AWS 기술 블로그
실제 사례로 알아보는 Cloudwatch Database Insights
이 글은 AWS Database Blog에 게시된 Amazon CloudWatch Database Insights applied in real scenarios by Cade Kettner, Nirupam Datta, and Ryan Moore을 한국어 번역 및 편집 하였습니다.
AWS는 2024년 12월 Amazon Aurora(PostgreSQL, MySQL 호환 버전)와 PostgreSQL, MySQL, MariaDB, SQL Server, Oracle용 Amazon Relational Database Service(Amazon RDS)를 위한 Amazon CloudWatch Database Insights가 발표되었습니다. CloudWatch Database Insights는 DevOps 엔지니어, 애플리케이션 개발자, 데이터베이스 관리자에게 맞춤형 환경을 제공하는 데이터베이스 모니터링 솔루션입니다. 이 기능은 데이터베이스 문제 해결 프로세스를 빠르게 진행하여 전체 데이터베이스 플릿(Fleet) 단위의 문제를 해결함으로써 전반적인 운영 효율성을 향상시키도록 설계되었습니다. 이 글에서는 CloudWatch Database Insights를 사용하여 RDS 와 Aurora 리소스 문제를 해결하는 방법을 보여드리도록 하겠습니다. AWS의 목표는 복잡한 데이터베이스 문제를 자신 있게 효율적으로 해결하는 데 필요한 지식과 기술을 제공하는 것입니다.
솔루션 개요
데이터베이스 관리자가 직면하는 일반적인 문제의 해결 과제에 대해 세 가지 시나리오를 보여드리겠습니다. 이 데모는 CloudWatch Database Insights를 탐색하고 사용하는 방법을 이해하는 데 도움이 될 것입니다. 이 시나리오를 살펴보기 전에 “New Amazon CloudWatch Database Insights: Comprehensive database observability from fleets to instances” 글을 참고하여 CloudWatch Database Insights의 개요를 확인하시는 것을 추천 드립니다.
요구 사항
관리 콘솔에서 CloudWatch Database Insights에 액세스하려면 이를 먼저 활성화해야 합니다. 이를 위해 RDS DB 인스턴스나 Aurora DB 클러스터에 대해 CloudWatch Database Insights의 Advanced Mode가 활성화되어야 합니다. 이 기능을 활성화하는 데는 비용이 발생합니다. 자세한 내용은 CloudWatch 요금 페이지를 참고해주십시오. Amazon RDS 와 Aurora용 CloudWatch Database Insights에는 두 가지 작동 모드가 있습니다. 표준(Standard) 모드는 데이터베이스 지표를 중심으로 한 기본 기능을 지원합니다. 고급(Advanced) 모드는 SQL 쿼리에 대한 실행 계획이나 Lock 분석, 쿼리 통계, 플릿(Fleet) 전체 모니터링 대시보드, CloudWatch에서 Amazon RDS 이벤트 보기 등의 추가 기능을 제공합니다. 자세한 비교는 Database Insights 모드에 대한 공식 매뉴얼을 참조해주십시오.
CloudWatch Database Insights 콘솔에 액세스 하기
Amazon CloudWatch 콘솔을 통해서 Cloudwatch database Insights 에 액세스 할 수 있습니다:
- Cloudwatch 콘솔의 탐색창에서 Insights 를 선택하고 다음 Database Insights 를 선택합니다.
- 패널 왼쪽의 “Database Instance” 를 선택합니다.
- 그리고 추가 조사를 원하는 RDS 인스턴스를 선택합니다.
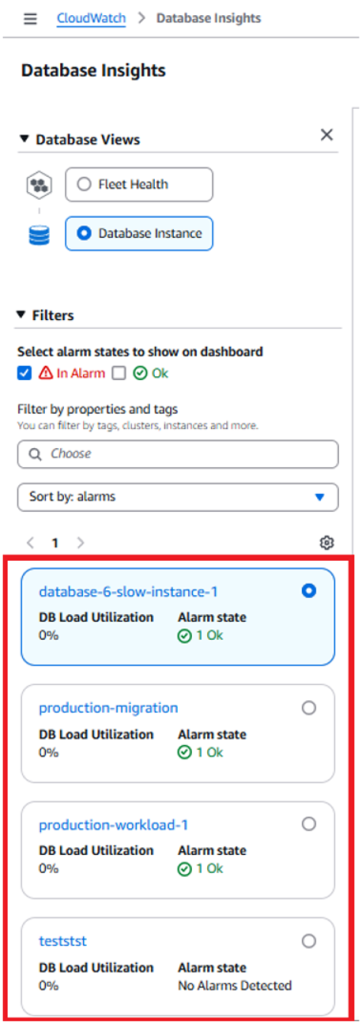
Demo #1: 인덱스 부재로 인한 쿼리 퍼포먼스 이슈
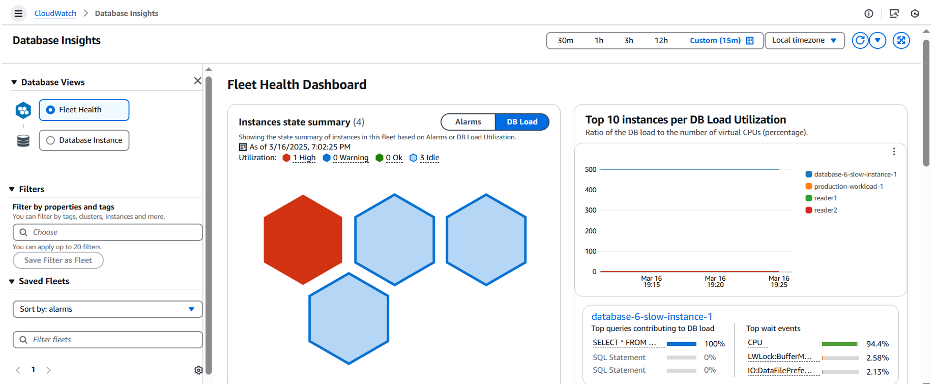
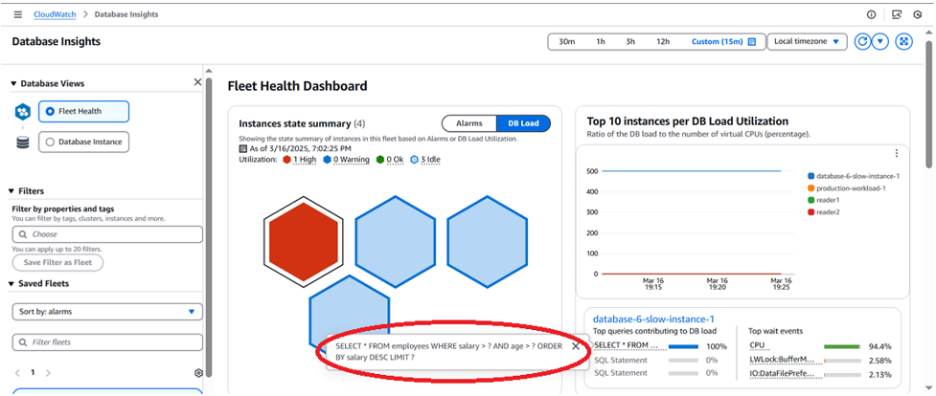
CloudWatch Database Insights는 최적화 되지 않은 쿼리를 식별하고 튜닝이나 최적화에 대한 단서를 제공하는 데 도움을 줄 수 있습니다. 이 예시에서는 테이블에 적합한 인덱스가 없어 수행 속도가 느린 쿼리를 보여줍니다. 테스트 설정에서는 샘플 데이터 세트가 포함된 Aurora PostgreSQL Writer 인스턴스(t3.medium)를 사용했습니다. 테스트 테이블인 employees에는 5,200만 개의 행을 가지며 크기는 약 10GB입니다. 이 데이터베이스를 사용하는 애플리케이션의 응답 시간이 증가하고 있습니다. 이 문제를 해결하기 위해 먼저 CloudWatch Database Insights Fleet Health 대시보드를 엽니다. 이 대시보드에는 모니터링되는 Aurora PostgreSQL 인스턴스 중 하나가 표시됩니다. 그중 하나에서 DB 부하가 발생하고 있으며 이는 빨간색 육각형으로 표시됩니다.
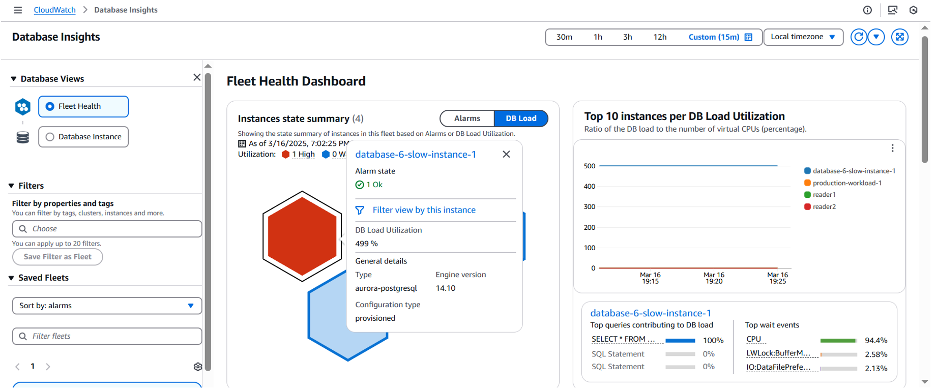
빨간색 육각형을 선택하면 아래와 같이 인스턴스에 대한 추가 정보를 확인할 수 있습니다. 여기에는 DB 인스턴스 이름, DB 부하 사용률 지표, 엔진 버전, 컴퓨팅 구성과 같은 추가 메타데이터가 포함됩니다.
Fleet Health Dashboard는 Fleet의 높은 부하를 알려줄 뿐만 아니라 부하에 가장 큰 영향을 미치는 쿼리도 표시합니다. 다음 보기에서 볼 수 있듯이 대부분의 부하를 유발하고 있는 읽기 쿼리가 표시됩니다.
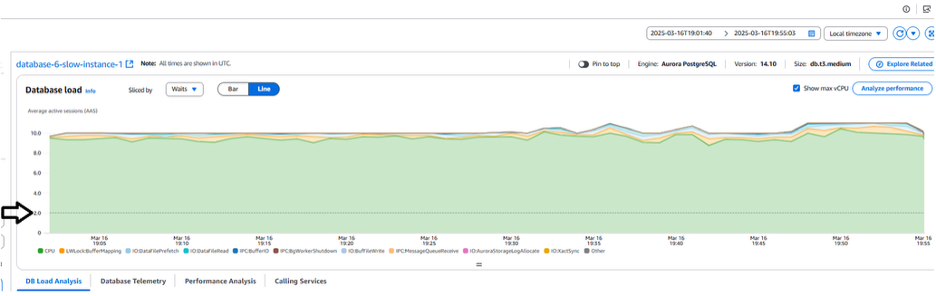
이 쿼리를 좀더 자세히 분석하기 위해 왼쪽 패널의 데이터베이스 뷰 아래에서 ‘Database Instance’ 를 선택해 보겠습니다. 데이터베이스 인스턴스 뷰를 선택하면 평균 활성 세션(AAS) 수로 표현된 데이터베이스 부하 지표를 볼 수 있습니다. AAS 수치는 아래 스크린샷에서 화살표가 가리키는 점선인 vCPU 기준선보다 훨씬 높습니다. 그래프에서 녹색으로 표시된 것처럼 활성 세션은 주로 CPU를 사용하고 있음을 알 수 있습니다. 이는 활성 데이터베이스 세션 수가 데이터베이스 인스턴스(t3.medium)의 vCPU 수를 초과함을 나타냅니다. 즉 CPU 사용량이 높아 인스턴스가 감당할 수 있는 수준을 초과한 워크로드가 발생했음을 의미합니다.
CPU와 IO:DataFilePreFetch와 같은 주요 대기 이벤트가 대부분의 부하를 유발하는 것을 확인할 수 있습니다. 이러한 대기 이벤트는 그래프 하단의 키에 포함되어 있습니다:

각 데이터베이스 엔진 별로 이 대기 이벤트는 각기 다른 명을 사용하지만 모두 유사한 주제를 따르며 워크로드 문제 진단에 중요한 역할을 합니다. 대기 이벤트 메뉴얼에서 설명하는 바와 같이 이 특정 대기 이벤트는 데이터베이스가 CPU를 사용 중이거나 CPU 사용을 기다리고 있음을 나타냅니다. 페이지 아래로 스크롤하여 이 문제를 일으키는 쿼리를 확인할 수 있습니다.
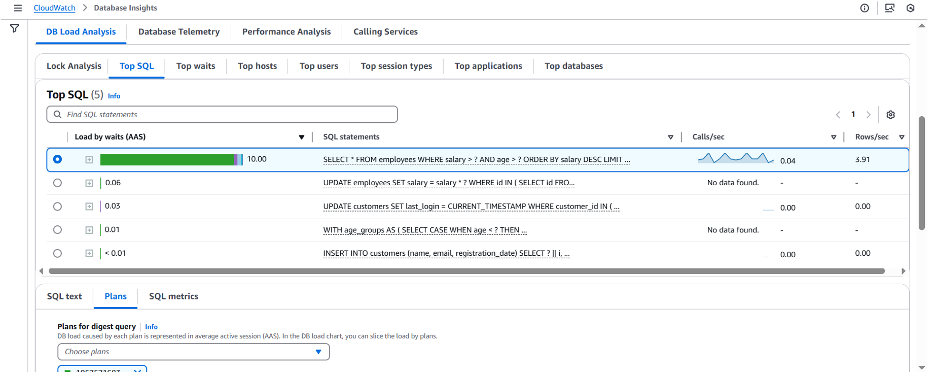
이전 뷰를 기반으로 처음에 Fleet Health Dashboard에서 확인했던 정보를 확인할 수 있습니다. 즉 해당 부하의 증가는 읽기 쿼리로 인해 발생했습니다. CloudWatch Database Insights 내 특정 데이터베이스 엔진의 경우 쿼리 실행 계획을 확인할 수 있습니다. 다음은 최적화 되지 않은 쿼리의 실행 계획을 살펴보겠습니다:
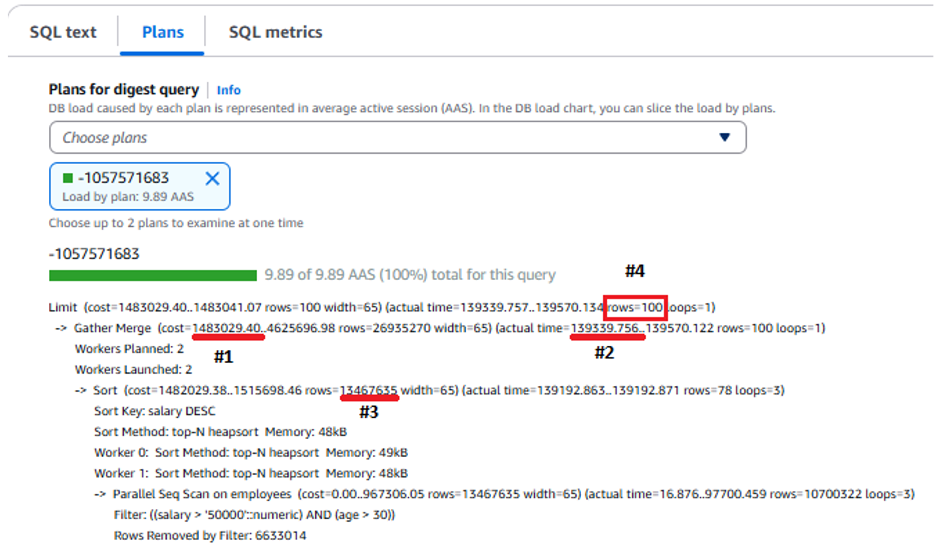
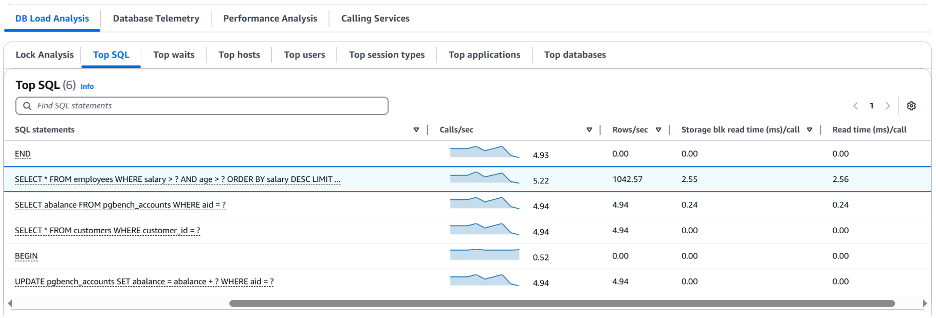
실행계획 상에서 해당 쿼리는 매우 높은 비용인 1,483,029 [#1] 을 가지며 실행 시간은 139,339 밀리초(milliseconds) [#2] 로 나옵니다. 추가적으로 100건의 결과를 도출 하기 위해서 1300만건에 가까운 행을 정렬했습니다. 이 쿼리의 성능이 좋지 않다는 것을 명확하게 확인 하기 위해 아래의 문장(SQL Statement) 수준의 매트릭을 검토해 보겠습니다.
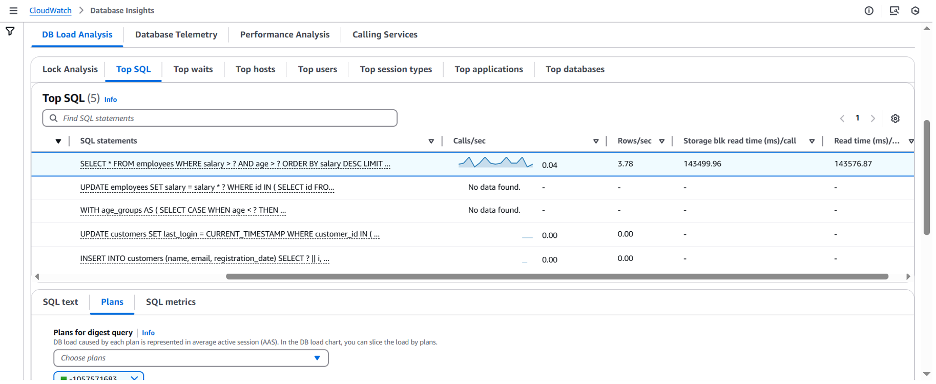
“Top SQL” 탭 오른쪽 상단의 설정 아이콘을 사용하여 각 쿼리에 대한 추가 지표를 선택했습니다. 여기에는 Storage blk read time (ms)/call 과 Read time (ms)/call) 이 포함됩니다. 이러한 지표는 선택한 기간 동안 집계되지만 문제가 발생한 기간 동안 각 쿼리가 디스크에서 블록을 읽는 데 소요된 총 시간과 각 호출(실행)당 소요된 시간을 파악하는 데 도움이 될 수 있습니다. Aurora PostgreSQL 호환 데이터베이스의 SQL 통계에 대한 자세한 내용은 Aurora PostgreSQL의 SQL 통계를 참조해 주십시오.
이 특정 쿼리는 호출 당 143초가 넘게 소요되고 있으며 Storage blk read time (ms)/call을 기준으로 볼 때 대부분의 시간을 스토리지에서 블록 읽기를 수행하는 데 사용되고 있습니다. “SQL Metrics” 를 선택하면 특정 SQL 쿼리에 대한 시간별 이러한 지표의 과거 데이터를 검토할 수 있습니다. 아래에서 문제가 있는 읽기 쿼리에 대한 시간별 calls/sec 을 확인할 수 있습니다.
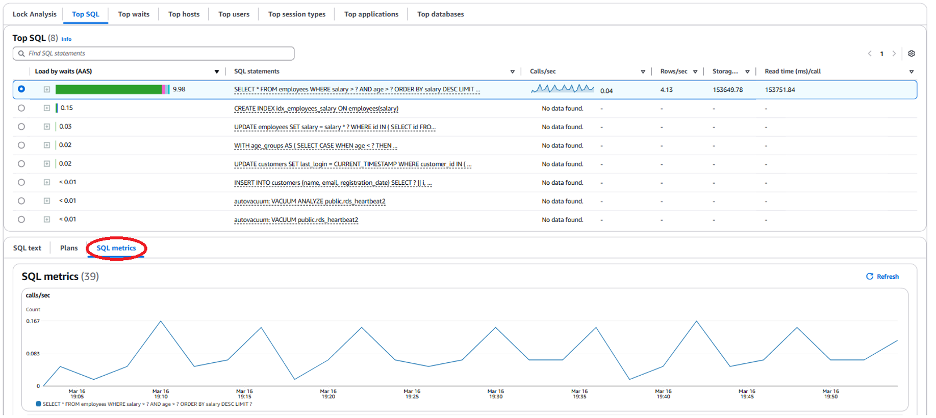
아래로 스크롤하면 SQL 쿼리에 대해 수집된 모든 매트릭을 확인할 수 있습니다. 아래에서는 앞서 언급했듯이 이 쿼리에 대해 매우 높은 storage blk read 매트릭을 확인할 수 있습니다.
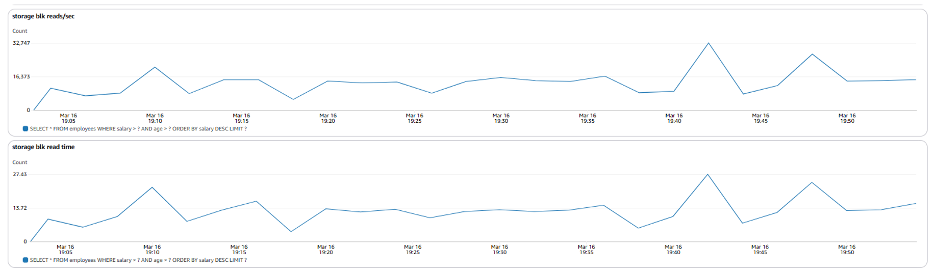
지금까지 수집한 정보를 바탕으로 employees 테이블의 salary 컬럼에 인덱스를 추가하면 도움이 될 가능성이 높습니다. 앞서 살펴본 것과 같이 쿼리는 조건절에 이 컬럼이 사용됩니다. 인덱스를 추가하게 되면 데이터베이스가 이 컬럼과 해당 컬럼을 사용하는 다른 쿼리에 대해 더 나은 실행 계획을 선택하는데 도움이 될 것입니다. Dbeaver를 사용해서 현재 이 테이블에 존재하는 인덱스를 확인할 수 있습니다.
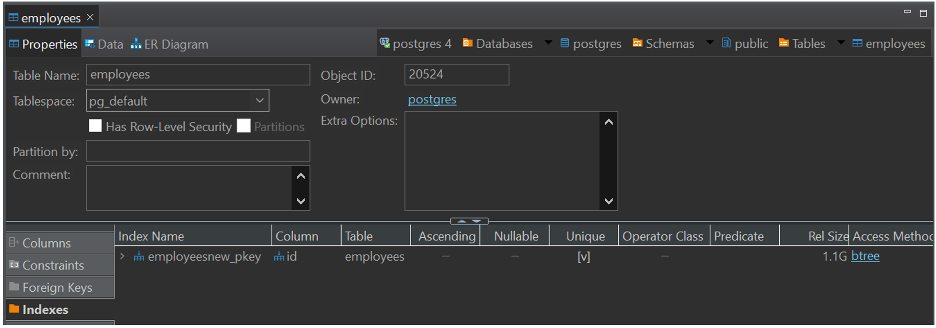
조회되는 바와 같이 테이블에는 Primary Key만 있고 Secondary Key(Index)가 없습니다. 다음 구문을 사용하여 Salary 컬럼에 인덱스를 추가하고 이것이 Aurora PostgreSQL 인스턴스의 부하를 줄이는 데 도움이 되는지 확인해 보겠습니다.

인덱스를 추가한 후 Fleet Health Dashboard에서 DB 부하 사용률이 급격히 감소한 것을 확인할 수 있습니다. 또한 DB 부하 요약이 녹색 육각형으로 표시된 ‘OK’ 로 변경된 것을 확인할 수 있습니다.
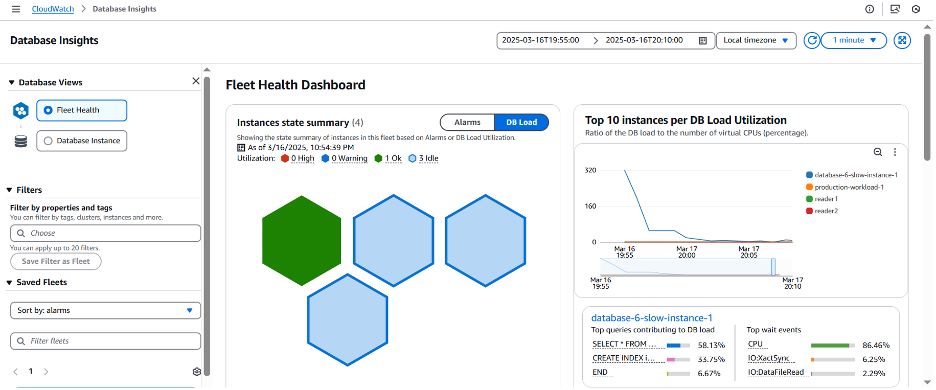
Database Instance 뷰를 선택하면 3월 16일 19:56 UTC에 인덱스를 추가한 후 AAS가 점선인 vCPU 선 아래로 떨어진 것을 확인할 수 있습니다.
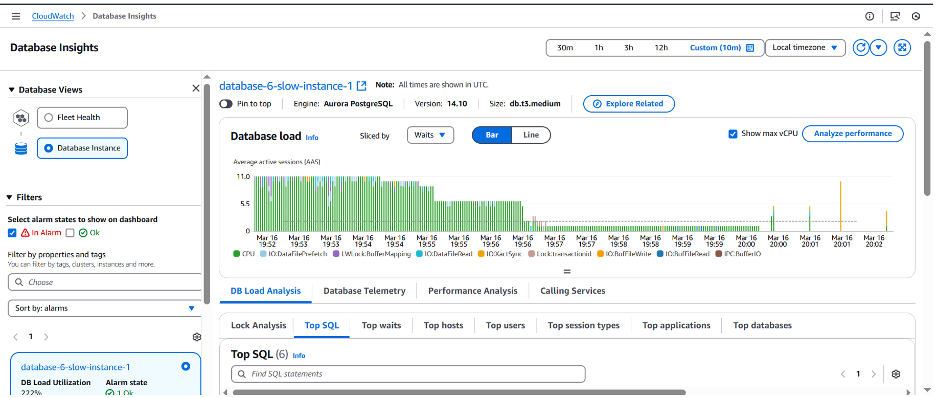
다음으로 문제가 있는 쿼리가 개선되었는지 확인하실 수 있습니다.
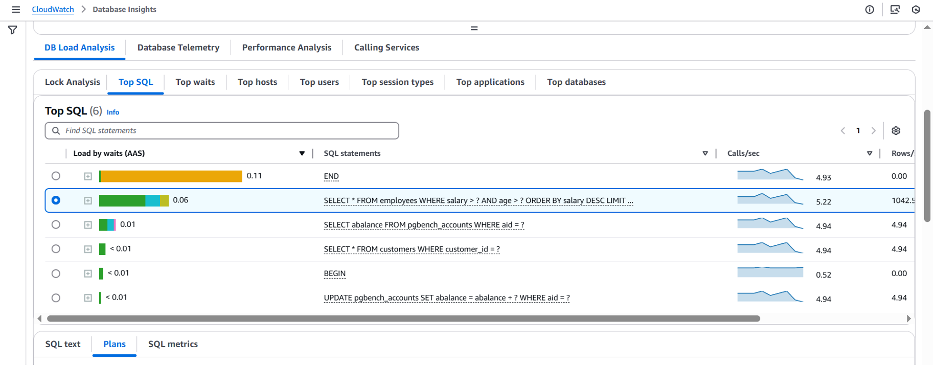
아래에서 볼 수 있듯이 새로 추가된 인덱스를 통해 쿼리 플랜의 성능이 훨씬 향상되었습니다. 비용은 0.56으로 크게 감소했고 현재 쿼리 수행시간은 10밀리초입니다.
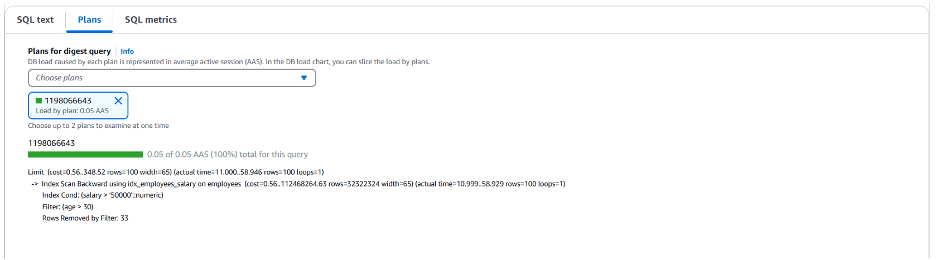
새로운 보조 인덱스 덕분에 SQL 지표도 향상되는 것을 확인할 수 있습니다. 이제 이 쿼리를 더 자주(초당 5회) 호출할 수 있게 되었고 디스크 읽기 시간은 99.99% 가 줄어 들었습니다.
CloudWatch Database Insights를 사용하여 문제를 해결함으로써 테이블의 인덱스 누락으로 인해 발생한 데이터베이스 성능 문제를 빠르고 효과적으로 완화할 수 있었습니다. 약간의 데이터베이스 기본 지식이 필요하지만 Database Insights 덕분에 문제를 파악하고 해결에 필요한 모든 데이터와 수정 사항을 검증할 수 있는 지표를 얻을 수 있었습니다.
Demo #2: 데이터베이스 마이그레이션 중 스토리지 용량 제한에 도달
스토리지 용량 관리는 데이터베이스 관리의 중요한 측면으로, 간과될 경우 심각한 성능 문제나 애플리케이션 중단으로 이어질 수 있습니다. 간혹 데이터베이스가 빠르게 증가하기 때문에 적절한 모니터링과 관리가 없다면 예기치 못한 스토리지 제한에 도달할 수 있습니다. 스토리지 가득 참 상태라고 하는 이러한 시나리오는 애플리케이션 장애, 데이터 삽입 오류, 그리고 심각한 성능 저하를 초래할 수 있습니다. 다운타임이 발생하는 데이터 마이그레이션 중에 RDS for MySQL 인스턴스가 스토리지 용량 한계에 도달하는 실제 시나리오를 시뮬레이션해 보겠습니다. CloudWatch Database Insights가 임박한 스토리지 문제를 식별하고 관리자에게 알람을 제공하는 데 어떻게 도움이 되는지 살펴보겠습니다.
이 예에서는 개발 팀이 온프레미스에서 35GB의 MySQL 데이터베이스를 MySQL용 RDS로 마이그레이션하고 있습니다. 그러나 마이그레이션 중에 다음과 같은 오류와 함께 애플리케이션 수준의 장애 알람을 받게 됩니다.
ERROR 2002 (HY000): Can't connect to MySQL server on 'production-migration.xxxxxx.us-east-1.rds.amazonaws.com' (115)
ERROR 1053 (08S01): Server shutdown in progress
이 문제를 조사하기 위해 CloudWatch Database Insights 내의 Fleet Health Dashboard로 이동해 보겠습니다. 이전 시나리오와 유사하게 인스턴스 중 하나가 빨간색으로 표시되고 있습니다. 하지만 이번에는 빨간색 육각형의 인스턴스가 높은 DB 부하가 아닌 경고 상태에 있음을 나타냅니다. 이는 이전에 구성된 CloudWatch 경보가 정의된 임계값을 초과하고 있음을 의미합니다. Amazon RDS에서 CloudWatch 알람을 구성하는 방법을 알아보려면 Amazon RDS 모니터링을 위한 CloudWatch 경고 생성을 참조해주십시오.
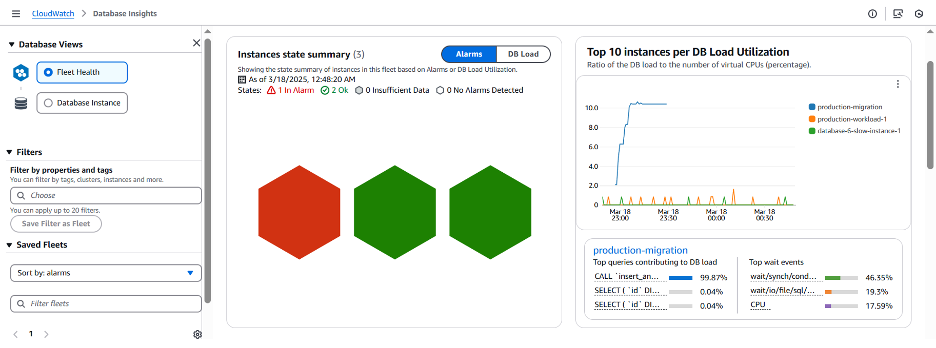
페이지를 더 아래로 스크롤하면 Fleet 전체에서 총 24개의 RDS 이벤트가 있으며 이 중 2개는 중간 심각도, 22개는 낮은 심각도입니다. 이러한 이벤트는 선택한 기간 동안 Fleet에서 발생한 상황에 대한 추가적인 단서나 맥락을 제공하는 데 도움이 됩니다.
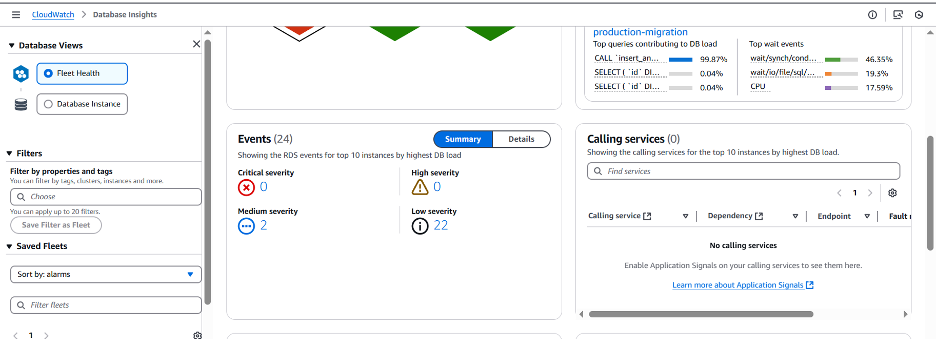
Free storage capacity for DB instance production-migration is low at 1% of the allocated storage [Allocated storage: 19.27 GB, Free storage: 176.68 MB]. The database will be shut down to prevent corruption if free storage is lower than 300.01 MB. You can increase the allocated storage to address this issue.
이러한 이벤트를 자세히 살펴보면 RDS 인스턴스의 프로덕션 마이그레이션이 스토리지 최대 용량에 도달했으며 내장된 Amazon Elastic Block Store(Amazon EBS) 볼륨의 손상을 방지하기 위해 중지를 수행한 것임을 알 수 있습니다.
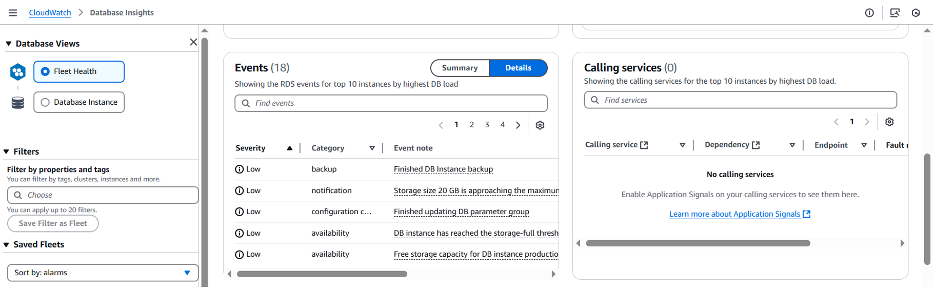
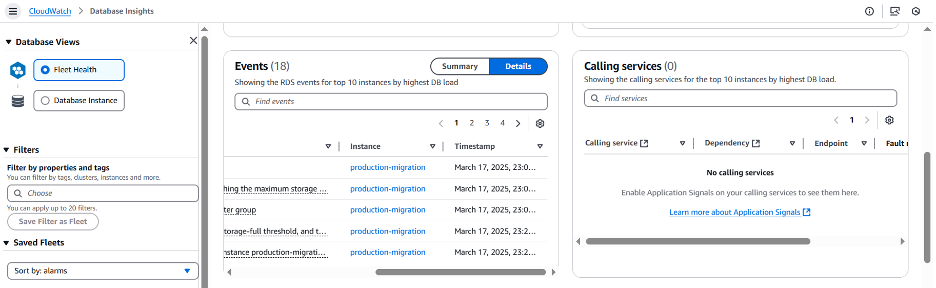
인스턴스 수준의 보기를 검토하여 어떤 CloudWatch 알람이 위배되었는지 확인하고 데이터베이스의 현재 상태를 확인해 보겠습니다.
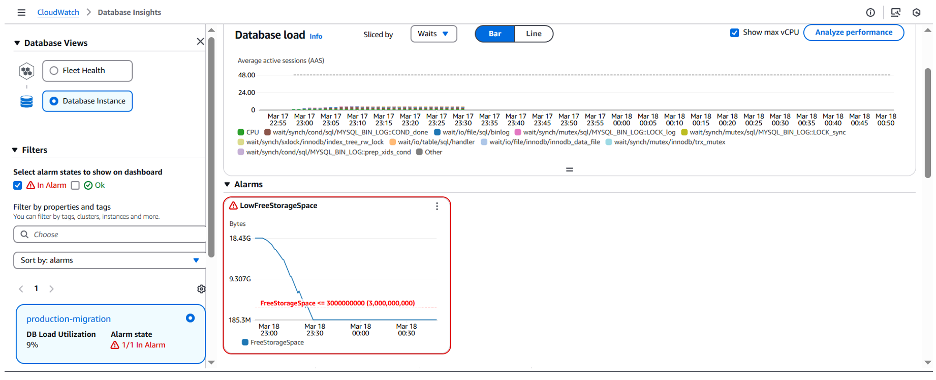
FreeStorageSpace 지표에 구성된 CloudWatch 알람이 3GB로 설정된 임계값을 초과했음을 확인할 수 있습니다. 저장 공간이 부족할 때 알림을 받으려면, CloudWatch 알람을 설정하는 것이 좋습니다. 이렇게 하면 RDS 이벤트에서 이전에 제안한 것처럼 할당된 공간이 모두 소진되었음을 확인할 수 있습니다.
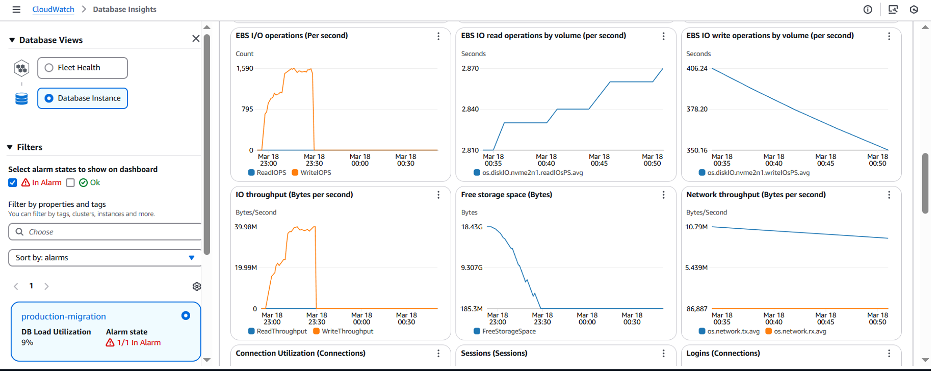
Database Telemetry로 이동하면 공간이 소진된 후에 Read IOPS 와 Write IOPS와 같은 기타 Amazon EBS 관련 측정 항목이 0으로 감소한 것을 확인할 수 있습니다. 이는 데이터베이스가 정지된 경우 예상되는 현상입니다.
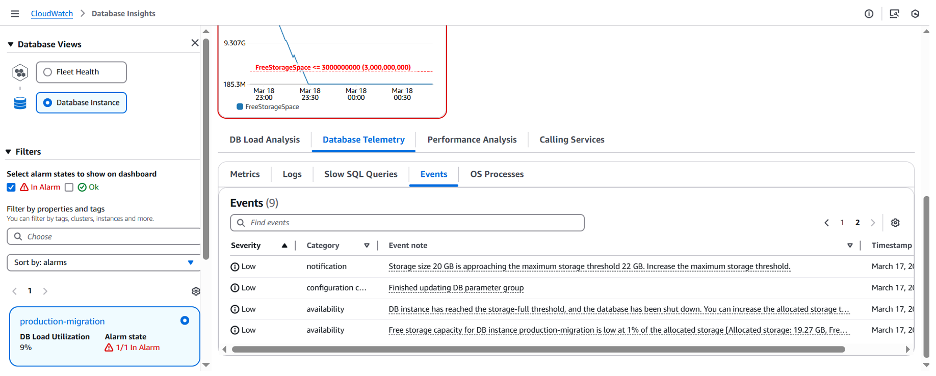
마지막으로 문제를 해결하기 전에 이벤트(Events) 섹션을 확인하여 이 인스턴스(운영-마이그레이션)에서 발생한 모든 이벤트를 확인할 수 있습니다. 이를 통해 데이터베이스가 실제로 정지 되었는지 확인할 수 있습니다.
DB instance has reached the storage-full threshold, and the database has been shut down. You can increase the allocated storage to address this issue.
이러한 세부 정보는 애플리케이션에서 연결 오류가 발생하는 이유를 설명합니다. RDS 이벤트에서 언급된 바와 같이 데이터베이스 인스턴스가 시작될 수 있도록 할당된 스토리지를 늘려야 합니다. Amazon RDS 콘솔로 이동하여 현재 스토리지가 Full 인 상태인 production-migration 인스턴스를 선택할 수 있습니다.
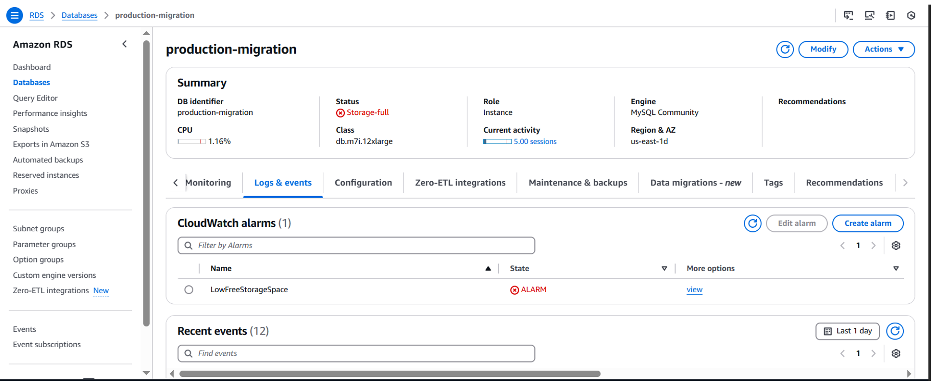
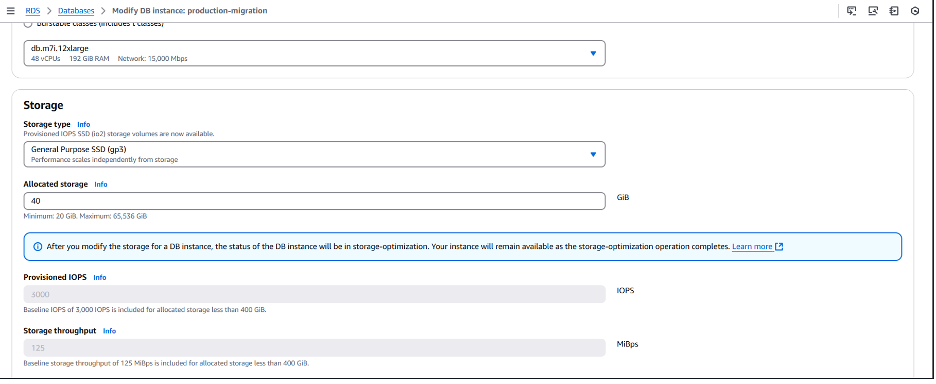
다음 단계는 변경 작업을 성공적으로 완료하기 위해 스토리지 용량을 최소 10% 늘리는 것입니다. 다음 예에서 데이터베이스에 할당된 스토리지 용량을 모두 사용하지 않고 약 35GB의 데이터 셋을 마이그레이션할 수 있도록 스토리지 용량을 20GiB에서 40GiB로 늘려 보겠습니다. 스토리지 크기 조정 단계와 고려 사항에 대한 자세한 내용은 DB 인스턴스 스토리지 용량 늘리기를 참조해주십시오.
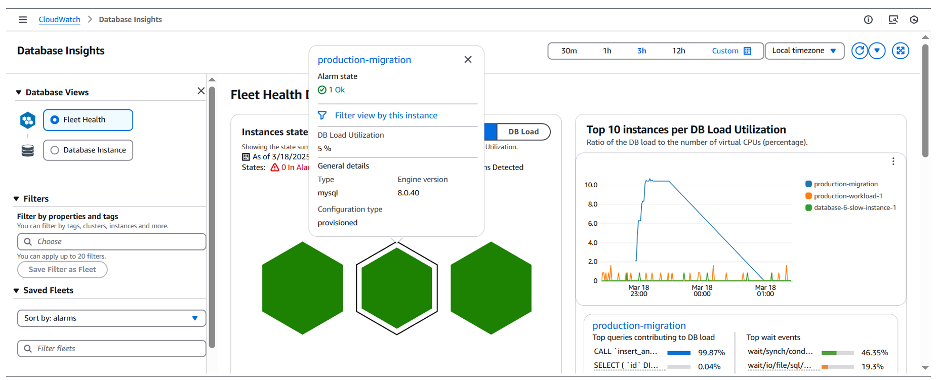
수정을 실행한 뒤 CloudWatch Database Insights를 사용하여 RDS MySQL 인스턴스의 production-migration이 실행 중인지 알람 상태가 사라졌는지 확인할 수 있습니다.
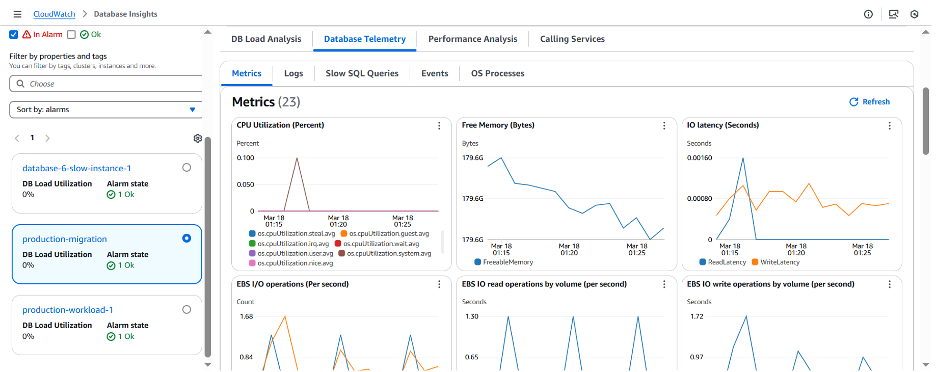
Database Telemetry 뷰를 확인하면 스토리지 관련 CloudWatch 지표를 검토하여 인스턴스에 충분한 여유 스토리지가 있는지 확인할 수 있습니다. CPU 사용률이나 여유 메모리와 같은 다른 지표도 정상 수준으로 보입니다.
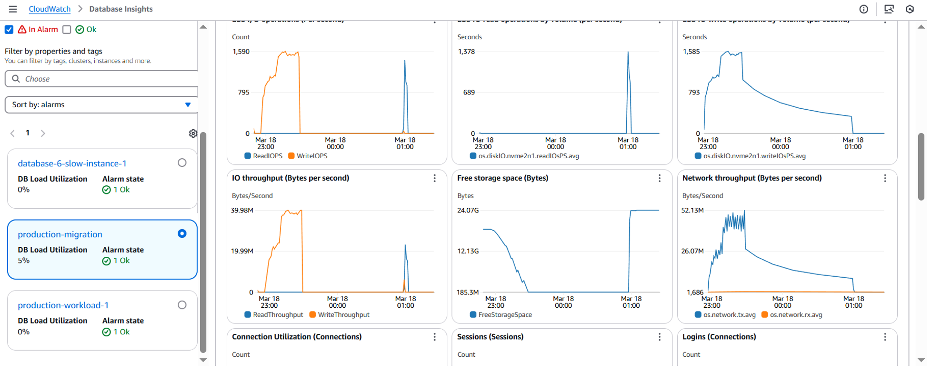
데모 #3: Out-of-Memory 이슈로 인한 데이터베이스 재시작
메모리 부족(OOM) 오류로 인한 안정성 문제는 많은 DBA에게 익숙한 또 다른 일반적인 시나리오입니다. 이 문제를 시뮬레이션하고 식별해서 완화하는 방법을 보여드리겠습니다. 먼저 Fleet Health Dashboard를 살펴보겠습니다.
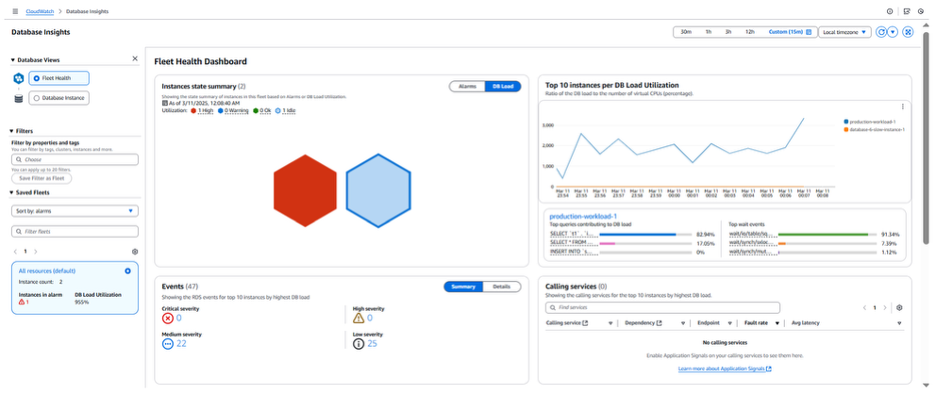
Fleet Health Dashboard 에서 볼 수 있듯이 빨간색 육각형으로 표시된 RDS 인스턴스에 높은 DB 부하 경고가 표시되어 있습니다. 오른쪽 창(“Top 10 instance…”)에서 production-workload-1 인스턴스가 매우 높은 수준의 DB 부하를 겪고 있음을 확인할 수 있습니다. Fleet Health Dashboard의 알람 부분으로 이동해 보겠습니다.
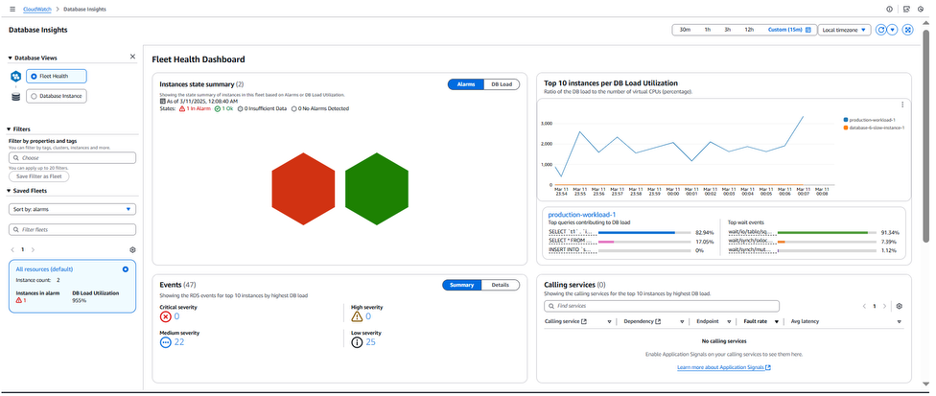
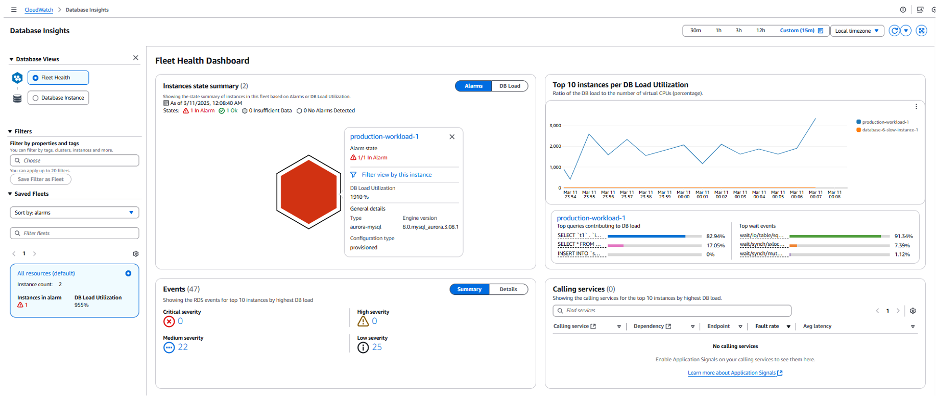
이 문제와 관련하여 빨간색 육각형은 인스턴스에 하나 이상의 활성화된 CloudWatch 알람이 있음을 나타냅니다. 예시에서 production-workload-1 인스턴스의 EngineUptime CloudWatch 지표에 활성화된 알람이 설정되어 있으며 이 알람은 정의된 임계값을 초과했습니다. 데이터베이스 가용성에 영향을 미치는 이벤트가 발생할 때 알림을 받으려면 EngineUptime 지표에 CloudWatch 알람을 구성하는 것이 좋습니다. 이 알람이 위배되면 인스턴스의 가용성 문제가 있음을 의미하며 이는 데이터베이스가 재시작되어 EngineUpTime 지표가 재설정되는 모든 상황을 의미합니다. 이 문제의 잠재적 원인을 확인하기 위해 페이지 아래로 스크롤하여 인스턴스의 메모리 및 CPU 지표를 검토하고 단서를 찾을 수 있는지 확인해 보겠습니다.
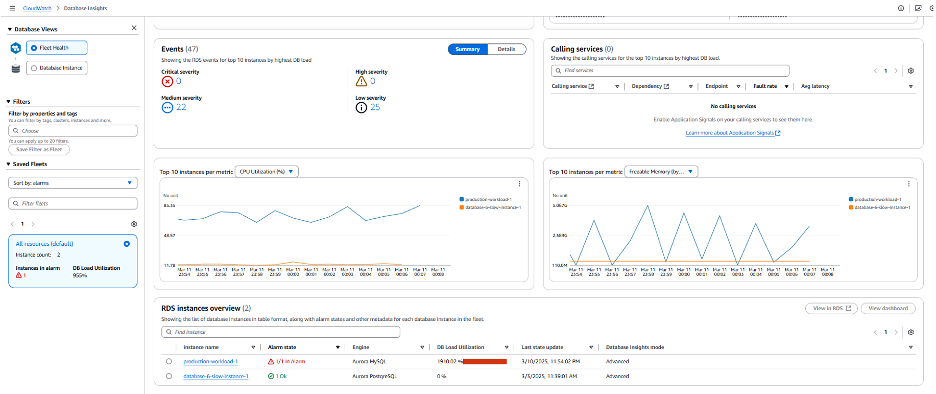
다음 스크린샷에서 볼 수 있듯이 사용 가능한 메모리 그래프의 파란색 선은 메모리 수준이 극단적인 값(메모리가 거의 가득 찬 상태부터 메모리가 거의 비어 있는 상태까지) 사이를 왔다 갔다 하고 있음을 나타냅니다. 이는 반복적인 재부팅의 잠재적인 현상일 수 있습니다. 이를 확인하기 위해 왼쪽 창에서 데이터베이스 인스턴스 뷰를 선택하도록 하겠습니다.
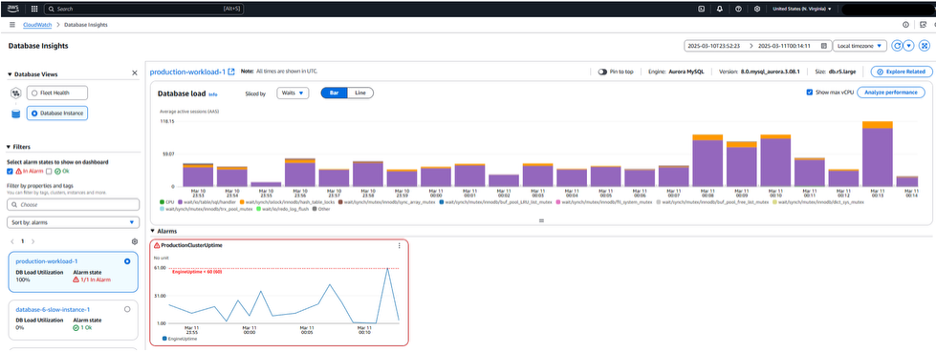
데이터베이스 부하가 증가하는 것을 확인할 수 있으며 이전에 Fleet Health Dashboard에서 확인했던 것처럼 CloudWatch 알람 ProductionClusterUptime이 경보 상태인 것을 확인할 수 있습니다. 더 아래로 스크롤하면 데이터베이스 부하를 유발하는 주요 쿼리를 확인할 수 있습니다.
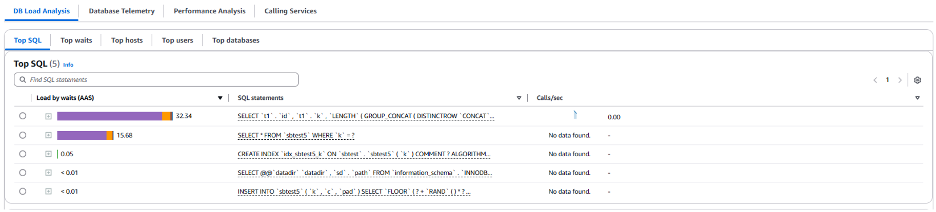
이 데이터베이스에서 두 가지 유형의 SELECT 쿼리가 주요 부하 원인으로 작용하는 것으로 보입니다. 또한 데이터베이스 Database Telemetry 탭으로 이동하여 이 인스턴스의 메트릭을 검토해서 해당 쿼리가 데이터베이스에 미치는 영향에 대한 자세한 정보를 수집할 수 있습니다.
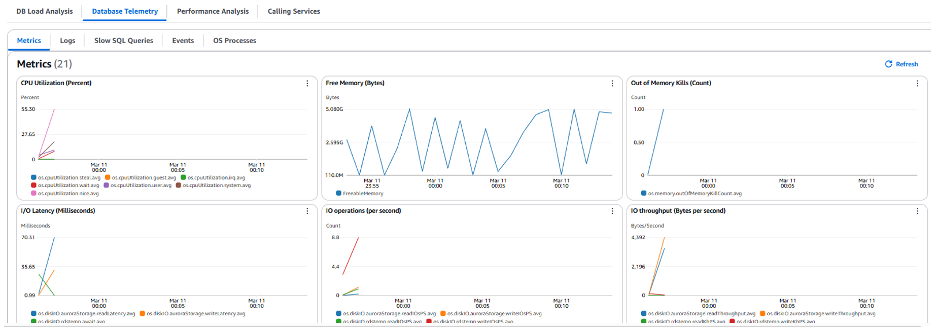
Fleet Health Dashboard에서 확인했던 것과 유사하게 메모리가 0에 가까운 수준으로 자주 감소하고 있습니다. 또한 다른 지표에서도 데이터 포인트가 누락되는 현상이 나타나는데 이는 안정성 문제를 나타내는 또 다른 잠재적 징후입니다. 메모리 부족이 문제의 원인인지 확인하려면 Database Telemetry의 이벤트 탭으로 이동하여 인스턴스의 특정 RDS 이벤트를 확인할 수 있습니다.
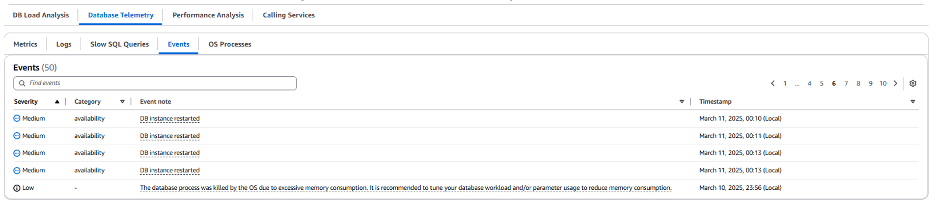
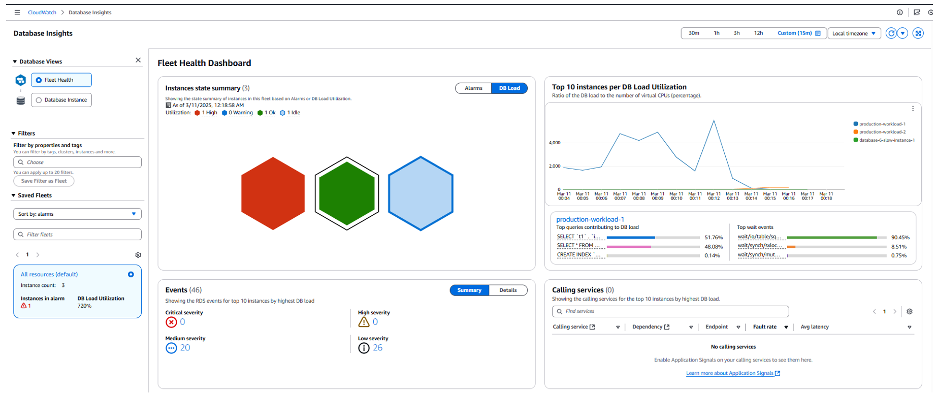
이벤트에서 볼 수 있듯이 데이터베이스가 반복적으로 재시작되고 있으며 과도한 메모리 소모로 인해 운영 시스템이 데이터베이스 프로세스를 중지했다는 경고 메시지가 주기적으로 표시됩니다. 이 문제를 일시적으로 해결하기 위해 더 큰 인스턴스 클래스(db.r8g.24xlarge)를 사용하여 인스턴스를 생성하고 장애 조치(failover)를 수행하여 워크로드에 더 많은 리소스를 제공할 수 있습니다. 아래 스크린샷에서 볼 수 있듯이 이렇게 하면 플릿(production-workload-2)에 인스턴스가 추가됩니다. 장애 조치(Failover) 후 데이터베이스 부하가 수용 가능함을 나타내는 ‘OK’ 상태로 즉시 전환됩니다.
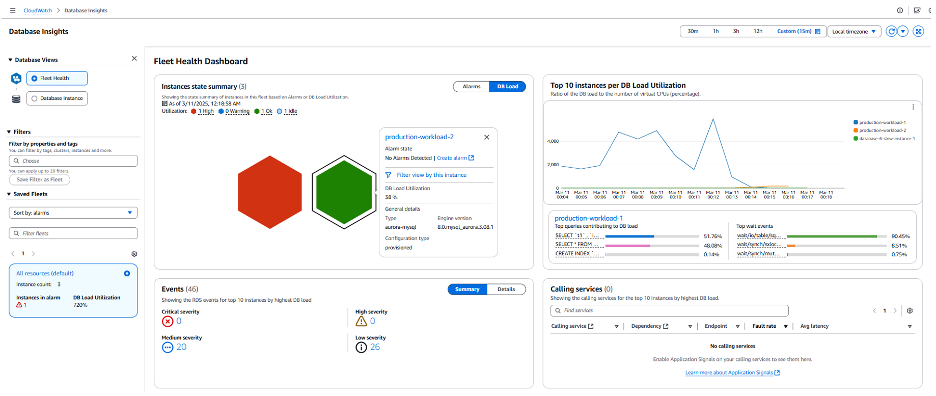
또한 이전 그래프에서 장애 조치(Failover) 후 원래 인스턴스인 production-workload-1의 DB 부하가 감소하는 것을 확인할 수 있습니다. 이 신규 인스턴스에서 OOM 으로 인한 재부팅이 발생하지 않는지 확인하려면 Database Instance 뷰로 이동해 봅니다.
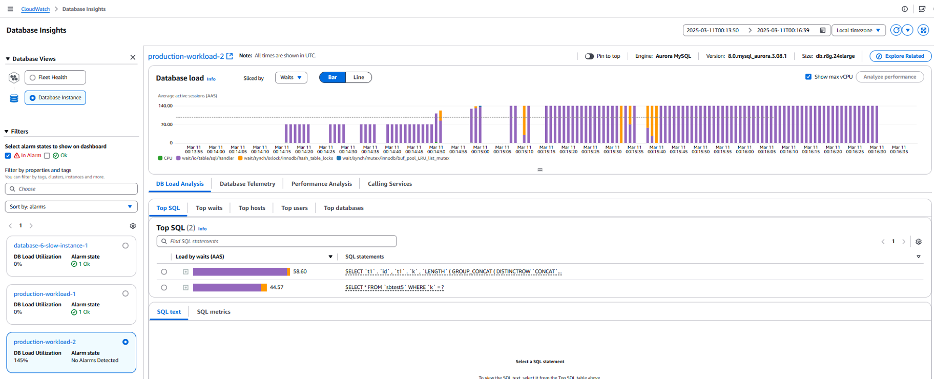
이전 스크린샷에서 볼 수 있듯이 여전히 동일한 쿼리를 실행하고 있지만 리소스(vCPU, Memory)가 늘어나서 부하가 훨씬 낮아졌습니다. Database Telemetry 분석 탭으로 이동하여 메모리가 더 이상 거의 0으로 떨어지지 않았는지를 확인할 수 있습니다.
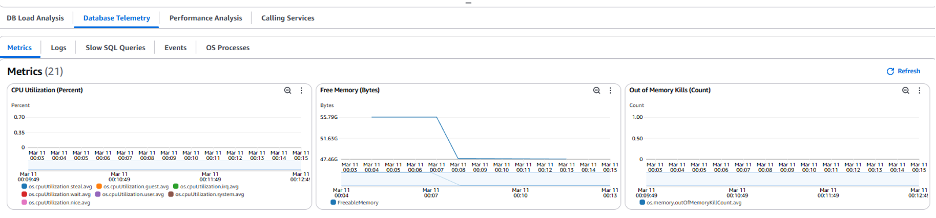
이제 허용 가능한 양의 메모리가 확보되었으므로 애플리케이션 팀과 함께 트래픽 증가 원인을 추가로 조사하기 전까지는 이 인스턴스 크기 변경을 통해 워크로드를 원활히 처리할 수 있을 것입니다. 부하가 정상화되고 인스턴스 크기를 줄여도 안전하다고 판단되면 원래 인스턴스(production-workload-1)로 장애 조치(Failover)를 수행하고 큰 인스턴스(production-workload-2)를 삭제할 수 있습니다.
물론 인스턴스 크기를 늘리는 것이 이러한 쿼리 문제에 대한 임시 해결책이긴 하지만 쿼리 최적화를 검토하는 것이 논리적인 다음 단계일 수 있습니다.
결론
지금까지 CloudWatch Database Insights를 사용하여 데이터베이스 문제를 해결하는 방법을 살펴보았습니다. 이 기능에 익숙해지려면 CloudWatch Database Insights를 더 자세히 살펴 보시는 것을 추천드립니다.