AWS 기술 블로그
Claude Code 비용/사용량을 한눈에: AWS에 Observability 플랫폼 구축하기
AI 코딩 어시스턴트의 도입이 가속화되면서, 조직은 새로운 질문에 직면하고 있습니다. “우리 팀이 AI 도구를 얼마나 효과적으로 사용하고 있는가?” 세션당 비용은 합리적인지, 어떤 모델이 비용 대비 높은 생산성을 제공하는지, 도구 실행의 성공률은 어떤지 — 이러한 질문에 답하려면 체계적인 관측성(Observability) 플랫폼이 필요합니다.
Claude Code는 Anthropic이 제공하는 터미널 기반 AI 코딩 에이전트입니다. Amazon Bedrock을 통해 Claude Code를 사용하는 경우, Amazon CloudWatch에서 모델 호출 로깅으로 API 호출 횟수나 토큰 사용량 등의 기본 모니터링이 가능합니다. 그러나 Claude Code는 OpenTelemetry(OTel) 프로토콜을 통해 세션, 비용, 도구 실행 결과, 코드 변경량 등 에이전트 수준의 풍부한 텔레메트리를 내보냅니다. OTel 기반 수집 파이프라인을 구성하면 CloudWatch 기본 모니터링만으로는 얻기 어려운 — 사용자별 비용 추적, 도구 성공률, 모델별 비용 효율 비교, 세션 패턴 분석 등 — 에이전트 행동에 대한 심층적인 관측성을 확보할 수 있습니다.
이 블로그에서는 AWS 관리형 서비스만으로 구성된 이중 파이프라인(Dual Pipeline) 아키텍처를 통해 Claude Code의 메트릭과 이벤트를 수집, 저장, 분석하는 Observability Platform을 구축하는 방법을 소개합니다.
이 블로그에서 다루는 내용
- Claude Code가 OTel로 내보내는 8종 메트릭과 5종 이벤트의 활용
- 사용자별 비용 추적, 모델 효율 비교, 도구 성공률 분석 등 실제 운영 인사이트
- AWS Distro for OpenTelemetry(ADOT), Amazon Managed Service for Prometheus (AMP), Amazon Athena, Amazon Managed Grafana를 조합한 이중 파이프라인 아키텍처의 설계와 구현
AI 코딩 에이전트에 Observability가 필요한 이유
Claude Code와 같은 AI 코딩 에이전트는 단순한 코드 자동 완성을 넘어, 파일 읽기/쓰기, 쉘 명령 실행, Git 커밋, PR 생성 등 에이전틱(agentic) 워크플로우를 수행합니다. 하나의 사용자 프롬프트가 수십 번의 AI 모델 API 호출과 도구 실행을 유발하므로, 기존 소프트웨어 모니터링과는 다른 관점의 관측성이 필요합니다.
조직이 답해야 할 핵심 질문
| 관점 | 질문 | 필요한 데이터 | |
|---|---|---|---|
| 1 | 비용 관리 | 팀별/사용자별 AI 비용은 얼마인가? | 모델별 토큰 사용량, 요청 단위 비용 |
| 2 | 생산성 측정 | AI 도구가 실제 생산성에 기여하는가? | 세션 시간, 코드 변경량, 커밋/PR 수 |
| 3 | 성능 모니터링 | API 응답 시간은 적절한가? | 레이턴시 p50/p90/p99, 캐시 히트율 |
| 4 | 도구 안정성 | 도구 실행 실패율이 높지 않은가? | 도구별 성공률, 에러 메시지, 실행 시간 |
| 5 | 보안 감사 | 도구 실행이 적절히 승인되고 있는가? | 자동/수동 승인 비율, 거부된 도구 |
Claude Code는 이러한 질문에 답하기 위해 8종의 메트릭과 5종의 이벤트를 OTel 프로토콜로 내보냅니다(2026년 3월 기준). 문제는 이 데이터를 어떻게 수집하고, 어디에 저장하며, 어떻게 시각화할 것인가입니다.
어떻게 구축할 것인가
왜 이중 파이프라인인가?
Claude Code의 텔레메트리는 크게 두 가지 성격의 데이터로 나뉩니다:
| 관점 | 메트릭(Metrics) — 실시간 집계 | 이벤트(Events) — 심층 분석 | |
|---|---|---|---|
| 1 | 데이터 | 세션 수, 토큰 사용량, 비용, 코드 라인 수, 커밋, PR, 활성 시간, 도구 결정 | 사용자 프롬프트, 도구 실행 결과, API 요청/응답, API 오류, 도구 결정 |
| 2 | 특성 | 시계열 카운터, 합산/비율(rate) 계산 | 개별 레코드, SQL 쿼리 기반 분석 |
| 3 | 핵심 질문 | “지금 무슨 일이 일어나고 있는가?” | “왜 그런 일이 일어났는가?” |
| 4 | 최적 저장소 | Prometheus (시계열 DB) | Amazon S3 (Parquet) + Athena |
단일 저장소로 두 가지 요구사항을 모두 충족하기 어렵습니다. Prometheus는 실시간 rate 계산에 뛰어나지만 개별 이벤트 쿼리에 부적합하고, Athena는 SQL 기반 심층 분석에 강하지만 실시간 갱신에 적합하지 않습니다. 이 플랫폼은 각 데이터 유형에 최적화된 저장소로 라우팅하는 이중 파이프라인으로 이 문제를 해결합니다.
전체 아키텍처
![]()
전체 파이프라인은 Amazon ECS + Fargate 로 구성된 ADOT Collector, AMP, Managed Grafana, Athena 등 AWS 관리형 서비스로 구성하여 별도의 인프라 운영 부담을 최소화했습니다. 비용 분석과 같이 실시간 집계와 심층 분석이 동시에 필요한 영역에서는 Prometheus와 Athena를 하나의 대시보드에서 결합하는 하이브리드 접근을 사용합니다.
컴포넌트별 심층 분석
1. 수집 계층: ADOT Collector on ECS + Fargate
AWS Distro for OpenTelemetry(ADOT)는 OpenTelemetry Collector의 AWS 배포판으로, AWS 서비스와의 네이티브 통합을 제공합니다. 이 플랫폼에서는 ADOT Collector를 ECS + Fargate 위에 배포하여 두 개의 파이프라인을 동시에 운영합니다.
# config/adot-collector-config.yaml (핵심 발췌)
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
exporters:
# 메트릭 파이프라인: AMP로 전송
prometheusremotewrite:
endpoint: ${AMP_REMOTE_WRITE_ENDPOINT}
auth:
authenticator: sigv4auth
resource_to_telemetry_conversion:
enabled: true
# 이벤트 파이프라인: CloudWatch Logs로 전송
awscloudwatchlogs:
log_group_name: ${CW_LOG_GROUP_NAME}
log_stream_name: "claude-code-events"
service:
pipelines:
metrics:
receivers: [otlp]
processors: [memory_limiter, batch/metrics]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [memory_limiter, batch/logs]
exporters: [awscloudwatchlogs]주의: Cumulative Temporality 필수
prometheusremotewrite exporter는 cumulative temporality 메트릭만 지원하며, delta temporality 메트릭은 경고 없이 삭제합니다. 클라이언트에서 OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE=delta를 설정하면 메트릭이 AMP에 도달하지 않습니다. 이 환경변수를 제거하거나 cumulative로 명시 설정이 필요합니다.
ADOT Collector는 ECS Fargate 위에서 운영되며, 앞단의 NLB(Network Load Balancer)가 개발자 PC의 OTLP 트래픽을 수신합니다. gRPC(4317)와 HTTP(4318) 프로토콜을 모두 지원하므로 클라이언트 환경에 맞게 선택할 수 있습니다.
2. 메트릭 파이프라인: AMP
ADOT Collector가 Prometheus Remote Write API를 통해 8종의 메트릭을 AMP에 전송합니다. SigV4 인증으로 보안을 보장하며, resource_to_telemetry_conversion: true 설정으로 OTel 리소스 속성(organization_id, user_id 등)을 Prometheus 라벨로 자동 변환합니다.
| Prometheus 메트릭 | 설명 | 주요 라벨 | |
|---|---|---|---|
| 1 | claude_code_session_count |
세션 시작 횟수 | organization_id, user_id |
| 2 | claude_code_cost_usage |
비용 (USD) | organization_id, user_id, model |
| 3 | claude_code_token_usage |
토큰 사용량 | organization_id, user_id, model, type |
| 4 | claude_code_active_time_total |
활성 시간 (초) | organization_id, user_id |
| 5 | claude_code_lines_of_code_count |
코드 변경 라인 수 | organization_id, user_id, type |
| 6 | claude_code_commit_count |
커밋 수 | organization_id, user_id |
| 7 | claude_code_pull_request_count |
PR 생성 수 | organization_id, user_id |
| 8 | claude_code_code_edit_tool_decision |
코드 편집 도구 결정 | organization_id, user_id, tool_name |
AMP는 완전 관리형 서비스로 인프라 관리 없이 메트릭을 저장하고 PromQL로 쿼리할 수 있습니다. Grafana가 30초 간격으로 자동 새로고침하여 실시간에 가까운 모니터링을 제공합니다.
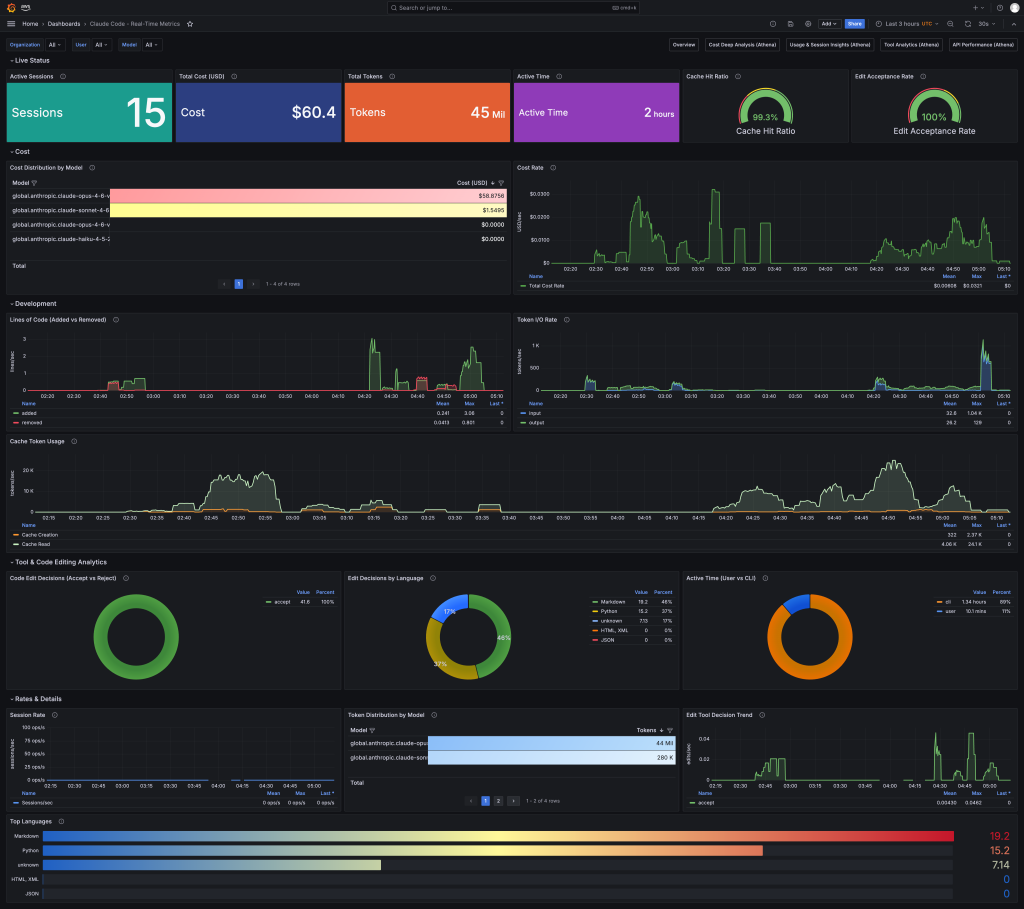
<Real-Time Metrics 대시보드> AMP 를 통해 수집한 실시간 메트릭, 메트릭 기반이기 때문에 실시간 정보 확인이 가능하며 비용, 사용량, 세션 정보 등을 확인할 수 있습니다.
3. 이벤트 파이프라인: CloudWatch Logs → Amazon Data Firehose → S3 → Athena
이벤트 파이프라인은 개별 이벤트 레코드를 분석 최적화된 형태로 저장합니다. 이 파이프라인의 핵심 과제는 ADOT의 OTLP JSON 출력을 Athena에서 쿼리 가능한 Parquet 형식으로 변환하는 것입니다.
데이터 변환: Lambda Transformer
CloudWatch Logs Subscription Filter에서 Firehose로 전달되는 데이터는 CloudWatch Logs 엔벨로프(base64 + gzip)로 래핑되어 있습니다. Lambda Transformer가 이 엔벨로프를 디코딩하고 OTLP 구조를 Glue 스키마 호환 평면(flat) JSON으로 변환합니다.
# lambda/firehose-transformer/index.py (핵심 로직)
def handler(event, context):
output = []
for record in event['records']:
# 1. Base64 디코딩
compressed = base64.b64decode(record['data'])
# 2. Gzip 해제
decompressed = gzip.decompress(compressed)
# 3. CW Logs 엔벨로프 파싱
envelope = json.loads(decompressed)
# CONTROL_MESSAGE 필터링
if envelope.get('messageType') == 'CONTROL_MESSAGE':
output.append({'recordId': record_id, 'result': 'Dropped', ...})
continue
# 4. OTLP JSON -> 평면 JSON 변환
flat_records = []
for log_event in envelope.get('logEvents', []):
flat = parse_otlp_log(log_event.get('message', ''))
if flat:
flat_records.append(flat)
# 5. Newline-delimited JSON으로 결합
joined = '\n'.join(json.dumps(r) for r in flat_records) + '\n'
output.append({'recordId': record_id, 'result': 'Ok',
'data': base64.b64encode(joined.encode()).decode()})
return {'records': output}Firehose는 Glue Data Catalog 스키마를 참조하여 이 JSON을 Apache Parquet(Snappy 압축)으로 자동 변환한 후, Hive 스타일 파티셔닝(year=/month=/day=/hour=)으로 S3에 저장합니다.
이벤트 기반 실시간 파티션 등록
일반적으로 Athena에서 새 파티션을 인식하려면 MSCK REPAIR TABLE을 실행하거나 Glue Crawler를 운영해야 합니다. 이 플랫폼은 보다 효율적인 방법을 사용합니다.
S3 ObjectCreated 이벤트 → Amazon EventBridge → Lambda → Glue BatchCreatePartition API
Firehose가 S3에 새 Parquet 파일을 쓰면, S3 이벤트 알림이 EventBridge를 통해 Lambda를 트리거하고, Lambda가 Glue BatchCreatePartition API를 호출하여 수 초 내에 파티션을 자동 등록합니다. AlreadyExistsException 처리로 멱등성이 보장되므로 중복 호출에도 안전합니다. Glue Crawler의 주기적 스캔이나 MSCK REPAIR TABLE의 전체 스캔이 불필요하여 비용과 지연 시간 모두 줄일 수 있습니다.
통합 이벤트 스키마 (28 컬럼 + 4 파티션 키)
5종의 이벤트를 하나의 통합 스키마로 관리합니다. event_name 필드가 이벤트 유형의 식별자(discriminator) 역할을 하며, 각 이벤트 유형에 해당하지 않는 필드는 NULL을 갖습니다. 이 설계로 Firehose의 단일 Parquet 변환 설정만으로 모든 이벤트를 처리할 수 있습니다.
| 이벤트 | 설명 | 주요 고유 필드 | |
|---|---|---|---|
| 1 | claude_code.user_prompt |
사용자 프롬프트 입력 | prompt_length |
| 2 | claude_code.tool_result |
도구 실행 결과 | tool_name, success, duration_ms |
| 3 | claude_code.api_request |
API 호출 완료 | model, cost_usd, input/output_tokens |
| 4 | claude_code.api_error |
API 호출 오류 | model, error, status_code |
| 5 | claude_code.tool_decision |
도구 사용 결정 | tool_name, decision, source |
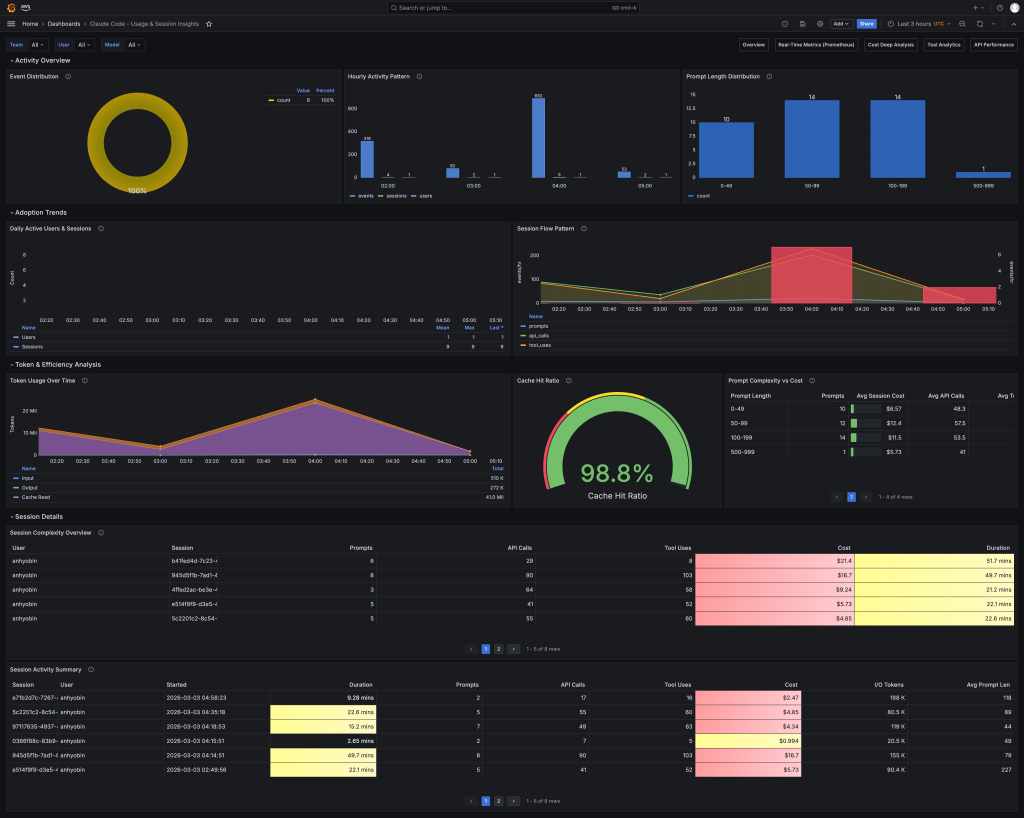
<Usage & Session Insights 대시보드> 준실시간으로 수집한 이벤트를 기반으로 통계 정보를 보여줍니다. 프롬프트에 관한 인사이트, 세션 복잡도 등의 상세 정보 등을 확인할 수 있습니다.
4. 대시보드: 6종 80패널 프로덕션 시각화
Managed Grafana에서 6개 프로덕션 수준 대시보드(총 80패널)를 통해 Claude Code 텔레메트리를 시각화합니다. 게이지 패널, 스파크라인, 그라디언트 채움, 임계값 기반 색상, 테이블 셀 컬러링, 드릴다운 데이터 링크 등 운영 환경에 적합한 시각화를 제공합니다.
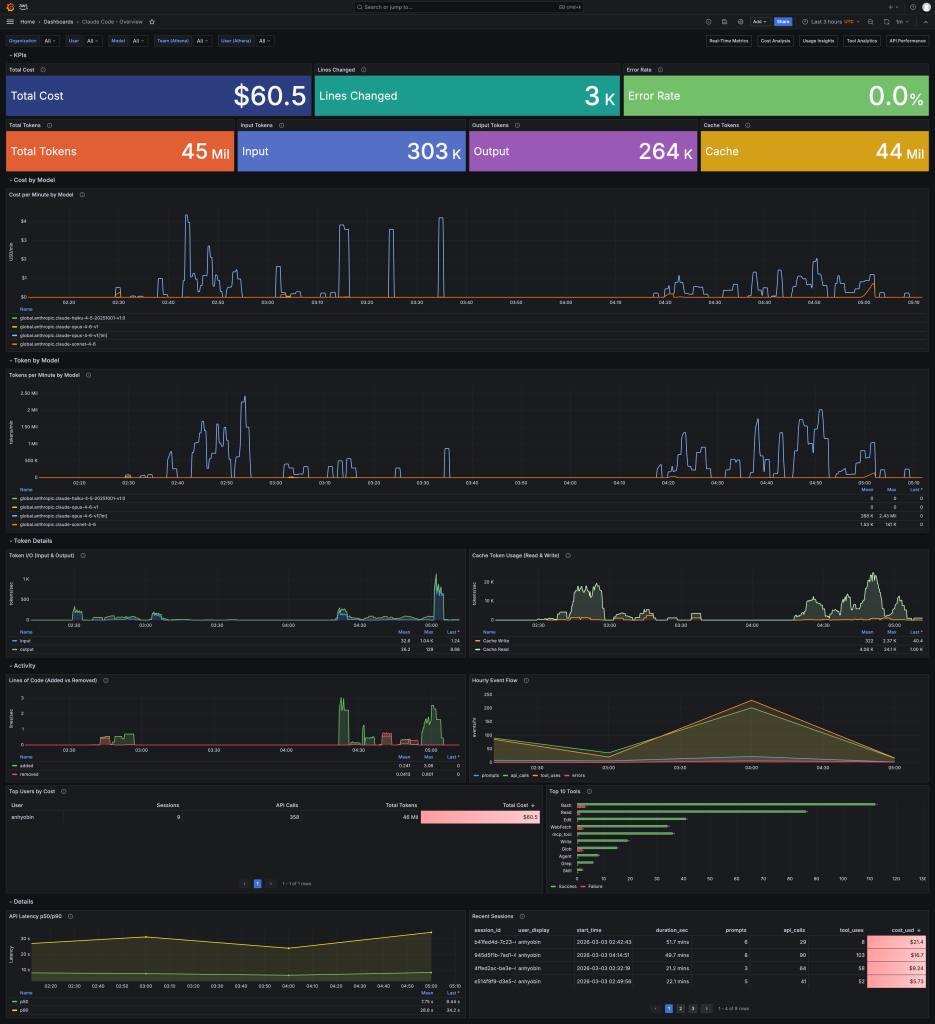
<Overview 대시보드> 메트릭과 이벤트를 종합하여 유저별 사용량, 비용 등의 정보를 빠르게 파악할 수 있습니다.
대시보드 구성 및 네비게이션
| 대시보드 | 패널 수 | 데이터 소스 | 주요 시각화 | |
|---|---|---|---|---|
| 1 | Overview | 17 | Prometheus + Athena | KPI 스파크라인, 임계값 색상, 드릴다운 링크 |
| 2 | Real-Time Metrics | 18 | Prometheus (AMP) | 게이지(캐시 히트율/수락률), 30초 자동 새로고침 |
| 3 | Cost Deep Analysis | 10 | Prometheus + Athena | 모델 비용 비교, 캐시 효율, 에러 비용 낭비 |
| 4 | Usage & Session Insights | 10 | Athena | 세션 복잡도, 프롬프트 길이 분포, 시간대별 패턴 |
| 5 | Tool Analytics | 12 | Athena | 도구 성공률 게이지, 승인/거부, 에러 패턴 |
| 6 | API Performance | 13 | Athena | 레이턴시 p50/p90/p99, 에러율 게이지, 캐시 효과 |
결론
이 블로그에서는 Claude Code가 OTel로 내보내는 8종의 메트릭과 5종의 이벤트를 AWS 관리형 서비스 기반의 이중 파이프라인으로 수집, 저장, 시각화하는 방법을 소개했습니다. 주요 구성을 요약하면 다음과 같습니다.
- 수집: ADOT Collector가 단일 수집 지점에서 메트릭과 이벤트를 두 파이프라인으로 분기
- 메트릭 파이프라인: AMP에 Prometheus Remote Write로 전송하여 실시간 집계 및 PromQL 쿼리
- 이벤트 파이프라인: Lambda로 OTLP JSON을 변환하고 Firehose가 Parquet로 S3에 저장, EventBridge 기반 실시간 파티션 등록으로 Athena에서 즉시 쿼리
- 시각화: Grafana 대시보드에서 Prometheus와 Athena를 결합하여, 실시간 모니터링과 이벤트 단위 심층 분석을 동시에 제공
Claude Code를 팀에 도입했다면, 누가 얼마나 사용하고 있는지, 비용은 합리적인지, 도구 실행은 안정적인지를 데이터로 확인할 수 있어야 합니다. 이 Observability 플랫폼이 그 출발점이 되기를 바랍니다.
시작하기
Claude Code에서 텔레메트리를 활성화하려면 다음 환경변수를 설정합니다.
# 텔레메트리 활성화 및 OTLP 전송 설정
export CLAUDE_CODE_ENABLE_TELEMETRY=1
export OTEL_METRICS_EXPORTER=otlp
export OTEL_LOGS_EXPORTER=otlp
export OTEL_EXPORTER_OTLP_PROTOCOL=grpc
export OTEL_EXPORTER_OTLP_ENDPOINT=http://<NLB_DNS>:4317
# (선택) 팀/부서별 비용 추적
export OTEL_RESOURCE_ATTRIBUTES="team_id=backend,department=engineering,cost_center=CC-001"설정 후 Claude Code를 실행하면 메트릭은 약 30초 후 Real-Time Metrics 대시보드에, 이벤트는 5~10분 후 Athena 대시보드에 표시됩니다.
이 블로그에서 소개한 전체 플랫폼은 AWS CDK로 구성되어 있으며, 다음의 GitHub 리포지토리에서 소스 코드를 확인하고 직접 배포할 수 있습니다.