Amazon Web Services 한국 블로그
Category: Amazon Simple Storage Service (S3)

Amazon S3 annotations 기능 소개: 쿼리 가능한 리치 컨텍스트를 객체에 직접 첨부 가능
오늘은 Amazon Simple Storage Service(Amazon S3)를 위한 새로운 메타데이터 기능인 S3 annotations (이하, 주석)을 발표합니다. 이 기능을 사용하면 풍부한 대규모 비즈니스 컨텍스트를 객체에 직접 첨부할 수 있습니다. JSON, XML, YAML 또는 일반 텍스트와 같은 유연한 형식으로, 각 객체당 최대 1MB 크기의 명명된 주석을 최대 1,000개까지 저장할 수 있습니다. 객체를 다시 작성하지 않고도 언제든지 주석을 수정하거나 […]

Amazon S3 Files 정식 출시 – S3 버킷을 파일 시스템처럼 접근 가능
모든 AWS 컴퓨팅 리소스를 Amazon Simple Storage Service(Amazon S3)와 원활하게 연결하는 새로운 파일 시스템인 Amazon S3 Files를 발표합니다! 10여 년 전, AWS 트레이너로 일하면서 객체 스토리지와 파일 시스템의 근본적인 차이를 설명하는 데 긴 시간을 할애했습니다. 제가 가장 좋아하는 비유는 S3 객체를 도서관의 책(페이지를 편집할 수 없고 책 전체를 바꿔야 함)과 비교하는 것이었습니다. 반면, 컴퓨터의 파일은 […]
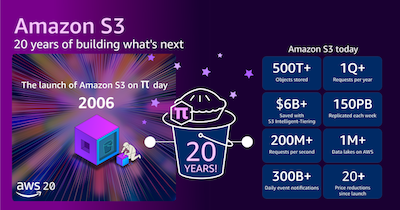
Amazon S3의 20년 역사와 차세대 서비스 방향
20년 전 오늘, 2006년 3월 14일에 Amazon Simple Storage Service(Amazon S3)는 새로운 소식 페이지에 게시된 한 단락의 간단한 발표와 함께 조용히 출범했습니다. Amazon S3는 개발자가 웹 스케일 컴퓨팅을 쉽게 구현할 수 있도록 설계된 인터넷용 스토리지입니다. Amazon S3는 언제 어디서든, 웹에 원하는 양의 데이터를 저장하고 검색하는 데 사용할 수 있는 간단한 웹 서비스 인터페이스를 제공합니다. 이를 […]

Amazon S3 범용 버킷용 계정 리전별 네임스페이스 소개
오늘은 자체 계정의 리전 네임스페이스에서 범용 버킷을 만들어 데이터 스토리지 크기와 범위 요구 사항이 늘어남에 따라 버킷 생성과 관리를 간소화해 주는 Amazon Simple Storage Service(Amazon S3) 새 기능을 발표합니다. 여러 AWS 리전에서 범용 버킷 이름을 생성하면서도 원하는 버킷 이름을 항상 사용할 수 있도록 보장할 수 있습니다. 이 기능을 사용하면 요청한 버킷 이름에 계정의 고유한 접미사를 […]
Amazon S3 Vectors 정식 출시: 높은 확장성과 성능 개선을 통해 90%까지 비용 절감
오늘, Amazon S3 Vectors가 대폭 향상된 확장성과 프로덕션급 성능으로 정식 출시되었다는 기쁜 소식을 전해드립니다. S3 Vectors는 벡터 데이터의 저장 및 쿼리를 기본적으로 지원하는 최초의 클라우드 객체 스토리지입니다. S3 Vectors를 사용하면 전문 벡터 데이터베이스 솔루션 대비 벡터 저장 및 쿼리 총 비용을 최대 90%까지 절감할 수 있습니다. 7월에 S3 Vectors의 평가판을 발표한 후, 저는 여러분이 이 […]
Amazon S3 Storage Lens, 성능 지표, 수십억 개의 접두사 지원, S3 테이블 내보내기 지원
오늘 Amazon S3 Storage Lens의 세 가지 새로운 기능을 발표합니다. 이러한 기능을 통해 스토리지 성능 및 사용 패턴에 대한 심층적인 인사이트를 얻을 수 있습니다. 성능 지표 추가, 수십억 개의 접두사 분석 지원, Amazon S3 Tables 테이블로의 직접 내보내기 기능을 통해 애플리케이션 성능을 최적화하고, 비용을 절감하고, Amazon S3 스토리지 전략에 대한 데이터 기반 의사 결정을 내리는 […]

Amazon FSx for NetApp ONTAP, Amazon S3와 통합 기능 정식 출시
오늘, Amazon Simple Storage Service(Amazon S3)를 사용하여 Amazon FSx for NetApp ONTAP 파일 시스템의 데이터에 액세스할 수 있는 기능을 발표합니다. 이 기능을 사용하면 기업 파일 데이터를 사용하여 검색 증강 생성(RAG)을 위한 Amazon Bedrock Knowledge Bases로 생성형 AI 애플리케이션을 강화하고, Amazon SageMaker로 기계 학습(ML) 모델을 학습시키고, Amazon S3와 통합된 타사 서비스로 인사이트를 생성하고, Amazon Quick Suite와 […]
Amazon S3 범용 버킷에 대한 속성 기반 액세스 제어 기능 출시
기업이 확장됨에 따라 스토리지 리소스에 대한 액세스 권한을 관리하는 작업은 점점 더 복잡해지고 시간이 많이 걸립니다. 새로운 팀원이 합류하고, 기존 직원의 역할이 변경되고, 새 S3 버킷이 생성되면 조직은 여러 유형의 액세스 정책을 지속적으로 업데이트하여 S3 버킷 전반의 액세스를 관리해야 합니다. 이 문제는 멀티 테넌트 S3 환경에서 특히 두드러집니다. 이러한 환경에서는 관리자가 공유 데이터세트와 수많은 사용자에 […]
Amazon S3 Vectors 소개: 대규모 벡터를 지원하는 최초 클라우드 스토리지 (미리 보기)
오늘 AWS는 벡터 업로드, 저장 및 쿼리에 드는 총 비용을 최대 90% 절감할 수 있고 내구성이 뛰어난 목적별 벡터 스토리지 솔루션인 Amazon S3 Vectors의 평가판을 발표합니다. Amazon S3 Vectors는 대규모 벡터 데이터세트를 저장하고 1초 미만의 쿼리 성능을 기본적으로 지원하는 최초의 클라우드 객체 저장소로, 기업이 합리적인 비용으로 AI 지원 데이터를 대규모로 저장하는 데 활용할 수 있습니다. […]

Amazon S3 Metadata, 모든 S3 객체에 대한 메타데이터 지원 시작
이제 Amazon S3 Metadata는 새 객체와 변경 사항뿐만 아니라 Amazon Simple Storage Service(Amazon S3) 버킷에 있는 모든 기존 객체에 대해서도 완전한 가시성을 제공합니다. 이 확장된 적용 범위 덕분에 전체 S3 스토리지 풋프린트에 대한 메타데이터를 분석하고 쿼리할 수 있게 되었습니다. 오늘날 많은 고객들이 Amazon S3를 사용하여 비정형 데이터를 대규모로 저장하고 있습니다. 버킷에 무엇이 있는지 파악하려면 장기적으로 […]