AWS 기술 블로그
Amazon SageMaker HyperPod의 오토스케일링 알아보기
이 글은 Artificial Intelligence 블로그에 게시된 글 (Introducing auto scaling on Amazon SageMaker HyperPod)을 한국어로 번역 및 편집하였습니다.
2025년 8월에 Amazon SageMaker HyperPod가 Karpenter를 통한 관리형 노드 오토스케일링 지원하기 시작했습니다. 이를 통해 추론 및 학습 요구 사항에 맞춰 SageMaker HyperPod 클러스터를 효율적으로 확장할 수 있습니다. 실시간 추론 워크로드는 예측 불가능한 트래픽 패턴에 대응하고 서비스 수준 계약(SLA)을 유지하기 위해 오토스케일링이 필수적입니다. 수요가 급증할 때는 응답 시간이나 비용 효율성을 저하시키지 않으면서 GPU 컴퓨팅 리소스를 신속하게 조정하는 것이 필요합니다. 자체적으로 관리하는 Self-managed Karpenter와 달리, 완전 관리형 방식은 Karpenter 컨트롤러의 설치, 구성, 유지 관리에 따른 운영 부담을 줄이며 SageMaker HyperPod의 복원력 기능과 더욱 긴밀하게 통합됩니다. 또한 이 관리형 방식은 제로 스케일링(scale to zero)을 지원하여 Karpenter 컨트롤러 자체를 실행하기 위한 전용 컴퓨팅 리소스가 불필요하므로 비용 효율성도 높습니다.
SageMaker HyperPod는 대규모 모델 학습 및 배포에 최적화된 고성능 복원력 인프라, 관측성 및 도구를 제공합니다. Perplexity, HippocraticAI, H.AI, Articul8 등의 기업이 이미 모델 학습 및 배포에 SageMaker HyperPod를 활용하고 있습니다. 많은 회사가 파운데이션 모델(FM) 학습 뿐만 아니라 대규모 추론을 하게 되면서, 수요에 따라 노드 스케일을 확장 및 축소하며 실제 프로덕션 트래픽을 처리할 수 있는 GPU 노드 오토스케일링 기능이 필요해졌는데 이를 위해서는 강력한 클러스터 오토 스케일러가 필요합니다. AWS가 개발한 오픈 소스 Kubernetes 노드 수명 주기 관리도구(lifecycle manager)인 Karpenter는 스케일링 시간을 최적화하고 비용을 절감하는 강력한 기능으로 인해 Kubernetes 사용자들 사이에서 많이 채택되고 있는 클러스터 오토 스케일러입니다.
이 발표를 통해 SageMaker HyperPod에서 설치 및 유지보수되는 Karpenter 기반의 관리형 오토스케일링 솔루션을 제공하여, 비핵심 반복 작업(undifferentiated heavy lifting)에 대한 부담을 줄여줍니다. 이 기능은 SageMaker HyperPod EKS 클러스터에서 사용할 수 있으며, 오토스케일링을 활성화하여 SageMaker HyperPod 클러스터를 더 이상 정적 인프라가 아닌 수요에 따라 탄력적으로 확장되는 동적인 비용 최적화된 인프라로 전환할 수 있습니다. 이는 Karpenter라는 시장에서 검증된 노드 수명 주기 관리도구와 복원력(resilience)과 같은 대규모 머신러닝(ML) 워크로드의 특성에 맞춰 특수 설계된 SageMaker HyperPod의 인프라를 결합합니다. 이 글에서는 Karpenter의 이점을 자세히 살펴보고, SageMaker HyperPod EKS 클러스터에서 Karpenter를 활성화하고 설정하는 방법을 살펴봅니다.
새로운 기능과 장점
SageMaker HyperPod 클러스터의 Karpenter 기반 오토스케일링은 다음과 같은 기능을 제공합니다.
- 완전 관리형 수명 주기 – SageMaker HyperPod가 Karpenter 설치, 업데이트 및 유지 관리를 처리하여 운영 부담을 줄입니다
- 적시(Just-in-time) 프로비저닝 – Karpenter가 대기 중인 파드를 관찰하고 온디맨드 풀에서 워크로드에 필요한 컴퓨팅 자원을 프로비저닝합니다
- 제로 스케일링 – 전용 컨트롤러 인프라 없이도 노드 개수를 0개까지 축소할 수 있습니다
- 지능형(Workload-aware) 노드 선택 – Karpenter가 파드 요구사항, 가용 영역 및 가격을 기반으로 최적의 인스턴스 유형을 선택하여 비용을 최소화합니다
- 자동 노드 통합(Consolidation) – Karpenter가 클러스터 최적화 가능성을 정기적으로 탐색하고, 워크로드를 재배치하여 사용률(Utilization)이 낮은 노드를 방지합니다
- 통합 복원력 – Karpenter가 SageMaker HyperPod의 내장된 내결함성 및 노드 복원 메커니즘을 사용합니다
이러한 기능은 최근 출시된 Continuous Provisioning 기능을 기반으로 구축되었습니다. 따라서 워크로드는 사용 가능한 인스턴스에서 즉시 시작되는 동시에 아직 시작되지 않은 나머지 용량을 위해 SageMaker HyperPod가 백그라운드에서 자동으로 프로비저닝합니다. 인스턴스 capacity 부족이나 기타 문제로 노드 프로비저닝이 실패하더라도 SageMaker HyperPod는 클러스터가 목표 규모에 도달할 때까지 백그라운드에서 자동으로 재시도하므로, 오토스케일링은 논블로킹 방식으로 이뤄지며 복원력이 확보됩니다.
솔루션 개요
다음은 솔루션 아키텍처 다이어그램입니다.
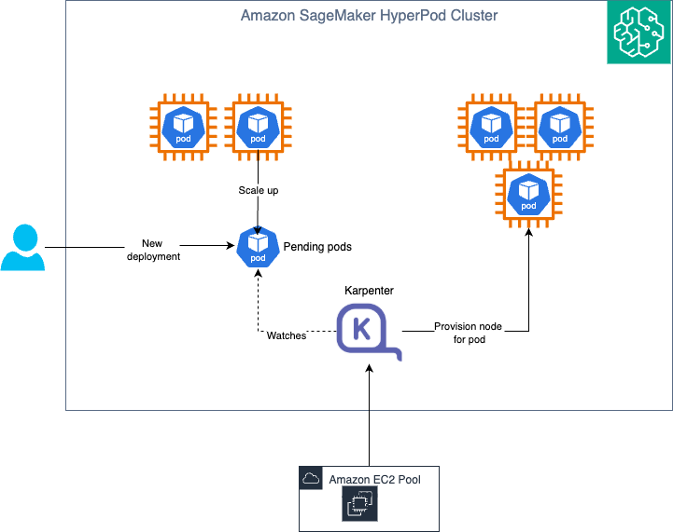
Karpenter는 클러스터 내에서 컨트롤러 역할을 하며 아래 순서로 동작합니다.
- 감시(Watching) – Karpenter가 Kubernetes API 서버를 통해 클러스터 내에서 스케줄링이 불가한 파드를 감지합니다. 배포 시 Pending 상태로 진입하거나 레플리카 수 증가를 위해 오토스케일링된 파드가 이에 해당할 수 있습니다.
- 평가(Evaluating) – Karpenter가 이러한 파드를 발견하면, 파드의 요구 사항(GPU, CPU, 메모리)과 토폴로지 제약 조건에 맞는 NodeClaim의 shape과 size를 계산하고, 기존 NodePool에 매칭 가능한지 확인합니다. 각 NodePool에 대해 SageMaker HyperPod API를 쿼리하여 지원되는 인스턴스 유형을 조회하고, 인스턴스 유형 메타데이터(하드웨어 요구 사항, 영역, 용량 유형)에 기반하여 일치하는 NodePool을 찾습니다.
- 프로비저닝(Provisioning) – 조건에 맞는 NodePool을 찾으면 Karpenter는 NodeClaim을 생성하고 새 노드로 사용할 인스턴스 프로비저닝을 시도합니다. 내부적으로 sagemaker:UpdateCluster API를 사용하여 그 인스턴스 그룹의 capacity를 증가시킵니다.
- 중단(Disrupting) – Karpenter는 새 노드 필요 여부를 주기적으로 확인합니다. 불필요한 노드는 삭제하며, 이는 내부적으로 SageMaker HyperPod 클러스터에 대한 노드 삭제 요청으로 처리됩니다.
사전 요구 사항
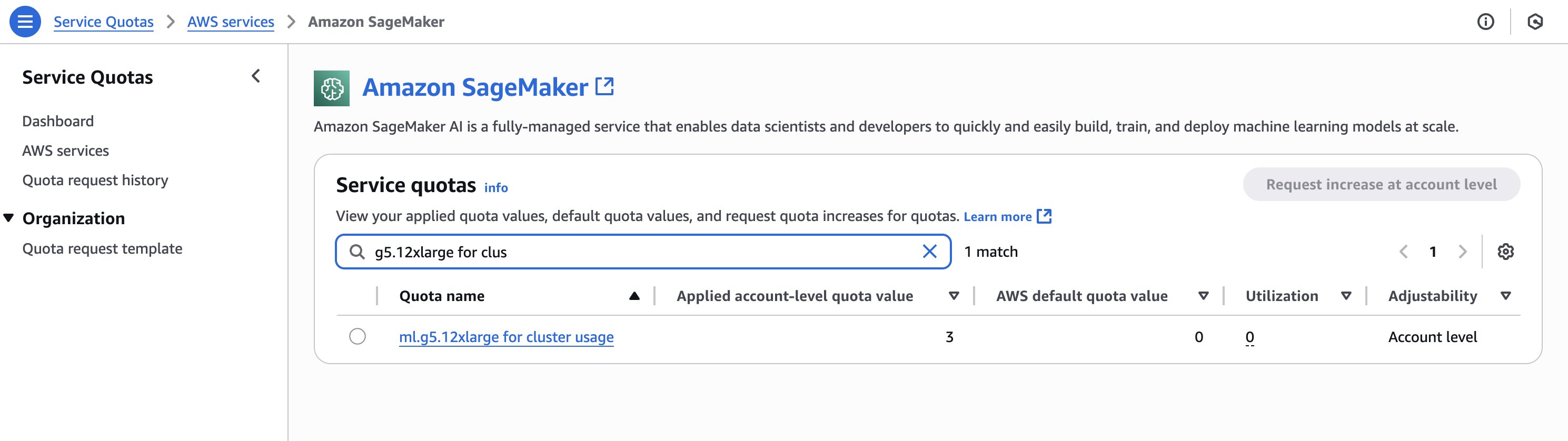
SageMaker HyperPod 클러스터에서 생성할 인스턴스에 대해 충분한 할당량(quota)이 확보되어 있는지 확인합니다. 할당량을 확인하려면 Service Quotas 콘솔의 탐색 창에서 AWS services를 선택한 다음 SageMaker를 선택합니다. 예를 들어, 다음 스크린샷은 g5.12xlarge 인스턴스의 가용 할당량(3개)을 보여줍니다.
클러스터를 업데이트하려면 먼저 Karpenter에 대한 AWS Identity and Access Management(IAM) 권한을 생성해야 합니다. 자세한 내용은 Karpenter를 사용한 HyperPod 오토스케일링을 위한 IAM 역할 생성을 참조하십시오.
SageMaker HyperPod 클러스터 생성 및 구성하기
먼저 SageMaker HyperPod EKS 클러스터를 시작 및 구성하고, 클러스터 생성 시 continuous provisioning 모드가 활성화되어 있는지 아래 순서로 확인합니다.
- SageMaker AI 콘솔에서 네비게이션 패널의 HyperPod clusters를 선택합니다.
- Create HyperPod cluster와 Orchestrated on Amazon EKS를 선택합니다.
- Setup options에서 Custom setup을 선택합니다.
- Name에 이름을 입력합니다.
- Instance recovery에서 Automatic을 선택합니다.
- Autoscaler에서 Karpenter를 선택합니다.
- Cluster role에서 Create a new IAM role을 선택합니다.
- Instance Group을 필요에 맞게 추가합니다.
- Submit을 선택합니다.

이 설정은 virtual private cloud(VPC), 서브넷, 보안 그룹, EKS 클러스터와 같은 필요한 구성을 생성하고 클러스터에 operator를 설치합니다. EKS 클러스터와 같은 리소스를 새로 생성하지 않고 기존의 것을 사용하도록 지정할 수도 있습니다. 설치 과정은 약 20분이 소요됩니다.
OverrideVpcConfig를 선택하고 각 InstanceGroup마다 서브넷을 하나만 선택하여 각 InstanceGroup이 단일 가용 영역으로 제한되도록 합니다.

이제 갖고 계신 AWS 계정 정보로 AWS CLI 설정을 마친 후, AWS Command Line Interface(AWS CLI) 또는 Boto3의 DescribeCluster API를 통해 생성된 클러스터에 Karpenter가 활성화되었는지 확인할 수 있습니다.
다음은 Boto3 예시입니다:
import boto3
client = boto3.client('sagemaker')
print(client.describe_cluster(ClusterName=<Your_Cluster_Name>).get("AutoScaling"))다음은 AWS CLI 예시입니다.
다음은 출력 예시입니다.
{'Mode': 'Enable',
'AutoScalerType': 'Karpenter',
'Status': 'InService'}이제 클러스터 생성이 완료됐습니다. 다음으로 Karpenter를 위한 custom resource를 클러스터에 설치해보겠습니다.
HyperpodNodeClass 생성하기
HyperpodNodeClass는 SageMaker HyperPod에 사전 생성된 인스턴스 그룹에 매핑되는 custom resource로, Karpenter의 오토스케일링 결정에 사용되는 인스턴스 유형과 가용 영역에 대한 제약 조건을 정의합니다. HyperpodNodeClass를 사용하기 위해 NodePool에서 파드 확장에 사용할 AWS 컴퓨팅 리소스의 소스로 지정할 SageMaker HyperPod 클러스터의 InstanceGroups 이름을 지정합니다.
여기서 사용한 HyperpodNodeClass 이름은 다음 섹션의 NodePool에서 참조되는데, NodePool은 이 이름을 통해 사용할 HyperpodNodeClass리소스를 식별합니다. HyperpodNodeClass를 생성하려면 다음 단계를 완료하십시오.
- 다음 예시와 같은 YAML 파일(예:
nodeclass.yaml)을 생성합니다. SageMaker HyperPod 클러스터 생성 시 사용한InstanceGroup이름을 추가합니다. 기존 SageMaker HyperPod EKS 클러스터에 새 인스턴스 그룹을 추가할 수도 있습니다. - NodePool 구성에서
HyperPodNodeClass이름을 참조합니다.
다음은 ml.g6.xlarge 및 ml.g6.4xlarge 인스턴스를 사용하는 HyperpodNodeClass예시입니다:
apiVersion: karpenter.sagemaker.amazonaws.com/v1
kind: HyperpodNodeClass
metadata:
name: multiazg6
spec:
instanceGroups:
# name of InstanceGroup in HyperPod cluster. InstanceGroup needs to pre-created
# before this step can be completed.
# MaxItems: 10
- auto-g6-az1
- auto-g6-4xaz2kubectl을 사용하여 EKS 클러스터에 구성을 적용합니다:
kubectl apply -f nodeclass.yamlHyperpodNodeClass상태를 모니터링하여Ready조건이True로 설정되었는지 확인합니다:
kubectl get hyperpodnodeclass multiazg6 -oyamlHyperpodNodeClass를 적용하려면 AutoScaling 이 활성화되어 있어야 하며, AutoScaling 상태가 InService로 변경되어야 합니다.
자세한 내용과 주요 고려 사항은 SageMaker HyperPod EKS의 오토스케일링을 참조하십시오.
NodePool 생성하기
NodePool은 Karpenter가 생성할 수 있는 노드와 해당 노드에서 실행할 수 있는 파드에 대한 제약 조건을 설정합니다. NodePool은 다음과 같은 다양한 작업을 수행하도록 설정할 수 있습니다:
- Karpenter가 생성하는 노드에서 실행 가능한 파드를 제한하는 label과 taint 정의
- 특정 가용 영역, 인스턴스 유형, 컴퓨터 아키텍처 등으로 노드 생성 제한
NodePool에 대한 자세한 내용은 NodePools를 참조하십시오. SageMaker HyperPod 관리형 Karpenter는 잘 알려진 Kubernetes 및 Karpenter 요구 사항 중 일부만을 지원하는데, 이에 대해서는 이 게시물에서 설명할 예정입니다.
NodePool을 생성하려면 다음 단계를 완료하십시오:
- 원하는 NodePool 구성으로
nodepool.yaml이라는 YAML 파일을 생성합니다.
다음은 NodePool을 생성하기 위한 구성 예시입니다. NodePool에 ml.g6.xlarge SageMaker 인스턴스 유형을 포함시키고, 단일 가용 영역으로 설정합니다. 다른 커스텀 옵션에 대한 정보는 NodePools를 참조하십시오.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: gpunodepool
spec:
template:
spec:
nodeClassRef:
group: karpenter.sagemaker.amazonaws.com
kind: HyperpodNodeClass
name: multiazg6
expireAfter: Never
requirements:
- key: node.kubernetes.io/instance-type
operator: Exists
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["ml.g6.xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a"]- NodePool을 클러스터에 적용합니다.
- NodePool 상태를 모니터링하여
Ready조건이True로 설정되었는지 확인합니다.
이 예시를 통해 NodePool을 사용하여 파드의 하드웨어(인스턴스 유형)와 배치(가용 영역)를 지정하는 방법을 살펴봤습니다.
간단한 워크로드 실행해보기
다음 워크로드는 파드당 1 CPU와 256MB 메모리를 요청하는 Kubernetes deployment를 실행합니다. 파드는 아직 생성되지 않은 상태입니다.
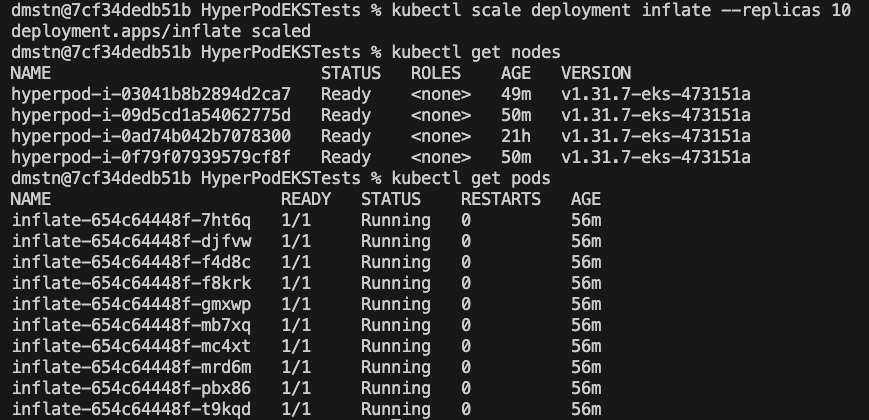
이를 적용하면 다음 스크린샷과 같이 클러스터에서 deployment 및 이를 위한 단일 노드가 시작되는 것을 확인할 수 있습니다.

이 deployment를 확장하려면 다음 명령을 사용합니다.
그러면 몇 분 내로 Karpenter가 요청된 노드를 클러스터에 추가하는 것을 확인할 수 있습니다.
KEDA와 Karpenter를 사용하여 추론을 위한 고급 오토스케일링 구현하기
SageMaker HyperPod에서 엔드투엔드 오토스케일링 솔루션을 구현하기 위해 Karpenter와 함께 Kubernetes Event-driven Autoscaling (KEDA)를 구성할 수 있습니다. KEDA는 Amazon CloudWatch 메트릭, Amazon Simple Queue Service(Amazon SQS) 대기열 길이, Prometheus 쿼리, 리소스 활용 패턴 등 다양한 메트릭을 기반으로 파드에 대한 오토스케일링을 지원합니다. 모델 배포를 대상으로 Keda ScaledObject 리소스를 구성하면, KEDA가 실시간 수요 정보를 기반으로 추론 파드 개수를 동적으로 조정할 수 있습니다.
KEDA와 Karpenter를 통합하면 강력한 2계층 오토스케일링 아키텍처를 구성할 수 있습니다. KEDA가 워크로드 메트릭을 기반으로 파드를 확장하거나 축소하면, Karpenter가 변화하는 리소스 요구 사항에 따라 자동으로 노드를 프로비저닝하거나 삭제합니다. 이 조합을 통해 클러스터가 항상 적절한 양의 컴퓨팅 리소스를 확보하여 비용을 제어하면서 최적의 성능을 제공합니다. 효과적인 구현을 위해 다음 내용을 참고하십시오.
- Karpenter의 노드 프로비저닝 시간을 고려하여 KEDA에서 적절한 버퍼 임계값 설정
- 스케일링 진동을 방지하기 위한 쿨다운 기간을 신중하게 구성
- Karpenter가 최적의 노드를 선택할 수 있도록 명확한 리소스 요청 및 제한 정의
- 워크로드 별 특성에 맞는 전용 NodePool 생성
다음은 Application Load Balancer(ALB) 요청 수에 대한 CloudWatch 메트릭을 기반으로 파드 수를 스케일링하는 KEDA ScaledObject 예시입니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: nd-deepseek-llm-scaler
namespace: default
spec:
scaleTargetRef:
name: nd-deepseek-llm-r1-distill-qwen-1-5b
apiVersion: apps/v1
kind: Deployment
minReplicaCount: 1
maxReplicaCount: 3
pollingInterval: 30 # seconds between checks
cooldownPeriod: 300 # seconds before scaling down
triggers:
- type: aws-cloudwatch
metadata:
namespace: AWS/ApplicationELB # or your metric namespace
metricName: RequestCount # or your metric name
dimensionName: LoadBalancer # or your dimension key
dimensionValue: app/k8s-default-albnddee-cc02b67f20/0991dc457b6e8447
statistic: Sum
threshold: "3" # change to your desired threshold
minMetricValue: "0" # optional floor
region: us-east-2 # your AWS region
identityOwner: operator # use the IRSA SA bound to keda-operator리소스 정리
추가 비용이 발생하지 않도록 SageMaker HyperPod 클러스터를 삭제하십시오.
결론
SageMaker HyperPod의 Karpenter 노드 오토스케일링 출시로, ML 워크로드를 요구 사항 변화에 맞게 자동 조정하고, 리소스 활용을 최적화하며, 필요 시 정밀하게 스케일링하여 비용을 절감할 수 있게 됐습니다. 또한 KEDA와 같은 이벤트 기반 파드 오토스케일러와 통합하여 커스텀 메트릭 기반으로 스케일링하는 방법에 대해 알아봤습니다.
ML 워크로드에서 이러한 장점을 활용하려면 SageMaker HyperPod 클러스터에서 Karpenter를 활성화하십시오. 자세한 구현 지침과 모범 사례는 SageMaker HyperPod EKS의 오토스케일링을 참조하십시오.