Amazon Web Services ブログ
LangGraph と Amazon DynamoDB で耐久性のある AI エージェントを構築する
本記事は 2026 年 01 月 13 日 に公開された “Build durable AI agents with LangGraph and Amazon DynamoDB” を翻訳したものです。
原文: https://aws.amazon.com/blogs/database/build-durable-ai-agents-with-langgraph-and-amazon-dynamodb/
私は AI エージェントの急速な進化に魅了されてきました。過去 1 年間で、AI エージェントがシンプルなチャットボットから、複雑な問題を推論し、意思決定を行い、長い会話全体でコンテキストを維持できる洗練されたシステムへと成長するのを見てきました。しかし、エージェントの性能はメモリの質次第です。
この記事では、Amazon DynamoDB と LangGraph を使用し、新しい DynamoDBSaver コネクタを活用して、耐久性のある状態管理を備えた本番環境対応の AI エージェントを構築する方法を紹介します。DynamoDBSaver は、AWS が Amazon DynamoDB 向けに保守している LangGraph チェックポイントライブラリです。これは、DynamoDB と LangGraph 専用に構築された本番環境対応の永続化レイヤーを提供し、ペイロードのサイズに基づいてインテリジェントに処理しながらエージェントの状態を保存します。
この実装により、エージェントがスケールし、障害から回復し、長時間実行されるワークフローを維持するために必要な永続性を得る方法を学びます。
Amazon DynamoDB の概要
Amazon DynamoDB は、あらゆる規模で 1 桁ミリ秒のパフォーマンスを実現する、サーバーレスでフルマネージドな分散 NoSQL データベースです。構造化データまたは半構造化データを保存し、一貫したミリ秒単位のレイテンシーでクエリを実行し、サーバーやインフラストラクチャを管理することなく自動的にスケールできます。DynamoDB は低レイテンシーと高可用性を実現するように構築されているため、セッションデータ、ユーザープロファイル、メタデータ、またはアプリケーションの状態を保存するためによく使用されます。これらの同じ特性により、AI エージェントのチェックポイントとスレッドメタデータを保存するための理想的な選択肢となっています。
LangGraph の紹介
LangGraph は、複雑なグラフベースの AI ワークフローを構築するために設計された LangChain のオープンソースフレームワークです。プロンプトと関数を一直線に連鎖させる代わりに、LangGraph では分岐、マージ、ループが可能なノードを定義できます。各ノードはタスクを実行し、エッジがノード間のフローを制御します。
LangGraph はいくつかの重要な概念を導入しています:
- スレッド (Threads): スレッドは、一連の実行の累積状態を含む各チェックポイントに割り当てられる一意の識別子です。グラフが実行されると、その状態はスレッドに永続化されます。これには、config で thread_id を指定する必要があります (
{"configurable": {"thread_id": "1"}})。状態を永続化するには、実行前にスレッドを作成する必要があります。 - チェックポイント (Checkpoints): チェックポイントは、各スーパーステップで保存されるグラフ状態のスナップショットで、config、メタデータ、状態チャネル値、実行する次のノード、タスク情報 (エラーや中断データを含む) を含む StateSnapshot オブジェクトで表されます。チェックポイントは永続化され、後でスレッドの状態を復元できます。たとえば、シンプルな 2 ノードグラフは 4 つのチェックポイントを作成します:
STARTでの空のチェックポイント、node_a の前のユーザー入力を含むもの、node_b の前の node_a の出力を含むもの、そしてENDでの node_b の出力を含む最終的なものです。 - 永続性 (Persistence): 永続性は、チェックポインタの実装を使用して、チェックポイントがどこにどのように保存されるか (メモリ内、データベース、外部ストレージなど) を決定します。チェックポインタは各スーパーステップでスレッドの状態を保存し、履歴状態の取得を可能にし、グラフがチェックポイントから再開したり、以前の実行状態を復元したりできるようにします。
永続性により、ヒューマン・イン・ザ・ループレビュー、リプレイ、障害後の再開、状態間のタイムトラベルなどの高度な機能が可能になります。
InMemorySaver は、LangGraph の組み込みチェックポイントメカニズムで、会話の状態とグラフ実行履歴をメモリに保存し、永続性、タイムトラベルデバッグ、ヒューマン・イン・ザ・ループワークフローなどの機能を有効にします。InMemorySaver は高速なプロトタイピングに使用できますが、状態はメモリ内にのみ存在し、アプリケーションの再起動時に失われます。
次の図は、LangGraph のチェックポイントアーキテクチャを示しています。高レベルのワークフロー (スーパーステップ) が START から END までノードを通じて実行される一方で、チェックポインタが継続的に状態スナップショットをメモリ (InMemorySaver) に保存します:
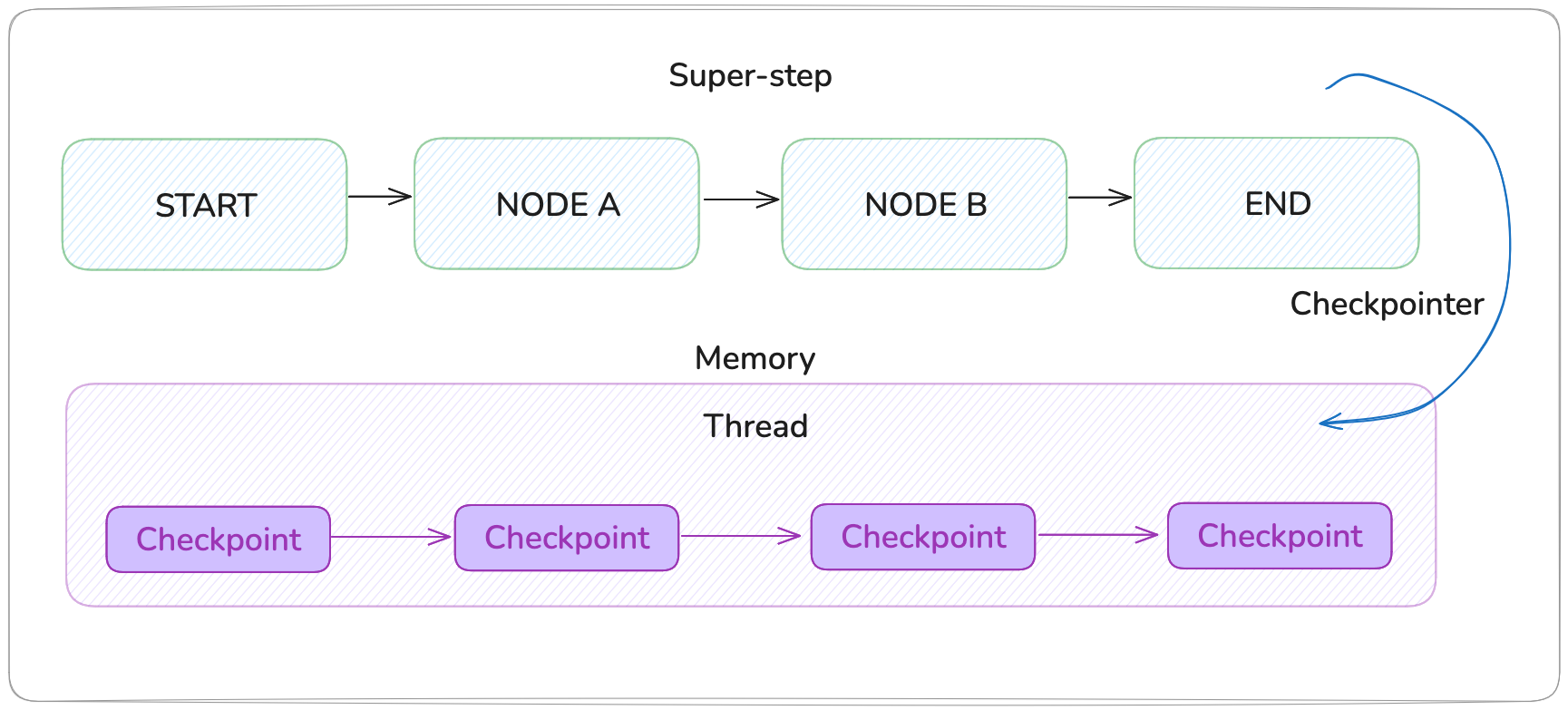
永続性が重要な理由
デフォルトでは、LangGraph は InMemorySaver を使用してチェックポイントをメモリに保存します。これはセットアップが不要で、即座に読み書きアクセスが可能なため、実験には最適です。
しかし、メモリ内ストレージには 2 つの大きな制限があります。それは一時的でローカルであることです。プロセスが停止すると、データは失われます。複数のワーカーを実行する場合、各インスタンスは独自のメモリを保持します。他の場所で開始されたセッションを再開することはできず、ワークフローが途中でクラッシュした場合に回復することもできません。
本番環境では、これは受け入れられません。エージェントが中断した場所から再開し、ノード間でスケールし、分析や監査のために履歴を保持できる、永続的でフォールトトレラントなストアが必要です。そこで DynamoDBSaver の出番です。
複雑な複数ステップの問い合わせを処理するカスタマーサポートエージェントを構築しているシナリオを想像してください。顧客が注文について尋ね、エージェントが情報を取得し、応答を生成し、応答を送信する前に人間の承認を待ちます。
しかし、次のような場合はどうなるでしょうか:
- ワークフローの途中でサーバーがタイムアウトした場合
- 複数のワーカーにスケールする必要がある場合
- 顧客が数時間後に戻って会話を続ける場合
- エージェントの意思決定プロセスを監査したい場合
メモリ内ストレージでは、お手上げです。プロセスが停止した瞬間に、すべてが消えてしまいます。各ワーカーは独自の分離された状態を維持します。再開、リプレイ、または何が起こったかを確認する方法はありません。
DynamoDBSaver の紹介
langgraph-checkpoint-aws ライブラリは、AWS 専用に構築された永続化レイヤーを提供します。DynamoDBSaver は、軽量なチェックポイントメタデータを DynamoDB に保存し、大きなペイロードには Amazon S3 を使用します。
仕組みは次のとおりです:
- 小さなチェックポイント (< 350 KB):
thread_id、checkpoint_id、タイムスタンプ、状態などのメタデータを含むシリアル化されたアイテムとして DynamoDB に直接保存されます - 大きなチェックポイント (≥ 350 KB): 状態は S3 にアップロードされ、DynamoDB は S3 オブジェクトへの参照ポインタを保存します
- 取得: 再開時、セーバーは DynamoDB からメタデータを取得し、S3 から大きなペイロードを透過的にロードします
この設計により、DynamoDB のアイテムサイズ制限に達することなく、小さな状態と大きな状態の両方を効率的に処理しながら、耐久性とスケーラビリティを提供します。
DynamoDBSaver には、コストとデータライフサイクルの管理に役立つ組み込み機能が含まれています:
- Time-to-Live (
ttl_seconds) により、指定された間隔でチェックポイントの自動有効期限が有効になります。古いスレッドの状態は手動介入なしでクリーンアップされ、一時的なワークフロー、テスト環境、または特定の期間を超えた履歴状態に価値がないアプリケーションに最適です。 - 圧縮 (
enable_checkpoint_compression) は、状態データをシリアル化および圧縮することで、保存前にチェックポイントのサイズを削減し、取得時に完全な状態の忠実性を維持しながら、DynamoDB の書き込みコストと S3 ストレージコストの両方を削減します。
これらの機能を組み合わせることで、永続化レイヤーの運用コストとストレージフットプリントをきめ細かく制御でき、アプリケーションのスケールに応じて耐久性要件と予算制約のバランスを取ることができます。
はじめに
実行間でエージェントの状態を永続化し、履歴チェックポイントを取得する方法を示す実用的な例を構築しましょう。
前提条件
開始する前に、必要な AWS リソースをセットアップする必要があります:
- DynamoDB テーブル:
DynamoDBSaverは、チェックポイントメタデータを保存するためのテーブルが必要です。テーブルには、PK (文字列) という名前のパーティションキーと SK (文字列) という名前のソートキーが必要です。 - S3 バケット (オプション): チェックポイントが 350 KB を超える可能性がある場合は、大きなペイロードストレージ用の S3 バケットを提供します。セーバーは、オーバーサイズの状態を自動的に S3 にルーティングし、DynamoDB に参照を保存します。
AWS Cloud Development Kit (AWS CDK) を使用して、これらのリソースを定義できます:
const table = new dynamodb.Table(this, 'CheckpointTable', {
tableName: 'my_langgraph_checkpoints_table',
partitionKey: { name: 'PK', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'SK', type: dynamodb.AttributeType.STRING },
timeToLiveAttribute: 'ttl',
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const bucket = new s3.Bucket(this, 'CheckpointBucket', {
bucketName: 'amzn-s3-demo-bucket',
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: cdk.RemovalPolicy.DESTROY
});
アプリケーションが DynamoDBSaver を LangGraph チェックポイントストレージとして使用するには、次の AWS Identity and Access Management (AWS IAM) 権限が必要です:
DynamoDB テーブルアクセス:
dynamodb:GetItem– 個別のチェックポイントを取得dynamodb:PutItem– 新しいチェックポイントを保存dynamodb:Query– スレッド ID でチェックポイントを検索dynamodb:BatchGetItem– 複数のチェックポイントを効率的に取得dynamodb:BatchWriteItem– 単一の操作で複数のチェックポイントを保存
S3 オブジェクト操作 (350KB を超えるチェックポイントの場合):
s3:PutObject– チェックポイントデータをアップロードs3:GetObject– チェックポイントデータを取得s3:DeleteObject– 期限切れのチェックポイントを削除s3:PutObjectTagging– ライフサイクル管理のためにオブジェクトにタグを付ける
S3 バケット設定:
s3:GetBucketLifecycleConfiguration– ライフサイクルルールを読み取るs3:PutBucketLifecycleConfiguration– 自動データ有効期限を設定
インストール
pip を使用して LangGraph と AWS チェックポイントストレージライブラリをインストールします:
pip install langgraph langgraph-checkpoint-aws
基本設定
大きなチェックポイント用のオプションの S3 バケットとテーブルを使用して、DynamoDB チェックポイントセーバーを設定します:
from langgraph.graph import StateGraph, END
from langgraph_checkpoint_aws import DynamoDBSaver
from typing import TypedDict, Annotatedimport operator
# 状態を定義
class State(TypedDict):
foo: str
bar: Annotated[list[str], add]
# DynamoDB 永続性を設定
checkpointer = DynamoDBSaver(
table_name="my_langgraph_checkpoints_table",
region_name="us-east-1",
ttl_seconds=86400 * 30, # 30 日
enable_checkpoint_compression=True,
s3_offload_config={
"bucket_name": "amzn-s3-demo-bucket",
}
)
ワークフローの構築
グラフを作成し、チェックポインタでコンパイルして、呼び出し間で永続的な状態を有効にします:
# セッション用の thread_id
THREAD_ID = "99"
workflow = StateGraph(State)
workflow.add_node(node_a)
workflow.add_node(node_b)
workflow.add_edge(START, "node_a")
workflow.add_edge("node_a", "node_b")
workflow.add_edge("node_b", END)
graph = workflow.compile(checkpointer=checkpointer)
config: RunnableConfig = {"configurable": {"thread_id": THREAD_ID}}
graph.invoke({"foo": "", "bar": []}, config)
状態の取得
現在の状態を取得するか、タイムトラベルデバッグのために以前のチェックポイントにアクセスします:
# 最新の状態スナップショットを取得
config = {"configurable": {"thread_id": THREAD_ID}}
latest_checkpoint = graph.get_state(config)
print(latest_checkpoint)
# 特定の checkpoint_id の状態スナップショットを取得
checkpoint_id = latest_checkpoint.config.get("configurable", {}).get("checkpoint_id")
config = {"configurable": {"thread_id": THREAD_ID, "checkpoint_id": checkpoint_id}}
specific_checkpoint = graph.get_state(config)
print(specific_checkpoint)
実際のユースケース
1. ヒューマン・イン・ザ・ループレビュー
機密性の高い操作 (金融取引、法的文書、医療アドバイス) の場合、人間の監視のためにワークフローを一時停止できます:
# エージェントが応答を生成
workflow.invoke({"query": "Approve my loan"}, config)
# 人間が別のプロセス/UI でレビュー
# チェックポイントは DynamoDB に安全に保存される
# 承認後、再開
workflow.invoke({"approved": True}, config)
2. 障害回復
本番システムでは、障害が発生します。ネットワークの中断、API のタイムアウト、または一時的なエラーにより、実行が途中で停止する可能性があります。
メモリ内チェックポイントでは、進行状況が失われます。DynamoDBSaver を使用すると、ワークフローは最後に成功したチェックポイントをクエリし、そこから再開できます。これにより、再計算が削減され、回復が高速化され、信頼性が向上します。
try:
workflow.invoke({"input": "complex query"}, config)
except Exception as e:
# エラーをログに記録し、運用チームに警告
pass
# 後で、最後に成功したチェックポイントから再試行
# 完了したステップを再実行する必要はない
workflow.invoke({}, config)
3. 長時間実行される会話
一部のワークフローは数時間または数日にわたります。DynamoDB の耐久性により、会話が確実に永続化されます:
# 1 日目: 顧客が問い合わせを開始
workflow.invoke({"messages": ["I need help"]}, config)
# 2 日目: 顧客がさらに情報を提供
workflow.invoke({"messages": ["Here's my account number"]}, config)
# 3 日目: エージェントがタスクを完了
workflow.invoke({"action": "resolve"}, config)
プロトタイプから本番環境への移行は、チェックポインタを変更するだけで簡単です。MemorySaver を DynamoDBSaver に置き換えて、永続的でスケーラブルな状態管理を実現します:
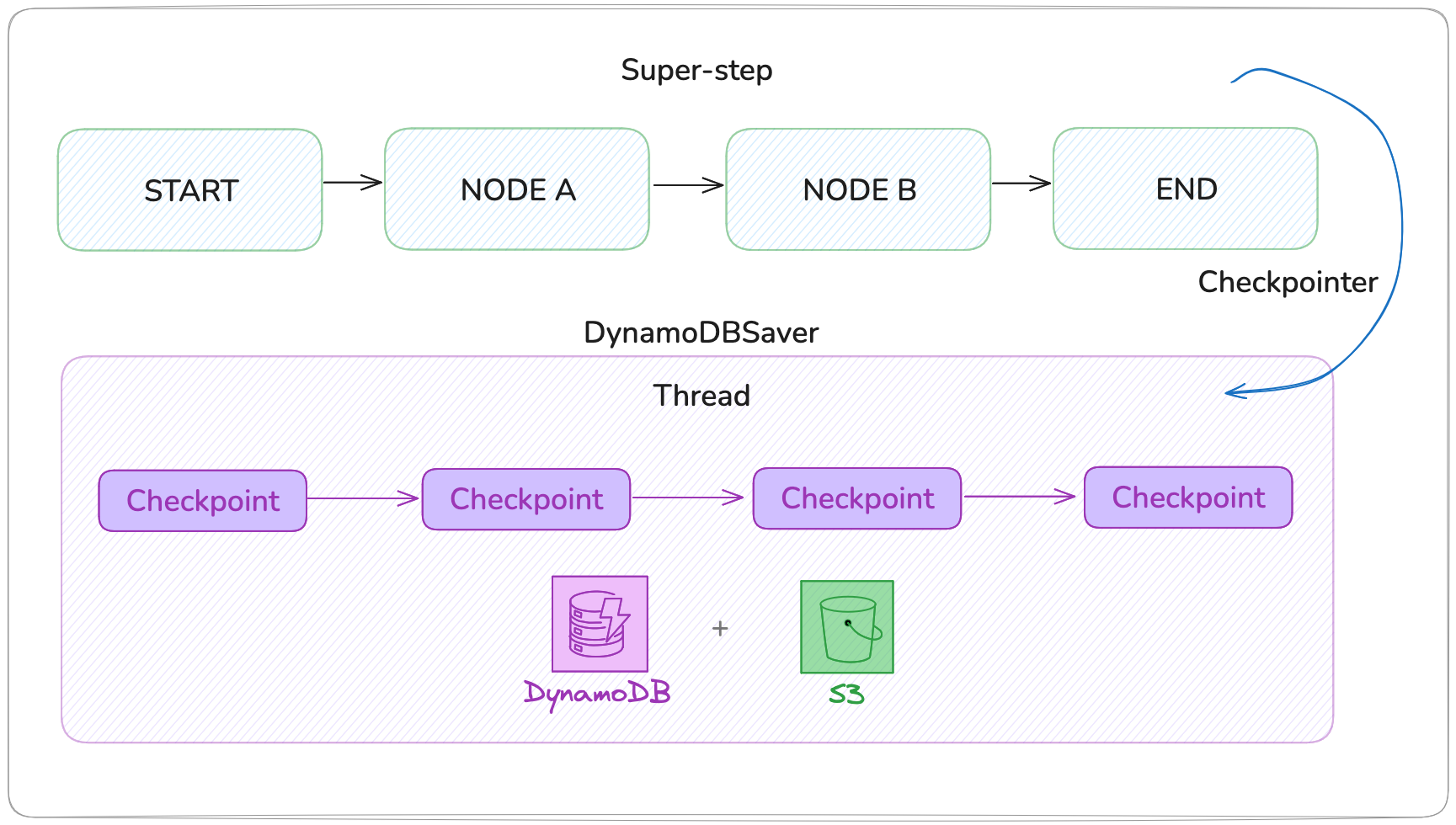
クリーンアップ
継続的な料金の発生を避けるために、作成したリソースを削除します:
AWS CDK を使用してデプロイした場合は、次のコマンドを実行します:
cdk destroy
CLI を使用した場合は、次のコマンドを実行します:
- DynamoDB テーブルを削除:
aws dynamodb delete-table --table-name my_langgraph_checkpoints_table
- Amazon S3 バケットを空にして削除:
aws s3 rm s3://amzn-s3-demo-bucket --recursive
aws s3 rb s3://amzn-s3-demo-bucket
まとめ
LangGraph を使用すると、インテリジェントでステートフルなエージェントを簡単に構築できます。DynamoDBSaver により、本番環境で安全に実行できます。
DynamoDBSaver を LangGraph アプリケーションに統合することで、耐久性、スケーラビリティ、および特定の時点から複雑なワークフローを再開する能力を得ることができます。人間の監視を伴うシステムを構築し、長時間実行されるセッションを維持し、中断から適切に回復できます。
今すぐ始めましょう
プロトタイピング中はメモリ内チェックポイントから始めてください。本番環境に移行する準備ができたら、DynamoDBSaver に切り替えて、エージェントが記憶し、回復し、自信を持ってスケールできるようにします。pip install langgraph-checkpoint-aws でライブラリをインストールします。
利用可能な設定オプションを確認するには、langgraph-checkpoint-aws ドキュメント で DynamoDBSaver の詳細をご覧ください。
本番ワークロードの場合は、Amazon Bedrock AgentCore Runtime を使用して LangGraph エージェントをホストすることを検討してください。AgentCore は、スケーリング、モニタリング、インフラストラクチャ管理を処理するフルマネージドランタイム環境を提供し、AWS が運用の複雑さを管理する間、エージェントロジックの構築に集中できます。
著者について

Lee Hannigan
Lee は、アイルランドのドニゴールを拠点とする Sr. DynamoDB Database Engineer です。彼は、ビッグデータと分析技術の強固な基盤を持つ、分散システムにおける豊富な専門知識をもたらします。彼の役割では、Lee は DynamoDB のパフォーマンス、スケーラビリティ、信頼性の向上に焦点を当てながら、顧客と社内チームがその機能を最大限に活用できるよう支援しています。