AWS 기술 블로그
Enterprise Agentic AI를 위한 Amazon Bedrock AgentCore Built-in Tools: Code Interpreter and Browser Tool
인공지능이 ‘말하는 존재’에서 ‘행동하는 존재’로 진화하다
인공지능은 오랫동안 언어를 이해하고 생성하는 영역에 머물러 있었습니다. 대규모 언어 모델(LLM, Large Language Model)의 발전은 문맥 이해, 번역, 요약, 대화 등에서 인간 수준의 성과를 보여주었지만, 그 모든 능력은 여전히 “예측(prediction)”의 한계를 벗어나지 못했습니다. 즉, LLM은 데이터를 기반으로 가장 가능성이 높은 단어를 생성할 뿐, 실제 계산이나 검증을 수행하지 못했습니다.
그러나 엔터프라이즈 환경에서 진정한 AI의 가치는 단순한 언어 예측이 아니라 행동(action) 에서 비롯됩니다. 기업이 기대하는 AI는 데이터를 직접 분석하고, 코드를 실행하며, 실시간 정보를 활용해 스스로 판단하고 검증할 수 있어야 합니다. 이러한 패러다임의 전환은 바로 Agentic AI, 즉 “스스로 사고하고 실행하는 지능형 에이전트”의 시대를 여는 핵심 개념입니다.
Amazon은 이러한 변화의 중심에서 Bedrock AgentCore를 통해 완전한 Enterprise Agentic AI 플랫폼을 구현했습니다. AgentCore는 모델 추론, 메모리 관리, 보안 정책, 그리고 도구 실행 환경을 하나로 통합한 엔터프라이즈급 AI 인프라이며, 그 핵심에는 Built-in Tools인 Code Interpreter와 Browser Tool이 있습니다. 이 두 도구는 LLM이 단순한 언어 생성기를 넘어, 실제로 코드를 실행하고 웹을 탐색하며, 검증 가능한 결과를 산출하는 능동적 에이전트로 발전하도록 설계되었습니다.
지금까지의 LLM은 학습 시점에 고정된 데이터에 의존하기 때문에, 최신 정보를 반영하거나 실제 데이터를 분석·검증하는 데 한계가 있었습니다. 기업은 이를 보완하기 위해 외부 API를 직접 연결하거나 별도의 Python 환경을 운영해왔지만, 이 방식은 복잡하고 보안 및 일관성 유지가 어렵다는 문제가 있었습니다. Bedrock AgentCore는 이 문제를 근본적으로 해결합니다. Code Interpreter는 모델이 직접 코드를 실행하여 데이터를 계산·분석하고, 그 결과를 바탕으로 신뢰도 높은 인사이트를 제공합니다. Browser Tool은 실시간으로 웹을 탐색하여 최신 정보를 확보함으로써, 빠르게 변화하는 외부 환경에 대응할 수 있도록 합니다.
이처럼 Amazon Bedrock AgentCore의 Built-in Tools은 Agentic AI가 요구하는 “지능적 행동력”을 구현함으로써, AI가 언어를 넘어 현실 세계와 상호작용하며 스스로 검증하는 엔터프라이즈급 지능체계로 진화하도록 돕습니다. 이를 통해 고객은 정확하고 신뢰할 수 있는 AI 기반 의사결정 환경을 구축하고, 데이터 분석과 업무 자동화를 한 단계 높일 수 있으며, 더 나아가 AI가 실제로 행동하는 기업형 Agentic Intelligence를 실현할 수 있습니다.
LLM의 본질적 한계: 추론은 언어가 아니다
언어 모델의 추론 능력은 통계적 예측의 산물입니다. 하지만 현실의 문제는 단순히 말로 해결되지 않습니다. 예를 들어 “2023년 이후 매출 성장률을 기반으로 2026년 순이익을 예측하라”는 질문을 받았을 때, LLM은 문맥적으로 그럴듯한 답을 생성할 수 있지만, 실제 계산을 수행하거나 그 결과가 실제 데이터와 일치하는지 스스로 확인할 수 없습니다.
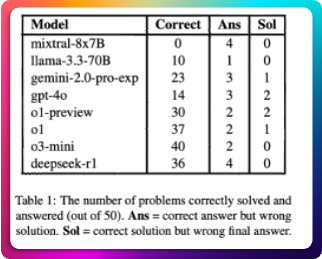
이 한계를 학문적으로 분석한 연구들이 있습니다. ‘Boye & Moëll(2025)’의 논문 “Large Language Models and Mathematical Reasoning Failures (arXiv:2502.11574)” 은 LLM이 단계적 수학 추론을 수행할 때 내부 일관성이 붕괴하는 패턴을 통계적으로 입증했습니다. 모델은 자연어 표현에는 능하지만, 논리적 검증 단계에서는 오류를 범하는 경향을 보입니다. 이 문제를 해결하기 위한 연구의 방향은 명확했습니다. “LLM이 스스로 코드를 작성하고 실행하게 하자.” 즉, 모델이 자연어 명령을 해석해 코드를 생성하고, 그 코드를 실제 실행 환경에서 돌려 나온 결과를 학습 피드백으로 사용하는 것입니다.
Boye & Moëll(2025), “Large Language Models and Mathematical Reasoning Failures
2025년 ‘Chen et al.’이 발표한 “R1-Code-Interpreter: R1-Code-Interpreter: LLMs Reason with Code via Supervised and Multi-stage Reinforcement Learning (arXiv:2505.21668)” 는 이 접근법을 실험적으로 증명했습니다. 코드 실행 결과를 피드백으로 사용한 LLM은 순수 언어 추론 모델보다 논리 일관성이 46% → 87%로 향상되었습니다. 이 연구는 AI가 언어를 넘어 행동으로 나아가기 위해 “코드 실행”이 필수적임을 보여주었습니다.
Chen et al.(2025), R1-Code-Interpreter: Training LLMs to Reason with Code
Code Interpreter의 등장: 실행을 통한 검증
Amazon Bedrock AgentCore의 Code Interpreter는 이 연구적 전환을 실제 산업 환경에 적용한 결과물입니다. 이 도구는 AI가 생성한 코드를 격리된 보안 환경에서 실행하고, 그 결과를 다시 모델의 컨텍스트로 되돌려주는 완전 관리형 서비스입니다. 이 구조는 LLM이 단순히 “정답을 추측하는 모델”이 아니라, 결과를 스스로 검증하는 모델로 진화할 수 있게 합니다. 즉, 언어 모델의 한계를 “검증 가능한 실행(Verifiable Execution)”으로 보완합니다. 그 결과 Code Interpreter는 AI가 생성한 코드가 운영 환경을 침범하지 않으면서도 완전한 컴퓨팅 자원을 사용할 수 있도록 보장합니다.
Code Interpreter의 실행 구조
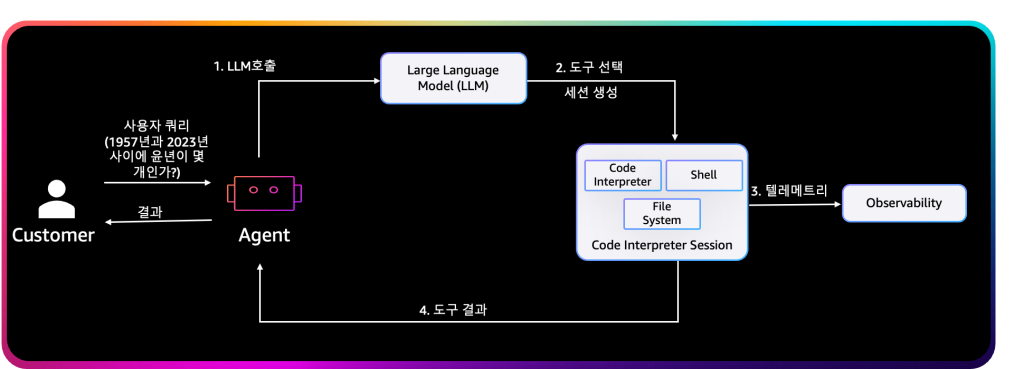
1. 요청 처리
사용자의 자연어 명령이 Bedrock 에이전트에 전달되면, AgentCore는 이 명령을 분석하여 “Code Execution Tool” 호출이 필요한지를 결정합니다. 예를 들어 사용자가
“CSV 파일에서 2023년 매출 합계를 계산해줘.”
라고 입력하면, 모델은 내부 계획 단계에서
“execute_python 호출 필요”라는 판단을 내립니다.
이후 요청은 AgentCore Gateway를 통해 SigV4 서명으로 인증되고, Firecracker 기반의 독립 세션이 생성됩니다.
2. 격리 환경에서 실행
모든 코드는 Firecracker MicroVM 안에서 실행됩니다. 이 환경은 AWS Lambda와 동일한 격리 계층을 사용하며, CPU, 메모리, 스토리지 자원이 세션 단위로 독립 배정됩니다. 세션 종료 시 모든 파일, 메모리 페이지, 임시 디스크가 삭제되며 네트워크 접근은 기본적으로 차단됩니다. 이는 NIST SP 800-53 Rev. 5의 SC-7(System Protection)과 AC-6(Least Privilege) 항목을 준수하는 구조입니다. 데이터 입출력은 IAM Execution Role 정책을 통해 통제되며, Amazon S3, Amazon DynamoDB, Amazon Redshift 등과 안전하게 연동할 수 있습니다.
3. 결과 반환 및 검증
실행 결과는 JSON 형태로 직렬화되어 모델의 컨텍스트로 반환됩니다. Bedrock 에이전트는 이 데이터를 기반으로 추가 추론을 수행하거나, 결과를 Browser Tool로 전달해 시각화할 수 있습니다. 이 전 과정이 CloudTrail 이벤트로 로깅되어 운영자와 보안 감사팀이 모든 실행을 추적할 수 있습니다. 위와 같은 작동 방식을 통하여 예를 들어 “지난 5년간 윤년의 수를 계산하라”는 요청이 들어오면, 모델은 다음과 같은 코드를 생성합니다.
count = 0
for year in range(2019, 2025):
if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0):
count += 1
print(count)
이 코드는 Code Interpreter 세션 내에서 실행되고, 출력 결과(2)가 모델에게 JSON 형태로 전달됩니다. 이제 모델은 자신이 “예측”한 것이 아니라 “검증된 결과”를 사용자에게 제시하게 됩니다.
AgentCore Code Interpreter 동작 과정
AgentCore Code Interpreter 의 동작 방식을 깊게 알아보기
AgentCore System Code Interpreter: 서버리스 환경에서의 안전한 코드 실행
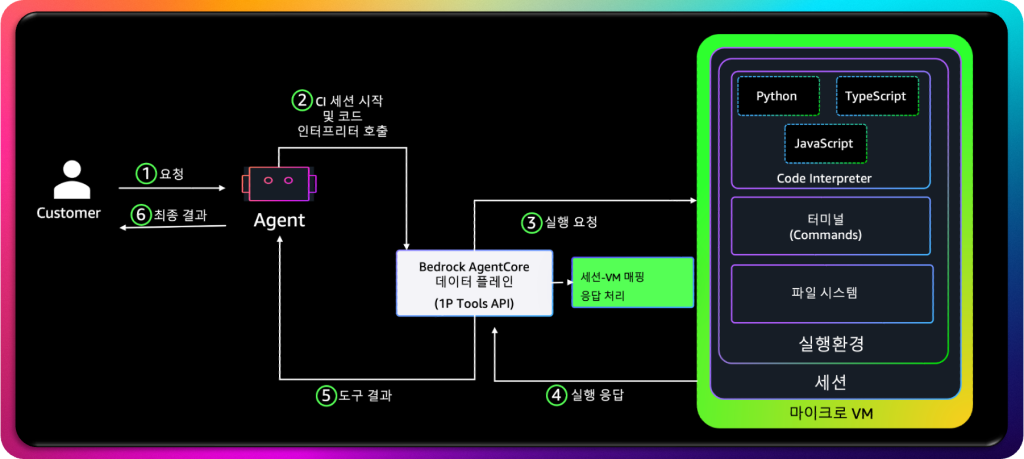
Amazon Bedrock AgentCore의 System Code Interpreter는 완전 관리형 서버리스(Serverless) 런타임 환경으로, AI 에이전트가 외부 인프라 구성 없이도 코드를 실행하고 데이터를 분석할 수 있도록 설계된 도구입니다. 이 구조의 핵심은 보안성과 실행 효율성의 균형에 있습니다. 즉, 사용자는 별도의 VM을 직접 생성하거나 네트워크를 구성할 필요 없이 AgentCore의 API 호출 한 번만으로 안전한 코드 실행 환경을 얻을 수 있습니다.
System Code Interpreter는 Amazon Bedrock의 데이터 플레인(Data Plane)을 통해 동작합니다. 고객이 요청을 보내면, LLM 기반 에이전트가 해당 요청을 분석하고 코드 실행이 필요한 경우 자동으로 Code Interpreter 세션을 시작합니다. 이때 Bedrock AgentCore는 내부적으로 Firecracker 기반의 마이크로 VM(Micro VM) 을 할당하여 각 실행 세션을 완전히 격리된 환경에서 처리합니다. 이 격리 구조는 코드 실행 중 발생할 수 있는 보안 위험, 데이터 누출, 또는 외부 네트워크 접근 문제를 원천적으로 차단합니다.
실행 요청은 AgentCore의 1P Tools API를 통해 전달되며, AgentCore는 세션과 VM을 매핑한 뒤 해당 환경에서 Python, JavaScript, 또는 TypeScript 코드를 수행합니다. 각 세션은 독립적인 파일 시스템과 명령 터미널을 포함하며, 일반적인 코드 실행뿐만 아니라 임시 데이터 저장, 로깅, CLI 기반 연산까지 지원합니다. 또한, Amazon S3와의 통합을 통해 최대 5GB까지의 대용량 데이터를 다룰 수 있습니다. 이 덕분에 단순한 스크립트 실행을 넘어, 데이터 분석과 모델 결과 검증, 구조화된 파일 입출력까지 원활하게 수행할 수 있습니다.
보안 측면에서도 Bedrock은 System Code Interpreter에 CloudTrail 로그와 CloudWatch 메트릭을 기본적으로 통합하여 모든 세션의 실행 이력과 리소스 사용량을 추적할 수 있도록 했습니다. 운영자는 각 코드 실행이 언제, 어떤 세션에서, 어떤 언어로 수행되었는지를 실시간으로 모니터링할 수 있으며, 이는 AI 기반 자동화 환경에서 필수적인 운영 투명성(Operational Transparency)을 제공합니다. 세션은 기본적으로 15분 동안 유지되며, 필요에 따라 최대 8시간까지 확장할 수 있습니다. Bedrock은 이를 통해 실험적 코드 실행부터 장기 분석 작업까지 폭넓은 사용 시나리오를 지원합니다.
결국, System Code Interpreter는 “보안 샌드박스”라는 개념을 엔터프라이즈 수준으로 끌어올린 사례라 할 수 있습니다. LLM 에이전트가 외부 명령을 실행하더라도, 모든 코드가 독립된 환경에서 제한된 권한으로 실행되며, 사용자는 이 과정을 실시간으로 감시할 수 있습니다. 이 구조는 AI가 데이터를 “이해하고, 계산하며, 증명하는” 과정의 첫 번째 단계이자, Amazon Bedrock이 추구하는 안전한 실행형 인공지능(Executable AI) 의 기반이 됩니다.
AgentCore System Code Interpreter 동작 과정
AgentCore Custom Code Interpreter: 확장 가능한 엔터프라이즈용 샌드박스
Custom Code Interpreter는 System Code Interpreter를 기반으로 하면서도 엔터프라이즈 환경에서 필요한 세밀한 제어권을 제공합니다. 이 도구는 동일한 실행 모델 위에 설계되었지만, 추가적으로 IAM 역할, VPC 네트워크 구성, 런타임 커스터마이징 등 기업 맞춤형 보안 및 운영 요구사항을 반영할 수 있도록 확장되었습니다.
Custom Code Interpreter는 AgentCore의 컨트롤 플레인(Control Plane) 과 데이터 플레인(Data Plane) 이 함께 작동하는 이중 구조로 동작합니다. 먼저 에이전트는 사용자의 요청을 해석한 뒤, 컨트롤 플레인을 통해 새로운 Custom Code Interpreter 리소스를 생성합니다. 이 과정에서 사용자는 직접 IAM 실행 역할을 지정하거나, 사내 VPC 환경 내에서 실행되도록 네트워크 정책을 구성할 수 있습니다. 이렇게 생성된 Custom Interpreter는 고유한 리소스 ID를 부여받으며, 이후 동일한 데이터 플레인을 통해 코드 실행 요청을 전달받습니다.
실행 과정은 System Interpreter와 유사하지만, Custom Interpreter의 가장 큰 차별점은 “사용자가 실행 환경의 소유자”라는 점입니다. 즉, 기업은 자신들의 네트워크 정책과 데이터 거버넌스 정책에 맞춰 코드 실행 환경을 설계할 수 있습니다. 예를 들어 금융기관은 공공 네트워크 접근을 완전히 차단한 상태에서 내부 데이터베이스나 감사용 로그에 접근하는 Python 스크립트를 실행할 수 있고, 의료기관은 HIPAA 준수 환경 내에서 데이터 전처리 코드를 수행할 수 있습니다. 이러한 기능은 Bedrock의 보안 모델을 단순한 격리 수준에서 정책 기반 보안(Policy-based Security) 수준으로 확장시킵니다.
또한 Custom Interpreter는 장기 실행 작업과 CI/CD 파이프라인 통합에도 유용합니다. System Interpreter가 단기 세션 중심의 “즉시 실행형(Runtime)”이라면, Custom Interpreter는 반복적 분석이나 테스트 워크로드에 맞게 구성할 수 있습니다. 실행이 완료되면 관리자는 세션을 명시적으로 중지하고, 필요 시 해당 Custom Interpreter 리소스를 삭제할 수 있습니다. 이 단계적 종료 절차는 리소스 낭비를 방지하고, 보안 사고 가능성을 최소화하는 AWS 권장 운영 패턴입니다.
공식 개발자 문서에서는 이 구조를 “Enterprise-grade Compliance-ready Execution Sandbox”로 정의합니다. 이는 곧 Custom Code Interpreter가 단순히 코드를 실행하는 도구가 아니라, 조직의 보안 체계와 규제 준수 환경 내에서 AI가 안전하게 데이터를 처리할 수 있도록 보장하는 실행 프레임워크라는 의미입니다.
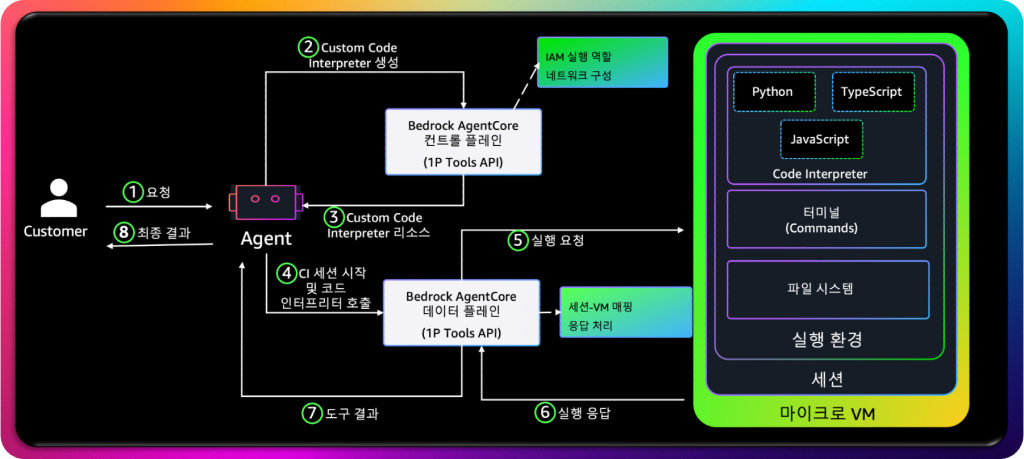
AgentCore Custom Code Interpreter 동작 과정
System Code Interpreter와 Custom Code Interpreter는 단순한 상하 관계가 아닙니다. 전자는 신속하고 안전한 서버리스 실험 환경을 제공하며, 후자는 조직 수준의 제어와 통제를 가능하게 하는 확장형 아키텍처입니다. Amazon Bedrock AgentCore는 이 두 구조를 통해
“누구나 바로 실행할 수 있는 안전한 기본 환경”과 “기업이 신뢰할 수 있는 맞춤형 환경”이라는 두 가지 목표를 동시에 충족시킵니다.
결국 이 두 Interpreter의 존재는 AI가 코드를 실행하는 과정을 완전히 “신뢰 가능한 행위(Trustworthy Execution)”로 만들기 위한 AWS의 답이라고 할 수 있습니다. 모든 세션은 기록되고, 모든 실행은 감사 가능하며, AI가 내리는 판단과 행동의 근거를 추적할 수 있는 투명한 구조를 유지합니다. 이것이 바로 Amazon Bedrock AgentCore가 다른 AI 플랫폼과 차별화되는 근본적인 이유이며, AI 시대의 “실행 가능한 신뢰(Executable Trust)”를 구현하는 설계 철학이 투영 된 것으로 불 수 있습니다.
AgentCore Code Interpreter 사용해보기
로우 레벨 Code Interpreter 실행
Code Interpreter 클라이언트를 직접 호출하는 가장 기본적인 형태입니다. 참고문헌 섹션의 AWS Labs GitHub에서 제공하는 샘플과 동일한 구조로, bedrock_agentcore.tools.code_interpreter_client 모듈의 CodeInterpreter 클래스가 핵심적인 역할을 수행합니다.
Code Interpreter는 아래와 같은 순서로 동작합니다:
- CodeInterpreter(region)으로 리전 기반 API 클라이언트를 초기화합니다.
- start()로 Firecracker 기반 세션을 생성하며, 이 세션은 기본적으로 15분 유지되고 최대 8시간까지 유지되도록 설정 가능합니다.
- invoke(“executeCode”, {…})를 호출하면 격리된 샌드박스에서 Python 코드를 실행합니다.
- 모든 실행 결과는 JSON 형태의 메시지 스트림으로 반환되며, CloudTrail에 이벤트가 기록됩니다.
from bedrock_agentcore.tools.code_interpreter_client import CodeInterpreter
import json
# 1. Code Interpreter 클라이언트 초기화
client = CodeInterpreter("us-west-2")
# 2. 샌드박스 세션 시작
client.start()
# 3. 코드 실행
response = client.invoke(
"executeCode",
{
"language": "python",
"code": 'print("Hello World!!!")',
"clearContext": False,
},
)
print(json.dumps(response, indent=2))
이 패턴은 단일 스크립트 환경에서 Code Interpreter를 활용해야 하는 경우에 적합합니다. 예를 들어,
- 데이터 분석 자동화 스크립트
- 서버리스 기반 데이터 품질 검증
- 파일 조작 및 EDA
등 위의 작업을 신속하게 과제 단위(evaluation unit)로 수행할 수 있습니다.
Agentic AI와의 연결 고리: Strands Agent기반 Code Interpreter 통합 에이전트
많은 엔터프라이즈는 Code Interpreter를 단독으로 사용하는 대신 에이전트의 “도구(tool)”로 통합하여 모델이 필요 시 자동 호출하도록 구성합니다. Strands는 도구 호출 기반의 Agentic 프레임워크이며, Code Interpreter는 “execute_python”이라는 도구로 래핑됩니다. 이 패턴은 AI 에이전트가 아래와 같은 흐름으로 작동하는 구조를 구현합니다:
- 모델이 사용자의 질문을 분석하여 “코드 실행 필요 여부”를 판단합니다.
- 모델은 자연어 명령을 바탕으로 Python 코드를 생성합니다.
- Code Interpreter 세션이 자동 생성되며 해당 코드를 실행합니다.
- 실행 결과는 다시 모델 컨텍스트로 주입되어 최종 답변이 생성됩니다.
Strands Agent를 활용한 Code Interpreter 사용은 아래와 같이 구현할 수 있습니다.
from bedrock_agentcore.tools.code_interpreter_client import code_session
from strands import Agent, tool
import json
SYSTEM_PROMPT = """
You are an assistant that validates important answers through code execution.
"""
@tool
def execute_python(code: str, description: str = "") -> str:
if description:
code = f"# {description}\n{code}"
with code_session("us-west-2") as code_client:
response = code_client.invoke(
"executeCode",
{
"code": code,
"language": "python",
"clearContext": False,
},
)
for event in response["stream"]:
return json.dumps(event["result"])
agent = Agent(
tools=[execute_python],
system_prompt=SYSTEM_PROMPT,
)
이 패턴은 실제 기업 환경에 적합하며 아래와 같은 도메인에서 유용하게 활용 될 수 있습니다.
- 데이터 검증 에이전트
- 로그 분석 자동화
- 파일 기반 리포트 생성 에이전트
- 수치 계산 기반 재무·보안 분석
이러한 영역에서 Code Interpreter가 기반이 되는 “Executable Reasoning” 구조를 완성하여 Agentic AI 구축에 속도와 품질을 더해줄 수 있습니다.
AgentCore Code Interpreter 데모 비디오
상황 별 실제 예시를 보여주는 데모 비디오는 아래와 같습니다. AWS Lab의 샘플코드를 바탕으로하되, 실제 유저가 주로 활용하게 될 챗봇환경을 가정하여 프론트엔드를 추가 개발하고 백엔드를 애플리케이션향으로 재구성 및 구축하여 테스트한 결과 입니다.
- CodeExecution: https://youtu.be/2q98O-Iqpt0
- CodeExecution with Agent(Langchain): https://youtu.be/jajE_xKLhL8
- CodeExecution with Agent(Strands): https://youtu.be/I6bItzEFs6c
- CodeExecution Visualization: https://youtu.be/2CnZDOKG_88
- File Operations: https://youtu.be/08duV-GeJEQ
- Run Command: https://youtu.be/JBiAnMC-UbE
- Advanced Data Analysis: https://youtu.be/fLnvl_vPZVg
학술적 맥락: 실행을 통한 인지 강화
최근 LLM 연구의 핵심 흐름은 단순한 문장 생성이나 지식 회상에서 벗어나, ‘행동을 통한 인지(Acting through Cognition)’ 로 진화하고 있습니다. 이 흐름은 학계에서 흔히 “Action-augmented Cognitive Loop”라고 불리며, 인간의 사고 과정을 모방한 순환 구조 즉, 생각(Reasoning) → 행동(Acting) → 검증(Verification) → 수정(Refinement)—을 모델 내부에서 재현하는 것을 목표로 합니다. 이 개념의 출발점은 LLM이 단순히 언어적 예측을 수행하는 존재에서 벗어나, 스스로 사고 과정을 실험하고 그 결과를 반영할 수 있는 능동적 존재로 발전해야 한다는 문제의식에서 비롯되었습니다. 다시 말해, “한 번의 예측으로 끝나는 모델”이 아니라, 자신이 내린 판단을 행동(Action) 으로 검증하고 그 결과를 다시 학습(Feedback) 으로 통합할 수 있는 순환적 구조가 필요하다는 것입니다.
이러한 철학은 여러 대표적인 연구들에서 구체화되었습니다. 가장 최근의 예로 Chen et al. (2025) 의 R1-Code-Interpreter 연구는, 언어 모델이 코드를 실행해 스스로의 논리를 검증하는 과정에서 강화 신호(Reinforcement via Execution) 를 학습에 활용할 수 있음을 보여주었습니다 (arXiv:2505.21668). 이 연구는 모델이 단순히 “답을 생성하는” 것이 아니라, “결과를 실행해 확인하고 그에 따라 자신의 추론을 보정하는” 능력을 갖추도록 훈련하는 프레임워크를 제시했습니다. 이보다 앞서 Schick et al. (2023) 의 Toolformer 연구에서는, LLM이 외부 API를 스스로 호출하는 방법을 학습함으로써 도구 사용 능력(tool use) 을 내재화할 수 있음을 입증했습니다 (arXiv:2302.04761). 이는 모델이 단순한 언어적 추론을 넘어서 외부 세상과 상호작용하며 결과를 받아들이는 일종의 “행동적 사고(Active Reasoning)”를 가능하게 만들었습니다. 또한 Yao et al. (2022) 의 ReAct (Reason + Act) 프레임워크는, 모델이 추론 단계와 행동 단계를 교차 반복하도록 설계함으로써, 단순한 텍스트 예측 이상의 능동적 문제 해결 패턴을 실현했습니다 (arXiv:2210.03629). 이 접근법은 LLM이 환경으로부터 실시간 피드백을 받아 스스로의 판단 과정을 수정할 수 있게 함으로써, 일종의 “내재적 실험(Internal Experimentation)” 구조를 갖춘 셈이 되었습니다.
이제 위에서 언급한 연구 흐름은 학문적 영역을 넘어 산업적 구현으로 확장되고 있습니다. 그 대표적인 예가 바로 Amazon Bedrock AgentCore Code Interpreter입니다. 이 도구는 LLM이 생성한 코드를 실제로 실행해 보고, 그 결과를 다시 모델의 컨텍스트로 되돌려주는 완전 관리형 서비스로, 앞서 언급한 R1-Code-Interpreter 및 ReAct류 연구의 개념을 실제 엔터프라이즈 환경에 적용한 사례로 불 수 있습니다. 이 기능을 AWS 인프라의 보안·거버넌스 프레임워크와 통합함으로써, “행동을 통한 인지(Action-based Cognition)”가 실제 기업 환경에서도 작동할 수 있음을 보여주고 있습니다. 즉, 언어 모델이 단순히 논리적 답변을 예측하는 수준에 머무르지 않고, 코드를 실행하여 스스로를 검증하고, 그 결과를 다시 학습에 반영하는 자가 강화형 인공지능(Self-verifying AI) 의 형태로 발전할 수 있도록 한 것입니다. 이러한 접근은 연구적으로 제안된 “Action-augmented Cognitive Loop”를 산업 수준의 현실로 끌어올린 사례로 볼 수 있습니다. Bedrock AgentCore Code Interpreter는 실제 고객 데이터, IAM 정책, 그리고 감사(Audit) 요건이 적용되는 환경 속에서도 이러한 루프가 안전하게 작동하도록 설계되었습니다. 이는 곧 “AI가 스스로 사고하고, 행동하며, 검증할 수 있는 엔터프라이즈형 인지 시스템(Enterprise-grade Cognitive System)”의 출현을 의미하며, 학술적 개념과 산업적 구현 사이의 경계를 실질적으로 허물어낸 Amazon Bedrock의 중요한 진화로 평가됩니다.
AI가 세상을 탐색하는 방식: Browser Tool의 철학
AI가 스스로 행동할 수 있으려면, 세상과의 접촉면을 가져야 합니다. Code Interpreter가 내부적으로 데이터를 분석하고 계산한다면, Browser Tool은 외부 데이터를 관찰하고 수집합니다. 이 둘의 결합은 AI를 “닫힌 언어 모델”에서 “열린 관찰자(Open Observer)”로 전환시킵니다. Amazon Bedrock AgentCore의 Browser Tool은 이러한 확장을 안전하게 구현하기 위해 만들어졌습니다. AI가 실제 웹 리소스, API 포털, 클라우드 대시보드, 내부 인트라넷과 상호작용하도록 하되, 모든 행동이 기록되고 통제되는 구조입니다.
AgentCore Browser Tool의 동작 원리를 구성하는 핵심 기술들
Amazon Bedrock AgentCore의 Browser Tool은 단순히 웹페이지를 열고 스크린샷을 캡처하는 수준의 기능이 아닙니다. 이 도구는 크로미움(Chromium) 기반의 브라우저를 완전하게 원격 제어하고, LLM의 자연어 명령을 실시간 브라우저 행동으로 변환하는 고도화된 자동화 프레임워크 위에서 작동합니다. 이를 가능하게 하는 세 가지 핵심 기술이 바로 Chrome DevTools Protocol(CDP), Playwright/Puppeteer, 그리고 Amazon DCV(Desktop Cloud Visualization) 입니다.
CDP – Chrome DevTools Protocol
CDP는 크로미움 기반 브라우저(Chrome, Edge, Brave 등)를 원격으로 디버깅하고 제어하기 위한 저수준 프로토콜입니다. 원래는 개발자가 브라우저 상태를 검사하거나 콘솔·DOM·네트워크 트래픽을 추적하기 위해 만들어졌지만, 이후에는 브라우저 자동화와 AI 기반 상호작용을 위한 핵심 API 계층으로 발전했습니다. Browser Tool은 이 CDP를 활용하여 브라우저의 내부 상태를 실시간으로 읽고,LLM이 생성한 명령을 브라우저의 동작으로 변환합니다. 예를 들어, 모델이 “해당 페이지의 버튼을 클릭해라”라고 판단하면, AgentCore는 CDP를 통해 해당 요소의 역할(Role)과 좌표를 식별하고, 그 위치로 클릭 이벤트를 전달합니다. 이러한 접근 방식은 단순한 HTML 파싱보다 훨씬 안전하고 정확하며, 렌더링 이후의 동적 콘텐츠까지 제어할 수 있습니다. CDP는 Target, Runtime, Network, DOM 등 30개 이상의 도메인 API를 제공하며 각 명령은 WebSocket을 통해 전달됩니다. 이 때문에 Browser Tool은 브라우저 내부를 “데이터 수준에서” 다룰 수 있으며, 이는 AI 에이전트가 브라우저와 신뢰성 있게 상호작용할 수 있도록 보장합니다.
Playwright / Puppeteer – 브라우저 자동화 계층
CDP가 저수준 통신 프로토콜이라면, Playwright와 Puppeteer는 그 위에서 동작하는 고수준 자동화 라이브러리입니다. 두 라이브러리는 브라우저 제어를 위한 오픈소스 툴로, AI나 테스트 자동화 시스템이 사람이 하는 행동과 거의 동일한 방식으로 브라우저를 조작할 수 있게 해줍니다.
예를 들어 다음과 같은 명령이 실행될 수 있습니다.
page.goto('https://amazon.com')
page.getByRole('button').click()
이 간단한 두 줄의 코드가 실제로는 CDP 명령 수십 개를 생성하며, Browser Tool은 이를 Playwright Adapter를 통해 처리합니다. 즉, LLM은 자연어로 “아마존 페이지를 열고 버튼을 눌러라”라고 말하고, AgentCore는 이를 Playwright 명령으로 번역해 브라우저에 전달하는 것입니다. Playwright는 Puppeteer보다 더 다양한 브라우저(Chromium, Firefox, WebKit)를 지원하며, 동시 세션 관리 및 스크린샷, 네트워크 캡처 등도 제공합니다. Bedrock Browser Tool은 이 Playwright 엔진을 AWS 환경에 맞게 AWS Fargate 기반 컨테이너에서 안전하게 실행되도록 최적화했습니다. 이 방식은 클라우드 환경에서 다중 브라우저 세션을 병렬로 처리하면서도 보안과 네트워크 정책을 유지할 수 있게 하며, AI가 실제 사용자처럼 웹 애플리케이션을 탐색하고 데이터를 수집할 수 있도록 합니다.
Amazon DCV – 원격 시각화 및 감사 투명성
Browser Tool의 또 다른 중요한 구성 요소는 Amazon DCV입니다. DCV는 AWS가 제공하는 고성능 원격 그래픽 및 데스크톱 스트리밍 프로토콜로, 원래는 HPC(High Performance Computing) 시각화나 CAD 애플리케이션 원격 접속용으로 설계되었습니다. 그러나 Bedrock은 이 기술을 AI 브라우저 행동의 “시각적 감사(Visual Audit)”를 위해 재해석했습니다. Browser Tool은 DCV를 사용해 에이전트의 브라우저 화면을 실시간으로 스트리밍합니다. 운영자는 Bedrock 콘솔이나 DCV 클라이언트를 통해 AI가 어떤 페이지를 열고, 어떤 요소를 클릭하며, 어떤 텍스트를 읽는지를 실시간으로 확인할 수 있습니다. 이는 단순한 모니터링을 넘어 Explainable AI(설명 가능한 인공지능) 를 실현하는 핵심 메커니즘입니다.
DCV는 고급 압축 알고리즘과 TLS 암호화를 통해 낮은 대역폭에서도 60fps 수준의 렌더링을 제공하며, 데이터는 절대 로컬에 저장되지 않습니다. 즉, 운영자는 AI의 행동을 투명하게 감시할 수 있지만, 보안상의 이유로 세션 내부 데이터를 직접 추출할 수는 없습니다. 이 방식은 “AI가 웹에서 무엇을 하고 있는가?”라는 질문에 대한 가시적이고 신뢰할 수 있는 답을 제공합니다. AI가 행동하고, 인간이 이를 눈으로 확인할 수 있다는 점에서 Browser Tool은 투명성과 보안의 공존이라는 어려운 문제를 기술적으로 해결한 사례라 할 수 있습니다.
통합적 의미: LLM이 웹을 ‘이해하고 행동하는’ 기반
결국 CDP, Playwright, DCV의 결합은 AI가 단순히 텍스트를 생성하는 존재에서 “웹 환경을 이해하고, 그 위에서 직접 행동할 수 있는 존재”로 발전하게 하는 핵심 인프라입니다. CDP는 브라우저 내부의 구조적 접근을, Playwright는 인간 행동의 자동화를, DCV는 그 행동의 시각적 투명성을 담당합니다. 이 세 계층이 조화를 이루며, Bedrock AgentCore의 Browser Tool은 AI와 인간이 협력하는 새로운 형태의 지능형 웹 상호작용 플랫폼(Intelligent Web Interaction Layer) 으로 자리 잡았습니다.
Browser Tool의 구조와 동작 흐름
결국 Amazon Bedrock AgentCore Browser Tool은 단순한 “웹 자동화 브라우저”가 아니라, AI 에이전트의 웹 행동을 투명하게 통제·기록·시각화할 수 있는 보안형 세션 플랫폼입니다. 세션 격리, 명령 인증, 실시간 렌더링, 완전한 감사 추적의 네 가지 축을 통해, Amazon은 AI가 실제 웹 환경에서 안전하고 신뢰 가능한 행동을 수행할 수 있는 엔터프라이즈급 인프라를 완성했습니다.
사용자가 “아마존에서 신발 검색”과 같은 자연어 쿼리를 입력하면, AgentCore의 브라우저 도구는 이 단순한 문장을 실제 행동 시퀀스(Action Sequence) 로 변환합니다.
우선, 에이전트는 LLM을 활용해 사용자의 의도를 분석하고, 목표를 달성하기 위한 단계별 계획을 세웁니다. Nova Act 환경에서는 Amazon이 자체 파인튜닝한 Nova 모델을 사용하며, Strands 또는 browser-use 기반 환경에서는 특정 모델에 종속되지 않고 다양한 LLM이 사용될 수 있습니다. 모델은 “아마존 웹사이트로 이동하기 → 검색창 찾기 → ‘신발’ 입력 → 엔터 누르기”와 같은 구체적인 단계들을 스스로 추론합니다.
그다음 LLM은 이러한 단계를 구조화된 형태로 출력합니다. 이 구조화된 출력은 단순한 텍스트가 아니라 도구 호출(tool invocation) 목록이며, AgentCore 프레임워크에서 정의한 Playwright 추상 계층(Playwright abstraction layer)에 매핑됩니다. 예를 들어, “클릭(click)”이라는 추상 명령은 Playwright의 page.click() API에 해당하지만, 에이전트는 이를 자체 추상화된 “클릭 도구(click tool)” 호출로 표현합니다. 이렇게 함으로써 LLM은 코드 세부사항을 몰라도 Playwright 명령을 안전하게 호출할 수 있습니다.
이후 Playwright는 웹소켓(WebSocket) 연결을 통해 기본 CDP(Chrome DevTools Protocol) 명령을 실행합니다. CDP는 크로미움 기반 브라우저를 제어하기 위한 저수준 API로, 브라우저 내부 상태를 점검하거나 DOM 요소와 상호작용하는 역할을 합니다. Playwright는 LLM이 생성한 고수준 명령을 이 CDP 명령으로 변환하고, AgentCore 브라우저 세션에서 실제 액션—예를 들어 페이지 이동, 입력, 클릭—을 수행합니다.
명령이 실행된 후, 브라우저는 그 결과를 스크린샷과 함께 다시 웹소켓을 통해 AgentCore로 전송합니다. 이 응답에는 브라우저의 상태, 페이지 내용, 실행 로그 등이 포함되며, 모두 LLM으로 다시 전달됩니다. 모델은 이 데이터를 바탕으로 후속 추론을 진행하거나, 사용자의 다음 요청을 예측합니다.
Amazon Bedrock AgentCore Browser Tool의 아키텍처는 단순한 웹 자동화 도구의 수준을 넘어선, 완전 관리형 세션 기반 보안 웹 행동 프레임워크(Secure Web Action Framework) 로 설계되어 있습니다. 이 구조는 2025년 Amazon Bedrock Developer Guide의 “Built-in Tools for Secure Agent Actions” 섹션에서 제시된 공식 아키텍처와 일치하며 , AI 에이전트가 웹 환경과 상호작용할 때 발생할 수 있는 보안·감사·운영상의 문제를 근본적으로 해결하기 위한 구성으로 만들어졌습니다.
이 시스템의 중심에는 네 가지 핵심 구성요소가 있습니다. 먼저 Session Manager는 사용자의 요청이 들어오면 자동으로 ECS Fargate 기반의 컨테이너 인스턴스를 생성해 브라우저 세션을 할당합니다. 이 세션은 완전히 격리된 환경에서 실행되며, 인프라 관리가 필요 없는 서버리스 구조를 유지합니다. 브라우저 세션은 임시적이며 각 사용 후 재설정되고 최대 8시간까지 실행 가능하며 기본값은 15분으로 설정되어 있습니다 . 이를 통해 수백 개의 세션을 동시에 운영하더라도 보안이나 확장성 측면에서 일관된 품질을 유지할 수 있습니다.
다음으로 Playwright Adapter는 LLM의 자연어 명령을 실제 브라우저 행동으로 변환하는 핵심 모듈입니다. 모델이 “상품 페이지로 이동해 가격을 확인해”와 같은 명령을 내리면, 이 어댑터는 해당 명령을 Playwright API의 click, fill, goto 등의 CDP(Chrome DevTools Protocol) 명령으로 매핑합니다 . 이를 통해 LLM은 저수준 브라우저 명령을 직접 다루지 않고도 웹 UI를 제어할 수 있으며, AgentCore Gateway를 통해 모든 명령이 SigV4로 인증되어 실행됩니다.
세 번째 구성요소는 DCV Renderer입니다. 이는 AWS DCV(Desktop Cloud Visualization) 기술을 사용하여 브라우저 화면을 실시간으로 스트리밍하는 모듈로, 슬라이드에 명시된 “DCV Server → Rendered Image Transmission → Local DCV Client/AWS Console” 구조를 따릅니다 . 이를 통해 운영자는 웹 세션의 상태를 실시간으로 관찰하고, AI 에이전트가 어떤 버튼을 클릭하고 어떤 페이지를 열람하는지를 직접 확인할 수 있습니다. 이 시각화 계층은 단순한 화면 공유가 아니라, Explainable Automation 및 Visual Transparency 를 구현하는 핵심 기술로 기능합니다.
마지막으로 Audit Logger는 CloudTrail과 연동되어 명령 호출, URL, 타임스탬프, 결과 스냅샷등의 모든 세션 이벤트를 기록합니다. 이 기능은 엔터프라이즈 보안 정책과 규제 요건을 충족하기 위한 것으로, 슬라이드에서 “logging · 실시간 뷰 · 세션 녹화 · CloudTrail 로깅”으로 요약된 부분이 이에 해당합니다 . 이러한 로깅 구조 덕분에 모든 브라우저 액션은 이후 보안 감사나 문제 재현 시 완전히 추적 가능합니다.
결국 Amazon Bedrock AgentCore Browser Tool은 단순한 “웹 자동화 브라우저”가 아니라, AI 에이전트의 웹 행동을 투명하게 통제·기록·시각화할 수 있는 보안형 세션 플랫폼입니다. 세션 격리, 명령 인증, 실시간 렌더링, 완전한 감사 추적의 네 가지 축을 통해, Amazon은 AI가 실제 웹 환경에서 안전하고 신뢰 가능한 행동을 수행할 수 있는 엔터프라이즈급 인프라를 완성했습니다.
AgentCore Browser Tool은 자체적으로 브라우저 세션을 제공하지만, 이 세션 위에서 “어떤 AI가 브라우저 행동을 계획하느냐”는 상위 에이전트 또는 자동화 프레임워크가 결정합니다. 대표적인 예로 Amazon이 제공하는 Nova Act, 그리고 오픈소스 기반의 Strands, browser-use와 같은 실행 프레임워크들이 있습니다.
- Nova Act는 Amazon이 파인튜닝한 모델로 자연어 명령을 행동 계획으로 변환하는 고수준 브라우저 자동화 엔진입니다.
- Strands는 멀티에이전트 의사결정 프레임워크로, 브라우저 제어가 필요할 때 Nova Act 또는 Playwright 추상 계층을 호출합니다.
- browser-use는 LLM이 전체 브라우저 탐색 단계를 직접 계획하고 수행하는 경량 자동화 엔진입니다.
이처럼 어떤 엔진이 행동 계획을 담당하더라도, 최종적으로는 AgentCore Browser Tool이 제공하는 CDP 기반 브라우저 세션에서 실제 행동이 수행됩니다.
사용자가 “아마존에서 신발 검색”과 같은 자연어 쿼리를 입력하면, AgentCore의 브라우저 도구는 이 단순한 문장을 실제 행동 시퀀스(Action Sequence) 로 변환합니다.
우선, 에이전트는 LLM을 활용해 사용자의 의도를 분석하고, 목표를 달성하기 위한 단계별 계획을 세웁니다. Nova Act 환경에서는 Amazon이 자체 파인튜닝한 Nova 모델을 사용하며, Strands 또는 browser-use 기반 환경에서는 특정 모델에 종속되지 않고 다양한 LLM이 사용될 수 있습니다. 모델은 “아마존 웹사이트로 이동하기 → 검색창 찾기 → ‘신발’ 입력 → 엔터 누르기”와 같은 구체적인 단계들을 스스로 추론합니다.
그다음 LLM은 이러한 단계를 구조화된 형태로 출력합니다. 이 구조화된 출력은 단순한 텍스트가 아니라 도구 호출(tool invocation) 목록이며, AgentCore 프레임워크에서 정의한 Playwright 추상 계층(Playwright abstraction layer)에 매핑됩니다. 예를 들어, “클릭(click)”이라는 추상 명령은 Playwright의 page.click() API에 해당하지만, 에이전트는 이를 자체 추상화된 “클릭 도구(click tool)” 호출로 표현합니다. 이렇게 함으로써 LLM은 코드 세부사항을 몰라도 Playwright 명령을 안전하게 호출할 수 있습니다.
이후 Playwright는 웹소켓(WebSocket) 연결을 통해 기본 CDP(Chrome DevTools Protocol) 명령을 실행합니다. CDP는 크로미움 기반 브라우저를 제어하기 위한 저수준 API로, 브라우저 내부 상태를 점검하거나 DOM 요소와 상호작용하는 역할을 합니다. Playwright는 LLM이 생성한 고수준 명령을 이 CDP 명령으로 변환하고, AgentCore 브라우저 세션에서 실제 액션—예를 들어 페이지 이동, 입력, 클릭—을 수행합니다.
명령이 실행된 후, 브라우저는 그 결과를 스크린샷과 함께 다시 웹소켓을 통해 AgentCore로 전송합니다. 이 응답에는 브라우저의 상태, 페이지 내용, 실행 로그 등이 포함되며, 모두 LLM으로 다시 전달됩니다. 모델은 이 데이터를 바탕으로 후속 추론을 진행하거나, 사용자의 다음 요청을 예측합니다.
결국 이 일련의 과정은 “자연어 → 구조화된 명령 → 브라우저 실행 → 시각적 피드백 → 재추론”으로 이어지는 완전한 루프를 형성합니다. 이 루프를 통해 LLM은 단순히 텍스트를 이해하는 수준을 넘어, 실제 웹 환경에서 목적 지향적 행동을 수행할 수 있습니다. AgentCore Browser Tool은 이 모든 단계를 자동화된 안전한 경로로 연결하여, AI가 사람처럼 웹을 탐색하고, 행동하고, 그 결과를 스스로 검증할 수 있도록 합니다.
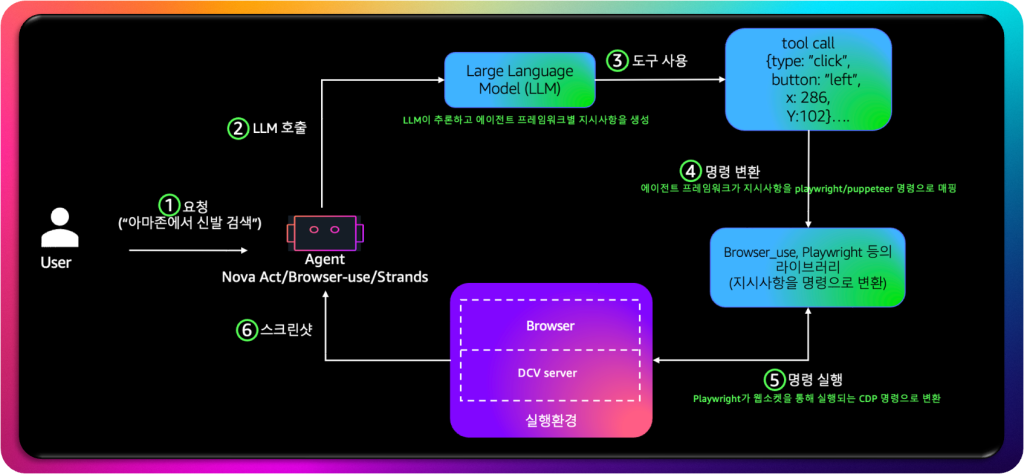
AgentCore Browser Tool 동작 과정
DCV Live View
AI가 웹 상에서 행동할 때 가장 큰 문제는 “보이지 않는다”는 점입니다. AI가 어떤 버튼을 클릭했는지, 어디로 이동했는지, 어떤 데이터를 읽었는지를 운영자가 직접 확인하기 어렵습니다. 물론 Headless 형태로 일임하는 경우도 있지만, 직접 확인이나 실시간 모니터링이 필요할수도, 동작의 제어권을 중간에 가져와 Task를 수행하고 싶을 수도 있습니다.
AWS DCV(Desktop Cloud Visualization) 기술은 이 문제를 해결합니다. DCV는 원격 그래픽 세션을 실시간으로 인코딩해 전송하는 프로토콜로, 원래는 HPC 시각화나 게임 스트리밍에 활용되던 기술입니다. Bedrock AgentCore Browser Tool은 이 기술을 AI 관찰(Observation of AI Behavior) 영역에 응용했습니다. 운영자는 DCV 스트림을 통해 AI가 열람 중인 화면, 클릭한 버튼, 입력한 텍스트를 실시간으로 확인할 수 있습니다. 이것은 단순한 모니터링을 넘어, AI 자동화 환경에서의 Explainable Automation (설명 가능한 자동화)을 구현하는 핵심 기술입니다.
실제로 Alan Chan 등이 발표한 Visibility into AI Agents (ACM CHI 2024) 논문은 AI 에이전트의 행동 로그와 시각적 피드백을 인간이 실시간으로 관찰할 수 있을 때 사용자의 신뢰도가 유의미하게 향상된다는 결과를 보였습니다 (dl.acm.org/10.1145/3630106.3658948). 또한 Sunnie S. Y. Kim (2024)의 연구 Establishing Appropriate Trust in AI through Transparency and Explainability 에서는 AI 시스템의 투명성이 사용자 신뢰 형성에 직접적인 영향을 미친다는 사례를 실험적으로 입증했습니다 (openreview.net/forum?id=RwEiwrxhoP).
Bedrock AgentCore Browser Tool은 이러한 연구 결과를 엔터프라이즈 레벨에서 구체화한 예시입니다. AWS DCV 기반의 시각적 피드백을 통해 운영자는 AI의 모든 행동을 직접 감시하고 감사할 수 있으며, 이는 AI 운영 신뢰(Operational Trust)를 구축하는 핵심 기반이 됩니다.
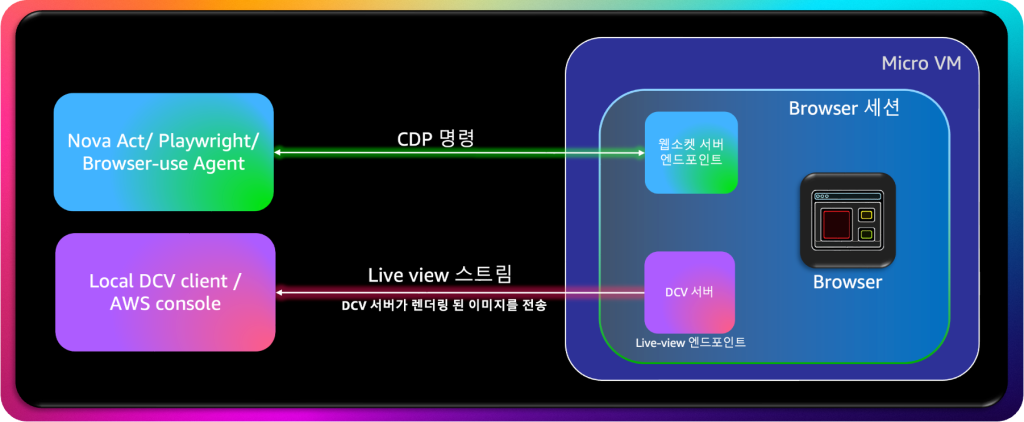
AgentCore Browser Tool의 DCV Live View
다채로운 SDK 활용
AgentCore SDK는 Bedrock 기반 에이전트가 브라우저를 제어하고 세션을 관리하는 모든 핵심 역할을 담당합니다. 이 SDK는 두 가지 수준의 API 레이어로 구성되어 있습니다. 하위 계층은 Boto3를 직접 호출하는 저수준 API로, 사용자가 세부 옵션을 모두 명시해야 하는 대신 세밀한 제어가 가능합니다. 상위 계층은 AgentCore Python SDK로, 이 SDK는 Boto3를 내부적으로 활용하면서도 고수준 추상화 객체를 제공해 사용자가 더 적은 코드로 브라우저 세션을 생성하고 관리할 수 있습니다 .
브라우저 세션 흐름은 다음과 같습니다. 우선 start_browser_session() API를 호출하면 임시 세션이 생성되고, 웹소켓 엔드포인트(ws_url)와 라이브 뷰 엔드포인트가 반환됩니다. 여기서 웹소켓은 Playwright나 Puppeteer 라이브러리가 전송하는 CDP 명령을 중계하는 역할을 하며, 서명된 헤더를 사용하여 보안을 유지합니다 . 이후 create_presigned_live_view_url()을 통해 사전 서명된 라이브 뷰 URL을 생성하면, DCV 클라이언트가 이 URL에 접속하여 브라우저 화면을 실시간으로 렌더링합니다. 이 기능은 AgentCore Browser Tool의 시각적 감사(Visual Auditability) 기능의 핵심입니다 .
SDK는 Nova Act, Strands, Browser-Use 등 여러 에이전틱 프레임워크와의 통합도 지원합니다. 각 프레임워크는 LLM의 명령을 CDP 명령으로 매핑하는 방식이 조금씩 다릅니다. 예를 들어 Nova Act는 keep_alive=True 옵션을 활용해 지속적인 세션 연결을 유지하고, Strands는 AgentCoreBrowser(region=”us-west-2″)와 같이 지역 및 모델을 명시적으로 지정하여 에이전트를 구성합니다. Browser-Use SDK는 상대적으로 경량화된 인터페이스를 제공하며, BrowserSession() 객체를 통해 CDP 웹소켓 URL과 헤더를 등록하고 persistent 세션을 유지합니다 . 모든 프레임워크는 결국 AgentCore SDK를 통해 세션을 시작하고, 웹소켓 통신을 통해 CDP 명령을 전달하는 공통 구조를 가집니다.
이러한 SDK 설계는 Bedrock 플랫폼의 철학—“에이전트가 복잡한 인프라를 직접 관리하지 않도록 하는 완전 관리형 실행 환경”—과 일치합니다. 사용자는 인프라 프로비저닝 없이 API 호출만으로 세션을 시작할 수 있으며, 각 세션은 최대 8시간 동안 유지되고 기본값은 15분으로 설정됩니다. 모든 브라우저 세션은 격리된 컨테이너에서 실행되며, 종료 후에는 자동으로 폐기되어 보안이 보장됩니다 .
결국 AgentCore SDK는 단순한 API 세트가 아니라, LLM-중심 브라우저 자동화와 엔터프라이즈급 보안·관찰성(Observability)을 연결하는 핵심 브리지입니다. 이를 통해 Nova Act, Strands, Browser-Use 같은 고수준 프레임워크가 AgentCore의 서버리스 브라우저 인프라를 안정적으로 활용할 수 있습니다.
AgentCore Browser Tool 빠르게 사용해보기
Amazon Bedrock AgentCore의 Browser Tool은 AWS Labs GitHub 리포지토리의 02-Agent-Core-browser-tool 예제를 통해 다양한 방식으로 활용할 수 있으며, 특히 엔터프라이즈 환경에서는 세 가지 대표 패턴이 널리 사용됩니다. 모든 방식은 AgentCore가 제공하는 동일한 브라우저 세션(Chromium 기반, CDP WebSocket, DCV Live View)을 기반으로 하지만, 브라우저 행동을 결정하는 주체가 누구인가에 따라 구조와 사용 목적이 달라집니다.
첫 번째는 Playwright 단독 사용 패턴으로, 개발자가 직접 Playwright 코드를 작성하여 AgentCore가 제공하는 CDP Endpoint에 연결해 브라우저를 제어하는 방식입니다. 이 패턴은 기존 브라우저 자동화 스크립트를 Bedrock 환경에서 그대로 재사용할 수 있다는 장점이 있습니다.
두 번째는 Nova Act와 Browser Tool의 결합 패턴입니다. 이 방식은 Nova LLM이 자연어 명령을 기반으로 브라우저 행동을 스스로 계획하고 실행합니다. GitHub 예제는 Nova Act가 AgentCore Browser의 CDP Endpoint를 받아, 검색·입력·클릭과 같은 UI 액션을 계획적으로 수행하는 과정을 보여줍니다. 단일 작업을 안정적으로 자동화해야 하는 기업 시나리오에서 유용합니다.
세 번째는 Browser Use + Browser Tool 결합 패턴으로, LLM이 복잡한 멀티스텝 웹 탐색을 스스로 수행하는 구조입니다. Browser Use는 브라우저 환경을 직접 탐색하며 적절한 행동을 결정하는 고수준 에이전틱 프레임워크로, 다단계 승인 프로세스, 내부 SaaS 기반 대시보드 조작, 장문의 폼 자동화와 같이 복잡성이 높은 엔터프라이즈 워크플로우에 적합합니다.
이러한 세 가지 패턴은 모두 AgentCore Browser Tool의 안전한 세션 기반 웹 실행 환경을 바탕으로 하며, 기업은 요구사항에 따라 “직접 제어”, “LLM 계획 기반 자동화”, “다단계 에이전틱 브라우저 조작” 중 적합한 구조를 선택하여 실제 운영 시스템에 적용할 수 있습니다.
Playwright 기반 AgentCore Browser Tool
Playwright 기반 접근 방식은 AgentCore Browser Tool과 가장 직접적으로 대응되는 제어 방식입니다. 개발자가 Playwright 스크립트를 직접 작성하여 브라우저 동작을 명시적으로 제어할 수 있기 때문에, 기존 UI 자동화나 테스트 자동화를 이미 운영하고 있는 조직에서는 매우 자연스럽게 도입할 수 있습니다. AgentCore는 browser_session(region) 컨텍스트를 통해 Fargate 기반의 격리된 브라우저 세션을 자동으로 생성하며, 이 세션은 CDP(WebSocket) 프로토콜을 통해 외부에서 제어할 수 있습니다.
아래는 브라우저 세션을 생성하고 SigV4 인증 헤더 및 CDP 엔드포인트를 획득하는 예시입니다.
with browser_session("us-west-2") as client:
ws_url, headers = client.generate_ws_headers()
여기에서 ws_url은 AgentCore가 생성한 브라우저 세션의 CDP(WebSocket) 엔드포인트이며, headers는 SigV4 인증 헤더입니다. 이 헤더를 Playwright가 그대로 사용하기 때문에, 브라우저 제어는 AWS IAM 인증을 기반으로 안전하게 수행됩니다.
브라우저 동작을 실시간으로 확인해야 하는 경우 BrowserViewerServer를 함께 사용할 수 있습니다. 이 구성 요소는 AWS DCV 기술을 활용해 브라우저 화면을 스트리밍하며, 운영자는 실시간으로 브라우저 상태와 클릭·입력 등의 동작을 확인할 수 있습니다.
viewer = BrowserViewerServer(client, port=8005) viewer_url = viewer.start(open_browser=True)
이제 Playwright를 사용해 AgentCore 브라우저 세션을 직접 제어할 수 있습니다.
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(ws_url, headers=headers)
page = browser.contexts[0].pages[0]
page.goto("https://amazon.com")
page.get_by_role("searchbox").fill("running shoes")
page.keyboard.press("Enter")
이 코드가 실행되는 순간부터 Playwright는 로컬 브라우저가 아닌, AgentCore 환경에 존재하는 Chromium 브라우저를 제어합니다. 모든 세션 활동은 CloudTrail로 기록되며, 브라우저는 Fargate 기반 컨테이너에서 완전히 격리된 상태로 실행됩니다.
Playwright 방식은 브라우저 자동화 로직을 가장 세밀하게 제어할 수 있는 구조입니다. 기존 Playwright 기반 자동화 스크립트를 그대로 확장할 수 있고, 로컬 브라우저 인프라를 관리할 필요 없이 AWS가 제공하는 서버리스 브라우저 실행 환경을 그대로 활용할 수 있습니다. 또한 SigV4 인증·CloudTrail 감사·격리된 실행 환경을 통해 보안 요구사항을 충족하면서도 안정적인 자동화가 가능합니다. 이 방식은 예측 가능성과 유지보수성을 중시하는 엔터프라이즈 환경에서 특히 강력한 선택지입니다.
Nova Act + AgentCore Browser Tool
Nova Act는 자연어를 기반으로 브라우저 행동을 계획하고 실행하는 고수준 에이전트 프레임워크입니다. 사용자가 단순 문장 형태로 지시를 내리면, Nova Act는 DOM 상태를 분석하고 필요한 단계별 브라우저 행동을 자동으로 생성합니다. 개발자는 더 이상 Playwright 코드 자체를 작성할 필요가 없으며, AgentCore Browser Tool이 제공하는 CDP 엔드포인트를 Nova Act가 직접 사용하게 됩니다.
먼저, AgentCore Browser Tool에서 브라우저 세션을 생성한 뒤 CDP 엔드포인트 정보를 획득합니다.
with browser_session("us-west-2") as client:
ws_url, headers = client.generate_ws_headers()
Nova Act는 CDP 엔드포인트와 API 키를 입력받아 초기화되며, 초기 페이지 URL을 설정하여 작업을 시작합니다.
from nova_act import NovaAct
with NovaAct(
cdp_endpoint_url=ws_url,
cdp_headers=headers,
nova_act_api_key=NOVA_ACT_API_KEY,
starting_page="https://www.amazon.com",
) as nova_act:
result = nova_act.act("Search for coffee makers and find the cheapest one.")
이 과정에서 Nova Act는 다음과 같은 기능을 수행합니다.
- LLM 기반 브라우저 행동 계획 생성
- DOM 분석을 통한 요소 위치 파악
- 클릭·입력·스크롤 등의 이벤트 자동 실행
- Playwright CDP 계층을 통한 실제 동작 수행
- 결과 수집 및 구조화
Nova Act 방식은 단일 자연어 지시를 완전한 브라우저 작업으로 전환해야 하는 환경에서 특히 강력합니다. Playwright API를 직접 다루지 않아도 되는 높은 추상화 덕분에 개발 생산성이 크게 향상되며, AgentCore의 보안·감사 인프라와 결합되어 안정적인 자동화가 가능합니다. 반복적인 UI 업무나 단일 조회·검색 시나리오를 자동화해야 하는 조직에서 매우 빠르게 가치를 창출할 수 있습니다.
Strands + Nova Act + Browser Tool
Strands 프레임워크를 활용하면 Nova Act를 하나의 브라우저 자동화 도구(tool)로 통합할 수 있습니다. Strands는 LLM 기반 의사결정·계획 수립·도구 호출을 담당하고, Nova Act는 브라우저 제어에만 집중하는 구조입니다. 이 접근 방식은 브라우저 자동화가 전체 문제 해결 파이프라인의 일부가 되어야 하는 멀티에이전트 환경에서 특히 유용합니다.
다음은 Strands 도구로 Nova Act 브라우저 자동화를 래핑하는 예시입니다.
@tool
def browser_automation_tool(starting_url: str, instructions: str) -> str:
with browser_session("us-west-2") as client:
ws_url, headers = client.generate_ws_headers()
with NovaAct(
cdp_endpoint_url=ws_url,
cdp_headers=headers,
nova_act_api_key=NOVA_ACT_API_KEY,
starting_page=starting_url,
) as nova_act:
return str(nova_act.act(instructions))
상위 Supervisor Agent는 브라우저 자동화가 필요한 순간 이 도구를 호출하며, Nova Act는 해당 작업을 실행합니다.
이 방식은 브라우저 자동화를 전체 에이전트 생태계에 자연스럽게 통합할 수 있는 구조입니다. Strands가 고수준 의사결정과 워크플로우 조정을 담당하고, Nova Act가 신뢰도 높은 브라우저 실행을 담당함으로써 대규모 멀티에이전트 시스템에서도 일관된 동작을 유지할 수 있습니다. 이는 기업 내부에서 브라우저 기반 시스템과 여러 에이전트가 연동되어야 하는 실제 운영 환경에 매우 적합합니다.
Browser Use + AgentCore Browser Tool
Browser Use는 복잡한 멀티스텝 웹 탐색을 자동화하기 위한 고급 프레임워크입니다. Nova Act가 단일 작업을 안정적으로 처리하는 경우에 적합하다면, Browser Use는 여러 페이지를 오가며 조건을 판단하고, 데이터를 수집하고, 다시 다른 페이지로 이동해야 하는 복잡한 업무에 강합니다.
먼저, AgentCore Browser Tool을 통해 CDP 엔드포인트를 생성합니다.
client = BrowserClient(region="us-west-2")
client.start()
ws_url, headers = client.generate_ws_headers()
browser_session = BrowserSession(
cdp_url=ws_url,
browser_profile=BrowserProfile(headers=headers),
keep_alive=True,
)
await browser_session.start()
Browser Use Agent는 Claude 등의 LLM과 연결하여 전체 브라우저 작업을 수행합니다.
from browser_use.llm import ChatBedrockClaude
from browser_use import BrowserUseAgent
bedrock_chat = ChatBedrockClaude(
model_id="anthropic.claude-3-5-sonnet",
region="us-west-2",
)
agent = BrowserUseAgent(
task="Find the cheapest coffee maker on Amazon.",
llm=bedrock_chat,
browser_session=browser_session,
)
result = await agent.run()
Browser Use는 다음과 같은 특징을 가지고 있습니다.
- 멀티 페이지 이동
- 복잡한 입력 폼 처리
- 테이블·대시보드 기반 정보 수집
- 장문 워크플로우 자동화
Browser Use는 웹 UI 중심의 실제 엔터프라이즈 업무를 자동화하는 데 최적화된 구조입니다. LLM이 페이지 상태를 판단하며 다음 행동을 결정하기 때문에, 기존 스크립트 자동화로는 구현하기 어려웠던 복잡한 UI 흐름도 자연스럽게 처리할 수 있습니다. 대규모 웹 기반 운영 시스템, 복잡한 기업 포털, 승인 절차 자동화 등 다양한 영역에서 활용될 수 있으며, AgentCore Browser Tool의 격리된 실행 환경과 결합되어 신뢰성과 보안성을 모두 확보할 수 있습니다.
Browser Use 데모 비디오
- AgentCore Browser: Nova Act 1st: https://youtu.be/j9zCkq6wZsQ
- AgentCore Browser: Nova Act 2nd: https://youtu.be/ycSRVolaE3M
- AgentCore Browser: Browser Use: https://youtu.be/VITbXP7rQrE
Browser Tool과 Code Interpreter의 연동
이 두 도구는 상호 독립적이면서도 상호 보완적입니다. 하나는 데이터를 “가져오는” 역할을, 다른 하나는 데이터를 “이해하고 변환하는” 역할을 수행합니다. 실제 워크플로우는 다음과 같이 작동합니다.
- Browser Tool 이 외부 데이터를 수집 → JSON / CSV / HTML 형식으로 저장.
- Code Interpreter 가 이 데이터를 받아 분석, 통계 계산, 시각화.
- Browser Tool 이 결과를 다시 사용자에게 시각화(예: 보고서 페이지, 대시보드).
이 구조는 AI가 단일 요청 내에서 완전한 “Perception → Reasoning → Action → Validation” 루프를 수행하도록 합니다. 이는 ReAct 프레임워크(Yao et al., 2022)의 개념을 엔터프라이즈 운영에 실현한 사례라 할 수 있습니다. Browser Tool은 단순한 보조 기능이 아니라 AI의 운영 투명성(Operational Transparency) 과 설명 가능성(Explainability) 을 확장하는 기술입니다. AI가 단독으로 행동할 수 있을 때, 그 행동을 인간이 시각적으로 이해하고 감사할 수 있는 구조를 제공한다는 점에서 Browser Tool은 “관찰 가능한 자동화(Observable Automation)”의 기초입니다. Code Interpreter가 내부 데이터 분석의 표준을 만들었다면, Browser Tool은 외부 상호작용의 표준을 정의했습니다. 이 두 도구의 결합이 곧 Amazon Bedrock AgentCore의 진정한 차별점입니다.
이 구조는 학술적으로도 중요한 전환점을 의미합니다.
- 실행 기반 추론(Reasoning through Execution) : LLM이 코드를 통해 자기 검증.
- 관찰 기반 행동(Acting through Observation) : LLM이 브라우저를 통해 외부 세계를 인식.
- 통합 인지 루프(Cognitive Verification Loop) : Code Interpreter와 Browser Tool의 결합을 통해 모델이 스스로 데이터를 수집·분석·검증하는 완전한 폐루프를 형성.
이 개념은 인간의 인지과학 모델(Perception–Cognition–Action Loop)과 유사하며, AI 시스템의 자율성과 신뢰성을 동시에 확보하는 기반이 됩니다.
AI가 기업 내에서 실제로 “일”을 하기 시작한 시점은, 언어 모델이 단순히 텍스트를 예측하던 단계를 넘어서 자율적으로 데이터를 수집하고 실행하며 결과를 검증할 수 있게 되었을 때부터입니다. Amazon Bedrock AgentCore의 Code Interpreter와 Browser Tool은 바로 그 지점을 구체화한 두 축이라 할 수 있습니다. Code Interpreter는 내부 연산과 분석을 담당하며, Browser Tool은 외부 정보와 상호작용하는 채널을 제공합니다. 이 둘의 연결은 AI가 “보는 것과 계산하는 것을 통합한” 지각-인지-행동 루프(Perception–Cognition–Action Loop) 를 형성합니다. 이 루프는 단순히 기술적 조합이 아니라, AI의 신뢰성(reliability)과 투명성(transparency)을 동시에 해결하는 가장 강력한 구조적 답변이 되고 있습니다.
Built-in Tools 통합 실행 아키텍처
엔터프라이즈 환경에서 Code Interpreter와 Browser Tool이 함께 작동할 때, 이들은 서로의 데이터를 안전하게 주고받으면서도 완전히 분리된 실행 공간을 유지할 수 있습니다. 다음과 같은 흐름으로 웹을 탐색한 결과를 코드 인터프리터를 통하여 분석하는 통합 루프를 구성할 수 있습니다.
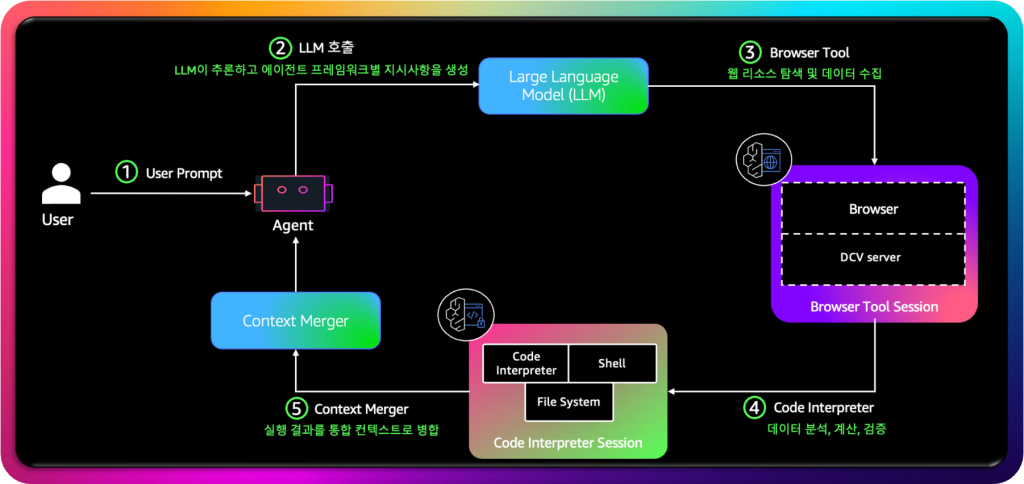
AgentCore Builit-in Tools lnteration
사용자가 자연어로 명령이나 질문을 입력하면(① User Prompt), 이 입력은 Agent로 전달됩니다. 에이전트는 입력을 분석한 뒤, 적절한 처리 방식을 결정하기 위해 LLM 을 호출합니다(②). 이때 LLM은 주어진 프롬프트를 바탕으로 에이전트 프레임워크에 맞는 지시사항을 추론하고 생성합니다. LLM이 생성한 지시사항 중 웹 탐색이나 최신 정보 수집이 필요한 경우, Browser Tool이 활성화되며(③) Browser Tool은 실제 웹 리소스를 탐색하고 필요한 데이터를 수집하는 역할을 수행하게 됩니다. 이 과정에서 DCV 서버와 브라우저 세션이 함께 작동하여 안전하게 외부 데이터를 가져올 수 있습니다. 한편, 데이터 분석이나 계산, 검증이 필요한 경우에는 Code Interpreter Tool를 호출합니다(④). 이후, Browser Tool과 Code Interpreter Tool의 실행 결과는 다시 Context Merger로 전달되어(⑤) 새로운 컨텍스트로 병합됩니다. 병합된 컨텍스트는 에이전트의 다음 추론 과정에 반영되어, 보다 정교하고 맥락적인 응답을 생성할 수 있습니다.
즉, 이 아키텍쳐는 사용자 입력 → LLM 추론 → 툴 실행 → 결과 병합 → 응답 생성이라는 순환 구조로 작동하며, 에이전트가 단순한 텍스트 응답을 넘어 탐색, 계산, 검증, 실행을 수행하는 지능형 조력자 역할을 수행할 수 있도록 합니다.
Bedrock AgentCore Built-in Tools의 연구적, 산업적, 인문학적 의미
Amazon Bedrock AgentCore는 Code Interpreter와 Browser Tool을 통해 LLM이 스스로 실행하고 검증하는 능력을 갖추도록 문제를 해결하려고 합니다. Code Interpreter는 모델이 직접 코드를 실행해 데이터를 계산하거나 분석함으로써 추론의 정확성을 높입니다. Browser Tool은 실시간으로 웹을 탐색하여 최신 정보를 확보하고, 모델이 시시각각 변화하는 세상과 연결될 수 있도록 합니다. 이를 통해 LLM은 단순한 텍스트 생성기를 넘어, 사실 기반으로 사고하고 행동하는 에이전트로 진화할 수 있습니다.
Amazon Bedrock AgentCore의 Built-in Tools, 즉 Code Interpreter와 Browser Tool은 단순한 기능적 확장을 넘어 인공지능 발전의 방향을 상징적으로 보여줍니다. 지금까지의 대규모 언어 모델(LLM)은 주로 텍스트를 생성하거나 정보를 요약하는 수준에서 작동했습니다. 그러나 Bedrock AgentCore Built-in Tools는 AI가 언어적 추론을 넘어 실행(Execution) 을 통해 사고를 검증하는 구조를 제공합니다. 모델이 코드를 실행하고, 실제 웹 환경을 탐색하며, 그 결과를 다시 자체 추론에 반영하는 과정은 일종의 “사고-행동-검증” 순환 구조를 형성합니다. 이 변화는 인공지능이 단순히 “답을 예측하는 존재”에서 “결과를 실험하고 확인하는 존재”로 발전했음을 의미합니다.
이러한 설계는 최근 연구 동향과도 일치합니다. 여러 학계 연구에서 Executable Reasoning, 즉 “실행 가능한 추론”이 신뢰성 높은 AI 시스템의 핵심이라고 강조합니다. 모델이 자신의 판단을 코드 실행이나 시뮬레이션을 통해 검증할 때, 인간이 그 결과를 이해하고 신뢰할 가능성이 높아진다는 것입니다. Bedrock AgentCore Code Interpreter는 이 개념을 실제 산업 환경에서 구현했습니다. 사용자의 요청은 SigV4 인증을 거쳐 격리된 Firecracker MicroVM 세션에서 실행되며, 결과는 직렬화된 데이터 형태로 모델에 반환됩니다. 이 구조는 코드 실행이 운영 환경을 침범하지 않으면서도 완전한 계산 자원을 활용할 수 있도록 합니다. 즉, AI가 스스로 수행한 연산의 근거를 명확히 남기고, 결과를 인간이 검증 가능한 형태로 제공하는 것입니다.
Browser Tool은 이러한 “실행 기반 추론”을 외부 세계로 확장합니다. LLM이 자연어 명령을 내리면 Playwright Adapter가 이를 브라우저 행동으로 변환하고, ECS Fargate 기반의 Session Manager가 격리된 세션을 생성합니다. AWS DCV 기술은 브라우저의 실제 화면을 실시간으로 스트리밍하여, 운영자가 AI의 행동을 직접 관찰할 수 있게 합니다. 모든 명령과 스크린샷, 타임스탬프는 CloudTrail에 기록되어 AI의 웹 상호작용 과정을 완전히 추적할 수 있습니다. 이 시스템은 단순한 자동화를 넘어 AI의 투명성과 설명가능성을 보장하는 인프라로 작동합니다.
이 두 도구가 결합된 구조는 기술적 측면에서 Cognitive Verification System(인지 검증 시스템) 으로 볼 수 있습니다. Browser Tool이 데이터를 감지하고(Perception), Code Interpreter가 이를 분석하며(Cognition), 결과를 다시 검증 및 피드백하는(Verification) 루프를 형성하기 때문입니다. 이는 인간의 인지 과정과 유사한 형태로, AI가 스스로의 행동을 평가하고 조정할 수 있는 기반을 제공합니다.
산업적으로 이 구조는 엔터프라이즈 AI 운영의 신뢰성과 투명성을 크게 강화합니다. Code Interpreter 와 Browser Tool 모두 CloudTrail, KMS, IAM, CloudWatch 등 AWS 보안 서비스와 통합되어, 모든 세션과 행동이 감사 가능한 형태로 기록됩니다. 또한 Firecracker 기반 격리 환경과 서버리스 세션 모델은 확장성 및 비용 효율성을 유지하면서도 운영 위험을 줄이는 효과를 보입니다. 즉, AI가 기업 환경에서 안전하게 “행동”할 수 있는 운영적 인지 인프라(Operational Cognitive Infrastructure)가 형성된 것입니다.
결국 Amazon Bedrock AgentCore Built-in Tools은 AI 역사의 한 단계 진화를 나타냅니다. 언어로만 사고하던 모델이 이제 실행을 통해 사고를 검증하고, 자신의 판단을 설명할 수 있게 된 것입니다. 이러한 변화는 기술적 혁신을 넘어 인문학적 전환으로도 읽힙니다. AI는 더 이상 인간의 지시를 따르는 도구가 아니라, 함께 실험하고 검증하며 배우는 동료로 진화하고 있습니다. 미래의 개발자는 AI에게 “정답을 묻는” 사람이 아니라, AI와 함께 “해답을 탐구하는 공동 연구자”가 될 것입니다.
Agentic AI의 핵심 플랫폼이자 실행 지능(Executable Intelligence)의 기반인 Amazon Bedrock AgentCore Built-in Tools가 여러분의 여정에 함께하길 바랍니다. 이 도구들이 여러분이 목표하는 비즈니스와 기술적 목적지에 한층 더 빠르고, 안전하게 도달할 수 있도록 돕는 동반자가 되길 기대합니다.
Session Video Link
https://skillbuilder.aws/learn/WJCD4RD411/agentcore-code-interpreter-browser–/MJB26KNV67
참고문헌 및 공식 레퍼런스
- AWS Labs GitHub Repository (2025).
Amazon Bedrock AgentCore Samples – 01-tutorials/05-AgentCore-tools
https://github.com/awslabs/amazon-bedrock-agentcore-samples/tree/main/01-tutorials/05-AgentCore-tools - AWS Documentation (2025).
Amazon Bedrock Developer Guide
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html - AWS News Blog (2018).
Firecracker – Lightweight Virtualization for Serverless Computing.
https://aws.amazon.com/blogs/aws/firecracker-lightweight-virtualization-for-serverless-computing/ - Chen, Z. et al. (2025).
R1-Code-Interpreter: LLMs Reason with Code via Supervised and Multi-stage Reinforcement Learning. arXiv:2505.21668
https://arxiv.org/abs/2505.21668 - Boye, J. & Moëll, J. (2025).
Large Language Models and Mathematical Reasoning Failures. arXiv:2502.11574
https://arxiv.org/abs/2502.11574 - Schick, T. et al. (2023).
Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2502.04761
https://arxiv.org/abs/2502.04761 - Yao, S et al. (2022).
ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2502.03629
https://arxiv.org/abs/2502.03629