Amazon Web Services ブログ
Amazon Redshift Serverless のキューベース QMR できめ細かなリソース制御を実現する
本記事は 2026 年 1 月 15 日 に公開された「Unlock granular resource control with queue-based QMR in Amazon Redshift Serverless」を翻訳したものです。
Amazon Redshift Serverless は、データウェアハウス運用からインフラストラクチャ管理と手動スケーリングの要件を取り除きます。Amazon Redshift Serverless のキューベースクエリリソース管理は、クエリを専用キューに分離し、高負荷のクエリが他のユーザーに影響を与えることを防ぐ自動ルールを使用することで、重要なワークロードを保護し、コストを制御するのに役立ちます。さまざまなワークロードに対してカスタマイズされた監視ルールを持つ専用クエリキューを作成でき、リソース使用量をきめ細かく制御できます。キューを使用すると、メトリクスベースの述語と自動応答を定義でき、時間制限を超えたり過剰なリソースを消費したりするクエリを自動的に中止するなどの対応が可能です。
さまざまな分析ワークロードには、それぞれ異なる要件があります。マーケティングダッシュボードには、一貫した高速な応答時間が必要です。データサイエンスワークロードでは、複雑でリソース集約的なクエリを実行する場合があります。抽出、変換、ロード (ETL) プロセスでは、オフピーク時に長時間の変換を実行する場合があります。
組織がより多くのユーザー、チーム、ワークロードにわたって分析の使用を拡大するにつれて、共有環境で一貫したパフォーマンスとコスト管理を確保することがますます困難になっていきます。最適化が不十分な単一のクエリが過度のリソースを消費し、ビジネスクリティカルなダッシュボード、ETL ジョブ、経営層向けレポートのパフォーマンスを低下させる可能性があります。Amazon Redshift Serverless のキューベース Query Monitoring Rules (QMR) を使用すると、管理者はキューレベルでワークロードに応じたしきい値と自動アクションを定義できます。これは、以前のワークグループレベルの監視からの大幅な改善です。BI レポート、アドホック分析、データエンジニアリングなどの異なるワークロード用に専用キューを作成し、キュー固有のルールを適用して、実行時間またはリソース消費制限を超えるクエリを自動的に中止、ログ記録、または制限できます。ワークロードを分離し、ターゲットを絞った制御を実施することで、このアプローチはミッションクリティカルなクエリを保護し、パフォーマンスの予測可能性を向上させ、リソースの独占を防ぎます。これらすべてを、サーバーレスエクスペリエンスの柔軟性を維持しながら実現します。
この記事では、Redshift Serverless でクエリキューを使用してワークロードを実装する方法について説明します。
キューベース監視とワークグループレベル監視の比較
クエリキューが導入される前は、Redshift Serverless はワークグループレベルでのみクエリ監視ルール (QMR) を提供していました。これは、目的やユーザーに関係なく、すべてのクエリが同じ監視ルールの対象となることを意味していました。
キューベース監視は、大きな進化をしています。
- きめ細かな制御 – さまざまなワークロードタイプ用に専用キューを作成できます
- ロールベースの割り当て – ユーザーロールとクエリグループに基づいて、クエリを特定のキューに振り向けることができます
- 独立した動作 – 各キューは独自の監視ルールを維持します
ソリューション概要
以下のセクションでは、一般的な組織が Redshift Serverless でクエリキューを実装する方法を検討します。
アーキテクチャコンポーネント
ワークグループ設定
- クエリキューが定義される基本単位
- キュー定義、ユーザーロールマッピング、監視ルールが含まれます
キュー構造
- 単一のワークグループ内で動作する複数の独立したキュー
- 各キューには独自のリソース割り当てパラメータと監視ルールがあります
ユーザー/ロールマッピング
- 以下に基づいて、クエリを適切なキューに振り向けます。
- ユーザーロール (例: analyst、etl_role、admin)
- クエリグループ (例: reporting、group_etl_inbound)
- 柔軟なマッチングのためのクエリグループワイルドカード
Query Monitoring Rules (QMR)
- 実行時間やリソース使用量などのメトリクスのしきい値を定義します
- しきい値を超えた場合の自動アクション (中止、ログ記録) を指定します
前提条件
Amazon Redshift Serverless でクエリキューを実装するには、以下の前提条件が必要です。
Redshift Serverless 環境:
- アクティブな Amazon Redshift Serverless ワークグループ
- 関連付けられた名前空間
アクセス要件:
- Redshift Serverless 権限を持つ AWS Management Console アクセス
- AWS CLI アクセス (コマンドライン実装の場合はオプション)
- ワークグループの管理データベース認証情報
必要な権限:
- Redshift Serverless 操作の IAM 権限 (CreateWorkgroup、UpdateWorkgroup)
- データベースユーザーとロールを作成および管理する機能
ワークロードタイプの特定
まず、ワークロードを分類することから始めます。一般的なパターンには以下が含まれます。
- インタラクティブ分析 – 高速な応答時間を必要とするダッシュボードとレポート
- データサイエンス – 複雑でリソース集約的な探索的分析
- ETL/ELT – より長い実行時間を持つバッチ処理
- 管理 – 特別な権限を必要とするメンテナンス操作
キュー設定の定義
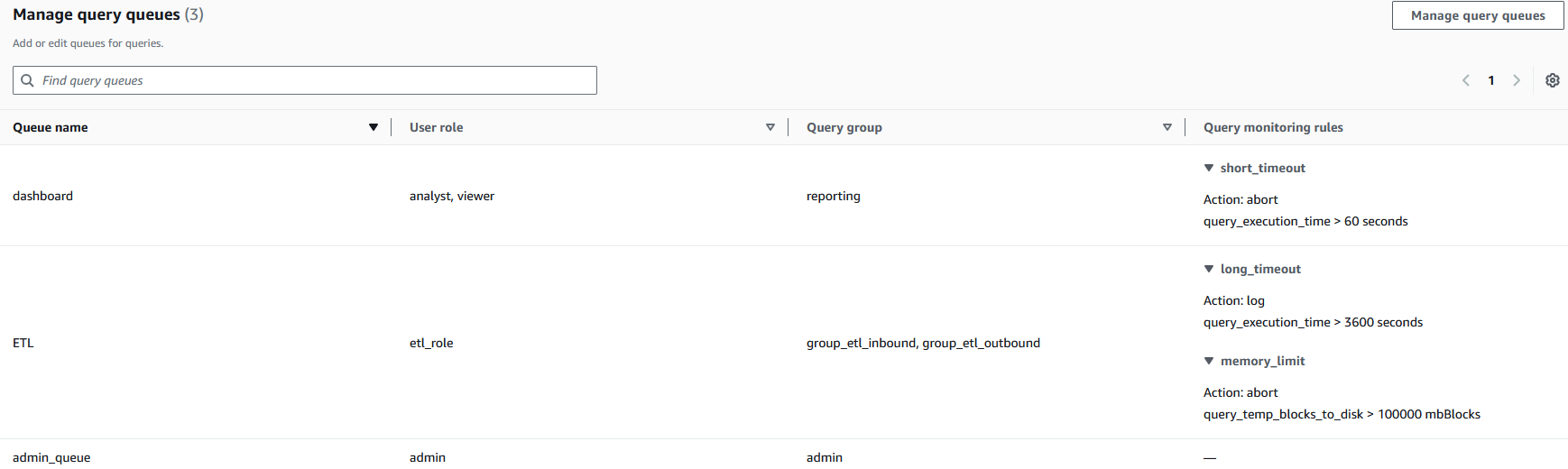
各ワークロードタイプに対して、適切なパラメータとルールを定義します。実用的な例として、3 つのキューを実装したいとします。
- Dashboard キュー – analyst および viewer ユーザーロールによって使用され、60 秒を超えるクエリを停止する厳格なランタイム制限が設定されています
- ETL キュー – etl_role ユーザーロールによって使用され、データ処理操作中のリソース使用量を制御するために、ディスクスピル (
query_temp_blocks_to_disk) に 100,000 ブロックの制限があります - Admin キュー – admin ユーザーロールによって使用され、クエリ監視制限は適用されません
AWS Management Console を使用してこれを実装するには、以下の手順を実行します。
- Redshift Serverless コンソールで、ワークグループに移動します。
- 制限 タブの クエリキュー で、キューを有効にする を選択します。
- 以下のスクリーンショットに示すように、適切なパラメータで各キューを設定します。
各キュー (dashboard、ETL、admin_queue) は特定のユーザーロールとクエリグループにマッピングされ、クエリルール間に明確な境界を作成します。クエリ監視ルールはリソース管理を自動化します。たとえば、dashboard キューは 60 秒を超えるクエリを自動的に停止し (short_timeout)、ETL プロセスには異なるしきい値でより長い実行時間を許可します。この設定は、適切なガードレールを備えた個別の処理レーンを確立することでリソースの独占を防ぎ、重要なビジネスプロセスが必要な計算リソースを維持しながら、リソースを大量に消費する操作の影響を制限できるようにします。
または、AWS Command Line Interface (AWS CLI) を使用してソリューションを実装することもできます。
以下の例では、test-namespace という既存の名前空間内に test-workgroup という名前の新しいワークグループを作成します。これにより、以下のコマンドを使用して、キューを作成し、各キューに関連する監視ルールを確立できます。
また、以下のコマンドを使用して、update-workgroup で既存のワークグループを変更することもできます。
キュー管理のベストプラクティス
以下のベストプラクティスを検討してください。
- シンプルに始める – 最小限のキューとルールのセットから始めます
- ビジネスの優先順位に合わせる – 重要なビジネスプロセスを反映するようにキューを設定します
- 監視と調整 – キューのパフォーマンスを定期的に確認し、しきい値を調整します
- 本番環境の前にテスト – 本番環境に適用する前に、テスト環境でクエリメトリクスの動作を検証します
クリーンアップ
リソースをクリーンアップするには、Amazon Redshift Serverless ワークグループと名前空間を削除します。手順については、ワークグループの削除を参照してください。
まとめ
Amazon Redshift Serverless のクエリキューは、さまざまな分析ワークロードに合わせたキュー固有の Query Monitoring Rules を有効にすることで、サーバーレスのシンプルさときめ細かなワークロード制御のギャップを埋めます。ワークロードを分離し、ターゲットを絞ったリソースしきい値を実施することで、ビジネスクリティカルなクエリを保護し、パフォーマンスの予測可能性を向上させ、高負荷のクエリを制限できます。これにより、予期しないリソース消費を最小限に抑え、コストをより適切に管理しながら、Redshift Serverless の自動スケーリングと運用のシンプルさの恩恵を受けることができます。
今すぐ Amazon Redshift Serverless を始めましょう。
著者について
Srini Ponnada Srini は、Amazon Web Services (AWS) のシニアデータアーキテクトです。20 年以上にわたり、お客様がスケーラブルなデータウェアハウスとビッグデータソリューションを構築するのを支援してきました。AWS で効率的なエンドツーエンドソリューションを設計および構築することを愛しています。
Niranjan Kulkarni Niranjan は、Amazon Redshift のソフトウェア開発エンジニアです。Amazon Redshift Serverless の採用と Amazon Redshift のセキュリティ関連機能に注力しています。仕事以外では、家族と時間を過ごし、質の高いテレビドラマを視聴することを楽しんでいます。
Ashish Agrawal Ashish は現在、Amazon Redshift のプリンシパルテクニカルプロダクトマネージャーであり、クラウドベースのデータウェアハウスと分析クラウドサービスソリューションを構築しています。Ashish は IT 分野で 24 年以上の経験があります。Ashish は、データウェアハウス、データレイク、Platform as a Service の専門知識を持っています。Ashish は世界中の技術カンファレンスで講演しています。
Davide Pagano Davide は、Amazon Redshift のソフトウェア開発マネージャーであり、自動ワークロード管理、多次元データレイアウト、Amazon Redshift Serverless の AI 駆動スケーリングと最適化などのスマートなクラウドベースのデータウェアハウスと分析クラウドサービスソリューションの構築を専門としています。データベースで 10 年以上の経験があり、そのうち 8 年は Amazon Redshift に特化しています。
この記事は Kiro が翻訳を担当し、Solutions Architect の Tatsuya Koyakumaru がレビューしました。