Amazon Web Services 한국 블로그
Category: AWS Glue

Amazon Athena 및 Amazon QuickSight를 활용한 2백년간 글로벌 기후 데이터 시각화
전 세계 기후 변화는 우리의 삶의 질에 심각한 영향을 미치고 있습니다. 이 때문에 향후 지속 가능성에 대한 조사도 증가하고 있습니다. 공공 및 민간 부문의 연구원은 기록된 기후의 역사를 연구하고 기후 예측 모델을 사용하여 미래를 계획하고 있습니다. 이 글은 기후 변화와 그 개념에 대한 설명을 돕기 위해 Global Historical Climatology Network Daily(GHCN-D)를 소개합니다. 그리고, Amazon Web […]

AWS Glue를 활용한 서버리스 스트리밍 ETL 기능 출시
데이터를 분석할 때, 가장 먼저 취하는 방법은 일괄(Batch) 처리 모델입니다. 일정 기간 동안 데이터를 수집한 다음, 분석 도구에 넣는 것입니다. 신속히 대응하려면 스트리밍(Streaming) 모델을 사용할 수 있습니다. 이 모델에서는 데이터가 도착하는 대로 처리하거나, 한 번에 레코드 하나씩 처리하거나, 10개, 100개, 1,000개 단위의 마이크로 배치로 레코드를 처리합니다. 연속적인 입력 파이프라인을 관리하고 즉석에서 데이터를 처리하는 작업은 상당히 […]

Woot.com은 어떻게 AWS 기반 서버리스 데이터 레이크를 구축 하였는가?
이 글에서는 관계형 데이터베이스를 기반으로 구축된 기존 데이터 웨어하우스를 대체할 클라우드 네이티브 데이터 웨어하우스를 설계하는 방법에 대해 Woot.com의 사례를 소개합니다. (Woot는 2004 년에 설립되어 2010년 Amazon에 의해 인수된 최초의 일일 거래 사이트입니다. 원래 Woot는 매진 할 때까지 하루에 단 하나의 제품만을 제공했으나, 최근에는 7 가지 카테고리에 걸쳐 특별 일일 거래 및 기타 기간 한정 상품을 […]

AWS Glue를 이용한 파티션 데이터 처리
AWS Glue는 Hive 스타일 파티션으로 구성된 데이터 세트 처리에 향상된 기능을 제공합니다. AWS Glue 크롤러는 Amazon S3에 저장된 데이터의 파티션을 자동으로 구별합니다. AWS Glue ETL(추출, 변환, 로드) 라이브러리는 DynamicFrames로 작업할 때 기본적으로 파티션을 지원하며, DynamicFrames는 스키마를 지정하지 않더라도 분산된 데이터 콜렉션을 나타냅니다. DynamicFrames를 생성할 때 S3를 호출하지 않더라도 서술자를 통해 파티션을 필터링할 수 있습니다. 또한 […]

AWS Glue, 서울 리전 출시
AWS Glue는 고객이 분석을 위해 손쉽게 데이터를 준비하고 로드할 수 있게 지원하는 완전관리형 ETL(추출, 변환 및 로드) 서비스입니다. AWS 관리 콘솔에서 클릭 몇 번으로 ETL 작업을 생성하고 실행할 수 있습니다. 빅데이터 분석 시 다양한 데이터 소스에 대한 전처리 작업을 할 때, 별도의 데이터 처리용 서버나 인프라를 관리할 필요가 없습니다. 이번에 서울 리전에서 본 서비스를 출시하고, […]

AWS Glue 기반 Amazon Aurora 데이터 추출 및 Quicksight 시각화 하기
AWS Glue는 서버리스 ETL 서비스로 데이터 분석을 위해 손쉽게 데이터를 준비하고 로딩할 수 있도록 지원하는 서비스 입니다. AWS Glue는 AWS에 저장된 데이터의 메타 데이터를 통해 데이터 카탈로그를 생성하고, 해당 카탈로그로 다양한 서비스에서 데이터에 접근하여 사용할 수 있습니다. 이 글에서는 실제 많은 고객들이 서비스 운영 데이터베이스로 사용하고 있는 Amazon Aurora의 DB 데이터를 AWS Glue를 통해 데이터 […]
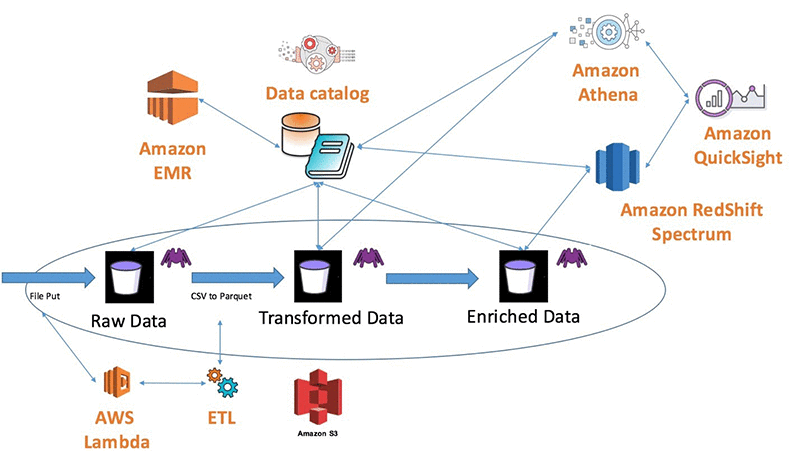
Amazon S3 및 AWS Glue를 이용한 데이터 레이크 구축하기
데이터 레이크(Data Lake)는 다양한 유형의 대량 데이터를 처리해야 하는 과제를 해결하는 데이터 저장 및 분석 방법으로서 점차 인기를 얻고 있습니다. 데이터 레이크를 사용하면 모든 데이터(정형 및 비정형)를 중앙 집중식 리포지토리 한 곳에 저장할 수 있습니다. 데이터를 있는 그대로 저장할 수 있으므로 데이터를 사전 정의된 스키마로 변환할 필요가 없습니다. 많은 기업들은 데이터 레이크에서 Amazon S3를 사용하는 […]

AWS Glue 정식 출시 – 완전 관리형 ETL 서비스
오늘 AWS Glue 서비스가 정식 출시되었습니다. AWS Glue는 완전 관리형, 서버리스 기반 클라우드 데이터 추출, 변환 및 로드 (ETL) 서비스입니다. 이 서비스는 몇 가지 매우 중요한 방식으로 다른 ETL 서비스 및 소프트웨어 플랫폼과 다릅니다. 첫째, Glue는 “서버가 필요하지 않습니다.” 어떤 인프라 자원도 프로비저닝하거나 관리 할 필요가 없으며, Glue 실행될 때만 비용을 지불합니다. 둘째, Glue는 많은 […]