Amazon Web Services 한국 블로그
Category: AWS re:Invent

AWS Lambda durable functions 출시 – 다단계 애플리케이션과 AI 워크플로우 구축 가능
최신 애플리케이션은 다단계 결제 처리, AI 에이전트 오케스트레이션, 사람의 결정을 기다리는 승인 프로세스 등 서비스 간의 복잡하고 장기적인 조정을 점점 더 요구합니다. 기존에는 이러한 기능을 구축하는 데 상태 관리, 장애 처리, 여러 인프라 서비스 통합 등 상당한 노력이 필요했습니다. 오늘부터 AWS Lambda durable functions를 사용하여 익숙한 AWS Lambda 환경에서 직접 안정적인 다단계 애플리케이션을 구축할 수 […]

Amazon EC2 X8aedz 인스턴스 정식 출시: 메모리 집약적 워크로드를 위한 5세대 AMD EPYC 프로세서 지원
오늘, 5세대 AMD EPYC 프로세서로 구동되며 메모리가 최적화된 새로운 고주파 Amazon Elastic Compute Cloud(Amazon EC2) x8Aedz 인스턴스의 출시를 발표합니다. 이러한 인스턴스는 클라우드에서 가장 높은 CPU 주파수인 5GHz를 제공합니다. 이전 세대 X2iezn 인스턴스 대비 최대 2배 더 높은 컴퓨팅 성능과 31% 가격 대비 성능을 제공합니다. X8aedz 인스턴스는 물리적 레이아웃 및 물리적 검증 작업과 같은 전자 설계 […]

AWS Database Saving Plan 도입 – 연간 약정 시 DB 비용을 최대 35%까지 절감
Amazon Web Services(AWS)에서 Savings Plans를 도입한 이후, 고객은 계정, 리소스 유형 및 AWS 리전 전반에서 사용량을 관리할 수 있는 유연성을 유지하면서도 지속적인 워크로드를 실행하는 데 드는 비용을 낮출 수 있었습니다. 오늘, AWS는 데이터베이스 절감형 플랜을 출시하여 이러한 유연한 요금 모델을 AWS 관리형 데이터베이스 서비스로 확장합니다. 이 플랜을 통해 고객은 1년 동안 일정한 사용량(시간당 비용)을 약정할 […]

Amazon RDS for SQL Server 및 Oracle, 비용 최적화와 확장성 향상
데이터베이스 환경을 관리하려면 리소스 효율성과 확장성 간의 균형이 필요합니다. 조직은 개발, 테스트 및 프로덕션 워크로드와 다양한 스토리지 및 컴퓨팅 요구 사항을 아우르는 전체 데이터베이스 수명 주기에 걸쳐 유연한 옵션을 필요로 합니다. 이러한 요구를 충족하기 위해 Amazon Relational Database Service(Amazon RDS)의 네 가지 새로운 기능을 발표합니다. 이러한 기능은 고객이 Amazon RDS for Oracle 및 Amazon RDS […]

Amazon OpenSearch Service, GPU 가속 및 자동 최적화를 통해 벡터 DB 성능 및 비용 향상
오늘 Amazon OpenSearch Service의 벡터 인덱스에 대한 서버리스 GPU 가속화 및 자동 최적화를 발표합니다. 이 기능을 통해 대규모 벡터 데이터베이스를 더 낮은 비용으로 더 빠르게 구축하고, 검색 품질, 속도, 비용 간의 최적의 균형을 위해 벡터 인덱스를 자동으로 최적화할 수 있습니다. 오늘 소개된 새로운 기능은 다음과 같습니다. GPU 가속화 – 비 GPU 가속 대비 인덱싱 비용의 […]

Amazon SageMaker AI, 서버리스 MLflow 기반 AI 개발 가속화 지원
2024년 6월 Amazon SageMaker AI with MLflow 출시 이후, 고객은 MLflow 추적 서버를 사용하여 기계 학습(ML) 및 AI 실험 워크플로를 관리해 왔습니다. 이러한 토대를 바탕으로 실험의 접근성을 더욱 높이기 위해 MLflow 환경을 지속적으로 발전시켜 나가고 있습니다. 오늘 MLFlow를 지원하는 Amazon SageMaker AI에 인프라 관리가 필요 없는 서버리스 기능이 추가되었다는 기쁜 소식을 전해드립니다. 이 새로운 MLFlow […]

Amazon Bedrock, 18개 완전관리형 오픈웨이트 모델 추가 (신규 Mistral Large 3 및 Ministral 3 모델 포함)
오늘 Amazon Bedrock에서 Google, Mistral AI, NVIDIA, OpenAI, Qwen의 완전 관리형 오픈 가중치 모델 18개가 추가로 출시되었습니다. 여기에는 새로운 Mistral Large 3 및 Ministral 3 3B, 8B, 14B 모델이 포함됩니다. 이번 출시를 통해 Amazon Bedrock은 이제 약 100개의 서버리스 모델을 제공하며, 선도적인 AI 기업들의 광범위하고 심층적인 모델을 제공하므로 고객은 고유한 요구 사항에 가장 적합한 기능을 […]

Amazon Bedrock AgentCore, 품질 평가와 정책 통제 기능 출시
오늘 Amazon Bedrock AgentCore의 새로운 기능을 발표합니다. 이 기능을 통해 AI 에이전트의 프로덕션 환경 진입을 가로막는 장벽을 더욱 효과적으로 제거할 수 있습니다. 다양한 산업 분야의 기업들이 규모에 관계없이 고성능 에이전트를 안전하게 구축, 배포 및 운영할 수 있는 최첨단 플랫폼인 AgentCore를 기반으로 이미 구축하고 있습니다. AgentCore SDK는 평가판 이후 단 5개월 만에 2백만 회 이상 다운로드되었습니다. […]
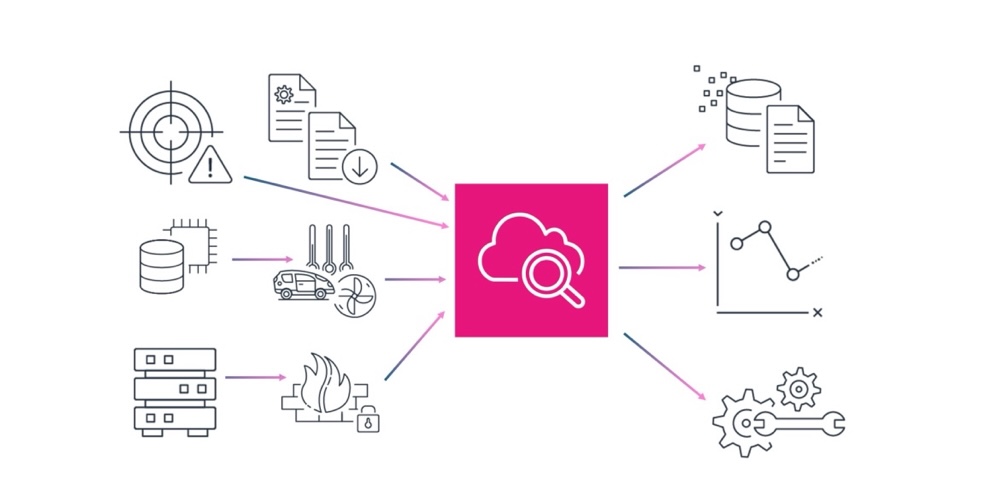
Amazon CloudWatch, 운영, 보안, 규정 준수를 위한 통합 데이터 관리 및 분석 기능 도입
오늘 부터 Amazon CloudWatch 기능을 확장하여 한 곳에서 유연하고 강력한 분석을 수행하고 데이터 중복 및 비용을 줄임으로써 운영, 보안 및 규정 준수 사용 사례 전반에서 로그 데이터를 통합 및 관리하고 있습니다. 이러한 향상된 기능으로 CloudWatch는 Open Cybersecurity Schema Framework(OCSF) 및 Open Telemetry(OTel) 형식에 대한 기본 지원을 통해 소스 간에 일관성을 제공하도록 데이터를 자동으로 정규화하고 처리할 […]

AWS DevOps Agent 출시: 사고 대응 가속화 및 시스템 신뢰성 향상 (미리보기)
오늘, 과거 인시던트와 운영 패턴을 체계적으로 분석하여 인시던트에 대응하고, 근본 원인을 파악하고, 향후 문제를 예방할 수 있도록 지원하는 프론티어 에이전트인 AWS DevOps Agent를 미리보기로 발표합니다. 프런티어 에이전트는 자율적이고 대규모 확장 가능하며, 지속적인 개입 없이 몇 시간 또는 며칠 동안 작동하는 새로운 유형의 AI 에이전트입니다. 프로덕션 환경에서 인시던트가 발생하면 당직 엔지니어가 이해관계자와의 소통을 관리하면서 근본 원인을 […]