Amazon Web Services 한국 블로그
Elastic Map Reduce 4.0.0 버전 출시 – 최신 업데이트 추가
Amazon EMR은 Apache Hadoop과 Apache Spark 등 빅데이터 프레임 워크를 쉽게 AWS 내에서 실행하여 대량 데이터 분석을 할 수 있도록 지원하는 클러스터 관리 플랫폼입니다. 이러한 프레임 워크와 Apache Hive와 Apache Pig 등 관련 오픈 소스 프로젝트를 함께 사용하여 데이터 분석 목적과 지능형 비즈니스(BI) 분석 등을 할 수 있습니다. 2009년에 처음 출시한 이후 (Announcing Amazon Elastic MapReduce), 그동안 다양한 콘솔 기능 지원과 많은 주요 기능 추가를 진행해왔습니다. 최근 몇 가지 기능 추가 소식은 아래와 같습니다.
- S3 암호화 지원 시작 (서버 및 클라이언트 양쪽 모두 지원).
- EMR의 파일 시스템의 일관성 (EMRFS).
- Hive/DynamoDB Connector를 활용한 데이터 가져오기/내보내기 및 질의
- CloudWatch 측정 수치 개선
오늘 Amazon EMR 4.0.0 버전을 발표합니다.
신규 버전은 기존 플랫폼에 많은 변화를 가져옵니다.특히, Hadoop 및 Spark의 최신 버전을 포함하고 있어 기존 클러스터에 설치 가능한 응용 프로그램의 설정 방법이 크게 개선됩니다. Hadoop과 Spark의 몇 가지 표준 및 규약을 준수하도록 일부 포트 및 경로 설정을 조정했습니다. 다른 AWS 서비스가 특정 버전 별로 출시하지 않고 뒤에서 지속적으로 자주 업데이트가 이루어지고 있는 것과는 달리 EMR은 기존 오픈 소스 버전 기반 출시를 해오고 있기 때문에 특정 EMR 버전에서만 사용할 수 있는 기능과 응용 프로그램을 사용하는 프로그램이나 스크립트를 작성할 수 있습니다.
만약 현재 AMI 버전 2.x 또는 3.x를 사용하시는 경우, 4.0.0으로 어떻게 마이그레이션할 것인지는 EMR 버전별 가이드를 읽어 보시기 바랍니다.
응용 프로그램 업데이트
EMR 사용자는 Hadoop 플랫폼 생태계 내 여러 응용 프로그램을 사용할 수 있습니다. 이 버전의 EMR은 다음 업데이트가 추가되었습니다:
- Hadoop 2.6.0 – 다수의 일반 기능과 사용성 개선 사항이 포함
- Hive 1.0 – 성능 개선, SQL 지원의 추가 몇 가지 보안 기능 포함
- Pig 0.14 – ORCStorage 클래스 성능 개선, Predicate Pushdown, 버그 수정 등
- Spark 1.4.1 – SparkR을 위한 바인딩과 새로운 Dataframe API 및 다양한 기능 추가 및 버그 수정 포함
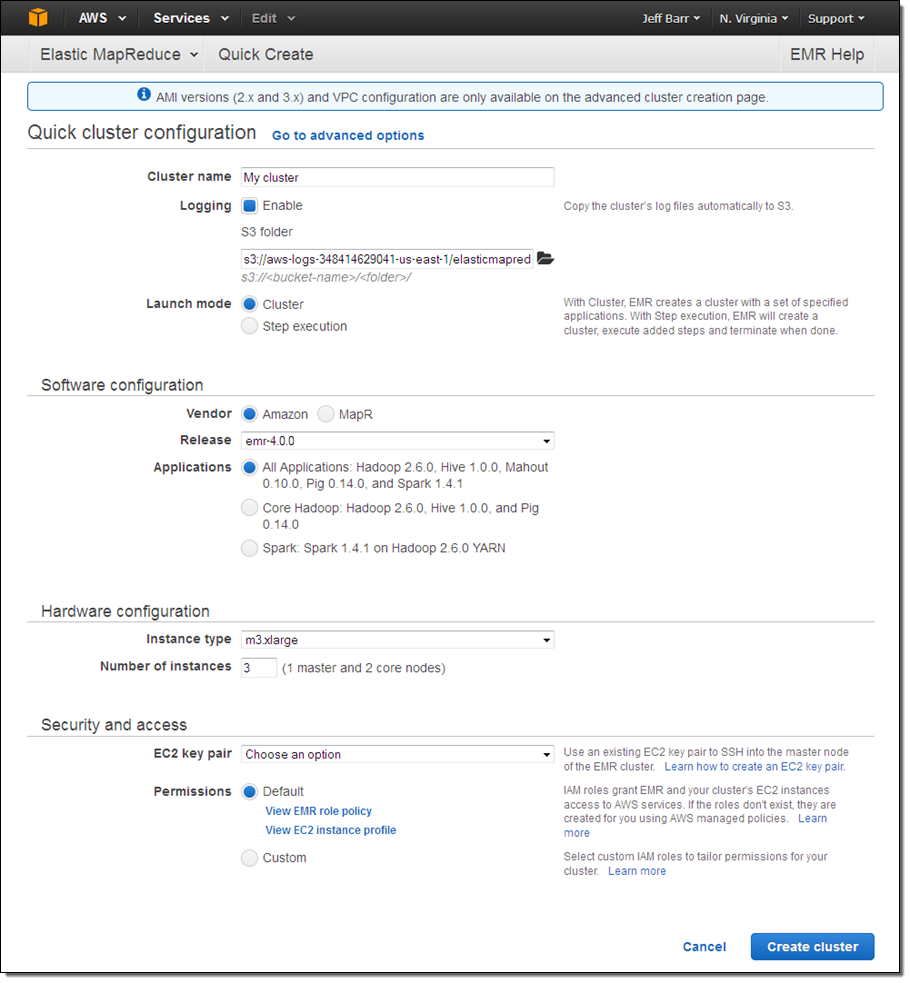
콘솔에서 빠른 클러스터 생성
콘솔에서 빠른 클러스터 설정(Quick cluster configuration)을 사용하여 EMR 클러스터를 만들 수 있습니다:
응용 프로그램 설정 편집 개선
Amazon EMR AMI 버전 2.x 및 3.x에서는 클러스터 내 응용 프로그램 설정을 위해 bootstrap action을 주로 사용하였습니다. Amazon EMR 버전 4.0.0에서는 클러스터를 만들 때 응용 프로그램의 기본 설정을 편집하는 직접적인 방법을 제공하도록 개선하였습니다. 편집할 설정 파일의 목록과 그 파일의 변경 사항 설정 개체를 전달할 수 있는 기능을 추가했습니다. 설정 객체는 CLI 또는 EMR API와 콘솔에서 만들어 볼 수 있습니다. 설정 정보는 로컬이나 Amazon Simple Storage Service (S3)에 저장하여 참조 할 수 있습니다 (콘솔을 사용하는 경우, 설정 값을 지정하거나 설정 파일을 사용하기 위해 클러스터를 만들 때 Go to advanced options를 클릭하십시오).
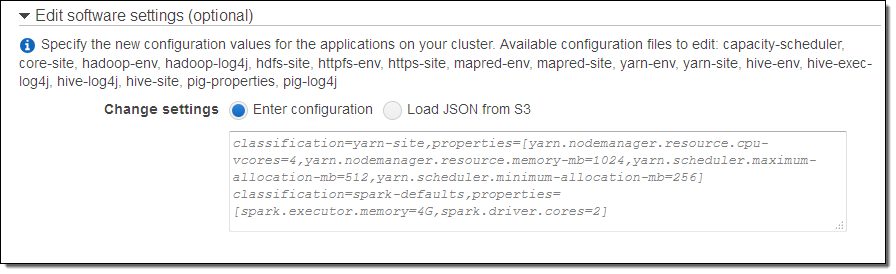
더 자세한 내용은 응용 프로그램 설정 문서를 살펴 보시기 바랍니다.
새로운 패키징 시스템 / 표준 포트와 경로
신규 버전에서는 Apache Bigtop 기반의 새로운 패키징 시스템을 출시했습니다. 이를 통해 더 빨리 새로운 응용 프로그램이나 새 버전을 EMR에 추가 할 수 있습니다.
또한, EMR 버전 4.0.0의 많은 포트와 경로를 오픈 소스 표준으로 변경했습니다. 이러한 변경 사항에 대한 자세한 정보는 4.x 변경 사항 문서를 살펴 보시기 바랍니다.
Spark를 위한 EMR 추가 설정
EMR 개발팀에서는 몇 가지 기술 팁을 여러분께 공유 드리고자 합니다.
Spark on YARN은 Spark 응용 프로그램에 사용되는 executor의 수를 동적으로 확장 할 수 있습니다. 하나의 executor가 사용하는 메모리(spark.executor.memory)와 코어(spark.executor.cores)는 spark-defaults에서 지정할 필요가 있으나, YARN은 Spark 응용 프로그램이 필요한 만큼의 executor를 자동으로 할당하게 됩니다. 동적 executor 할당을 활성화하려면 spark-defaults 설정 파일에서 spark.dynamicAllocation.enabled을 true로 설정합니다. 또한, Spark shuffle service가 Amazon EMR에서는 처음부터 활성화되어 있으므로 직접 설정할 필요가 없습니다.
클러스터 작성 시 maximizeResourceAllocation 옵션을 true로 하면 executor가 각 노드에서 사용 가능한 자원을 최대한 활용하도록 설정할 수 있습니다. 클러스터를 만들 때 설정 개체에서 “spark” 클래스 속성을 추가하여 설정할 수 있습니다. 이 옵션은 core node group 노드에서 사용 가능한 최대 CPU와 메모리 자원을 계산하여 이 정보를 바탕으로 관련 spark-defaults 값을 설정합니다. 클러스터 생성 시 지정된 첫 번째 core node의 숫자로 spark.executor.instances을 설정하여 executor 수도 정합니다. 참고로 이러한 설정은 동적 executor 할당과 함께 사용할 수 없습니다.
이러한 옵션에 대한 더 자세한 내용은 Configure Spark 문서를 살펴 보시기 바랍니다.
정식 출시
위의 모든 기능은 지금부터 이용 가능하며, 오늘부터 사용하실 수 있습니다.
만약 대규모 데이터 처리 및 EMR 사용이 처음이라면, Amazon EMR 시작하기 문서를 참조하십시오. 새로운 동영상 소개와 교육 및 프로페셔널 서비스에 대한 정보를 볼 수 있습니다. 빠르고 효율적으로 EMR에 대해 공부하실 수 있습니다.
— Jeff;
이 글은 Elastic MapReduce Release 4.0.0 With Updated Applications Now Available의 한국어 번역입니다.