AWS 기술 블로그
Amazon OpenSearch Service백프레셔와 Admission Control에 대한이해와 클러스터 복원력 향상
“이 게시글은 AWS Big Data Blog에 작성된 “Improved resiliency with backpressure and admission control for Amazon OpenSearch Service” 블로그를 번역및 편집 하였습니다.”
Amazon OpenSearch Service는 AWS가 관리하는 관리형 서비스로 클라우드 환경에서 OpenSearch 클러스터를 대규모로 보안, 배포 및 운영하는 것을 간단하게 만들어주는 관리형 서비스입니다. 2022년 OpenSearch는 내부적으로 샤드 인덱싱 백프레셔와 admission control이 적용 되었고, 이 기능을 통하여 클러스터 리소스와 수신 트래픽을 모니터링하여 메모리 부족과 같은 안정성 위험을 야기하고 메모리 경합, CPU 포화, GC 오버헤드 등으로 인해 클러스터 성능에 영향을 미칠 수 있는 요청을 선택적으로 거부할 수 있도록 개선되었습니다.
2023년 클러스터의 복원력을 더욱 향상시키는 Search Backpressure와 CPU 기반 Admission Control이 Amazon OpenSearch Service에 도입되었고, 이러한 개선 사항은 OpenSearch 버전 1.3 이상의 모든 버전에 적용되어 있으며 기본적으로 활성화 되어 있습니다.
Search Backpressure
백프레셔는 시스템이 작업으로 인해 과부하되는 것을 방지합니다. 트래픽 속도를 제어하거나 과도한 부하를 제거하여 크래시와 데이터 손실을 방지하고, 성능을 개선하며, 시스템의 전체적인 장애를 피합니다.
Search Backpressure는 노드가 부하를 받고 있을 때 진행 중인 리소스 집약적인 검색 요청을 식별하고 취소하는 메커니즘입니다. 이는 비정상적으로 높은 리소스 사용량을 보이는 검색 워크로드(복잡한 쿼리, 느린 쿼리, 많은 히트 수, 또는 무거운 집계 등)에 효과적이며, 그렇지 않으면 노드 크래시를 유발하고 클러스터의 상태에 영향을 미칠 수 있습니다.
Search Backpressure는 각 작업의 리소스 사용량을 모니터링하기 위한 사용하기 쉬운 API를 제공하는 작업 리소스 추적 프레임워크 위에 구축되었습니다. Search Backpressure는 주기적으로 노드의 리소스 사용량을 측정하고 CPU 시간, 힙 할당, 경과 시간과 같은 요소를 기반으로 진행 중인 각 검색 작업에 취소 점수를 할당하는 백그라운드 스레드를 사용합니다. 더 높은 취소 점수는 더 리소스 집약적인 검색 요청에 해당합니다. 검색 요청은 노드를 빠르게 복구하기 위해 취소 점수의 내림차순으로 취소되지만, 불필요한 작업을 피하기 위해 취소 횟수는 속도 제한됩니다.
다음 다이어그램은 Search Backpressure 워크플로우를 보여줍니다.

검색 요청은 취소 시 HTTP 429 “Too Many Requests” 상태 코드를 반환합니다. 일부 샤드만 실패하고 부분 결과가 허용되는 경우 OpenSearch는 부분 결과를 반환합니다. 다음 코드를 참조하세요.
{
"error": {
"root_cause": [
{
"type": "task_cancelled_exception",
"reason": "cancelled task with reason: heap usage exceeded [403mb >= 77.6mb], elapsed time exceeded [1.7m >= 45s]"
}
],
"type": "search_phase_execution_exception",
"reason": "SearchTask was cancelled",
"phase": "fetch",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "nyc_taxis",
"node": "9gB3PDp6Speu61KvOheDXA",
"reason": {
"type": "task_cancelled_exception",
"reason": "cancelled task with reason: heap usage exceeded [403mb >= 77.6mb], elapsed time exceeded [1.7m >= 45s]"
}
}
],
"caused_by": {
"type": "task_cancelled_exception",
"reason": "cancelled task with reason: heap usage exceeded [403mb >= 77.6mb], elapsed time exceeded [1.7m >= 45s]"
}
},
"status": 429
}Search Backpressure 모니터링
노드 통계 API를 사용하여 자세한 Search Backpressure 상태를 모니터링할 수 있습니다.
curl -X GET “https://{endpoint}/_nodes/stats/search_backpressure”
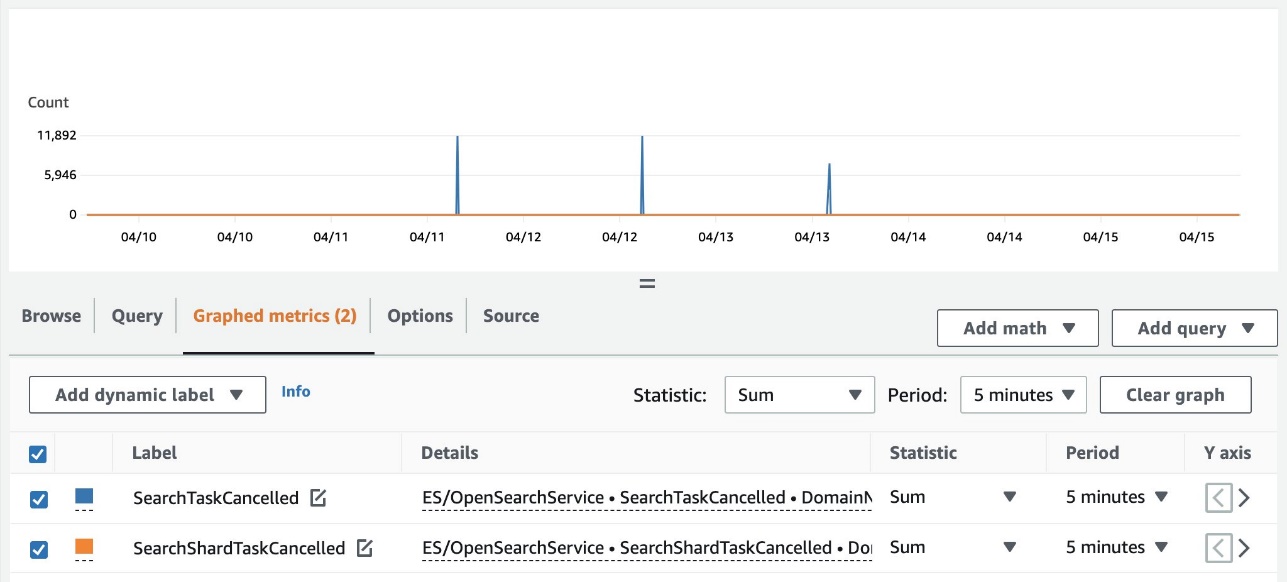
Amazon CloudWatch를 사용하여 클러스터 검색을 거부하는 매트릭의 요약을 볼 수도 있습니다. CloudWatch의 ES/OpenSearchService 네임스페이스에서 아래의 매트릭을 통해 확인 가능합니다.
- SearchTaskCancelled – 코디네이터 노드 검색 거부 횟수
- SearchShardTaskCancelled – 데이터 노드 검색 거부 횟수
다음 스크린샷은 CloudWatch 콘솔에서 이러한 메트릭을 추적하는 예시를 보여줍니다.
CPU 기반 Admission Control
Admission Control은 유기적인 검색 요청 증가와 트래픽 급증 모두에 대해 노드의 현재 용량을 기반으로 노드에 대한 검색 요청 수를 사전에 제한하는 게이트키핑 메커니즘입니다.
JVM 메모리 압박과 요청 크기 임계값에 더하여, 각 노드의 평균 CPU 사용량을 모니터링하여 수신되는 _search 및 _bulk 요청을 거부합니다. 이는 노드가 너무 많은 요청으로 인해 과부하되어 핫스팟, 성능 문제, 요청 타임아웃 및 기타 연쇄적 장애가 발생하는 것을 방지합니다. 과도한 요청은 거부 시 HTTP 429 “Too Many Requests” 상태 코드를 반환합니다.
HTTP 429 오류 처리
노드에 과도한 트래픽을 보내면 HTTP 429 오류를 받게 됩니다. 이는 클러스터 리소스 부족, 리소스 집약적인 검색 요청, 또는 의도하지 않은 워크로드 급증을 나타냅니다.
Search Backpressure는 거부 이유를 제공하므로 리소스 집약적인 검색 요청을 미세 조정하는 데 도움이 될 수 있습니다. 트래픽 급증의 경우 지수 백오프와 지터를 사용한 클라이언트 측 재시도를 권장합니다.
과도한 거부를 디버그하기 위해 다음 문제 해결 가이드를 따를 수도 있습니다.
- OpenSearch Service에서 검색 또는 쓰기 거부를 해결하는 방법은 무엇입니까?
- Amazon OpenSearch Service 클러스터에서 검색 지연 시간 급증 문제를 해결하는 방법은 무엇입니까?
결론
Search Backpressure는 과도한 부하를 제거하는 반응적 메커니즘이며, 허용 제어는 노드의 용량을 초과하는 요청 수를 제한하는 사전 예방적 메커니즘입니다. 둘 다 함께 작동하여 OpenSearch 클러스터의 전반적인 복원력을 향상시킵니다.
Search Backpressure는 OpenSearch에서 사용할 수 있으며, 컨트리뷰터를 찾고 있습니다. 시작하려면 RFC를 참조할 수 있습니다.