AWS 기술 블로그
AI-DLC 를 팀 프로젝트에 적용하기: Subagent 와 Custom Skill 로 확장한 Armiq 사례
0. 들어가며: 왜 AI-DLC를 적용했는가
AI-DLC(AI-Driven Development Life Cycle)는 요구사항 분석부터 설계, 코드 생성, 리뷰까지 SDLC 전 과정을 AI Agent 기반으로 수행하는 개발 방식입니다.
이번 사례의 파트너인 ARMIQ는 SAP 데이터 영역에서 오랫동안 솔루션을 공급해 온 기업으로, 법인·사업부 분리나 매각 과정에서 발생하는 데이터 분할·이관 이슈, 그리고 데이터 압축·암호화·클라우드 전송 등 데이터 관리와 보안 전반에 특화된 솔루션 (AODS · ADCS · ALCS · AETL · ACMS · APDE · ASRD · ATDM 등) 을 제공하고 있습니다. “AI 시대에 살아있는 데이터의 가능성을 실현한다”는 비전 아래 고객 맞춤형 솔루션을 지속적으로 확장해 왔습니다.
ARMIQ는 최근 솔루션 제작 및 현대화 가속화가 동시에 필요한 상황이었습니다. 전통적인 방식으로는 요구사항 문서화 → 설계 → 구현 → 리뷰의 각 단계마다 별도의 공수가 필요해, 두 프로젝트를 동시에 끌고 가기에는 개발 리소스가 부족했습니다.
AI-DLC를 도입한 이유는 명확했습니다. 반복적이고 규격화할 수 있는 설계·구현 작업을 Agent가 대신하게 하고, 사람은 요구사항 판단과 설계 의사결정에 집중하면 두 프로젝트를 병렬로 마무리할 수 있겠다고 판단했기 때문입니다.
이번 글에서 다루는 두 프로젝트(AETL, ACMS)의 개요는 다음 섹션에서 먼저 소개합니다.
1. AI-DLC ToolSet 개요
이번 Unicorn Gym에서 ARMIQ는 두 개의 프로젝트를 동시에 AI-DLC로 진행했습니다.
| 프로젝트 | 유형 | 기술 스택 | 규모 | 설명 |
|---|---|---|---|---|
| AETL | Brownfield | Node.js
모놀리스 (Express + React) |
8 Unit / 12 US + 17 TT / 테스트 16 파일 | 기존 데이터 파이프라인에 AI-DLC를 적용해 보안,구조 개선 |
| ACMS | Greenfield | TypeScript
Lambda (Aurora PostgreSQL) |
5 Unit / 31 US / API 55개(95% 커버) | 표준 기반 서버를 요구사항부터 새로 설계·구현 |
US(User Story): 사용자 관점의 요구사항 단위.
TT(Technical Task): 사용자 관점 요구사항으로는 표현되지 않지만 구현·운영에 필요한 내부 기술 작업입니다(예: 라이브러리 업그레이드, 보안 미들웨어 적용, IaC 변경).
AETL: ETL은 고객사 SAP 및 레거시 시스템 내에 있는 데이터를 AWS 클라우드로 전송하여 분석 및 AI에 활용할 수 있도록 지원합니다.
ACMS: CMS는 고객사 SAP 및 레거시 시스템 내에 있는 문서(document)를 AWS S3에 전송하여 통합관리 할 수 있도록 지원합니다.
AI-DLC ToolSet은 AI-DLC 워크플로우를 실제로 실행하기 위해 조립한 실행 환경입니다. AI-DLC 자체는 awslabs/aidlc-workflows 저장소에 워크플로우 정의(각 Phase와 단계, 승인 지점, 입출력 규칙)로 공개되어 있지만, 이 정의를 실제로 돌리려면 Agent 런타임(Kiro CLI 등), 외부 지식 소스 연결(MCP Server), 프로젝트별 특화 로직(Custom Skill)이 하나로 묶여야 합니다. 이번 Unicorn Gym에서 구성한 ToolSet은 Main Agent와 두 개의 Subagent(Reverse Engineering, Code Generation) 구조에 세 개의 MCP Server(context7, aws-knowledge-mcp-server, tavily)와 Custom Skill(requirements-generator, git-merge, skill-creator, Unit별 Code Review Skill)을 결합한 형태이며, 이 구성을 ARMIQ의 두 프로젝트에 동일하게 적용했습니다. 전체 구성은 aws-samples/sample-aidlc-toolset-with-subagents-and-custom-skills 저장소에서 확인할 수 있습니다. 두 프로젝트 모두 동일한 AI-DLC ToolSet을 사용했으며, 이번 Unicorn Gym에서는 기존 AI-DLC 구성 위에 세 가지 측면의 보완을 얹었습니다. Agent 구조를 Main–Subagent로 분리해 context 관리를 개선했고, git-merge와 requirements-generator 같은 Custom Skill로 팀 개발에서 실제로 부딪히는 문제들을 풀었으며, 생성된 코드를 전용 Code Review Skill로 다시 검토하여 품질 가드레일을 추가했습니다. 이 글에서는 각각을 실제 구성과 함께 살펴봅니다.
2. AI-DLC가 Brownfield와 Greenfield를 모두 다루는 방식
AETL(Brownfield)과 ACMS(Greenfield)는 출발 조건이 완전히 다른 프로젝트입니다. 하나는 이미 코드가 존재하는 상태에서 분석 및 개선이 필요했고, 다른 하나는 요구사항만 있는 상태에서 설계부터 시작해야 했습니다. 그럼에도 동일한 AI-DLC로 동시에 진행할 수 있는 것은, AI-DLC의 워크플로우 정의 자체가 Adaptive Workflow와 Unit이라는 두 가지 개념을 기반으로 설계되어 있기 때문입니다. AWS는 이 원칙을 Open-Sourcing Adaptive Workflows for AI-DLC 블로그에서 공개적으로 설명했으며, 실제 워크플로우 정의는 awslabs/aidlc-workflows 저장소에서 확인할 수 있습니다.
Adaptive Workflow: 고정된 단계가 아니라 적응하는 단계
AI-DLC의 워크플로우는 INCEPTION → CONSTRUCTION → OPERATIONS 3단계 구조를 가지지만, 그 안의 세부 단계들은 항상 실행(ALWAYS)과 조건부 실행(CONDITIONAL)로 구분됩니다. AI가 프로젝트의 상태와 복잡도를 분석해서 필요한 단계만 선택적으로 실행합니다.
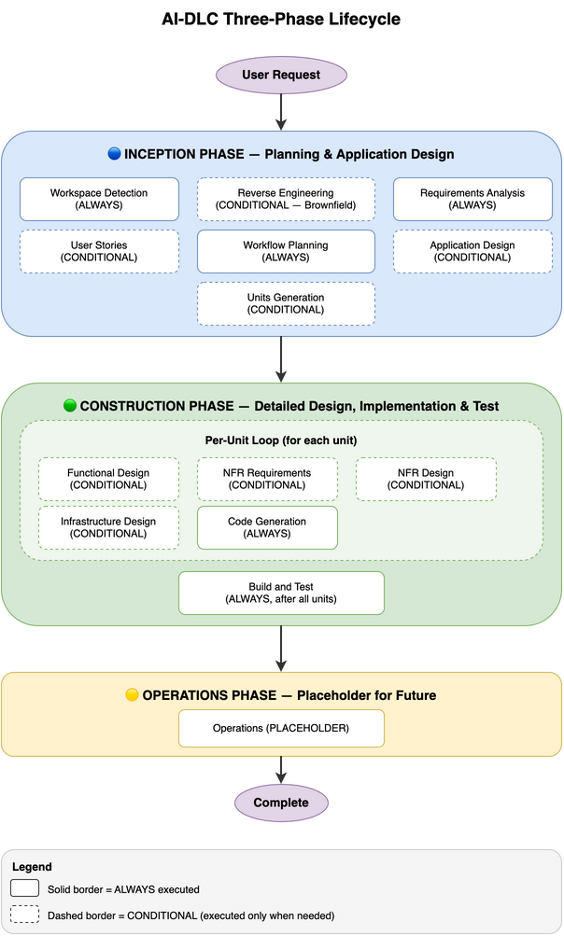
항상 실행되는 stage와 조건부로 실행되는 stage는 다음과 같이 구분됩니다. 이번 Unicorn Gym의 두 프로젝트를 예로 들면:
- Workspace Detection, Requirements Analysis, Workflow Planning, Code Generation, Build and Test는 항상 실행됩니다.
- Reverse Engineering은 Brownfield 프로젝트에서만 실행됩니다. AETL에서는 실행되었고, ACMS에서는 생략되었습니다.
- User Stories, Application Design, Units Generation 등은 복잡도와 범위에 따라 조건부로 실행됩니다.
워크플로우는 모든 단계를 정의해두지만, 실제 수행 시에는 해당 프로젝트에 맞는 단계만 선별적으로 실행됩니다. 덕분에 Brownfield와 Greenfield를 구분된 별도 프로세스로 운용할 필요 없이, 하나의 AI-DLC 적용 방식으로 두 프로젝트를 모두 커버할 수 있었습니다.
Unit: 병렬 개발의 단위
INCEPTION Phase의 마지막 단계인 Units Generation에서 프로젝트는 여러 개의 Unit으로 분할됩니다. Unit은 AI-DLC에서 CONSTRUCTION Phase의 작업 단위이자, 여러 개발자가 병렬로 작업할 수 있는 단위이기도 합니다.
일반적으로 Unit 구성은 다음과 같은 형태를 가집니다.
- 각 Unit은 독립적인 기능 경계를 가집니다 (예: User Service, Order Service, Shared Utils)
- 각 Unit은 자체적인 Functional Design, NFR Design, Infrastructure Design, Code Generation 사이클을 가집니다.
- 여러 개발자가 각자 자신의 PC에 프로젝트를 clone하여 서로 다른 Unit을 동시에 진행할 수 있습니다.
이 Unit 개념은 이후 섹션에서 설명할 git-merge Skill이 왜 필요한지의 배경이 됩니다. 팀 개발 환경에서 여러 개발자가 서로 다른 Unit을 병렬로 진행한 뒤 merge하는 시나리오에서, 단순한 코드 충돌 외에 AI-DLC 고유의 상태 파일 충돌까지 함께 발생하기 때문입니다.
3. Subagent 아키텍처: Main → Specialized Agent 위임 구조
이번 ToolSet의 Agent 구조는 Main Agent가 Orchestrator 역할을 하고, 무거운 작업은 전문 Subagent에게 위임하는 형태입니다.
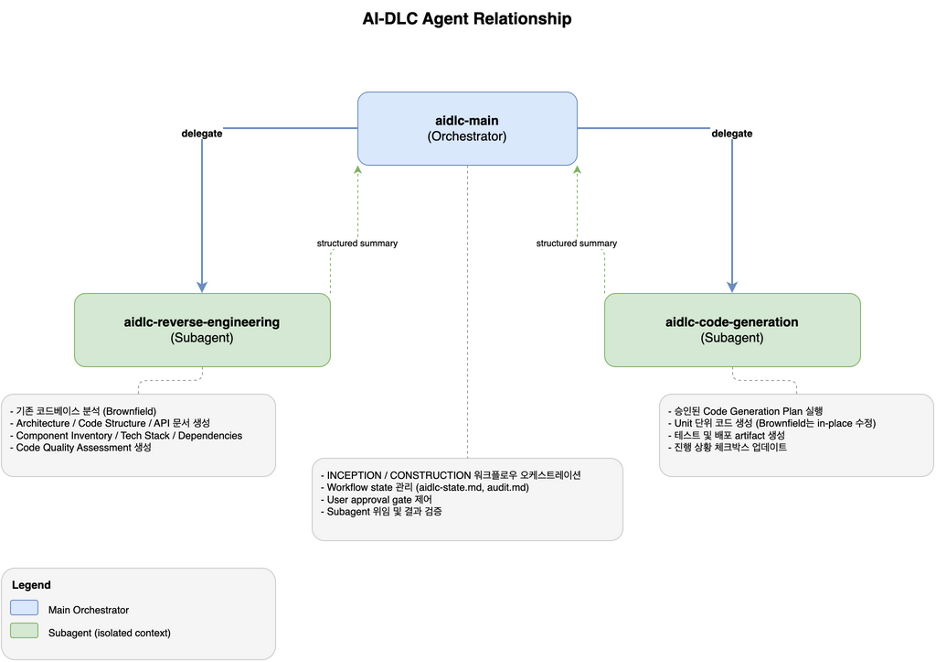
Main Agent(aidlc-main)는 전체 워크플로우의 오케스트레이션과 상태 관리, 사용자 승인 흐름을 담당하고, 두 개의 Subagent(aidlc-reverse-engineering, aidlc-code-generation)에 각각 기존 코드베이스 분석과 코드 생성 작업을 위임합니다. Subagent는 자체 context window에서 독립적으로 실행되고, 작업이 끝나면 Main Agent에게 요약된 결과만 반환합니다.
왜 Subagent인가?
Kiro 공식 문서에 따르면 Subagent는 자체 isolated context에서 독립적으로 실행되며, 작업이 끝나면 내장 summary tool을 통해 결과 요약만 Main Agent에게 자동 반환됩니다. Subagent 내부의 tool call과 중간 산출물은 해당 Subagent의 context에만 남고 Main Agent의 대화 context를 오염시키지 않습니다. 이 특성은 AI-DLC처럼 장시간에 걸쳐 대량의 문서/코드를 다루는 workflow에 두 가지 직접적인 이점을 제공합니다.
- Context Window 효율화:
- Reverse Engineering은 기존 코드베이스 전체를 분석해야 하고, Code Generation은 설계 문서를 기반으로 대량의 코드를 생성합니다. 이런 작업을 Main Agent의 context에서 직접 수행하면 분석과 생성 과정의 중간 산출물, 파일 읽기 결과, 탐색 trace가 모두 누적되어 context window가 빠르게 소진됩니다. Subagent로 분리하면 무거운 실행은 격리된 context에서 이뤄지고, Main Agent는 최종 요약만 받습니다.
- 역할 분리:
- Main Agent는 전체 워크플로우 상태 관리와 사용자 승인 흐름에 집중하고, Subagent는 분석생성 작업에만 집중합니다. 이를 통해 구조적으로 관심사가 분리됩니다.
Subagent 응답 포맷을 명시적으로 정의한 이유
Kiro CLI의 Subagent는 summary tool이 결과 요약을 반환하지만, 그 분량과 형식은 제어되지 않습니다. 여러 Unit에 대해 Subagent를 반복 호출하면 반환 텍스트가 누적되면서 Main Agent의 context를 잠식하게 됩니다. 결과적으로 Subagent 도입으로 얻으려던 context 효율화 효과가 상쇄됩니다.
이를 방지하기 위해 이번 ToolSet에서는 각 Subagent의 system prompt에 반드시 따라야 하는 응답 스키마를 명시했습니다. 예를 들어 Code Generation Subagent는 다음과 같은 고정 필드로만 응답하도록 강제됩니다.
그리고 프롬프트에 "Do NOT include code snippets in this response.", "Do NOT explain implementation details.", "Do NOT repeat file contents." 라는 명시적 negative instruction을 함께 넣었습니다. 생성된 코드는 이미 파일 시스템에 쓰여 있으므로, Main Agent는 “어떤 파일이 생성·수정되었고, 확장 규칙(extension rule, 프로젝트별 추가 코딩 규약)을 준수했는지, 블로킹 이슈가 있는지”만 알면 충분합니다.
Reverse Engineering Subagent도 동일한 원칙으로 STATUS / ARTIFACTS_DIR / FILES_CREATED / SUMMARY / ISSUES 필드만 반환하도록 정의했고, 분석 상세는 artifact 파일에만 쓰도록 분리했습니다.
이 설계는 Subagent 호출이 여러 번 이어질수록 효과가 누적된다는 점에서 실용적으로 중요합니다. 응답 포맷을 제어하지 않은 경우와 비교하면 Main Agent의 context에 추가되는 텍스트 양이 수 KB 수준으로 수렴하므로, 긴 INCEPTION–CONSTRUCTION 사이클 전체를 하나의 세션으로 진행할 수 있습니다.
Reverse Engineering Subagent
Brownfield 프로젝트(AETL)에서 특히 중요한 역할을 합니다. Main Agent는 역공학 단계의 분석·생성 작업만 이 Subagent에 위임하고, 상태 파일 업데이트와 사용자 승인 흐름은 직접 처리합니다. Subagent는 기존 코드베이스를 분석하여 다음 8개의 artifact를 자동 생성합니다.
- business-overview.md — 비즈니스 개요
- architecture.md — 아키텍처 분석
- code-structure.md — 코드 구조
- api-documentation.md — API 문서
- component-inventory.md — 컴포넌트 인벤토리
- technology-stack.md — 기술 스택
- dependencies.md — 의존성 분석
- code-quality-assessment.md — 코드 품질 평가
이 artifact들은 이후 INCEPTION Phase의 Requirements Analysis, Workflow Planning 등에서 핵심 입력 자료로 활용됩니다. 기존에는 사람이 수동으로 기존 시스템을 분석하고 문서화해야 했던 작업을 AI가 자동으로 수행하는 것입니다.
Code Generation Subagent
CONSTRUCTION Phase에서 unit별 코드 생성을 전담합니다. Main Agent가 Planning 단계에서 승인받은 Code Generation Plan을 입력으로 받아, 각 항목을 순차적으로 실행하며 진행 상황을 체크박스로 추적합니다. 생성된 코드는 workspace root에 직접 작성되고(Brownfield의 경우 기존 파일을 in-place 수정), 설계 문서는 aidlc-docs/construction/{unit-name}/code/에 저장됩니다.
참고로 Planning 단계 자체는 Main Agent가 수행합니다. “무엇을 만들 것인가를 정의하고 사용자 승인을 받는 일”은 Main Agent의 orchestration 책임이고, “승인된 Plan을 실제로 구현하는 일”만 Subagent에 위임하는 구조입니다.
두 Subagent 모두 필요한 경우 MCP Server를 통해 외부 지식 소스를 참조하여 분석·생성을 수행합니다.
MCP Server 활용
MCP(Model Context Protocol)는 Anthropic이 2024년 발표한 오픈 표준으로, AI 모델이 외부 데이터 소스나 도구에 표준화된 방식으로 접근할 수 있게 해주는 프로토콜입니다. 이번 ToolSet에는 세 개의 MCP Server가 설정되어 있고, 각각 서로 다른 정보 소스를 담당합니다.
- context7 : 오픈소스 라이브러리와 프레임워크의 최신 공식 문서를 조회하는 외부 서비스(Upstash 제공)입니다. 수많은 라이브러리의 API 레퍼런스와 코드 예제를 색인하고 있어서, Agent가 코드를 생성하기 직전에 “이 라이브러리의 최신 API signature는 무엇인가”를 확인할 수 있습니다. LLM은 학습 시점에 고정된 지식을 갖기 때문에, 최신 버전에서 API가 변경된 경우 outdated한 코드를 생성하기 쉽습니다. context7은 이 간극을 보완합니다. 이번 프로젝트에서는 Code Generation Subagent가 context7을 참조해 생성 코드의 정확도를 높였습니다.
- aws-knowledge-mcp-server : AWS가 제공하는 MCP Server입니다. AWS의 공식 문서, 블로그, What’s New 공지, Well-Architected 베스트 프랙티스, CDK/CloudFormation 패턴, SDK 레퍼런스를 MCP 프로토콜로 직접 조회할 수 있습니다. Infrastructure Design 단계나 AWS 서비스를 다루는 코드 생성 단계에서, Agent가 최신 AWS 레퍼런스를 기반으로 작업하도록 지원합니다. AWS 서비스는 API와 기능이 자주 업데이트되기 때문에, 모델의 학습 시점에 의존하지 않고 항상 최신 문서를 참조할 수 있다는 점에서 AI-DLC 워크플로우와 잘 맞습니다.
- tavily : AI 에이전트용으로 최적화된 웹 검색 외부 서비스입니다. 일반 검색 엔진 결과와 달리, 질문에 대한 답변에 도움이 되도록 정제된 형태로 결과를 반환합니다. 이번 사례에서는 주로 INCEPTION Phase에서 활용되었습니다. 요구사항이나 제약사항을 분석하는 과정에서 업계 관행, 표준 규격, 레퍼런스 아키텍처 같은 도메인 지식이 필요할 때 Main Agent가 tavily로 웹을 검색해 근거를 보강하는 방식입니다. 코드 생성 단계에서는 일반적으로 필요하지 않기 때문에, ToolSet 구성상 Main Agent에만 연결해두었습니다.
세 MCP Server는 모두 “모델의 학습 시점 이후의 최신 정보에 접근”한다는 공통 목적을 가지지만, 정보의 성격이 다릅니다. context7은 라이브러리 문서, aws-knowledge-mcp-server는 AWS 레퍼런스, tavily는 웹 전반의 도메인 지식을 담당합니다. AI-DLC가 생성하는 설계 문서와 코드의 품질은 “얼마나 최신의 정확한 정보를 참조했는가”에 크게 좌우되기 때문에, 세 소스를 함께 활용하는 것이 실제 품질에 유의미한 차이를 만듭니다. 에이전트 설정에서도 이 배치는 명시적으로 구분됩니다. Main Agent에는 세 MCP Server가 모두 연결되고, 두 Subagent에는 context7과 aws-knowledge-mcp-server만 연결됩니다. tavily는 INCEPTION Phase에서 주로 쓰이므로 Main Agent 전용으로 두었습니다.
4. Custom Skill: requirements-generator
AI-DLC의 INCEPTION Phase는 요구사항 분석에서 시작됩니다. 하지만 실제 고객 환경에서는 요구사항 문서 자체가 없는 경우가 많습니다. 있더라도 제품 소개서, 워크숍 슬라이드, 기능정의서 등 비정형 문서인 경우가 대부분입니다.
requirements-generator Skill은 이런 비정형 소스 문서(PDF, 마크다운, 이미지 등)를 분석하여 구조화된 요구사항 정의서와 제약사항 문서를 자동 생성합니다.
핵심 설계 원칙
- 소스 문서에 명시된 정보만으로 도출합니다 — 명시되지 않은 내용은 생성하지 않습니다.
- 확인할 수 없는 항목은 “정보 부족”으로 명시합니다 — 문서 말미에 정보 부족 항목 요약 테이블을 제공합니다.
- 체계적인 ID 네이밍: 기능 요구사항(FR-{영역}-{순번}), 비기능 요구사항(NFR-{순번}), 제약사항(카테고리별 접두사 TC(Technical Constraint), BC(Business Constraint), LC(Legal Constraint) 등).
출력 예시
- 요구사항: {프로젝트약어}_requirements.md
- 제약사항: {프로젝트약어}_constraints.md
이 Skill 덕분에 고객이 가진 기존 문서만으로도 AI-DLC의 INCEPTION Phase에 바로 진입할 수 있었습니다.
5. Custom Skill: git-merge
앞서 섹션 2에서 설명한 것처럼, INCEPTION Phase가 완료되면 프로젝트는 여러 Unit으로 분할되고, 각 개발자가 자신의 PC에서 서로 다른 Unit의 CONSTRUCTION Phase를 병렬로 진행합니다. 이때 필연적으로 발생하는 문제가 git merge conflict입니다.
실제 병렬 실행 시나리오: ACMS의 Wave 기반 협업
ACMS 프로젝트에서는 INCEPTION 결과로 5개 Unit이 도출된 뒤, 4인 팀이 Unit 간 의존성을 Wave 단위로 묶어 다음과 같이 병렬 진행했습니다.
| Wave | Unit | 실행 방식 | 담당 |
|---|---|---|---|
| Wave 1 | Unit 1
(기반 인프라) |
4명 전원
영역 분담 협업 |
A + B + C
+ D |
| Wave 2 | Unit 2
(핵심 도메인 API) |
4명 전원
영역 분담 협업 |
A + B + C
+ D |
| Wave 3 | Unit 3
(도메인 A) |
2명 (팀 1)
— Unit 5와 병렬 |
A + B |
| Wave 3 | Unit 5
(도메인 B) |
2명 (팀 2)
— Unit 3과 병렬 |
C + D |
| Wave 4 | Unit 4
(확장 기능) |
4명 전원
재합류 |
A + B + C
+ D |
Wave 1·2처럼 전원이 같은 Unit의 서로 다른 영역(Terraform / CI·CD / DB 스키마 / 공유 모듈)을 나눠 작업하는 경우에도, Wave 3처럼 두 팀으로 분기해 서로 다른 Unit을 동시에 진행하는 경우에도, 매 Wave 종료 시점에는 반드시 merge가 필요합니다. 그리고 이때 두 종류의 conflict가 동시에 발생합니다.
발생하는 Conflict 유형
1. AI-DLC 상태
모든 개발자가 자기 unit의 진행 상태를 aidlc-state.md와 audit.md에 기록하므로, push/merge 시 반드시 conflict가 발생합니다. 하지만 이 conflict는 논리적으로는 충돌이 아닙니다 — 각자 다른 unit에 대한 기록이기 때문입니다.
2. 공통 코드 Conflict
공통 unit(shared library 등)을 여러 개발자가 수정하면 실제 코드 충돌이 발생합니다.
Skill의 해결 전략
Conflict 감지 → 분류(상태파일/코드) → 자동 병합 or 분석 후 사용자 확인 → 검증
- 상태 파일: 양쪽 unit의 progress를 모두 반영하여 자동 병합 (사용자 확인 불필요)
- 코드 파일: 추가형(Additive, 양쪽 추가가 공존 가능)인지, 중복 수정형(Overlapping, 같은 코드를 양쪽에서 수정)인지, 의존성 변경형(Dependency, 공통 API가 바뀜)인지 분석한 뒤 사용자에게 해결 방안을 제시합니다.
이 Skill은 AI-DLC를 실제 팀 개발 환경에서 운용할 때 반드시 필요한 도구입니다. 여러 명이 서로 다른 Unit을 병렬로 진행하는 순간 반드시 마주치는 문제이지만, 도구가 없으면 매 merge마다 개발자가 수동으로 풀어야 하는 부담이 됩니다.
6. 코드 생성 이후: 전용 Code Review Skill로 한 번 더 검증
Code Generation Subagent가 unit 코드를 생성하면, 그 시점에 해당 코드 전용 Code Review Skill을 만들어 리뷰를 수행했습니다. 여기서 핵심은 두 가지입니다.
첫째, 리뷰 관점과 생성 관점을 분리합니다. 직전에 코드를 생성한 Agent가 같은 세션에서 자신의 코드를 리뷰하면, 동일한 가정을 재사용하기 쉬워 누락된 결함을 그대로 지나칠 가능성이 있습니다. Code Review를 별도 Skill로 분리해 호출하면, Agent는 리뷰어 역할의 system prompt로 처음부터 다시 코드를 읽고 판단합니다. 구조적으로 “작성자 관점”과 “리뷰어 관점”이 분리됩니다.
둘째, 범용 리뷰어가 아니라 해당 unit 전용 리뷰어를 만든다는 점입니다. Skill은 해당 unit의 설계 문서(Functional Design, NFR Design, Infrastructure Design), 요구사항, 제약사항을 참조 자료로 포함하고, 그 unit에서 실제로 쓰이는 기술 스택과 아키텍처 결정을 바탕으로 체크 포인트를 구성합니다. 범용 linter 수준이 아니라, 해당 unit의 맥락을 이해하고 있는 리뷰어 역할을 하도록 설계한 것입니다.
이런 Unit 전용 Skill을 매번 사람이 직접 작성하면 도입 비용이 너무 커집니다. 그래서 이번 ToolSet에는 Anthropic이 공개한 skill-creator를 Kiro CLI의 Skill 구조에 맞게 포함시켜, “Skill을 만드는 Skill”로 활용했습니다. skill-creator는 사용자의 의도와 트리거 조건을 인터뷰 형식으로 정리한 뒤, 프로젝트 문서와 MCP Server(라이브러리 레퍼런스, AWS 레퍼런스, 웹 검색)를 조회해 초안을 생성하고, 필요 시 평가(eval) 루프를 통해 설명문(description)과 체크리스트를 반복 개선합니다. 결과적으로 사람은 “무엇을 리뷰하고 싶은지”만 간단히 지시하면 되고, 나머지 구체화는 Agent가 수행합니다.
예를 들어 TypeScript 기반 unit에 대한 리뷰 Skill을 추가해야 할 때는 다음과 같은 prompt 하나면 충분합니다.
이 prompt가 이렇게 짧게 유지될 수 있는 이유는, prompt에서 요구하는 “프로젝트 정보와 설정된 프레임워크, 개발 언어 버전”이 이미 AI-DLC의 앞선 단계들에서 생성되어 workspace에 쌓여 있기 때문입니다. Reverse Engineering artifact, requirements-generator가 만든 요구사항/제약사항, Unit별 Functional/NFR/Infrastructure Design 문서가 모두 설계 의도의 1차 소스로 존재하므로, Agent는 별도 설명 없이 이들을 읽어 체크 포인트를 구성할 수 있습니다.
여기에 세 MCP Server로 최신성을 보강합니다. context7은 해당 프레임워크의 최신 API와 deprecated 경고를, aws-knowledge-mcp-server는 AWS 관련 베스트 프랙티스를, tavily는 일반 도메인 지식을 각각 제공합니다. 프로젝트 내부 설계 문서와 외부 최신 레퍼런스, 이 두 축이 결합되어 체크리스트가 만들어지고, 이번 두 프로젝트에서는 스택별로 네 종류의 Code Review Skill이 만들어졌습니다.
| Skill | 대상 | 주요 체크 포인트 예시 |
|---|---|---|
| javascript-code-review | AETL 백엔드 (Node.js + Express) | 프로젝트 표준 에러 클래스 사용, DB 쿼리 파라미터 바인딩, 자식
프로세스 에러 핸들링, 비효율 쿼리 패턴 탐지 |
| react-code-review | AETL 프론트엔드 (React 18 + Vite) | Hooks 의존성 배열, 실시간 연결 cleanup, 파생 상태 안티패턴, 리스트
가상화 |
| typescript-code-review | ACMS Lambda (TypeScript 5 +
Aurora) |
타입 안전성(any 금지), 표준 에러 클래스 계층 준수, 동적 SQL 컬럼
화이트리스트 적용 |
| terraform-code-review | 공통 IaC
(AWS Provider 5.x) |
IAM 최소 권한, Security Group CIDR, IMDSv2 강제, VPC Endpoint
활용 |
각 Skill의 SKILL.md에는 프로젝트 고유 패턴(커스텀 에러 클래스, 쿼리 파서의 화이트리스트 규칙 등)이 체크리스트로 박혀 있어서, 일반적인 ESLint/TSLint 수준에서는 절대 잡을 수 없는 설계 의도 위반까지 잡아냅니다.
리뷰 과정에서 실제로 다음과 같은 항목들이 잡혀 개선되었습니다.
- 생성 시 놓친 edge case나 예외 처리 누락
- 설계 문서에 정의된 요구사항제약사항과 실제 구현의 불일치
- 코드 스타일, 네이밍, 에러 핸들링 패턴 등 best practice 준수 여부
- 동일 기능에 대한 중복 구현이나 over-engineering된 부분
특히 ACMS에서는 Code Review 단계에서 실제 프로덕션 버그 2건이 잡혀 수정되었습니다.
- 쿼리 엔진의 SQL 파라미터 바인딩 누락 — 일부 쿼리 절의 값이 파라미터 바인딩을 거치지 않고 SQL 문자열에 인라인되던 이슈. “모든 리터럴은 파라미터 바인딩으로 처리한다”는 설계 원칙에 위반되며, 잠재적 SQL Injection 취약성 소지가 있었습니다. 프로덕션 배포 전 Code Review 단계에서 발견해 수정했습니다.
- 요청 파서의 ACL 처리 누락 — 요청 디코딩 경로 중 하나에서 ACL(Access Control Entry) 파싱 단계가 빠져 있어, 특정 입력 형식의 ACL 요청이 정상 처리되지 않던 이슈.
둘 다 unit 테스트로는 잘 드러나지 않는 유형이지만, “이 프로젝트의 Query Engine은 모든 리터럴이 파라미터 바인딩으로 처리되어야 한다”는 설계 원칙을 체크리스트로 가진 리뷰어가 보면 즉시 잡히는 이슈입니다. unit 전용 리뷰어 설계의 실효성을 보여준 대표 사례였습니다.
결과적으로 “AI가 생성한 코드를 AI가 다시 검증”하는 2단계 구조를 통해 최종적으로 개발자에게 전달되는 코드의 품질이 향상되었습니다. 개발자가 처음부터 모든 코드를 리뷰하는 부담 대신, 이미 한 차례 걸러진 코드를 받아 핵심 판단에 집중하도록 역할이 재배치됩니다.
7. 전체 워크플로우 요약
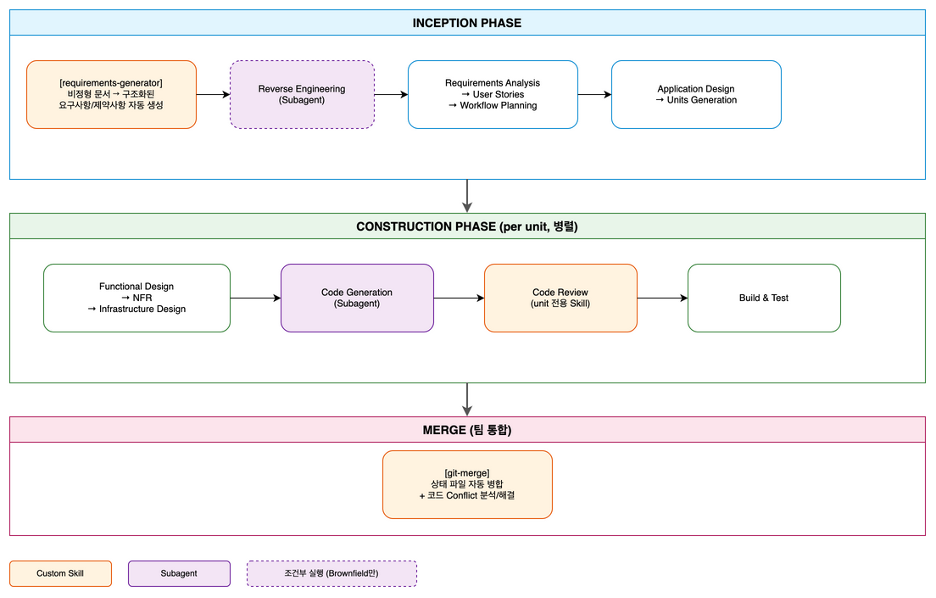
세 Phase는 단순히 순서대로 실행되는 단계가 아니라, 앞 Phase의 산출물이 다음 Phase의 입력으로 쌓이는 파이프라인입니다. INCEPTION에서 requirements-generator와 Reverse Engineering Subagent가 생성한 요구사항·제약사항·설계 artifact가 workspace에 축적되고, 이 문서들이 CONSTRUCTION의 Functional/NFR/Infrastructure Design과 Unit 전용 Code Review Skill의 입력이 됩니다. 여러 개발자가 각자 Unit을 병렬로 진행한 결과는 CONSTRUCTION Phase 말미의 merge 시점에 git-merge Skill이 상태 파일과 코드 conflict를 함께 처리하며 하나로 통합됩니다. 이번 Unicorn Gym의 ToolSet은 이 흐름 위에 Subagent 구조와 Custom Skill을 추가해, 실제 팀 프로젝트에서 AI-DLC가 더 매끄럽게 동작하도록 보완하는 데 초점을 맞췄습니다.
8. 두 프로젝트의 결과
위에서 설명한 AI-DLC 구성으로 두 프로젝트 모두 목표했던 범위까지 마무리했습니다. AETL은 V4 Multi-Process 구조로 재작성되었습니다. VBRP 테이블 21개(19.1M rows)의 처리 속도를 17,599 → 35,754 rows/s(+103%)로 개선했고, ACDOCA(19.6M rows)는 14,000 → 30,655 rows/s(+119%)로 개선했습니다. Transport·스케줄링·DLQ·실시간 모니터링까지 운영에 필요한 기능을 한 번에 포함했습니다. ACMS는 5개 Unit, 31개 User Story, 55개 API(기능 요구사항의 95% 커버)를 4주 내에 설계·구현 완료했으며, CMIS 기반 SAP 연동과 S3 암호화·Private Network 구성을 포함한 엔터프라이즈 수준의 아키텍처를 갖추었습니다. 두 결과 모두 이번 Unicorn Gym에서 AI-DLC에 추가한 Subagent 구조와 Custom Skill 없이는 병렬로 마무리하기 쉽지 않은 분량이었습니다.
| 프로젝트 | 주요 성과 | 성능 개선 | 추가 기능 |
|---|---|---|---|
| AETL | V4
Multi-Process 구조로 재작성 |
VBRP: 17,599 → 35,754 rows/s (+103%)
ACDOCA: 14,000 → 30,655 rows/s (+119%) |
Transport,
스케줄링, DLQ, 실시간 모니터링 |
| ACMS | 5개 Unit,
31개 User Story, 55개 API (95% 커버) 4주 내 완료 |
엔터프라이즈 수준 아키텍처 구현 | CMIS 기반
SAP 연동, S3 암호화, Private Network |
9. 마치며
이번 ARMIQ Unicorn Gym에서 집중한 것은 AI-DLC를 팀 프로젝트에 실제로 적용하면서 드러난 빈틈을 메우는 실용적 보완이었습니다. 구체적으로는 세 가지입니다.
- Subagent 아키텍처와 응답 포맷 강제를 통해, 긴 INCEPTION–CONSTRUCTION 사이클 동안 Main Agent의 context가 잠식되지 않도록 했습니다.
- requirements-generator로 고객이 가진 비정형 문서를 구조화된 요구사항/제약사항으로 변환해, INCEPTION Phase에 바로 진입할 수 있게 했습니다.
- git-merge Skill과 unit별 전용 Code Review Skill로, 여러 개발자가 서로 다른 Unit을 병렬로 진행한 뒤 발생하는 상태 파일 conflict와 생성 코드 품질 문제를 실제로 해결했습니다.
이번 Unicorn Gym은 기존 AI-DLC에 Subagent 구조와 Custom Skill을 결합해, 팀 단위 운용에서 걸리던 부분들을 하나씩 해소한 시도입니다. AI-DLC를 실제 프로젝트에 도입하려는 팀에게 이번 구성이 참고 사례로 활용될 수 있기를 기대합니다. 실제 구성은 aws-samples/sample-aidlc-toolset-with-subagents-and-custom-skills 에서 확인할 수 있습니다.