Amazon Web Services ブログ
自動推論で実現する Amazon のポスト量子暗号の検証と最適化
本ブログは 2026 年 4 月 7 日に公開された Amazon Science Blog “Verifying and optimizing post-quantum cryptography at Amazon” を翻訳したものです。
自動推論によって、セキュリティ、性能、保守性の要求をどのように両立させるか。
現在、安全なオンライン通信は公開鍵暗号によって実現されています。主に RSA と楕円曲線暗号 (ECC) が使われており、その安全性はある計算問題が困難であるという仮定に依存しています。しかし、これらの問題は従来のコンピュータでは困難と考えられているものの、十分に大規模な量子コンピュータでは扱える可能性があります。「Store now, decrypt later」(今保存して後で復号) 攻撃は、暗号化された情報を傍受しておき、量子コンピュータで復号できるようになるまで保持する攻撃です。こうした攻撃が技術的に実現可能になるよりはるか前から、対策が必要となります。
ポスト量子暗号 (PQC) は、従来のコンピュータ上で動作しながら量子コンピューティングに対しても安全な暗号です。2024 年、米国国立標準技術研究所 (NIST) は 8 年にわたる標準化作業を経て、標準規格 FIPS-203 を公開しました。FIPS-203 では、量子コンピュータからの攻撃に対して安全と考えられている鍵共有メカニズムとして、Module-Lattice-Based Key Encapsulation Mechanism (ML-KEM) が規定されています。
本記事では、Amazon Automated Reasoning Group、AWS Cryptography、そしてオープンソースコミュニティが協力して、ML-KEM のオープンソースかつ形式的に検証された最適化実装をどのように作り上げ、お客様を「Store now, decrypt later」攻撃から最高の保証と最小のコストで保護しているかをご紹介します。
優れた暗号エンジニアリングとは何か?
Amazon の Customer Obsession に従い、AWS は暗号ソリューションに取り組む際、次の 3 つの目標を優先します。
- お客様のデータのセキュリティ: 暗号は安全に実装することが極めて難しく、わずかな欠陥でもお客様のプライバシーを危険にさらす可能性があるため、万全を期す必要があります
- お客様の体験: 暗号には計算コストが伴います。AWS はこれを最小化し、お客様に最小のコストと最良の体験を提供します
- ソリューションを将来にわたって保守する能力: 保守に費やす時間が少ないほど、お客様のためにより多くのイノベーションを生み出せます
しかし、これらの目標の間にはトレードオフがあります。シンプルなコードは保守も安全な記述も最も簡単ですが、動作が遅くなりがちです。一方、高速なコードは監査が難しく、エラーが起きやすい傾向があります。
自動推論によって、AWS はこのトレードオフを解消し、安全で、高速で、保守しやすい暗号ソリューションを同時にお客様に提供できます。
なぜ新たな ML-KEM 実装が必要なのか
ML-KEM (旧称 Kyber) は実装の観点から十分に研究されています。一方では、Kyber リファレンスコードが、長年精査されてきたクリーンな C 言語実装を提供しています。他方では、ML-KEM をさまざまな指標やプラットフォーム向けに最適化する方法を記述した数多くの研究論文があります。
2024 年に AWS Cryptography と Amazon Automated Reasoning Group が直面した課題は、リファレンス実装のシンプルさと、研究で明らかになった最適化の可能性を、本番環境で使える単一の実装に組み合わせることでした。
同じ頃、AWS は Linux Foundation の Post-Quantum Cryptography Alliance (PQCA) の創設メンバーとなりました。PQCA は、「標準化過程にあるポスト量子暗号アルゴリズムの高保証ソフトウェア実装の構築を目指すオープンソースプロジェクトの集合」である Post-Quantum Cryptography Package (PQCP) を立ち上げました。
そこで AWS は独自にコードを開発するのではなく、チームメンバーが PQCP に参加し、まもなく mlkem-native を立ち上げました。これは、ML-KEM リファレンス実装と、最適化および形式的検証に関する研究を組み合わせることを目的とした、ML-KEM の高保証・高性能 C 言語実装です。
速く、そして慎重なコーディング
mlkem-native のモジュラー設計は、ML-KEM の高レベルロジックをカバーするフロントエンドと、性能が重要なすべてのサブルーチンを担当するバックエンドを組み合わせています。各サブルーチン (SHA3 の基礎となる Keccak 置換や、高速な多項式演算の基礎となる数論変換 (NTT) を含む) には、特定のハードウェア向けにネイティブに記述された、高効率な複数の実装が用意されています。デフォルトの C 言語実装に加えて、mlkem-native は AArch64、x86_64、RISC-V64 向けのアセンブリ/組み込み関数バックエンドを提供しています。
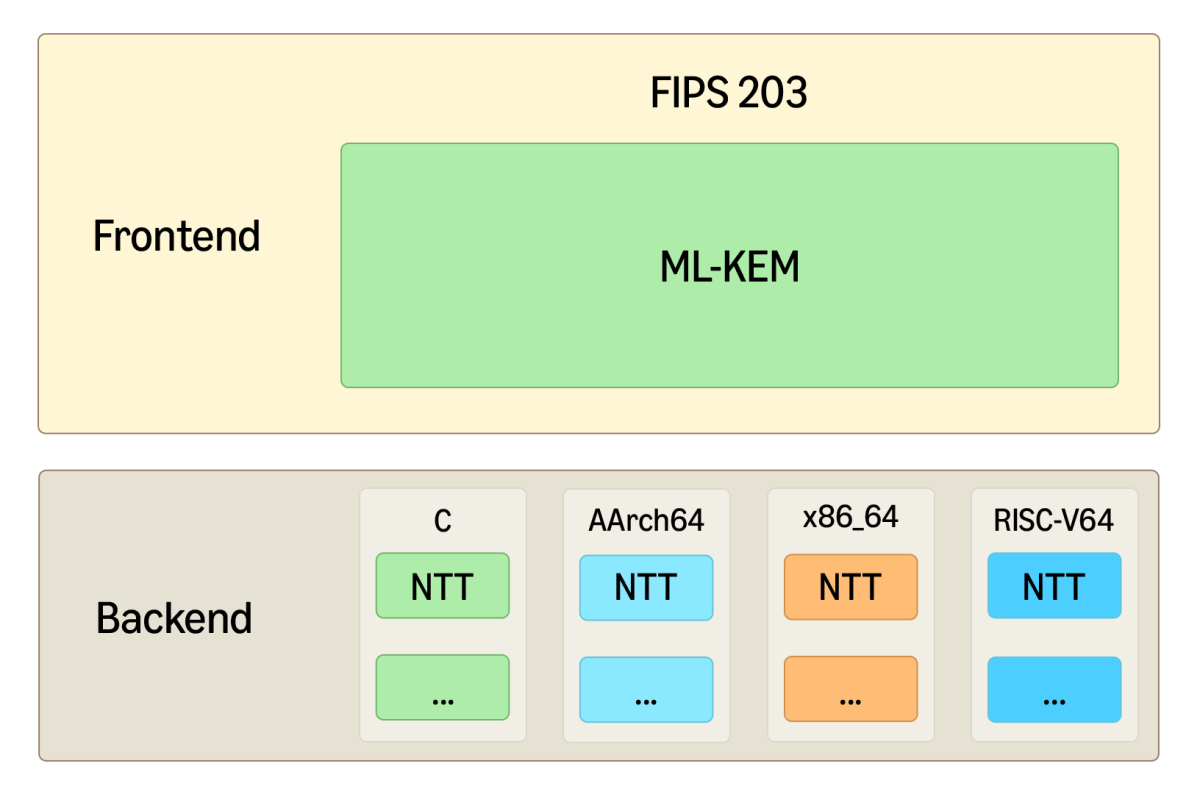
保守性のために重要なのは、フロントエンドとバックエンドの間のインターフェイスが固定されていることです。新しいターゲットアーキテクチャ向けの最適化を追加する開発者は、バックエンド仕様に従って選択したバックエンド機能を実装し、フロントエンドはそのまま維持します。バックエンド仕様の策定は、見かけほど単純ではないことが分かりました。これについては以下で説明します。
限界を知る
メモリ安全性
C プログラミング言語のよく知られた課題は、バッファオーバーフローのリスクです。メモリ領域の指定された境界を超えて書き込むと、データ構造が破壊され、悪意を持って悪用されると非特権コードの実行につながる可能性があります。こうした問題の総称がメモリ安全性です。Rust のようなメモリ安全な言語は、範囲外アクセスの影響を制限できます (たとえば、未定義動作を示す代わりにパニックする)。しかし、間違いそのものを防ぐわけではありません。
型安全性
もう一つのよく知られた課題は ML-KEM の実装に関するもので、整数オーバーフローのリスク、つまり型安全性の側面です。RSA や ECC と同様に、ML-KEM はモジュラー演算に依存しています。モジュラー演算では、演算の結果を特定の数 (ML-KEM の場合は素数 3,329 で、MLKEM_Q または単に q と表記) で割り、その剰余だけが次に持ち越されます。剰余演算子はパーセント記号 % で表されます。
論理的には、ML-KEM で 2 つの数 x と y を加算または乗算する必要がある場合、(x + y) % q および (x * y) % q を計算する必要があります。たとえば、(294 * 38) % q = 11,172 % q = 1,185 となります。このような「即時」のモジュラー q 演算は、データを「正規」範囲 {0, 1, 2, … , q-1} で表すために常にモジュラー還元を適用するもので、極めて遅くなります。
効率的な ML-KEM 実装では、代わりに「遅延」モジュラー q 演算を使用します。データはできるだけ長くモジュラー還元なしで操作され、最悪の場合のオーバーフローのリスクが生じたときにのみ還元が行われます。さらに、これにより Montgomery 還元のような不完全な還元アルゴリズムが使えるようになります。これは高速ですが、必ずしも完全に還元された出力を返すわけではありません。
ML-KEM の場合、モジュラー q = 3,329 のデータは通常、符号付き 16 ビット整数に格納されます。ML-KEM の数多くの算術ルーチン全体で遅延演算を扱う際には、データの最悪値の境界を追跡し、それらの境界が 16 ビット整数の限界を超える可能性のある箇所にモジュラー還元を挿入することが不可欠です。この領域での小さな間違いは、テストで見逃されることがあります。なぜなら、平均的な境界は最悪値の境界よりはるかに小さい傾向があるためです。そして、本番環境でランダムに表面化することがあります。
バッファ境界、特に算術境界の追跡は、時間がかかり、エラーが起きやすい作業です。たとえば、低レベルの算術関数の出力境界を弱めると、まったく別の関数で稀に算術オーバーフローが発生することがあります。これを手作業で確認するには、緻密なドキュメント作成と熟練した監査担当者が必要なだけでなく、開発が遅くなります。
mlkem-native では、C Bounded Model Checker (CBMC) というツールを使用して、C レベルでメモリ安全性と型安全性を自動的に検証しています。各関数について、機械可読かつ人間可読な契約をソースコードに追加してバッファと算術データの境界を指定し、CBMC にそれらの境界に対してバッファオーバーフローや算術オーバーフローが発生し得ないことを自動的に検証させます。
モジュラー還元の簡単な例を見てみましょう。
void mlk_poly_reduce_c(mlk_poly *r)
__contract__(
requires(memory_no_alias(r, sizeof(mlk_poly)))
assigns(memory_slice(r, sizeof(mlk_poly)))
ensures(array_bound(r->coeffs, 0, MLKEM_N, 0, MLKEM_Q)))
{
unsigned i;
for (i = 0; i < MLKEM_N; i++)
__loop__(
invariant(i <= MLKEM_N)
invariant(array_bound(r->coeffs, 0, i, 0, MLKEM_Q)))
{
/* Barrett reduction, giving signed canonical representative */
int16_t t = mlk_barrett_reduce(r->coeffs[i]);
/* Conditional addition to get unsigned canonical representative */
r->coeffs[i] = mlk_scalar_signed_to_unsigned_q(t);
}
mlk_assert_bound(r, MLKEM_N, 0, MLKEM_Q);
}関連する部分を一つずつ見ていきましょう。まず、__contract__( … ) に注目します。簡単に言うと、memory_no_alias と memory_slice の行は、コードが読み書きできるメモリを指定しています。これはメモリ安全性に関連します。ensures(array_bound(…)) 句は型安全性に関連しています。これは、関数が戻った時点でデータが区間 [0, 1, …, q) 内にあることを保証することを指定します。証明では、__loop__(invariant(…)) があり、ループがこの境界を段階的にどう確立するかを指定しています。i 番目のイテレーションでは、i 番目の係数まで成立します。最後に、実装は実質的に mlk_barrett_reduce と mlk_scalar_signed_to_unsigned_q を組み合わせています。CBMC はこれらの内部を見ず、それらの契約に置き換えます。
int16_t mlk_barrett_reduce(int16_t a)
__contract__(
ensures(return_value > -MLKEM_Q_HALF && return_value < MLKEM_Q_HALF)
{ ... }
int16_t mlk_scalar_signed_to_unsigned_q(int16_t c)
__contract__(
requires(c > -MLKEM_Q && c < MLKEM_Q)
ensures(return_value >= 0 && return_value < MLKEM_Q)
ensures(return_value == (int32_t)c + (((int32_t)c < 0) * MLKEM_Q))
{ ... }mlk_barrett_reduce がまず対称的な出力区間 (-q/2, …, q/2) を確立し、次に mlk_scalar_signed_to_unsigned_q がそれを [0,1, …, q) にマッピングしているのが分かります。この例では、仕様が望ましい形で整合していることを目視で簡単に確認できますが、より複雑な例ではそれほど明確ではありません。いずれにせよ、CBMC が自動的にチェックしてくれます。
速く動かしながら安全を保つ
上述の CBMC 証明は、mlkem-native の C コードに対するメモリ安全性と型安全性を確立します。しかし、mlkem-native の最も性能が重要な部分 (Keccak 置換と数論変換) は、AArch64 と x86_64 向けに手作業で最適化されたアセンブリで実装されています。
mlkem-native のアセンブリ実装に対して、高い性能を維持しつつ保証を得るために、AWS は次の 3 つのコンポーネントを使用しています。アセンブリのスーパーオプティマイザーである SLOTHY、対話型定理証明器である HOL Light、そして HOL Light 上に構築されたアセンブリ用検証基盤である s2n-bignum です。これらを組み合わせることで、開発者がクリーンで保守しやすいアセンブリを記述しつつ、デプロイされるコードが正当性の形式的保証を伴ってピーク性能を達成するワークフローが可能になります。
高性能なアセンブリを手で書くと、根本的なトレードオフが生じます。計算を明確に表現するクリーンで監査可能なコードは遅く、高速なコードは密で、マイクロアーキテクチャ固有で、保守が困難です。SLOTHY はマイクロアーキテクチャ固有の最適化を自動化することで、このトレードオフを解消します。アセンブリプログラムを制約充足問題に変換し、制約ソルバーを使用して最適な命令スケジュールとレジスタ割り当てを見つけ、最適化されたアセンブリを出力します。開発者は計算のロジックを重視したクリーンなコードを書き、SLOTHY が高速なコードを生成します。
AWS は、すべての AArch64 および x86_64 アセンブリルーチンの機能的正当性を、HOL Light と s2n-bignum を使用して証明します。SLOTHY が使用される場所では、特定の命令順序やレジスタ割り当てに依存しないように証明が記述されます。したがって、証明を調整することなく、特定のマイクロアーキテクチャ向けにコードを再最適化できます。この「事後」検証アプローチは、アセンブリで表現された計算の数学的な正しさを、それがどのように生成されたかにかかわらず確立します。特に、SLOTHY は信頼できるコンピューティングベース (TCB) から除外されます。
誠実さを保つ
形式的検証は決して絶対的なものではありません。すべての証明は、形式的なオブジェクト (仕様とモデル) を非形式的な現実世界の要件とシステムに結び付けるものであり、これらの結び付きにはギャップが生じます。形式的仕様は実際に必要なものを捉えているか? 形式的モデルは実際のシステムを忠実に反映しているか? 証明基盤自体は健全か?
お客様の信頼を獲得し維持するには、これらの限界について透明性を保つ必要があります。そこで AWS は、SOUNDNESS.md と題したドキュメントを作成・公開しました。ここでは、mlkem-native で何が証明され、何が仮定され、残存リスクがどこにあるかを、HOL Light 証明で使用されるハードウェアモデルの忠実性、CBMC のより大きな TCB、2 つの検証スタック間の手動の橋渡しに至るまでマッピングしています。各ギャップについて、実施されている緩和策を説明し、今後の作業の概要を示しています。
AWS の目標は完璧を主張することではなく、透明性を通じて信頼を獲得することです。コミュニティの皆様には SOUNDNESS.md を批判的に読み、AWS の前提に異議を唱え、残存するギャップを埋めることにご協力いただければ幸いです。
本番環境への展開
mlkem-native は、AWS サービス全体の安全な通信を支える Amazon のオープンソース暗号ライブラリ AWS-LC に統合されています。この統合では、自動インポーターを使用して mlkem-native のソースコードをアップストリームリポジトリから直接取り込み、AWS-LC が最新の検証済み実装と同期し続けることを保証します。
この統合は手間を最小限に抑えるよう設計されています。mlkem-native のモジュラーアーキテクチャにより、AWS-LC はコアの ML-KEM ロジックをインポートしながら、プラットフォーム固有のコンポーネントには独自の実装を提供できます。たとえば、AWS-LC は mlkem-native の暗号プリミティブを既存の FIPS-202 (SHA-3) 実装にマッピングし、AWS-LC の乱数生成およびメモリゼロ化関数を使用し、必要な場合はペアワイズ一貫性テストなど FIPS モード機能を有効にします。これを可能にしているのは、検証済みコードを変更することなく mlkem-native の API を AWS-LC のインフラストラクチャに橋渡しする薄い互換性レイヤーです。
重要なのは、メモリ安全性と型安全性を証明する CBMC 契約が、インポートされたソースコード内に保持されていることです。プリプロセッサがコンパイルされたバイナリからこれらを削除しますが、ソース内には残り、コードの保証の機械チェック可能なドキュメントとして機能します。これは、実装と共に移動する一種の「生きた証明」です。
さらに、mlkem-native も AWS-LC もオープンソースで寛容なライセンスのため、その利点は AWS の枠を超えて広がります。誰でも mlkem-native を自社のシステムに統合し、同じ性能と保証の組み合わせを得ることができます。形式的検証成果物 (CBMC 契約と HOL Light 証明) はリポジトリの一部であり、関連するすべてのツールはオープンソースであり、セットアップと証明チェックのスクリプトが提供されているため、AWS のセキュリティ主張を独立に検証できます。
インパクト
mlkem-native の開発は、自動推論を体系的に適用すれば、暗号エンジニアリングの 3 つの目標 (セキュリティ、性能、保守性) が衝突しないことを示しています。
CBMC は、複雑な算術全体で境界を手動で追跡する作業から AWS を解放し、テストでは見逃されて本番環境でランダムに表面化するエラーを捕捉しました。アノテーションはソースコード内に機械チェック可能なドキュメントとして残り、コードを同時により保守しやすく、より安全にします。HOL Light と s2n-bignum により、AWS は数学的な正当性の確実性を持って積極的なアセンブリ最適化をデプロイできました。SLOTHY により、特定のマイクロアーキテクチャ向けにピーク性能を達成しながら、クリーンで監査可能なコードを書くことができました。そして、証明は最適化に依存しないように記述されているため、検証をやり直すことなくコードのターゲットを変更できます。
その結果、従来の開発で達成できるものよりも、同時により安全で、より高速で、より保守しやすい実装が実現しました。AWS はお客様のセキュリティ、お客様の体験、そして革新する能力の間で妥協しませんでした。自動推論は 3 つすべてを実現したのです。
| AWS-LC-FIPS リリース | ||||
| プラットフォーム | 処理 | 3.1 | 4.0 | 改善倍率 |
| c7i | Keygen | 30899 | 65146 | 2.1 |
| Encaps | 30623 | 61233 | 2.0 | |
| Decaps | 25141 | 51545 | 2.0 | |
| c7g | Keygen | 29617 | 71134 | 2.4 |
| Encaps | 28482 | 66874 | 2.3 | |
| Decaps | 23919 | 64765 | 2.3 | |
Amazon の暗号ライブラリ AWS-LC で ML-KEM リファレンス実装から mlkem-native に切り替えた際の性能影響。ML-KEM-768 の性能は c7i および c7g EC2 インスタンスで測定されています。数値は 1 秒あたりの処理数を表します (高いほど良い)。ベースラインは ML-KEM の C リファレンス実装を含む AWS-LC-FIPS 3.1 リリースです。AWS-LC-FIPS 4 リリースは mlkem-native でビルドされています。プラットフォームは Intel(R) Xeon(R) Platinum 8488C を搭載した c7i と、Graviton 3 プロセッサを搭載した c7g です。
謝辞
同僚の John Harrison 氏 (Automated Reasoning Group の senior principal applied scientist) には、HOL Light での AArch64 アセンブリ証明の大部分を提供し、また HOL Light 対話型定理証明器および s2n-bignum 検証基盤の保守を担当いただいたことに感謝します。mlkem-native は AWS だけでなく、オープンソースコミュニティの多くのメンバーが関わる共同作業です。とりわけ、共同保守者である zeroRISC の Matthias Kannwischer 氏に感謝します。彼は AWS と共に mlkem-native を立ち上げ、以来プロジェクトの成功に重要な役割を果たしてきました。