Artificial Intelligence
Serve 3,000 deep learning models on Amazon EKS with AWS Inferentia for under $50 an hour
October 2023: This post was reviewed and updated to include support for Graviton and Inf2 instances.
More customers are finding the need to build larger, scalable, and more cost-effective machine learning (ML) inference pipelines in the cloud. Outside of these base prerequisites, the requirements of ML inference pipelines in production vary based on the business use case. A typical inference architecture for applications like recommendation engines, sentiment analysis, and ad ranking need to serve a large number of models, with a mix of classical ML and deep learning (DL) models. Each model has to be accessible through an application programing interface (API) endpoint and be able to respond within a predefined latency budget from the time it receives a request.
In this post, we describe an inference architecture, developed in collaboration with the Commerce Einstein Team at Salesforce, built on Amazon Elastic Kubernetes Service (Amazon EKS) to not only address the base prerequisites, but also pack thousands of unique PyTorch DL models in a scalable architecture. We explore a mix of Amazon Elastic Compute Cloud (Amazon EC2) instance families (c5, c6i, c7g, g4dn, Inf1, Inf2) to develop an optimal design from a cost and performance aspect. To meet these requirements, we build the DL inferencing service on Amazon EKS using FastAPI, a lightweight and efficient Python-based API server, and develop a model bin packing strategy to efficiently share compute and memory resources between models. To load test the architecture, we use a natural language processing (NLP) open-source PyTorch model from huggingface.co (bert-base-cased, approximately 800 MB) and simulate thousands of clients sending simultaneous requests to the service pool. We use AWS Inferentia, the AWS custom ML chip for inference workloads, to package and serve 3,000 unique PyTorch models while keeping the cost below $50/hour (On-Demand pricing), with a round trip latency of 70 milliseconds (P90) versus our target of 100 milliseconds. You can extend this architecture and optimization approach to any custom DL model.
Solution overview
The following is a simple, scalable, and highly available architecture based on a standard Amazon EKS infrastructure that can be deployed across Availability Zones.
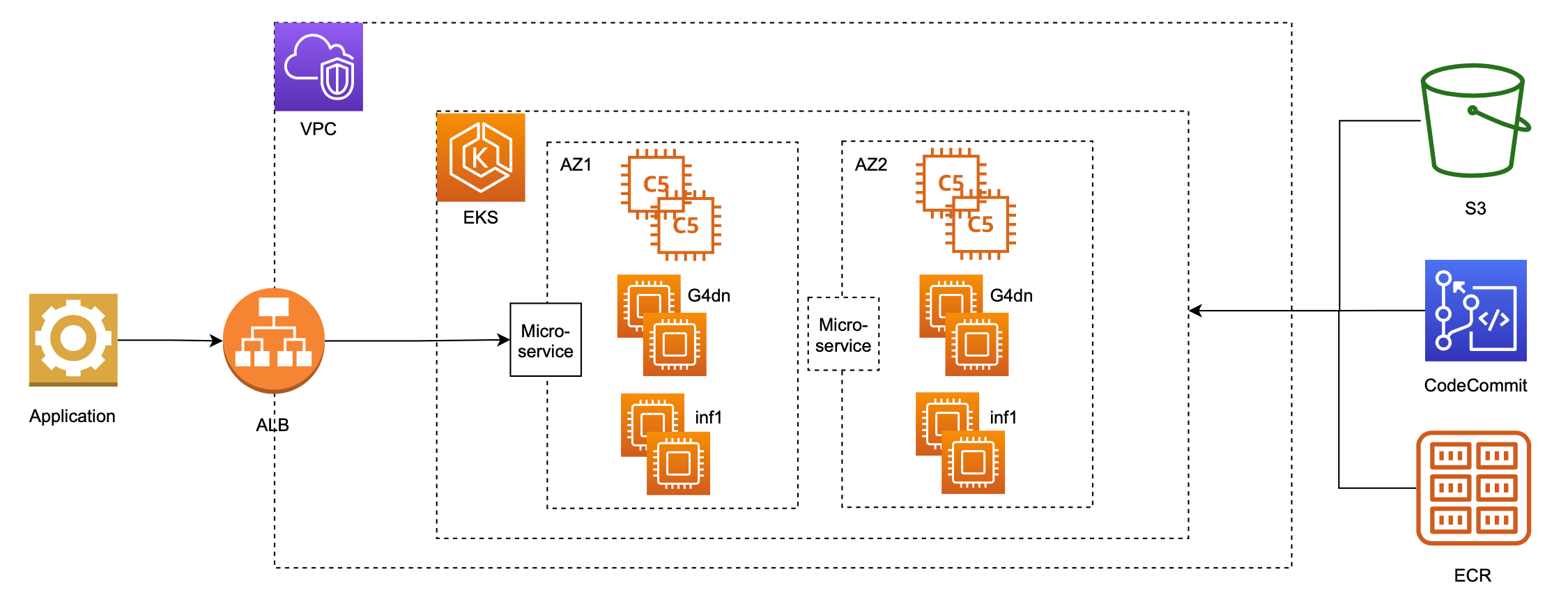
The Amazon EKS cluster has several node groups, with one EC2 instance family per node group. Each node group can support different instance types, such as CPU (c5,c6i,c7g), GPU (g4dn), and AWS Inferentia (Inf1,Inf2), and can pack multiple models per instance to maximize the number of served models. Next, the model serving application and DL framework dependencies are containerized, and these container images are stored on Amazon Elastic Container Registry (Amazon ECR). The container images are deployed to the cluster using deployment and service manifests, customized for each instance family. The model serving application downloads the model artifacts from Amazon Simple Storage Service (Amazon S3) at server initialization, which reduces the size of the container images on Amazon ECR and decouples the model data from the service definition.
Services like cluster-autoscaler, horizontal-pod-autoscaler, aws-load-balancer-controller, metrics-server, nginx-ingress-controller, neuron-device-plugin-daemonset, and nvidia-device-plugin-daemonset are deployed to the cluster as required. This design relies on Kubernetes coredns for name resolution of the service endpoints within the cluster. Each model is addressable through a combination of DNS name and model name. For example, http://<model server ID>.<name space>.svc.cluster.local:8080/predictions/<model id>.
For customization of the DNS names, we can use an ingress manifest.
The architecture is set up to run in five simple steps: build, trace, pack, deploy, and test. The code repository can be accessed in the GitHub repo.
- The build step builds the base container for the selected instance type, installing all the necessary base layers in the container.
- The trace step compiles the model. To maximize performance on GPU instances, the models were serialized into the TorchScript format using PyTorch libraries (torch.jit.trace). For Inf1 and Inf2 instances, the AWS Neuron SDK’s native integration with PyTorch was leveraged to compile the models into a Neuron bfloat16 format. The following is the code snippet to trace a model that runs in bfloat16 on AWS Inferentia or Automatic Mixed Precision (AMP) on a GPU instance:
- The pack step packs the model in a container with FastAPI, which also allows packing multiple models within the same container.
- The deploy step runs the model in the configured runtime (such as Kubernetes or Docker) and facilitates the management of the full lifecycle of the model server containers. The following code snippet sets the run options and launches the container in a configured runtime:
- The final step runs tests against the model servers deployed in the runtime environment.
Bin packing ML models
Bin packing of PyTorch ML models across EC2 instances is essential to efficiently share compute and memory resources between models. The task of bin packing the models can be formulated and solved as a 0-1 knapsack problem using combinatorial optimization. The following is the mathematical formulation for bin packing; nmodels is subject to a constraint of max processor memory (Mmax) and utilization (Cmax). This approach recommends optimal bin packing of the models across a minimal set of EC2 instances.

The number of bins is supersized to initialize the problem with a trivial solution of one model per bin and pruned to attain the target with minimal number of bins.

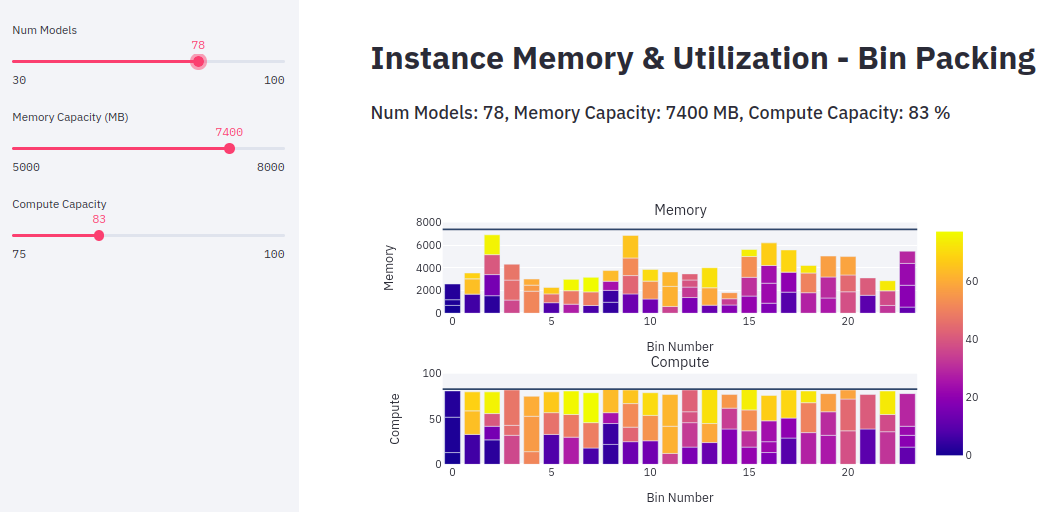
The following visualization shows a sample bin packing allocation for 78 models, each with unique memory and compute requirements. In this example, 78 models were packed into 23 instances (g4dn, Inf1) with a specified target maximum memory (7.4 GB) and compute capacity (83%). The coloring legend indicates model index.
We can use the preceding method to optimally bin pack models across instances. The following table summarizes bin packing results for Inf1 and g4dn instances. We chose these instance families because the transformer-based NLP model requires hardware acceleration to achieve the expected latency. We were able to bin pack more models in Inf1.6xlarge (48 GiB memory) compared to g4dn.12xlarge (192 GiB memory) because the Neuron compiler’s Auto Casting capability automatically converts FP32 models to 16-bit bfloat to maximize throughput. We also experimented with c5, c6i, c7g, and inf2 instance families. The table below shows the results we observed.
| Model | EC2 Instance | Server Type | Number of Models Bin Packed per Instance | Price per Instance
(On-Demand), $/hr |
Price per Model-hour
($) |
| bert-base-cased | inf1.2xlarge | FastAPI | 24 | 0.362 | 0.015 |
| bert-base-cased | g4dn.xlarge | FastAPI | 18 | 0.526 | 0.029 |
| bert-base-cased | inf1.xlarge | FastAPI | 11 | 0.228 | 0.020 |
| bert-base-cased | inf1.6xlarge | FastAPI | 76 | 1.180 | 0.015 |
| bert-base-cased | g4dn.12xlarge | FastAPI | 72 | 3.912 | 0.054 |
| bert-base-cased | c5.4xlarge | FastAPI | 32 | 0.68 | 0.021 |
| bert-base-cased | c6i.4xlarge | FastAPI | 15 | 0.68 | 0.045 |
| bert-base-cased | c7g.4xlarge
(Graviton) |
FastAPI | 32 | 0.58 | 0.018 |
| bert-base-cased | Inf2.8xlarge | FastAPI | 44 | 1.97 | 0.045 |
| bert-base-cased | Inf2.24xlarge | FastAPI | 264 | 6.49 | 0.025 |
Test methodology and observations
To load test at scale, we simulated over 40 clients sending simultaneous requests to the test pool (loading from multiple clients). Loading the system with more user requests increases the throughput at the expense of latency; the tests were designed to sweep the throughput-latency curve to find data points with optimized resource usage. We measured throughput and latency (P50, P90, P95) and summarized the results across four metrics: latency, throughput (inferences per second), number of models served per instance, and cost. In addition, we created tests to simulate single-sequential and single-random requests using curl to send a GET or POST request to each model in the test pool. The purpose of these experiments was to measure the best-case latency we can expect, as a baseline.
We ran several experiments to find optimal model packing across minimal sets of EC2 instances that would result in high performance at the lowest cost. We identified a few interesting options. Using 40 Inf1.6xl instances with DNS caching enabled, we could serve 3,040 models with throughput of 6,230 requests per second and 66 milliseconds P90 latency at a cost of $47.2/hour (On-Demand). Using Graviton instances we could serve 3200 models with throughput of 1205 requests per second and 12 milliseconds P90 latency for $58/hr. And using Inf2 instances we were able to scale throughput of 3168 models to over 10,000 requests per second with 43 milliseconds P90 latency. Although we didn’t use EC2 Spot Instances as a lever for cost-optimization in this architecture, we highly recommend using Spot if your inference workload is time flexible and fault tolerant. The following table summarizes our observations across instance types.
| Exp. # | Instances
(num x type) |
Models (num) | Sequential Response (ms) | Random Response (ms) | Throughput (req/s) | Latency with Load P90 (ms) | On-Demand Cost ($/hr) |
| 1 | 3 x inf1.6xl | 144 | 21 – 32 | 21 – 30 | 142 | 57 | 3.54 |
| 2 | 5 x inf1.6xl | 240 | 23 – 35 | 21 – 35 | 173 | 56 | 5.90 |
| 3 | 21 x inf1.6xl | 1008 | 23 – 39 | 23 – 35 | 218 | 24 | 24.78 |
| 4 | 32 x inf1.6xl | 1536 | 26 – 33 | 25 – 37 | 217 | 23 | 37.76 |
| 5 | 4 x g4dn.12xl | 288 | 27 – 34 | 28 – 37 | 178 | 30 | 15.64 |
| 6 | 14 x g4dn.12xl | 1008 | 26 – 35 | 31 – 41 | 154 | 30 | 54.76 |
| 7 | 32 x inf1.6xl +
21 x g4dn.12xl |
3048 | 27 – 35 | 24 – 45 | 248 | 28 | 119.91 |
| 8 | 40 x inf1.6xl | 3002 | 24 – 31 | 25 – 38 | 1536 | 33 | 47.20 |
| 9 | 40 x inf1.6xl
(With DNS Caching) |
3040 | 24 – 31 | 25 – 38 | 6230 | 66 | 47.20 |
| 10 | 30 x c5.4xl | 960 | – | – | 720 | 15 | 23.88 |
| 11 | 100 x c6i.4xl | 3000 | – | – | 920 | 9 | 68.00 |
| 17 | 60 x c7g.4xl | 1920 | – | – | 534 | 19 | 34.80 |
| 18 | 100 x c7g.4xl | 3200 | – | – | 1205 | 12 | 58.00 |
| 19 | 21 x Inf2.8xl | 924 | 12-17 | 10-14 | 3200 | 43 | 41.37 |
| 20 | 40 x Inf2.8xl | 1760 | 11-20 | 10-21 | 6016 | 43 | 78.80 |
| 21 | 72 x Inf2.8xl | 3168 | 11-22 | 10-22 | 10756 | 42 | 141.84 |
| 22 | 5 x Inf2.24xl | 1320 | 13-16 | 11-16 | 5013 | 67 | 32.45 |
| 23 | 12 x Inf2.24xl | 3168 | 12-14 | 11-14 | 10656 | 43 | 77.88 |
Conclusion
With this architecture, we were able to scale inference across 3,000 PyTorch models, achieving a target latency of less than 100 milliseconds, while simultaneously keeping costs under $50/hour (On-Demand), optimizing for cost by efficiently bin packing models across a minimal set of EC2 instances. Across all the tests, Inferentia instances yielded the highest throughput, lowest cost, fastest response time, and the maximum bin packing ratio compared to other instances. AWS customers like Snap, Airbnb, Sprinklr and many more have been using AWS Inferentia to achieve the highest performance and lowest cost on a variety of deployments. You can match other models with different processor types (Inferentia, x86 CPU, Graviton, GPU) and bin pack models accordingly by using the same methodology.
Learn more about the AWS Graviton processor to get started running your inference workloads on energy and cost-efficient arm-based infrastructure.
Learn more about the EC2 Inf1 and Inf2 instances to get started running your own custom ML pipelines on AWS Inferentia using the Neuron SDK.
About the Authors
Alex Iankoulski is a Principal Solutions Architect with a focus on autonomous workloads using containers. Alex is a hands-on full-stack infrastructure and software architect and has been building platforms using Docker to help accelerate the pace of innovation by applying container technologies to engineering, data science, and AI problems. Over the past 10 years, he has worked on combating climate change, democratizing AI and ML, and making travel safer, healthcare better, and energy smarter.
Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics-infused deep learning, building and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
Sundar Ranganathan is the Head of Business Development, ML Frameworks on the Amazon EC2 team. He focuses on large-scale ML workloads across AWS services like Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
Joshua Correa is a Salesforce Principal Member of Technical Staff working on the Commerce Einstein Team. Joshua has deep passion for building scalable, resilient and cost effective infrastructure for Machine Learning. Joshua enjoys working at the intersection of software engineering and data science to bring cutting edge models into production.
Modestus Idoko is a Specialist Solutions Architect in ML Frameworks. He focuses on helping customers build and deploy ML workloads at scale on AWS utilizing services like ParallelCluster and EKS. He has a deep research and technical background in computational sciences and has worked across industries including space, energy, and artificial intelligence/emerging technologies. He is passionate about innovative science and technologies and how to utilize the same to solve business problems.
Daniel Zilberman is a Senior Solutions Architect with a focus on container application problems and DevSecOps projects. Daniel is a hands-on full-stack infrastructure and GitOps architect and has been building solutions using various virtualization, container orchestration and HPC platforms to help customers improve their infrastructure capabilities, accelerate software development, and improve security by applying those technologies to respective business domains.