Amazon Web Services ブログ
Similarweb の HBase から Amazon DynamoDB への移行
大規模なデータ量を運用するうえで、運用面での重要な課題に直面します。Similarweb では Apache HBase でこれらの課題に直面し、Amazon DynamoDB で解決策を見出しました。
Similarweb は、Web サイトのトラフィック、アプリの利用状況、市場トレンドに関する AI 駆動のインサイトを提供するデジタルインテリジェンスプラットフォームであり、企業が競合をベンチマークし、成長戦略を最適化するのに役立ちます。
私たちは既存の Apache HBase インフラストラクチャでスケーラビリティと運用上の複雑さの問題が増大しており、より柔軟で効率的な代替案を模索することになりました。本記事では、データストレージを Apache HBase から DynamoDB へ移行した過程を紹介します。技術的な課題、移行アプローチ、データモデリング戦略、コスト最適化テクニック、そして得られた主なメリットについて議論します。DynamoDB へ移行することで、パフォーマンスとスケーラビリティが向上し、メンテナンス負荷が軽減され、チームはインフラ管理よりもイノベーションに注力できるようになりました。学んだ教訓と、この移行が業務オペレーションに与えた影響についても探っていきます。
背景
私たちの Web アプリケーションでは、ユーザーに大量のデータを提供するために堅牢なデータベースソリューションが必要です。そのソリューションは、データを効果的に保存し、迅速に取得し、ユーザーインターフェイスに結果を返す前に集計、グルーピング、ソートなどの操作を実行する必要があります。これを実現するため、データの性質とクエリパターンに基づいた 2 つのアプローチを採用し、Web アプリケーションを応答性が高くインタラクティブに保つよう設計しています。
最初のアプローチは、ユーザー入力に依存する動的クエリや、サイトグループのべき集合のデータを計算するような複雑な計算に関するものです。これは膨大な数の組み合わせとなり、事前計算は現実的ではありません。そのため、これらのクエリには Firebolt のようなクラウド分析データベース (OLAP システム) を使用しています。Firebolt は、JOIN、GROUP BY、その他の SQL ライクなクエリ操作を含む複雑なクエリパターンにも使用しています。これらのデータベースは、ETL ベースの事前集計に適さない大規模データセットのオンザフライ処理に優れています。
一方、2 つ目のアプローチでは、予測可能で事前計算可能なアクセスパターンを持つ機能について、DynamoDB のようなキーバリュー (KV) ストアを使用しています。定期的な ETL プロセスでデータを事前計算することにより、DynamoDB は集計情報への高速で簡素なアクセスを提供し、パフォーマンスとスケーラビリティのバランスを取りながらユーザーに応答性の高い体験を提供します。
トラフィックとエンゲージメントデータを取得するための要件
事前計算データの利用方法を示すために、プラットフォームの UI で表示している、Web サイトのトラフィックとエンゲージメントの経時的な推移という典型的なユースケースを見てみましょう。
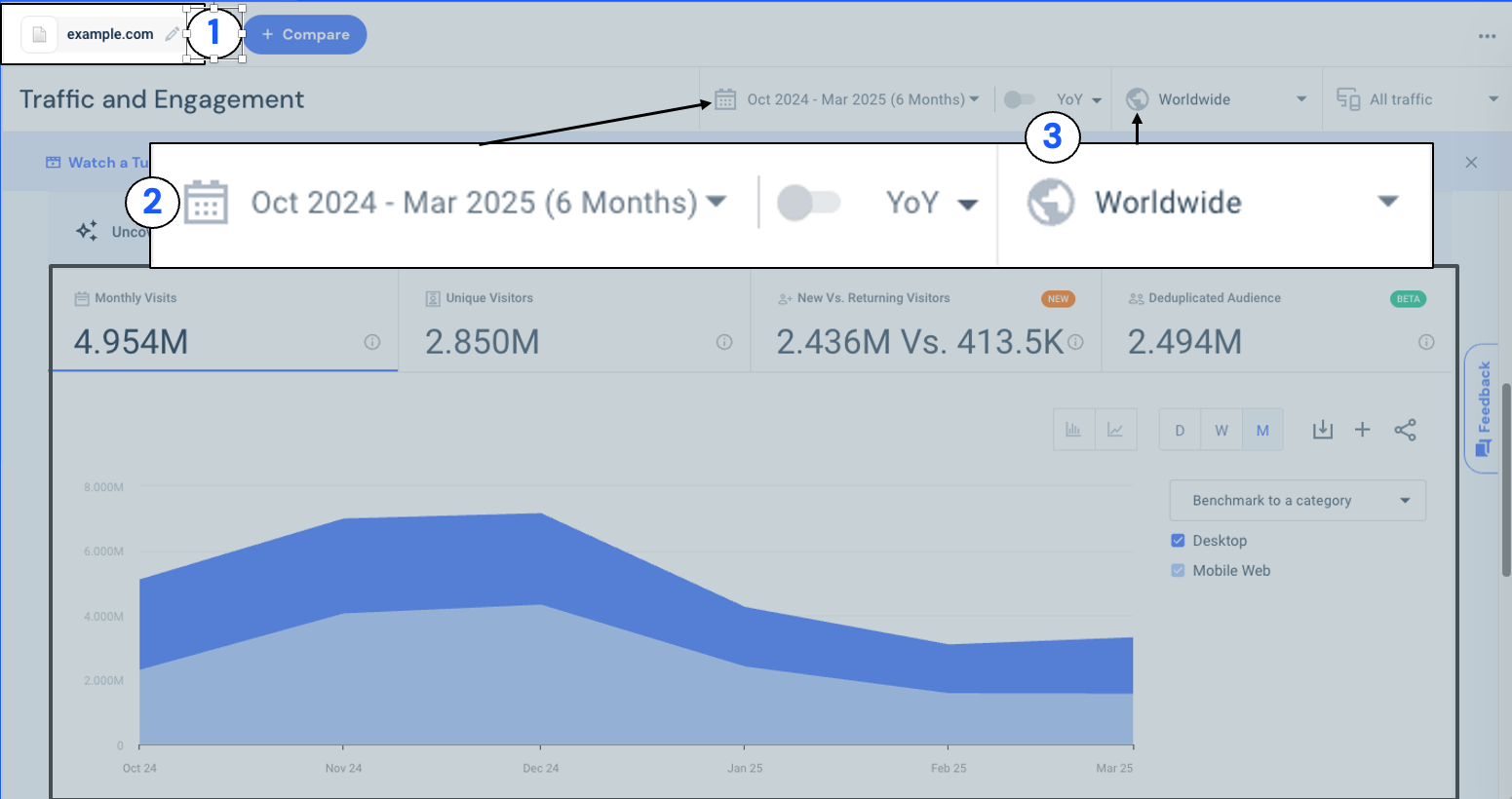
図 1: Similarweb の Traffic and Engagement レポートでは、ユーザーは分析するサイト (1) を選択し、日付範囲 (2) を選び、世界全体または特定の国などの地理的範囲 (3) を設定できます。これらの選択を行うと、グラフには選択した期間における訪問数やユニークユーザーといった主要メトリクスが表示されます。
例えば example.com などの Web サイトの訪問統計を、サイト名、日付、国 (ISO コード)、訪問数といった詳細とともに保存しています。
| Site | Country (ISO) | Date | Visits | TimeOnSite | BounceRate | … |
| example.com | 840 | 2026-01-22 | 7 | 15.2 | 7 | |
| example.com | 840 | 2026-01-23 | 11 | 11.7 | 1 | |
| example.com | 840 | 2026-01-24 | 3 | 20.3 | 4 | |
| example.com | 840 | 2026-01-25 | 12 | 13.2 | 5 | |
| example.com | 840 | 2026-01-26 | 9 | 19.1 | 7 |
アクセスパターンとしては、example.com の特定の日付範囲における全国の訪問データを取得したり、米国 (840) のような特定の国の訪問データをクエリしたりすることが考えられます。このシナリオでは、ETL プロセス中に日付、国、サイトの各組み合わせに対する訪問数を事前に計算して保存することで、これらの一般的なアクセスパターンに対して迅速な応答時間を実現しつつ、クエリ時の計算オーバーヘッドを最小限に抑えることができます。
これらの事前計算されたメトリクスは単純に見えますが、Similarweb の規模では、その背後にある書き込み負荷とクエリの多様性が既存の HBase クラスタを限界まで押し上げました。私たちのケースでは、データは継続的に書き込まれるのではなく、Spark ジョブを使用して日次、週次、月次といったスケジュールされた間隔で大規模なバッチで取り込まれます。
大規模スケールと柔軟なアクセス
Similarweb のトラフィックとエンゲージメントデータセットは膨大で、合計 255 テラバイト (TB) を超えます。データを継続的に取り込むトランザクションアプリケーションとは異なり、私たちの分析パイプラインは大きなバーストで呼吸します。データを新鮮に保つため、1 テーブルあたり約 70 億レコードを、数時間で完了させる必要があるタイトなスケジュールのバッチで取り込んでいます。
しかし、データを書き込むことは戦いの半分にすぎません。保存後、このデータは多様で複雑な読み取りパターンに対して即座に利用可能でなければなりません。ユーザーは単純なキー検索以上のことを行います。彼らは複数の次元でデータを切り分けて、競合をベンチマークし、トレンドを分析します。
次の図は、移行前のハイレベルなデータフローを示しています。
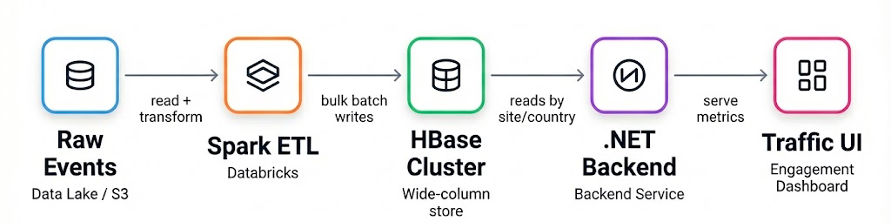
図 2 (移行前): 生のイベントはデータレイクに到達し、Spark ETL が日次集計を計算し、バルク書き込みで結果を HBase に保存します。.NET バックエンドはサイトと国のメトリクスをキー (および日付) で読み取り、Traffic and Engagement UI に提供します。すべての矢印はデータフローを表しています。
単純なキーバリュー検索を超えて
特定のフィルタリングパターンに対して 1 桁ミリ秒の読み取りを提供しながら、大規模な書き込みスパイクに対応できるデータベースソリューションが必要でした。具体的には、任意のサイトに対して以下の 4 つのアクセスパターンをサポートする必要がありました。
- サイトレベルの集計: サイトの全トラフィックを取得。
SELECT * WHERE Site = {site} - 特定の国の内訳: 特定の国にドリルダウン。
SELECT * WHERE Site = {site} AND Country = {country} - 時系列トレンド: 特定の期間の履歴を取得。
SELECT * WHERE Site = {site} AND Date BETWEEN {start} AND {end} - 複雑な組み合わせ: 国と日付範囲の両方でフィルタリング。
SELECT * WHERE Site = {site} AND Country = {country} AND Date BETWEEN {start} AND {end}
これを達成するために、理想的なデータベースは以下の 4 つの厳格な基準を満たす必要がありました。
- 高い書き込みスループット: 数時間で数十億レコードを取り込む。
- 多用途なクエリサポート: テーブル全体をスキャンせずに、前述の次元ベースのクエリを処理。
- パフォーマンスを保ったスケーラビリティ: ピーク書き込み時でも高い読み取りパフォーマンスを維持。
- コストの透明性: 請求書で驚くのではなく、実行前にコストを見積もれる予測可能な料金モデルを提供。
HBase が壁にぶつかった理由
HBase は長年にわたって私たちに役立ってきましたが、Similarweb の規模では、徐々に「使用するデータベース」から「運用するシステム」へと変化していきました。中核的な制限は生の能力ではありませんでした。それは、非常に大規模なバッチ書き込みと常時稼働の読み取りに対する厳しい期待を組み合わせた後に現れた運用リスクと不安定さでした。
1. RegionServer の不安定性がオンコール対応の原因に
繰り返し発生するインシデントの原因は、HBase の RegionServer がクラスタの他の部分と同期しなくなったり、ダウンしたりすることでした。RegionServer がドリフトしたり誤動作したりすると、ホストするリージョンの可用性とレイテンシに影響を与える可能性があります。回復が可能な場合でも、それは不安で時間がかかるものであり、頻繁に発生したため、実質的な運用負担となっていました。
2. ストレージとディスクのアップグレードが悪夢
大規模な HBase 環境におけるディスク管理とアップグレードは、常に非常に摩擦の大きいものでした。分散システムにおけるディスク変更は単独のイベントではありません。それはパフォーマンス、安定性、運用手順に波及します。ルーチンとなるべきインフラ作業がしばしば実質的なリスクを伴う複数ステップのメンテナンスに変わり、特に取り込みウィンドウや読み取り SLA を保護しようとしているときには厳しいものでした。
3. アーキテクチャの利点が私たちのアクセスパターンと一致しなかった
HBase のワイドカラムモデルは、大きな行から列のサブセットを読み取るときに真価を発揮します。私たちの場合、アクセスパターンはしばしばキーに対するメトリクスの完全なセットを読み取ることを必要としていたため、システムの最も強力な設計上の利点を一貫して享受することなく、システムの運用コストを支払っていることになっていました。
4. データベースがピーク向けにサイジングされていたため高コスト
テラバイト規模のバッチロードは短く激しい書き込みピークを生み出す一方で、製品は依然として高速で予測可能な読み取りを必要としていました。ピーク向けにサイジングされた常時稼働クラスタを維持することは、1 日のほとんどで実際に使用していないキャパシティに対して支払うことを意味していました。
これらの課題は単一の壊滅的な障害として現れたわけではありません。それらは累積する運用負荷として現れました。深夜の呼び出しが増え、クラスタの健全性に費やす時間が増え、ルーチンメンテナンスのリスクが増加しました。その複合化するオーバーヘッドが、フルマネージドな代替案を探すことを促しました。
DynamoDB がこれらの課題にどう対処するか
DynamoDB により、以下が可能になりました。
- クリティカルパスからクラスタ運用を排除。 DynamoDB では、リージョンサーバーをプロビジョニングする必要がなく、リバランスもなく、インフラ層でのキャパシティプランニングも手動で行う必要がありません。それにより、データベースの健全性に関連する日常的な運用作業と障害モードの数が直接削減されました。
- 永続的なオーバープロビジョニングなしでバッチ取り込み向けにスケール。 私たちの書き込みパターンは予測可能です。書き込むレコード数と完了までの時間ウィンドウがわかっています。DynamoDB ではキャパシティをダイヤルとして扱うことができます。取り込み実行の直前に プロビジョンド書き込みキャパシティユニット (WCU) を即座にスケールアップし、完了次第すぐにスケールダウンします。これにより、24 時間 365 日大規模なクラスタを稼働させ続けるのではなく、コストをバッチウィンドウに合わせることができました。
- 書き込みスパイク中も読み取りパフォーマンスを安定的に維持。 UI の背後にあるアクセスパターンは、主にキーベースの検索と日付範囲クエリです。DynamoDB のパーティション化されたアーキテクチャと、パーティションキーとソートキー に対する Query 操作 により、テーブルが非常に大きく成長し、取り込みジョブが並列実行されている場合でも、これらの読み取りを一貫して低レイテンシで提供できます。
- コスト動作を明示的かつ予測可能に。 DynamoDB のキャパシティとリクエストパターンが私たちのワークロードにきれいにマップされるため、レコード数、アイテムサイズ、予想されるクエリの形状から書き込みと読み取りのコストを見積もることができます。これにより、コストモデリングは事後的な驚きではなく、設計の一部となりました。
- 耐障害性とディザスタリカバリオプションの改善。 DynamoDB は、すぐに使えるマネージドバックアップとリカバリプリミティブを提供します。マルチリージョンのニーズに対しては、DynamoDB Global Tables でリージョン間でデータをレプリケートできるため、読み取りをローカルで提供でき、リカバリは大規模クラスタを圧力下で再構築することに依存しません。
この基盤が整ったことで、私たちのワークロード固有の部分、つまり高スループットで効率的に取り込む方法と、低コストでアクセスパターンを満たすためのキーモデリングに集中できるようになりました。次の図は、移行後のデータフローを示しています。
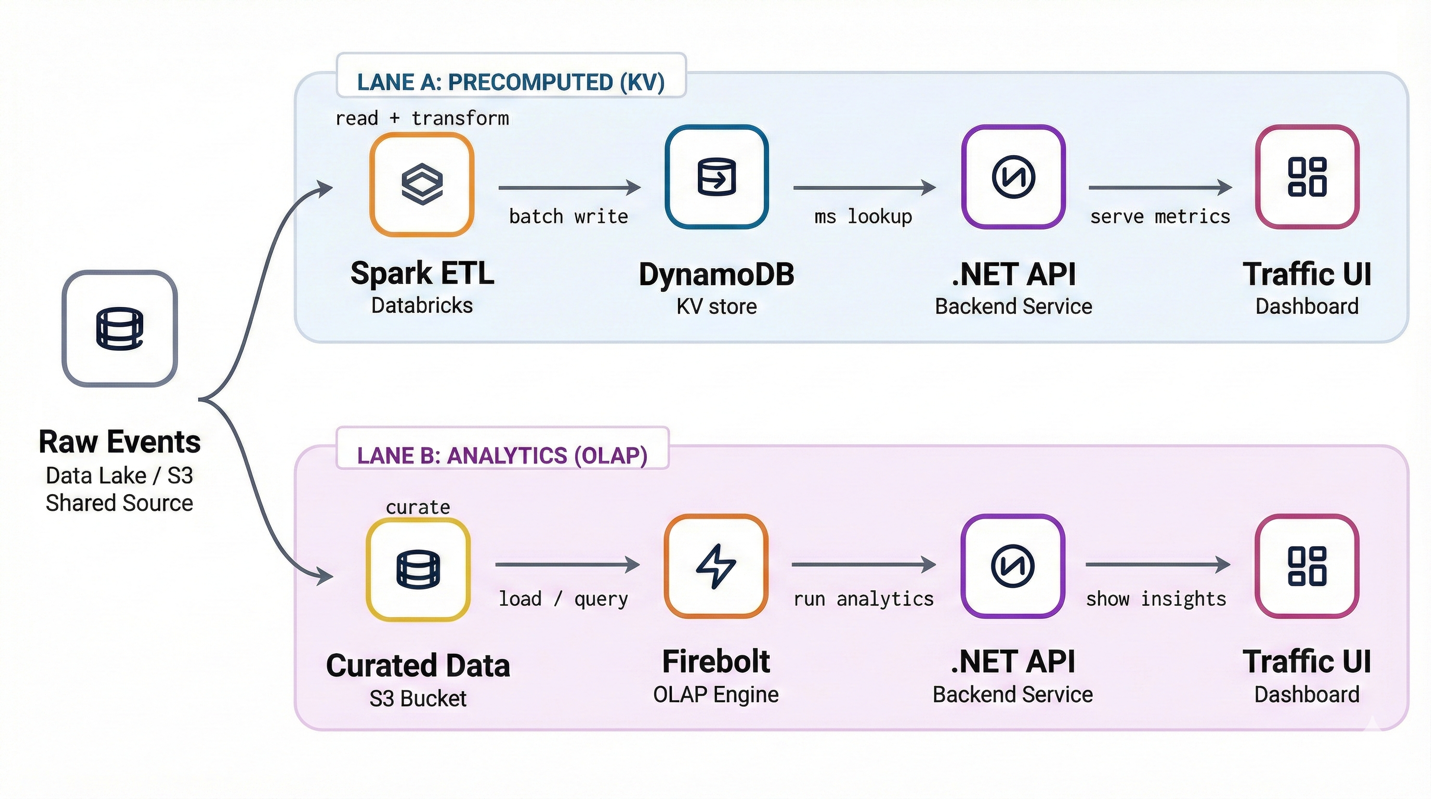
図 3 (移行後): 事前計算されたトラフィックとエンゲージメントメトリクスは、2 つのパスを通じて提供されます。予測可能で低レイテンシのアクセスのための DynamoDB に支えられたキーバリューレーンと、動的でアドホックなクエリのための Firebolt を使用する分析レーンです。.NET バックエンドはそれに応じてリクエストをルーティングします。歴史的に、レーン A は HBase を使用していました。それを DynamoDB に置き換えました。
データモデリング
DynamoDB のパフォーマンスとコストのメリットを最大限に引き出すためには、実際のクエリパターンに基づいてデータモデルを設計することが重要でした。私たちの目標は、応答時間と読み取り/書き込みキャパシティ使用量の両方を最小化する効率的なアクセスパスを作成することでした。
Traffic and Engagement の例を再度見てみましょう。コアアクセスパターンには、日付範囲全体にわたるサイトの訪問データの取得と、オプションで国によるフィルタリングが含まれます。
単純なアプローチ: パーティションキー
最初のアプローチは、次のようなフラットでユニークなパーティションキーを作成することかもしれません。
PK = {site}_{country}_{date}
| Primary key | Visits | TimeOnSite | BounceRate |
| PK | |||
| example.com_840_2026-01-21 | 4 | 24 | 12.31 |
1 か月分のデータ、例えば 2026 年 1 月の米国 (国コード 840) における example.com への訪問を取得するには、31 個の個別のキーを生成し、BatchGetItem リクエストを発行します。
example.com_840_2026-01-01
example.com_840_2026-01-02
...
example.com_840_2026-01-31
この設計は機能しますが、スケールでは非効率でコストがかかります。単一の BatchGetItem リクエスト内では、各アイテムの取得が個別の読み取り操作としてカウントされ、ペイロードサイズが小さくてもアイテムごとに 1 つの読み取りキャパシティユニットを消費します。
最適な設計: パーティションキーとソートキーを持つコンポジットキー
よりスケーラブルなモデルでは、パーティションキーとソートキーを持つコンポジットプライマリキーを使用します。
- パーティションキー (PK):
{site}_{country} - ソートキー (SK):
{date}
| Primary key | Visits | TimeOnSite | BounceRate | |
| PK | SK | |||
| example.com_840 | 2026-01-21 | 4 | 24 | 12.31 |
このセットアップでは、DynamoDB の効率的な Query API を使用して、日付範囲にわたるサイトと国のペアのすべてのレコードをクエリできます。
Query(PK="example.com_840", SK BETWEEN "2026-01-01" AND "2026-01-31")
これにより API コールの数が減り、ソートキーに対する範囲クエリを使用することで読み取りコストが大幅に削減されます。
コスト比較: Query 対 BatchGetItem
サイトと国の組み合わせごとに 500 日分のデータを取得し、各エントリが約 200 バイトであるユースケースを考えてみましょう。
注: RCU はアイテムサイズに応じて 4 KB チャンクでスケールします。結果整合性のある読み取りでは RCU が半分になります。
| アプローチ | 読み取り API | RCU 計算 | 推定コスト |
| フラット PK | BatchGetItem | 500 アイテム × 1 RCU = 500 RCU | $0.065 |
| コンポジット PK + SK | Query | 100 KB / 4 KB = 25 RCU | $0.00325 |
節約: コンポジットキー設計を使用することで 20 倍以上安価。
全世界のユースケース
コンポジットキーモデル (PK = {site}_{country}、SK = {date}) は、サイト、国、日付範囲でフィルタリングされた一般的なクエリを効率的にサポートしますが、全国にわたる訪問データをクエリする必要がある場合に課題が生じます。例えば、example.com の全世界の訪問を、全期間または特定の日付範囲で取得する場合です。
SELECT * WHERE Site = 'example.com'
SELECT * WHERE Site = 'example.com' AND Date BETWEEN '2026-01-01' AND '2026-01-31'
既存のスキーマでは、国コードがパーティションキーに埋め込まれており、これはパーティション間で書き込みと読み取りの負荷を均等に分散するために不可欠です。しかしこれは、データをクエリするには国を知る必要があることも意味し、グローバル集計のユースケースには望ましくありません。
シンプルですが非効率な解決策は、すべての国別パーティションにわたって Query API コールをファンアウトすることです。
# ファンアウト Query: すべての国にわたるサイトの訪問を取得
results = []
for country in country_codes: # ~200 ISO 3166 コード
pk = f"example.com_{country}"
response = query(
TableName='TrafficTable',
KeyConditionExpression="PK = :pk AND SK BETWEEN :start AND :end",
ExpressionAttributeValues={
":pk": pk,
":start": "2026-01-01",
":end": "2026-01-31"
}
)
results.extend(response['Items'])
# 国レベルのレコードを集計して単一の世界規模ビューにする
worldwide = {}
for item in results:
date = item['SK']
visits = item['visits']
worldwide[date] = worldwide.get(date, 0) + visits
# worldwide = {"2026-01-01": 148200, "2026-01-02": 136400, ...}
機能的には正しいものの、このアプローチにはいくつかの欠点があります。
- 高コスト: サイト/日付クエリごとに 200 以上の Query リクエスト。
- 増加したレイテンシ: 200 のクエリにわたって結果をクエリし集計することで、応答時間が大幅に増加する可能性があります。
- BatchQueryItem なし: BatchGetItem とは異なり、複数の Query リクエストを単一の API コールにバッチ処理するネイティブな方法はありません。
- 運用オーバーヘッド: 200 以上の並列クエリの管理は、アプリケーションに負荷をかけ、スロットリングのリスクを増加させる可能性があります。
ファンアウトのコストと複雑さを発生させずに効率的なグローバルクエリをサポートするため、ETL プロセス中に特別な合成国コード (例: 999) を導入しました。実際には、ETL パイプラインの一環として集計された世界規模メトリクスを事前計算して保存し、専用の「グローバル」パーティションに書き込みます。これは、世界規模データに指定されたパーティションキー PK = {site}_999 を使用することで実現します。
| Primary key | Visits | TimeOnSite | BounceRate | |
| PK | SK | |||
| example.com_840 | 2026-01-21 | 4 | 24 | 12.31 |
| example.com_999 | 2026-01-23 | 33 | 17 | 16.5 |
これにより、単一の Query リクエストで世界規模データをクエリできます。
Query(PK="example.com_999", SK BETWEEN "2026-01-01" AND "2026-01-31")
このようにして、読み取り時のパフォーマンスオーバーヘッドがなく、複数ではなく 1 つの Query リクエストを使用するためコストも削減されます。
もちろん、「999」アプローチにもコストがかかります。サイトと日付ごとに追加の世界規模ロールアップを計算する必要があるため ETL の複雑さが増し、サイト国レコードごとに追加のアイテムを永続化するためストレージも増えます。それでも、システムをエンドツーエンドで見ると、明らかな勝利です。読み取り時から書き込み時に作業をシフトし、200 以上のファンアウトクエリの必要性を排除し、アプリケーション側のオーケストレーションを減らし、一貫してより高速な世界規模読み取りを実現します。実際には、追加の ETL とストレージコストはクエリコストとレイテンシの節約によって上回られるため、ソリューション全体としてはより安価で高速になります。
次のセクションでは、初期データ移行と毎月のデータ取り込み中に時間とコストを節約するために、DynamoDB の機能をさらにどのように利用しているかを探ります。
DynamoDB への書き込み
バッチ取り込みは私たちの分析パイプラインの心拍です。継続的なストリームではなく、Databricks 上で日次、週次、月次のスケジュールで ETL Spark ジョブをトリガーするスケジュールされた Apache Airflow Directed Acyclic Graphs (DAGs) に依存しており、それぞれが下流機能の鮮度要件に合わせて調整されています。すべての実行で、テーブルが読み取りトラフィックに対してできるだけ早く準備できるように、短い時間ウィンドウ内に DynamoDB に数十億のアイテム、しばしば数テラバイトをプッシュします。
DynamoDB は、異なるワークロードパターンに対応する 2 つの異なる キャパシティモード を提供しています。オンデマンドモードはサーバーレスで従量課金型のモデルで、トラフィック需要に合わせて自動的にスケールし、キャパシティプランニングは不要で、使用した分のみ支払います。一方、プロビジョンドモードでは、希望する読み取りと書き込みのスループットを事前に指定する必要があり、課金はこのプロビジョンされたキャパシティに基づいて行われます (完全に使用されたかどうかにかかわらず)。私たちのケースでは、書き込むレコードの総数と取り込みの時間ウィンドウが既にわかっているため、必要な書き込みキャパシティユニットを正確に計算して設定できます。これにより、スケジュールされたバッチロードに対しては、プロビジョンドモードのほうがオンデマンドよりも大幅にコスト効率が良くなります。
エンドツーエンドのバッチワークフロー
- Airflow がロードをスケジュール
- DAG パラメータには、テーブル名とソースから読み取る日付範囲が含まれます。
- ジョブはピークの重複を避けるためにずらされます。
- Databricks Spark が ETL を実行
- Spark のパーティションは、並列処理を最大化するために DynamoDB のパーティションキーと整合します。
- DynamoDB Connector for Apache Spark を使用しており、これは書き込みをバッチ化し、指数バックオフによるリトライロジックを処理します。
- キャパシティはジャストインタイムでスケールアップ
- ターゲット DynamoDB テーブルへの最初の書き込みの前に、インフラスクリプトが UpdateTable を呼び出してテーブルのプロビジョンド書き込みキャパシティ、つまり書き込みキャパシティユニット (WCU) を計算されたピークまで引き上げます。スクリプトは、目標期間とレコード数に基づいてこのレベルを自動的に設定します。
- データを並列に書き込み
- DynamoDB Connector for Apache Spark を使用し、プロビジョンドキャパシティに密接に整合したスループットでデータを書き込みます。通常、プロビジョンド書き込みキャパシティの約 1.1 倍を目標とし、リソースを十分に活用しつつ最適な利用率を達成するため、制御されたレベルのスロットリングを受け入れます。
- キャパシティは自動的にスケールバックダウン
- ETL がすべてのレコードの書き込みを終えると、UpdateTable を再度呼び出してプロビジョンドキャパシティ書き込みレベルを下げる後続タスクをスケジュールします。
def run_etl(table_name, records_count, target_duration_hours=1):
# ステップ 3 -- キャパシティをジャストインタイムで計算してスケールアップ
desired_wcu = ceil(records_count / (target_duration_hours * 3600))
desired_wcu = clamp(desired_wcu, MIN_WCU, MAX_WCU)
wait_until_table_is_active(table_name)
current_wcu = describe_table(table_name).provisioned_write_capacity
update_table(table_name, wcu=current_wcu + desired_wcu) # UpdateTable API
wait_until_table_is_active(table_name)
try:
# ステップ 4 -- Spark DynamoDB Connector を介してデータを並列に書き込み
spark.write(target_table=table_name,
write_throughput_ratio=1.1) # プロビジョンド WCU の約 110%
finally:
# ステップ 5 -- キャパシティを自動的にスケールバックダウン
update_table(table_name, wcu=current_wcu) # UpdateTable API
wait_until_table_is_active(table_name)
DynamoDB テーブルのプロビジョンドキャパシティを計算してスケールアップする Python 疑似コード
Amazon Simple Storage Service (Amazon S3) からの Import Table を使用する
DynamoDB への書き込みの時間とコストをさらに削減するため、HBase からの移行時および一部の定期的な書き込みに、DynamoDB Import from S3 機能を使用して、Amazon Simple Storage Service (Amazon S3) から直接データをインポートしました。これにより、レコードごとの書き込みが不要になり、取り込み時に書き込みキャパシティユニットを消費することがなくなります。
メリット
- バルク取り込みで最大 90% のコスト削減。
- ETL 取り込みのための Databricks コンピューティング使用が不要。
- ネイティブインポートによってリトライロジックが隠蔽され、運用オーバーヘッドが取り除かれた簡素化された運用。
- 従来の Spark ジョブと比較してより高速な取り込み。
Import Table 機能は、アイテムごとの書き込み操作ではなく、取り込まれたデータの総量に基づいて課金されるため、特に私たちのケースのように小さなアイテムを持つ大きなテーブルを移行する場合、大幅なコスト削減を実現します。
S3 からのインポートワークフロー
- ETL 前の自動化の一環として、データは指定された S3 パスから読み取られ、Import from S3 機能でサポートされている DYNAMODB_JSON 形式に変換されます。
- 整形されたデータの S3 パスとテーブル定義を指定して ImportTable API を呼び出します。
- モニタリングタスクがインポート完了まで進捗を追跡します。
期間ごとに別々のテーブルにデータを保存するタイミング
DynamoDB の Import from S3 機能は、大規模なバックフィルにとってゲームチェンジャーですが、重要な制約があります。新しいテーブルにのみインポートできるという点です。その制限は、データセットが自然に時間でパーティション化されており、主に最近の期間でアクセスされる場合には機会となります。
月次のデータセットでは、意図的な設計を採用しました。月ごとに 1 つのテーブルを作成し、Import from S3 を使用してその月のデータをインポートし、データが古くなるにつれてそれらのテーブルのライフサイクルを管理します。
月次データに適している理由
このアプローチが特に月次ワークロードに適している理由は以下のとおりです。
- バルクロードが離散的: 各月のデータセットは通常完全なバッチとして生成されるため、インポートのクリーンな単位になります。
- クエリ時の運用の簡素さ: アプリケーションは、コールドデータとホットデータを 1 つの大きなテーブルで混在させる代わりに、関連する期間テーブルにクエリをルーティングできます。
- 保存期間管理が簡単に: 古いアイテムを削除する代わりに、期限切れになったテーブル全体を削除できます。
- コスト最適化が容易: 古い月次テーブルは、アプリケーションロジックを変更することなく、年齢を重ねるにつれて Standard-IA テーブルクラス に移行でき、ストレージコストを削減できます。
実用的な命名規則によって自動化が容易になります。例: {table_name}_2026-01。
エンドツーエンドの実行方法
- 各月について、データセットを生成し、サポートされているインポート形式の 1 つである DynamoDB JSON に変換し、新しい月次テーブルに ImportTable を実行します。
- インポート後、不要になったテーブルを削除する保存期間ポリシーを適用します。
- 古くなった月次テーブルを Table Class Standard-IA に移行してストレージコストを節約します。
- 要求された日付範囲が複数の月にまたがる場合、API は関連する月次テーブルにわたってクエリをファンアウトし、結果をマージします。
期間ベースのテーブルを使用すべきでない場合
このパターンは強力ですが、万能ではありません。
日次のデータセットの場合、1 日ごとにテーブルを作成するとテーブル数が爆発し、不必要な運用オーバーヘッドが発生します。そのような場合は、単一の長期間有効なテーブルを維持し、標準的な取り込みパス (Spark 書き込み + プロビジョンドキャパシティスケーリング) を続けるほうが良いです。
経験則
- 期間が粗い (月次以上) で、データがバルクでロードされ、保存期間がテーブルレベルで強制できる場合は、期間ごとに別々のテーブルを優先してください。
- 期間が細かすぎる (日次) 場合、または同じ物理テーブルへの継続的な増分書き込みが必要な場合は、単一のテーブルを優先してください。
結論
本記事では、Similarweb が Apache HBase から DynamoDB に移行した経緯を紹介しました。この移行は、運用を簡素化し、効率的にスケールし、インフラオーバーヘッドを削減しながら、大規模に高速で信頼性の高いインサイトを提供し続ける必要性によって推進されました。
レガシーの HBase セットアップは強力ではありましたが、増大するバッチ取り込みワークフローと動的クエリ要件のニーズに応えるのに苦労していました。安定性、運用メンテナンス、スケーリングの限界などの課題が、よりモダンなサーバーレスの代替案を求めるきっかけになりました。
DynamoDB を採用することで、以下を達成しました。
- インテリジェントな書き込みプロビジョニングを伴う ETL ジョブを使用した高パフォーマンスなバッチ取り込み。
- 大規模で多様なクエリパターンをサポートする柔軟でコスト効率の高いデータモデリング。
- フルマネージドでサーバーレスな DynamoDB アーキテクチャによる運用負担の削減。
- Amazon S3 から直接インポートすることによる低い運用負担と高速な履歴データ移行。
- 手動のクラスタ管理なしでのシステム信頼性とスケーラビリティの向上。
この移行は、データインフラのパフォーマンスと安定性を向上させ、エンジニアリングチームが機能の構築とイノベーションの推進に集中できるようにしました。DynamoDB は、私たちの分析パイプラインの強靭でコスト効率の高い基盤であることが証明されており、Similarweb がお客様にタイムリーで実行可能なデジタルインサイトを提供するというミッションを支えています。
本記事は 2026 年 06 月 16 日 に公開された “Similarweb’s migration from HBase to Amazon DynamoDB” を翻訳したものです。
原文: https://aws.amazon.com/blogs/database/similarwebs-migration-from-hbase-to-amazon-dynamodb/
著者について
 |
Idan LahavIdan はテルアビブを拠点とする Similarweb の R&D ディレクターです。バックエンドインフラ、プラットフォーム基盤、データエンジニアリングに深い専門知識を持ち、スケーラブルなデータパイプラインアーキテクチャの設計と、高スループットプラットフォームの複雑な課題の解決に注力しています。最近の HBase から DynamoDB への移行において、Idan は移行を可能にした基盤となるインフラ基盤の設計と管理を担当しました。 |
 |
Leonid KorenLeonid は AWS のプリンシパル NoSQL ソリューションアーキテクトで、お客様が NoSQL データベースを使用して既存のアプリケーションをモダナイズし、新しいアプリケーションを設計するのを支援しています。AWS に入社する前は、2000 年代初頭からバックエンドシステムの設計と開発を行ってきました。 |