AWS 기술 블로그
AWS DevOps Agent와 Custom MCP 서버를 활용한 HYBE의 인시던트 자동 조사 체계 구축 사례
1. HYBE 인프라운영팀 소개
하이브(HYBE)는 글로벌 엔터테인먼트 기업으로, 사내 시스템부터 B2C 서비스까지 다양한 워크로드를 AWS 위에서 운영하고 있습니다. 인프라운영팀은 다중 AWS 계정과 EKS 클러스터에 걸쳐 다수의 서비스를 효율적인 인력 구성으로 운영합니다. 모니터링은 Datadog, 소스 코드는 GitLab, 이슈 관리는 Jira를 사용하고 있습니다.
2. 개요
새벽 3시, Slack 알림과 함께 온콜 담당자의 전화가 울립니다. Datadog Error Tracking에서 portal-v3-gateway의 NullPointerException이 급증하고 있습니다. 운영자는 Datadog에서 에러 로그를 검색하고, APM 트레이스를 추적하고, GitLab에서 최근 배포된 MR을 찾고, 변경된 코드를 확인하고, 스택 트레이스와 소스 코드를 대조하여 원인을 추정한 뒤, 이 모든 내용을 정리하여 Jira 이슈를 작성합니다. 이 과정에 평균 30분에서 1시간이 소요됩니다.
이 글에서는 AWS DevOps Agent를 중심으로 활용하고, 4개의 Custom Model Context Protocol (MCP) 서버를 조합하여 에러 감지 → 자율 조사 → Jira 자동 생성, 그리고 문제 해결 후 MR 생성 → 자동 리뷰 결과 댓글 등록까지 전체 DevOps 워크플로우를 자동화한 사례를 소개합니다.
3. 인시던트 대응의 현실 — 에러 하나 조사하는 데 왜 30분이 걸리는가
도구 분산과 컨텍스트 전환
인시던트 발생 시 운영자가 해야 할 일:
- Datadog에서 에러 로그를 검색하고, APM 트레이스를 추적합니다.
- 이 서비스가 어떤 AWS 계정의 어떤 EKS 클러스터에서 돌아가는지 확인합니다.
- GitLab에서 최근 배포된 MR을 찾고, 변경된 코드를 확인합니다.
- 스택 트레이스와 소스 코드를 대조하여 원인을 추정합니다.
- 이 모든 내용을 정리하여 Jira 이슈를 작성합니다.
인프라운영팀의 인시던트 대응 과정에서 가장 많은 시간이 소비되는 곳은 의외로 “이 서비스가 어디에 있는지 파악하는 것“이었습니다. Datadog에서는 portal-v3-gateway-prod라는 이름으로 보이고, GitLab에서는 company/org/application/portal-v3/gateway라는 경로에 있고, AWS 태그에는 portal이라고 적혀 있습니다. 같은 서비스인데 시스템마다 이름이 다릅니다.
| 시스템 | portal-v3를 부르는 이름 |
|---|---|
| Datadog APM | portal-v3-gateway-prod, portal-main-db |
| Datadog 호스트 | (없음 — EKS 기반이라 호스트 태그 없음) |
| GitLab | company/org/application/portal-v3/gateway |
| AWS Tag | portal |
| EKS Namespace | app-portal-v3 |
| Jira | DEV-PROJECT |
| 사내용어 | 사내포털, 신규 포털 |
운영자는 이 매핑을 머릿속에 들고 다닙니다. 새로운 팀원이 오면 이 지식을 전달하는 데만 몇 주가 걸립니다. AI에게 “portal-v3 에러 조사해줘”라고 말해도, AI는 이 서비스의 GitLab 리포가 어디인지, 어떤 계정의 어떤 클러스터에서 돌아가는지 알 수 없습니다.
프로젝트 목표
인프라운영팀이 해결하고자 한 과제는 명확했습니다:
- 흩어진 도구의 정보를 하나로 연결하고
- 숙련된 운영자의 분석 패턴을 AI가 재현할 수 있어야 하며
- 사람이 자리를 비운 시간에도 즉각적인 초기 대응이 가능해야 한다
단순히 “AI 도구를 도입하자”가 아니라, 에러 감지 → 자율 조사 → Jira 자동 생성과 문제 해결 후 MR 생성 → 자동 리뷰 결과 댓글 등록까지 전체 파이프라인을 자동화하는 것이 목표였습니다.
4. 솔루션 설계 — AWS DevOps Agent + Custom MCP 하이브리드
왜 AWS DevOps Agent를 선택했는가
AWS DevOps Agent는 2025년 12월 re:Invent에서 Preview로 발표되고, 2026년 3월말에 GA된 서비스입니다. 인시던트가 발생하면 자율적으로 조사를 수행하고, 과거 패턴을 분석하여 예방적 개선을 추천하는 DevOps 특화 AI 에이전트입니다.
인프라운영팀이 AWS DevOps Agent를 선택한 이유는 다음과 같습니다:
- Topology 자동 빌드: AWS 리소스와 그 관계를 자동으로 매핑하여 애플리케이션 아키텍처를 이해
- Investigation 자율 분석: 알림이 들어오면 즉시 텔레메트리코드·배포 데이터를 상관 분석하여 근본 원인을 추적
- Proactive Prevention: 과거 인시던트 패턴을 분석하여 관찰성, 인프라, 배포 파이프라인 개선을 추천
- Custom MCP 지원: MCP Streamable HTTP를 통해 자체 도구를 연결하여 기능을 확장
특히 Custom MCP 지원이 결정적이었습니다. DevOps Agent의 핵심 기능을 그대로 활용하면서, 인프라운영팀 환경에 맞는 도구(Datadog, GitLab, 사내 서비스 카탈로그 등)를 MCP 서버로 연결할 수 있었기 때문입니다. Amazon Bedrock Agents나 Strands Agents SDK로 전체를 자체 구축하는 방안도 검토했지만, Topology, Investigation, Prevention 같은 DevOps 특화 기능을 직접 구현하려면 수개월의 개발 공수가 필요했습니다.
결론은 AWS DevOps Agent를 조사 엔진으로 활용하면서, 부족한 부분만 Custom MCP 서버로 확장하는 하이브리드 전략이었습니다. 인프라운영팀은 4개의 Custom MCP 서버를 Python FastAPI로 자체 구축하여 EKS에 배포했습니다.
구축 타임라인
3월부터 PoC를 진행하여 약 6주 만에 전체 파이프라인을 운영 환경에 투입했습니다. 1인이 설계·개발·운영까지 수행했다는 점이 이 하이브리드 전략의 핵심 증거입니다.
| 시점 | 마일스톤 |
|---|---|
| 2025.12 | re:Invent Preview 발표 |
| 2026.03 1주 ~ 2주 | DevOps Agent PoC 수행, Agent Space 생성, Service Catalog·GitLab·Athena MCP 개발 |
| 2026.03 3주 ~ 4주 | Datadog→Investigation→Jira 파이프라인 운영 투입 |
| 2026.03.31 | DevOps Agent GA |
| GA 직후 ~ 2주 | Custom Datadog MCP 전환, GitLab MR 자동 리뷰, WAF 로그 조회 완료 |
이 속도가 가능했던 이유는 명확합니다. Agent의 핵심 조사 로직(Topology, Investigation orchestration)은 managed service인 AWS DevOps Agent가 담당하고, 우리는 도구(MCP 서버)와 파이프라인(Lambda)만 만들면 됐기 때문입니다.
전체 아키텍처
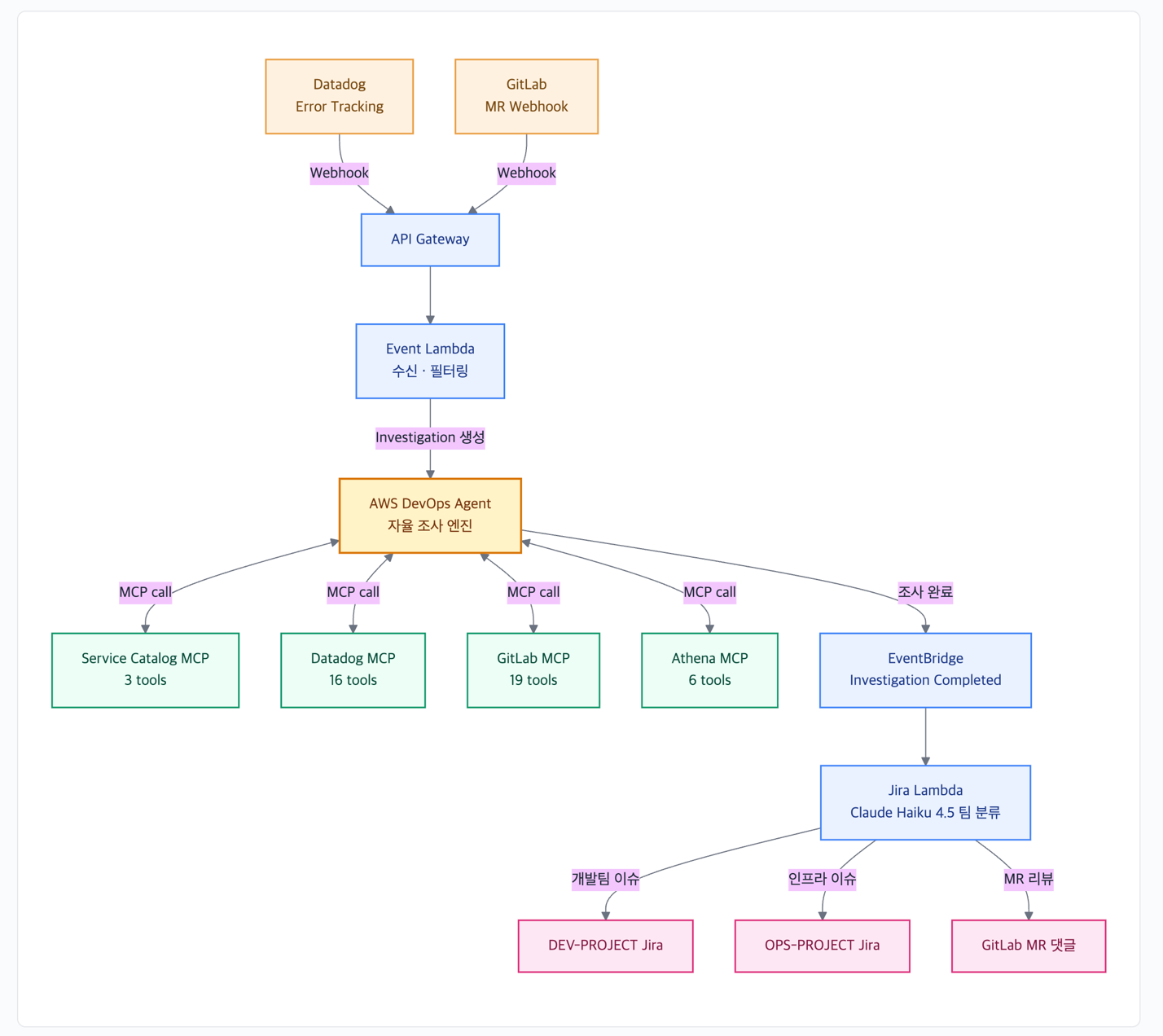
그림1. HYBE DevOps Agent 전체 아키텍처
시스템은 크게 세 가지 영역으로 구성됩니다.
1. 이벤트 수신 레이어
Datadog Error Tracking, GitLab MR Webhook — 두 가지 이벤트 소스를 Amazon API Gateway로 수신합니다. AWS Lambda 함수가 이벤트를 파싱하고, HMAC-SHA256 서명을 생성하여 DevOps Agent Webhook을 호출하면 Investigation이 자동 생성됩니다. Amazon DynamoDB로 7일간 중복을 방지하여, 같은 에러에 대해 Investigation이 반복 생성되지 않도록 합니다.
2. AI 에이전트 레이어
AWS DevOps Agent가 자율 조사 엔진으로 동작합니다. Investigation이 생성되면 Agent는 MCP 프로토콜로 도구를 호출하며 자율적으로 조사를 수행합니다.
| MCP 서버 | 역할 |
|---|---|
| Service Catalog MCP | 서비스 메타데이터 매핑 (이름 불일치 해결) |
| Datadog MCP | 로그·메트릭·APM 트레이스·에러 트래킹 조회 |
| GitLab MCP | 코드·커밋·MR·파이프라인 분석 |
| Athena MCP | S3 로그 아카이브 검색 (3일 이후) |
3. 후처리 레이어
Investigation이 완료되면 Amazon EventBridge가 Investigation Completed 이벤트를 발행합니다. Jira Integration Lambda가 이를 수신하여, Amazon Bedrock의 Claude Haiku 4.5로 담당팀을 자동 분류한 뒤 Jira에 이슈를 생성합니다.
5.구현 상세
Service Catalog MCP — 이름 불일치 문제를 풀다
앞서 설명한 “이름이 다른 세계” 문제를 해결하기 위해 가장 먼저 만든 것이 Service Catalog MCP 서버입니다.
핵심 아이디어는 Datadog, GitLab, AWS에서 수집한 raw 데이터를 Amazon Bedrock의 Claude 모델로 정제하여, 서비스마다 “이 서비스는 Datadog에서는 이 이름, GitLab에서는 이 경로, AWS에서는 이 계정”이라는 매핑을 자동으로 생성하는 것입니다.
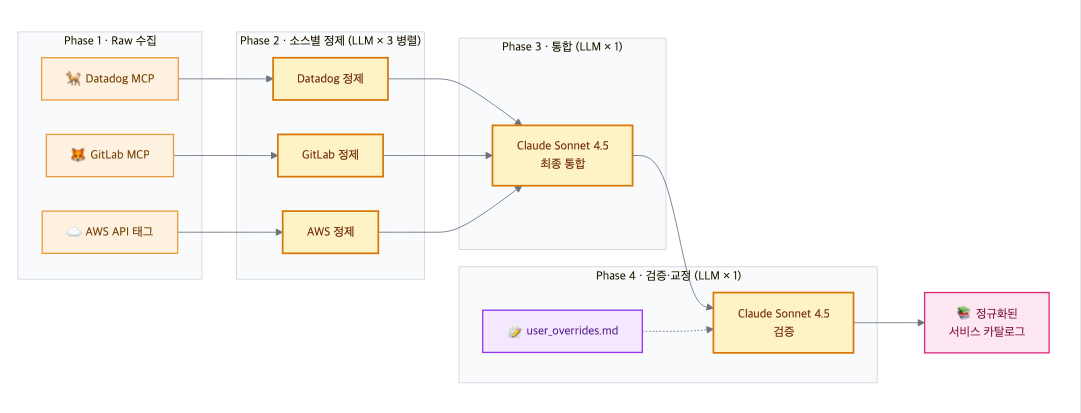
그림 2. Service Catalog 데이터 파이프라인
카탈로그 생성은 4단계 LLM 파이프라인으로 이루어집니다:
- Phase 1 — Raw 데이터 수집: Datadog(APM 서비스, 호스트, 로그 서비스), GitLab(프로젝트), AWS(Cross-Account appName 태그 리소스)에서 병렬 수집
- Phase 2 — 소스별 정제(LLM 3회 병렬): 각 소스의 raw 데이터를 LLM으로 정제하여 서비스 목록으로 변환.
- Phase 3 — 최종 통합 (LLM 1회): Phase 2의 정제 결과 3개 + user_overrides.md + 계정 정보를 LLM에 넣어 하나의 카탈로그로 병합
- Phase 4 — 검증/교정 (LLM 1회): Phase 3 결과를 다시md와 대조하여 LLM이 검증/교정. Phase 3에서 입력이 커서 user_overrides.md에서 정의한 내용을 놓치는 경우가 있기 때문에, 별도 검증 단계로 한 번 더 잡아줍니다.
Phase 4가 필요했던 이유가 있습니다. Phase 3까지만 돌리면 LLM이 비슷한 이름의 서비스를 잘못 합치는 경우가 발생했습니다. 예를 들어 account-mgmt(계정관리)와 asset-approval(자산승인)은 Datadog 호스트 appname이 유사하고 같은 AWS 계정에 있지만 완전히 다른 서비스입니다. user_overrides.md에 “이 둘은 별도 서비스”라고 명시하고, Phase 4에서 이를 검증하도록 했습니다. 이 파일은 운영자가 자연어로 보정 메모를 작성하면 LLM이 참고하는 구조로, 코드 변경 없이 카탈로그 품질을 개선할 수 있습니다.
Service Catalog는 CronJob으로 매일 자동 갱신됩니다. 갱신 시 서비스 수가 기존 대비 30% 이상 감소하면 수집 실패로 판단하여 저장을 거부하고, 기존 카탈로그를 유지합니다.
Skill + Catalog 조합으로 Agent의 조사를 안내하다
Service Catalog MCP는 데이터를 제공하지만, Agent가 이 데이터를 언제, 어떻게 활용할지는 DevOps Agent Skills로 안내합니다. Skills는 Agent Space에 등록하는 자연어 지침으로, Agent가 관련 작업을 수행할 때 자동으로 로드되어 조사 방법을 가이드합니다.
인프라운영팀은 3개의 Custom Skill을 등록하여 사용하고 있습니다.
| Skill | 역할 |
|---|---|
| service-catalog-first | 어떤 도구를 호출하기 전에 반드시 Service Catalog MCP를 먼저 조회하라는 규칙 |
| log-search-routing-guide | Datadog(최근 3일)과 Athena(과거/인프라 로그) 중 어디서 로그를 검색할지 판단하는 가이드 |
| gitlab-code-investigation | 스택 트레이스에서 코드를 추적하는 방법 가이드 |
예를 들어 service-catalog-first Skill의 SKILL.md에는 이런 내용이 자연어로 적혀 있습니다:
Agent가 이 Skill을 읽고, Investigation 시작 시 자율적으로 Service Catalog MCP의 search_service 도구를 호출합니다. 코드로 호출 순서를 강제하는 것이 아니라, Skill(자연어 지침) + Catalog(서비스 메타데이터)를 조합해서 Agent가 스스로 도구를 선택하는 구조입니다.
실제 질의/응답 예시
Agent가 search_service(query=”portal-v3″)를 호출하면 다음과 같은 응답을 받습니다:
이 응답을 받은 Agent는 Skill의 매핑 가이드에 따라 자율적으로 판단합니다:
- Datadog 로그 검색 시 →
service: portal-v3-prod사용 - GitLab 코드 조회 시 →
company/org/application/portal-v3/gateway경로 사용 - EKS Pod 확인 시 →
internal-eks-prod클러스터의app-portal-v3네임스페이스 조회 - 장애 전파 의심 시 → 의존성(
account-mgmt,legal-mgmt)도 함께 조사
Service Catalog가 없었다면 Agent는 “portal-v3의 GitLab 리포가 뭐지?”부터 추론해야 합니다. 컨텍스트 토큰이 낭비되고, 잘못된 리포를 찾을 수도 있습니다. Skill로 “먼저 카탈로그를 조회하라”고 안내하고, 카탈로그 한 번 조회로 정확한 컨텍스트를 확보하는 것이 조사 속도와 정확도 모두에 결정적이었습니다.
3개 Skill의 관계
3개 Skill은 독립적이 아니라 서로 의존 관계를 가집니다:
Agent는 Investigation 시작 시 이 3개 Skill을 모두 읽고, 상황에 따라 자율적으로 조합하여 사용합니다. 코드로 호출 순서를 강제하는 것이 아니라, 자연어 지침 + 서비스 메타데이터를 조합해서 Agent가 스스로 도구를 선택하는 구조입니다.
Datadog MCP — 조사 시나리오에 맞는 도구 커스터마이징
AWS DevOps Agent는 Datadog MCP Integration을 기본 제공합니다. 인프라운영팀은 자체적으로 API 접근 권한을 관리하고, 조사 시나리오에 맞게 도구를 커스터마이징하기 위해 Custom Datadog MCP 서버를 구축했습니다. Python FastAPI로 Datadog REST API를 래핑하여 필요한 도구만 선별적으로 제공하며, 도구의 응답 형식이나 파라미터도 Investigation에 최적화할 수 있습니다.
참고: Agent Space의 Custom MCP에는 도구 수 제한이 있습니다. Datadog은 Custom MCP 또는 SaaS MCP Integration 중 선택적으로 사용할 수 있으므로, SaaS MCP의 기능이 개선되면 전환하여 Custom 도구 수 쿼터를 다른 MCP 서버에 활용할 수 있습니다.
GitLab MCP — 코드까지 추적하는 조사
AWS DevOps Agent는 GitLab 네이티브 연동을 기본 제공하여 배포 이벤트 감지와 코드 변경 상관 분석이 가능합니다. 그러나 인프라운영팀이 필요로 한 것은 스택 트레이스에서 소스 코드를 직접 읽고, 에러 메시지로 코드를 검색하고, 심볼 정의를 추적하는 수준의 심층 코드 조사였습니다. 기본 연동만으로는 이러한 세밀한 코드 레벨 분석이 어려워 19개 도구를 갖춘 Custom GitLab MCP 서버를 자체 구축했습니다.
gitlab-code-investigation Skill이 Agent에게 언제, 어떤 도구로 코드를 조사해야 하는지를 안내합니다. 이 Skill의 핵심은 Agent가 사용자 요청을 기다리지 않고 선제적으로 코드를 확인하도록 지시하는 것입니다:
- 스택 트레이스/예외 발생 → 해당 클래스, 메서드, 라인 번호의 코드를 읽어라
- 에러 메시지 → 에러 문자열을 코드에서 검색하여 발생 위치를 찾아라
- 배포 관련 이슈 → 최근 커밋과 MR 변경사항을 확인하라
| 상황 | 사용할 도구 | 예시 |
|---|---|---|
| 파일명을 알 때 | gitlab_search_files | filename=”PaymentService.java” |
| 클래스/메서드 정의 찾기 | gitlab_find_symbol_light | symbol=”PaymentService.validate” |
| 에러 메시지로 검색 | gitlab_search_code | query=”error.bad.request” |
| 최근 배포 확인 | gitlab_get_commits + gitlab_get_mr_changes | since=”2026-04-07T00:00:00Z” |
| 설정 파일 확인 | gitlab_get_file | file_path=”src/main/resources/application.yml” |
이 흐름을 통해 Agent는 “3일 전 MR !247에서 PaymentService.java의 null 체크가 빠졌고, 이것이 NullPointerException의 원인”이라는 수준의 분석을 자율적으로 수행합니다.
Athena MCP — 3일 이전 로그도 검색
인덱스 비용을 고려하여 Datadog 로그 인덱스 보존 기간을 3일로 설정하고, 이후 S3로 아카이브하고 있습니다. “이 에러가 언제부터 발생했는가?”를 확인하려면 아카이브된 로그를 검색해야 합니다.
Datadog 로그 아카이브를 S3에 저장하고, Athena Partition Projection으로 서비스명/날짜/시간 기준 자동 파티셔닝을 설정했습니다. 추가로 Secondary 계정의 VPC Flow Logs, ELB Access Logs, 그리고 WAF 로그도 Athena 테이블로 구성하여, 네트워크·보안 레벨 분석까지 가능하게 했습니다. log-search-routing-guide Skill이 Agent에게 이 판단 기준을 제공합니다.
| 로그 소스 | 용도 | 계정 |
|---|---|---|
| Datadog Archive | 3일 이후 앱 로그 | Primary |
| VPC Flow Logs | 네트워크 트래픽 분석 | Secondary (각 계정) |
| ELB Access Logs | ALB 접근 로그 | Secondary (각 계정) |
| WAF Logs | 보안 이벤트 (BLOCK/ALLOW) | Primary (전 계정 통합) |
WAF 로그는 전 계정의 Web ACL 로그가 단일 S3 버킷에 집중되는 구조입니다. web_acl_name 파티션 키로 서비스별 필터링이 가능하며, Agent가 “이 서비스에 비정상 트래픽이 있었는가?”를 보안 관점에서도 조사할 수 있게 됩니다.
Skill에는 각 Athena 테이블의 파티션 키와 예시 쿼리도 포함되어 있어 Agent가 올바른 SQL을 생성할 수 있습니다. Athena MCP 서버는 IRSA를 통해 Cross-Account Assume Role로 Secondary 계정의 로그에도 접근합니다. 쿼리는 SELECT만 허용하여 안전성을 확보했습니다.
에러 감지 → 조사 → Jira 자동 생성 파이프라인
에러 감지부터 Jira 이슈 생성까지 사람의 개입 없이 자동으로 이루어지는 파이프라인을 구축했습니다.
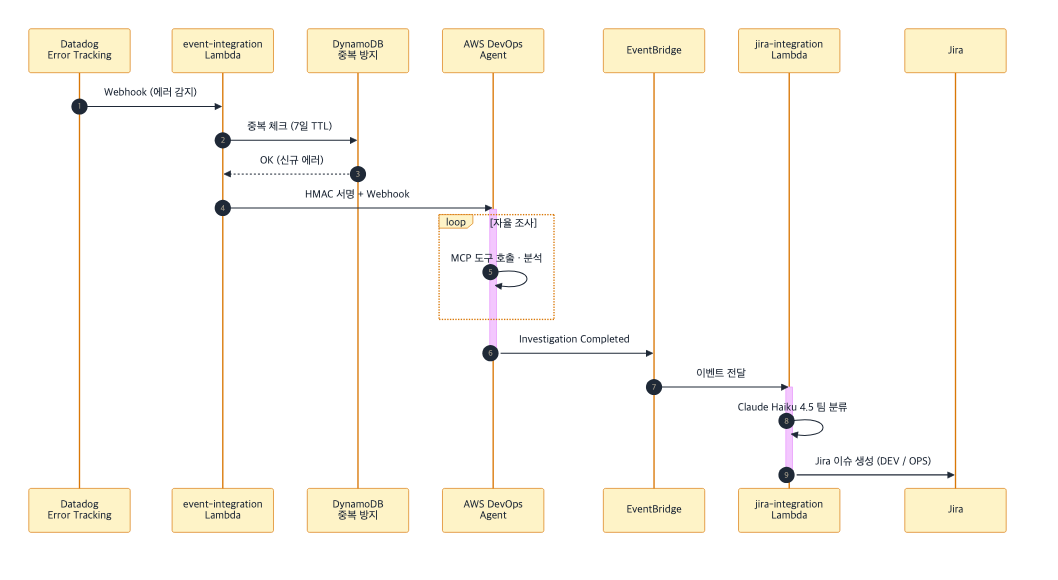
그림 3. Datadog 에러 감지 → 자율조사 → Jira 자동 생성 Sequence Diagram
Event Integration Lambda
Datadog Error Tracking, GitLab MR Webhook — 두 가지 이벤트 소스를 API Gateway로 수신합니다. Lambda가 DevOps Agent Webhook을 호출하면 Investigation이 자동 생성됩니다.
Datadog Error Tracking의 경우, Lambda에서 에러 타입에 따라 Priority를 자동 매핑합니다:
- Connection Refused, SQL Injection → CRITICAL
- SQLException, DataIntegrityViolation, Regression → HIGH
- 기본 → MEDIUM
DynamoDB로 7일간 중복을 방지하여, 같은 에러에 대해 Investigation이 반복 생성되지 않도록 합니다.
Jira Integration Lambda
Investigation이 완료되면 EventBridge가 Investigation Completed 이벤트를 발행합니다. Jira Integration Lambda가 이를 수신하여:
ListJournalRecordsAPI로 Investigation summary 마크다운을 조회합니다- Claude Haiku 4.5로 담당팀을 자동 분류합니다
- 팀별 Jira 프로젝트에 이슈를 생성합니다
담당팀 분류에 LLM을 사용한 이유가 있습니다. 처음에는 키워드 규칙 기반으로 구현하려 했습니다. “NullPointerException이면 개발팀, Pod CrashLoopBackOff면 인프라팀.” 그러나 현실의 인시던트는 이렇게 깔끔하지 않습니다. 앱 코드의 데드락이 Pod 가용성 저하로 이어지는 경우, 양쪽 팀 모두에게 이슈가 필요합니다.
Investigation summary는 이미 정제된 분석 결과이므로 입력 토큰이 소량(~4K)이고, Haiku 4.5의 지연은 1~2초, 건당 비용은 $0.001 미만입니다. 키워드 규칙 대비 유지보수 부담이 없고, “both”(양팀 모두) 판단도 자연스럽게 처리됩니다.
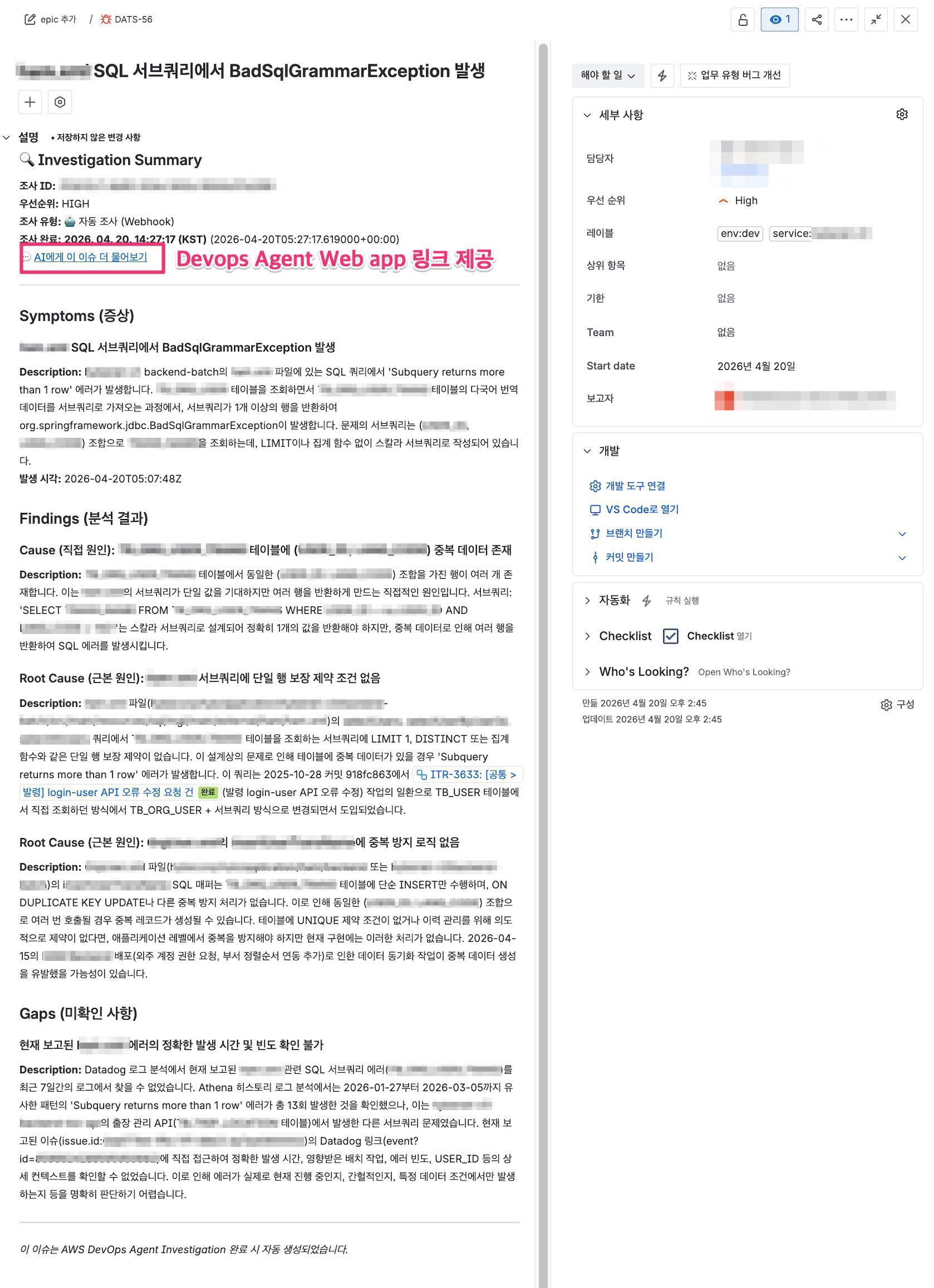
그림 4. Jira 이슈 등록 예시
Jira 이슈 본문에는 DevOps Agent Web app으로 연결되는 링크가 포함됩니다. 개발자나 운영자가 추가 질문이 있을 때 이 링크를 통해 해당 Investigation에 접근하여, Chat 기능으로 “이 에러가 다른 서비스에도 영향을 주었는가?”, “이전에 비슷한 패턴이 있었는가?” 같은 후속 질의를 자연어로 할 수 있습니다.
MR 리뷰 자동화 — 배포 전 자동 코드 리뷰
hotfix/feature 등의 브랜치에서 main으로 MR을 생성하면, GitLab Webhook → Event Lambda → DevOps Agent Investigation이 자동으로 시작됩니다. SDLC 관점에서 코드 리뷰는 main 병합 전에 수행하는 것이 타당하며, 개발팀 요청으로 이 시점에 리뷰가 동작하도록 구성했습니다. Agent는 GitLab MCP로 변경 코드를 분석하고, Service Catalog MCP로 영향 범위를 파악하고, Datadog MCP로 해당 서비스의 현재 상태를 확인합니다.
Investigation 완료 후의 MR 댓글 게시는 별도의 GitLab Review Integration Lambda가 담당합니다. 이 Lambda는 GitLab API에 접근하기 위해 VPC 내에 배치되어 있으며(NAT Gateway 경유), Cross-region EventBridge를 통해 이벤트를 수신합니다:
Investigation 완료 (ap-northeast-1, Tokyo)
→ EventBridge Rule (GITLAB-MR-* 패턴 감지)
→ Cross-region 전달 (ap-northeast-2, Seoul)
→ GitLab Review Lambda (VPC)
→ GitLab API로 MR 댓글 게시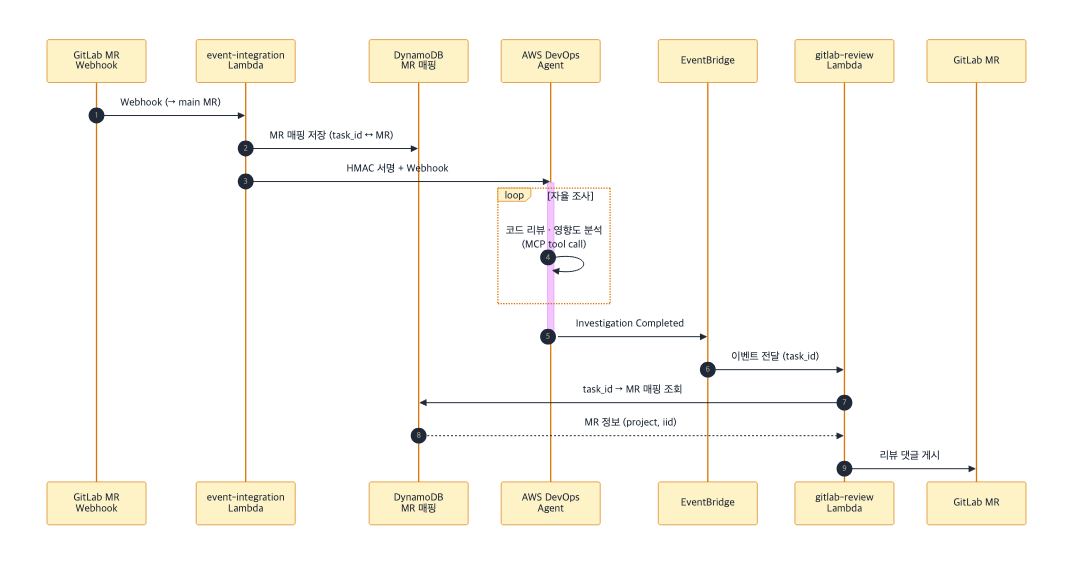
그림 5. GitLab MR → 자동 리뷰 → MR 댓글 등록 Sequence Diagram
리뷰 결과 추출 로직도 개선했습니다. Agent는 root cause가 존재할 때에만 investigation summary를 남기는데, 운영 환경에서는 summary가 생성되지 않는 케이스도 존재합니다. 이 경우 journal records 중 가장 긴 assistant message를 리뷰 결과로 선택합니다 — 최종 분석 결과가 항상 가장 길고, 중간 메시지(도구 호출 안내 등)는 짧다는 관찰에 기반합니다.
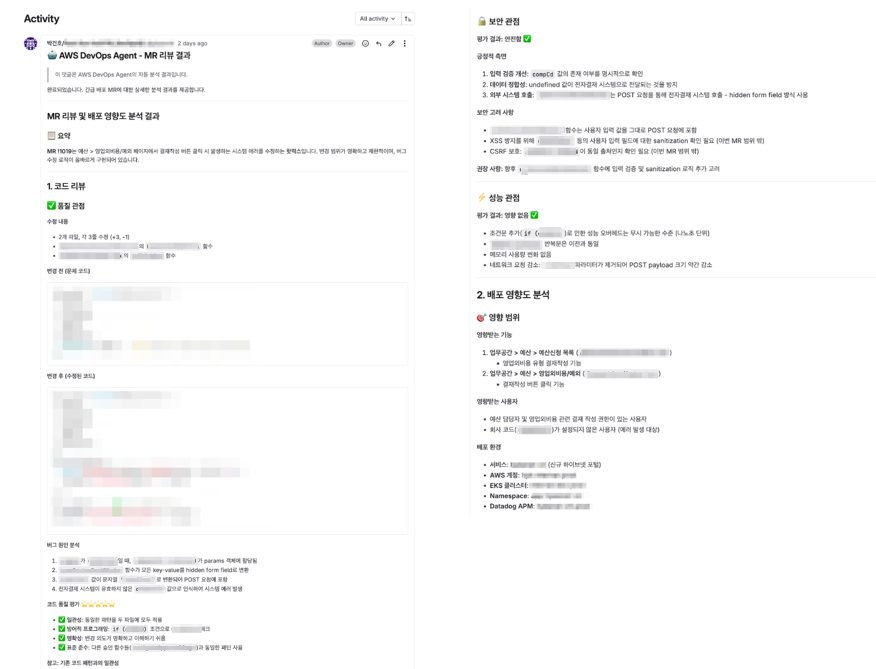
그림 6. MR review 예시
6. 다중 계정 환경에서의 운영
다중 계정 환경을 하나의 Agent로
인프라운영팀의 환경은 단일 계정이 아닙니다. 사내시스템, B2C 서비스, 콘텐츠 관리 등 서비스 도메인별로 AWS 계정이 분리되어 있고, dev/prod 환경을 포함한 다중 계정 구성으로 운영합니다. AWS DevOps Agent의 Secondary sources 기능을 활용하여, 하나의 Agent Space에서 모든 계정의 EKS 클러스터에 접근할 수 있도록 구성했습니다.
각 Secondary 계정에 DevOpsAgentCrossAccountRole을 생성하고, aidevops.amazonaws.com 서비스가 직접 Assume하는 trust policy를 설정합니다. Athena MCP 서버도 IRSA + Cross-Account Assume Role로 Secondary 계정의 VPC Flow Logs, ELB Access Logs에 접근합니다. 모든 Cross-Account Role과 EKS Access Entry는 Terraform으로 관리합니다.
Infrastructure as Code
전체 인프라를 3개의 Terraform 프로젝트로 관리합니다:
| 프로젝트 | 관리대상 |
|---|---|
| 메인 인프라 | Agent Space, IAM Role, Cross-Account Role, EKS Access Entry, Athena 테이블, MCP Association |
| Event Integration | Lambda, API Gateway, DynamoDB (이벤트 중복 방지) |
| Jira Integration | Lambda, EventBridge Rule, DynamoDB (Jira 중복 방지) |
| GitLab Review Integration | Lambda (VPC), Cross-region EventBridge, Secrets Manager |
| Synthetic Monitoring | Lambda, EventBridge Scheduler, DynamoDB (상태 관리) |
Agent Space 자체도 awscc_devopsagent_agent_space 리소스로 Terraform에서 생성합니다. MCP 서버의 Association과 도구 선택도 awscc_devopsagent_association으로 코드화하여, MCP 서버 재등록이 필요한 상황에서도 terraform apply 한 번으로 복구할 수 있습니다.
7. 시행착오와 교훈
MCP 에러 응답 설계 — Agent의 행동을 도구 응답으로 유도하다
Custom MCP 서버를 운영하면서 가장 중요한 교훈 중 하나입니다.
MCP 프로토콜에서 도구 응답의 isError: true는 “도구 자체가 실패했다”는 의미입니다. 처음에는 “검색 결과 없음”도 에러로 응답했는데, Agent가 이를 “이 도구는 작동하지 않는다”로 해석하여 같은 도구를 파라미터를 바꿔 재시도하지 않고 포기하는 문제가 발생했습니다.
해결: 모든 응답을 isError: false로 보내되, 응답 본문에 상황별 가이드 메시지를 포함합니다:
"결과 없음. 시간 범위를 넓히거나 다른 service_name을 시도하세요."
이렇게 하면 Agent는 도구를 “성공적으로 사용했지만 원하는 결과가 없었다”고 해석하여, 파라미터를 조정해 재시도합니다. 코드로 Agent에게 강제하는 것이 아니라, 도구 응답 설계로 Agent의 행동을 자연스럽게 유도하는 패턴입니다.
같은 원리로, 도구의 description에 한 줄 추가하는 것만으로도 Agent의 행동이 극적으로 바뀝니다. 예를 들어 Datadog logs 도구의 description에 “보존 기간 3일, 이전 로그는 Athena MCP를 사용하세요”를 추가하기 전에는 Agent가 6~7회 다른 도구를 시도하며 로그를 찾아갔지만, 추가 후에는 1회 만에 올바른 도구로 전환하게 되었습니다. 실제로 Skill보다 도구 description이 더 즉각적인 효과를 보이는 경우가 많았는데, Agent가 도구를 선택할 때 반드시 이름과 description을 확인하기 때문입니다.
Skill — 코드 0줄로 Agent 행동을 바꾸다
AWS DevOps Agent의 Skill은 마크다운 파일 하나입니다. Agent Space에 등록하면, Agent가 관련 작업을 수행할 때 자동으로 로드되어 조사 방법을 안내합니다. 인프라운영팀은 3개의 Custom Skill을 등록하여 사용하고 있습니다.
실제로 log-search-routing-guide에 WAF 로그 조회 절차를 6줄 추가한 것만으로, Agent가 즉시 WAF 로그를 올바르게 라우팅하기 시작했습니다. 코드 변경도, 서버 재배포도 없이 자연어 지침 하나로 Agent의 능력이 확장됩니다. 이것이 rule-based 자동화와 AI Agent의 근본적 차이입니다.
LLM이 서비스를 잘못 합치는 문제
Service Catalog 생성 초기, LLM이 account-mgmt(계정관리)와 asset-approval(자산승인)을 하나의 서비스로 합치는 문제가 반복되었습니다. Datadog 호스트 appname이 유사하고, 같은 AWS 계정에 있기 때문입니다.
user_overrides.md라는 자유 형식 텍스트 파일을 도입하여 “이 둘은 별도 서비스”라고 명시하고, Phase 4 검증 단계에서 LLM이 이를 대조하도록 했습니다. 이 파일은 운영자가 자연어로 보정 메모를 작성하면 LLM이 참고하는 구조로, 코드 변경 없이 카탈로그 품질을 개선할 수 있습니다.
EKS 클러스터의 자연어 별칭
Agent가 조사 결과를 설명할 때 internal-eks-prod라는 기술적 이름 대신 “사내시스템 클러스터”라고 부르면 개발팀이 더 쉽게 이해합니다. 카탈로그의 name_aliases에 eks_cluster_aliases 필드를 추가하여, 실제 클러스터명과 자연어 별칭을 모두 검색 가능하게 했습니다.
Jira 팀 분류 — 키워드 규칙 vs LLM
처음에는 키워드 규칙으로 팀을 분류하려 했습니다. 그러나 “앱 코드 데드락 → Pod 가용성 저하”처럼 양팀에 걸치는 인시던트를 규칙으로 처리하기 어려웠습니다. Claude Haiku 4.5를 도입한 후, 건당 $0.001 미만의 비용으로 정확한 분류가 가능해졌고, 새로운 패턴이 나타나도 규칙을 추가할 필요가 없어졌습니다.
중복 방지의 두 계층
같은 에러에 대해 Investigation이 반복 생성되거나, 같은 Investigation에 대해 Jira 이슈가 중복 생성되는 문제를 방지하기 위해 DynamoDB 기반 중복 방지를 두 계층으로 구성했습니다:
| 계층 | TTL | Key | 용도 |
|---|---|---|---|
| Event Integration | 7일 | incident_id | 같은 Datadog 알림에 대한 Investigation 중복 방지 |
| Jira Integration | 90일 | task_id | 같은 Investigation에 대한 Jira 중복 방지 |
에러가 Recovered 후 다시 발생(Regression)하면 새 Investigation과 새 Jira 이슈가 생성됩니다 — 이것은 별개의 발생이니까요.
8. 도입 성과
Before → After
| 항목 | Before | After |
|---|---|---|
| 에러 감지 → 원인 파악 | 운영자가 수동으로 30분~1시간 | Agent가 자율 조사, 운영자 개입 없이 완료 |
| Jira 이슈 작성 | 운영자가 수동 작성 (15~30분) | 자동 생성 (원인 분석 + 해결방안 포함) |
| MR 리뷰 | 사람이 직접 확인 | Agent가 1차 리뷰 자동 수행, 사람은 최종 승인 |
| 서비스 컨텍스트 파악 | 운영자 머릿속 지식에 의존 | Service Catalog 1회 조회로 즉시 확보 |
| 야간/주말 대응 | 초기 대응 지연, 장애 확산 위험 | Agent가 즉시 조사 시작, 출근 시 Jira에 분석 결과 준비 |
운영자의 하루가 바뀌다
월요일 아침 출근 시나리오:
주말간 발생한 에러에 대해 이미 Investigation이 완료되어 있고, Jira에 분석 결과가 정리되어 있습니다. 운영자는 Jira 목록을 훑으며 “이건 개발팀에 넘기자”, “이건 이미 복구됐으니 close” 판단만 수행합니다. 궁금한 게 있으면 DevOps Agent 웹앱 링크를 클릭하여 “이 에러가 다른 서비스에도 영향 줬어?” 같은 후속 질의를 자연어로 합니다.
수요일 정기 배포 시나리오:
개발팀이 main으로 MR을 머지하면 자동으로 MR 리뷰 댓글이 등록됩니다. 배포 후 에러가 급증하면 즉시 Investigation이 생성되고, “3일 전 MR !247에서 변경된 null 체크 제거가 원인”이라는 수준의 분석이 수 분 내에 Jira에 등록됩니다.
개발팀에게 달라진 점
개발팀 입장에서의 변화를 요약하면 다음과 같습니다:
- Before: Datadog 알람 확인 → 로그 검색 → 최근 배포 확인 → 코드 확인 → 원인 추정 → Jira 이슈 작성
- After: 출근하면 Jira에 이슈가 이미 등록되어 있음 (원인 분석 포함). 궁금하면 DevOps Agent 웹앱 링크를 클릭하여 Chat으로 추가 질의. 문제 해결 후 MR을 생성하면, 자동으로 리뷰 결과가 댓글로 등록됨.
자동 생성된 Jira 이슈에는 증상, 직접 원인, 근본 원인, 수정 방안, 근거가 구조화되어 포함됩니다. 개발자는 이슈를 읽고 바로 수정 작업에 착수할 수 있습니다. 추가 질문이 있을 때는 이슈 본문에 포함된 DevOps Agent 웹앱 링크를 통해 해당 Investigation에 접근하여, “이 에러가 다른 서비스에도 영향을 주었는가?”, “이전에 비슷한 패턴이 있었는가?” 같은 후속 질의를 자연어로 할 수 있습니다.
비용 효율성
| 항목 | 비용 |
|---|---|
| DevOps Agent | AWS Enterprise Support 크레딧을 통해 추가 비용 부담 없이 운영 |
| Custom MCP 서버 4개 (EKS Pod) | 기존 클러스터 활용, 추가 노드 불필요 (~$0) |
| Jira/Event Integration Lambda | 수 달러 수준의 운영 비용 (Bedrock Haiku 분류 포함) |
| Athena 쿼리 | 수 달러 수준의 운영 비용 (파티션 최적화) |
이와 같은 자율 조사 시스템을 자체 구축한다면 LLM 호출 비용, 에이전트 오케스트레이션 인프라, 지속적인 유지보수 공수가 필요합니다. AWS DevOps Agent는 Agent가 실제로 작업하는 시간에 대해서만 초 단위로 과금되며($0.0083/agent-second), 대기 중에는 비용이 발생하지 않습니다. 특히 AWS Enterprise Support 고객은 월간 AWS Support 비용의 75%에 해당하는 DevOps Agent 크레딧을 매월 제공받습니다. 인프라운영팀은 이 크레딧 덕분에 현재 DevOps Agent를 추가 비용 거의 없이 운영하고 있습니다. 자체 구축 대비 개발 공수와 운영 비용 모두를 절감한 셈입니다.
아티스트 이벤트 대응
엔터테인먼트 기업 특성상, 앨범 발매·콘서트 티켓 오픈·라이브 방송 등 아티스트 이벤트에 따라 트래픽이 급증하는 상황이 빈번합니다. 이런 순간에 에러가 발생하면 수 분의 대응 지연이 사용자 경험에 직접적인 영향을 미칩니다. AWS DevOps Agent가 에러 감지 즉시 자율 조사를 시작하고, 원인 분석과 함께 Jira 이슈를 자동 생성해주기 때문에 운영자는 원인 파악에 시간을 쓰는 대신 해결에 바로 집중할 수 있게 되었습니다.
9. 향후 계획
- MCP 도구 확장: Datadog SLO 조회, GitLab 파이프라인 상태, Athena에 CloudTrail 로그 추가
- Amazon Bedrock AgentCore Gateway 도입 검토: MCP 서버의 인증/라우팅을 단일 포인트로 통합
- Synthetic Monitoring 운영 안정화: 자체 구축한 HTTP 가용성 체크(Datadog Synthetic 대체) 운영 고도화
- 비용 최적화 보조 에이전트: Strands Agents로 Cost Explorer + Trusted Advisor 분석, 주간 리포트 자동 생성
10. 마치며
이 프로젝트에서 가장 중요했던 교훈은, AI 도구를 도입하는 것과 AI가 실제로 일하게 만드는 것은 다른 문제라는 점입니다.
AWS DevOps Agent는 Topology 자동 빌드, 자율 조사, 예방적 개선 추천 등 강력한 기능을 제공하지만, 그것만으로는 우리 환경에서 완벽하게 동작하지 않았습니다. 16개 계정에 흩어진 서비스들의 이름 매핑, 코드 저장소 위치, 로그 아카이브 구조 — 이런 조직 고유의 컨텍스트를 Agent에게 전달해야 했습니다. Custom MCP 서버와 Skills로 이 컨텍스트를 제공하고, Datadog 에러 감지부터 Investigation 생성, Bedrock을 활용한 담당팀 분류, Jira 이슈 자동 등록까지 전후 파이프라인을 연결한 것이 실질적인 가치를 만들었습니다.
Managed 서비스인 AWS DevOps Agent의 핵심 기능을 활용하면서, 부족한 부분만 자체 구축하는 하이브리드 전략은 소규모 팀이 빠르게 성과를 내는 데 효과적이었습니다. PoC를 시작하고 약 6주, 1인이 설계부터 운영 투입까지 완료할 수 있었던 것은 이 전략 덕분입니다.
같은 패턴으로 시작하려면
이 시스템의 각 조각은 독립적입니다. 전체를 한꺼번에 구축할 필요가 없습니다:
- MCP 서버 하나 만드는 데 필요한 것: Python + FastAPI + 반나절
- Skill 하나 추가하는 데 필요한 것: 마크다운 파일 하나
- 이벤트 파이프라인 하나 연결하는 데 필요한 것: Lambda + EventBridge Rule
MCP 서버 하나만 만들어도 Agent가 바로 도구를 사용하기 시작하고, Skill 한 줄 수정만으로 Agent의 행동이 바뀝니다. 작게 시작하고, 효과가 확인되면 점진적으로 확장하는 것이 가능합니다.
