Amazon Web Services 한국 블로그
AWS Glue 데이터 카탈로그, Apache Iceberg 테이블 자동 압축 지원
오늘 Apache Iceberg 형식의 트랜잭션 테이블을 자동으로 압축할 수 있는 AWS Glue 데이터 카탈로그의 새로운 기능이 출시됩니다. 이를 통해 트랜잭션 데이터 레이크 테이블의 성능을 항상 일정하게 유지할 수 있습니다.
데이터 레이크는 처음에 주로 방대한 양의 원시, 비정형 또는 반정형 데이터를 저렴한 비용으로 저장하는 용도로 설계되었으며 일반적으로 빅 데이터 및 분석 사용 사례와 관련이 있었습니다. 시간이 흐르면서 조직이 데이터 레이크를 단순한 보고 이상의 용도로 사용할 수 있는 가능성을 인식하고 데이터 일관성을 보장하기 위해 트랜잭션 기능을 포함해야 한다는 점을 알게 되면서 데이터 레이크의 가능한 사용 사례도 점점 더 늘어나고 있습니다.
데이터 레이크는 데이터 품질, 거버넌스 및 규정 준수에 있어 중추적인 역할을 하는데, 특히 데이터 레이크에서 저장하는 중요한 비즈니스 데이터의 양이 증가함에 따라 업데이트 또는 삭제가 필요한 경우가 많습니다. 또한 데이터 중심 조직은 백엔드 분석 시스템을 고객 애플리케이션과 거의 실시간으로 동기화해야 합니다. 이 시나리오에서는 데이터 무결성 저하 없이 동시 쓰기 및 읽기를 지원할 수 있는 데이터 레이크의 트랜잭션 기능이 필요합니다. 마지막으로, 이제 데이터 레이크는 통합 지점 역할을 하므로 다양한 소스 간에 안전하고 신뢰할 수 있는 데이터 이동을 위한 트랜잭션이 필요합니다.
데이터 레이크 테이블의 트랜잭션 의미 체계를 지원하기 위해 조직에서는 Apache Iceberg와 같은 오픈 테이블 형식(OTF)을 채택했습니다. OTF 형식을 채택하는 데에는 몇 가지 어려움이 따릅니다. 예를 들어 기존 데이터 레이크 테이블을 Parquet 또는 Avro 형식에서 OTF 형식으로 변환하거나, 각 트랜잭션이 Amazon Simple Storage Service(S3)에서 새 파일을 생성할 때마다 많은 수의 작은 파일을 관리하거나, 대규모로 개체 및 메타데이터 버전 관리를 관리해야 합니다. 일반적으로 조직은 이러한 문제를 해결하기 위해 자체 데이터 파이프라인을 구축하고 관리하며, 이로 인해 인프라에 대한 차별화되지 않은 작업이 추가로 발생합니다. 코드를 작성하고, Spark 클러스터를 배포하여 코드를 실행하고 클러스터 규모를 조정하며 오류를 관리하는 등의 작업을 수행해야 합니다.
여기서 가장 어려운 점은 테이블에 트랜잭션을 기록할 때마다 생성되는 작은 개별 파일을 몇 개의 큰 파일로 압축하는 일이라는 사실을 고객과 이야기를 나누면서 알게 되었습니다. 대용량 파일은 더 빠르게 읽고 스캔할 수 있으므로 분석 작업과 쿼리를 더 빠르게 실행할 수 있습니다. 압축은 파일 크기가 큰 테이블 스토리지를 최적화합니다. 테이블의 스토리지는 다수의 작은 파일에서 소수의 큰 파일로 바뀝니다. 또한 메타데이터 오버헤드를 줄이고 S3로의 네트워크 왕복을 줄이며 성능을 개선합니다. 컴퓨팅 비용을 청구하는 엔진을 사용하면 쿼리를 실행하는 데 필요한 컴퓨팅 파워가 줄어들기 때문에 성능이 향상되어 사용 비용에도 도움이 됩니다.
하지만 Iceberg 테이블을 압축하고 최적화하기 위한 맞춤형 파이프라인을 구축하는 데는 시간과 비용이 많이 듭니다. 계획을 관리하고 인프라를 프로비저닝하며 압축 작업을 예약하고 모니터링해야 합니다. 이것이 바로 AWS에서 오늘 자동 압축 기능을 출시하는 이유입니다.
작동 방식
Iceberg 테이블에서 자동 압축을 활성화하고 모니터링하는 방법을 설명하기 위해 먼저 AWS Management Console의 AWS Lake Formation 페이지 또는 AWS Glue 페이지부터 살펴보겠습니다. 여기 Iceberg 형식의 테이블이 있는 기존 데이터베이스가 하나 있습니다. 며칠 동안 이 테이블에서 트랜잭션을 실행하면 테이블이 기본 S3 버킷에서 작은 파일로 조각화되기 시작합니다.

압축을 활성화하려는 테이블을 선택한 다음, Enable compaction(압축 활성화)을 선택합니다.
AWS Glue 테이블, S3 버킷 및 CloudWatch 로그 스트림에 액세스할 수 있는 권한을 Lake Formation 서비스에 전달하려면 IAM 역할이 필요합니다. 새 IAM 역할을 생성하거나 기존 IAM 역할을 선택합니다. 기존 역할에는 테이블에 대한 lakeformation:GetDataAccess 및 glue:UpdateTable 권한이 있어야 합니다. 또한 이 역할에는 logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents를 “arn:aws:logs:*:your_account_id:log-group:/aws-lakeformation-acceleration/compaction/logs:*”로 설정해야 합니다. 역할이 신뢰할 수 있는 권한 서비스의 이름은 glue.amazonaws.com으로 설정해야 합니다.
그런 다음, Turn on compaction(압축 켜기)을 선택합니다. 짠! 압축은 자동으로 이루어지므로 따로 관리할 필요가 없습니다.
서비스가 테이블의 변경 비율을 측정하기 시작합니다. Iceberg 테이블에는 파티션이 여러 개가 있을 수 있으므로 서비스에서는 각 파티션에 대해 이 변경 비율을 계산하고 이 변경 비율이 임계값을 위반하는 경우 파티션을 압축하도록 관리 작업을 예약합니다.
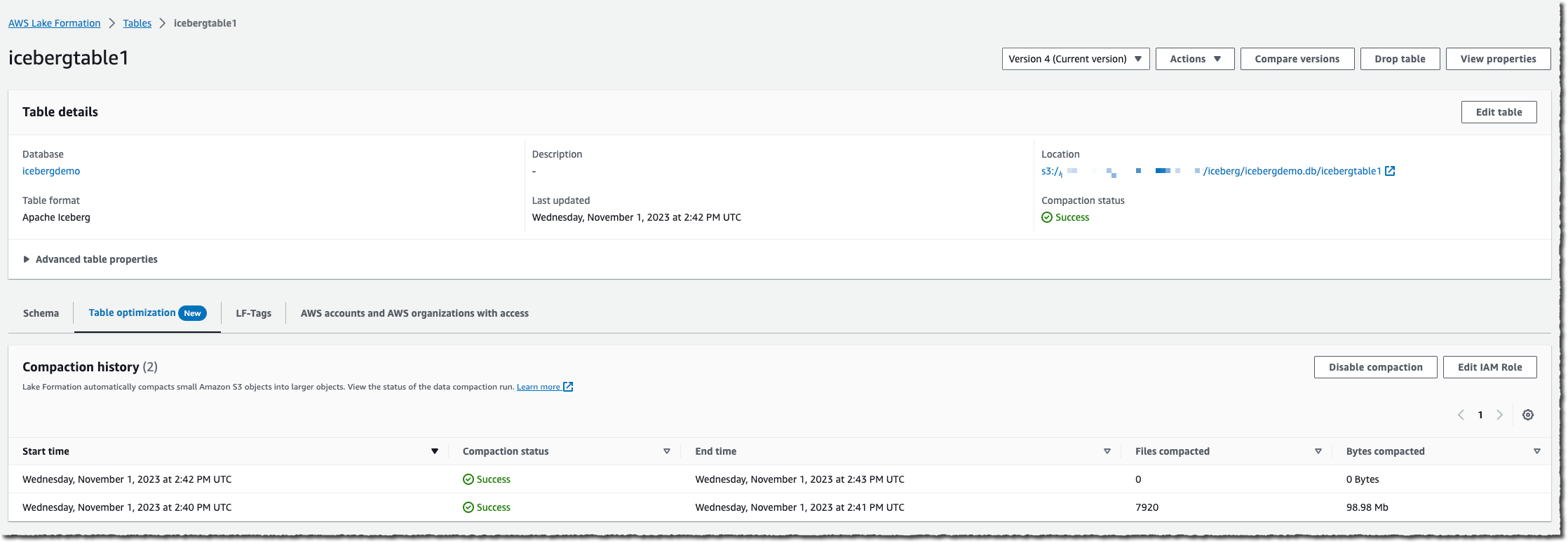
테이블에 변경 사항이 많이 누적되면 콘솔의 Optimization(최적화) 탭에서 Compaction history(압축 이력)를 볼 수 있습니다.
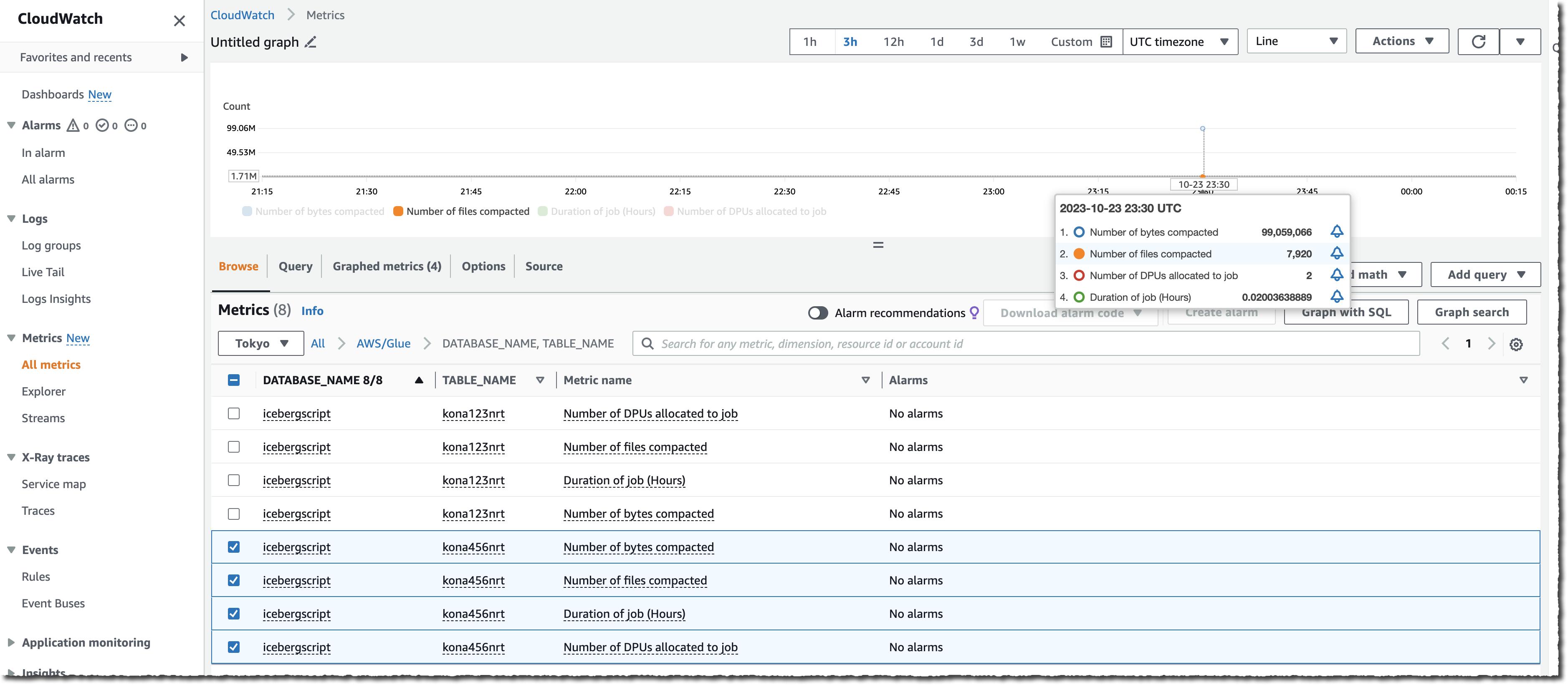
또한 S3 버킷에 있는 파일 수(NumberOfObjects 지표 사용)를 관찰하거나 두 개의 새로운 Lake Formation 지표인 numberOfBytesCompacted 또는 numberOfFilesCompacted 중 하나를 관찰하여 전체 프로세스를 모니터링할 수도 있습니다.
AWS Console 외에도 이 새로운 기능을 보여주는 6개의 새로운 API가 있는데 CreateTableOptimizer, BatchGetTableOptimizer, UpdateTableOptimizer, DeleteTableOptimizer, GetTableOptimizer 및 ListTableOptimizerRuns입니다. 이러한 API는 AWS SDK 및 AWS Command Line Interface(AWS CLI)에서 사용할 수 있습니다. 이 새로운 API를 사용하려면 언제나 그렇듯 SDK 또는 CLI를 최신 버전으로 업데이트해야 합니다.
알아야 할 사항
오늘 이 새로운 기능을 출시하면서 몇 가지 추가 사항을 알려드리고 싶습니다.
- 압축 시 삭제 파일은 병합되지 않습니다. 삭제된 데이터가 있는 테이블은 압축되지만 이와 관련된 삭제 파일이 있는 데이터 파일은 건너뛰게 됩니다.
- VPC 엔드포인트를 통해 VPC에서 단독 액세스하도록 구성된 S3 버킷은 지원되지 않습니다.
- Apache Parquet을 사용하여 데이터를 저장하는 Apache Iceberg 테이블을 압축할 수 있습니다.
- 압축은 기본 서버 측 암호화(SSE-S3)로 암호화된 버킷 또는 KMS 관리 키를 사용한 서버 측 암호화(SSE-KMS)로 암호화된 버킷에서 작동합니다.
가용성
이 새로운 기능은 AWS Glue 데이터 카탈로그를 사용할 수 있는 AWS 리전은 US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Tokyo), 그리고 Europe (Ireland)에서 오늘부터 사용 가능합니다.
가격 지표는 컴퓨팅 용량의 vCPU 4개와 16GB 메모리로 구성된 처리 능력의 상대 척도인 데이터 처리 장치(DPU)입니다. 초 단위로 측정되는 DPU/시간당 요금이 부과되며 최소 단위는 1분입니다.
이제 기존의 압축 데이터 파이프라인을 폐기하고 이 새로운 완전 관리형 기능으로 전환할 차례입니다.