AWS News Blog
Elastic MapReduce Release 4.0.0 With Updated Applications Now Available
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. By using these frameworks and related open-source projects, such as Apache Hive and Apache Pig, you can process data for analytics purposes and business intelligence workloads. First launched in 2009 (Announcing Amazon Elastic MapReduce), we have added comprehensive console support and many, many features since then. Some of the most recent features include:
- Support for S3 encryption (both server-side and client-side).
- Consistent view for the EMR Filesystem (EMRFS).
- Data import, export, and query via the Hive / DynamoDB Connector.
- Enhanced CloudWatch metrics.
Today we are announcing Amazon EMR release 4.0.0, which brings many changes to the platform. This release includes updated versions of Hadoop ecosystem applications and Spark which are available to install on your cluster and improves the application configuration experience. As part of this release we also adjusted some of the ports and paths so as to be in better alignment with several Hadoop and Spark standards and conventions. Unlike the other AWS services which do not emerge in discrete releases and are frequently updated behind the scenes, EMR has versioned releases so that you can write programs and scripts that make use of features that are found only in a particular EMR release or a version of an application found in a particular EMR release.
If you are currently using AMI version 2.x or 3.x, read the EMR Release Guide to learn how to migrate to 4.0.0.
Application Updates
EMR users have access to a number of applications from the Hadoop ecosystem. This version of EMR features the following updates:
- Hadoop 2.6.0 – This version of Hadoop includes a variety of general functionality and usability improvements.
- Hive 1.0 -This version of Hive includes performance enhancements, additional SQL support, and some new security features.
- Pig 0.14 – This version of Pig features a new ORCStorage class, predicate pushdown for better performance, bug fixes, and more.
- Spark 1.4.1 – This release of Spark includes a binding for SparkR and the new Dataframe API, plus many smaller features and bug fixes.
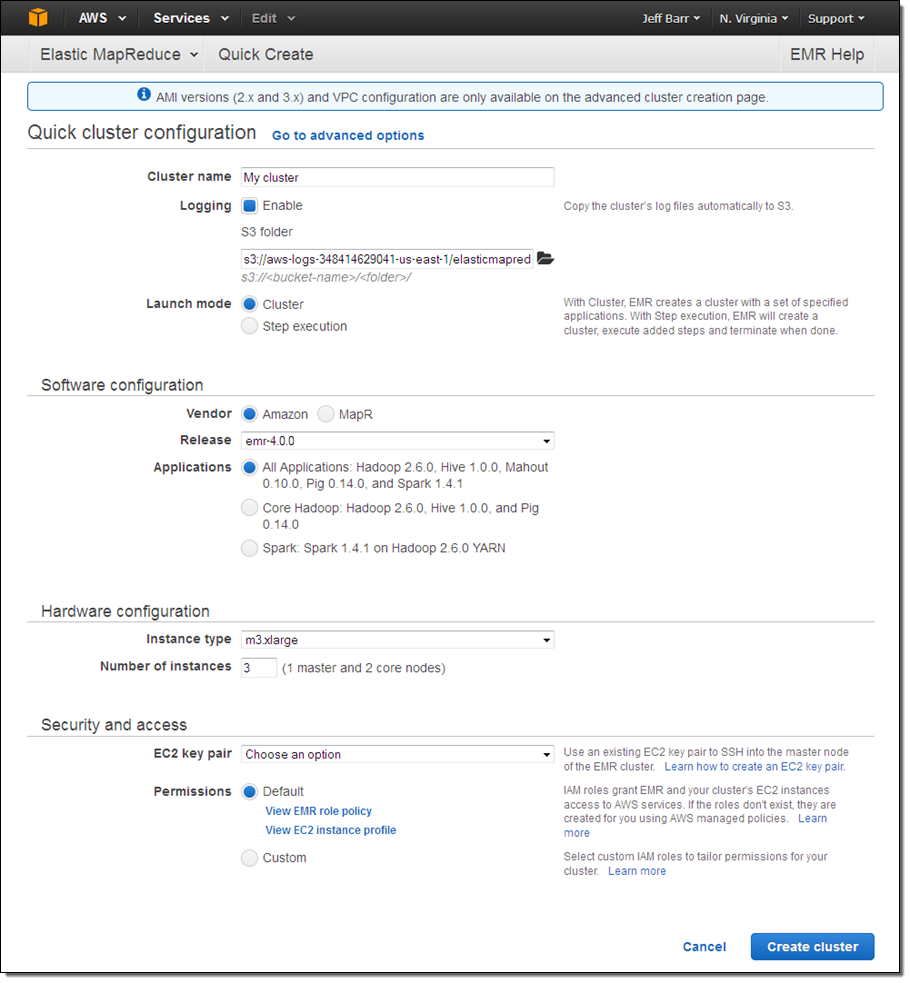
Quick Cluster Creation in Console
You can now create an EMR cluster from the Console using the Quick cluster configuration experience:
Improved Application Configuration Editing
In Amazon EMR AMI versions 2.x and 3.x, bootstrap actions were primarily used to configure applications on your cluster. With Amazon EMR release 4.0.0, we have improved the configuration experience by providing a direct method to edit the default configurations for applications when creating your cluster. We have added the ability to pass a configuration object which contains a list of the configuration files to edit and the settings in those files to be changed. You can create a configuration object and reference it from the CLI, the EMR API, or from the Console. You can store the configuration information locally or in Amazon Simple Storage Service (Amazon S3) and supply a reference to it (if you are using the Console, click on Go to advanced options when you create your cluster in order to specify configuration values or to use a configuration file):
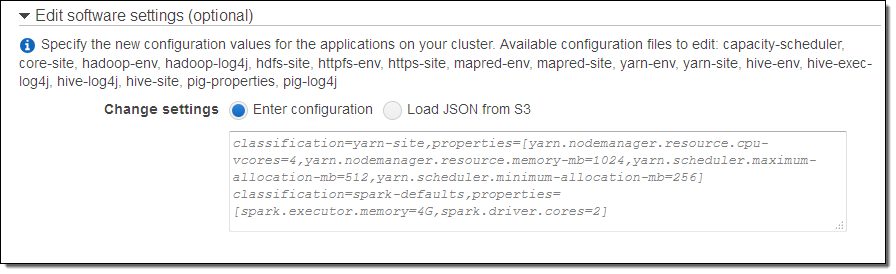
To learn more, read about Configuring Applications.
New Packaging System / Standard Ports & Paths
Our release packaging system is now based on Apache Bigtop. This will allow us to add new applications and new applications to EMR even more quickly.
Also, we have moved most ports and paths on EMR release 4.0.0 to open source standards. For more information about these changes read Differences Introduced in 4.x.
Additional EMR Configuration Options for Spark
The EMR team asked me to share a couple of tech tips with you:
Spark on YARN has the ability to dynamically scale the number of executors used for a Spark application. You still need to set the memory (spark.executor.memory) and cores (spark.executor.cores) used for an executor in spark-defaults, but YARN will automatically allocate the number of executors to the Spark application as needed. To enable dynamic allocation of executors, set spark.dynamicAllocation.enabled to true in the spark-defaults configuration file. Additionally, the Spark shuffle service is enabled by default in Amazon EMR, so you do not need to enable it yourself.
You can configure your executors to utilize the maximum resources possible on each node in your cluster by setting the maximizeResourceAllocation option to true when creating your cluster. You can set this by adding this property to the “spark” classification in your configuration object when creating your cluster. This option calculates the maximum compute and memory resources available for an executor on a node in the core node group and sets the corresponding spark-defaults settings with this information. It also sets the number of executors—by setting spark.executor.instances to the initial core nodes specified when creating your cluster. Note, however, that you cannot use this setting and also enable dynamic allocation of executors.
To learn more about these options, read Configure Spark.
Available Now
All of the features listed above are available now and you can start using them today
If you are new to large-scale data processing and EMR, take a look at our Getting Started with Amazon EMR page. You’ll find a new tutorial video, along with information about training and professional services, all aimed at getting you up and running quickly and efficiently.
— Jeff;