AWS 기술 블로그
Amazon Bedrock 사용량 관리 및 최적화 하기
Amazon Bedrock을 이용하여 다양한 AI 서비스를 구축하고 Poc단계부터 실제 서비스를 런칭하는 단계까지 안정적인 AI 서비스를 구축하는 것은 쉽지 않은 긴 여정입니다. 특히 LLM의 토큰 사용량 관리와 토큰 최적화는 운영서비스를 런칭한 이후 겪게 되는 중요한 문제들이라고 할수 있습니다. AI 서비스를 성공적으로 런칭한 고객들 조차도 LLM 토큰 사용량에 대한 명확한 모니터링, 토큰 최적화, 그리고 리밋 증설하는 부분에서 어려움을 겪는 것을 보게 되었습니다. 이 블로그에서는 실제 AI 서비스를 구축한 많은 고객사분들에게 Bedrock 토큰 사용량 관리 및 최적화 방법에 대한 조금이나마 도움을 드리고자 해서 쓰게 되었습니다.
Amazon Bedrock의 3가지 엔드포인트 및 Limit 증설방법
먼저 Amazon Bedrock에서 사용할수 있는 3가지 엔드포인트 유형을 말씀드리겠습니다. Regional Endpoint 는 각 리전별 단일 Bedrock 엔드포인트 입니다. 그리고 Cross Region Inference(CRIS) Endpoint로 Geo CRIS 와 Global CRIS 2가지 유형이 있습니다.
1. Regional 엔드포인트
각 리전에 존재하는 표준 Bedrock API 엔드포인트로, 다음과 같은 형태로 구성됩니다. 서울리전을 예로 들어서 설명 드리겠습니다.
- bedrock.ap-northeast-2.amazonaws.com (Control plane) : 관리 및 제어를 담당하는 엔드포인트로 모델 자체를 실행하는 것이 아니라, 모델의 목록을 조회하거나 모델 상세정보를 확인하고, Provisioned Throughput 생성및 관리, 그리고 모델 파인튜닝 작업을 관리할 때 사용합니다.
- bedrock-runtime.ap-northeast-2.amazonaws.com ( Data Plane) : 실제 모델 추론(Inference)을 수행하는 엔드포인트입니다. 사용자가 텍스트나 이미지를 입력하고 모델로부터 응답을 받는 핵심적인 실행단계로 주로 사용하는 엔드포인트라고 할수 있습니다.
- bedrock-agent.ap-northeast-2.amazonaws.com ( Agent Plane) : AI 에이전트 및 기술적 오케스트레이션을 관리하는 엔드포인트로 단순한 모델 호출을 넘어, 복잡한 작업을 자율적으로 수행하는 에이전트 설계를 담당합니다. Bedrock Agent나 Knowledge Base를 생성하고 관리하는데 사용합니다.
| 구분 | Bedrock (Control) | Bedrock Runtime | Bedrock Agent |
|---|---|---|---|
| 핵심 역할 | 모델 관리 및 인프라 설정 | 실제 모델 추론 (응답 생성) | 자율 에이전트 및 지식기반 구축 |
| 호출 빈도 | 낮음 (초기 설정 시) | 매우 높음 (실시간 서비스) | 중간 (에이전트 로직 설계 시) |
| 사용 사례 | 사용 가능한 모델 리스트 보여줘 | 이 질문에 답변해줘 | 이 문서를 참고해서 결제까지 완료해 줘 |
엔드포인트의 구성과 종류에 대한 자세한 내용은 Amazon Bedrock Endpoint 할당량 문서를 참조해주세요.
모델을 단일 리전에서 호출하는 방식입니다. 만약 해당리전에서 서비스가 중단된다면, 서비스가 복구될 때까지 다른 리전의 엔드포인트로 Fail over 하도록 모델을 호출하는 애플리케이션 코드를 직접 수정해야 합니다. Cross Region Infrerence가 나오기 전까지 기본적으로 사용했기때문에, 혹시 아직도 기본 Regional 엔드포인트를 사용하고 계시다면, CRIS를 사용하는 것을 강력하게 권장 드립니다.
2. Geo CRIS / Global CRIS (Inference Profile 기반)
CRIS는 Amazon Bedrock의 Cross-Region Inference 기능을 말합니다. 엔드포인트를 직접 지정해서 호출하지 않고 Inference Profile을 통해 사용하는 간접적인 방식입니다. Regional Endpoint와 다르게 CRIS는 사용자가 직접 리전 단위로 호출하지 않습니다. 따라서 특정 리전에서 발생할수 있는 장애 처리와 토큰 관련 리밋으로 인한 서비스 중단 문제를 피해갈 수 있습니다. 아래와 같이 두가지 유형이 있습니다.
Geo Cross-Region Inference(CRIS)
특정 지리(US, EU, APAC 등)내에서 한개의 리전을 베이스로 하지만, 해당 리전에서 장애가 발생해도, 자동으로 다른 리전으로 Fail Over가 되므로 안정적으로 서비스를 운영할수 있습니다. 예를 들어 서울리전에서 Geo CRIS를 사용하면, 리전 장애가 발생하거나, Limit Throttle로 인해 서비스가 원활하지 않더라도 도쿄리전이나 싱가폴 리전으로 자동 라우팅되어 해당 이슈를 피해갈 수 있습니다.
Global Cross-Region Inference(CRIS)
Geo CRIS와 기본적으로 동일하며 다른 점은 지리적인 제한 없이 전 세계 상용 리전으로 라우팅이 가능하여, 처리량과 가용성을 극대화하는 글로벌 엔드포인트라는 점입니다. 앞서 설명드린 서울리전뿐 아니라 다른 리전에서도 장애가 동시 다발적으로 발생하는 경우가 있다고 가정해보겠습니다. 이 때에도 장애가 나지 않은 다른 지역의 리전을 통해서 서비스를 계속 이어갈 수 있습니다. 다만, Global CRIS의 경우 Geo CRIS에 비해서 50ms~300ms정도의 레이턴시가 발생할수 있습니다. Geo 와 Global CRIS의 차이점을 아래와 같이 정리하였습니다.
| 항목 | Geo CRIS | Global CRIS |
|---|---|---|
| 라우팅 범위 | 지정한 지리 (US, EU, APAC, JP, AU 등) 내부 상용 리전 중에서만 자동 라우팅 | 전 세계 지원 상용 리전 중 최적의 리전으로 자동 라우팅 |
| 데이터 제한 / 컴플라이언스 | 지정 지리 경계를 벗어나지 않도록 처리되어 데이터 레지던시와 규제 요구 충족에 유리 | 특정 지리 내 처리 보장은 없으며, 데이터 레지던시 요건이 느슨한 워크로드에 적합 |
| 처리량 · 확장성 | 단일 리전보다는 높지만, Global보다는 작은 리전 풀이라 상대적으로 낮은 처리량 | 가장 넓은 리전 풀을 쓰기 때문에 CRIS 타입 중 최고 수준 처리량 · 탄력성 |
| 가격 구조 | 동일 모델 대비 Global endpoint보다 약 10% 프리미엄 (전용 지역 용량 확보 비용 반영) | Claude Sonnet 4.5 기준으로 Regional 대비 약 10% 저렴 (프리미엄 없음) |
| 주요 사용 시나리오 | 금융 · 공공 등 특정 지리 내 처리 요구가 있거나, 고객 계약상 데이터가 특정 지역 밖으로 나가면 안 되는 경우 | 전 세계 사용자 대상 서비스, 최대 가용성 · 처리량이 중요하고 데이터 지리 제한이 크지 않은 경우 |
| 엔드포인트 / 모델 ID 예시 | us.anthropic.claude-sonnet-4-20250514-v1:0
us.anthropic.claude-haiku-4-5-20251001-v1:0 us.anthropic.claude-sonnet-4-5-20250929-v1:0 |
global.anthropic.claude-sonnet-4-20250514-v1:0
global.anthropic.claude-haiku-4-5-20251001-v1:0 global.anthropic.claude-sonnet-4-5-20250929-v1:0 |
CRIS가 지원되는 리전및 예제에 대한 설명은 앤트로픽의 문서에도 자세하게 잘 나와있습니다. 참고 부탁드립니다.
3.Bedrock Quota Limit 증설 방법
CRIS를 사용하더라도 사용량이 증가하면서 Quota Limit 증설이 필요할 수 있습니다. 아래 화면과 같이 AWS Management Console에서 Service Quotas > AWS services > Amazon Bedrock로 들어가서 Quota name을 찾아서 신청합니다. Service Quotas에서 Limit 증설을 신청하게 되면, 자동으로 Support Case가 생성됩니다. 생성된 Case를 통해 진행상황과 결과를 확인할 수 있습니다. 만약 증설하고자 하는 Quota가 비활성화되어 있다면, 별도로 Support Case를 오픈하여 요청하시면 됩니다. Support Case에서 증설 작업이 완료되었다는 메세지를 확인한 후에는 아래 화면에서와 같이 “Applied account-level quota value” 컬럼에서 증설된 값을 확인하실 수 있습니다.
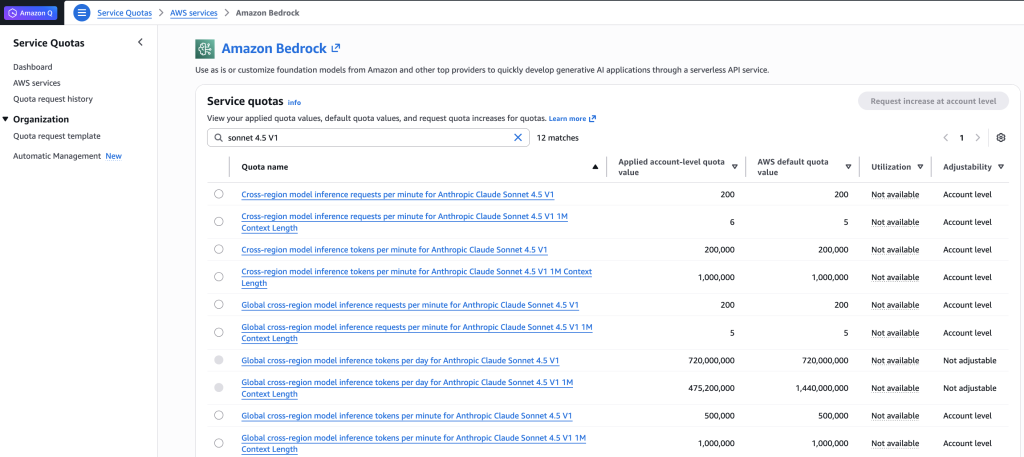
Figure 1. Bedrock Quota Limit
주요 Service Limit (Claude Sonnet 4.5 V1 모델의 예)
| 항목 | Quota name | Quota name의 의미 |
|---|---|---|
| 요청 횟수 제한 | Cross-region model inference requests per minute for Anthropic Claude Sonnet 4.5 V1 | 다른 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 추론 요청을 할 때 분당 허용되는 최대 요청 수 – 표준 컨텍스트 길이 (기본 128K 토큰)를 사용하는 모델에 적용됨. |
| Cross-region model inference requests per minute for Anthropic Claude Sonnet 4.5 V1 1M Context Length | 다른 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 추론 요청을 할 때 분당 허용되는 최대 요청 수 – 확장된 1M (백만) 토큰 컨텍스트 길이를 사용하는 모델 버전에 적용됨. | |
| Global cross-region model inference requests per minute for Anthropic Claude Sonnet 4.5 V1 | 전 세계 모든 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 분당 수행할 수 있는 최대 크로스 리전 추론 요청 수 – 표준 컨텍스트 길이 (기본 128K 토큰)를 사용하는 모델에 적용됨. | |
| Global cross-region model inference requests per minute for Anthropic Claude Sonnet 4.5 V1 1M Context Length | 전 세계 모든 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 분당 수행할 수 있는 최대 크로스 리전 추론 요청 수 – 확장된 1M (백만) 토큰 컨텍스트 길이를 사용하는 모델 버전에 적용됨. | |
| 토큰 처리량 제한 | Cross-region model inference tokens per minute for Anthropic Claude Sonnet 4.5 V1 | 다른 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 처리할 수 있는 분당 최대 토큰 수 – 표준 컨텍스트 길이 (기본 128K 토큰)를 사용하는 모델에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. |
| Cross-region model inference tokens per minute for Anthropic Claude Sonnet 4.5 V1 1M Context Length | 다른 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 처리할 수 있는 분당 최대 토큰 수 – 확장된 1M (백만) 토큰 컨텍스트 길이를 사용하는 모델 버전에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. | |
| Global cross-region model inference tokens per day for Anthropic Claude Sonnet 4.5 V1 | 전 세계 모든 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 하루 (24시간) 동안 처리할 수 있는 최대 토큰 수 – 표준 컨텍스트 길이 (기본 128K 토큰)를 사용하는 모델에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. | |
| Global cross-region model inference tokens per day for Anthropic Claude Sonnet 4.5 V1 1M Context Length | 전 세계 모든 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 하루 (24시간) 동안 처리할 수 있는 최대 토큰 수 – 확장된 1M (백만) 토큰 컨텍스트 길이를 사용하는 모델 버전에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. | |
| Global cross-region model inference tokens per minute for Anthropic Claude Sonnet 4.5 V1 | 전 세계 모든 리전에서 Claude Sonnet 4.5 V1 모델을 사용하여 분당 처리할 수 있는 최대 토큰 수 – 표준 컨텍스트 길이 (기본 128K 토큰)를 사용하는 모델에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. | |
| Global cross-region model inference tokens per minute for Anthropic Claude Sonnet 4.5 V1 1M Context Length | 전 세계 모든 리전에서 확장된 1백만 토큰 컨텍스트를 지원하는 Claude Sonnet 4.5 V1 모델을 사용하여 분당 처리할 수 있는 최대 토큰 수 – 확장된 1M (백만) 토큰 컨텍스트 길이를 사용하는 모델 버전에 적용됨. 입력 및 출력 토큰 모두 이 제한에 포함됨. |
*위 주요 Service Limit 에서 “Cross-region model inference”는 Geo CRIS로 생각하면 되고, “Global cross-region model inference”는 Global CRIS로 생각하시면 됩니다.
Service Limit 증설 신청할 때 주의사항
- Supported Regions and models 공식 문서를 참고하여 Geo CRIS와 Global CRIS 각각에 대해서 각 모델별로 지원되는 region 정보를 확인하고 신청해야 합니다. 이 문서는 자주 업데이트가 되므로, Service Limit을 신청할 때 항상 그 시점에 확인한 후 신청하는 것이 좋습니다.
- Use Case 1 : 예를 들어 사용자가 ap-northeast-2 region에 있고 APAC region 내에서 Anthropic Claude Sonnet 4 의 API를 호출하고 싶은 경우에는 이 문서에서 “APAC Claude Sonnet 4” 부분을 찾아서 클릭하면 지원하는 Source Regions 정보가 나오는데, 사용자가 있는 ap-northeast-2 region이 Source Region으로 지원되는지 확인한 후 Service Limit 증설을 신청하면 됩니다.
- Use Case 2 : 또 다른 예를 들어보면 사용자가 ap-northeast-2 region에 있고 APAC region 내에서 Anthropic Claude Sonnet 4.5 의 API를 호출하고 싶은 경우에 이 문서에서 “APAC Claude Sonnet 4.5” 항목이 있는지 확인해 보면 현재 존재하지 않는 것을 확인할 수 있습니다. 이 경우는 Geo CRIS로 APAC region을 지원하지 않는 것이므로 Global CRIS를 사용해야 합니다. 그래서 “Global Claude Sonnet 4.5” 항목을 찾아 클릭해보면 지원하는 Source Regions 정보에 ap-northeast-2 region이 존재함을 확인할 수 있고, 따라서 Global CRIS로 Service Limit 증설을 신청하면 됩니다.
- Use Case 3 : 이번에는 사용자가 ap-northeast-2 region에 있고 Global region 내에서 Anthropic Claude Sonnet 4 의 API를 호출하고 싶은 경우인데, 이 문서에서 “Global Claude Sonnet 4” 항목을 찾아서 클릭해 보면 Source Regions에 ap-northeast-2 region이 현재 존재하지 않는 것을 확인할 수 있습니다. 이 경우는 Global CRIS로 지원하지 않는 것이므로 Geo CRIS를 사용해야 합니다. 그래서 “APAC Claude Sonnet 4” 항목을 찾아서 클릭해 보면 지원하는 Source Regions 정보에 ap-northeast-2 region이 존재함을 확인할 수 있고, 따라서 Geo CRIS로 Service Limit 증설을 신청하면 됩니다.
- Service Limit 증설을 신청한 후 Support Case에서 증설이 완료되었음을 확인하게 되면, 반드시 AWS Management Console의 Service Quotas 서비스 또는 AWS CLI를 이용하여 해당 Service Limit이 원하는 값으로 증설이 되었는지 확인해야 합니다. 간혹 Support Case에서 증설이 완료되었다고 안내가 되어도 Service Quotas 서비스 또는 AWS CLI를 이용하여 해당 Service Limit 값을 확인해 보면 원하는 값으로 증설이 되어 있지 않을 수 있습니다. 이것은 처음부터 큰 값으로 증설하지 않고 먼저 적정 값으로 증설한 후 적정 값에 도달하면 더 큰 값으로 증설하기 위함이오니, 이럴 경우에는 한 번 더 Service Quotas 또는 Support Case를 통해서 Service Limit 증설을 원하는 값으로 요청할 필요가 있습니다.
Amazon Bedrock에서 사용량 관리를 위한 모니터링
Amazon Bedrock 사용량을 최적화하더라도, 사용량 증가에 따른 모니터링은 필수입니다. 기본적으로 Bedrock의 사용량을 모니터링하는 방법은 크게 두가지로 Bedrock 사용량 지표는 CloudWatch 메트릭(집계) 과 Invocation 로그(상세) 2가지로 볼수 있습니다.
1. 사용량 관련 주요 지표(CloudWatch Metrics) – GenAI Observability
가장 간단하고 쉬운 방법은 CloudWatch 콘솔의 대시보드를 이용하면 됩니다. 아래 그림에서 보듯이, 왼쪽 메뉴에서 GenAI Observability를 클릭하면 기본적으로 토큰사용 갯수를 비롯한 Bedrock의 주요 사용지표들을 확인할 수 있습니다. 모델별 토큰 카운트를 비롯해서 Input/Output 토큰, Throttle횟수, Error count등 다양한 지표를 확인할수 있습니다.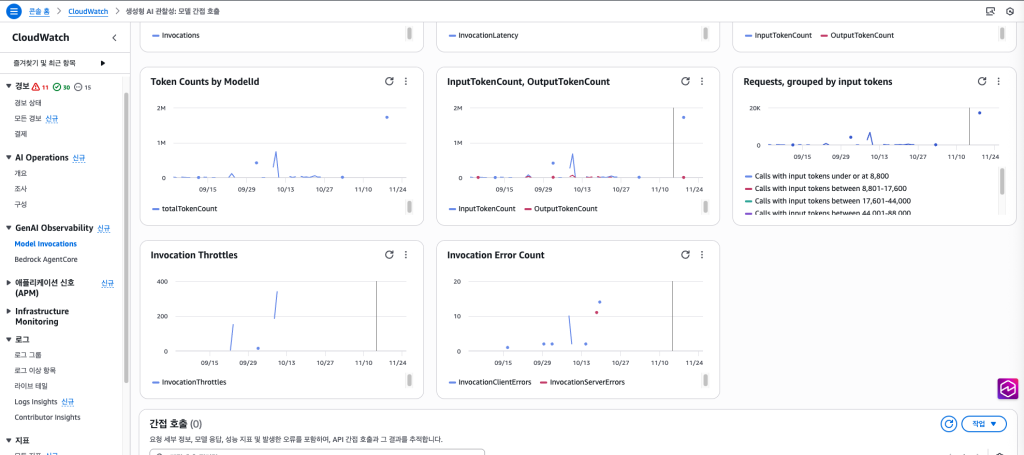
Figure 2. Bedrock 사용량 관련 주요 지표
주요 지표들을 보면 다음과 같습니다. 아래 표는 토큰 사용량 지표들을 정리한 내용입니다. 토큰 지표는 비용 관리의 핵심입니다. Bedrock은 입력/출력 토큰 단위로 과금되므로, 이 지표를 통해 실시간 비용을 추정하고 예산 초과를 방지할 수 있습니다.
| 지표명 | 단위 | 설명 |
|---|---|---|
| InputTokenCount | SampleCount | 입력 프롬프트의 토큰 수. 비용 산정의 기준이 되며, 프롬프트 최적화 효과를 측정할 때 필수 |
| OutputTokenCount | SampleCount | 모델이 생성한 응답의 토큰 수. 비용 예측 및 max_tokens 파라미터 조정에 활용 |
| CacheReadInputTokens | SampleCount | Prompt Caching 사용 시 캐시에서 읽은 토큰 수. 0이면 캐싱 미사용 |
| CacheWriteInputTokens | SampleCount | Prompt Caching 사용 시 캐시에 쓴 토큰 수 |
호출 성능 지표도 중요합니다. 토큰 사용량과 더불어서 InvocationLatency, Throttles 등의 지표도 서비스가 잘 작동하는지 확인하는 중요척도이므로 주의해서 보고 필요한 경우 알람을 설정해두는 것이 필요합니다.
| 지표명 | 단위 | 설명 |
|---|---|---|
| Invocations | SampleCount | InvokeModel, Converse API 등의 성공적인 호출 횟수 |
| InvocationLatency | Milliseconds | 요청부터 응답까지의 전체 지연 시간. 사용자 경험 품질의 핵심 지표 |
| InvocationThrottles | SampleCount | 스로틀링 (요청 제한)된 호출 수. TPM / RPM 할당량 초과 여부 파악 |
| InvocationClientErrors | SampleCount | 클라이언트 측 오류 (4xx). 잘못된 요청 형식, 권한 문제 등 |
| InvocationServerErrors | SampleCount | AWS 서버 측 오류 (5xx). 서비스 가용성 문제 감지 |
InvocationThrottles는 특히 중요한데, 이 값이 증가하면 현재 할당량(TPM/RPM)이 워크로드에 비해 부족하다는 신호입니다. 할당량 증가 요청을 고려하거나 CRIS(Cross-Region Inference)를 활용해야 합니다.
2. Bedrock Invocation Logging 활성화(상세 로깅)
좀 더 상세하게 토큰 사용량을 모니터링하는 방법도 있습니다. 특히 요청별 프롬프트/응답 메타데이터, 토큰 수 등을 남기려면 아래 그림처럼, Bedrock 콘솔에서 모델 호출 로깅(Model invocation logging) 을 활성화해야 합니다.
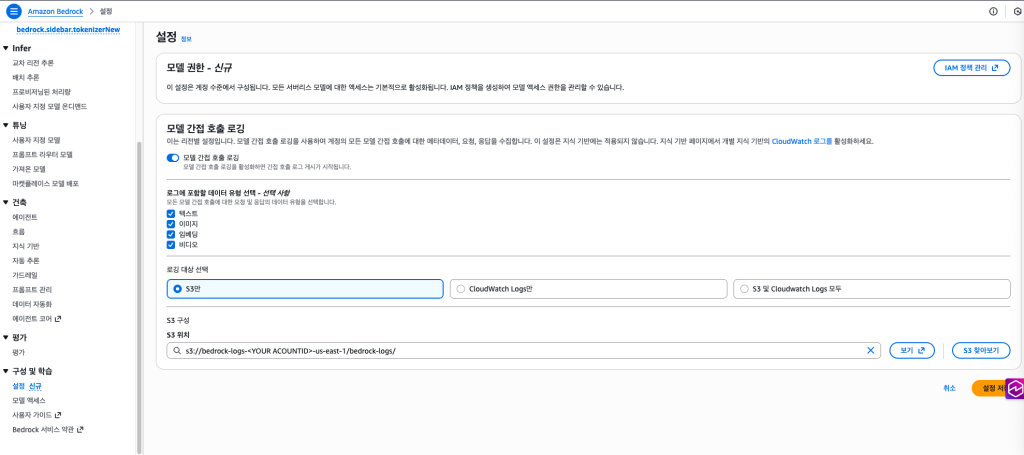
Figure 3. Bedrock Invocation logging
로깅대상은 위 그림에 나와있듯이 3가지 유형중에 한가지를 선택할 수 있습니다. S3버킷을 선택한 경우는 이미 버킷을 생성하고 폴더가 만들어져있어야 합니다. 물론 버킷이름이나 폴더명은 무엇으로 만들든지 상관 없습니다. S3 로깅하는 부분에 대해서는 밑에서 자세히 설명 드리겠습니다.
- S3 Only
- CloudWatch Logs Only
- S3 및 CloudWatch Logs 둘다 저장
S3에 데이터를 보내고 아테나를 연동하여 쿼리 형태로 조회할수도 있고, CloudWatch log로 내보내는 방법도 있습니다. 바로 위에서 설명드린 대시보드 형태의 토큰 카운트를 측정하는 것보다 더욱 자세한 사용량을 추적할수 있습니다. 모두 체크하고 S3등 상세 로그를 저장할 목적지를 세팅하면, 이후의 Bedrock 모델 호출이 해당 로그 그룹 및 S3 버킷으로 전송됩니다. 여기서 얻을 수 있는 상세정보는 다음과 같습니다.
- identity.arn: 호출한 IAM 사용자/역할 ARN
- modelId: 사용된 모델 ID
- input.inputTokenCount: 해당 요청의 입력 토큰 수
- output.outputTokenCount: 해당 요청의 출력 토큰 수
- operation: InvokeModel, Converse 등 API 작업 유형
- 요청/응답의 전체 내용 (100KB 이하)
S3-Athena를 연동하면, SQL 쿼리로 기간별, LLM 모델별로 input/output 토큰수를 쉽게 파악할수 있습니다.
다만, Bedrock Logging을 위한 S3버킷및 CloudWatch logs 는 Region 별로 각각 정해줘야 합니다.
모든 리전의 통합 사용량을 보고 싶다면 S3버킷의 Cross Region Replcation을 이용해서 한 곳에서 확인할 수 있습니다.
Cli 명령문을 통해서도 로깅 설정이 가능하며, 이와 관련된 실제 사용 예제는 Github Sample Code를 통해서 확인 해보실 수 있습니다.
3. Application 별로 사용량을 측정할수 있는가?
토큰 사용량 모니터링에 대한 질문 중에 Application별로 사용량을 측정할수 있는 문의를 많이 받게 됩니다. 기본적으로는 Application에서 직접 자신의 식별자를 Bedrock 로깅에 넣는 방법이 있습니다. Converse API의 requestMetadata 파라미터를 사용하는 방법입니다. 아래 Python 소스코드를 참조해주세요
import boto3
import json
client = boto3.client('bedrock-runtime', region_name='us-east-1')
# Converse API 사용
response = client.converse(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
messages=[
{
"role": "user",
"content": [{"text": "What is machine learning?"}]
}
],
# 애플리케이션 식별 정보 추가
requestMetadata={
"application_name": "CustomerServiceApp",
"application_id": "app-001",
"environment": "production",
"team": "customer-support",
"cost_center": "CS-123",
"tenant_id": "tenant-456",
"user_id": "user-789",
"request_source": "mobile"
}
){
"timestamp": "2025-12-03T10:54:53Z",
"accountId": "************",
"identity": {
"arn": "arn:aws:iam::************:user/********"
},
"requestId": "********-****-****-****-************",
"operation": "Converse",
"modelId": "anthropic.claude-3-haiku-20240307-v1:0",
"input": {
"inputTokenCount": 17
},
"output": {
"outputTokenCount": 90
},
"requestMetadata": {
"application_name": "DocumentAnalysisApp",
"application_id": "app-004",
"environment": "production",
"team": "product",
"cost_center": "PROD-999",
"tenant_id": "ABC-corp"
}
}이번에는 S3를 로깅대상으로 선택한 경우입니다. 아래와 같이 S3에 들어간 데이터를 아테나에서 쿼리하고 애플리케이션 별 토큰 사용량을 확인할수 있습니다. 아래와 같이 S3에 들어간 json 데이터를 Amazon Glue에서 Database를 생성하고 테이블로 생성하여 쿼리로 토큰 사용량을 집계할수 있습니다. json 데이터는 앞서 설명한 CloudWatch log에서 출력한 데이터와 동일한 포맷입니다. S3://<S3 Bucket Name>/bedrock-logs/AWSLogs/<AccountID>/<Region>/YYYY/MM/DD/ 밑에 20251204…json.gz로 저장됩니다. 그외 다른 파일 및 폴더는 Permission Check등을 실행하는 환경파일로서 참고만 하시면 됩니다.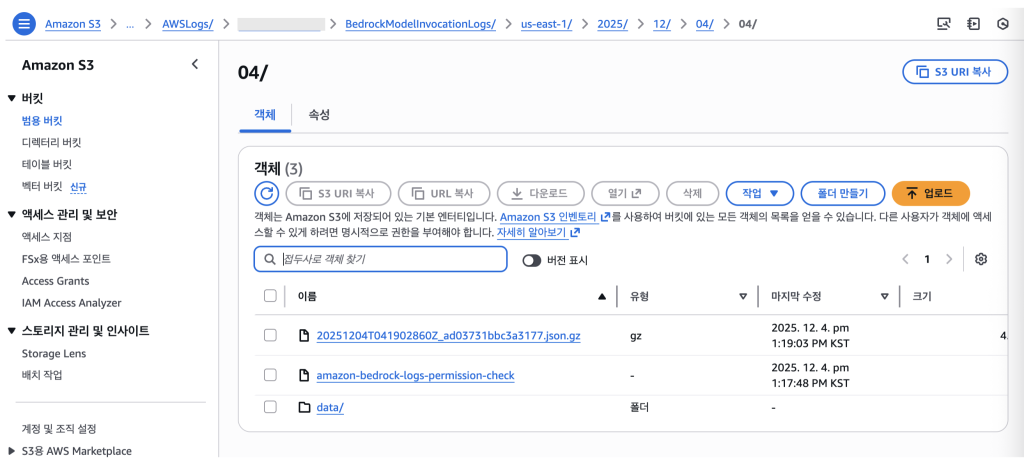
Figure 4. Bedrock 로그가 S3 에 저장된 모습
SELECT requestmetadata.application_name as app, SUM(input.inputtokencount) as total_input, SUM(output.outputtokencount) as total_output, COUNT(*) as requests FROM bedrock_logs_db.model_invocation_logs GROUP BY requestmetadata.application_name ORDER BY total_input + total_output DESC;
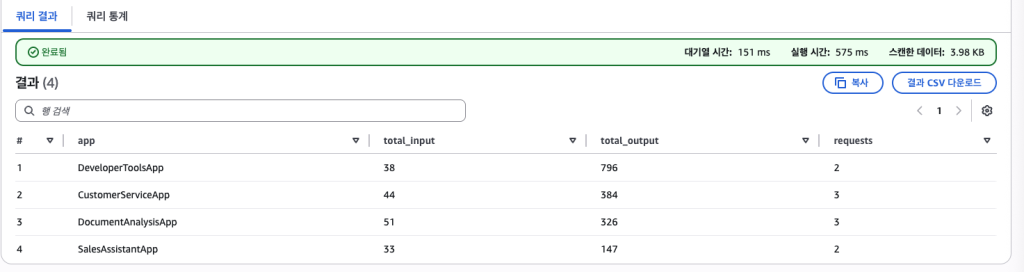
만약 서비스를 모두 런칭하신 이후, 애플리케이션을 수정하기 어려운 경우, IAM Role의 ARN에 애플리케이션별로 Role을 설정해서 애플리케이션 토큰 사용량을 확인하는 방법도 있습니다. 이렇게 하면 애플리케이션의 변경 없이도 쉽게 각 애플리케이션별 토큰사용량을 측정할수 있습니다. identity.arn 부분에 application 또는 팀별, 프로젝트별로 구분해서 다양한 사용량 분석을 할수 있습니다. IAM Role 네이밍 규칙 예시는 {ApplicationName}-BedrockRole 와 같은 방식으로 하면 됩니다. 고객서비스, 데이터분석, 챗봇서비스와 같은 형태 말고도, 프로젝트, 팀단위 별로도 롤을 부여하고 사용량을 체크할 수 있는 등 여러가지 다양한 측면의 분석이 쉽게 가능해집니다. Application들이 이미 사용되고 있다는 가정 하에, 소스코드를 수정하지 않고 IAM Role을 추가하려면 다음과 같은 과정을 거치면 되겠습니다.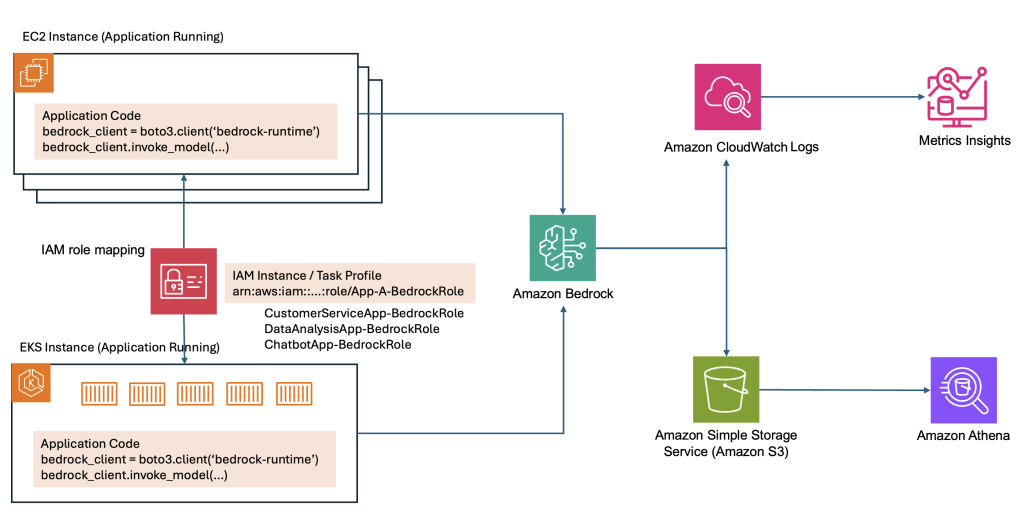 Figure 5. Bedrock 사용량 수집/저장/분석 아키텍쳐
Figure 5. Bedrock 사용량 수집/저장/분석 아키텍쳐
1) Application별로 IAM Role 을 생성합니다. (아래는 간단한 예시로 만든 Role 입니다)
- CustomerServiceApp-BedrockRole
- DataAnalysisApp-BedrockRole
- ChatbotApp-BedrockRole
2) EC2/ECS 또는 Lambda에 Role을 할당합니다.
- EC2: Instance Profile 에서 위 Role중 하나를 선택합니다.
- ECS: Task Definition의 TaskRoleArn을 지정합니다.
3) Application 코드는 그대로 실행합니다.
- boto3는 자동으로 instance profile 또는 task role을 credential로 받아서 사용합니다.
4) 사용량에 대한 분석을 실행합니다.
- S3-Athena를 연계하여 사용량을 분석합니다.
- CloudWatch Log insights로 사용량을 분석합니다.
위와 같은 방법으로 Application코드의 수정없이 Bedrock의 Application 사용량을 확인할 수 있습니다.
이와 관련한 데모를 보여드리겠습니다. 데모 영상은 링크를 클릭하면 바로 보실 수 있습니다.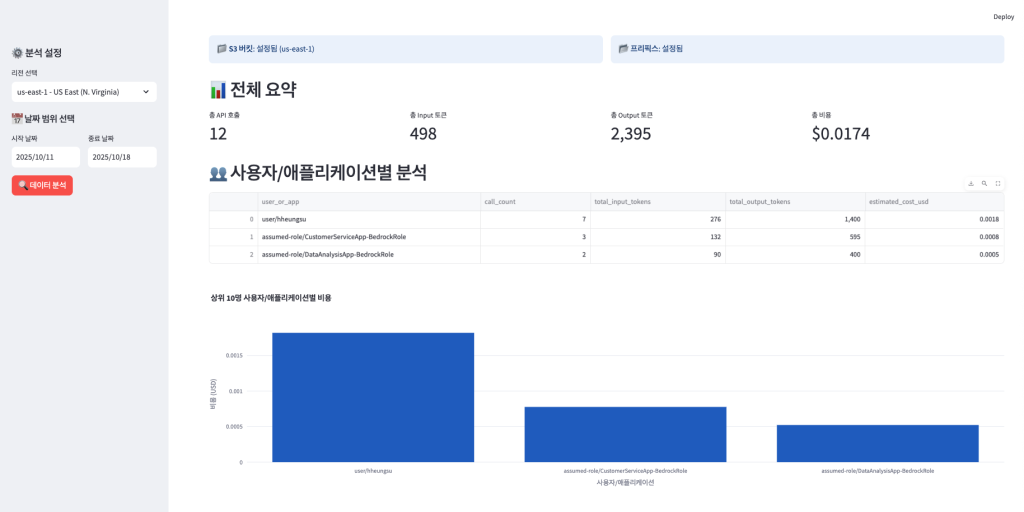
Figure 6. Bedrock 사용량 분석 대시보드
데모 영상에서 확인할 수 있는 내용은 다음과 같습니다.
- 애플리케이션별 비용 분석이 가능합니다.
- 유저 , 팀 또는 프로젝트별 비용을 기간내에서 분석할 수 있습니다.
- 리전별/모델별 사용패턴 확인 : 특정 리전및 모델 별로 사용량을 확인할 수 있습니다.
자세한 내용 및 구현 방법에 대해서는 Github Sample을 참조해 주세요.
Amazon Bedrock에서 사용량 최적화
Amazon Bedrock에서는 비용을 최적화하고 효율성을 높일 수 있는 방법으로 캐싱 기법인 프롬프트 캐시(Prompt Cache)와 시맨틱 캐시(Semantic Cache), 컨텍스트 메모리 관리 기능인 Bedrock 에이전트코어 메모리, 그리고 지능형 프롬프트 라우팅(Intelligent Prompt Routing) 등을 사용할 수 있습니다.
1. 프롬프트 캐시
프롬프트 캐시는 LLM에서 동일하거나 유사한 프롬프트 요청에 대해 기존 결과를 재사용하는 기술입니다. 상황에 따라 다르지만 반복적인 프롬프트 요청 상황에서는 약 90%의 추론 처리 비용 절감과 85%의 응답 속도 개선 효과를 보입니다. 아래 그림은 3가지 API 호출 시나리오를 보여줍니다. 각 호출은 시스템 프롬프트(10,000 토큰)와 개별 질문(50-100 토큰)으로 구성되며, 매 API 호출마다 동일한 시스템 프롬프트가 반복되어 토큰이 비효율적으로 사용되는 상황을 나타냅니다. 프롬프트 캐시를 사용하면 API 호출 2와 3에서는 개별 질문에 해당하는 토큰만 처리하면 되므로, 비용 절감과 속도 개선을 동시에 이룰 수 있습니다.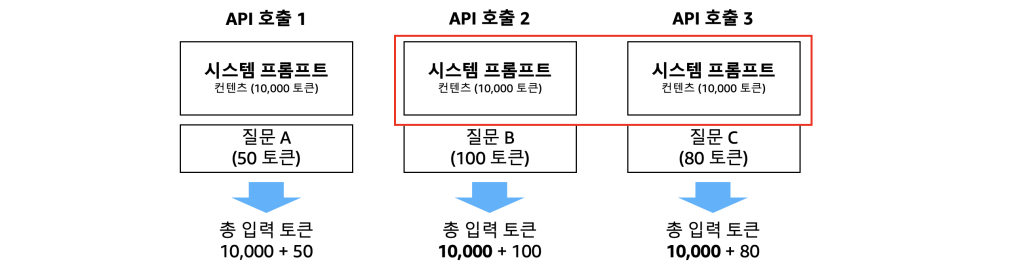
Figure 7. Bedrock Prompt Cache
2. 시맨틱 캐시
비용과 시간을 절약하기 위한 또 다른 캐싱 방법으로 시맨틱 캐시가 있습니다. 프롬프트 캐싱처럼 정확한 문자열을 매칭하는 방식이 아닌, 벡터 임베딩을 사용하여 의미적으로 유사한 쿼리들을 식별하고 이전에 생성된 응답을 재사용합니다. 예를 들어, IT 헬프데스크 챗봇에서 수천 명의 사용자가 같거나 비슷한 질문을 할 때, 매번 LLM을 호출하지 않고 캐시된 응답을 재활용할 수 있습니다. 실험 결과에 따르면 이 방식으로 LLM 추론 비용을 최대 86%, **쿼리 응답 지연 시간을 최대 88%**까지 줄일 수 있었습니다. 아래 이미지는 Amazon AgentCore Runtime을 중심으로 한 시맨틱 캐싱 아키텍처의 워크플로우를 보여줍니다. 주요 프로세스는 다음과 같은 5단계로 구성됩니다:
- 임베딩생성(Create embedding): Amazon Bedrock 임베딩 모델을 사용하여 입력 쿼리의 벡터 임베딩 생성
- 쿼리 검색(Try to read): 일레스틱캐시(ElastiCache for Valkey)에서 유사한 기존 쿼리 검색
- 캐시 미스 반환(Return Cache miss): 일레스틱캐시에서 유사한 결과를 찾지 못한 경우 표시
- 응답 생성(Create Response): Amazon Bedrock LLM 모델을 사용하여 새로운 응답 생성
- 응답 캐시(Cache the response): 생성된 응답을 일레스틱캐시에 저장
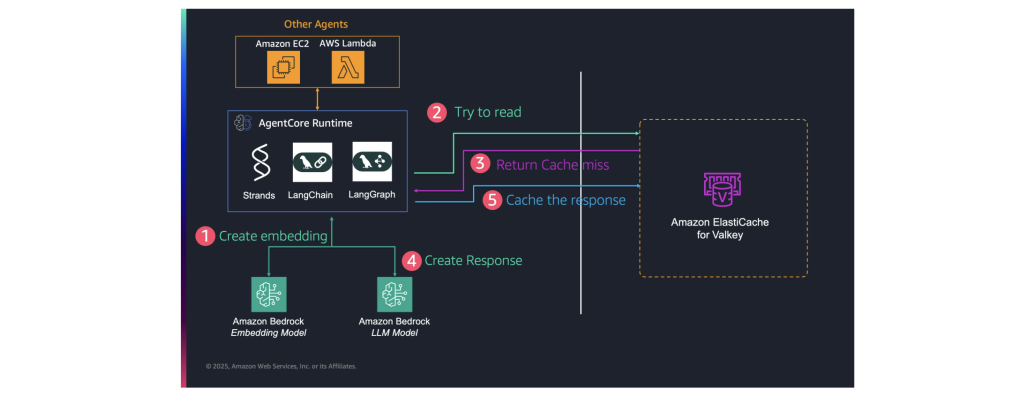
Figure 8. Bedrock Semantic Cache 흐름도
3. 지능형 프롬프트 라우팅(Intelligent Routing)
지능형 프롬프트 라우팅은 단일 엔드포인트를 제공하여 동일한 모델 패밀리 내의 서로 다른 기본 모델 간에 요청을 효율적으로 라우팅하는 기술입니다. 베드락에서는 현재 Anthropic과 Meta 프롬프트 라우터를 제공합니다. 예를 들어, 앤트로픽 모델인 Sonnet과 Haiku 모델을 Intelligent Routing 방식으로 구성하여 사용할 경우, Sonnet 단일 모델을 사용할 때와 비교했을 때 약 2% 수준의 품질 저하는 있었지만 전체적으로 약 30%의 비용 절감 효과와 응답 속도 개선 효과를 보였습니다. LLM 추론에서 민감한 수치는 아니지만 약 15-25ms의 라우팅 오버헤드가 발생할 수 있습니다.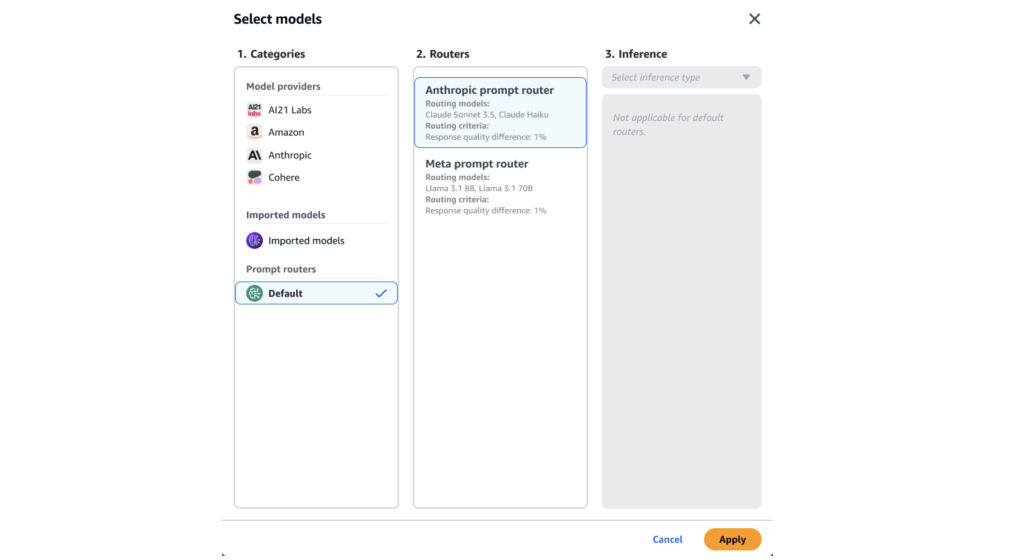
Figure 9. 지능형 Prompt Routing 적용화면
4. Bedrock 에이전트코어 메모리
Amazon 에이전트코어는 단기 메모리와 장기 메모리를 분리하여 운영합니다. 단기 메모리는 현재 진행 중인 대화의 즉각적인 맥락을 유지하면서도, 모든 대화 내용을 매번 LLM에 전달하지 않고 필요한 부분만 선택적으로 활용합니다. 장기 메모리는 벡터 임베딩을 활용한 시맨틱 검색을 통해, 방대한 과거 대화 기록 중에서 현재 맥락과 관련성이 높은 정보만을 효율적으로 검색하여 제공합니다. 에이전트코어 메모리는 자동 요약 기능을 통해 긴 대화 내용을 압축된 형태로 저장관리 하도록 아래의 장기 메모리 추출 전략을 제공합니다. 이를 통해 토큰 사용량을 최적화하면서도 에이전트가 과거 맥락을 효과적으로 이해하고 활용할 수 있게 합니다.
- 사용자 선호도 (User Preferences): 사용자의 취향, 선호도, 구매 이력 등을 시간에 따라 업데이트하며 저장.
- 의미적 기억 (Semantic Memory): 제품 사양이나 회사 정책과 같은 사실적이고 도메인에 특화된 정보를 저장.
- 요약 (Summarization): 이전 대화 세션의 주요 내용을 요약하여 저장.
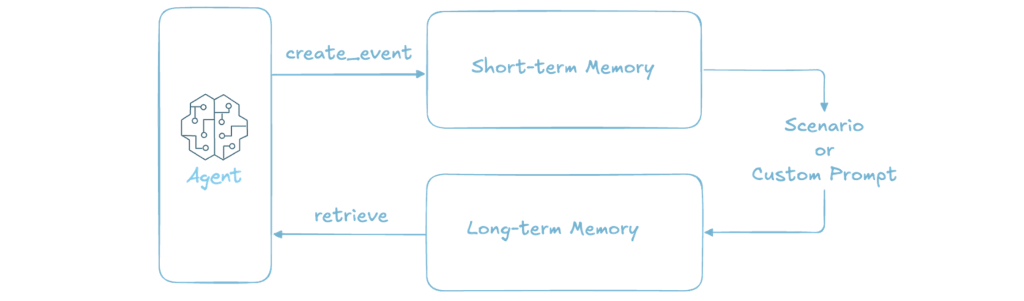
Figure 10 Bedrock AgentCore Memory
지금까지 비용 효율성과 성능을 최적화하기 위한 Amazon Bedrock의 주요 기능들을 살펴보았습니다. 이 4가지 기능들은 독립적으로 또는 조합하여 사용할 수 있어, 각 워크로드의 특성과 요구사항에 맞는 최적의 비용 효율화 전략을 구성할 수 있습니다.
마무리하며
이 블로그에서는 Amazon Bedrock 에서 사용하는 3가지 엔드포인트, 특히 그 중에서 CRIS(Cross Region Inference)를 소개드렸고, Bedrock 의 Quota Limit 증설 신청방법 및 Bedrock의 토큰 사용량 모니터링 방법을 비롯하여 Bedrock 사용량을 최적화하는 여러가지 내용을 소개 드렸습니다. Amazon Bedrock을 사용한 운영 서비스를 운영하시거나, 계획하시는 모든 분들께 조금이라도 도움이 되었으면 합니다.