスでは 1.6Tbps と 4 倍)になります。これらの EFA インターフェースは、Neuron Collective Communication(集団通信)ライブラリを使用するモデル学習ワークロードを大規模に実行するのに役立ちます。Trn1 UltraClusters には、Amazon FSx for Lustre などの並列ネットワーク接続ストレージサービスも含まれており、大規模なデータセットへの高スループットアクセスによって、クラスターの効率的な運用を実現します。Trn1 UltraClusters は、最大 30,000台の Trainium デバイスをホストでき、1つのクラスターで最大6エクサフロップスのコンピューティングを実現できます。EC2 Trn1 UltraClusters は、最大6エクサフロップスのコンピューティングを実現する、文字通りオンデマンドのスーパーコンピューターであり、従量課金制で利用できます。この記事では、Slurm などの HPC ツールを使用して UltraCluster を立ち上げ、ワークロードを管理します。
ソリューションの概要
AWS では、AWS Batch、Amazon Elastic Kubernetes サービス (Amazon EKS)、UltraClusters など、分散モデル学習や大規模な推論ワークロードのためのさまざまなサービスを提供しています。この投稿では、UltraCluster でのモデル学習に焦点を当てています。このソリューションでは、AWS ParallelCluster 管理ツールを使って、Trn1 UltraCluster をスピンアップするために必要なインフラストラクチャと環境を作成します。インフラストラクチャは、仮想プライベートクラウド (VPC) 内のヘッドノードと複数の Trn1 コンピュートノードで構成されています。クラスター管理とジョブスケジューリングシステムとして Slurm を使用しています。次の図は、ソリューションのアーキテクチャを示しています。
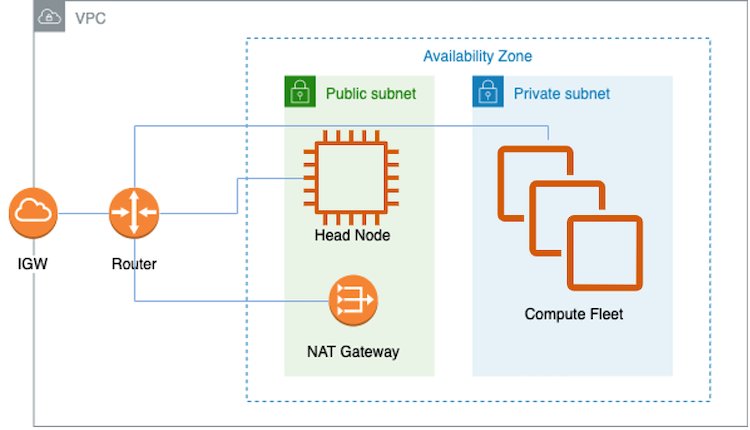
このソリューションの詳細とデプロイ方法については、こちら の GitHub レポジトリ(Train a model on AWS Trn1 ParallelCluster)を参照してください。
このソリューションの重要なステップをいくつか見てみましょう。
1. VPC とサブネットを作成
2. コンピュートフリートを設定
3. クラスターを作成
4. クラスターを確認
5. 学習ジョブを開始
前提条件
この記事の続きを読むには、Amazon Elastic Compute Cloud (Amazon EC2) などの AWS のコアサービスに関する幅広い知識を前提としており、また、ディープラーニングと PyTorch の基本的な知識が必要です。
VPC とサブネットを作成
VPC とサブネットを作成する簡単な方法は、Amazon 仮想プライベートクラウド (Amazon VPC) コンソールを使用することです。詳しい説明は GitHub をご参照ください。VPC とサブネットをセットアップしたら、コンピュートフリート内のインスタンスを設定する必要があります。簡単に言うと、これは ParallelCluster の作成に使用される YAML ファイルにある customActions で指定されたインストールスクリプトが行います。詳細は「ParallelCluster の作成」をご参照ください。ParallelCluster には、前述のアーキテクチャ図に示したように、2 つのサブネットとネットワークアドレス変換 (NAT) ゲートウェイを持つ VPC が必要です。この VPC は、Trn1 インスタンスが利用可能なアベイラビリティーゾーンに存在する必要があります。また、この VPC には、ヘッドノードと Trn1 コンピュートノードをそれぞれ保持するパブリックサブネットとプライベートサブネットが必要です。また、Trn1 コンピュートノードが AWS Neuron パッケージをダウンロードできるように、NAT ゲートウェイのインターネットアクセスも必要です。通常、コンピュートノードは OS パッケージ、Neuron ドライバーとランタイム、マルチインスタンス学習用の EFA ドライバーのアップデートを受け取ります。
ヘッドノードについては、前述のコンピュートノード用のコンポーネントに加えて、PyTorch-NeuronX および NeuronX コンパイラも搭載されているため、Trainium などの XLA デバイスでのモデルコンパイルプロセスが可能になります。
コンピュートフリートの設定
Trn1 UltraCluster を作成するための YAML ファイルでは、InstanceType は trn1.32xlarge と指定されています。MaxCount と MinCount を使って、コンピュートフリートサイズのレンジを指定します。MinCount を使用すると、一部またはすべての Trn1 インスタンスをいつでも利用できるようにすることができます。MinCount を 0 に設定すると、実行中のジョブがない場合に Trn1 インスタンスがこのクラスターから解放されます。
Trn1 は、複数のキューがある UltraCluster にデプロイすることもできます。以下は、キューを 1 つだけ Slurm ジョブ送信用に設定する例です。
複数のキューが必要な場合は、それぞれ個別に maxCount、minCount、Name を持つ複数の InstanceTypeを指定できます。
ここでは、ユーザーが Slurm ジョブのリソースを柔軟に選択できるように、2つのキューが設定されています。
クラスターを作成
Trn1 UltraCluster を起動するには、ParallelCluster ツールがインストールされている環境から次の pcluster コマンドを使用します。
このコマンドでは、以下のオプションを使用しています。
--cluster-configuration– クラスター構成の設定が記載された YAML ファイル-n (or --cluster-name)– クラスター名
上記コマンドは、AWS アカウントに Trn1 クラスターを作成します。クラスター作成の進行状況は、AWS CloudFormation コンソールで確認できます。詳細については、「AWS CloudFormation コンソールの使用」を参照してください。
または、次のコマンドを使用してリクエストのステータスを確認することもできます。
このコマンドを実行すると、以下のようなステータスが表示されます。
出力から得られる重要なパラメータは以下の通りです。
- instanceId – ヘッドノードのインスタンス ID 。Amazon EC2 コンソールに表示されます。
- computeFleetStatus – コンピュートノードの準備状況。
- Tags – このクラスターの作成に使用された
pclusterツールのバージョン。
クラスターを確認
前述の pcluster describe-cluster コマンドを使用してクラスターを確認できます。クラスターを作成すると、出力に次の内容が表示されます。
この時点で、ヘッドノード (Amazon EC2 コンソールのインスタンス ID で確認可能) に SSH で接続できます。以下は、クラスターの論理図です。
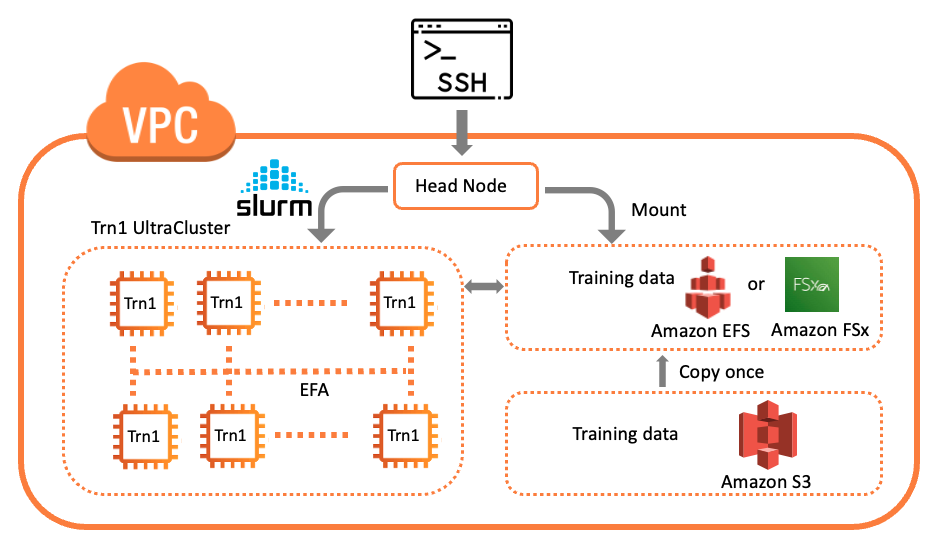
ヘッドノードに SSH 接続すると、sinfo などの Slurm コマンドを使用してコンピュートフリートとそのステータスや、システムのノード情報を確認できます。出力例を以下に示します。
パーティションが1つ表示されていますが、これはキューが 1 つあることを示しています。使用可能なノードは 16個あり、リソースが割り当てられています。ヘッドノードから、任意のコンピュートノードに SSH 接続できます。
exit を使用してヘッドノードに戻ります。
同様に、別のコンピュートノードからコンピュートノードに SSH 接続できます。各コンピュートノードには、neuron-top などの Neuron ツールがインストールされています。学習スクリプトの実行中に neuron-top を呼び出して、各ノードでの NeuronCore の使用率を調べることができます。
学習ジョブを開始
このクラスターの実行例として、Hugging Face BERT-Large 事前学習チュートリアルを使用します。学習データとスクリプトがクラスターにダウンロードされたら、Slurm コントローラーを使用してワークロードを管理および調整します。sbatch コマンドで学習ジョブを送信します。シェルスクリプトは neuron_parallel_compile API 経由で Python スクリプトを呼び出し、完全な学習を実行しなくてもモデルをグラフにコンパイルします。次のコードを参照してください。
このコマンドでは、以下のオプションを使用しています。
--exclusive– このジョブはすべてのノードを使用し、現在のジョブの実行中は他のジョブとノードを共有しません。--nodes– ジョブで使用するノード数--wrap– Slurm コントローラによって実行されるコマンド文字列の定義。今回の例では、すべてのノードを使用してモデルを並行してコンパイルします。
モデルが正常にコンパイルされたら、次のコマンドで完全な学習ジョブを開始できます。
このコマンドは、Hugging Face BERT-Large モデルの学習ジョブを起動します。Trn1.32xLarge ノードが 16台あれば、8時間以内に完了することが期待できます。
この時点で、squeue などの Slurm コマンドを使用して、送信されたジョブを確認できます。出力例は次のとおりです。
この出力は、ジョブが 16 のコンピュートノードで実行されている (R) ことを示しています。
ジョブの実行中、出力はキャプチャされ、Slurm ログファイルに追加されます。ヘッドノードのターミナルから、リアルタイムで確認できます。
また、Slurm ログファイルと同じディレクトリに、このジョブに対応するディレクトリがあります。このディレクトリには、たとえば次のものが含まれます。
このディレクトリには、すべてのコンピュートノードからアクセスできます。results.json は、モデルの構成、バッチサイズ、合計ステップ数、勾配累積ステップ、学習データセット名など、この特定のジョブ実行のメタデータをキャプチャします。各コンピュートノードごとのモデルチェックポイントと出力ログもこのディレクトリにキャプチャされます。
クラスターのスケーラビリティ
Trn1 UltraCluster は、相互接続された複数の Trn1 インスタンスが大規模なモデル学習ワークロードを並行して実行し、合計計算時間または収束までの時間を短縮します。クラスターのスケーラビリティには、ストロングスケーリングとウィークスケーリングの 2 つの尺度があります。通常、モデルの学習において、利用料金は勾配更新におけるスループットによって決まるため、学習の実行を高速に行う必要があります。ストロングスケーリングとは、プロセッサ数が増えても問題の合計サイズが変わらないシナリオを指します。ストロングスケーリングは、モデル学習のスケーラビリティの重要な尺度です。ストロングスケーリング (並列化の影響)を評価する際には、グローバルバッチサイズを同じに保ち、収束にどれくらいの時間がかかるかを確認する必要があります。このようなシナリオでは、コンピュートノードの数に応じて勾配累積のマイクロステップを調整する必要があります。これは、学習シェルスクリプト run_dp_bert_large_hf_pretrain_bf16_s128.sh で次のように実行することで実現されます。
一方、ノードを追加することで一定時間に実行できるワークロードの数を評価したい場合は、ウィークスケーリングを使用してスケーラビリティを測定します。ウィークスケーリングでは、Neuron コアの数と同じ割合で問題のサイズが大きくなるため、Neuron コアあたりの作業量は同じに保たれます。ウィークスケーリング、またはノードを追加して負荷が増えた場合の影響を評価するには、学習スクリプトから上記の行を削除し、勾配累積のステップ数を一定に保ち、学習スクリプトで指定されているデフォルト値(32)にします。
結果の評価
スケーリングの効果を実証するために、Neuron のパフォーマンスページにいくつかのベンチマーク結果を提供しています。このデータは、複数のインスタンスを使用してさまざまな大規模モデルの学習ジョブを並列化し、大規模に学習することの利点を示しています。
リソースの削除
この UltraCluster のすべてのインフラストラクチャを削除するには、pcluster コマンドを使用してクラスターとそのリソースを削除します。
まとめ
この記事では、AWS の Trainium アクセラレータを利用する Trn1 UltraCluster で学習ジョブをスケーリングすることで、モデルの学習にかかる時間を短縮する方法について説明しました。また、BERT-large モデル用の分散学習ジョブをデプロイする方法が記載された Neuron サンプルリポジトリへのリンクも提供しました。Trn1 UltraCluster は、分散型の学習ワークロードを実行して、超大規模なディープラーニングモデルを大規模に学習します。分散学習を行うことによって、単一の Trn1 インスタンスでの学習に比べて、モデルの収束がはるかに速くなります。
Trainium 搭載の Trn1 インスタンスの使用を開始する方法の詳細については、Neuron のドキュメントをご覧ください。
翻訳は機械学習ソリューションアーキテクトの大渕が担当しました。
原文はこちらです。