AWS News Blog
Amazon Redshift Update – Next-Generation Compute Instances and Managed, Analytics-Optimized Storage

|
We launched Amazon Redshift back in 2012 (Amazon Redshift – The New AWS Data Warehouse). With tens of thousands of customers, it is now the world’s most popular data warehouse. Our customers enjoy consistently fast performance, support for complex queries, and transactional capabilities, all with industry-leading price-performance.
The original Redshift model establishes a fairly rigid coupling between compute power and storage capacity. You create a cluster with a specific number of instances, and are committed to (and occasionally limited by) the amount of local storage that is provided with each instance. You can access additional compute power with on-demand Concurrency Scaling, and you can use Elastic Resize to scale your clusters up and down in minutes, giving you the ability to adapt to changing compute and storage needs.
We think we can do even better! Today we are launching the next generation of Nitro-powered compute instances for Redshift, backed by a new managed storage model that gives you the power to separately optimize your compute power and your storage. This launch takes advantage of some architectural improvements including high-bandwidth networking, managed storage that uses local SSD-based storage backed by Amazon Simple Storage Service (Amazon S3), and multiple, advanced data management techniques to optimize data motion to and from S3.
Together, these capabilities allow Redshift to deliver 3x the performance of any other cloud data warehouse service, and most existing Amazon Redshift customers using Dense Storage (DS2) instances will get up to 2x better performance and 2x more storage at the same cost.
Among many other use cases, this new combo is a great fit for operational analytics, where much of the workload is focused on a small (and often recent) subset of the data in the data warehouse. In the past, customers would unload older data to other types of storage in order to stay within storage limits, leading to additional complexity and making queries on historical data very complex.
Next-Generation Compute Instances
The new RA3 instances are designed to work hand-in-glove with the new managed storage model. The ra3.16xlarge instances have 48 vCPUs, 384 GiB of Memory, and up to 64 TB of storage. I can create clusters with 2 to 128 instances, giving me over 8 PB of compressed storage:
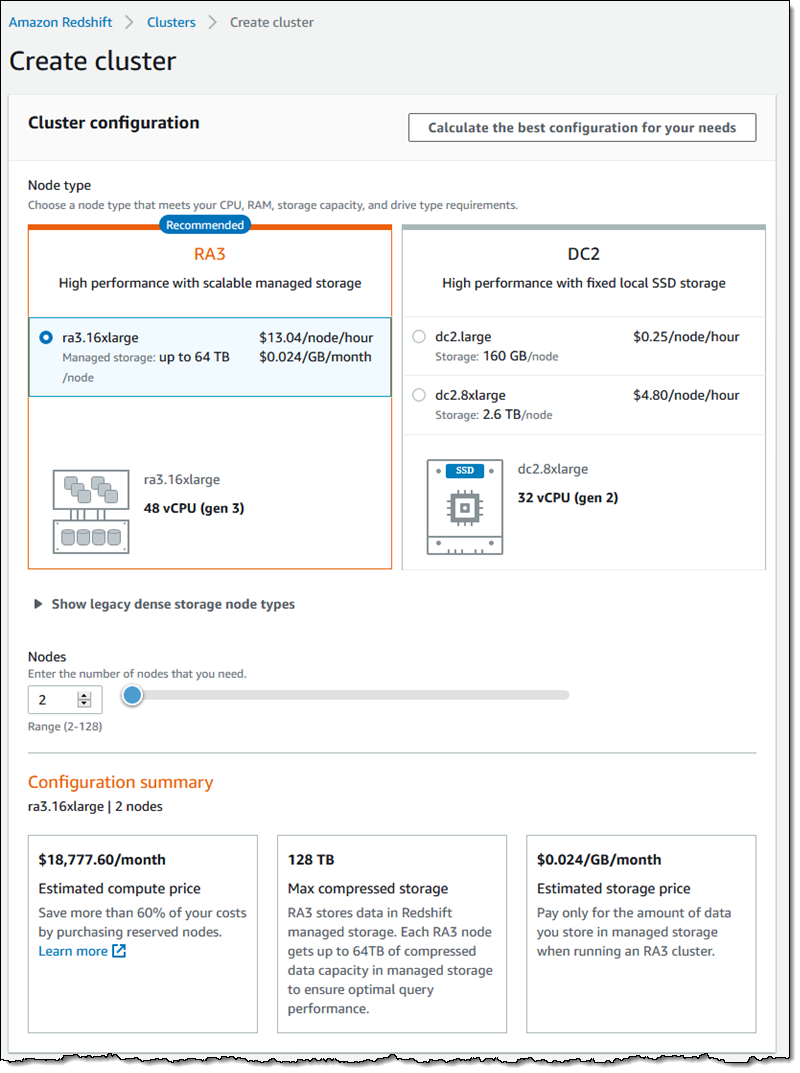
I can also create a new RA3-powered cluster from a snapshot of an existing cluster, or I can use Classic resize to upgrade my cluster to use the new instance type.
If you have an existing snapshot or a cluster, you can use the Amazon Redshift console to get a recommended RA3 configuration when you restore or resize. You can also get recommendations from the DescribeNodeConfigurationOptions function or the describe-node-configuration-options command.
Managed, Analytics-Optimized Storage
The new managed storage is equally exciting. There’s a cache of large-capacity, high-performance SSD-based storage on each instance, backed by S3, for scale, performance, and durability. The storage system uses multiple cues, including data block temperature, data blockage, and workload patterns, to manage the cache for high performance. Data is automatically placed into the appropriate tier, and you need not do anything special to benefit from the caching or the other optimizations. You pay the same low price for SSD and S3 storage, and you can scale the storage capacity of your data warehouse without adding and paying for additional instances.
Price & Availability
You can start using RA3 instances together with managed storage in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (N. California), US West (Oregon), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), EU (Frankfurt), EU (Ireland), EU (London).
— Jeff;