AWS 기술 블로그
클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기
소개
미디어, 광고, 교육 산업에서 비디오 콘텐츠는 폭발적으로 증가하고 있습니다. Cisco의 예측에 따르면 2022년 기준으로만 전체 인터넷 트래픽의 82%가 비디오가 될 것이라고 전망하였습니다.[1] 하지만 이 방대한 영상 자산에서 원하는 장면을 찾고, 콘텐츠를 분류하고, 인사이트를 추출하는 것은 여전히 어려운 과제입니다.
기존의 비디오 검색은 수동으로 입력한 메타데이터나 파일명에 의존했습니다. “2024년 마케팅 캠페인 영상”이라는 제목만으로는 그 안에 어떤 장면이 있는지, 누가 등장하는지, 어떤 대화가 오가는지 알 수 없습니다.
TwelveLabs Marengo는 이 문제를 해결하기 위해 설계된 멀티모달 비디오 임베딩 모델입니다. Amazon Bedrock을 통해 제공되는 이 모델은 영상의 시각, 오디오, 텍스트 요소를 각각 이해하고, 자연어로 영상을 검색할 수 있게 해줍니다.
해당 블로그에서는 VoD(Video on Demand) 환경에서 TwelveLabs Marengo를 활용한 비디오 분석 파이프라인을 구축할 때, 상황에 맞는 아키텍처 조합을 살펴봅니다.
Option 1: 입고 영상에 대한 즉시 처리
영상이 Amazon S3와 같은 클라우드 환경에 업로드되는 즉시 분석을 시작해야 하는 경우가 있습니다. 사용자가 별도의 작업을 트리거하지 않아도, 신규 영상을 시스템이 자동으로 감지하고 새 영상에 대해 비디오 임베딩 및 분석 작업을 시작합니다. 여러 방법 중 대표적인 2가지 방법을 설명합니다.
적합한 사례
- UGC(User Generated Content) 플랫폼: 사용자가 영상을 업로드하면 즉시 영상을 요약하고 검색
- 미디어 서비스(예.CMS): 영상이 올라오면 바로 중요 구간을 찾아 편집하거나 메타데이터 추출
- 콘텐츠 모더레이션: 업로드 즉시 부적절한 콘텐츠를 감지
방법 A: S3 Event Notification + Lambda
Amazon S3 Event Notifications를 활용하는 방식은 저장된 영상에 대해 후처리를 진행할 수 있는 가장 단순한 구성입니다. Amazon S3 버킷에 영상이 업로드되면 Event Notification이 AWS Lambda 함수를 직접 호출하고, Lambda가 Bedrock의 Marengo API를 호출하여 임베딩을 생성합니다.
다음 예시에서는 아래와 같은 트리거 조건을 사용하였습니다.
- 이벤트: s3:ObjectCreated:*
- input Prefix: videos/
- output Prefix: embeddings/
- Suffix: .mp4
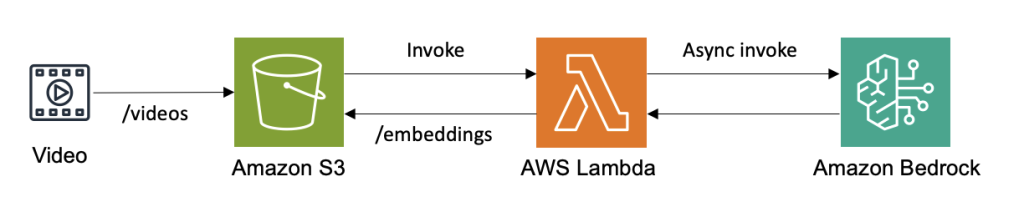 [그림 1. S3 Event Notification + Lambda를 활용한 단일 호출]
[그림 1. S3 Event Notification + Lambda를 활용한 단일 호출]
방법 B: Amazon EventBridge Event Buses + Rules
Amazon EventBridge Event Buses + Rules 방식을 사용하면 다음과 같은 이점이 있습니다.
- 단일 이벤트, 다중 타겟 하나의 영상 업로드 이벤트에 대해 여러 Rule을 정의하여 동시에 다른 작업을 트리거할 수 있습니다. 예를 들어, 영상이 업로드되면 임베딩 생성, 썸네일 추출, 메타데이터 저장을 병렬로 실행하여 전체 처리 시간을 단축할 수 있습니다.
- 이벤트 기반 느슨한 결합 S3 이벤트를 EventBridge로 라우팅하면 이벤트 생산자(S3)와 소비자(Lambda, Step Functions 등)가 완전히 분리됩니다. 새로운 처리 로직을 추가할 때 기존 설정을 수정할 필요 없이 Rule만 추가하면 되며, 시스템 확장이 용이합니다.
- 중앙 집중식 모니터링 모든 이벤트 흐름이 EventBridge를 통과하므로 CloudWatch에서 이벤트 발생량, 매칭된 Rule, 타겟 호출 성공/실패를 한눈에 파악할 수 있습니다. 문제 발생 시 어느 단계에서 실패했는지 빠르게 추적할 수 있습니다.
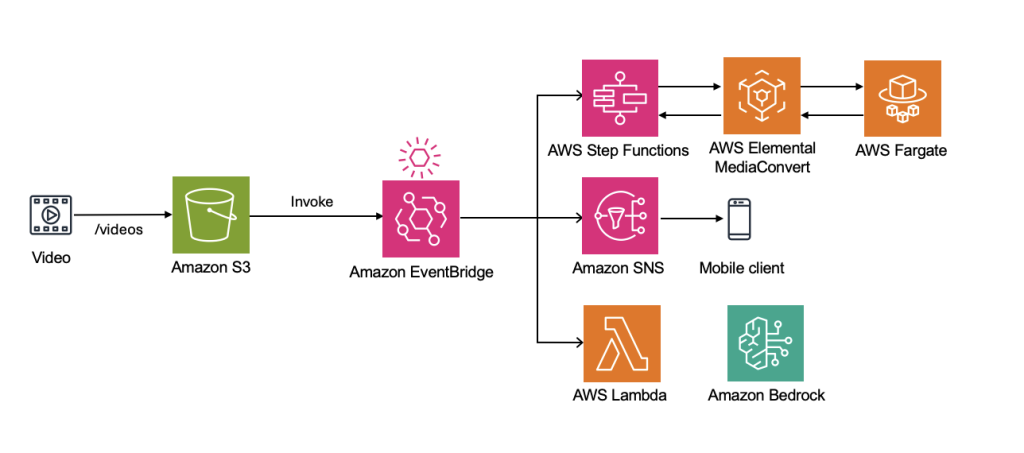 [그림 2. S3 EventBridge Event Buses + Rules를 이용한 다중 작업 실행 아키텍쳐 예시]
[그림 2. S3 EventBridge Event Buses + Rules를 이용한 다중 작업 실행 아키텍쳐 예시]
사용자는 Amazon EventBridge 콘솔의 좌측 Rules탭에서 드래그&드랍 방식으로 전체 플로우를 설정할 수 있습니다.
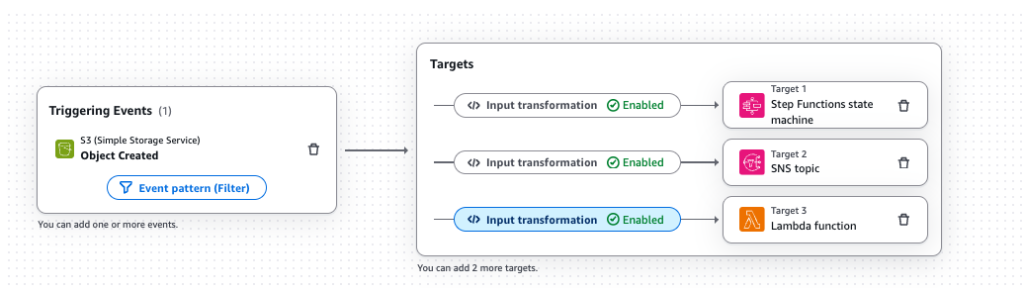 [그림 3. EventBridge Rules를 활용한 다중 타겟 지정 예시]
[그림 3. EventBridge Rules를 활용한 다중 타겟 지정 예시]
아래 그림과 같이 S3 버킷에서 EventBridge 알림이 활성화되어 있는지 확인을 하고 진행합니다. 
[그림 4. S3버킷 속성 탭에서 Amazon EventBridge 활성화]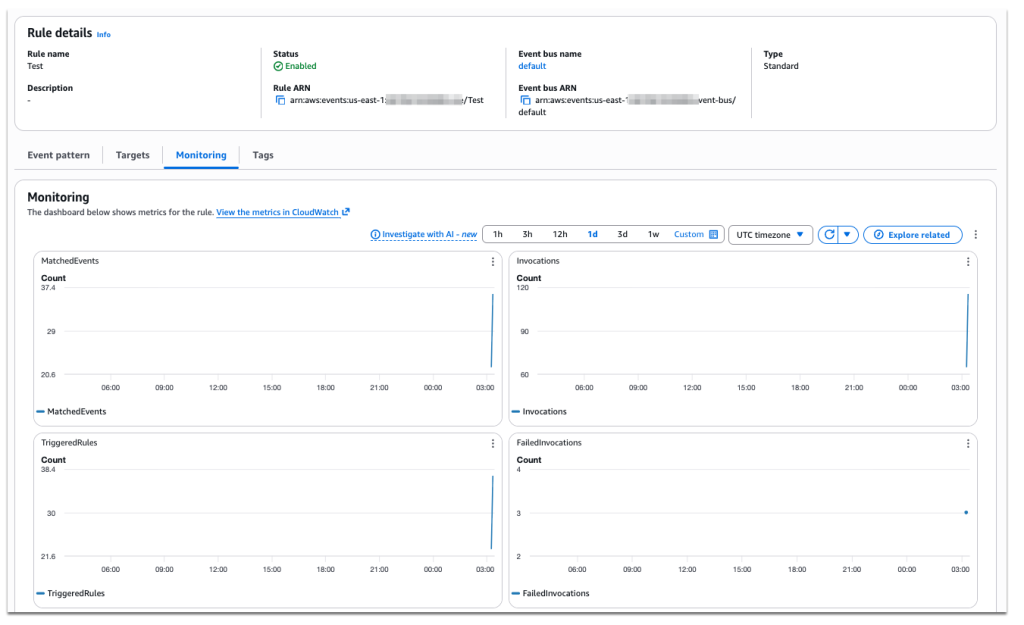 [그림 5. Rules 모니터링 탭에서 결과 모니터링]
[그림 5. Rules 모니터링 탭에서 결과 모니터링]
*모니터링에서 보여주는 메트릭은 다음과 같습니다.
- MatchedEvents: 이벤트 패턴과 일치한 이벤트 개수
- Invocations: 룰이 타깃을 실제로 호출한 총 횟수
- TriggeredRules: 특정 이벤트로 트리거된 룰의 개수
- FailedInvocations: 재시도 후에도 최종 실패로 끝난 타깃 호출 횟수
Option 2: 대규모 영상 배치 처리
이미 축적된 대량의 영상에 비디오 분석을 수행하거나, 매일 적재되는 영상을 근무 시간 외에 일괄 처리해야 하는 경우가 있습니다. 이처럼 실시간성보다 처리 효율과 비용 최적화가 중요하고, 정해진 스케줄에 따라 영상 분석 작업을 체계적으로 제어해야 할 때 적합한 방식입니다.
적합한 사례
- 미디어 아카이브 마이그레이션: 수백, 수천 개의 기존 영상을 체계적으로 처리해야 할 때
- 스케줄 기반 처리: 매일 특정 시간에 전날 업로드된 영상을 일괄 처리해야 할 때
방법 A: MWAA (Amazon Managed Workflows for Apache Airflow)
MWAA (Amazon Managed Workflows for Apache Airflow)는 Airflow에 익숙한 엔지니어가 DAG(Directed Acyclic Graph)로 비디오 분석 워크플로우를 정의하고, 웹 UI에서 실행 상태를 모니터링하는 상황에 적합합니다.
아키텍처 흐름
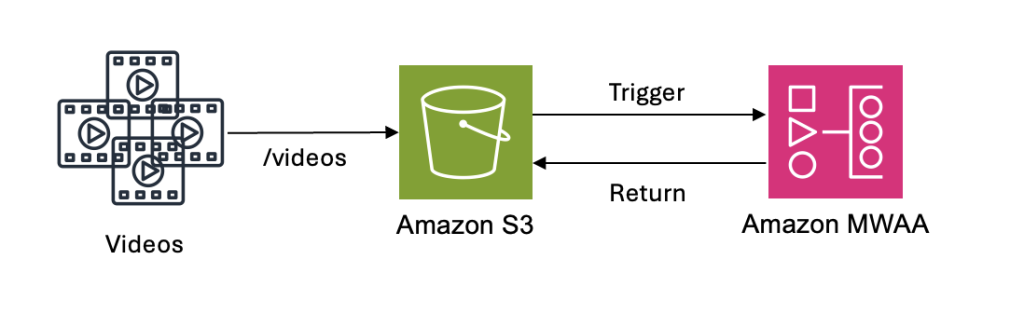 [그림 6. MWAA를 활용한 비디오 분석 워크플로우 정의]
[그림 6. MWAA를 활용한 비디오 분석 워크플로우 정의]
아래 예시는 특정 Amazon S3버킷의 videos/ 경로에 5개의 프록시 영상(Proxy)을 저장해둔 상태입니다. 
[그림 7. videos 폴더에 저장된 프록시 영상]
video_embedding_batch Dag는 매일 새벽2시에 videos/폴더에 저장된 프록시 영상 중, 임베딩 작업이 실행되지 않은 비디오에 대해서 일괄 임베딩 작업을 실행하도록 설정돼 있습니다. 
[그림 8. video_embedding_batch Dag Schedule 설정]
아래 이미지는 AWS MWAA (Managed Workflows for Apache Airflow) DAG 대시보드의 태스크 로그 뷰어 화면입니다. 구체적으로 DAG 실행 완료 후 로그 분석 상태를 보여주며, 작업이 성공적으로 마무리된 것을 확인할 수 있습니다. Airflow UI에서 태스크 로그를 레벨별로 시각화하고 있으므로 단계별 발생한 이슈를 쉽게 파악하고 조치할 수 있습니다.
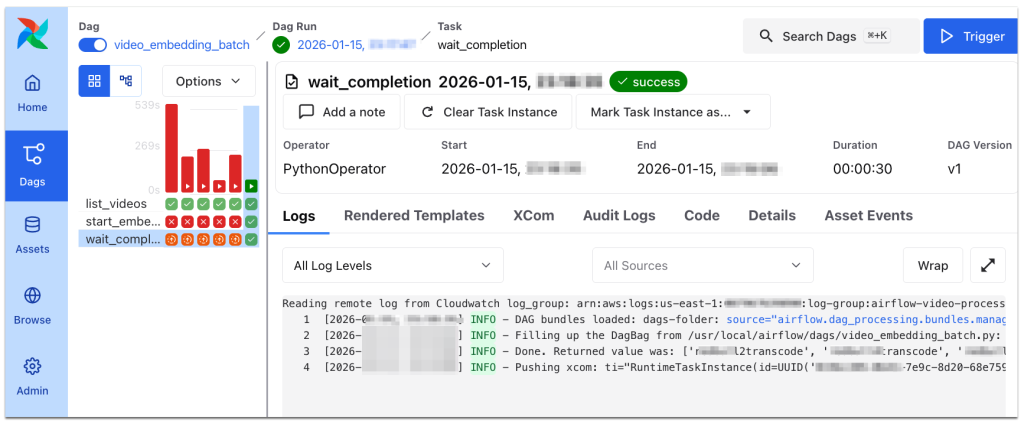 [그림 9. 성공 태스크의 로그 뷰어 화면]
[그림 9. 성공 태스크의 로그 뷰어 화면]
상세 로그를 보면 videos/ 폴더에 저장된 5개의 영상에 대해 신규 임베딩 작업이 성공적으로 수행된 것을 확인할 수 있습니다.
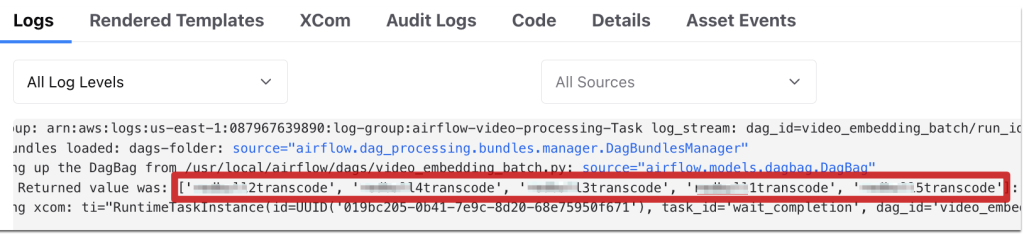 [그림 10. 성공 태스크에 대한 상세 로그 내용]
[그림 10. 성공 태스크에 대한 상세 로그 내용]
방법 B: EventBridge Scheduler + Lambda or StepFunctions
MWAA는 Airflow 생태계의 강력한 기능을 제공합니다. 하지만 단순한 스케줄 기반 배치 처리가 필요한 경우, 이에 걸맞는 단순한 선택이 더 나은 선택일 수도 있습니다. Amazon EventBridge Scheduler는 크론(cron) 또는 rate 표현식으로 정해진 시간에 200개 이상의 AWS 서비스를 직접 호출할 수 있는 서버리스 스케줄러입니다. 별도의 인프라 관리 없이 스케줄을 생성하고, 재시도 정책과 DLQ(Dead Letter Queue)를 설정할 수 있어 운영 부담이 최소화됩니다.
타겟 서비스로 Lambda를 선택하면 가장 가볍고 빠르게 구성할 수 있고, AWS Step Functions를 선택하면 복잡한 워크플로우를 시각적으로 오케스트레이션할 수 있습니다. 두 옵션 모두 완전 서버리스로 동작하며, 처리할 영상이 없는 시간에는 비용이 전혀 발생하지 않습니다.
옵션 1: EventBridge Scheduler + Lambda
가장 단순하고 빠르게 구성할 수 있는 조합입니다. EventBridge Scheduler가 크론 표현식에 따라 Lambda 함수를 직접 호출하고, Lambda가 S3에서 미처리 영상 목록을 조회한 뒤 Bedrock의 비동기 추론 API(StartAsyncInvoke)를 통해 임베딩 작업을 시작합니다.
참고: TwelveLabs Marengo 모델의 비디오 임베딩은 비동기 추론만 지원합니다. InvokeModel은 텍스트/이미지 입력에만 사용할 수 있으며, 비디오 입력은 반드시 StartAsyncInvoke를 사용해야 합니다.
주의: StartAsyncInvoke는 inference profile(예: apac.twelvelabs.marengo-embed-2-7-v1:0)을 지원하지 않습니다. 반드시 base model ID(예: twelvelabs.marengo-embed-2-7-v1:0)를 사용해야 합니다.
아키텍처 흐름
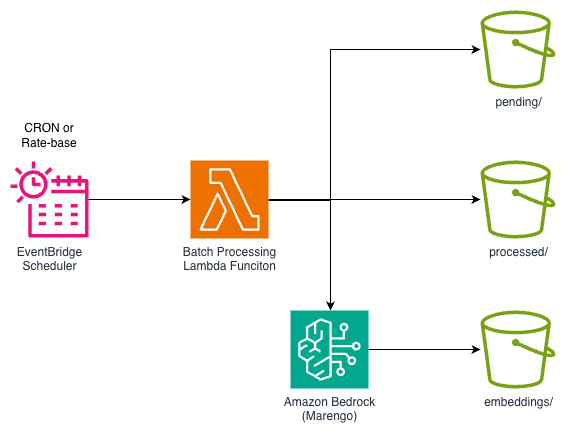 [그림 11. EventBridge Scheduler + Lambda를 활용한 배치 처리 아키텍처]
[그림 11. EventBridge Scheduler + Lambda를 활용한 배치 처리 아키텍처]
- EventBridge Scheduler가 설정된 크론 표현식(예: 매일 새벽 2시)에 따라 Lambda 함수를 비동기로 호출합니다.
- Lambda 함수는 S3 버킷의
pending/폴더에서 미처리 영상 목록을 조회합니다. - 각 영상에 대해 Amazon Bedrock의
StartAsyncInvokeAPI를 호출하여 비동기 임베딩 작업을 시작합니다. - 비동기 작업이 완료되면 json 결과값은 S3
embeddings/폴더에 자동으로 저장됩니다. - 재처리 방지를 위해 처리 완료된 영상은 기존
pending/에서processed/폴더로 이동됩니다.
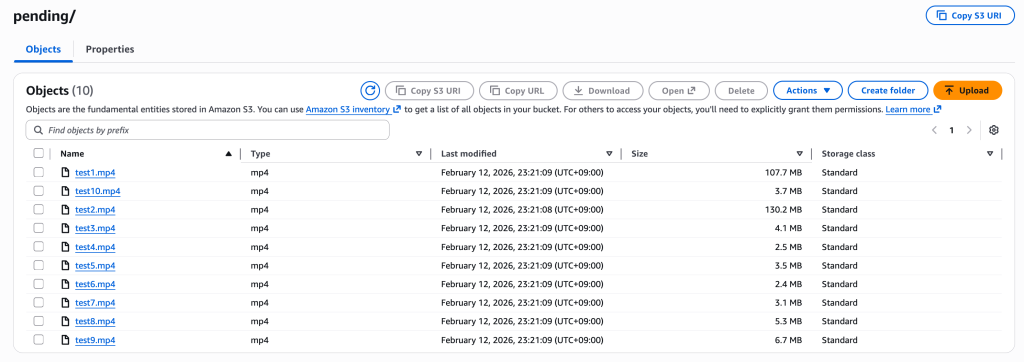 [그림 12. S3 pending/ 폴더에 저장된 10개 영상들]
[그림 12. S3 pending/ 폴더에 저장된 10개 영상들]
주요 특징
- 최소 구성: EventBridge Scheduler 1개 + Lambda 함수 1개로 전체 파이프라인 구성
- 비용 효율: EventBridge Scheduler 프리 티어(월 1,400만 호출)와 Lambda 프리 티어(월 100만 요청)를 활용하면 소규모 워크로드에서 거의 무료로 운영 가능
- 빠른 배포: 별도의 인프라 프로비저닝 없이 콘솔에서 수 분 내에 설정 완료
- 비동기 처리: Lambda는 임베딩 작업을 시작만 하고 즉시 반환하므로, 영상 길이와 관계없이 많은 수의 작업을 빠르게 제출 가능
제약 사항
- 비동기 API 특성상 Lambda 실행 시점에 임베딩 결과를 바로 받을 수 없습니다. 작업 완료 여부는
GetAsyncInvokeAPI로 폴링하거나, EventBridge를 통해 완료 이벤트를 수신해야 합니다. - 개별 영상 처리 실패 시 전체 배치가 실패할 수 있으므로, 코드 레벨에서 try-catch 기반의 에러 핸들링이 필요합니다.
아래는 EventBridge Scheduler에서 스케줄을 지정하는 방식입니다. Cron expression을 통해 지정하며, Rate-based 스케줄 역시 지정할 수 있습니다. 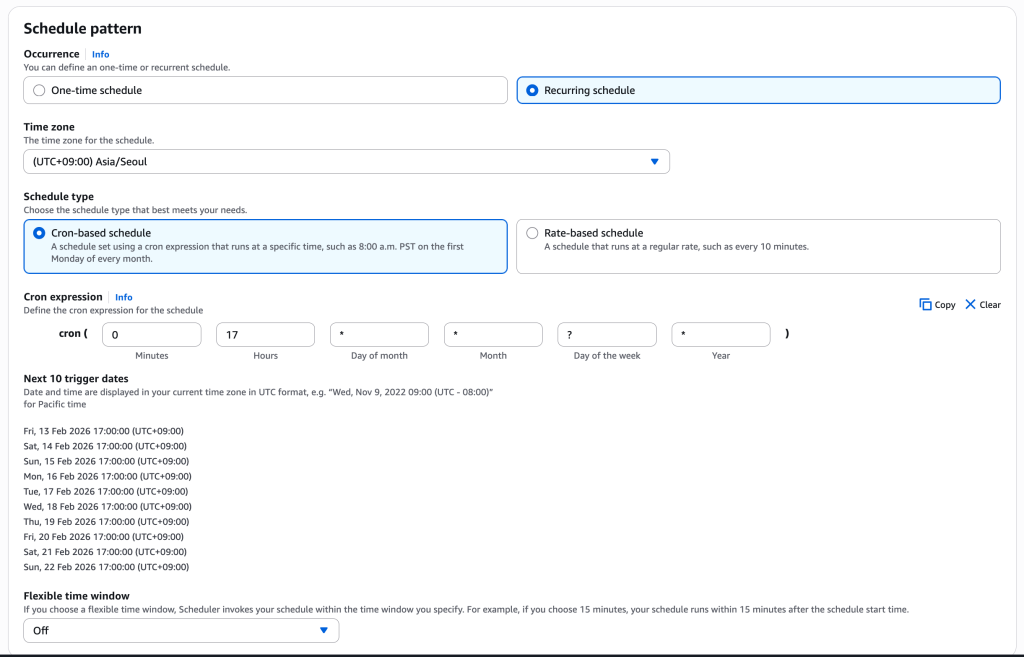
[그림 13. EventBridge Scheduler 콘솔에서 크론 스케줄 설정 예시]
아래는 EventBridge Scheduler에서 Lambda를 타겟으로 지정하는 설정 화면입니다. 타겟 API로 AWS Lambda를 선택하고, 대상 Lambda 함수의 ARN을 지정합니다.
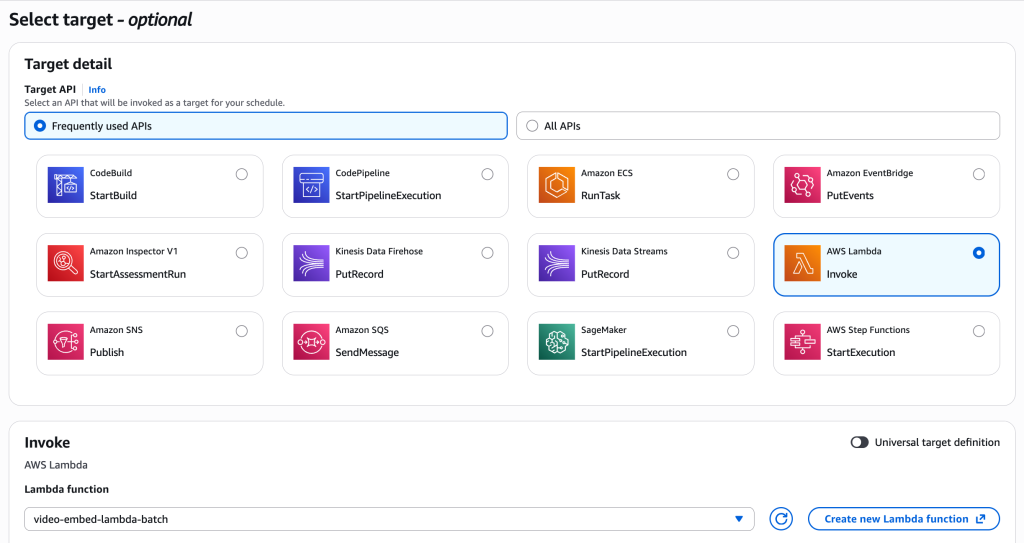 [그림 14. EventBridge Scheduler에서 Lambda 타겟 지정]
[그림 14. EventBridge Scheduler에서 Lambda 타겟 지정]
아래는 타겟 Lambda가 Marengo 모델을 활용하는 예시 코드입니다.
Lambda 함수가 실행되면 CloudWatch Logs에서 처리 결과를 확인할 수 있습니다. 아래 로그에서는 pending/ 폴더의 영상을 순차적으로 처리하고, 각 영상의 임베딩 생성 완료 여부를 기록하고 있습니다.
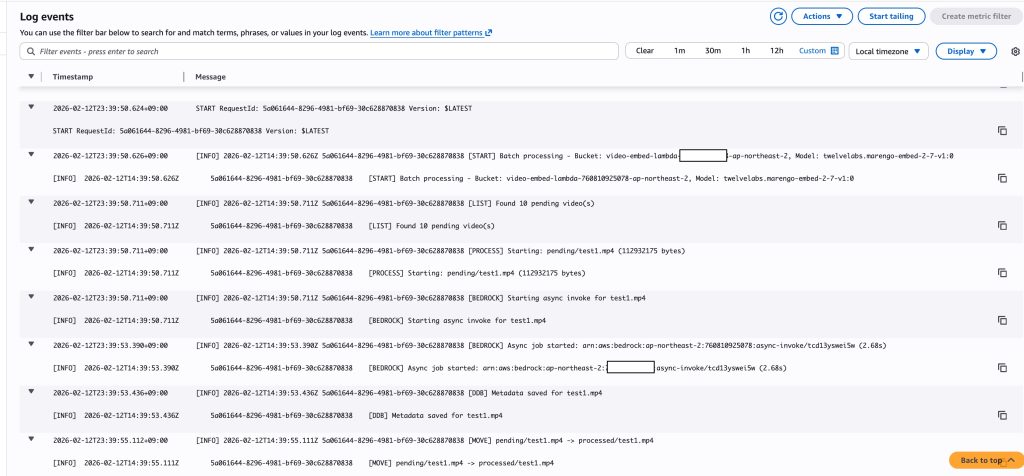 [그림 15. Lambda 실행 로그에서 배치 처리 결과 확인]
[그림 15. Lambda 실행 로그에서 배치 처리 결과 확인]
아래와 같이 영상들이 processed/ 경로로 옮겨지고, 임베딩도 올바르게 생성된 것을 볼 수 있습니다. 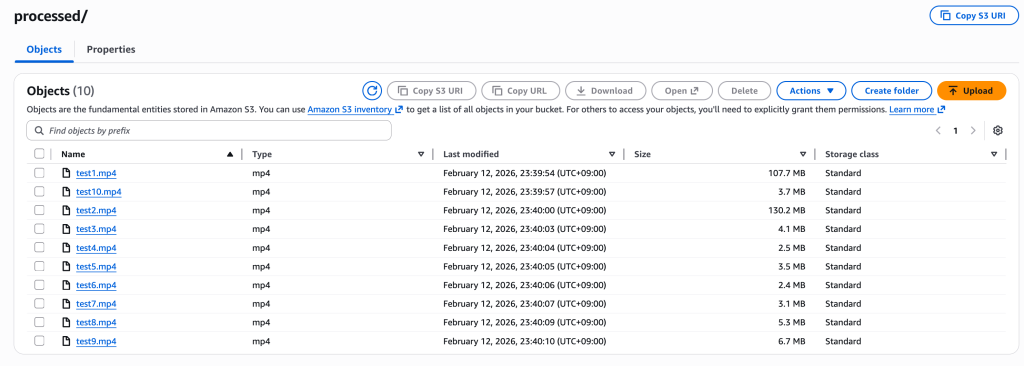
[그림 16. 영상 처리 후, S3 processed/ 폴더에 저장된 10개 영상들]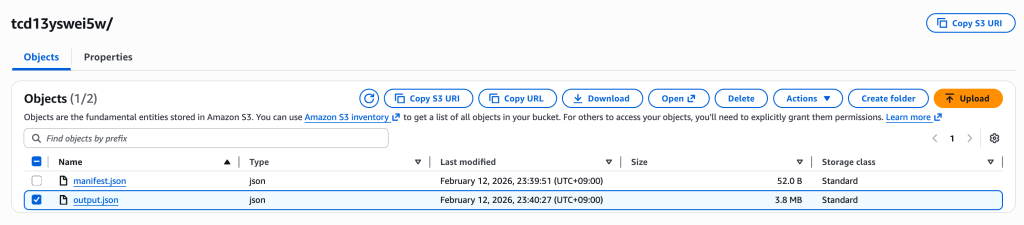 [그림 17. 임베딩 처리 후, 확인 가능한 output.json 파일]
[그림 17. 임베딩 처리 후, 확인 가능한 output.json 파일]  [그림 18. 예시 ouput.json 파일 내용]
[그림 18. 예시 ouput.json 파일 내용]
옵션 2: EventBridge Scheduler + Step Functions
처리할 영상 수가 많거나, 영상별로 여러 단계의 분석(임베딩 생성 → 메타데이터 추출 → 결과 저장)을 수행해야 하는 경우에는 Step Functions가 더 적합합니다. 특히 Step Functions의 Distributed Map 상태를 활용하면 S3의 영상 목록을 자동으로 읽어 최대 10,000개의 병렬 자식 워크플로우를 실행할 수 있어, 대규모 배치 처리에서 처리 시간을 획기적으로 단축할 수 있습니다.
아키텍처 흐름
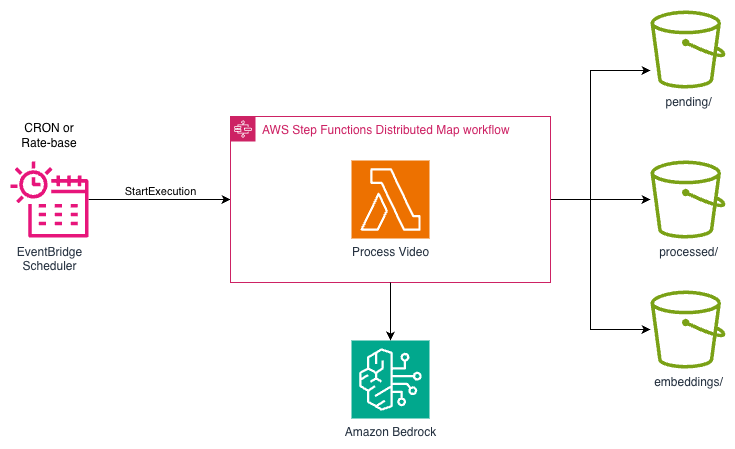 [그림 19. EventBridge Scheduler + Step Functions + Lambda를 활용한 배치 처리 아키텍처]
[그림 19. EventBridge Scheduler + Step Functions + Lambda를 활용한 배치 처리 아키텍처]
- EventBridge Scheduler가 Lambda와 유사하게 설정된 크론 표현식에 따라 Step Functions 상태 머신(State Machine)의 실행을 시작합니다.
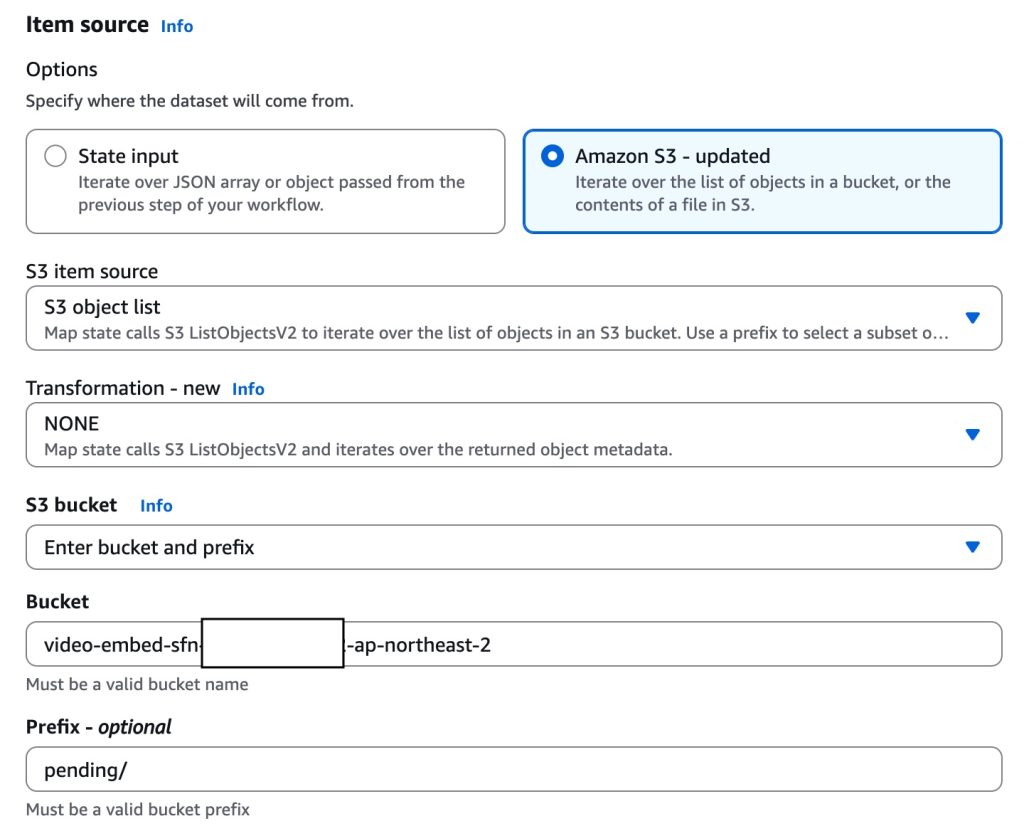
- 상태 머신의 Distributed Map 상태가 S3 버킷의
pending/폴더를 ItemReader로 지정하여 미처리 영상 목록을 자동으로 수집합니다. - 각 영상에 대해 자식 워크플로우(Child Workflow Execution)가 병렬로 실행됩니다. 자식 워크플로우 내에서 Lambda 함수가 Bedrock의
StartAsyncInvokeAPI를 호출하여 비동기 임베딩 작업을 시작합니다. - 개별 영상 처리 실패 시 Step Functions의 내장 재시도(Retry) 및 에러 핸들링(Catch)이 자동으로 동작하여, 일시적 오류에 대해 지수 백오프(Exponential Backoff)로 재시도합니다.
- 모든 비동기 작업이 제출되면 결과는 S3
embeddings/폴더에 자동으로 저장되고, 처리 완료된 영상은processed/폴더로 이동됩니다.
주요 특징
- 대규모 병렬 처리: Distributed Map으로 수십개의 영상을 동시에 처리하여 전체 배치 시간을 대폭 단축
- 내장 에러 핸들링: 개별 영상 실패가 전체 배치에 영향을 주지 않으며, 실패한 항목만 자동 재시도
- 시각적 워크플로우 모니터링: Step Functions 콘솔에서 각 영상의 처리 상태를 실시간으로 확인 가능
- 유연한 워크플로우 구성: 임베딩 생성 외에 썸네일 추출, 메타데이터 저장 등 후속 단계를 워크플로우에 쉽게 추가 가능
제약 사항
- Lambda 단독 구성 대비 아키텍처 복잡도가 높고, 상태 머신 정의(ASL: Amazon States Language)에 대한 이해가 필요합니다.
- Step Functions Standard Workflow의 상태 전환(State Transition)당 과금이 발생하므로, 영상 수가 매우 적은 경우에는 Lambda 단독 구성이 더 비용 효율적일 수 있습니다.
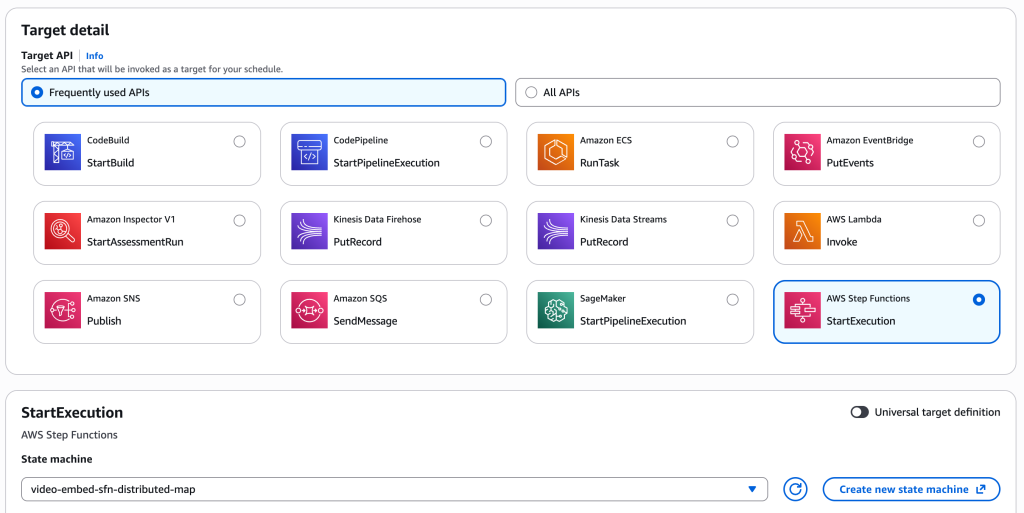 [그림 20. EventBridge에 Step Functions가 Target인 예시]
[그림 20. EventBridge에 Step Functions가 Target인 예시]
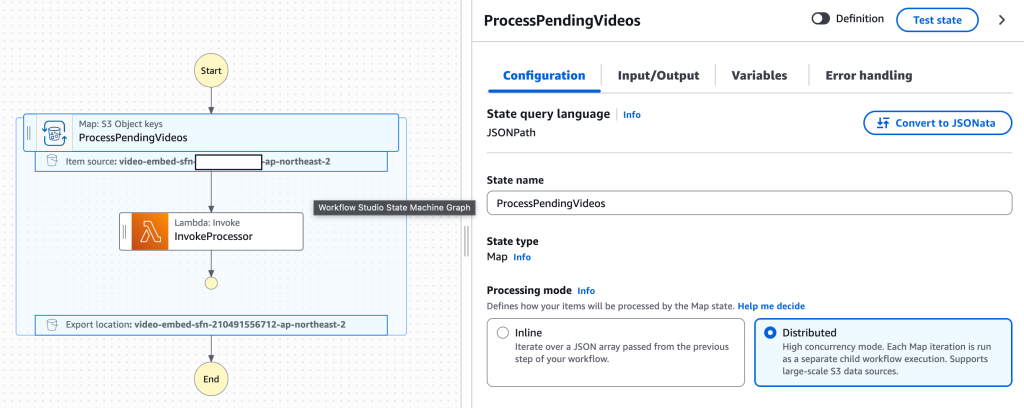
 [그림 21. Step Functions Workflow Studio에서 Distributed Map 구성 예시]
[그림 21. Step Functions Workflow Studio에서 Distributed Map 구성 예시]
아래는 Step Functions 콘솔에서 상태 머신 실행 결과를 확인하는 화면입니다. Distributed Map의 각 자식 워크플로우 실행 상태(성공/실패)를 한눈에 파악할 수 있습니다.
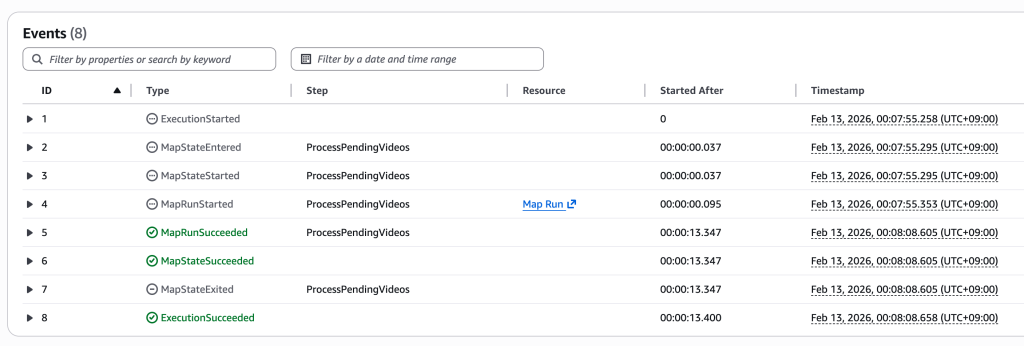
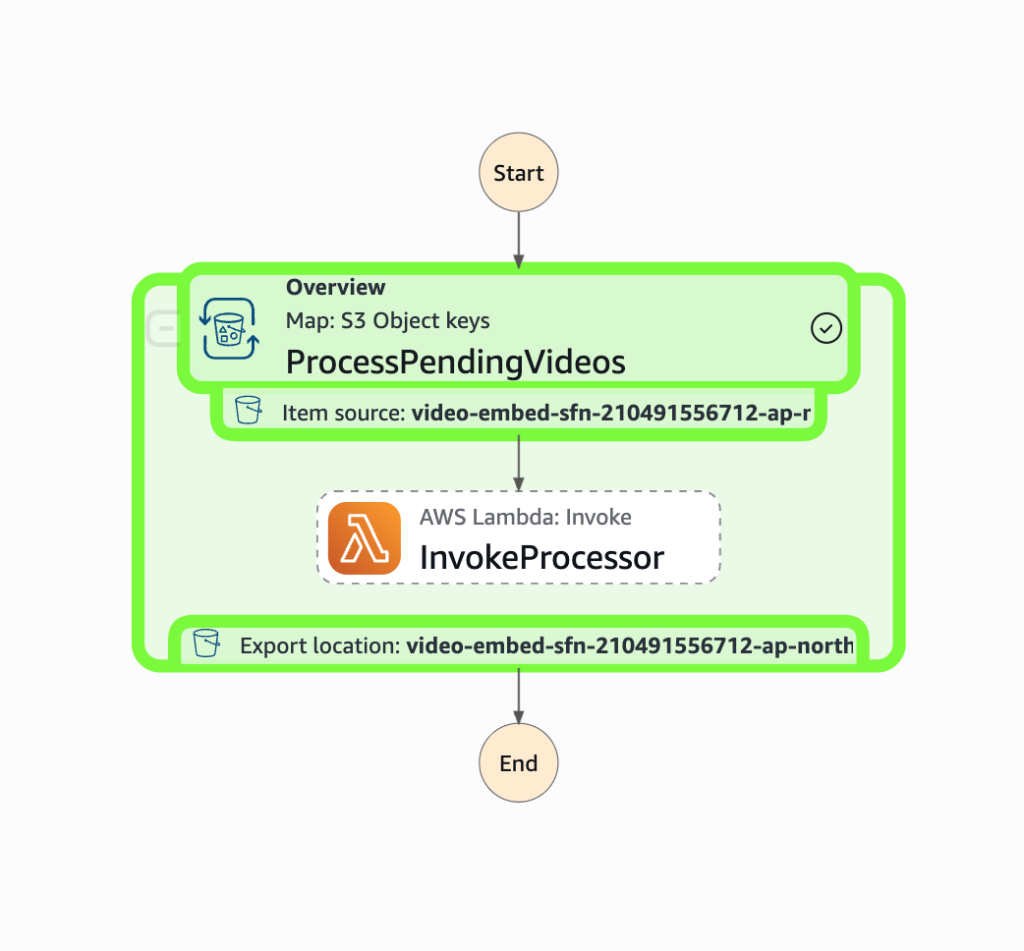 [그림 22. Step Functions 실행 결과 화면]
[그림 22. Step Functions 실행 결과 화면]
Lambda 함수 예시는 아래와 같습니다.
import boto3, json, os, time, logging
from datetime import datetime, timezone
logger = logging.getLogger()
logger.setLevel(logging.INFO)
s3 = boto3.client('s3')
ddb = boto3.resource('dynamodb')
bedrock = boto3.client('bedrock-runtime')
BUCKET = os.environ['BUCKET_NAME']
TABLE = os.environ['TABLE_NAME']
MODEL_ID = os.environ['MODEL_ID']
def handler(event, context):
"""Process a single video from Distributed Map input."""
key = event.get('Key', '')
logger.info(f"[START] Processing single video: {key}")
if not key or not key.startswith('pending/'):
logger.info(f"[SKIP] Not a pending video: {key}")
return {'status': 'skipped', 'key': key}
ext = key.lower().split('.')[-1]
if ext not in ('mp4', 'mov', 'avi'):
logger.info(f"[SKIP] Not a video file: {key}")
return {'status': 'skipped', 'key': key}
filename = key.split('/')[-1]
start = time.time()
table = ddb.Table(TABLE)
try:
# 1. Call Bedrock Marengo API (async for video)
s3_uri = f"s3://{BUCKET}/{key}"
result_key = f"embeddings/{filename}"
account_id = context.invoked_function_arn.split(':')[4]
model_input = {
"inputType": "video",
"mediaSource": {"s3Location": {"uri": s3_uri, "bucketOwner": account_id}}
}
logger.info(f"[BEDROCK] Starting async invoke for {filename}")
br_resp = bedrock.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={"s3OutputDataConfig": {"s3Uri": f"s3://{BUCKET}/{result_key}"}}
)
invocation_arn = br_resp['invocationArn']
elapsed = round(time.time() - start, 2)
logger.info(f"[BEDROCK] Async job started: {invocation_arn} ({elapsed}s)")
# 2. Save metadata to DynamoDB
table.put_item(Item={
'video_key': key,
'status': 'processing',
'invocation_arn': invocation_arn,
'result_key': result_key,
'started_at': datetime.now(timezone.utc).isoformat()
})
logger.info(f"[DDB] Metadata saved: {filename}")
# 3. Move to processed/
new_key = f"processed/{filename}"
s3.copy_object(Bucket=BUCKET, CopySource={'Bucket': BUCKET, 'Key': key}, Key=new_key)
s3.delete_object(Bucket=BUCKET, Key=key)
logger.info(f"[MOVE] {key} -> {new_key}")
return {'status': 'success', 'key': key, 'invocation_arn': invocation_arn, 'elapsed': elapsed}
except Exception as e:
elapsed = round(time.time() - start, 2)
logger.error(f"[ERROR] {key}: {str(e)} ({elapsed}s)")
raise # Let Step Functions handle retryLambda vs. Step Functions: 어떤 것을 선택할까?
| 기준 | Lambda 단독 | Step Functions |
|---|---|---|
| 처리 영상 수 | 소규모 | 대규모 (수십건 병렬 처리) |
| 처리 방식 | 순차적 비동기 작업 제출 | 대규모 병렬 비동기 작업 제출 |
| 에러 핸들링 | 코드 레벨 직접 구현 | 내장 Retry/Catch 자동 처리 |
| 워크플로우 복잡도 | 단일 작업 (임베딩 작업 제출) | 다단계 파이프라인 (분석 → 저장 → 알림) |
정리하면, 매일 수십 건 이하의 영상을 단순히 임베딩 처리하는 경우에는 Lambda 단독 구성이 가장 효율적입니다. 반면, 수십 건 이상의 영상을 병렬로 처리하거나, 임베딩 외에 추가 분석 단계가 필요한 경우에는 Step Functions의 Distributed Map을 활용하는 것이 처리 시간과 안정성 측면에서 유리합니다.
방법 C: AWS Batch
영상 콘텐츠가 폭발적으로 증가하면서, 대규모 영상을 효율적으로 분석하고 의미 있는 메타데이터를 추출하는 일이 중요한 과제로 떠오르고 있습니다. 이러한 환경에서 AWS Batch는 처리 시간이 길고 주기적으로 실행되며, 실시간 응답이 필요 없는 대용량 영상 분석 워크로드에 매우 적합한 선택지입니다. AWS Batch의 주요 장점은 다음과 같습니다.
- 비용 효율성 Spot Instance를 활용하면 컴퓨팅 비용을 약 70~90%까지 절감할 수 있으며, 작업이 없는 경우 인스턴스 수가 자동으로 0까지 축소되어 불필요한 비용이 전혀 발생하지 않습니다.
- 완전 자동화된 운영 작업량에 따라 컴퓨팅 리소스가 자동으로 확장·축소되므로 별도의 운영 개입이 거의 필요 없습니다. 또한 완전 관리형 서비스이기 때문에 인프라 운영에 대한 부담을 크게 줄일 수 있습니다.
- 안정적인 대규모 배치 처리 컨테이너 기반으로 대규모 배치 작업을 실행하며, 작업 실패 시 자동 재시도와 Spot Instance 중단에 대한 대응 기능이 기본으로 제공됩니다. 특히 Array Job을 활용하면 수많은 배치 작업을 효율적으로 제출하고 관리할 수 있습니다.
특히 AWS Batch는 TwelveLabs 모델 호출뿐만 아니라 OCR, 텍스트 추출, 오디오 추출 등 하나의 영상을 기반으로 여러 분석 워크로드를 병렬 또는 순차적으로 처리해야 하는 복잡한 시나리오에서 더욱 강력한 가치를 제공합니다. 이러한 특성 덕분에 대규모 영상 분석 파이프라인을 유연하고 안정적으로 구성할 수 있습니다.
아키텍처 흐름
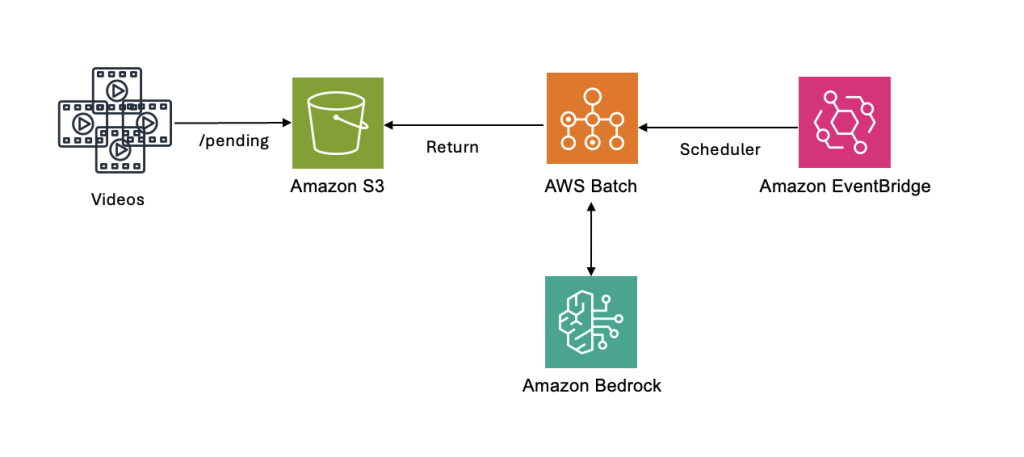 [그림 23. AWS Batch를 활용한 비디오 분석 워크플로우 정의]
[그림 23. AWS Batch를 활용한 비디오 분석 워크플로우 정의]
- 분석이 필요한 영상은 S3 버킷의 pending/ 폴더에 업로드됩니다.
- EventBridge Scheduler가 설정된 주기(예: 매시간, 매일)에 따라 AWS Batch Job을 트리거합니다. Batch Job이 시작되면 Compute Environment에서 EC2 Spot Instance가 자동으로 프로비저닝되고, 분석 로직이 담긴 컨테이너가 실행됩니다.
- 컨테이너는 먼저 S3 pending/ 폴더에 있는 영상 목록을 조회합니다. 각 영상에 대해 Amazon Bedrock의 TwelveLabs Marengo API를 호출하여 영상 분석을 수행합니다. Marengo는 영상의 요약, 태그, 장면 정보 등을 추출하여 JSON 형태로 반환합니다.
- 분석이 완료되면 전체 결과는 S3 results/ 폴더에 JSON 파일로 저장되고, 이후 처리가 완료된 영상은 pending/ 에서 processed/ 폴더로 이동되어 재처리 대상에서 제외됩니다.
- 모든 영상 처리가 완료되면 Batch Job이 종료되고, EC2 인스턴스는 자동으로 축소되어 비용이 발생하지 않습니다. 다음 스케줄 주기에 새로운 영상이 pending/ 에 있으면 동일한 프로세스가 반복됩니다.
테스트 결과는 다음과 같습니다.
아래 예시는 특정 Amazon S3버킷의 pending/ 경로에 2개의 작업할 영상을 저장해둔 상태입니다. 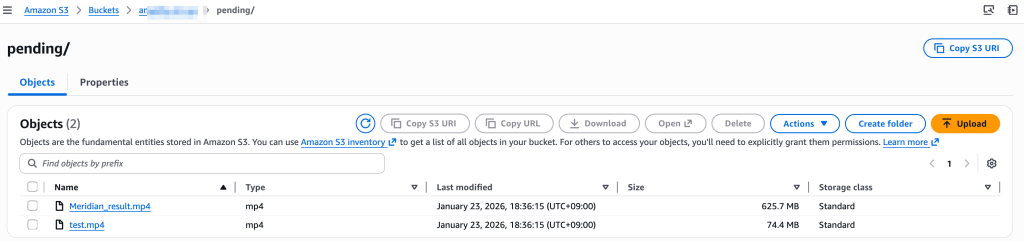
[그림 24. AWS Batch를 작업전 영상]
하기와 같은 CLI 명령어로 AWS Batch Job를 수동으로 생성합니다.
aws batch submit-job \
—job-name video-analysis-$(date +%Y%m%d-%H%M%S) \
—job-queue video-analysis-job-queue \
—job-definition video-analysis-analyzer \
—region us-east-1
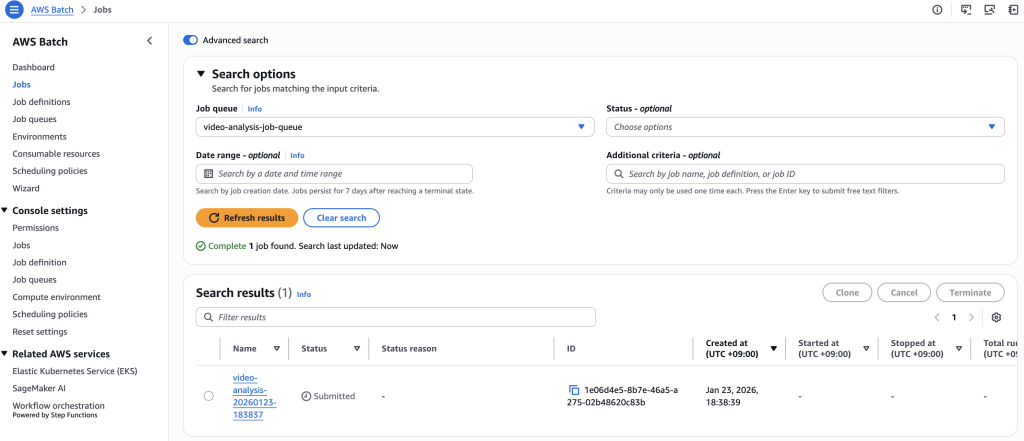 [그림 25. AWS Batch Job 상태]
[그림 25. AWS Batch Job 상태]
Job이 정상적으로 실행되면 상태가 RUNNING을 거쳐 SUCCEEDED로 변경되며, 이는 모든 영상 분석 작업이 성공적으로 완료되었음을 의미합니다. 작업이 완료되면 pending/ 경로에 있던 영상은 자동으로 processed/ 폴더로 이동하며, results/ 경로에는 각 영상별 분석 결과가 저장된 것을 확인할 수 있습니다.
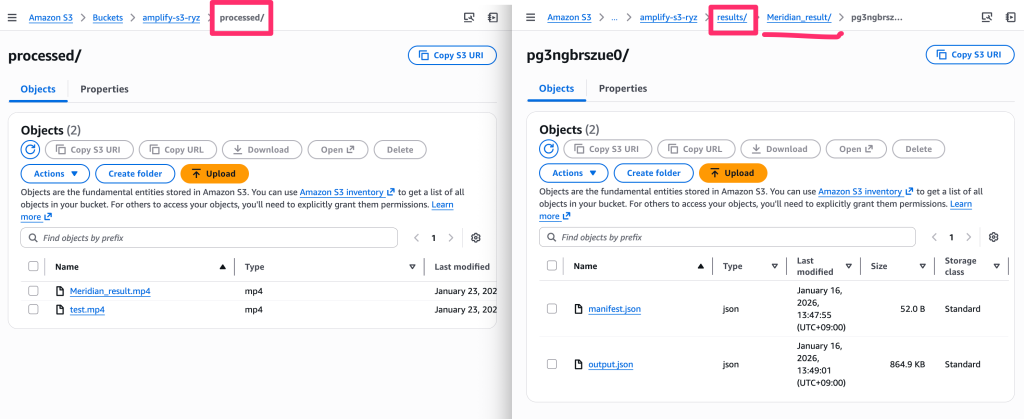 [그림 26. S3 버킷 결과 확인]
[그림 26. S3 버킷 결과 확인]
또한 Amazon CloudWatch Logs를 통해 각 AWS Batch Job의 실행 로그를 확인할 수 있으며, 이를 통해 영상별 처리 과정, 분석 단계별 로그, 오류 발생 여부 등을 상세하게 추적할 수 있습니다. 아래 예시에서는 2개의 영상에 대한 처리 프로세스를 단계별 로그로 확인할 수 있으며, 이를 통해 배치 작업의 진행 상태를 쉽게 파악하고 문제 발생 시 신속하게 조치할 수 있습니다.
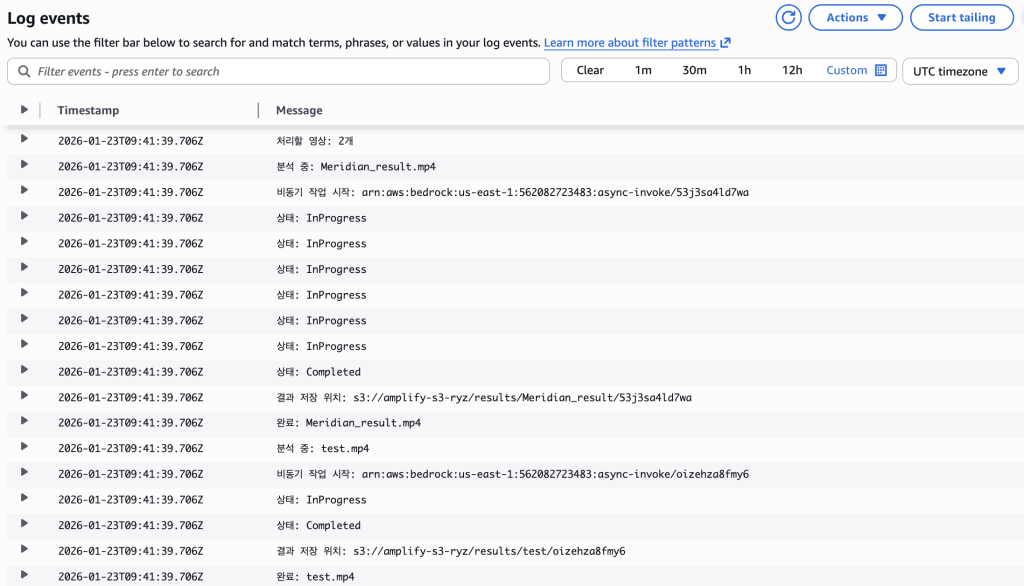 [그림 27. Batch Job 로그 확인]
[그림 27. Batch Job 로그 확인]
결론
TwelveLabs Marengo와 AWS 서비스를 조합하면 VoD 환경에서 강력한 비디오 인텔리전스 파이프라인을 구축할 수 있습니다. 즉시 처리가 필요한 경우 이벤트 기반 아키텍처를, 대규모 배치 처리가 필요한 경우 스케줄링 또는 배치 처리 아키텍처를 선택할 수 있습니다.
Marengo의 멀티모달 임베딩을 통해 “자연어로 영상을 검색”하는 새로운 가능성이 열리고 이에 따라 사용자는 영상 메타데이터에 의존하지 않고도 영상 속 장면을 검색할 수 있습니다. 2부에서는 준실시간으로 비디오 분석 파이프라인을 구성하는 아키텍쳐 및 방법론을 살펴봅니다. 3부에서는 “자연어로 영상을 검색”하는 에이전트를 구현하는 방법에 대해 확인할 수 있습니다.
관련 블로그
- 2부: 클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 2부 – 준실시간 환경에서 AWS 미디어 서비스를 활용한 분석 파이프라인 구축하기
- 3부: 클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 3부 – Strands Agent를 활용한 Agentic video engine구현
- 4부: 클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 4부 – TwelveLabs Marengo 3.0 임베딩 및 검색 전략과 구현 가이드
- 5부: 클라우드 환경에서의 비디오 인텔리전스 구현 : TwelveLabs로 시작하는 AI 영상 분석 5부 – 비디오 임베딩을 위한 Vector DB 비교