Amazon Web Services ブログ
AWS Inferentiaを使用して Amazon EKS で 3,000種類のディープラーニングモデルを 1 時間あたり 50 USD 以下で提供
この記事は、2021年9月30日に Alex Iankoulski、Joshua Correa、Mahadevan Balasubramaniam、Sundar Ranganathan によって投稿された Serve 3,000 deep learning models on Amazon EKS with AWS Inferentia for under $50 an hour を翻訳したものです。
より多くのお客様が、より大規模でスケーラブルで、より費用対効果の高い機械学習 (ML) 推論パイプラインをクラウドに構築する必要性を感じています。これらの基本前提条件以外では、本番環境の ML 推論パイプラインの要件は、ビジネスユースケースによって異なります。レコメンデーションエンジン、感情分析、広告ランキングなどのアプリケーションの典型的な推論アーキテクチャでは、古典的な ML モデルとディープラーニング(DL)モデルを組み合わせて、多数のモデルを提供する必要があります。各モデルは、アプリケーションプログラミングインターフェイス(API)エンドポイントを介してアクセスでき、リクエストを受けてから事前に定義されたレイテンシー要件内で応答できなければなりません。
この記事では、Amazon Elastic Kubernetes サービス(Amazon EKS)上に構築された、Salesforce の Commerce Einstein チームと共同で開発された推論アーキテクチャについて説明します。このアーキテクチャでは、基本的な前提条件に対応するだけでなく、スケーラブルなアーキテクチャに何千もの独自のDLモデルを詰め込むことができます。Amazon Elastic Compute Cloud(Amazon EC2)インスタンスファミリー(c5、g4dn、Inf1)を組み合わせて、コストとパフォーマンスの観点から最適なデザインを検討しました。これらの要件を満たすために、軽量で効率的な Python ベースの API サーバーである FastAPI を使用して、Amazon EKS 上に DL 推論サービスを構築し、モデル間でコンピューティングリソースとメモリリソースを効率的に共有するためのモデルビンパッキング戦略を開発しています。アーキテクチャの負荷試験では、 huggingface.co の自然言語処理 (NLP) オープンソースモデル (bert-base-case-case、約 800 MB) を使用し、数千のクライアントが同時にサービスプールにリクエストを送信するシミュレーションを行いました。Inf1 インスタンスのカスタム ML チップである AWS Inferentia を使用して、3,000種類のユニークな ML モデルをパッケージ化して提供しながら、コストを 50 USD/時間(オンデマンド料金)以下に抑え、ラウンドトリップレイテンシーは 目標の 100 ミリ秒(P90)に対して70 ミリ秒を実現しています。このアーキテクチャと最適化のアプローチは、任意のカスタム DL モデルに拡張することができます。
ソリューションの概要
以下は、標準的な Amazon EKS インフラストラクチャをベースにした、シンプルでスケーラブルかつ可用性の高いアーキテクチャであり、アベイラビリティーゾーン全体にデプロイすることができます。

Amazon EKSクラスターには複数のノードグループがあり、ノードグループごとに 1 つの EC2 インスタンスファミリーがあります。各ノードグループは、CPU (c5)、GPU (g4dn)、AWS Inferentia (Inf1) などの異なるインスタンスタイプをサポートでき、インスタンスごとに複数のモデルをパックして、提供されるモデルの数を最大化できます。次に、モデルサービングアプリケーションと DL フレームワークの依存関係がコンテナ化され、これらのコンテナイメージが Amazon Elastic Container Registry(Amazon ECR)に保存されます。コンテナイメージは、インスタンスファミリーごとにカスタマイズされたデプロイメントマニフェストとサービスマニフェストを使用してクラスターにデプロイされます。モデルサービングアプリケーションは、サーバーの初期化時に Amazon Simple Storage Service(Amazon S3)からモデルアーティファクトをダウンロードします。これにより、Amazon ECR 上のコンテナイメージのサイズが縮小され、モデルデータがサービス定義から切り離されます。
cluster-autoscaler、horizontal-pod-autoscaler、aws-load-balancer-controller、metrics-server、nginx-ingress-controller、neuron-device-plugin-daemonset および nvidia-device-plugin-daemonset などのサービスは、必要に応じてクラスターにデプロイされます。この設計では、クラスター内のサービスエンドポイントの名前解決を Kubernetes coredns に依存しています。各モデルは、DNS 名とモデル名の組み合わせによってアドレス指定可能です。たとえば、http://<model server ID>.<name space>.svc.cluster.local:8080/predictions/<model id> のように指定します。
DNS 名のカスタマイズには、Ingressマニフェストを使用できます。
このアーキテクチャは、ビルド、トレース、パック、デプロイ、テストという 5 つのシンプルなステップで実行できるように設定されています。コードリポジトリは GitHub リポジトリからアクセスできます。
- ビルドステップでは、選択したインスタンスタイプのベースコンテナを構築し、必要なすべてのベースレイヤーをコンテナにインストールします。
- トレースステップでは、モデルをコンパイルします。モデルはターゲット EC2 インスタンスで実行されます。Inf1 で実行するには、 AWS Neuron SDK を使用してモデルをトレースする必要があります。以下は、AWS Inferentia の bfloat16 または GPU インスタンス上のAutomatic Mixed Precision (AMP)で実行されるモデルをトレースするためのコードスニペットです。
print('\nTracing model ...')
example_inputs = (
torch.cat([inputs['input_ids']] * batch_size,0),
torch.cat([inputs['attention_mask']] * batch_size,0)
)
os.makedirs(f'traced-{model_name}', exist_ok=True)
torch.set_num_threads(6)
if 'inf' in processor:
model_traced = torch.neuron.trace(model,
example_inputs,
verbose=1,
compiler_workdir=f'./traced-{model_name}/compile_wd_{processor}_bs{batch_size}_seq {sequence_length}_pc{pipeline_cores}',
compiler_args = ['--neuroncore-pipeline-cores', str(pipeline_cores)])
else:
model_traced = torch.jit.trace(model, example_inputs)- パックステップでは、FastAPIを使用してモデルをコンテナにパックします。同じコンテナ内に複数のモデルをパックすることもできます。
- デプロイステップでは、設定されたランタイム (Kubernetes や Docker など) でモデルを実行し、モデルサーバーコンテナのライフサイクル全体の管理を容易にします。次のコードスニペットは、実行オプションを設定し、設定されたランタイムでコンテナを起動します。
echo "Runtime: $runtime"
echo "Processor: $processor"
if [ "$runtime" == "docker" ]; then
server=0
while [ $server -lt $num_servers ]; do
run_opts="--name ${app_name}-${server} -e NUM_MODELS=$num_models -e POSTPROCESS=$postprocess -e QUIET=$quiet -P"
if [ "$processor" == "gpu" ]; then
run_opts="--gpus 0 ${run_opts}"
fi
CMD="docker run -d ${run_opts} ${registry}${model_image_name}${model_image_tag}"
echo "$CMD"
eval "$CMD"
server=$((server+1))
done
elif [ "$runtime" == "kubernetes" ]; then
kubectl create namespace ${namespace} --dry-run=client -o yaml | kubectl apply -f -
./generate-yaml.sh
kubectl apply -f ${app_dir}
else
echo "Runtime $runtime not recognized"
fi- 最後のステップでは、ランタイム環境にデプロイされたモデルサーバーに対してテストを実行します。
ビンパッキング ML モデル
複数の EC2 インスタンス間で ML モデルをビンパッキングすることは、モデル間でコンピューティングリソースとメモリリソースを効率的に共有するために不可欠です。モデルのビンパッキングは、組み合わせ最適化を用いた 0-1 ナップザック問題として定式化して解くことができます。以下にビンパッキングの定式化を示します。nmodels は最大プロセッサメモリ(Mmax)と使用率(Cmax)の制約を受けます。このアプローチでは、最小限の EC2 インスタンスでモデルを最適にビンパッキングすることを推奨しています。
ビンの数は、ビンごとに 1 つのモデルという簡単な解で問題を初期化するために超過され、最小のビンの数で目標を達成するためにプルーニング(pruning)されます。

次の図は、それぞれが固有のメモリ要件とコンピューティング要件を持つ 78 個のモデルに対するビンパッキングの割り当ての例を示しています。この例では、78個のモデルが 23 のインスタンス (g4dn、Inf1) にパックされ、ターゲット最大メモリ (7.4 GB) とコンピューティングキャパシティ (83%) を指定しています。カラーリングの凡例はモデルのインデックスを示しています。
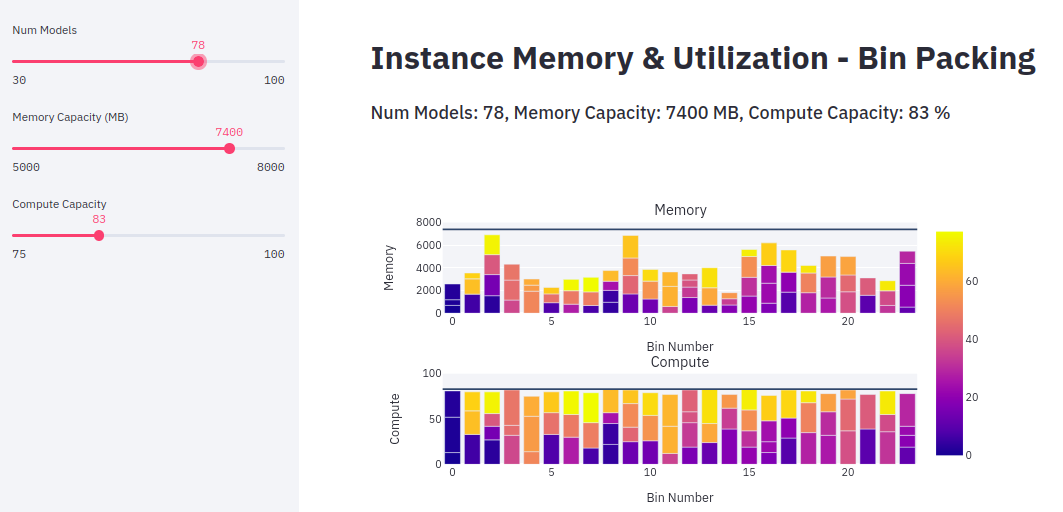
上記の方法を使用して、インスタンス間でモデルを最適にビンパックすることができます。次の表は、Inf1 インスタンスと g4dn インスタンスのビンパッキングの結果をまとめたものです。Transformer ベースの NLP モデルでは、期待されるレイテンシー要件を達成するためにハードウェアアクセラレーションが必要なため、これらのインスタンスファミリーを選択しました。inf1.6xlarge (48 GiB メモリ) では、g4dn.12xlarge (192 GiB メモリ) に比べて、より多くのモデルをビンパックすることができました。これは、Neuron コンパイラのAuto Casting 機能により、FP32 モデルを 16 ビットの bfloat に自動的に変換し、スループットを最大化するためです。
| モデル | EC2 インスタンス | サーバータイプ | インスタンスあたりのビンパックされたモデルの数 | インスタンスあたりの料金 (オンデマンド), USD/時間 | モデル時間あたりの料金 (USD) |
| bert-base-cased | inf1.2xlarge | FastAPI | 24 | 0.362 | 0.015 |
| bert-base-cased | g4dn.xlarge | FastAPI | 18 | 0.526 | 0.029 |
| bert-base-cased | inf1.xlarge | FastAPI | 11 | 0.228 | 0.020 |
| bert-base-cased | inf1.6xlarge | FastAPI | 76 | 1.180 | 0.015 |
| bert-base-cased | g4dn.12xlarge | FastAPI | 72 | 3.912 | 0.054 |
テスト方法と測定結果
大規模な負荷テストを行うために、テストプールに同時にリクエストを送信する 40以上のクライアントをシミュレート (複数のクライアントからのロード) しました。より多くのユーザーリクエストでシステムをロードすると、レイテンシーを犠牲にしてスループットが向上します。テストは、スループットとレイテンシーの曲線をスイープして、最適化されたリソース使用率のデータポイントを見つけるようにしました。スループットとレイテンシー(P50、P90、P95)を測定し、レイテンシー、スループット(1 秒あたりの推測数)、インスタンスあたりのモデル数、コストの 4 つのメトリクスで結果をまとめました。さらに、curl を使用してシングルシーケンシャルおよびシングルランダムリクエストをシミュレートするテストを作成し、テストプール内の各モデルに GET または POST リクエストを送信しました。これらの実験の目的は、ベースラインとして期待できるベストケースのレイテンシーを測定することでした。
いくつかの実験を行い、最小のコストで最高のパフォーマンスを実現する EC2 インスタンスの最小セットに最適なモデルパッキングを見つけました。次の表は、テスト結果の一部をまとめたものです。最良の結果は、DNS キャッシュを有効にした 40台の inf1.6xl インスタンスを使用した場合で、3,040 のモデルを6,230 リクエスト/秒のスループット、 66 ミリ秒(P90 レイテンシー)で処理し、47.2 USD/時間(オンデマンド)のコストで実現しました。一方、32台の inf1.6xl インスタンスと 21台の g4dn.12xl インスタンスを使用した最適な混合インスタンスのデプロイでは、3,048のモデルをサービングすることができましたが、スループットは248 リクエスト/秒と大幅に低下し、コストは 119.91 USD/時間に増加しました。今回のアーキテクチャでは、コスト最適化のための手段として EC2 スポットインスタンスを使用していませんが、推論ワークロードが時間的な要件に柔軟で耐障害性に優れている場合は、スポットを使用することを強くお勧めします。次の表は、インスタンスタイプ別の結果をまとめたものです。
| Exp. # | インスタンス (数×タイプ) | モデル (数) | シーケンシャル応答(ミリ秒) | ランダム応答 (ミリ秒) | スループット (リクエスト/秒) | P90のレイテンシー (ミリ秒) | オンデマンドコスト (USD/時間) |
| 1 | 3 x inf1.6xl | 144 | 21 – 32 | 21 – 30 | 142 | 57 | 3.54 |
| 2 | 5 x inf1.6xl | 240 | 23 – 35 | 21 – 35 | 173 | 56 | 5.9 |
| 3 | 21 x inf1.6xl | 1008 | 23 – 39 | 23 – 35 | 218 | 24 | 24.78 |
| 4 | 32 x inf1.6xl | 1536 | 26 – 33 | 25 – 37 | 217 | 23 | 37.76 |
| 5 | 4 x g4dn.12xl | 288 | 27 – 34 | 28 – 37 | 178 | 30 | 15.64 |
| 6 | 14 x g4dn.12xl | 1008 | 26 – 35 | 31 – 41 | 154 | 30 | 54.76 |
| 7 | 32 x inf1.6xl +
21 x g4dn.12xl |
3048 | 27 – 35 | 24 – 45 | 248 | 28 | 119.91 |
| 8 | 40 x inf1.6xl | 3002 | 24 – 31 | 25 – 38 | 1536 | 33 | 47.2 |
| 9 | 40 x inf1.6xl
(DNS キャッシュあり) |
3040 | 24 – 31 | 25 – 38 | 6230 | 66 | 47.2 |
まとめ
このスケーラブルなアーキテクチャにより、推論を 3,000種類のモデルにスケーリングし、100 ミリ秒のレイテンシー要件を達成すると同時に、最小限の EC2 インスタンスでモデルを効率的にビンパッキングすることでコストを最適化し、コストを 50 USD/時間(オンデマンド)以下に抑えることができました。すべてのテストにおいて、Inf1 インスタンスは、他のインスタンスと比較して最高のスループット、最小のコスト、最速の応答時間、および最大のビンパッキング率を実現しました。Snap、Airbnb、Sprinklr などのAWSの多くのお客様は、AWS Inferentia を使用して、さまざまなデプロイで最高のパフォーマンスを低コストを実現しています。テストされた DL モデルでは、inf1 および g4dn インスタンスタイプでハードウェアアクセラレーションを使用する必要がありますが、他のモデルタイプを異なるインスタンスタイプ(Inf1、CPU、GPU)とマッチングさせ、説明した方法で適宜ビンパックモデルを作成することができます。
AWS Inferentia チップとAmazon EC2 Inf1インスタンスの詳細をご覧いただき、Neuron SDK を使用して AWS Inferentia 上で独自のカスタムMLパイプラインを実行し始めましょう。
________________________________________
翻訳はアンナプルナラボの常世が担当しました。