AWS News Blog
Amazon Redshift – The New AWS Data Warehouse
You may have noticed that we announced Amazon Redshift today a data warehouse service that is a lot faster, simpler, and less expensive than alternatives available today.
Let’s Talk About Data
A data warehouse is a specialized type of relational database, optimized for high-performance analysis and reporting of transactions. It collects current and historical transactional data from many disparate operational systems (manufacturing, finance, sales, shipping, etc.) and pulls it together in one place to guide analysis and decision-making. Without a data warehouse, a business lacks an integrated view of its data. Essential reports aren’t available in time, visibility into changes that affect the business is reduced, and business suffers.
To date, setting up, running, and scaling a data warehouse has been complicated and expensive. Maintaining and monitoring all the moving parts (hardware, software, networking, storage) requires deep expertise across a number of disciplines. At scale, even comparatively simple things like loading or backing up data get hard. Getting fast performance requires mastery of complicated query plans, access methods, and indexing techniques. No surprise, traditional data warehouses have been seen as gold-plated, premium-priced products with substantial upfront costs.
Enter Amazon Redshift
Amazon Redshift makes it easy for you setup, run, and scale a data warehouse of your own. AWS customers such as Netflix, JPL, and Flipboard have been testing it as part of a private beta. We are launching Amazon Redshift in a limited public beta mode today.
Amazon Redshift is a massively parallel, fully-managed data warehouse service, designed for data sets from hundreds of gigabytes to several petabytes in size, and appropriate for an organization of any size from a startup to a multi-national at a price point that will take you by surprise. Amazon Redshift is fully managed, so you no longer need to worry about provisioning hardware, installation, configuration or patching of system or database software, Because your business is dependent on your data, Amazon Redshift takes care to protect it by replicating all data within the cluster as well as in S3.
Amazon Redshift won’t break the bank (or your credit card, since it is completely pay-as-you-go). We did the math and found that it would generally cost you between $19,000 and $25,000 per terabyte per year at list prices to build and run a good-sized data warehouse on your own. Amazon Redshift, all-in, will cost you less than $1,000 per terabyte per year. For that price you get all of the benefits that I listed above without any of the operational headaches associated with building and running your own data warehouse.
Like every AWS service, you can create and manipulate an Amazon Redshift cluster using a set of web service APIs. You can create a cluster programmatically, keep it around as long as you need it, and then delete it, all with a couple of calls. Of course, you can also create and manage your Amazon Redshift cluster using the AWS Management Console.
Let’s take a deeper look at Amazon Redshift!
Amazon Redshift Architecture
An active instance of Amazon Redshift is called a Data Warehouse Cluster, or just a cluster for short. You can create single node and multi-node clusters. Single node clusters store up to 2 TB of data and are a great way to get started. You can convert a single node cluster to a multi-node cluster as your needs change. Each multi-node cluster must include a Leader Node and two or more Compute Nodes. A Leader Node manages connections, parses queries, builds execution plans, and manages query execution in the Compute Nodes. The Compute Nodes store data, perform computations, and run queries as directed by the Leader Node.
Amazon Redshift nodes come in two sizes, the hs1.xlarge and hs1.8xlarge, which hold 2 TB and 16 TB of compressed data, respectively. An Amazon Redshift cluster can have up to 32 hs1.xlarge nodes for up to 64 TB of storage or 100 hs1.8xlarge nodes for up to 1.6 PB of storage. We currently set a maximum cluster size of 40 nodes (640 TB of storage) by default. If you need to store more than 640 TB of data, you can simply fill out a form to request a limit increase. Keep in mind that Amazon Redshift is a column-oriented database and that it is able to compress data to a higher degree than is generally possible with a traditional row-oriented database.
The Leader Node of each cluster is accessible through ODBC and JDBC endpoints, using standard PostgreSQL drivers. The Compute Nodes run on a separate, isolated network and are never accessed directly. Amazon Redshift is ANSI SQL compatible, and should work with your existing BI tools. Jaspersoft and Microstrategy have already certified that it works with their tools, and others will soon follow.
Amazon Redshift is designed to retain data integrity in the face of disk and node failures. The first line of defense consists of two replicated copies of your data, spread out over up to 24 drives on different nodes within your data warehouse cluster. Amazon Redshift monitors the health of the drives and will switch to a replica if a drive fails. It will also move the data to a health drive if possible, or to a fresh node if necessary. All of this happens without any effort on your part, although you may see a slight performance degradation during the re-replication process
Pricing
Like every other part of AWS, Amazon Redshift is priced on a pay-as-you-go basis. You pay only for the resources that you use, and there are no minimums. Billing begins when your cluster is available and you are billed based on the number of Compute Nodes in the cluster. We dont charge for the leader node, network transfers in or out, and only charge for S3 storage once it exceeds the provisioned size of your cluster. Pricing is below:
| Price/Hour per hs1.xlarge compute node | Price/Hour per hs1.8xlarge compute node | Effective Hourly Price per TB | Effective Annual Price per TB | |
| On-Demand | $0.850 | $6.80 | $0.425 | $3,723 |
| 1 Year Reserved | $0.500 | $4.00 | $0.250 | $2,190 |
| 3 Year Reserved | $0.228 | $1.82 | $0.114 | $999 |
Amazon Redshift keeps two copies of each block of data within the cluster, and maintains a free space buffer in case drives fail and their data needs to be re-distributed across the other drives in the cluster. This focus on durability and reliability is the reason for the 3:1 ratio between raw and available disk storage on these instances. The $999 price per terabyte per year mentioned above is based on the 16 TB of available storage.
Getting Started With Amazon Redshift
Here’s what you need to do to get started with Amazon Redshift:
- Provision a Cluster
- Download Drivers
- Get a SQL Client
- Load Data
Clusters are provisioned using the AWS Management Console. Clicking the Launch DW Cluster button initiates the provisioning process. Here’s the first page:
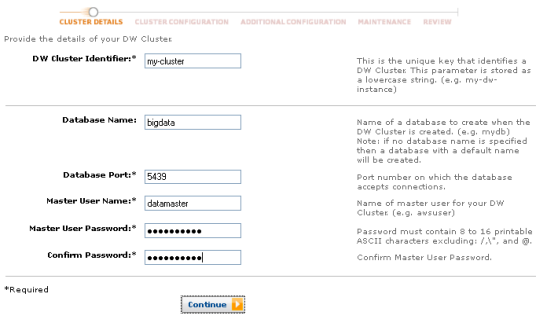
Once the cluster is up and running, the JDBC and ODBC connection strings are available in the console:
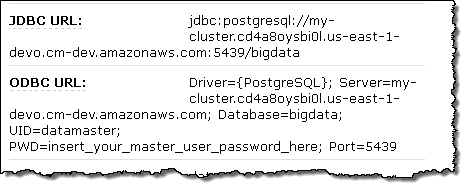
- ODBC – http://ftp.postgresql.org/pub/odbc/versions/msi/psqlodbc_08_04_0200.zip (psqlODBC installer for Windows).
- JDBC – http://jdbc.postgresql.org/download/postgresql-8.4-703.jdbc4.jar (platform neutral JDBC driver).
You can connect to Amazon Redshift using many different SQL client applications including SQL Workbench.
The final step is to load data. You can bulk load data from Amazon S3 into an Amazon Redshift database with a single command:
To take advantage of parallelism, you can split your data into multiple files within the folder and the bulk load command will load the data in parallel into each Compute Node.
Tool Support
A number of vendors are already providing tools that have been tested with Amazon Redshift and they’re available in the AWS Marketplace. Here’s a sampling of what’s there now:
And That’s That
As I noted earlier, Amazon Redshift is available in limited preview form. You can apply here if you are interested in participating. As you can tell from what I’ve written above, this is a rich and powerful product, and I’ll have a lot more to say about it in the future. Let me know what you think!
— Jeff;